
整理|华卫
今日,华为正式宣布开源盘古 70 亿参数的稠密模型、盘古 Pro MoE 720 亿参数的混合专家模型和基于昇腾的模型推理技术。华为表示,“此举是华为践行昇腾生态战略的又一关键举措,推动大模型技术的研究与创新发展,加速推进人工智能在千行百业的应用与价值创造。”
根据华为官网显示:
盘古 Pro MoE 72B 模型权重、基础推理代码,已正式上线开源平台。
基于昇腾的超大规模 MoE 模型推理代码,已正式上线开源平台。
盘古 7B 相关模型权重与推理代码将于近期上线开源平台。
开源地址:https://gitcode.com/ascend-tribe
盘古 Pro MoE:昇腾原生的分组混合专家模型
盘古 Pro MoE 模型基于分组混合专家模型(Mixture of Grouped Experts, MoGE)架构构建,总参数量为 720 亿、激活参数量达 160 亿,并针对昇腾 300I Duo 和 800I A2 平台进行系统优化。
其中,MoGE 是华为提出的创新架构,旨在从路由机制上实现跨设备的计算负载均衡。
混合专家模型(MoE)在大语言模型(LLMs)中逐渐兴起,该架构能够以较低计算成本支持更大规模的参数,从而获得更强的表达能力。这一优势源于其稀疏激活机制的设计特点,即每个输入 token 仅需激活部分参数即可完成计算。然而,在实际部署中,不同专家的激活频率存在严重的不均衡问题,一部分专家被过度调用,而其他专家则长期闲置,导致系统效率低下。
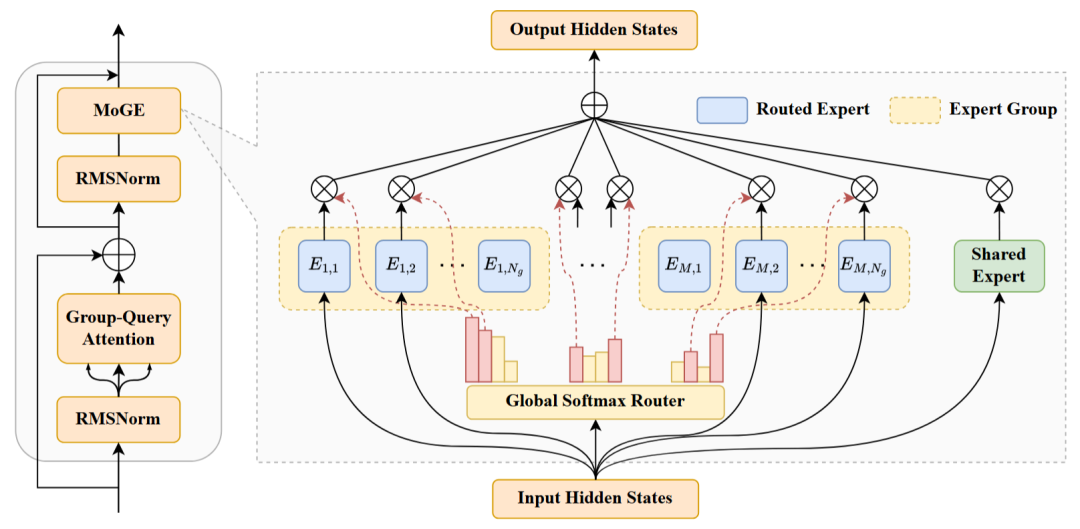
MoGE 架构设计示意图
而 MoGE 的核心思想是在专家选择阶段对专家进行分组,并约束 token 在每个组内激活等量专家,在典型的分布式部署中,每个专家分组对应独立的计算设备,从而 MoGE 天然地实现了跨设备的计算负载均衡,这一设计显著提升了训练和推理场景下的系统吞吐量。
据介绍,盘古 Pro MoE 在昇腾 800I A2 上实现了单卡 1148 tokens/s 的推理吞吐性能,并可进一步通过投机加速等技术提升至 1528 tokens/s,显著优于同等规模的 320 亿和 720 亿参数的稠密模型;在昇腾 300I Duo 推理服务器上,其也实现了极具性价比的模型推理方案。
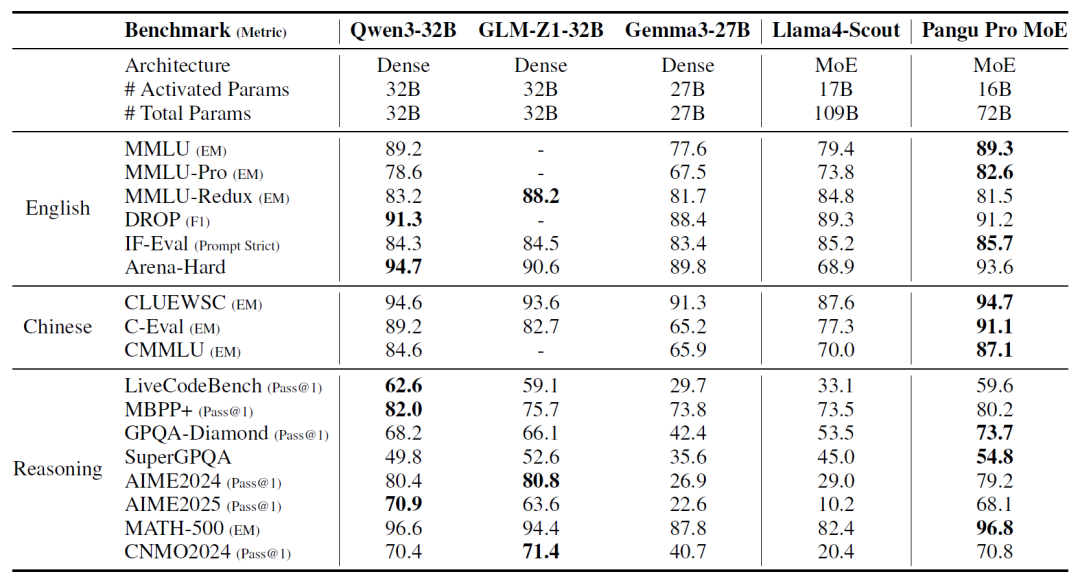
另华为的研究表明,昇腾 NPU 能够支持盘古 Pro MoE 的大规模并行训练。多项公开基准测试结果表明,盘古 Pro MoE 在千亿内总参数模型中处于领先地位。
超大规模 MoE 模型的推理部署方案
在 2025 年新年致辞中,华为轮值董事长孟晚舟曾提到:“华为十多个实验室与合作伙伴的工程师组成团队,面对天成 AI 集群系统和单芯片性能的工程挑战,应用了数学补物理、非摩尔补摩尔、系统补单点等思想,在散热、供电、高速、高密及大芯片在板可靠性等工程领域进行突破。”
