

当地时间 1 月 29 日,Meta 发布了 Code Llama 70B,Meta 表示这是“Code Llama 家族中体量最大、性能最好的模型版本”。Code Llama 70B 与先前其他家族模型一样提供三种版本,且均可免费用于研究和商业用途:
CodeLlama – 70B,基础编码模型;
CodeLlama – 70B – Python,专门用于 Python 编码的 70B 模型;
Code Llama – 70B – Instruct 70B,针对自然语言指令理解进行微调的版本。
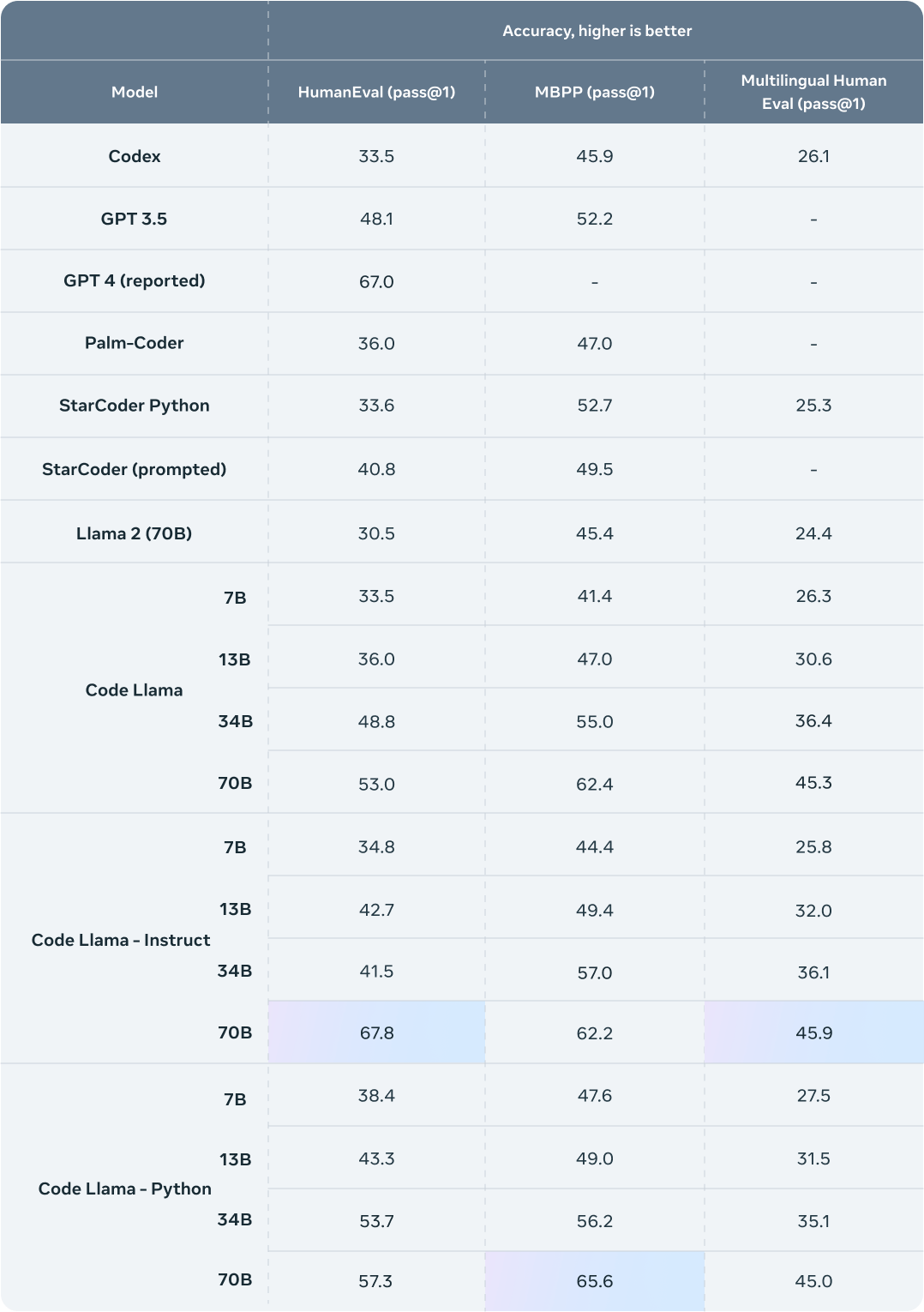
为了对比现有解决方案测试 Code Llama 的性能表现,Meta 选择了两项流行的编码基准:HumanEval 与 Mostly Basic Ptyon Programming(MBPP)。其中 HumanEval 主要测试模型根据文档字符串补全代码的能力,而 MBPP 则测试模型根据描述编写代码的能力。
从基准测试结果来看,Code Llama 的表现优于编码专用的开源 Llama,甚至超越了 Llama 2。例如,Code Llama 34B 在 HumanEval 上的得分为 53.7%,优于 GPT-3.5 的 48.1%,更接近 OpenAI 论文报告的 GPT-4 的 67%。在 MBPP 上,Code Llama 34B 得分为 56.2%,超越了其他最先进的开源解决方案,已经与 ChatGPT 基本持平。
扎克伯格在 Facebook 上说道,“编写和编辑代码已经成为当今人工智能模型最重要的用途之一。编码能力也被证明对人工智能模型更严格、更符合逻辑地处理其他领域的信息非常重要。我对这个进展感到自豪,并期待 Llama 3 和未来的模型中包括这些进展。”
Code Llama 实现原理
Code Llama 是 Llama 2 模型的编码专用版本,是后者在编码数据集之上接受进一步训练的产物,且数据采集周期更长。从本质上讲,Code Llama 拥有比 Llama 2 更强的编码功能。它可以根据代码和自然语言提示词生成代码及与代码相关的自然语言(例如,“为我这一条输出斐波那契序列的函数”),亦可用于代码补全和调试。
Code Llama 支持当今多种高人气编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C# 和 Bash。
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
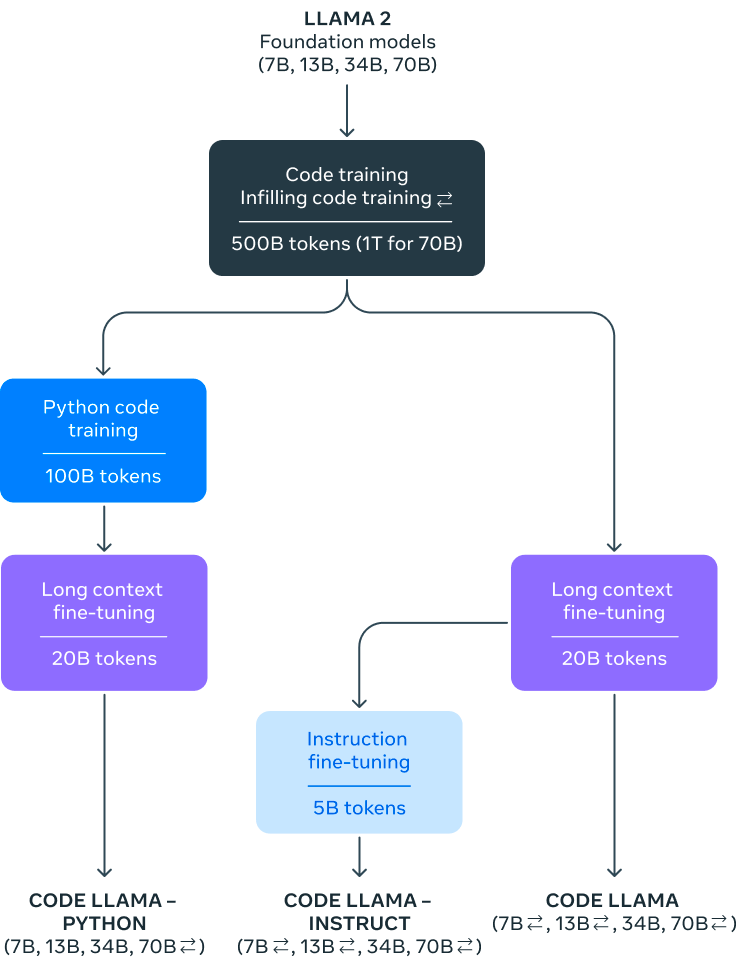
