

本文最初发布于 Medium 网站,经原作者授权由 InfoQ 中文站翻译并分享。
我们身处一个数据无处不在的时代。过去几年来,劳动力市场上与数据相关的岗位一直是热门。数据科学家、数据分析师和数据工程师是与数据相关的三大职业类别。如果你有兴趣进入这个领域,或者已经身在其中,那么你应该了解一下数据领域的行业就业现状。当你踏上数据行业的职业生涯,相关岗位工作要求、薪水和满意度等信息可以帮助你做足准备。
在这篇文章中,我会以 StackOverflow 年度开发人员调查为基础来探索一些有趣的问题。文章包含一些数据分析和建模内容,分为三大部分:
第 1 部分:工资
数据行业中哪些岗位的薪水最高?
不同国家之间的工资对比;
工资水平与工作年限的对应关系;
不同性别之间的工资差异;
工资 vs 工作满意度。
第 2 部分:数据行业的就业市场变化,对比 2020 年和 2019 年的数据
数据行业岗位数量的变化;
工资变化;
工作满意度的变化。
第 3 部分:工作满意度
使用 XGBoost 的多类分类来预测工作满意度;
通过建模获得的洞察。
本文所用数据的说明:
在呈现分析结果之前,有必要解释一些重要的数据处理步骤。读者可以先跳过本节,在后文遇到疑问时再回来细读。
这份调查的问题主要针对具有一般开发人员背景的受访者,包括软件开发和数据分析领域。2020 年的调查数据包含 64,461 份回复。我利用了“DevType”问题并对数据进行了预处理,因此只会分析身处数据相关岗位的受访者。问卷中的问题如下。
以下哪一项符合你的情况?请选择所有适用的选项。
学术研究员
数据或业务分析师(DA)
数据科学家或机器学习专家(DS)
数据库管理员
设计师
开发人员,后端
开发人员,桌面或企业应用程序
开发人员,嵌入式应用程序或设备
开发人员,前端
开发人员,全栈
开发人员,游戏或图形开发人员,移动设备
开发人员、QA 或测试人员
DevOps 专家
教育家
工程师,数据(DE)
工程师,现场可靠性工程经理
市场营销或销售专业产品经理
科学家
高级管理(CSuite、VP 等)学生
