
AppDynamics 公司的智能程序平台可以帮助客户分析软件程序的性能、用户体验和业务影响等,并可以提供实时的监控、故障解决和分析等服务。智能程序平台的核心是负责记录、跟踪和比较性能指标的指标处理引擎。在软件程序复杂度爆发性增长和许多公司把单一程序拆分成微服务的背景下,指标处理引擎需要采集和分析的指标也变得极度复杂和庞大,因而他们不得不重构了整个系统。 Gautam Borah 在 AppDyamics 公司负责产品设计和开发基于大数据技术的下一代指标处理系统,他最近在博客中记录了这次重构的选型情况。
AppDynamics 的程序性能管理(Application Performance Management ,APM)代理在为几千个程序几百万行代码收集性能指标,它们支持包括 Jave、.Net、Node.js、PHP 和 Python 等在内的多种语言和框架。可收集浏览器、手机和服务器程序数据,还有扩展程序从各种异构程序和基础设施模块收集数据。收集到的指标被周期性的发送给指标处理引擎,它把各种维度的指标收集起来再以不同角度的视图展示出去。
最初的指标处理引擎是基于 MySQL 的,但当指标指数级的增长之后,要处理的指标数已经逼近 MySQL 的物理上限。研发团队总结对智能平台的主要需求是:
- 处理的指标总量要比当前翻许多倍
- 各个维度的数据保留期限要延长很多
- 实时收集业务集群指标数据,并要做集合运算
- 要支持批处理
- 系统容错,消除单点故障
- 软件升级不停服
研发团队进行了周密的选型。StumbleUpon 的 OpenTSDB 和 MetaMarkets 的 Druid 都是不错的时间序列数据库,但由于指标处理引擎的需求太特别,用它们不太合适。在能提供容错和横向扩展的开源键值型存储中,最主流和使用最广的就是 HBase 和 Cassandra 了。
最终选择的是 HBase,胜出原因也是它的分区策略是按主键有序排列的范围分区,这样就可以自由的按时间范围进行查询,时间跨度大也无所谓,并且方便使用各种集合算法。
HBase 的键值对存储在表中,而且每张表都被拆分成多个 Region,每个 Region 中都存储着一段按主键排序的连续数据,即表中从一个 Region 的初始主键开始到结束主键的范围内的所有数据都存储在这一个 Region 中。Hortonworks 有文章详细解释了这个机制。
Cassandra 分区策略与此不同,它的节点是按一致性哈希环分布的,所有的主键都转换成 Murmur3 哈希值然后放在某个节点中。Datastax 的文章中解释了这种分区策略。
为什么按主键做范围查询如此重要?
如下图所示的 AppDynamics 程序性能仪表盘提供了整个程序性能指标的拓朴视图。仪表盘展现了业务程序的调用链,还有每分钟调用率、平均响应时间、每分钟错误率和每分钟异常率等性能统计。
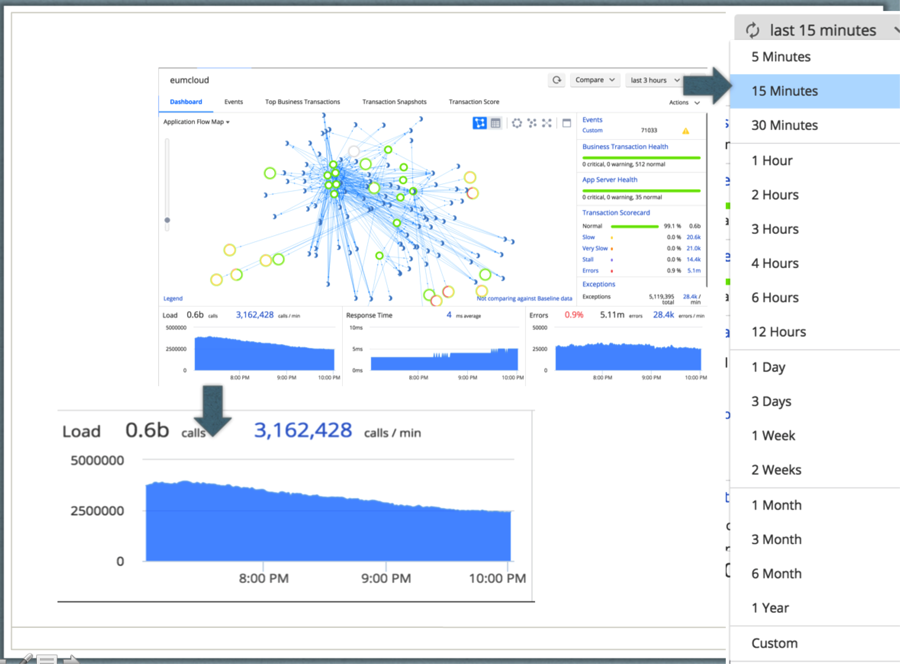
拓朴图、调用链、性能统计等都是直接按时间范围从指标库里查出来的。典型的查询语句是:
Select SUM(totals calls) from METRICS where metricID = m1 and time in range (t1, t2), t1-start time, t2 – end time. Select AVG(response time) from METRICS where metricID = m1 and time in range (t1, t2), t1-start time, t2 – end time. Select SUM(total errors) from METRICS where metricID = m1 and time in range (t1, t2), t1-start time, t2 – end time.
