
1.前言
今天,我们非常高兴的宣布,基于 LangStack 的全新 Deep Research 开源项目——DeerFlow,正式在 ByteDance 的 GitHub 官方组织上开源啦!
Github 项目仓库:https://github.com/bytedance/deer-flow
DeerFlow 官方网站:https://deerflow.tech/
DeerFlow 命名的由来
Deer 是 Deep Exploration and Efficient Research 的缩写。Flow 则体现了基于 LangGraph 的流程设计。
DeerFlow 究竟带来了哪些功能和创新呢?就让我们跟着演示一起来体验一下:
2.演示
视频演示
在该视频中,我们演示了包括深度研究、MCP 集成、报告 AI 增强编辑以及播客生成等功能:
00:07 添加 MCP
00:19 开始深度研究
00:22 Human-in-the-Loop
00:43 开始生成丰富图文报告
00:53 AI 增强报告编辑
01:08 播客生成
Multi-Agent 架构演示
https://deerflow.tech/#multi-agent-architecture
回放演示
DeerFlow 回放模式
DeerFlow 支持时下流行的 Replay 模式,即将与大模型的多轮流式交互过程以快速回放的形式进行还原。
3.项目特色
🆕 全新的 Multi-Agent 架构设计
独家设计的 Research Team 机制,支持多轮对话、多轮决策和多轮任务执行。与 LangChain 原版 Supervisor 相比,显著减少 Tokens 消耗和 API 调用次数,从而提升了执行效率。同时,Re-planning 机制赋予系统更高的灵活性,能够动态迭代任务计划以适应复杂场景。
🦜 基于 LangStack 的开源框架
DeerFlow 采用 Multi-Agent 架构设计,构建于 LangChain 和 LangGraph 的开源框架之上,代码结构清晰、逻辑简洁,极大地降低了学习门槛,非常适合初学者快速深入理解多智能体系统的工作原理,轻松探索多智能体协作的潜力,同时体验 LangStack 的强大功能。
🧩 支持 MCP 无缝集成
与 Cursor、Claude Desktop 一样,DeerFlow 也是一个 MCP Host,这意味着你可以通过 MCP 来拓展 DeerFlow 的 Researcher Agent 能力,从而实现类似私域搜索、域内知识库访问、Computer / Phone / Browser Use 等功能。
🤖 AI 生成的 Prompt
DeerFlow 采用了 Meta Prompt 的模式,所有 Prompts 都由 OpenAI 的官方 Meta Prompt 生成,即让大模型来生成自己的 Prompt,从而确保了 Prompt 的高质量,同时也极大的降低了 Prompt 工程的门槛。
🙍🏻♂️ Human-in-the-loop
不满意 AI 生成的计划或报告?DeerFlow 支持用户通过自然语言对生成的内容进行实时修改和优化。无论是调整细节、补充信息,还是重新定义方向,用户都可以轻松地与 AI 协作,确保最终结果完全符合预期。
🎧 支持生成播客及 PPT
DeerFlow 支持从报告生成双人主持的播客,借助火山引擎的语音技术,以及丰富的音色,可以生成非常自然的播客音频内容。同时,DeerFlow 支持从报告生成 PPT,并且支持生成文字版的 PPT。
4.核心揭秘
4.1 LangStack 开源框架
DeerFlow 基于包括 LangChain、LangGraph 在内的 LangStack 技术栈构建 Multi-Agent。