系统管理员
其他
请注意,受访者可以选择多个 DevType,甚至可以选择多个数据岗位(即 DA、DS、DE)。我只保留了与数据岗位关联的数据条目,并按不同类型的岗位做了分类。因此,两个新创建的实例可能来自具有多个数据岗位的同一个数据实例。
为了让分析结果更加一致可靠,我还过滤了“就业状态”,只保留当前有工作的受访者。经过这些数据准备工作,我们筛选出了 11,186 个数据岗位实例。2019 年调查数据也做了同样的数据准备,创建了 17,370 个实例,它们会与第 2 部分中的 2020 年数据进行比较。
第 1 部分:工资情况
我们先来看看这三种数据职业的分布情况。在这里我们可以看到它们的数字非常接近,DA 排名第一,然后是 DS、DE(图 1a)。就平均工资(美元)而言,我们可以看到 DS 和 DE 几乎相同,而 DA 的工资略低(图 1b)。
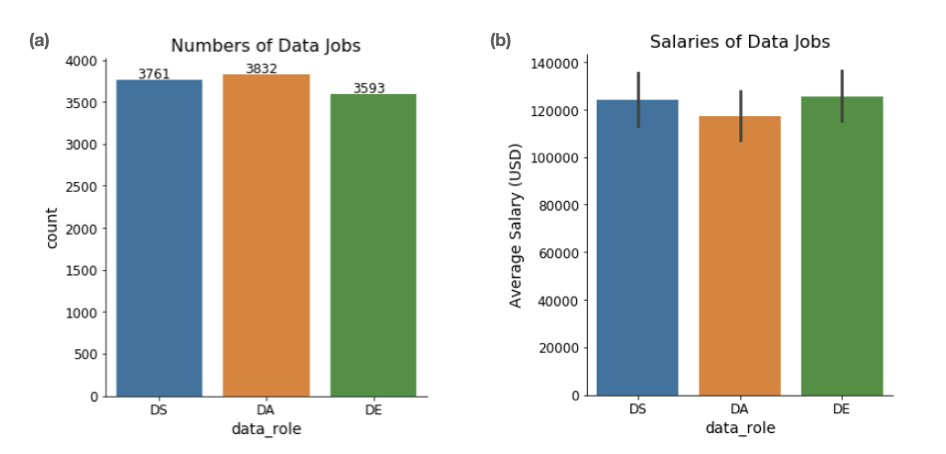
图 1(a):2020 年调查中的数据职业分布。(b):数据职业的薪水。
接着我们来看不同国家(受访者最多的前 9 个国家)的工资水平,我们可以在图 2 中看到一些有趣的细节:
美国的数据行业工作收入最高。美国的平均工资远高于其他国家,甚至高于西方其他发达国家(即德国、英国、加拿大)。
与 DA 相比,DS(和 DE)不一定是收入较高的工作。事实上,我们看到在加拿大和法国,DA 的薪水比 DS 高很多。**这可能会让你想起一句话:数据科学家是 21 世纪最性感的工作。它可能不像你想象的那么性感,至少从收入调查数据来看不那么理想。**然而,StackOverflow 调查数据并不一定准确反映了现实世界的总体情况。
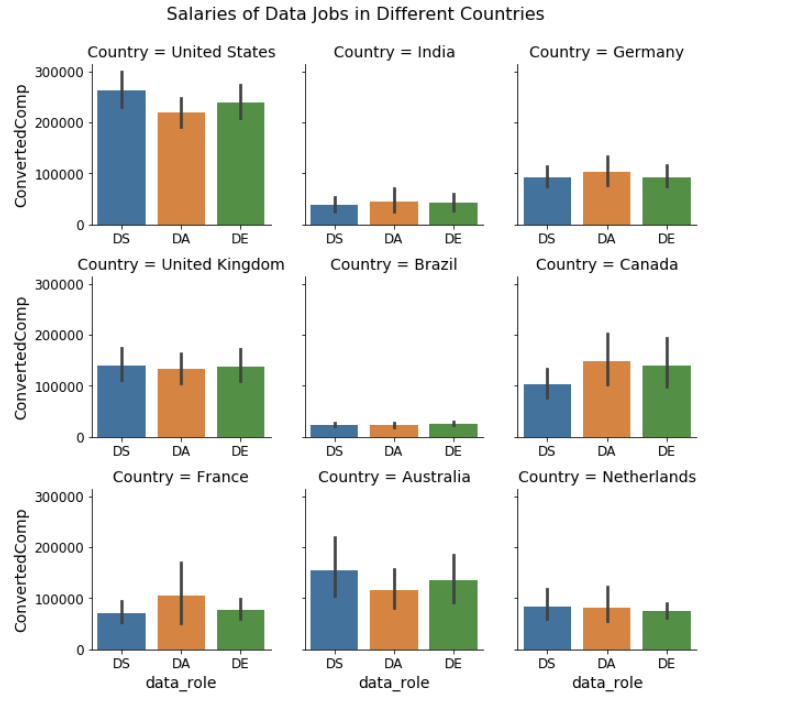
图 2:不同国家数据行业工作的薪水。
与薪水相关的一个重要因素是工作年限。在调查数据中,我们用“专业编程年数”来评价工作经验,将受访者按“专业编程年数”分为四组。在图 3 中,从“0-3 年”到“6-13 年”,我们可以看到工资逐渐缓慢增加,而“13+年”组的工资有大幅上涨。