当前,华为公布并开源相关代码的昇腾超大规模 MoE 模型推理部署方案,正是沿着这一思路,包括以下几个方面的核心技术能力:
从点到面的推理框架侧优化技术
把数学最优实现变为物理最优的 FlashComm 通算优化技术
把串行计算变成四流并发的通算极致掩盖技术
以加法代乘法昇腾 MLA 最优实现
硬件感知亲和的大量创新算子
其中,OmniPlacement 是一种高效负载均衡算法,通过专家重排、层间冗余部署和近实时调度,在 3 个 token 推理步骤内实现近 90% 的专家均衡,大幅提升 MoE 推理性能。
在大模型推理优化领域,投机推理作为一种极具潜力的技术路径,通过引入轻量模型或外部知识数据,为大模型生成推理草稿,解码阶段一次推理多个 token,提升了计算密度。以 DeepSeek V3/R1 模型为例,其创新性地引入 MTP(Multi-Token Prediction)投机层,有效实现了投机推理技术的落地。投机推理在模型解码阶段的高计算密度天然匹配昇腾高算力带宽比的特点,为充分发挥这一优势,在低时延大并发场景下实现高吞吐,华为提出了投机推理框架 FusionSpec,持续提升 MTP 在昇腾上的推理性能,并使得 MTP 部分框架耗时从 10ms 左右降为 1ms。
OptiQuant 是一个基于华为昇腾芯片模型量化算法的精度解决方案,设计了层间自动混精、自动混合校准、离群值抑制、可学习的截断和 SSZW 参数量化算法,在 DeepSeek R1/V3 大模型推理场景中,实现了 INT8 量化模式与 FP8 的模型推理精度持平,而且进一步发挥了 Atlas 800I A2 和 CloudMatrix384 集群推理硬件性能。
FlashComm 系列技术通过三大创新实现“以数学补物理”的突破,用于解决大模型推理过程中面临的通信瓶颈:
FlashComm: 大模型推理中的 AllReduce 通信优化技术。将 AllReduce 基于通信原理进行拆解,并结合后续计算模块进行协同优化。
FlashComm2:大模型推理中以存换传的通信优化技术。在保持计算语义等价的前提下,实现 ReduceScatter 和 MatMul 算子的计算流程重构。
FlashComm3: 大模型推理中的多流并行技术。充分挖掘昇腾硬件的多流并发能力,实现 MoE 模块的高效并行推理。
在热门开源模型的实测中,FlashComm 技术展现出惊人的工程落地能力:在 Atlas 800I A2 上用两节点 16 卡部署 DeepSeekV3/R1 的场景下,采用 FlashComm 通信方案,Prefill 阶段端到端时延减少了 22%~26%。在 Atlas 800I A2 上采用单节点 8 卡部署 Llama 3.1-70B 的 A8W8 量化模型时,采用 FlashComm 通信方案,在不同并发下,Decode 阶段端到端时延减少了 4% 至 14%。
