

6 月 21 日,由北京智源人工智能研究院主办的 2020 北京智源大会正式开幕(直播入口: https://2020.baai.ac.cn ),大会为期四天,各主题论坛和分论坛将围绕如何构建多学科开放协同的创新体系、如何推进人工智能与经济社会发展深度融合、如何建立人工智能安全可控的治理体系、如何与各国携手开展重大共性挑战的研究与合作等一系列当下最受关注的问题进行交流和探讨。
在智源大会第四天(6 月 24 日) 下午的全体上,香港科技大学教授、微众银行 CAIO 杨强进行了题为《AI 的新三定律: 隐私、安全和可解释性》的演讲,探讨了 AI 在隐私、安全及可解释性方面的一些研究和进展,以及联邦学习在其中可以起到什么作用。
以下内容根据杨强的演讲整理,未经本人确认。
机器人三定律与 AI“新三定律”
杨强教授首先谈到了“阿西莫夫三定律”。

他认为,虽然人们畅想的 AI 是全无人的 AI,但是 AI 的发展离不开人,AI 要有一些规则,要有与阿西莫夫有不一样的地方。

比如,AI 的运算结果要解释给人类用户,但是 AlphaGo 不是这样的,它无法解释下每一步棋的原因;同时,AI 运行的问题要人类工程师能够 debug;另外,AI 流程需要人类监管。
这些确实是目前 AI 面临的一些挑战,因此,本着为人类服务的原则,AI 的发展需要新的定律,杨强教授将它称为“新三定律”。
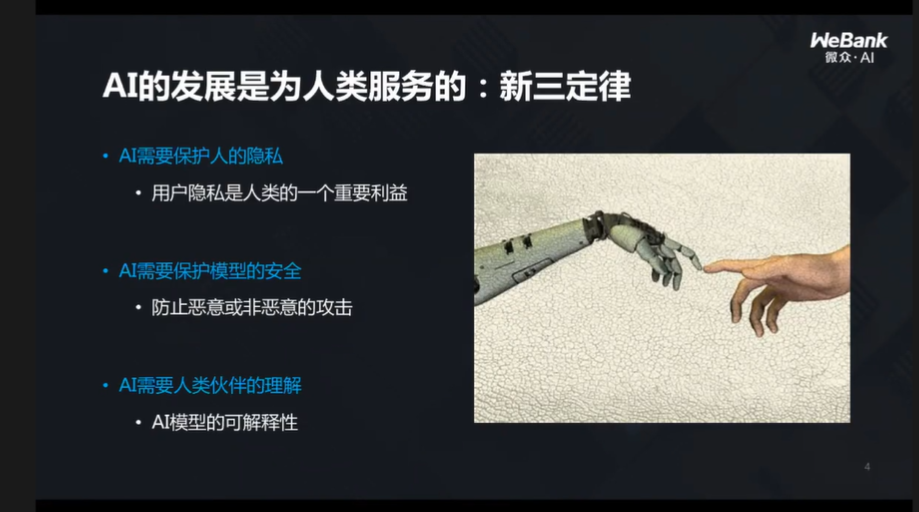
随后他分别对每一条定律进行了详细地解释。
定律 1:AI 要保护人类隐私

杨强教授说,AI 的力量来自大数据,但是更多时候,人们接触到的都是小数据。比如,在金融场景下,洗钱的数据跟非洗钱相比是很小的数据,在第四范式的金融实践中,研究人员也发现:小额贷款的样本数据远远大于大额贷款的样本数据。这对于 AI 来说是一项不小的挑战。

科幻小说、电影里,观众与读者能够看到的机器人、机器设备很多都是端计算,广义的机器人看到的景象只是反映了一个角度,只有把所有的角度聚合起来,才能有全面的数据。但是,在聚合的过程中,涉及到收集的问题,对每一个终端来说,它能收集的数据是有限的,因此,是不是可以把多个终端的数据聚合起来?