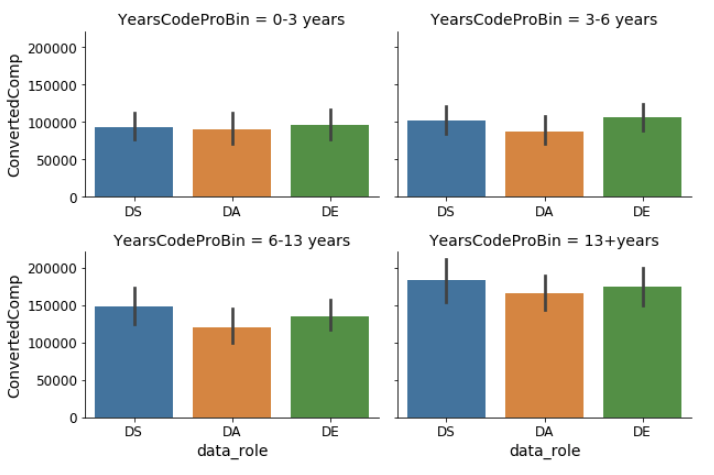
图 3:各个“专业编程年数”组中数据岗位的薪水。这样的分组是为了让各组中的样本数尽量相当。
另一个有趣且重要的观察角度是该领域的性别分布。开发人员的性别差异是一个受长期关注的问题。我们在这个行业中也看到了这个问题(图 4)。
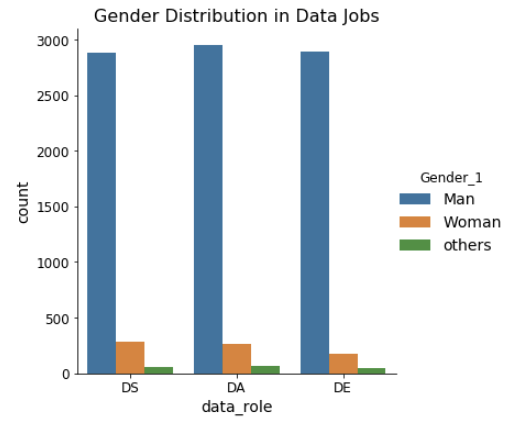
图 4:数据行业工作中的性别分布。为了方便做图,所有非二元性别都被分到了“其他”组中。
在工资方面,我们可以看到男性和女性之间没有实质性差异(图 5a),但女性的工资波动范围更大(高方差,图 5b)。
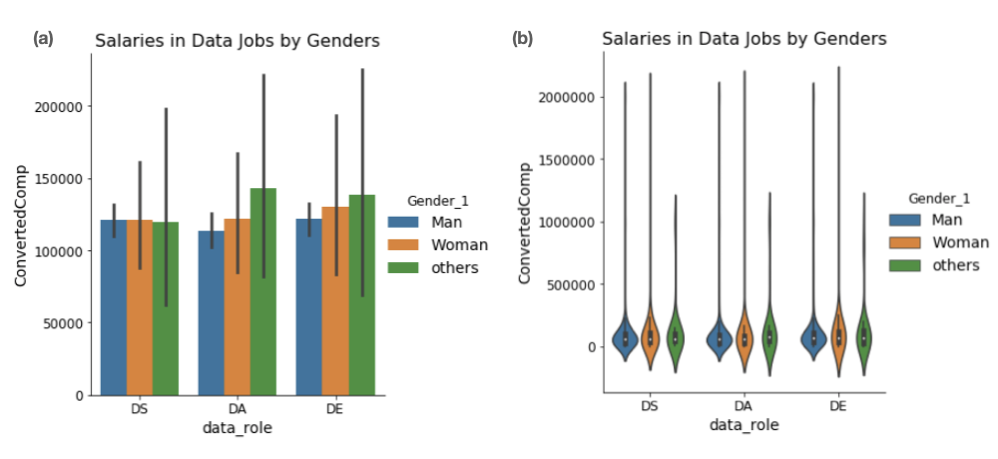
图 5:按性别划分的数据行业工作薪资。(a)条形图。(b)小提琴图。
最后,让我们看看工作满意度与薪水之间的关系。正如你所料,工作满意度并不总是与薪水呈正相关,这也是图 6a 中的数据显示的结果。这也可能表明,有一群数据工程师对自己的工作非常不满意,但他们的薪水却很高(见图 6b 最右侧的绿色高条)。当然,还有许多因素会影响我们在现实世界中的工作满意度。在第 3 部分中,我将应用机器学习建模来预测工作满意度并寻找更多见解。
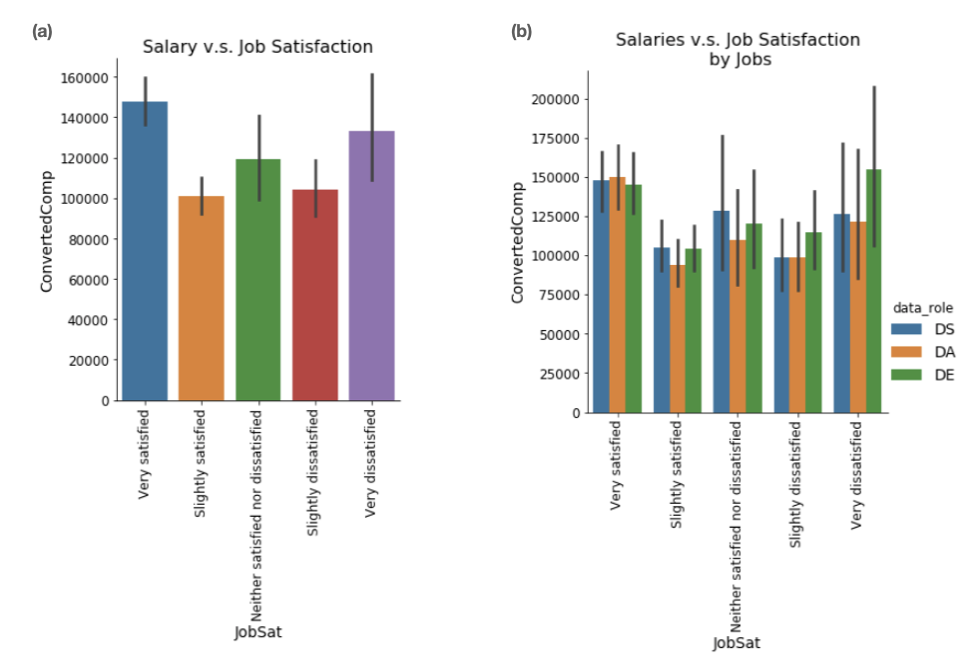
图 6:薪水 vs.工作满意度。
第 2 部分:数据行业工作的变化,对比 2020 年和 2019 年的数据
在这一部分中,我们来看看数据领域的一些趋势。由于我们的分析基于 StackOverflow 的调查数据,而他们 2018 年的调查形式与 2019 年和 2020 年有较大差异,因此我们只使用 2019 年、2020 年的数据来做对比。
我们首先注意到,2020 年从原始数据中筛选出的有效调查回复总数为 53,159,也就是说 15.69%的受访者从事与数据相关的工作。相比之下,2019 年的调查数据有 77,420 份有效调查回复,16.71%的回复者从事数据相关工作。