LangGraph提供了非常易用的 SDK 使得我们可以快速搭建 ReAct 设计模式的子 Agent,还提供了 Multi-Agent Supervisor 设计模式的默认实现。而得益于 LangChain 其活跃且丰富的社区贡献,本项目得以快速的与包括 Tavily Search、DuckDuckGo、Brave Search、Python REPL 等工具进行集成,同时我们还在项目中将 Jina Reader 服务包装为 LangChain 工具。
这里我们以创建一个具备“联网搜索” 功能的多步 ReAct Agent为例,通过下面的代码即可实现:
from langchain_community.tools.tavily_search.tool import TavilySearchResultsfrom langgraph.prebuilt import create_react_agent# 创建一个 Tavily Search 工具# Tavily 是知名的搜索引擎 API 提供商web_search = TavilySearchResults( name="web_search" # 将该工具重新命名为“web_search”)# 创建一个 ReAct 风格的联网搜索 agentresearcher_agent = create_react_agent( name="DeepLink", # 取一个好听的名字 model=model, # 指定模型,LangChain 支持市面上几乎所有的大语言模型 tools=[web_search], # 为 Agent 分配一个或多个的工具 prompt=my_prompt # Prompt 请参考下一章节)4.2 Meta Prompt
笔者知道很多读者都很关心 Prompt 提示词工程,在前文中提到,这一次我们采用的仍然是 Meta Prompt 的方式,即让大语言模型自动生成 Prompt。
以上一节中“联网搜索” 为例,首先我们可以用中文编写一段提示:
“你是一个具有联网搜索功能的 ReAct Agent,你可以利用 web_search 工具,通过一次或多次的在互联网上搜索必要的相关内容,来回答和解决我的问题。”
接下来,让我们一起看一下 Meta prompt 生成的提示词:
You are a ReAct Agent equipped with web search capabilities. You can utilize the `web_search` tool to perform one or multiple searches on the internet to gather necessary information and answer my questions or solve my problems effectively. # Steps1. **Understand the Query**: Carefully analyze the user's question or problem to identify the key information needed.2. **Plan the Search**: Break down the query into specific search terms or sub-questions that will help retrieve relevant information.3. **Perform Web Searches**: Use the `web_search` tool to gather information. Conduct multiple searches if necessary to refine or expand the results.4. **Analyze Results**: Evaluate the information retrieved from the searches for accuracy, relevance, and completeness.5. **Reasoning**: Combine the information gathered with logical reasoning to form a coherent and accurate response.6. **Provide the Answer**: Deliver the final answer or solution, ensuring it is clear, concise, and directly addresses the user's query.