这虽然是一个很好的想法,但是近年来,随着各国相关政策法规的出现,使得数据的聚合不能那么直接与轻松。例如欧盟颁布的 GDPR:

该项规定要求:当数据用于某一目的时,就不可用于另一目的。也正是在各种政策法规的影响下,科技巨头们纷纷受到罚款。
而国内的情况也在逐渐趋于严格:
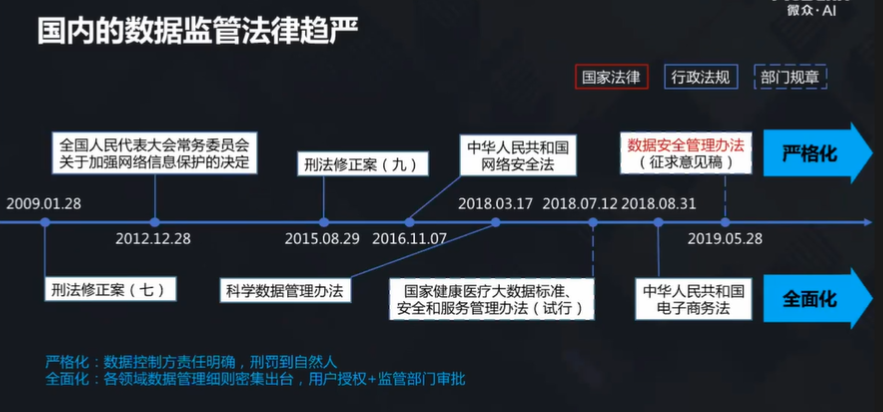
杨强教授说,法规的通用化、多样化虽然保护了用户的隐私,但也在一定程度上造成了人工智能出现了一种理想与现实的隔离。

实际上,人们目前面对的并非是海量的聚合数据,而是各种数据的孤岛,孤岛之间没有桥梁,也就没法让数据聚合起来。
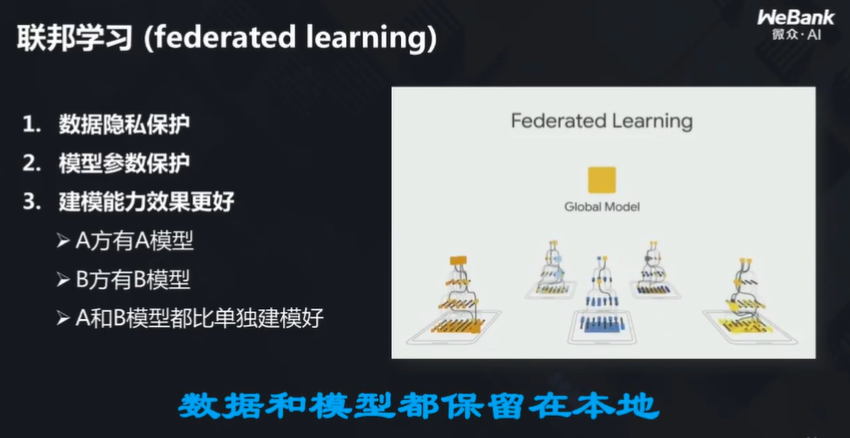
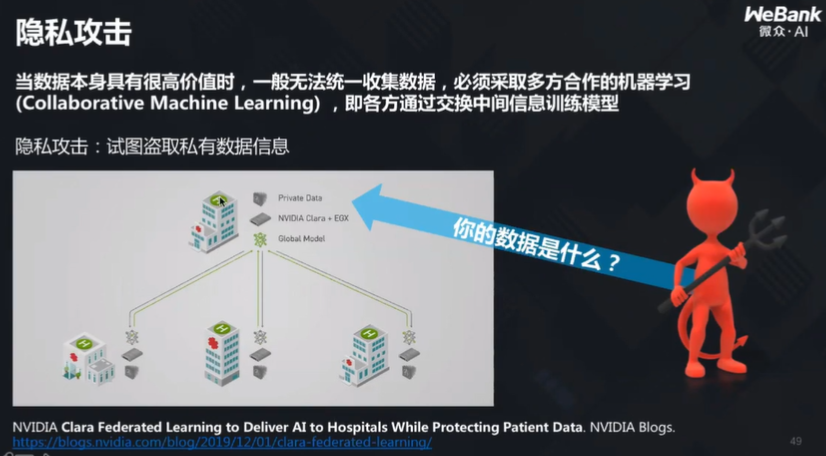
为了解决这样的问题,企业与研究机构提出了各种各样的解决方案,其中一个叫联邦学习。
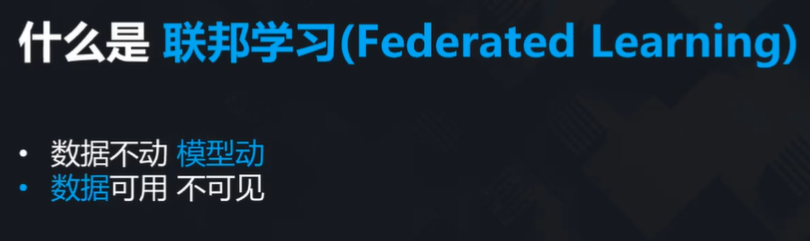