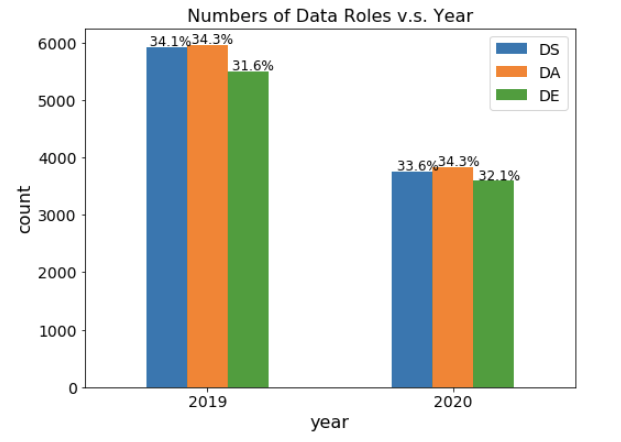
图 7:数据岗位和分布的数量,2019 年对比 2020 年。请注意,由于我们创建数据实例的方式,这里的总数大于调查回复的数量。
首先,数据显示这三个岗位之间的分布几乎没有变化(图 7)。2019 年的统计数字更大,因为 2019 年的调查有更多的回复,这并不一定意味着 2020 年与数据相关的工作数量有所减少。
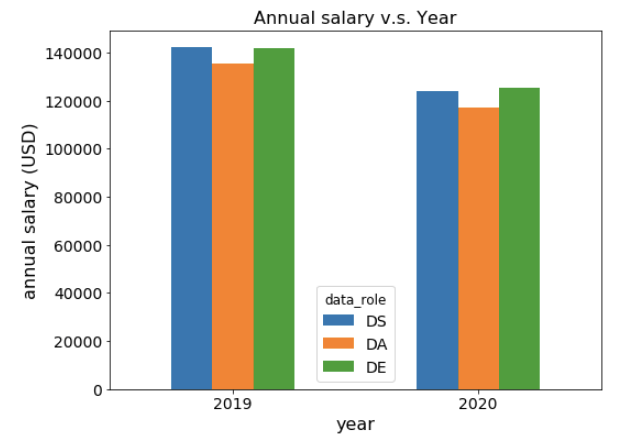
图 8:2019 年和 2020 年之间的工资比较。
谈到薪水的变化,也许这是我遇到的最令人惊讶的结果。我们可以看到所有三个数据岗位的薪水都减少了,总体平均减少了约 16,000 美元(图 8)。
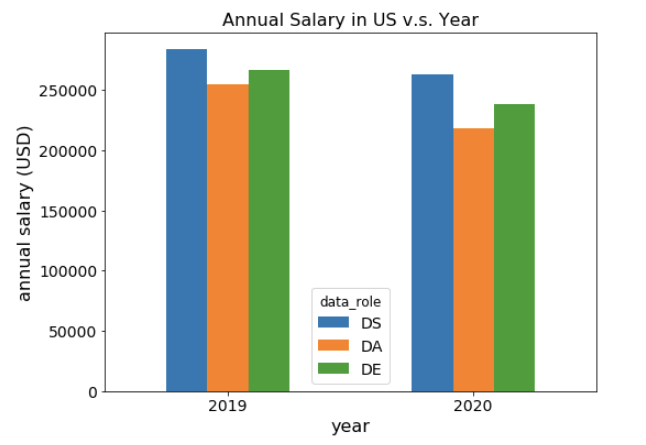
图 9:2019 年和 2020 年的工资对比,仅美国数据。
为了进一步验证这一变化,我只使用美国的数据做了图,并且观察到了类似的工资下降情况(图 9)。这次我们看到 DS 的薪水只是略有下降,而 DA 和 DE 的下降幅度更大。如果能使用其他数据源来交叉验证这种下降趋势是否属实,会很有趣的。如果事实的确如此,那么原因是什么?这又会产生什么影响?附带说明一下,我首先认为工资的这种下降趋势可能是由于 Covid-19 以及市场低迷造成的。但 2020 年的调查数据实际上是在 2020 年 2 月收集的,那时疫情尚未产生影响。
最后,我们来看看工作满意度,这是帮助深入了解就业市场的另一个重要因素。问卷中关于工作满意度的问题如下:
你对目前的工作满意吗?(如果你从事多项工作,请回答你花费最多时间的工作。)
非常不满意 Very dissatisfied(-2)
有点不满意 Slightly dissatisfied(-1)
一般水平 Neither satisfied nor dissatisfied(0)
略满意 Slightly satisfied(1)