# Notes- Ensure the information retrieved is from credible and authoritative sources.- If the query is ambiguous, ask clarifying questions before proceeding with the search.- Avoid including outdated or irrelevant information in the response.怎么样?是不是很专业的三段论?生成的 Prompt 中包含了 Job Instruction、Steps 和 Notes,当然还可以包含可选的 Examples。你可以在生成的 Prompt 基础上,再进行手工的调整。当然,你还可以继续和 Meta Prompt Agent 进行一轮或多轮的对话,让它根据你的修订要求进一步迭代新的 Prompt。
借助 LangStack 技术栈和 Meta Prompt 提示工程技术,任何程序员都可以轻松搭建一个专业的“联网搜索” Agent!
4.3 Multi-Agent 架构
4.3.1 常见的 Multi-Agent 架构
在 LangChain 和 LangGraph 中,常见 Multi-Agent 架构包括:
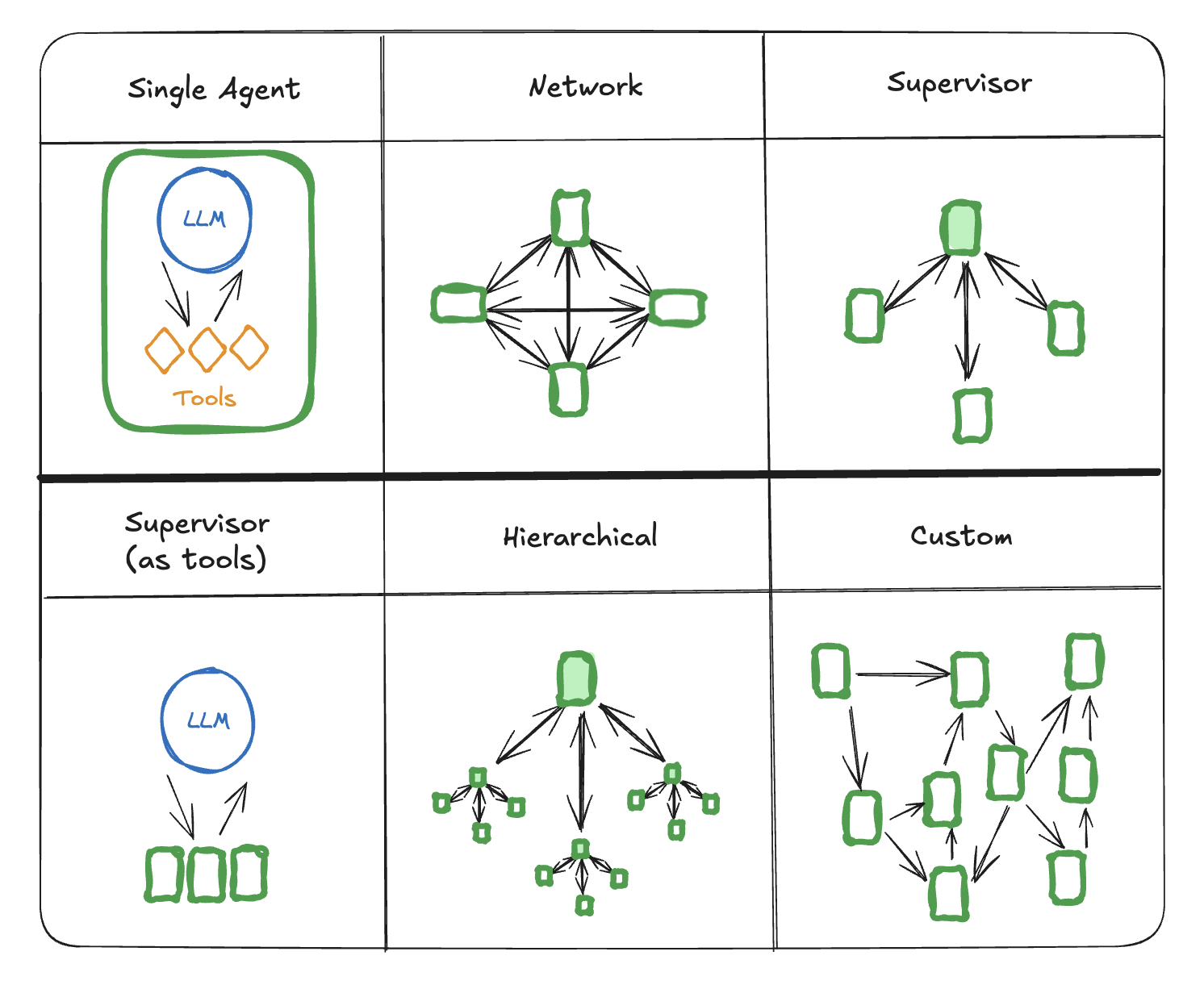
Single Agent
顾名思义,整个系统中只有一个 Agent 负责处理所有的工作。
Network
每个 Agent 都可以与其他所有 Agent 通信。任何 Agent 都可以决定接下来要调用哪个其他 Agent。
Supervisor
每个 Agent 只与一个 Supervisor Agent 通信。Supervisor Agent 决定接下来应该调用哪个 Agent。
Supervisor(作为工具调用)
这是 Supervisor 架构的一种特殊情况。单个 Agent 可以被表示为一个工具。在这种情况下,Supervisor Agent 使用一个 tool-call 调用 LLM 来决定调用哪个 Agent 工具。
Hierarchical
可以定义一个具有多个 Supervisor 的多 Agent 系统。这是 Supervisor 架构的一个泛化,允许更复杂的控制流程。
Custom
每个 Agent 只与部分 Agent 通信。流程的部分是确定性的,只有某些 Agent 可以决定接下来要调用哪个其他 Agent。
其中 Supervisor 是最常见的 Multi-Agent 架构。
4.3.2 LangGraph 中的 StateGraph
在 Multi-Agent 架构中,通常会用 Graph 来表示系统网络拓扑结构,这也是为什么我们选择 LangGraph 框架的原因。在 Graph 中,Agent 表示为 Graph 上的一个节点。每个 Agent 节点执行其步骤,并决定是结束执行还是将控制权交给另一个代理,包括可能将控制权交回自身(自循环)。