杨强教授介绍说,联邦学习的主要思想是:数据保持原地不动,模型通过加密情况下的沟通得到成长。
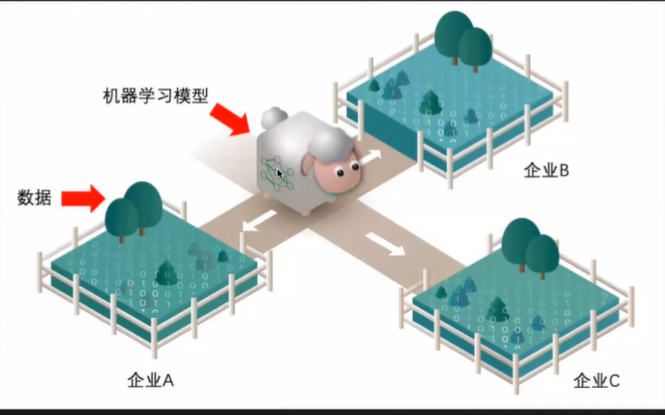
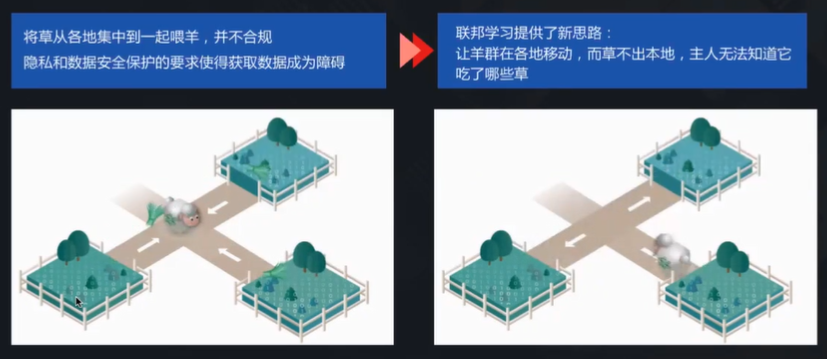
他随后通过一个形象的比喻解释了联邦学习的思路:如果将机器学习模型比作绵羊,企业比作羊圈,而数据是羊圈里的草料,过去的方法就是企业把草料集中到一处喂给绵羊,但是在这种情况下,隐私与数据安全就没有办法保证。
联邦学习提供的思路则是:让羊群在各个羊圈移动,而草不必从本地运出,谁也不知道羊吃了哪些草,羊也可以在一天一天强壮、成长。不同企业的数据隐私都可以得到保护,模型也得到了训练。
顺着联邦学习的思路,杨强教授讲到了联邦学习的两大问题:横向联邦学习与纵向联邦学习。
横向联邦学习
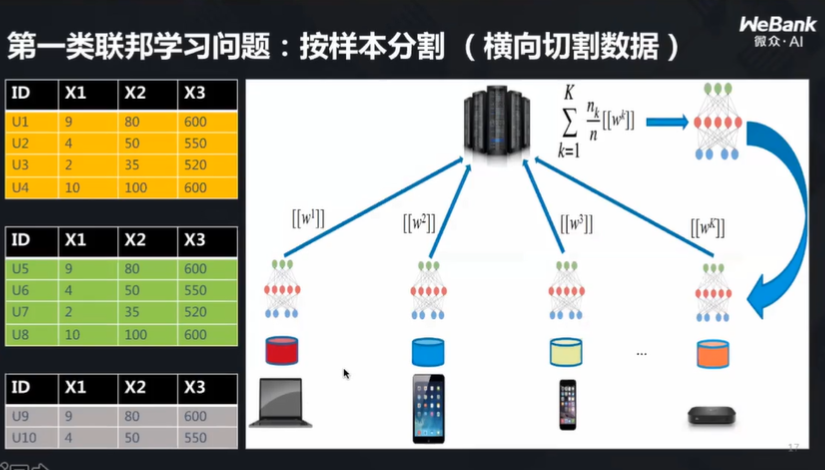
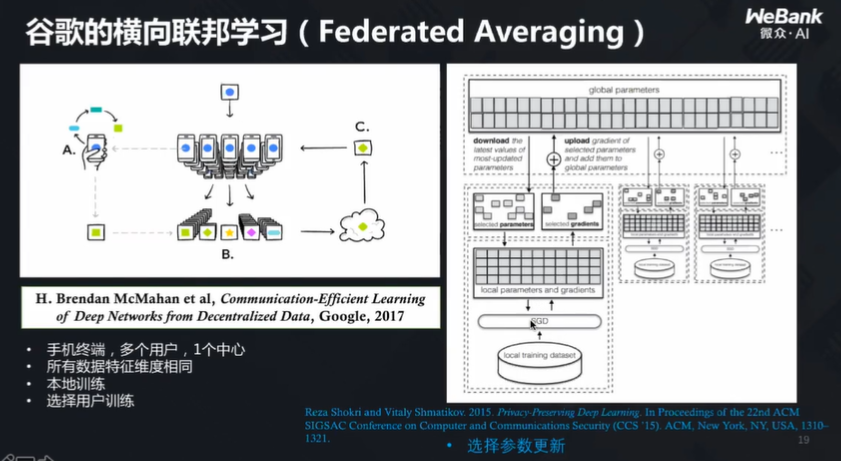