非常满意 Very satisfied(2)
我将不同等级的满意度转换为范围从-2 到 2 的值。平均分数如图 10 所示。我们可以观察到,在 2019 年和 2020 年,DS 的满意度得分最高,其次是 DE 和 DA。此外,从 2019 年到 2020 年,所有三个数据岗位的满意度都有所下降,这与工资的变化趋势是一致的。
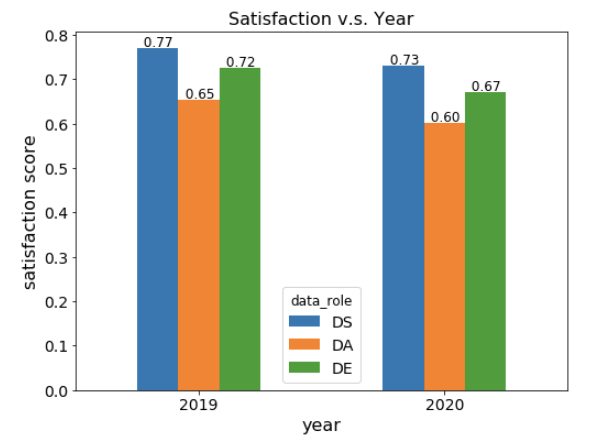
图 10:2019 年和 2020 年工作满意度对比。
第 3 部分:工作满意度预测
在本文的最后一部分,我想构建机器学习模型来预测工作满意度。正如我们之前看到的,工作满意度问题有五个答案选项。因此这里的预测将是一个多分类问题。
为避免不同年份的数据分布不一致,这里仅使用 2020 年调查数据进行建模。另外,请注意数据是不平衡的。“非常满意”和“比较满意”占总数据的 60%以上,“非常不满意”不到 10%。
一些重要的数据处理步骤包括:1)数据清洗;2)缺失数据插补;3)分类数据编码;4)特征选择/工程。这里我会跳过这些技术细节,你可以参考GitHub存储库中的笔记本和代码以了解更多细节。对于建模,我使用 XGBoost 算法和 oneVsRest 方法来解决这个多分类问题。
3.1:探索性数据分析(EDA)
在展示建模结果之前,我将展示一些 EDA 作为数据科学项目的例程,让你快速了解工作满意度。如第 1 部分所示,工资和工作满意度不一定相互关联(图 6)。那么其他可能影响工作满意度的重要因素都有哪些呢?
如图 11 所示,公司规模和工作满意度之间肯定存在某种模式,但我们很难得出一般性结论。合理的猜测是,在小公司中,“非常满意”的比例往往高于“比较满意”。
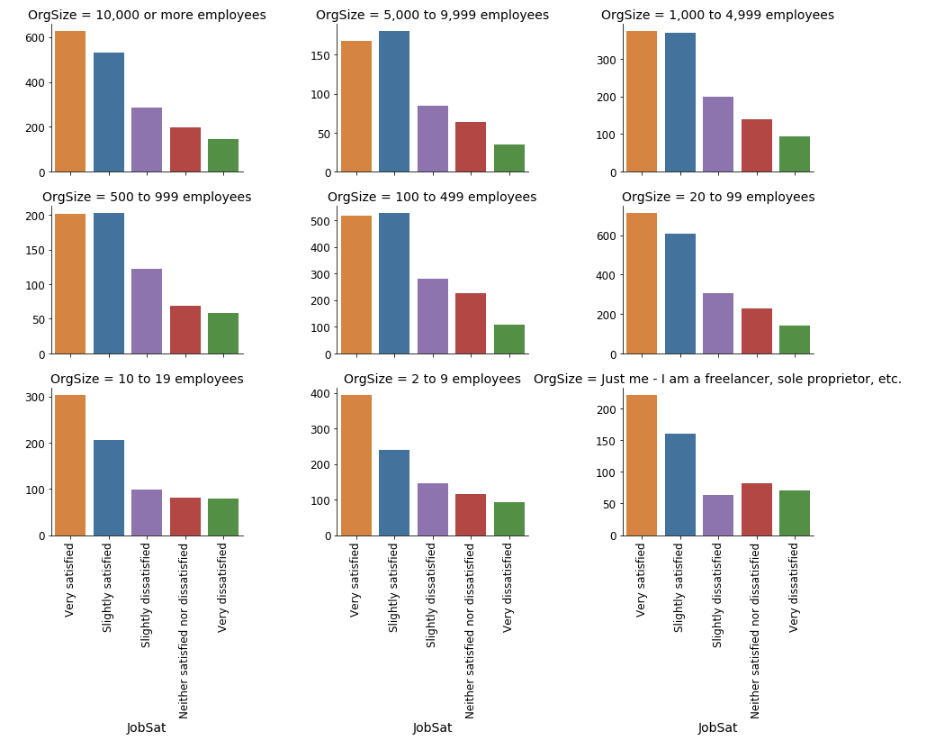
图 11:不同规模公司的工作满意度分布。
加班是另一个与一般意义上的工作满意度相关的因素。然而这种关联就算存在也是模糊的(图 12)。的确,在从不加班的组中,“非常满意”的比例并非最大。
