
AWS 最近宣布 Amazon S3 支持 Apache Iceberg 表的排序和叠放顺序压缩功能。这些新功能能够有效减少数据扫描时间,降低引擎成本,适用于 S3 表和以及通过 AWS Glue 数据目录优化的传统 S3 存储桶。
排序压缩能够显著减少查询引擎扫描的数据文件数量,而叠放顺序压缩则通过高效的文件修剪,在跨多列查询时进一步提升性能。AWS 首席开发者布道师 Sébastien Stormacq 解释道:
在处理高吞吐量或频繁更新的数据集时,数据湖往往会积累大量小文件,这些文件会对查询成本和性能产生负面影响。尽管默认的 binpack 策略结合托管压缩能够显著提升性能,但为 S3 和 S3 表引入排序和叠放顺序压缩功能,可以为涉及多个维度过滤的查询带来更大的性能提升。
排序压缩会按照用户定义的列顺序对文件进行组织。当表指定了排序顺序后,S3 表的压缩操作会在执行过程中通过排序将相似值聚集在一起。
在 Apache Iceberg 中,压缩功能可用于将小文件合并为大文件(bin packing)、将删除文件与数据文件合并、根据查询模式对数据进行排序,或通过使用空间填充曲线对数据进行聚类以优化不同的查询模式(叠放顺序排序)。
S3 表提供了托管体验,在压缩过程中会根据定义的表元数据自动进行分层排序。对于需要平等优先处理多个查询谓词的场景,可以通过维护 API 启用叠放顺序压缩。对于通用型 S3 存储桶中的 Iceberg 表,可以在 Glue 数据目录控制台配置压缩方法。Stormacq 还提到:
根据我的经验,根据数据布局和查询模式的不同,从 Binpack 切换到排序或叠放顺序压缩时,性能提升可达三倍甚至更多。
宝马的产品经理 Ruben Simon 评论道:
在宝马最大的大数据分析平台上,我们使用了数千个 S3 存储桶和 Iceberg 表,通过采用叠放顺序优化,实现了显著的查询性能提升。如果再加上布隆过滤器,效果会更强大。
在 "S3 Managed Tables, Unmanaged Costs: The 20x Surprise with AWS S3 Tables" 这篇文章中,Onehouse.ai 的软件工程师 Vinish Reddy Pannala 和产品副总裁 Kyle Weller 对压缩的可配置选项不足提出了质疑:
在表创建大约 3 小时后,S3 表最终触发了压缩,执行了 10 次替换操作,并在 1 小时内压缩了大约 100 GB 的数据。这暴露了 S3Tables 方法的一个深层次问题,即它没有考虑到理想的压缩配置应当根据不同类型的读取器和写入器进行调整。
现有的压缩文件将保持不变,只有在启用排序或叠放顺序后写入的新数据才会受到影响,除非客户使用标准的 Iceberg 工具显式重写数据,或者通过调整表维护设置中的目标文件大小来改变这一情况。AWS 首席分析专家 Yonatan Dolan 警告:
每个人都在谈论 Apache Iceberg 中的排序、叠放顺序和 binpack 压缩对查询性能带来的优化。没错,排序确实有效(前提是操作正确),叠放顺序在某些查询上可以超越 binpack。但在我的基准测试中,使用 TPC-H SF100 lineitem 数据集(约 6 亿行 / 17 GB 压缩),我发现了一个更具影响力的因素:文件在压缩前的初始大小会对成本产生巨大影响。
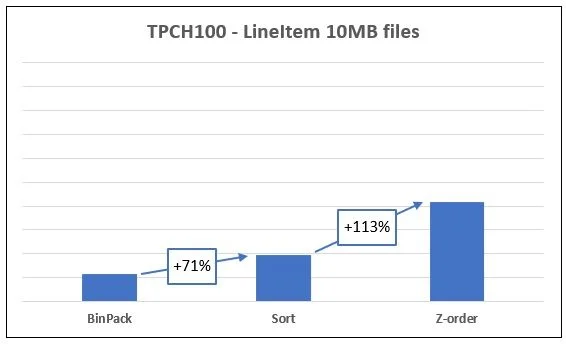
来源:Yonatan Dolan 的帖子
这些新的压缩功能已在支持 S3 表的所有区域推出,并适用于支持与 Glue 数据目录集成的标准 S3 存储桶。使用这些功能无需额外费用。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
原文链接:
https://www.infoq.com/news/2025/07/amazon-s3-iceberg-compaction/