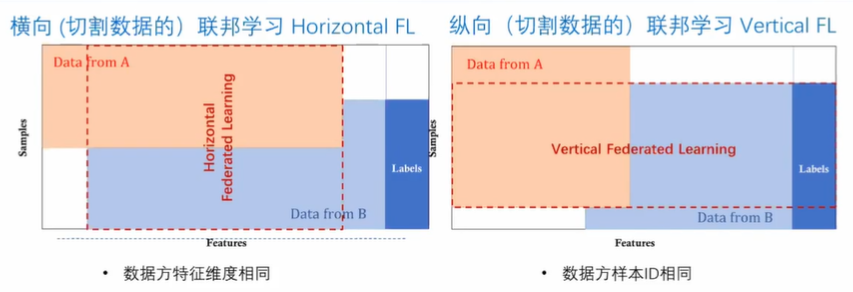
横向联邦学习的特点是:所有终端上的特征差不多,用户却不一样,样本也不一样,即按照样本分割。
在这样的前提下,如何更新模型?谷歌提出了一种方法:联邦平均,即往云端发送的消息里只包含模型参数,这些参数是受到加密保护的。当所有参数在云端得到了更新,求出一个平均值,并将更新后的模型下发到各个终端,使得每个模型得到更新,这样谁的隐私都不被泄露,模型也得到了更新。
纵向联邦学习
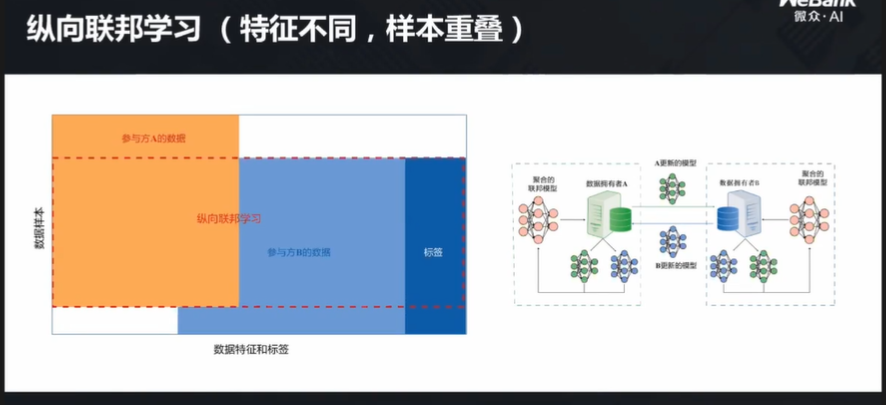
与横向联邦学习有所不同,纵向联邦学习的样本重合,但是特征不重叠。
举例来说,比如某银行有的是金融数据,而某互联网企业有的是用户行为数据,由于政策法规,这两个机构之间的数据不允许互传,但是他们可以建一个大表,将数据放入并进行切割,从而得到两边都可以使用的模型。
联邦学习和迁移学习
随后,杨强教授提到了联邦学习与迁移学习直接的相互协作。