StateGraph 是一种用于表示状态和状态之间转换关系的 Graph 结构。它可以帮助开发者以直观的方式设计和管理复杂的状态机(State Machine)。在 StateGraph 中,节点(Node)表示 Agent,边(Edge)表示 Agent 之间的转换逻辑,在整个 Graph 中自上而下都在传递着同一份状态(State,有的地方也成为 Context),State 是一个字典对象,所有节点都可以读取或更改该状态的值。通过定义 Node 和 Edge,开发者可以构建一个清晰的状态流,从而更好的管理系统的行为。在 LangGraph 中,你可以用多种方式创建节点和用于连接节点的边,其中最简单的方法是为每一个节点创建一个函数,然后通过手工添加的方式构建一个状态图。
StateGraph 在多种场景中都非常有用,例如多步骤的业务流程、游戏中的状态管理、机器人控制中的状态切换,以及 Multi-Agent 系统中的 Agent 行为建模。
以 LangGraph 框架的官方示例为例,为了创建一个类似下方这样的 StateGraph:
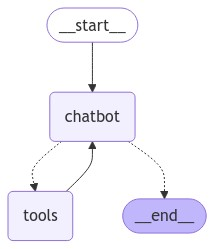
from langchain.chat_models import init_chat_modelfrom langchain_tavily import TavilySearchfrom langchain_core.messages import BaseMessagefrom langgraph.checkpoint.memory import MemorySaverfrom langgraph.graph import MessagesState, StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langgraph.prebuilt import ToolNode, tools_condition# 创建一个 State Graph 空对象# MessagesState 表示一个包含了 `messages` 数组的 TypedDictgraph = StateGraph(MessagesState)# 创建一个与 Tavily Search 工具绑定的大语言模型对象tool = TavilySearch(max_results=2)tools = [tool]llm = get_chat_model() # 需要实现 get_chat_model() 方法llm_with_tools = llm.bind_tools(tools)# 定义 Chatbot 节点def chatbot(state: State): return {"messages": [llm_with_tools.invoke(state["messages"])]}# 向 State Graph 添加 Chatbot 节点和工具节点graph.add_node("chatbot", chatbot)tool_node = ToolNode(tools=[tool])graph.add_node("tools", tool_node)# 将节点用边(Edge)连接起来graph.add_conditional_edges( "chatbot", tools_condition,)graph.add_edge("tools", "chatbot")graph.add_edge(START, "chatbot")4.3.3 Handoffs 模式
在 Multi-Agent Supervisor 交互中,一个常见的模式是 Handoffs,即一个 Agent 将控制权交给另一个 Agent。
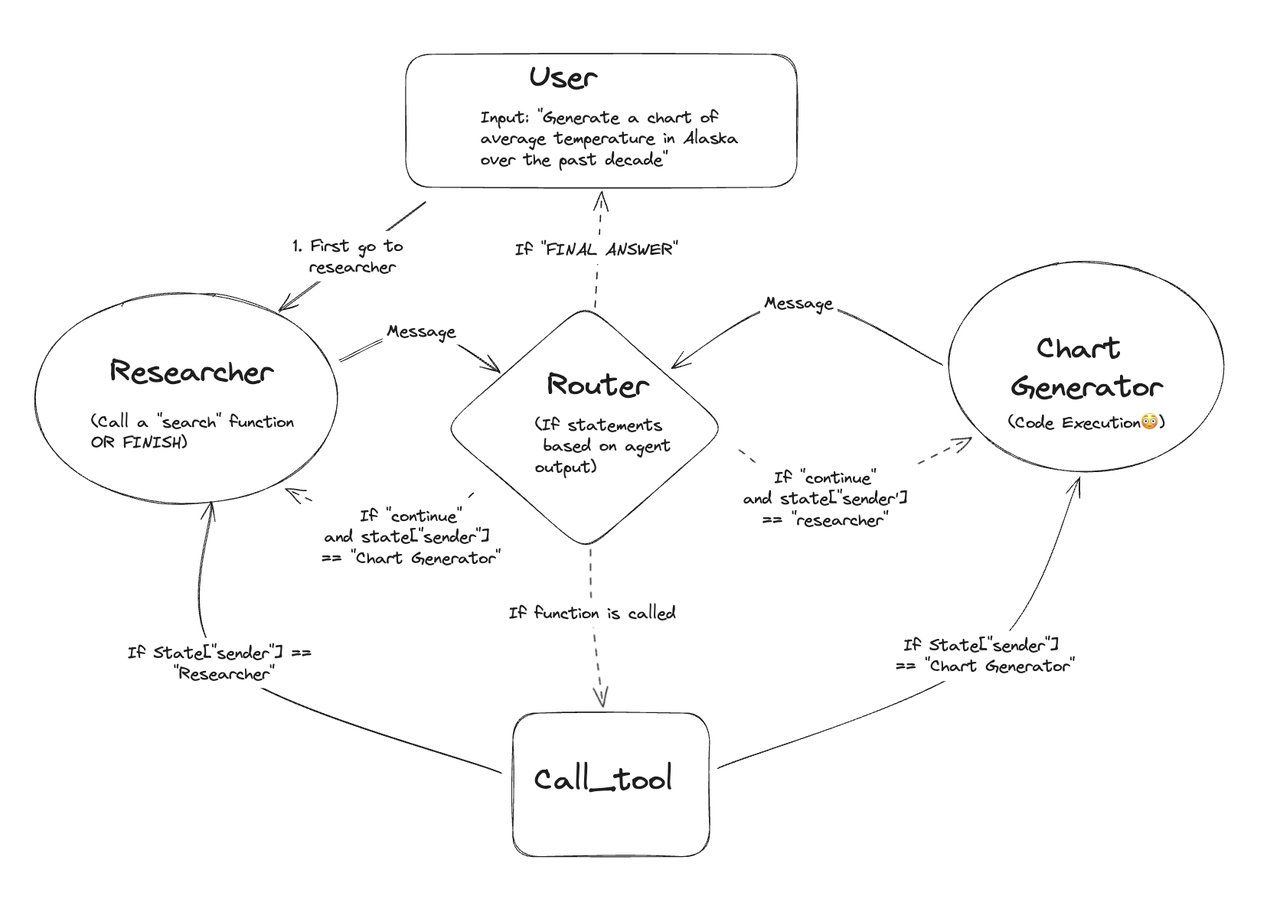
例如,在上图中,位于中央的
Router会根据当前状态,将控制权根据规则跳转到:Researcher:如果发送者是Chat GeneratorChat Generator:如果发送者是Researcher