这次,Meta 将发布四种 Code Llama 模型版本,参数分别为 7B、13B、34B 和 70B。各模型版本使用 500B 代码 token 与代码相关数据进行训练,且 70B 模型则采用 1TB token 进行训练。7B 与 13B 基础与指令模型还经过 fill-in-the-middle(FIM)训练,允许向现有代码中插入新代码,因此可以支持开箱即用的代码补全等任务。
三种模型分别能够满足不同的服务与延迟要求。例如,7B 模型可以在单一 GPU 上运行。34B 和 70B 模型则可返回最佳结果并提供更好的编码辅助功能。其中 7B 与 13B 模型运行速度更快,适合实时代码补全等强调低延迟的编码任务。
Code Llama 模型可实现最多 10 万个上下文 token 的稳定生成能力。所有模型均在 1.6 万个 token 的序列上进行训练,并在最多 10 万个 token 的输入场景下表现出性能提升。
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
除了能够生成更长的编码程序之外,更长的输入序列窗口还能为编码大模型解锁其他令人兴奋的新用例。例如,用户可以向模型输入来自代码库的更多上下文信息,确保生成结果的相关性更强。这还有助于在体量更大的代码库中进行调试,帮助开发人员快速找到与特定问题相关的所有代码。现在,开发人员可以将完整代码直接提交至大模型,高效完成涉及大量代码的调试任务。
此外,Meta 还进一步微调了 Code Llama 的两个附加变体:Code Llama – Python 与 Code Llama – Instruct。
Code Llama – Python 是 Code Llama 的特定语言专用变体,使用 100B 个 Python 代码 token 上接受了进一步微调。由于 Python 是代码生成领域的基准测试语言,并且通过 PyTorch 在 AI 社区中发挥着重要作用,所以 Meta 相信这套专用模型将提供更有针对性的实际功能。
Code Llama – Instruct 则是 Code Llama 的指令微调与对齐变体。指令微调同样属于继续训练过程,能够满足其他特定目标。该模型接受“自然语言指令”输入与预期输出组合的持续训练,因此能够更好地理解人们对于提示词的生成期望。由于 Code Llama – Instruct 专门就生成实用、安全的自然语言回答进行了微调,因此在使用 Code Llama 进行代码生成时,Meta 建议开发者优先选择 Code Llama – Instruct。
Meta 并不建议开发者使用 Code Llama 或者 Code Llama – Python 执行常规自然语言任务,因为这两套模型并不是为遵循自然语言指令所设计。Code Llama 专门用于特定编码任务,不适合作为其他通用任务的基础模型。