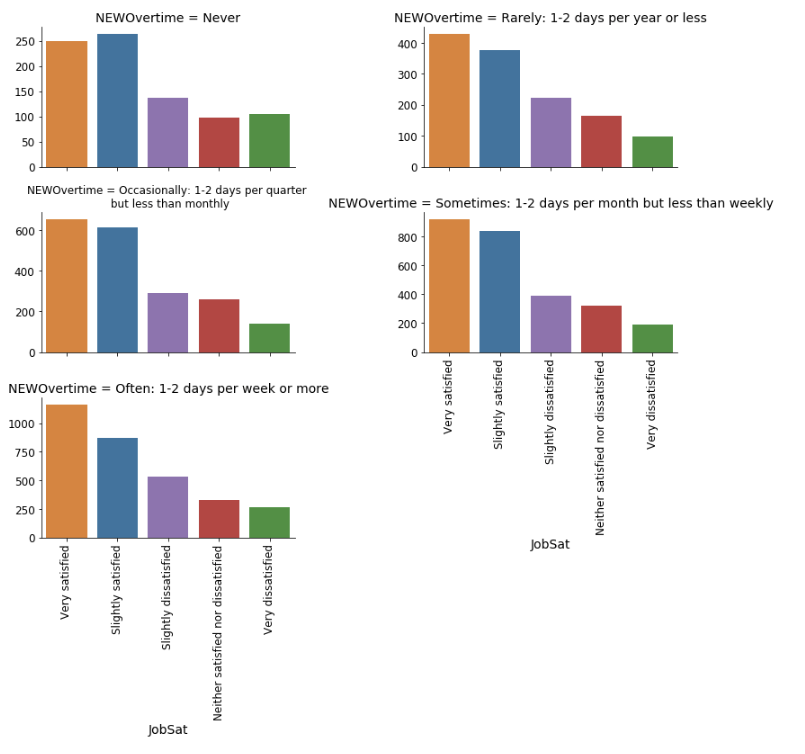
图 12:不同加班时间组之间的工作满意度分布。
最后让我们检查一下不同国家的工作满意度分布。一个观察结果很显眼:在印度和巴西等发展中国家,“非常满意”的比例相对较低。尽管如此,我们不能就此断定这是数据领域独有的特殊现象。相反,无论哪个领域,发展中国家“非常满意”的比例都可能较低。
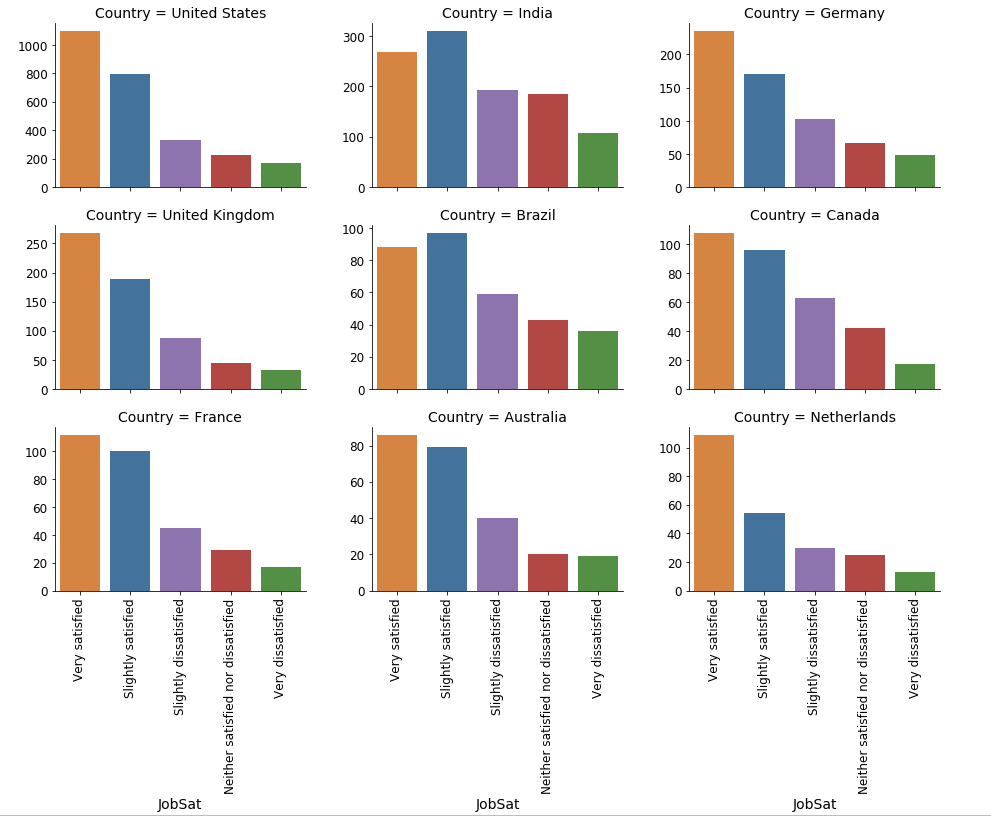
图 13:不同国家的工作满意度分布。请注意,为简单起见,我们没有在建模步骤中使用国家(Country)作为特征。国家是一个高基数特征,应该使用更高级的编码技术,而不是简单的单热编码(one-hot-encoding)。
3.2:使用 XGBoost 处理多分类问题
这里我们来关注模型性能,所以检查混淆矩阵。我们的模型有两个观察结果:
模型存在过拟合问题,尽管在建模步骤中已经应用了多种技术来解决过拟合问题;
该模型可以在合理的水平上正确预测次要类别,尽管将实例预测为“非常满意”和“略满意”会出很多错误。
该模型被“非常满意”和“略满意”混淆(图 14,右)。
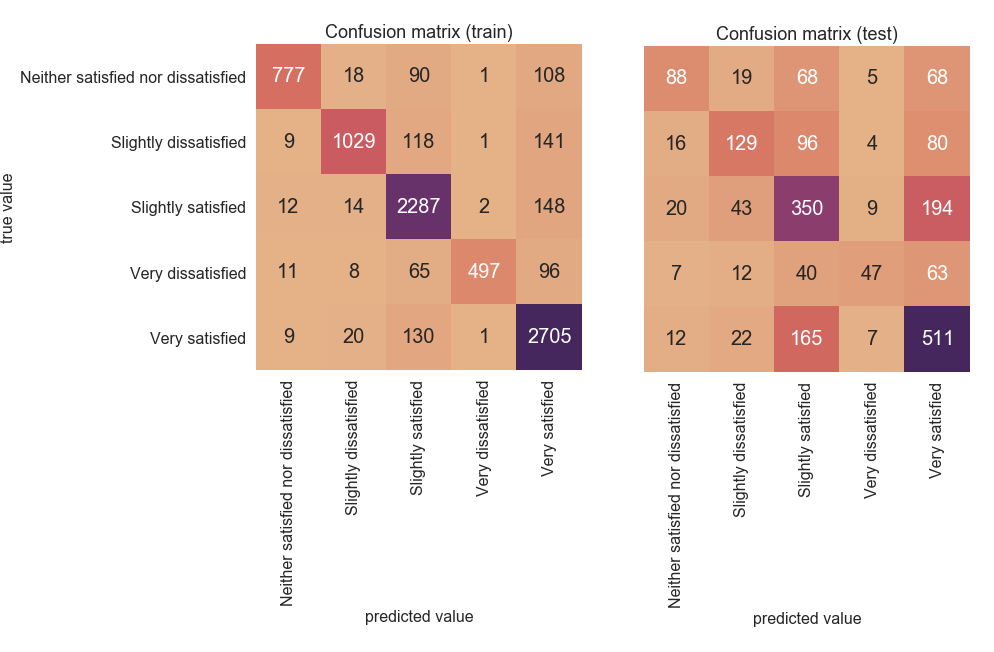
图 14:混淆矩阵的模型性能。左:训练数据的混淆矩阵。右:测试数据的混淆矩阵。
当然,模型还有改进的余地,但与使用朴素贝叶斯的基线模型(这里没展示)相比,模型性能相当不错。此外,数据集本身可能也存在挑战,因此无论如何都难以学习一般模式(即过拟合问题)。
3.3:模型可解释性和见解
为了理解模型并获得更多见解,我们来检查在树构建过程中计算的顶级特征(图 15)。
使用单热编码给解释带来了一些不便,因为原来的特征现在被分解成多个二值特征。两个最重要的特征是关于“NEWOnboardGood”的:“NEWOnboardGood_1”表示对“你认为贵公司的入职流程是否良好”的回答为“是”,“NEWOnboardGood_2”表示“否”。很明显,良好的入职流程通常与高工作满意度相关。
