
整理 | 华卫
昨日(7 月 30 日),ACL(国际计算语言学年会)公布了 2025 年的获奖论文。令人惊喜的是,这些论文里的中国作者比例超过 51%,排在第二的美国仅为 14%。
其中,一篇由 DeepSeek 梁文锋作为通讯作者、与北京大学等联合发表的论文不仅拿下 Best Paper 奖,相关成果也引发热议。
现场讲座中,该论文的第一作者袁境阳透露,这项技术可以把上下文长度扩展到 100 万 tokens,并将应用在他们的下一个前沿模型中。据了解,袁境阳当时写这篇论文时还只是 Deepseek 的实习生。

引入两大核心技术创新
长上下文建模对于下一代语言模型至关重要,但标准注意力机制的高计算成本带来了显著的计算挑战。随着序列长度的增加,延迟瓶颈问题愈发凸显。理论估算表明,在解码 64k 长度的上下文时,采用 softmax 架构的注意力计算占总延迟的 70%–80%,这凸显了对更高效注意力机制的迫切需求。
为解决这些局限性,有效的稀疏注意力机制在实际应用中必须应对两项关键挑战:与硬件适配的推理加速,要将理论上的计算量减少转化为实际的速度提升,就需要在预填充和解码阶段都采用硬件友好型的算法设计,以缓解内存访问和硬件调度方面的瓶颈;兼顾训练的算法设计,通过可训练算子实现端到端计算,在维持模型性能的同时降低训练成本。
综合考虑这两个方面,现有方法仍存在明显差距。该团队认为,稀疏注意力为在保持模型能力的同时提高效率提供了一个很有前景的方向。
在获奖论文中,他们提出了 NSA,这是一种可原生训练的稀疏注意力(Natively trainable Sparse Attention)机制。它将算法创新与硬件对齐优化相结合,以实现高效的长上下文建模。据介绍,NSA 采用动态分层稀疏策略,结合粗粒度的 token 压缩和细粒度的 token 选择,以同时保留全局上下文感知和局部精度。
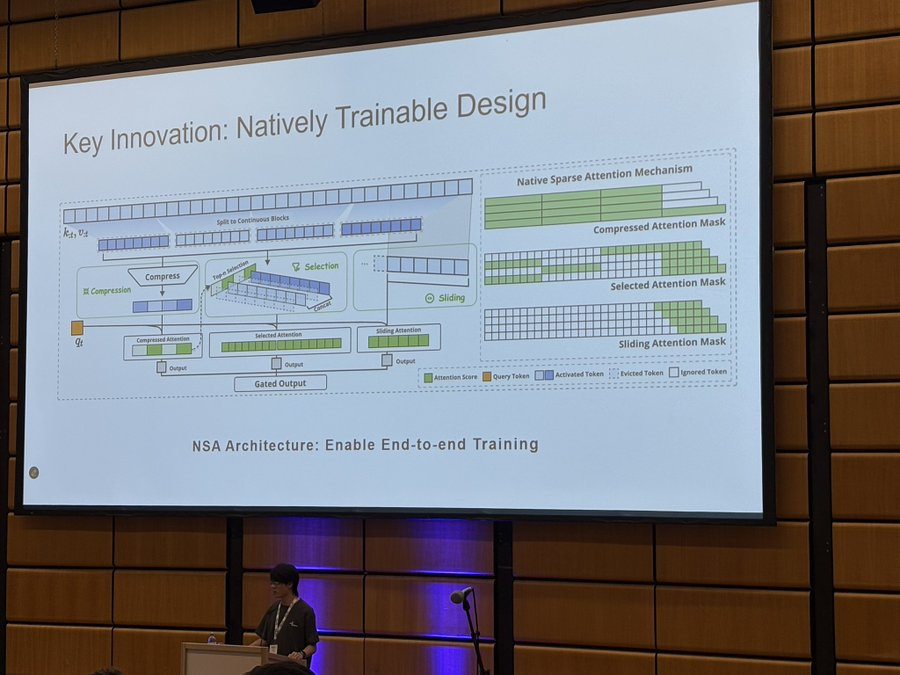
具体来说,NSA 引入了两项核心创新。
通过算术强度平衡的算法设计实现了显著的加速,并针对现代硬件进行了实现优化:优化块式稀疏注意力,以提高张量核利用率和内存访问,确保均衡的算术强度。
通过高效算法和反向算子实现稳定的端到端训练,在不牺牲模型性能的情况下减少了预训练计算量。
上下文处理速度狂飙,准确率堪称“完美”
在真实世界语言语料库上进行综合实验评估后,NSA 由于稀疏性过滤掉更多噪声,在基准测试中产生更好的准确率。据悉,该团队在一个拥有 270 亿参数的 Transformer 骨干网络(其中激活参数为 30 亿)上,使用 2600 亿个 token 进行预训练,并从通用语言评估、长上下文评估和思维链推理评估三个方面评估了 NSA 的性能,还在 A100 GPU 上将其内核速度与经过优化的 Triton 实现作了进一步比较。
