

本文最初发表在 Towards Data Science 博客,经原作者 Kurtis Pykes 授权,InfoQ 中文站翻译并分享。
我一直与朋友们热切地研究并尝试一些能使我成为更好的数据科学家的方法。如果不与那些帮助过我的人们分享目前的情况,我是不可能在事业上取得进步的。
最近,我在 LinkedIn 上进行了一次民意调查,我惊讶地发现,很多人持有这样的观点:数据科学家必须懂得编程标准并遵循工程最佳实践。
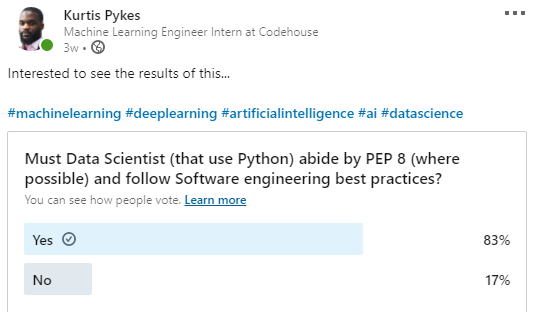
投票结果
许多数据科学家(包括我自己)都缺乏基本的统计学知识,对统计学的应用知之甚少。而数学家们认为,在应用之前,必须对应用于各种场景的原理有一个坚实的理解,我承认我并不了解这些原理。软件工程师希望数据科学家能够在遵循基本编程原则的同时进行实验。
最让我感到刺痛的是,每一位“赞成”的投票者目前都在担任数据科学家,而且其中许多人还担任领导角色(在投票时)——包括 4x Kaggle Grandmaster(Kaggle 数据科学竞赛大师)Abhishek Thakur 这样的人。好吧,我承认,你想要的角色决定了你对统计学和其他数学概念(如概率、线性代数和微积分等)的理解有多深——尽管基础知识是绝对必要的——但软件工程实践呢?
我曾经也是数据科学家中的一员,人们认为我们只是数据科学家,而不是软件工程师,因此我们的责任是从数据中提取有价值的见解,这仍然是一个事实,然而,这次调查扰乱了我的心智,让我陷入了深深的思考。
作为一名数据科学家,为什么要必须了解软件工程的基础知识呢?
我记得我的目标——成为一名不可或缺的数据科学家。我的意思是,如果我不知道或不去学习软件工程的基础知识,那我就不是不可或缺的数据科学家了吗?嗯,是的,基本上是如此。请注意,这句话做了一个假设,比如,你是一个数据科学家,所编写的代码很可能会进入生产环境。
在这一点上,我整理了一份清单,这些内容是软件工程的基本原则,应该适用于数据科学家。但由于我没有软件工程的背景,因此我咨询了很多软件工程师的朋友,帮助我列出了这份清单,并教我如何写出更好的生产代码。
下面是数据科学家应该知道的一些最佳实践:
整洁代码
注意:首先我想向 R 编程语言的用户致歉,因为我并没有对 R 编程语言的编码方面做过太多的研究,因此,本文提到的许多整洁代码的技巧,将主要针对 Python。
我学的第一门编程语言是 Python,因为我的英语很流利,对我来说,Python 与英语非常相似。从技术上讲,这指的是 Python 编程语言的高可读性,这是 Python 的设计者在意识到代码阅读的频率比代码编写的频率更高,特意设计成这样的。
当一名经验丰富的 Python 开发人员将部分代码称为非“Python 风格”时,他们通常意味着这些代码行没有遵循通用的指导原则,并且未能以被认为是最好的(听说是最易读的)的方式表达其意图。
——《Python 编程之美:最佳实践指南》(The Hitchhikers Guide to Python)
我将列出一些构成整洁代码的因素,但我并不打算说得过于详细,因为我相信,这些主题,有很多很棒的资源讲得比我还好,比如这两本书:《Style Guide for Python Code》和《Clean Code in Python》(译注:这两本书目前暂无中译本)。
有意义且可发音的命名约定;
清晰度高于一致性;
可搜索命名;
使你的代码易读。
请记住,不只是别人会阅读你的代码,你自己也会阅读。如果你不记得某些命名的含义,请想象一下别人会有什么希望。
模块化
