关键点:
- 了解机器学习数据流水线有关内容。
- 怎么用 Apache Spark 机器学习包来实现机器学习数据流水线。
- 数据价值链处理的步骤。
- Spark 机器学习流水线模块和 API。
- 文字分类和广告检测用例。
在之前的“用 Apache Spark 做大数据处理”系列文章中,我们学习了Apache Spark 框架,介绍了Spark 和它用作大数据处理的不同库(第一部分),Spark SQL 库(第二部分),Spark 流(第三部分)和Spark MLlib 机器学习库(第四部分)。
在这篇文章中,我们Spark 的其它机器学习API,名为 Spark ML ,如果要用数据流水线来开发大数据应用程序的话,这个是推荐的解决方案。
Spark ML( spark.ml )包提供了构建在 DataFrame 之上的机器学习 API,它已经成了 Spark SQL 库的核心部分。这个包可以用于开发和管理机器学习流水线。它也可以提供特征抽取器、转换器、选择器,并支持分类、汇聚和分簇等机器学习技术。这些全都对开发机器学习解决方案至关重要。
在这里我们看看如何使用 Apache Spark 来做探索式数据分析(Exploratory Data Analysis)、开发机器学习流水线,并使用 Spark ML 包中提供的 API 和算法。
因为支持构建机器学习数据流水线,Apache Spark 框架现在已经成了一个非常不错的选择,可以用于构建一个全面的用例,包括 ETL、指量分析、实时流分析、机器学习、图处理和可视化等。
机器学习数据流水线
机器学习流水线可以用于创建、调节和检验机器学习工作流程序等。机器学习流水线可以帮助我们更加专注于项目中的大数据需求和机器学习任务等,而不是把时间和精力花在基础设施和分布式计算领域上。它也可以在处理机器学习问题时帮助我们,在探索阶段我们要开发迭代式功能和组合模型。
机器学习工作流通常需要包括一系列的处理和学习阶段。机器学习数据流水线常被描述为一种阶段的序列,每个阶段或者是一个转换器模块,或者是个估计器模块。这些阶段会按顺序执行,输入数据在流水线中流经每个阶段时会被处理和转换。
机器学习开发框架要支持分布式计算,并作为组装流水线模块的工具。还有一些其它的构建数据流水线的需求,包括容错、资源管理、可扩展性和可维护性等。
在真实项目中,机器学习工作流解决方案也包括模型导入导出工具、交叉验证来选择参数、为多个数据源积累数据等。它们也提供了一些像功能抽取、选择和统计等的数据工具。这些框架支持机器学习流水线持久化来保存和导入机器学习模型和流水线,以备将来使用。
机器学习工作流的概念和工作流处理器的组合已经在多种不同系统中越来越受欢迎。象 scikit-learn 和 GraphLab 等大数据处理框架也使用流水线的概念来构建系统。
一个典型的数据价值链流程包括如下步骤:
- 发现
- 注入
- 处理
- 保存
- 整合
- 分析
- 展示
机器学习数据流水线所用的方法都是类似的。下图展示了在机器学习流水线处理中涉及到的不同步骤。
步骤#
名字
描述
ML1
数据注入
从不同的数据源中导入数据。
ML2
数据清洗
对数据进行预处理,为接下来的机器学习数据分析做好准备。
ML3
功能抽取
也叫特征工程,这一步是从数据集中抽取功能。
ML4
模型训练
在接下来的几个步骤里用训练数据集来训练机器学习模型。
ML5
模型验证
接下来要基于不同的预测参数来评估机器学习模型的效率。我们也会在验证步骤调节模型,这一步用于挑选出最佳模型。
ML6
模型测试
这一步是在做模型部署之前进行测试。
ML7
模型部署
最后一步是把选出来的模型部署到生产环境中运行。
表一:机器学习流水线处理步骤
这些步骤也可以用下面的图一表示。
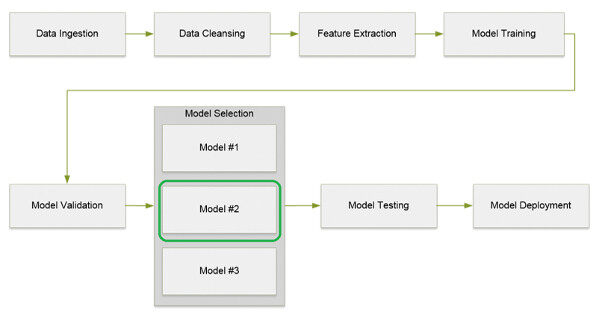
图一:机器学习数据流水线处理流图
接下来让我们一起看看每个步骤的细节。
数据注入:我们收集起来供给机器学习流水线应用程序的数据可以来自于多种数据源,数据规模也是从几百 GB 到几 TB 都可以。而且,大数据应用程序还有一个特征,就是注入不同格式的数据。
数据清洗:数据清洗这一步在整个数据分析流水线中是第一步,也是至关重要的一步,也可以叫做数据清理或数据转换,这一步主要是要把输入数据变成结构化的,以方便后续的数据处理和预测性分析。依进入到系统中的数据质量不同,总处理时间的60%-70% 会被花在数据清洗上,把数据转成合适的格式,这样才能把机器学习模型应用到数据上。