迁移学习是指:当某模型在一个领域已经很成熟了,但是新的目标领域数据有限、模型不够好,且与原领域有相似性,那么就有希望把知识从原领域迁移到目标领域,以达到优化等目的,类似人们常说的“举一反三”。
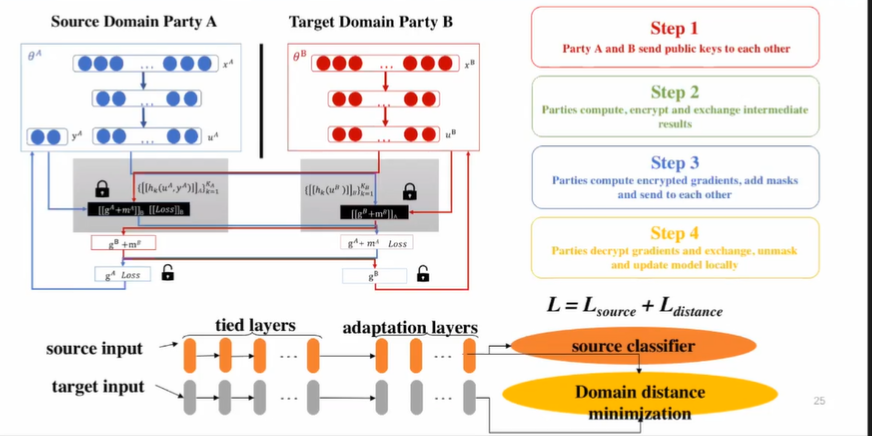
但是问题也出现了:如果参数、数据互相保密,能否继续迁移学习?或者数据的格式不一样,需要异构协作,在这样的前提下,又该如何进行联邦学习?
联邦迁移学习就是这样诞生的。
可是,新的问题又出现了:如果利用迁移学习的思想协助联邦学习,那么会有一个问题:速度将大大减慢,效率也会随之下降。
杨强教授介绍到,为了解决这一问题,目前研究人员们想出了三种解决方案:
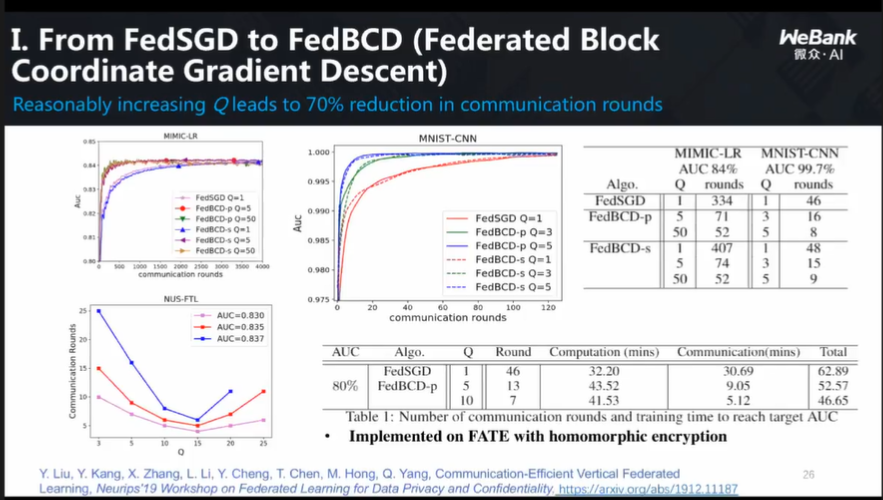
第一种:尽量减少沟通次数,让一次沟通发挥最大作用,尽可能在本地进行多次运转,并且在设计算法的时候,尽量让沟通并行化。如此一来,速度、效率都能有所提升,同时成本也有所降低;