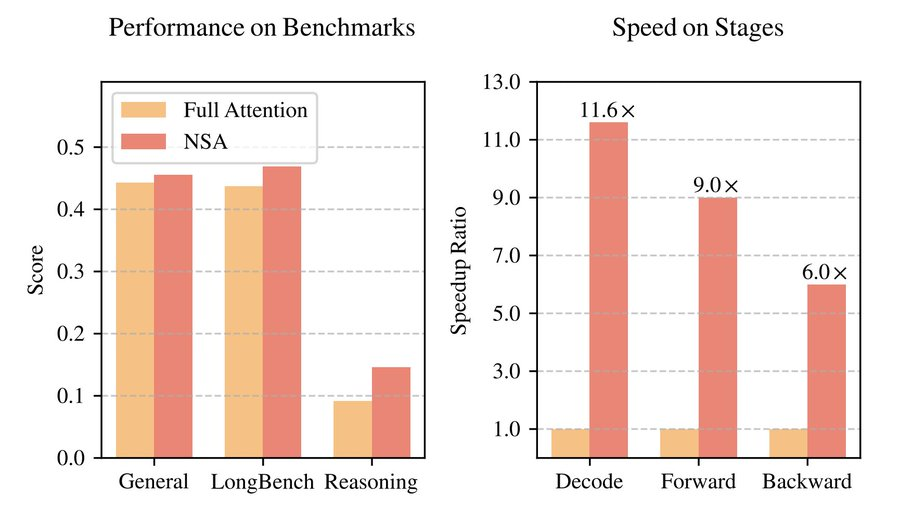
实验结果表明,NSA 的整体性能与全注意力模型相当甚至更优。在 9 项指标中的 7 项上,NSA 均超过了包括全注意力模型在内的所有基线。这表明,尽管 NSA 在较短序列上可能无法充分发挥其效率优势,但它展现出了强劲的性能。
值得注意的是,NSA 在推理相关的基准测试中取得了显著提升(DROP:+0.042,GSM8K:+0.034),这说明该团队的预训练有助于模型发展出专门的注意力机制。这种稀疏注意力预训练机制迫使模型聚焦于最重要的信息,通过过滤无关注意力路径中的噪声,可能会提升性能。在各类评估中表现出的一致性,也验证了 NSA 作为通用架构的稳健性。
在 64k 上下文的“大海捞针”测试中,NSA 在所有位置都实现了完美的检索准确率。此外,与全注意力相比,NSA 在解码、前向传播和反向传播方面都实现了显著的速度提升,且序列越长,提速比例越大。
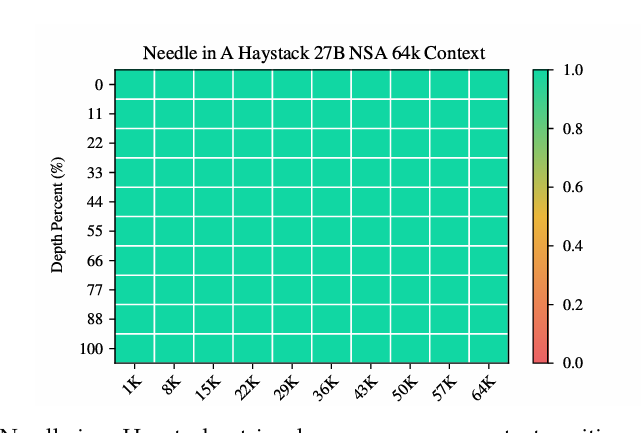
据该团队称,这一性能正是得益于其分层稀疏注意力设计,该设计结合了用于高效全局上下文扫描的 token 压缩和用于精确局部信息检索的 token 选择。粗粒度的 token 压缩以较低的计算成本识别相关的上下文块,而对 token 选择的标记级注意力则确保保留关键的细粒度信息。
同时,NSA 优于多种现有的稀疏注意力方法,包括 H2O、infLLM、Quest 以及 Exact-Top。
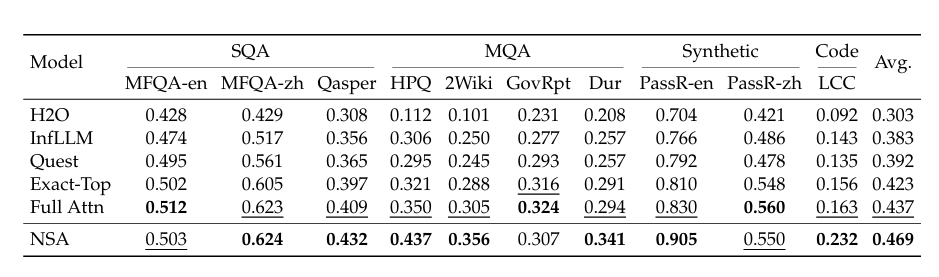
值得注意的是,NSA 在需要对长上下文进行复杂推理的任务上表现出色,在多跳问答任务(HPQ 和 2Wiki)上比全注意力模型分别提升 0.087 和 0.051,在代码理解任务(LCC)上超出基线模型 0.069,在段落检索任务(PassR-en)上优于其他方法 0.075。这些结果也验证了 NSA 处理各种长上下文挑战的能力,其原生预训练的稀疏注意力在学习任务最优模式方面带来了额外优势。
为评估 NSA 与先进下游训练范式的兼容性,该团队研究了其通过后期训练获得思维链数学推理能力的潜力。鉴于强化学习在较小规模模型上的效果有限,其采用来自 DeepSeek-R1 的知识蒸馏,使用 100 亿个 32k 长度的数学推理轨迹进行有监督微调(SFT)。这产生了两个可比较的模型:全注意力 - R(全注意力基线模型)和 NSA-R(稀疏变体)。