这可以部分归咎于我们学习数据科学的方式。如果一个数据科学家不能打开一个 Jupyter Notebook 并开始做一些探索,我会感到惊讶。但这就是 Jupyter Notebook 的作用:实验!然而不幸的是,许多关于学习数据科学的课程并没有很好地将我们从 Jupyter Notebook 转移到脚本上,而脚本对于生产环境来说更为有效。
当我们谈论模块化代码时,我们指的是被分离成独立模块的代码。通过有效地执行,模块化可以使打包、测试和可维护的代码能够重复使用。
在这个视频中,Abhishek Thakur 为 Kaggle 竞赛构建了一个机器学习包,这是我第一次接触到模块化。我以前也听过 Abhishek 提到过,他学习更多模块化和软件工程最佳实践的方式是通过阅读 GitHub 上的 Scikit Learn 代码。
其他有助于编写好的模块化代码的其他因素包括:
不要重复你自己(Don’t repeat yourself,DRY):是面向对象编程中的基本原则,程序员的行事准则。旨在软件开发中,减少重复的信息,编程过程中不写重复代码,将能够公共的部分抽象出来, 封装成工具类或者用 “abstraction” 类来抽象公有的东西,降低代码的耦合性,这样不仅提高代码的灵活性、健壮性以及可读性,也方便后期的维护或者修改。
单一功能原则(Single Responsibility Principle,SRP):是一种计算机编程原则,规定每个类都应该有一个单一的功能,并且该功能应该由这个类完全封装起来。
开闭原则(Open-Closed Principle):在面向对象编程领域中,开闭原则规定 “软件中的对象(类、模块、函数等等)应该对于扩展是开放的,但是对于修改是封闭的 ”,这意味着一个实体是允许在不改变它的源代码的前提下变更它的行为。
重构
代码重构可以定义为在运行时不改变代码外部行为的情况下重构现有代码的过程。
重构旨在改进软件的设计、结构和/或实现(其非功能属性),同时保留其功能。
重构代码有很多好处,例如,提高了代码的可读性,降低了复杂性,这反过来又导致源代码更容易维护,并且我们配备了一个内部架构,提高了我们编写的代码的可扩展性。
此外,我们不能只谈论代码重构而不谈论性能的提高。我们的目标是编写一个执行速度更快、占用内存更少的程序,特别是当我们有最终用户要执行一些任务时。
测试
注意:在机器学习模型的部署 Udemy 课程中,我简单学习了测试(以及本文所涉及的其他大多数想法)。
在某种意义上,数据科学是一个有趣的领域,即使我们的代码有错误,但我们的代码仍然有可能能够运行,而在软件相关项目中,代码会抛出一个错误。因此,我们最终会得到误导性的见解(也可能找不到工作)。因此,测试是必要的,如果你懂得测试,你的身价就会上升。
以下是我们进行测试的一些原因:
确保我们得到正确的输出。
更新代码更容易。
防止将破坏的代码推送到生产环境。
我相信还有更多的原因,但我不再就此赘述。
代码审查
代码审查的目的是通过推广最佳编程实践来提高代码质量,使代码能够为生产做好准备。此外,这对每个人都有好处,因为它往往会对团队和公司文化产生积极影响。
代码审查的主要原因是为了发现错误,尽管审查对于提高可读性以及确保满足编码标准非常有用。
结语
可以这么说,这绝对是一大堆需要学习的东西,但出于完全相同的原因,它推动了数据科学从业者被高估。能够制作出 Jupyter Notebook 已经不足以让你成为数据科学家脱颖而出,因为每个人都能做到。如果你想超越平均水平,你就必须做超过平均水平的事情,在这种情况下,可能要涉及到学习软件工程最佳实践。
作者介绍:
Kurtis Pykes,痴迷于数据科学、人工智能和商业技术应用。
原文链接:

加V:busulishang4668

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论