第二种:引入比较精密、高端的加密算法,把梯度值变成向量运算,效率也会提高;
第三种:采用新的加密手段、新的算法,让速度大幅度的提升。

上述做法也帮助工业界解决了一些难题,同时随着联邦学习的发展,一些与之相关的数据集也出现了:

杨强教授表示,除了上述进展,联邦学习的国际标准也很快会出台。
定律 2:AI 要保护模型安全
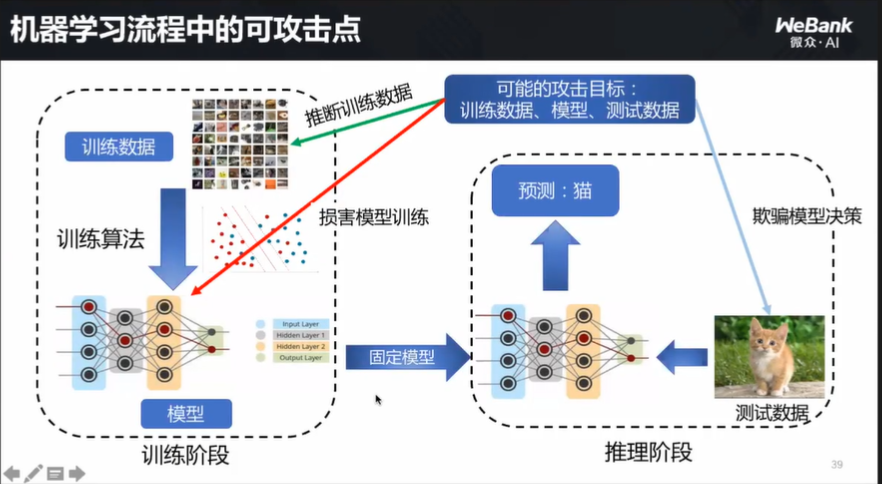
模型在什么情况下不安全?杨强教授认为,有三个薄弱环节要引起重视:训练数据本身、模型攻击以及测试数据作假。
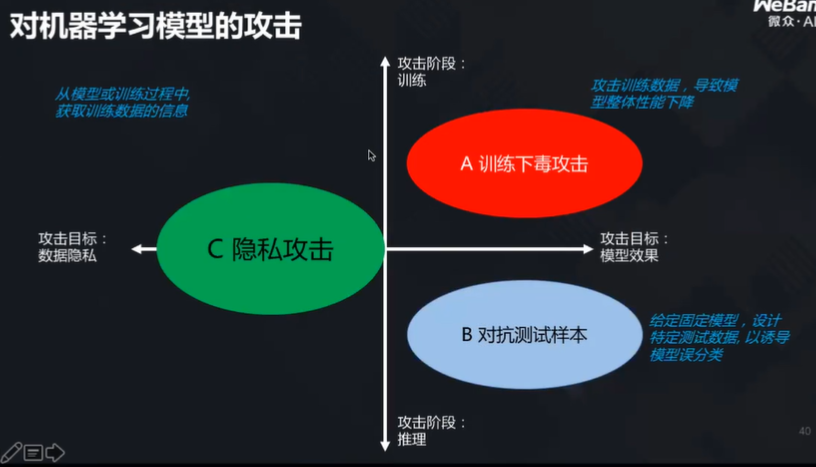
对训练数据的下毒攻击
杨强教授以案例来说明:如下图所示,右侧路牌上有“stop”字样的黄色像素点,如果对数据进行干扰,则模型在训练的时候无法正确识别对应的标记,最终将导致安全事故的发生。
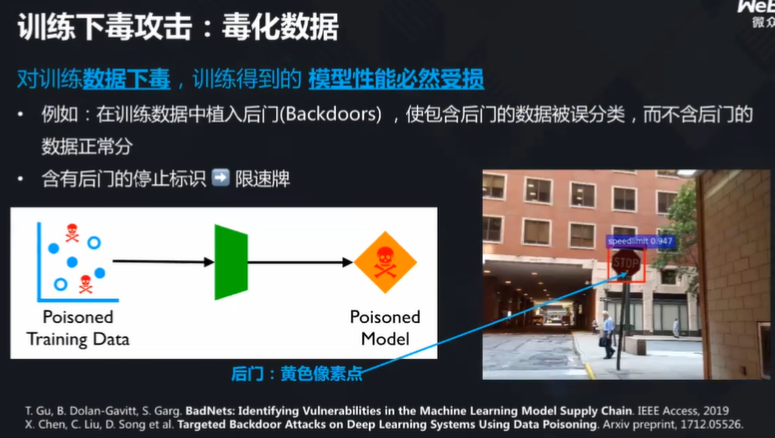