在 LangGraph 中,如果想实现上面 Handoffs 的效果,只需要 Agent 函数返回一个 Command 对象即可。例如,下面的这段代码中,通过 Python 的 Type Hint 描述了 Router 允许将控制权交给下游的 Researcher 或 Chat Generator,而通过实现 get_next_agent() 方法的逻辑,则可以动态的根据 state 参数决定要跳转到哪一个下游节点。
def router(state) -> Command[Literal["researcher", "chat_generator"]]: goto = get_next_agent(...) # 'researcher' / 'chat_generator' return Command( # 决定跳转到哪一个节点 goto=goto, # 更新状态 update={"my_state_key": "my_state_value"} )关于 Handoffs 模式
随着 OpenAI 的 Agent SDK 与 LangGraph 的 langgraph-supervisor-py 的推出,Handoffs 风格逐渐成为主流。在 LangGraph 中,Handoffs 是通过在你的 Agent 中自动内置了 transfer_to_xxx() 这样的工具来实现的,当大模型调用这类方法时,就表示需要主动跳转到哪一个下游节点。
4.3.4 研究团队中的 Agents
在了解了常见的 Multi-Agent 架构,以及如何基于 LangGraph 来新建一个 Handoffs 模式的 Supvervisor 后,接下来,让我们先来认识一下 DeerFlow 深度研究团队中的 Agent 们:
那么这些 Agent 是如何在一起协作从而完成 Deep Research 任务的呢?
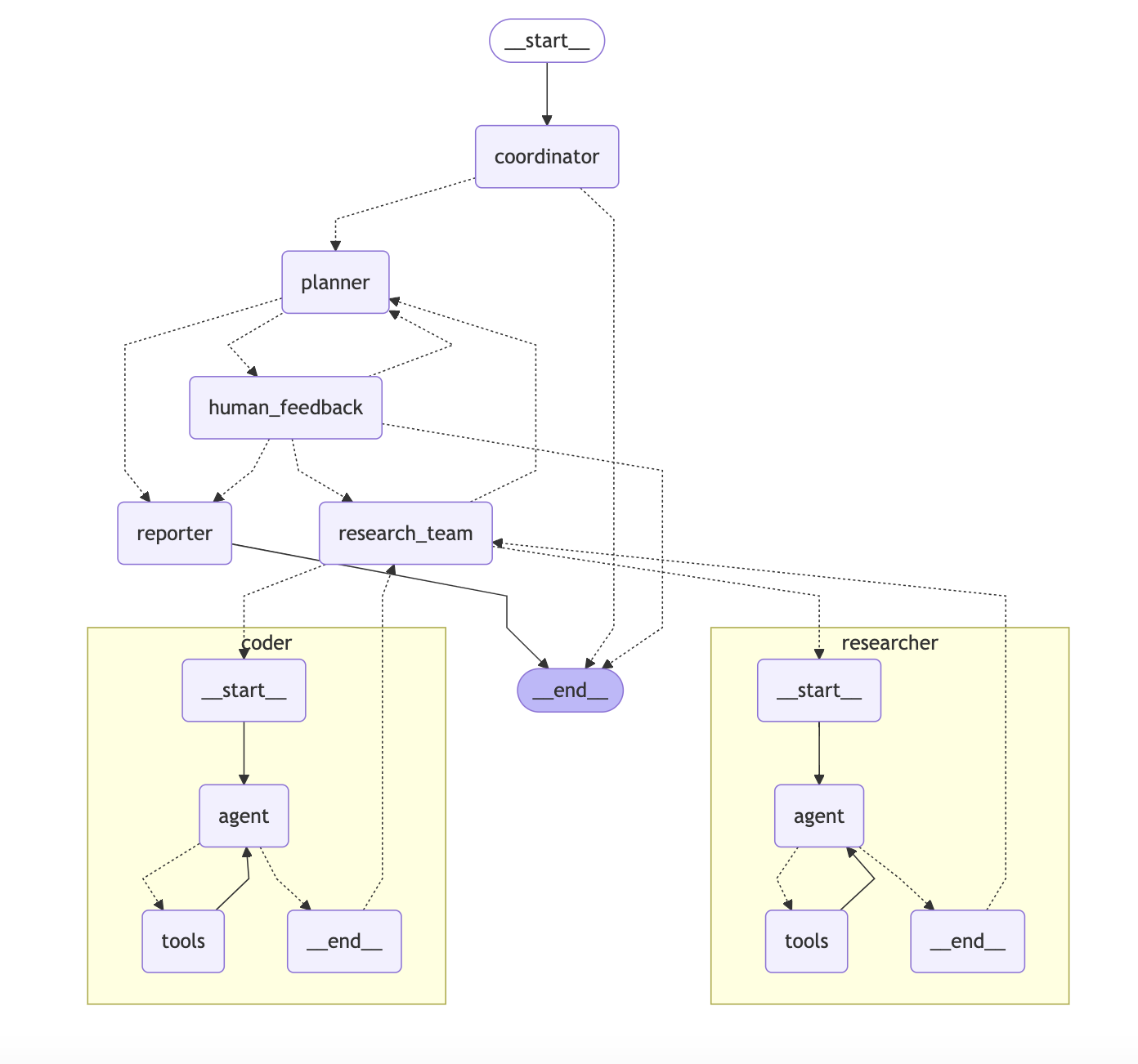
上边是 DeerFlow 的 Multi-Agent 架构图,而下方的这段录屏是在 LangGraph Studio 中调试流程。你可以通过在项目根目录下执行 make langgraph-dev 来运行 LangGraph Studio,帮你了解每一步细节。
上面的流程图如果觉得过于复杂,也可以参考下面的简版流程图:
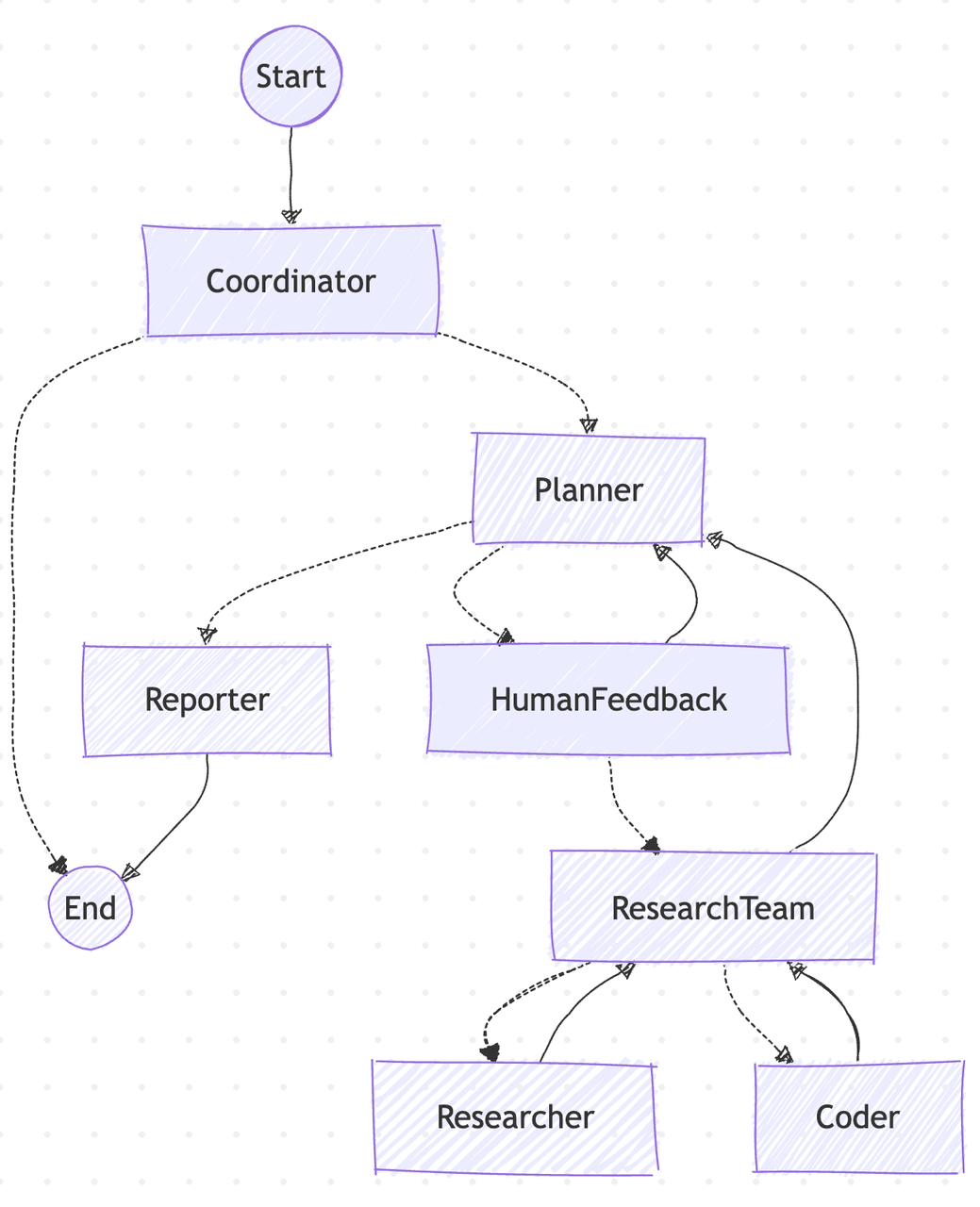
用户的原始问题首先会到达
Coordinator,由它判定是否为敏感内容,如果是,则会礼貌回应并结束;否则,handoff 给Planner。Planner负责生成研究计划,并通过 Interrupt 机制(HumanFeedback)允许用户使用自然语言修改计划。用户确认计划后,Planner会 handoff 给Research Team并开始研究。Research Team会根据研究计划,机械化的依次调取Researcher或Coder进行资料收集或代码执行,它们都是 ReAct 风格的子 Agent。当
Research Team完成工作后,将会 handoff 回Planner。若Planner认为研究已完成,会 handoff 给Reporter;否则会继续规划(Re-plan)并 handoff 回Research Team进行下一轮研究迭代,直到最终完成。Reporter负责将所有上下文进行总结陈词,并生成最终的研究报告,从而结束整个流程。
点击这里查看在线动画演示
4.4 核心工具
多亏有了 LangChain 丰富的社区工具集,DeerFlow 内置了以下工具供大模型调用:
4.5 MCP 集成
MCP 是一种开放协议,标准化了应用程序向大型语言模型(LLM)提供上下文的方式。可以将 MCP 类比为 AI 应用的 USB-C 接口。正如 USB-C 为设备连接各种外设和配件提供了标准化方式,MCP 为 AI 模型连接不同数据源和工具提供了标准化方法。
在 LLM 和 Agent 圈里,MCP 无疑是时下最火的技术之一。通过 LangChain 的 MCP 适配器,我们可以轻松地将 MCP 集成到我们的项目中:
示例
假设我们有一个名为
math_server和weatherMCP 服务,分别通过本地的stdio和远程的sse方式对外进行暴露。下面这段代码可以快速的从上述两个服务中获取所有工具。而它们和上一节中的内置工具一样,可以直接被 ReAct 风格的 Agent 调用,唯一需要注意的是它们采用的是async调用。
async with MultiServerMCPClient( { "math": { "command": "python", # Make sure to update to the full absolute path to your math_server.py file "args": ["/path/to/math_server.py"], "transport": "stdio", }, "weather": { # make sure you start your weather server on port 8000 "url": "http://localhost:8000/sse", "transport": "sse", } }) as client: all_tools = client.get_tools() ...你可能已经注意到了,在 MultiServerMCPClient 的构造函数中传入的 dict 对象参数,与我们平时在 Claude Desktop 或 Cursor 中的 JSON 配置一模一样。
需要注意的是,尽管 MCP 话题持续热度不减,然而优质的 MCP 服务并不多见,我们不能简单的将 MCP 认为是对传统 RPC 或 HTTP API 服务的二次封装。一个好的 MCP 服务接口设计,应该满足:
使用清晰的标题:提供易于理解的标题,明确描述工具及参数的用途。
确保对副作用的描述准确:明确指出工具是否会修改其环境,以及这些修改是否具有破坏性。
正确标注幂等性:仅当工具在使用相同参数重复调用时确实不会产生额外影响时,才将其标记为幂等。
设置适当的开放/封闭系统提示:明确工具是与封闭系统(如数据库)交互,还是与开放系统(如网络)交互。
4.6 语音合成与播客生成
根据报告生成播客
我们提供了一个特色功能——根据报告生成播客(Podcast)。该功能深受用户的欢迎和喜爱,毕竟大家都觉得利用片段时间,带着耳机去了解一个知识点是一个非常棒的学习方式。
在 DeerFlow 中,我们也提供了 Podcast 功能,下面这个 3 分钟的播客就是由 AI 生成男女主持人的脚本,并且通过火山引擎的语音技术将文本转换为多个语音片段,再通过程序进行合成最后形成了下面的播客:
是的,你一定猜到了,用来根据报告生成男女主持人播客脚本的 Prompt 也是由 Meta Prompt 生成的:
You are a professional podcast editor for a show called "Hello Deer." Transform raw content into a conversational podcast script suitable for two hosts to read aloud.# Guidelines- **Tone**: The script should sound natural and conversational, like two people chatting. Include casual expressions, filler words, and interactive dialogue, but avoid regional dialects like "啥."- **Hosts**: There are only two hosts, one male and one female. Ensure the dialogue alternates between them frequently, with no other characters or voices included.