另外,在使用 Code Llama 模型时,用户须遵守 Meta 指定的许可证与可接受使用政策。
更大参数会带来更高的硬件要求?
没有意外,Code Llama 70B 赢得了开发者们的赞扬,甚至有人称“Code Llama 70B 是代码生成领域的游戏规则改变者。”
但有自称使用过的开发者表示,“我使用 Ollama 尝试了 70B 模型,即使经过多次尝试,它也无法编写贪吃蛇游戏。而 ChatGPT 一次尝试就给出了一款可以运行的游戏。”
另一方面,随着模型参数的增加,开发者们也担心自己手头没有足够装备来满足运行 Code Llama 70B。有人指出,在 A100-80GB 上训练所有 12 个 Code Llama 模型需要 1400K GPU 小时。
运行大模型几乎可以归结为两个因素:内存带宽和计算能力,足够高的内存带宽才能“提供”计算,足够强大的计算才能跟上内存提供的数据。对于个人开发者来说,可能并没有完美设备,因此很开发者也在寻求更容易配置的量化模型版本。
也有开发者支招:可以在 64GB RAM 的 Macbook M1/M2 上运行 70B 模型。
开发者“tinco”表示,“据我所知,市场上没有其他笔记本电脑具有与 64GB MBP 一样多的 VRAM。您可以使用两个 3090 制成一台 Linux 台式计算机,将它们连接在一起提供 48GB 的 VRAM。这样显然可以运行 4 位量化的 6k 上下文 70B Llama 模型。”Tinco 进一步表示,人们推荐 Macbook 是因为它们是一种相对便宜且简单的方法,可以将大量 RAM 连接到加速器上。
Tinco 提醒道,这些是模型的量化版本,因此它们不如原始 70B 模型好,尽管人们声称它们的性能非常接近原始性能。要在不进行量化的情况下运行,则需要大约 140GB 的 VRAM。这只有一台 NVidia H100(不知道价格)或两台 A100(每台 18,000 美元)才能实现。
也有开发者分析称,理论上,单个 Nvidia 4090 能够以“可用”速度运行量化的 70B 模型。Mac 硬件在人工智能方面如此强大的原因是因为统一的架构,这意味着内存在 GPU 和 CPU 之间共享。还有其他因素,但本质上归结为每秒代币的优势。用户可以在内存带宽较低的旧 GPU 上运行这些模型中的任何一个,但每秒的令牌速度对于大多数人认为“可用”的速度来说太慢了,而且必要的量化可能会明显影响质量。
结束语
代码生成一直既被开发者叫好又被吐槽,即使是 ChatGPT 和 Copilot,因为虽然可以提效,但是质量问题一言难尽。