数据总会有各种各样的质量问题,比如数据不完整,或者数据项不正确或不合法等。数据清洗过程通常会使用各种不同的方法,包括定制转换器等,用流水线中的定制的转换器去执行数据清洗动作。
稀疏或粗粒数据是数据分析中的另一个挑战。在这方面总会发生许多极端案例,所以我们要用上面讲到的数据清洗技术来保证输入到数据流水线中的数据必须是高质量的。
伴随着我们对问题的深入理解,每一次的连续尝试和不断地更新模型,数据清洗也通常是个迭代的过程。象 Trifacta 、 OpenRefine 或 ActiveClean 等数据转换工具都可以用来完成数据清洗任务。
特征抽取:在特征抽取(有时候也叫特征工程)这一步,我们会用特征哈希(Hashing Term Frequency)和 Word2Vec 等技术来从原始数据中抽取具体的功能。这一步的输出结果常常也包括一个汇编模块,会一起传入下一个步骤进行处理。
模型训练:机器学习模型训练包括提供一个算法,并提供一些训练数据让模型可以学习。学习算法会从训练数据中发现模式,并生成输出模型。
模型验证:这一步包评估和调整机器学习模型,以衡量用它来做预测的有效性。如这篇文章所说,对于二进制分类模型评估指标可以用接收者操作特征(Receiver Operating Characteristic, ROC )曲线。ROC 曲线可以表现一个二进制分类器系统的性能。创建它的方法是在不同的阈值设置下描绘真阳性率(True Positive Rate, TPR )和假阳性率(False Positive Rate, FPR )之间的对应关系。
模型选择:模型选择指让转换器和估计器用数据去选择参数。这在机器学习流水线处理过程中也是关键的一步。ParamGridBuilder 和 CrossValidator 等类都提供了 API 来选择机器学习模型。
模型部署:一旦选好了正确的模型,我们就可以开始部署,输入新数据并得到预测性的分析结果。我们也可以把机器学习模型部署成网页服务。
Spark 机器学习
机器学习流水线 API 是在 Apache Spark 框架 1.2 版中引入的。它给开发者们提供了 API 来创建并执行复杂的机器学习工作流。流水线 API 的目标是通过为不同机器学习概念提供标准化的 API,来让用户可以快速并轻松地组建并配置可行的分布式机器学习流水线。流水线 API 包含在 org.apache.spark.ml 包中。
Spark ML 也有助于把多种机器学习算法组合到一条流水线中。
Spark 机器学习 API 被分成了两个包,分别是 spark.mllib 和 spark.ml。其中 spark.ml 包包括了基于 RDD 构建的原始 API。而 spark.ml 包则提供了构建于 DataFrame 之上的高级 API,用于构建机器学习流水线。
基于 RDD 的 MLlib 库 API 现在处于维护模式。
如下面图二所示,Spark ML 是 Apache Spark 生态系统中的一个非常重要的大数据分析库。
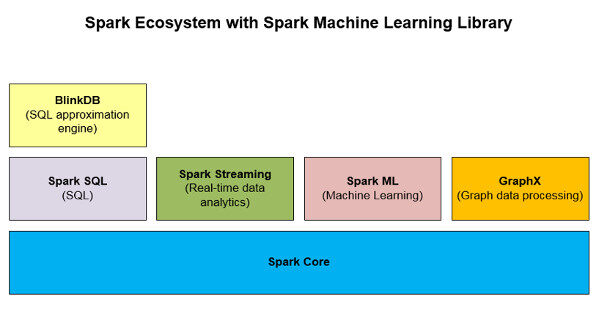
图二:包括了 Spark ML 的 Spark 生态系统
机器学习流水线模块
机器学习数据流水线包括了完成数据分析任务所需要的多个模块。数据流水线的关键模块被列在了下面:
- 数据集
- 流水线
- 流水线的阶段
- 转换器
- 估计器
- 评估器
- 参数(和参数地图)
接下来我们简单看看这些模块可以怎么对应到整体的步骤中。
数据集:在机器学习流水线中是使用 DataFrame 来表现数据集的。它也允许按有名字的字段保存结构化数据。这些字段可以用于保存文字、功能向量、真实标签和预测。
流水线:机器学习工作流被建模为流水线,这包括了一系列的阶段。每个阶段都对输入数据进行处理,为下一个阶段产生输出数据。一个流水线把多个转换器和估计器串连起来,描述一个机器学习工作流。
流水线的阶段:我们定义两种阶段,转换器和估计器。
转换器:算法可以把一个 DataFrame 转换成另一个 DataFrame。比如,机器学习模型就是一个转换器,用于把一个有特征的 DataFrame 转换成一个有预测信息的 DataFrame。