我们还看到“UndergradeMajor”是“NEWOnboardGood”之后的另一个重要特征。事实上,模型从数据中学到的是:
如果受访者是自然科学(如生物、化学、物理等)本科专业,则更有可能表示“非常满意”;
对于拥有另一工程学科(如土木、电气、机械等)本科专业的受访者来说结果类似
“Bash/Shell/PowerShell”特征很有趣,使用“Bash/Shell/PowerShell”作为其编程语言之一的受访者比不使用它们的受访者更有可能“非常满意”。至少这是模型从数据中学到的结果。
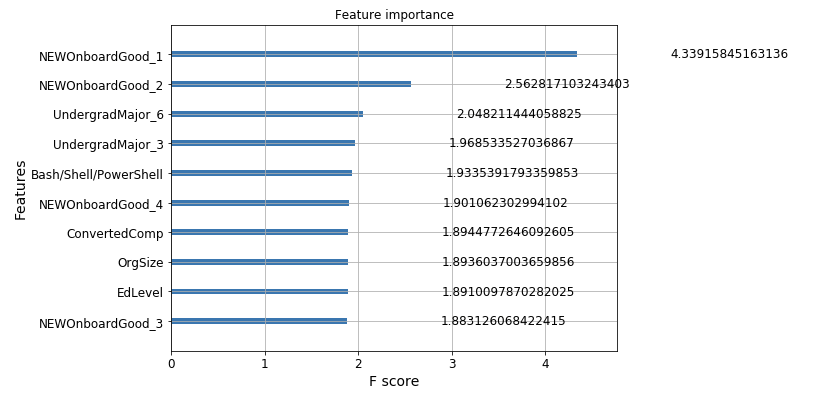
图 16:XGBoost 树构建过程中通过增益计算出的特征重要程度。
我们可以使用SHAP(一种非常通用的模型可解释性工具)来更好地理解模型行为。我们鼓励你在笔记本中探索更多见解。在这里,我将向你展示基于 SHAP 值的顶级特征,并展示两个关于 Salary(薪资)和 Company Size(公司规模)的依赖图示例。
首先,我们将看到 SHAP 值给出的顶级特征(图 17)与节点分裂期间根据信息增益计算的特征不同(图 16)。SHAP 值方法被认为能更一致地评估特征重要性(请参阅 SHAP 论文以供参考)。在这里,排名靠前的特征是“Salary”“NEWOnboardGood_1”“Age”“YeasCode”“OrgSize”,在我看来更符合常识。
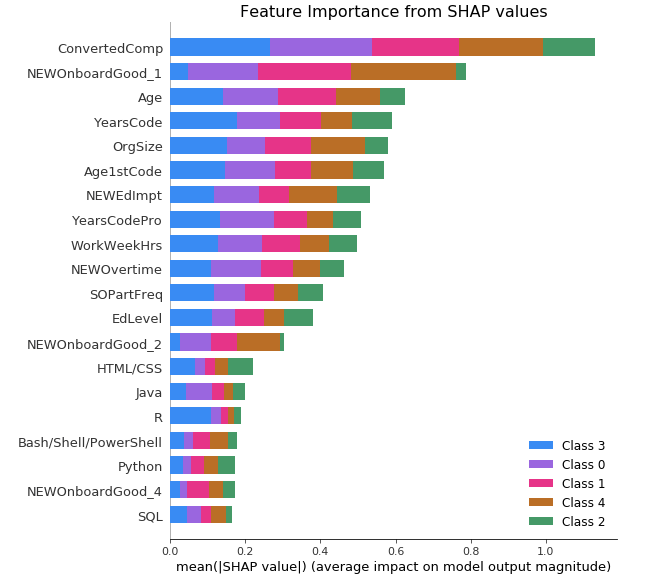
图 17:来自 SHAP 值的主要特征,与图 16 中来自信息增益的特征对比。从 0 级到 4 级:“一般水平”“有点不满意”“略满意”“非常不满意”“非常满意”。
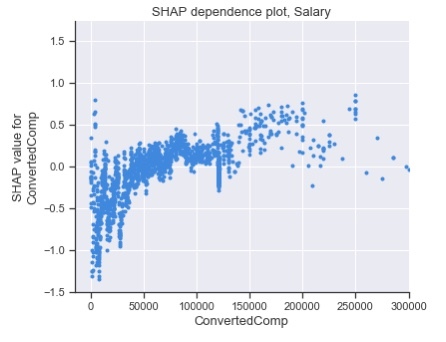
图 18:薪水的 SHAP 依赖图。
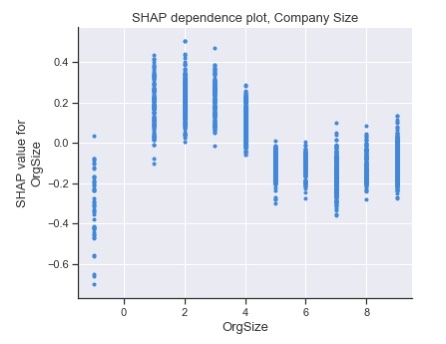