随着大语言模型的参数规模持续扩大,其推理过程对计算资源的需求持续增加,部署模式已从单卡演进到单节点再逐步演进为多卡多节点协同计算。在此过程中,华为希望通过优化一系列关键算子来提升硬件效率:
AMLA:以加代乘的高性能昇腾 MLA 算子。针对昇腾优化 MLA 算子,性能优于 FlashMLA 实现。
大模型推理中昇腾算子融合技术与设计原理。首次披露了基于昇腾的融合算子的设计原则。
SMTurbo:面向高性能原生 LoadStore 语义加速。介绍了基于 CloudMatrix384 集群的 Load/Store 语义加速方案。
此外,华为围绕盘古模型和昇腾平台开展软硬协同系统优化,在系统侧构建 H2P 分层混合并行优化、TopoComm 拓扑亲和通信优化、DuoStream 多流融合通算掩盖等技术,实现最优分布式并行推理提高计算效率;在算子侧设计开发 MulAttention 融合计算、SwiftGMM 融合计算、MerRouter 融合计算等算子融合技术,充分释放昇腾芯片的算力。基于上述昇腾亲和的系统优化,Pangu Pro MoE 的推理性能提升 6~8×。
7B 模型优于 Qwen,灵活切换快慢思考
当前,为追求卓越推理能力而设计的大语言模型(LLM)普遍面临着巨大的计算成本和推理延迟挑战,这限制了它们的实际应用与部署。为此,华为提出了 盘古 Embedded,一个在昇腾(Ascend)NPU 上开发的高效大语言模型推理器。
其核心是一个具备“快思慢想”(fast and slow thinking)能力的双系统框架。该框架通过一个用于常规请求的“快思考”模式和一个用于复杂推理的“慢思考”模式,在延迟和推理深度之间实现了精妙的平衡。此外,模型具备元认知能力,能够根据任务复杂度自动选择最优模式。我们通过一个创新的两阶段训练框架构建此模型,该框架融合了迭代蒸馏、模型合并以及由多源自适应奖励系统(MARS)引导的强化学习。
基于该双系统框架,华为构建了 盘古 Embedded 7B 模型,并在昇腾 NPU 平台上进行了深度系统优化。该模型在单一、统一的架构内实现了快速响应和高质量推理的灵活切换。
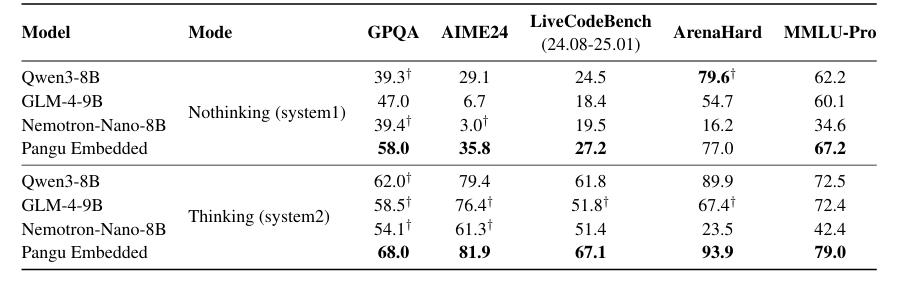
华为的研究表明,仅有 70 亿参数的盘古 Embedded 在多个权威的复杂推理基准测试中(如 AIME, GPQA 等),其表现优于 Qwen3-8B 和 GLM4-9B 等规模相近的业界领先模型。
参考链接:
https://arxiv.org/pdf/2505.22375
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。