- **Length**: Keep the script concise, aiming for a runtime of 10 minutes.- **Structure**: Start with the male host speaking first. Avoid overly long sentences and ensure the hosts interact often.- **Output**: Provide only the hosts' dialogue. Do not include introductions, dates, or any other meta information.- **Language**: Use natural, easy-to-understand language. Avoid mathematical formulas, complex technical notation, or any content that would be difficult to read aloud. Always explain technical concepts in simple, conversational terms.# Output FormatThe output should be formatted as a valid, parseable JSON object of `Script` without "```json":```tsinterface ScriptLine { speaker: 'male' | 'female'; text: string; // only plain text, never Markdown}interface Script { locale: "en" | "zh"; lines: ScriptLine[];}```# Examples<example>{ "locale": "en", "lines": [ { "speaker": "male", "text": "Hey everyone, welcome to the podcast Hello Deer!" }, { "speaker": "female", "text": "Hi there! Today, we’re diving into something super interesting." }, { "speaker": "male", "text": "Yeah, we’re talking about [topic]. You know, I’ve been thinking about this a lot lately." }, { "speaker": "female", "text": "Oh, me too! It’s such a fascinating subject. So, let’s start with [specific detail or question]." }, { "speaker": "male", "text": "Sure! Did you know that [fact or insight]? It’s kind of mind-blowing, right?" }, { "speaker": "female", "text": "Totally! And it makes me wonder, what about [related question or thought]?" }, { "speaker": "male", "text": "Great point! Actually, [additional detail or answer]." }, { "speaker": "female", "text": "Wow, that’s so cool. I didn’t know that! Okay, so what about [next topic or transition]?" }, ... ]}</example>> Real examples should be **MUCH MUCH LONGER** and more detailed, with placeholders replaced by actual content.