接着,他们在具有挑战性的美国数学邀请赛(AIME 24)基准上对这两个模型进行了评估,使用 0.7 的采样温度和 0.95 的核采样值,为每个问题生成 16 个回答并取平均分。并且,为验证推理深度的影响,他们在两种生成上下文序列下进行了实验。结果显示,NSA-R 在 8k 和 16k 序列长度下的表现均优于全注意力 - R。
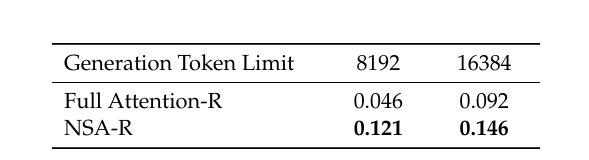
这些结果验证了原生稀疏注意力的两项关键优势:(1)预训练的稀疏注意力模式能够高效捕捉复杂数学推导所必需的长程逻辑依赖关系;(2)我们架构的硬件对齐设计保持了足够的上下文密度,以支持推理深度的增加,同时避免灾难性遗忘。在不同上下文长度下的持续优异表现证实,当稀疏注意力被原生整合到训练流程中时,其在高级推理任务中具有切实可行性。
计算效率方面,该团队将基于 Triton 实现的 NSA 注意力机制和全注意力机制,与基于 Triton 的 FlashAttention-2 在 8-GPU A100 系统进行了比较,以确保在相同后端下进行公平的速度对比。
结果表明,随着上下文长度的增加,NSA 实现了越来越显著的速度提升。在 64k 上下文长度下,前向速度提升高达 9.0 倍,反向速度提升高达 6.0 倍。值得注意的是,序列越长,速度优势就越明显。随着解码长度的增加,NSA 的方法延迟显著降低,在 64k 上下文长度下提速高达 11.6 倍,且这种内存访问效率方面的优势也会随着序列变长而进一步扩大。
值得一提的是,这篇论文早在今年 2 月就对外公布,而相关研究成果至今还没有出现在任何 DeepSeek 模型中。不过,根据论文一作袁境阳的说法,DeepSeek 下一代模型就将应用这项技术,这也让许多网友对 DeepSeek V4 的发布更加期待,毕竟其与 DeepSeek R2 的发布计划似乎也有很大关联。
早在今年 4 月,就有“DeepSeek R2 提前泄露”的传言在 AI 圈刷屏。源头是来自 Hugging Face CEO 发布的一条耐人寻味的帖子,配图是 DeepSeek 在 Hugging Face 的仓库链接,接着引发不少关于 R2 发布时间和技术细节的各类传播。但对此,DeepSeek 官方一直未作出回应。
前不久,有外媒报道称,DeepSeek R2 可能继续推迟。迟迟未发布的内部原因是 DeepSeek 创始人梁文锋对该模型当前的性能不满意,工程师团队仍在优化和打磨。与此同时,也有人这样推测:R2 好歹要等 V4 出来再说,V3 可能已经到达极限了。
参考链接:
https://arxiv.org/abs/2502.11089
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。