解决这个问题的一个最简单设计就是把 metricID 做为表的主键,把时间点做为表的字段,在某个时间点采取的指标值就保存在对应时间点的字段里。HBase 和 Cassandra 都支持这种设计,而且因为主键是 metricID,不管 HBase 还是 Cassandra,这个指标的所有值都会保存在一个分区里。查询一个时间范围内的指标值时,只需要把对应的时间点里的值取出,再加上上面查询语句对应的算法就可以了。
但这个设计在现实中是不可行的,因为不管理论上还是工程上,一张表所能支持的字段数都是有限的。在指标处理系统中,一分钟至少要保存一个值,一天就有几千个值,一星期就会有几百万,而一年则会有几十亿。不可能设计一张表有这么多字段。
一个相对好得多的改进设计是把主键按时间段分区。即主键是 metricID 加上时间段,对应的时间段里的各个时间点的值,则和上文一样作为表的字段保存起来。比如以一个小时为一个时间段,则从 12:00AM 到 12:00PM 总共会有 12 个主键值。有一篇文章讲述了Cassandra 如何用这个方法为时间序列问题建模的,具体就是它的组合主键。使用metricID 作为分区键,使用时间段的值作为集合键,收到的指标值作为表的字段保存起来。Cassandra 的存储引擎底层是使用组合字段来存储集合值的。所有相同分区键对应的逻辑行,实际上是做为一个物理宽行保存的。通过这种方法,Casasandra 每个物理行可以支持20 亿个字段。
HBase 则没有组合主键的概念,它的主键就是一个字符串。数据在 HBase 里的保存是按照主键的字母顺序排序的,主键值相邻的记录会保存在同一个分区里,即 Region。如果主键设计的好的话,几年的指标数据都可以保存在 HBase 的一个 Region 中。
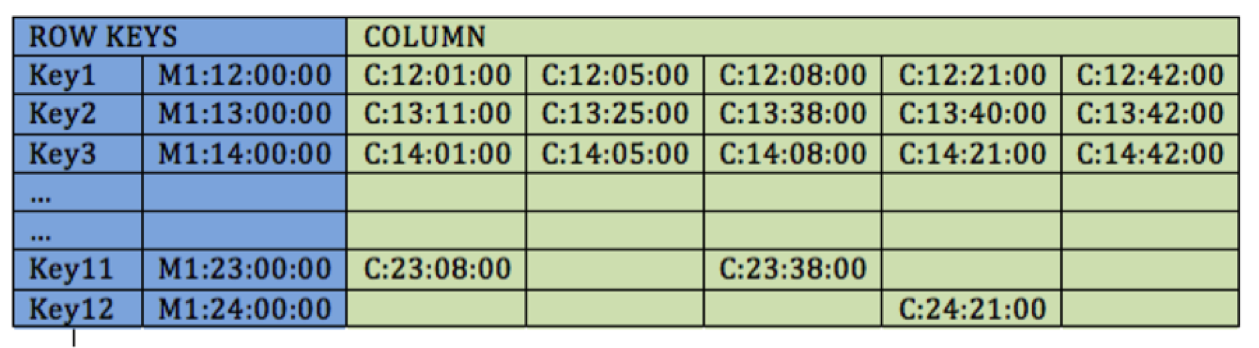
这个概念很重要,对这个用例也非常有用。因为一个很长的时间范围内的数据都存储在同一个 Region 中,那即使做一个半年内甚至两年内的集合运算,它也是在一个 Region Server 内部计算,算完了只把结果返回给调用程序,因而极大的减少了网络流量。如果不是这样的设计,那数据就可能会分散在多个分区(甚至是多台机器)上,做集合运算就要把数据从各个分区集中到一个客户端程序上,它做完集合运算后,再把最终结果发送到调用程序。这样代价非常大。
除此之外,弃用 Cassandra 还因为它缺少几个 HBase 已有的关键功能:
- HBase 允许把指标分配到不同的列族里,然后以列族为单位设置过期值。Cassandra 则以 Cell 为单位设置过期值,而且对相同类型的 Cell 要逐一设置,就使得存储非常臃肿。2015 年 11 月发布的 Cassandra 3.0 解决了这个问题。
- HBase 的设计是在可用性的基础上再提供了一致性,由于指标系统的策略引擎是不断计算的,所以这个功能非常关键。想进一步了解 CAP 理论可以参考这篇文章。
作者在下一篇博客中会讲到他使用 HBase 过程中碰到的问题及一些改进建议。作者非常欢迎大家留言反馈。
就在8 月18 号,首届应用性能管理技术大会 APMCon2016 将在京举办,届时,AppDynamics 的首席数据科学家赵宇辰将分享下一代数据驱动的智能 APM 技术,痛点,趋势及解决方案。想现场感受这场技术盛宴的火热吗?大会门票团购 6 折优惠,快来抢票。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论