有开发者在 Hacker News 上表示,“两个月后我取消了订阅(Copilot),因为我花了太多的精力去检查所有代码并修复所有错误。当尝试处理任何不琐碎的或与 SQL 有关的事情时(即使我用整个模式预先加载它),它基本上是无用的。自己编写所有内容要省力得多,因为我实际上知道自己想写什么,并且修复自己的错误比修复机器人的错误更容易。”
使用 ChatGPT 的“ben_w”表示,“我对它( ChatGPT)的功能感到惊讶,但即便如此,我也不会称其为‘好代码’。我将它用于 JavaScript 编程,因为虽然我可以阅读(大部分) JS 代码,但过去 14 年我一直专业从事 iOS 工作,因此不知道什么是浏览器领域的最佳实践。尽管如此,我得到工作代码后,我也可以发现它产生了错误的选择和(看起来)奇怪的东西。”
类似的问题我们也在之前的文章《代码屎山噩梦加速来袭,都是 AI 生成代码的锅?》中讨论过。最新研究也表示,GitHub Copilot “代码质量面临下行压力”,代码可维护性的趋势令人不安。
开源领域一直在进行生成更好代码的研究。在 Hugging Face 的“Big Code Models Leaderboard”上,也有很多被开发者认可的模型。
比如北京大学推出了⼀系列从 1.3B 到 33B 的 DeepSeek-Coder 开源代码模型。DeepSeek-Coder 基于 2 万亿个代币上从头训练,都使用 16K 的窗口大小和额外的填空任务在项目级代码语料库上进行预训练,以支持项目级代码补全和填充。测评结果表明,DeepSeek-Coder 不仅在多个基准测试中实现了开源代码模型中最先进的性能,⽽且还超越了 Codex 和 GPT-3.5 等现有的闭源模型。
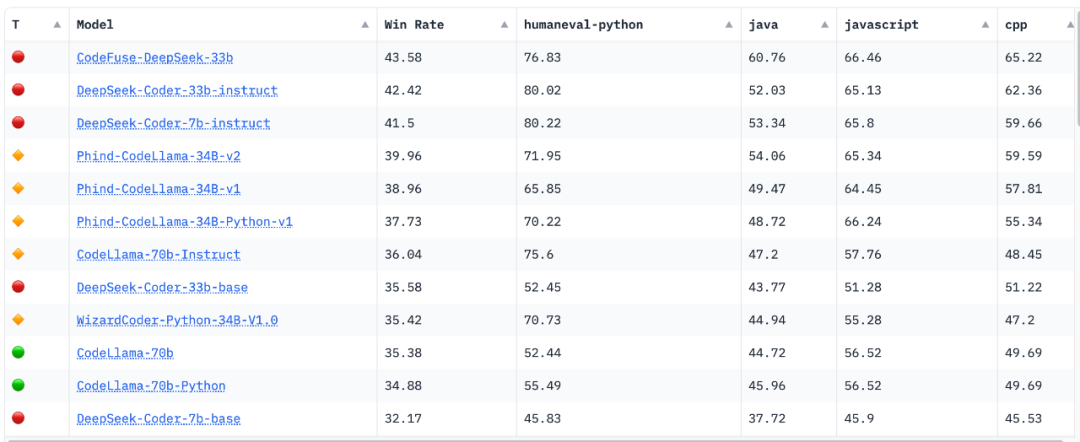
对于有开发者提出“当前 SOTA 本地代码生成模型是什么”的问题,可能现在还没有标准答案,大家还在努力想办法优化现在模型,现在远不是终点。
你心中的 SOTA 代码生成模型是什么?欢迎评论区说出你的使用感受和经验!
相关链接:
Meta 在研究论文中披露了 Code Llama 的开发细节以及基准测试的具体步骤,感兴趣的用户可以查看:
https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
感兴趣的朋友可以在 GitHub 上参阅 Code Llama 训练 recipes:
https://github.com/facebookresearch/codellama
参考链接:

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论