转换器会把一个 DataFrame 转成另一个 DataFrame,同时为它加入新的特征。比如在 Spark ML 包中, OneHotEncoder 就会把一个有标签索引的字段转换成一个有向量特征的字段。每个转换器都有一个 transform() 函数,被调用时就会把一个 DataFrame 转换成另一个。
估计器:估计器就是一种机器学习算法,会从你提供的数据中进行学习。估计器的输入是一个 DataFrame,输出就是一个转换器。估计器用于训练模型,它生成转换器。比如,逻辑回归估计器就会产生逻辑回归转换器。另一个例子是把 K-Means 做为估计器,它接受训练数据,生成 K-Means 模型,就是一个转换器。
参数:机器学习模块会使用通用的 API 来描述参数。参数的例子之一就是模型要使用的最大迭代次数。
下图展示的是一个用作文字分类的数据流水线的各个模块。
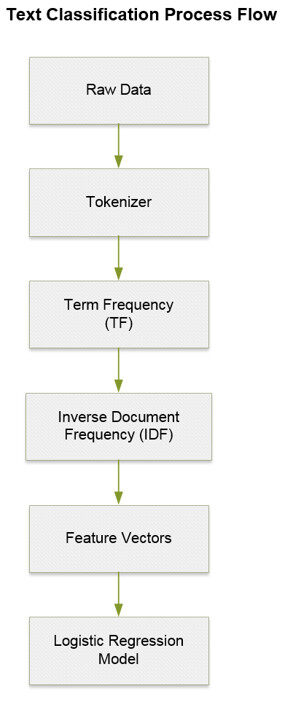
图三:使用 Spark ML 的数据流水线
用例
机器学习流水线的用例之一就是文字分类。这种用例通常包括如下步骤:
- 清洗文字数据
- 将数据转化成特征向量,并且
- 训练分类模型
在文字分类中,在进行分类模型(类似 SVM )的训练之前,会进行 n-gram 抽象和 TF-IDF 特征权重等数据预处理。
另一个机器学习流水线用例就是在这篇文章中描述的图像分类。
还有很多种其它机器学习用例,包括欺诈检测(使用分类模型,这也是监督式学习的一部分),用户分区(聚簇模型,这也是非监督式学习的一部分)。
TF-IDF
词频 - 逆向文档频率(Term Frequency - Inverse Document Frequency, TF-IDF )是一种在给定样本集合内评估一个词的重要程度的静态评估方法。这是一种信息获取算法,用于在一个文档集合内给一个词的重要性打分。
TF:如果一个词在一份文档中反复出现,那这个词就比较重要。具体计算方法为:
TF = (# of times word X appears in a document) / (Total # of
words in the document)
IDF:但如果一个词在多份文档中都频繁出现(比如 the,and,of 等),那就说明这个词没有什么实际意义,因此就要降低它的评分。
示例程序
下面我们看个示例程序,了解一下 Spark ML 包可以怎样用在大数据处理系统中。我们会开发一个文档分类程序,用于区别程序输入数据中的广告内容。测试用的输入数据集包括文档、电子邮件或其它任何从外部系统中收到的可能包含广告的内容。
我们将使用在 Strata Hadoop World Conference 研讨会上讨论的“用 Spark 构建机器学习应用”的广告检测示例来构建我们的示例程序。
用例
这个用例会对发送到我们的系统中的各种不同消息进行分析。有些消息里面是含有广告信息的,但有些消息里面没有。我们的目标就是要用 Spark ML API 找出那些包含了广告的消息。
算法
我们将使用机器学习中的逻辑回归算法。逻辑回归是一种回归分析模型,可以基于一个或多个独立变量来预测得到是或非的可能结果。
详细的解决方案
接下来咱们看看这个 Spark ML 示例程序的细节,以及运行步骤。
数据注入:我们会把包含广告的数据(文本文件)和不包含广告的数据都导入。
数据清洗:在示例程序中,我们不做任何特别的数据清洗操作。我们只是把所有的数据都汇聚到一个 DataFrame 对象中。
我们随机地从训练数据和测试数据中选择一些数据,创建一个数组对象。在这个例子中我们的选择是 70% 的训练数据,和 30% 的测试数据。
在后续的流水线操作中我们分别用这两个数据对象来训练模型和做预测。
我们的机器学习数据流水线包括四步:
- Tokenizer
- HashingTF
- IDF
- LR
创建一个流水线对象,并且在流水线中设置上面的各个阶段。然后我们就可以按照例子,基于训练数据来创建一个逻辑回归模型。
现在,我们再使用测试数据(新数据集)来用模型做预测。
下面图四中展示了例子程序的架构图。
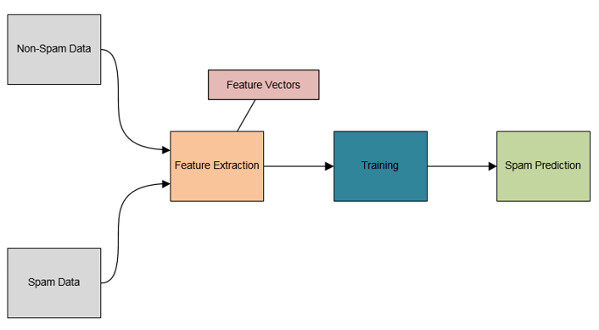
图 4:数据分类程序架构图
技术
在实现机器学习流水线解决方案时我们用到了下面的技术。
技术
版本
Apache Spark
2.0.0