# Notes- It should always start with "Hello Deer" podcast greetings and followed by topic introduction.- Ensure the dialogue flows naturally and feels engaging for listeners.- Alternate between the male and female hosts frequently to maintain interaction.- Avoid overly formal language; keep it casual and conversational.- Always generate scripts in the same locale as the given context.- Never include mathematical formulas (like E=mc², f(x)=y, 10^{7} etc.), chemical equations, complex code snippets, or other notation that's difficult to read aloud.- When explaining technical or scientific concepts, translate them into plain, conversational language that's easy to understand and speak.- If the original content contains formulas or technical notation, rephrase them in natural language. For example, instead of "x² + 2x + 1 = 0", say "x squared plus two x plus one equals zero" or better yet, explain the concept without the equation.- Focus on making the content accessible and engaging for listeners who are consuming the information through audio only.为了更好的解析脚本,将男生和女生的部分进行切割,因此这里选择用 JSON 格式来输出文本脚本。
此外,火山引擎的语音合成和大模型语音合成支持数十种声音音色,有的还支持语音合成标记语言(SSML),可以生成更逼真、更生动的声音!
5.写在最后
我们诚邀你加入 DeerFlow 的社区。无论你是前端、后端、测试、算法,还是产品经理、UX,或是对 AI 充满热情的爱好者,你的每一份贡献都将为 DeerFlow 注入新的活力。在 Github 上,你可以通过 Star 表达对我们的支持,也可以通过 Commits 与我们一同推动这个项目的成长,最后也欢迎大家转发和传播这篇本文。
期待在 Github 上与你相遇,共同见证这段属于我们的 AI 开源传奇!🌟
Github 仓库
https://github.com/bytedance/deer-flow
官网