图 19.公司规模的 SHAP 依赖图。OrgSize 的映射是:{1: ‘Just me — I am a freelancer, sole proprietor, etc.’, 2: ‘2 to 9 employees’, 3: ’10 to 19 employees’, 4: ’20 to 99 employees’, 5: ‘100 to 499 employees’, 6: ‘500 to 999 employees’, 7: ‘1,000 to 4,999 employees’, 8: ‘5,000 to 9,999 employees’, 9: ‘10,000 or more employees’, -1: ‘Missing’}
图 18 中的 SHAP 依赖图告诉我们如何使用薪水来预测实例是否“非常满意”。我们可以看到,总体而言,更高的薪水意味着实例更有可能“非常满意”,正如增长趋势所表明的那样。
对于公司规模,较小的规模倾向于对“非常满意”的预测结果做出积极贡献(图 19)。
结论
在这篇文章中,我们使用 StackOverflow 调查数据进行了一些探索性分析,并对数据行业就业市场有了一些了解。
我们分析了不同数据岗位的薪资分布,同时也考虑了其他因素,如国家、工作年限、性别。
我们将 2019 年的调查数据与 2020 年的数据进行了比较。令人惊讶的是,数据相关工作的薪水和工作满意度都下降了。
最后,我们构建了一个 XGBoost 多分类模型,通过检查特征重要性和依赖关系来预测工作满意度,并获得了对工作满意度的一些洞察。
这篇文章中的分析和建模更多是出于实践目的,而没有进一步调查就无法得出可靠的结论。最重要的是,StackOverflow 调查数据本身就可能存在偏差,不一定代表真实世界的群体情况。我希望你读完这篇文章能得到一些乐趣。要查看更多技术细节,请访问GitHub存储库。
原文链接:
https://towardsdatascience.com/salary-satisfaction-trend-of-data-jobs-f47bdf72afa3

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论