JDK
1.8
Maven
3.3
表二:在机器学习例子中用到的技术和工具
Spark ML 程序
根据研讨会上的例子而写成的机器学习代码是用Scala 编程语言写的,我们可以直接使用Spark Shell 控制台来运行这个程序。
广告检测Scala 代码片段:
第一步:创建一个定制的类,用来存储广告内容的细节。
case class SpamDocument(file: String, text: String, label:
Double)
第二步:初始化 SQLContext,并通过隐式转换方法来把Scala 对象转换成DataFrame。然后从存放着输入文件的指定目录导入数据集,结果会返回RDD 对象。然后由这两个数据集的RDD 对象创建DataFrame 对象。
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
//
// Load the data files with spam
//
val rddSData = sc.wholeTextFiles("SPAM_DATA_FILE_DIR", 1)
val dfSData = rddSData.map(d => SpamDocument(d._1, d._2,1)).toDF()
dfSData.show()
//
// Load the data files with no spam
//
val rddNSData = sc.wholeTextFiles("NO_SPAM_DATA_FILE_DIR",
1)
val dfNSData = rddNSData.map(d => SpamDocument(d._1,d._2, 0)).toDF()
dfNSData.show()
第三步:现在,把数据集汇聚起来,然后根据 70% 和 30% 的比例来把整份数据拆分成训练数据和测试数据。
//
// Aggregate both data frames
//
val dfAllData = dfSData.unionAll(dfNSData)
dfAllData.show()
//
// Split the data into 70% training data and 30% test data
//
val Array(trainingData, testData) =
dfAllData.randomSplit(Array(0.7, 0.3))
第四步:现在可以配置机器学习数据流水线了,要创建我们在文章前面部分讨论到的几个部分:Tokenizer、HashingTF 和 IDF。然后再用训练数据创建回归模型,在这个例子中是逻辑回归。
//
// Configure the ML data pipeline
//
//
// Create the Tokenizer step
//
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
//
// Create the TF and IDF steps
//
val hashingTF = new HashingTF()
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("rawFeatures")
val idf = new
IDF().setInputCol("rawFeatures").setOutputCol("features")
//
// Create the Logistic Regression step
//
val lr = new LogisticRegression()
.setMaxIter(5)
lr.setLabelCol("label")
lr.setFeaturesCol("features")
//
// Create the pipeline
//
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, idf, lr))
val lrModel = pipeline.fit(trainingData)
println(lrModel.toString())
第五步:最后,我们调用逻辑回归模型中的转换方法来用测试数据做预测。
//
// Make predictions.
//
val predictions = lrModel.transform(testData)
//
// Display prediction results
//
predictions.select("file", "text", "label", "features", "prediction").show(300)
结论
Spark 机器学习库是 Apache Spark 框架中最重要的库之一。它用于实现数据流水线。在这篇文章中,我们了解了如何使用 Spark ML 包的 API 以及用它来实现一个文本分类用例。
接下来的内容
图数据模型是关于在数据模型中不同的实体之间的连接和关系的。图数据处理技术最近受到了很多关注,因为可以用它来解决许多问题,包括欺诈检测和开发推荐引擎等。
Spark 框架提供了一个库,专门用于图数据分析。我们在这个系列的文章中,接下来会了解这个名为 Spark GraphX 的库。我们会用 Spark GraphX 来开发一个示例程序,用于图数据处理和分析。
引用
- 用 Apache Spark 做大数据分析——第一部分:介绍
- 用 Apache Spark 做大数据分析——第二部分: Spark SQL
- 用 Apache Spark 做大数据分析——第三部分: Spark 流
- 用 Apache Spark 做大数据分析——第四部分: Spark 机器学习
- Apache Spark 项目官方网站
- Spark机器学习网站
- Spark 机器学习编程指导
- Spark 研讨会关于广告检测的练习
关于作者
 ** Srini Penchikala ** 现在住在德克萨斯州奥斯汀,是一名高级软件架构师。他在软件架构、软件开发与设计方面有超过 22 年的经验。Penchikala 现在正在写一本关于 Apache Spark 的书。他也是曼宁出版社的图书“ Spring Roo in Action ”的作者之一。他曾在各种会议上做演讲,包括 JavaOne、SEI 架构技术会议(SATURN)、IT 架构会议(ITARC)、No Fluff Just Stuff、NoSQL Now、Enterprise Data World 和 Project World Conference 等。Penchikala 也发表过许多篇关于软件架构、安全与风险管理的文章,也在 InfoQ、ServerSide、OReilly Network(ONJava)、DevX Java、java.net 和 JavaWorld 等网站上发表过 NoSQL 和大数据主题的文章。他也是 InfoQ 上数据科学社区的主编。
** Srini Penchikala ** 现在住在德克萨斯州奥斯汀,是一名高级软件架构师。他在软件架构、软件开发与设计方面有超过 22 年的经验。Penchikala 现在正在写一本关于 Apache Spark 的书。他也是曼宁出版社的图书“ Spring Roo in Action ”的作者之一。他曾在各种会议上做演讲,包括 JavaOne、SEI 架构技术会议(SATURN)、IT 架构会议(ITARC)、No Fluff Just Stuff、NoSQL Now、Enterprise Data World 和 Project World Conference 等。Penchikala 也发表过许多篇关于软件架构、安全与风险管理的文章,也在 InfoQ、ServerSide、OReilly Network(ONJava)、DevX Java、java.net 和 JavaWorld 等网站上发表过 NoSQL 和大数据主题的文章。他也是 InfoQ 上数据科学社区的主编。
阅读英文原文: Big Data Processing with Apache Spark - Part 5: Spark ML Data Pipelines