如何防止呢?杨强教授介绍了一种方法:通过对数据进行故意扰动,进而观测其变化,如果模型输出分类出现了大幅变化,则不存在后门;但如果可以直接输出,那就证明数据被“下毒”了。

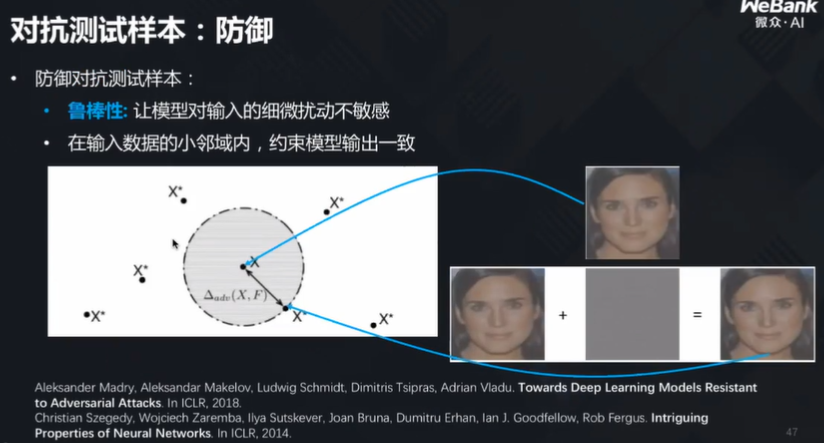
测试样本模型攻击

对抗样本分析大概可以这样理解:原本某人无法通过人脸识别系统验证,但是测试数据里加入了一些噪音,就可以让其通过验证。
防御方法如下:
隐私攻击
最后一种隐私攻击也是近年来比较常见的攻击方式,攻击者通过模型参数,能够反推出原始数据,进而得到相关信息。
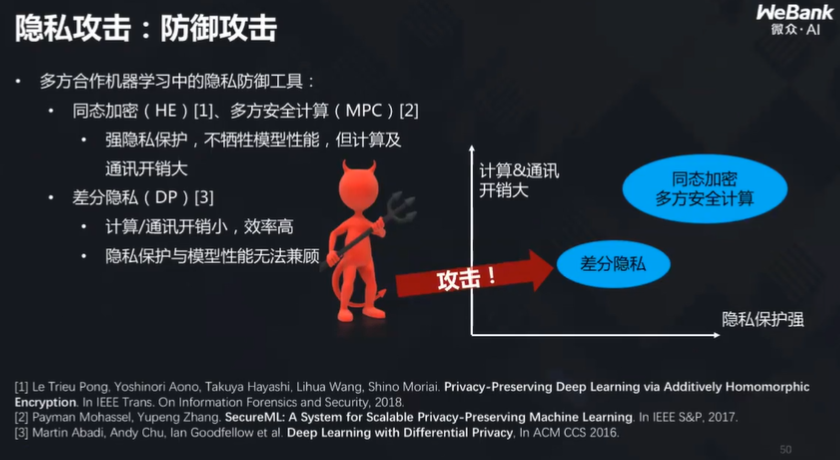
对付隐私攻击,常用的方法有同态加密与差分隐私。但是,同态加密实施难度比较大,因为其计算通讯开销大;虽然可以用差分隐私代替以提升效率,但是其保护性又比较低,如果使用差分隐私加密,则攻击者仍然可以重构原始数据。

比如,MIT 韩松教授团队设计出深度泄露攻击,针对差分隐私的防御,对训练数据进行了像素级别的提取,差分隐私法很难对这样的攻击进行防御:
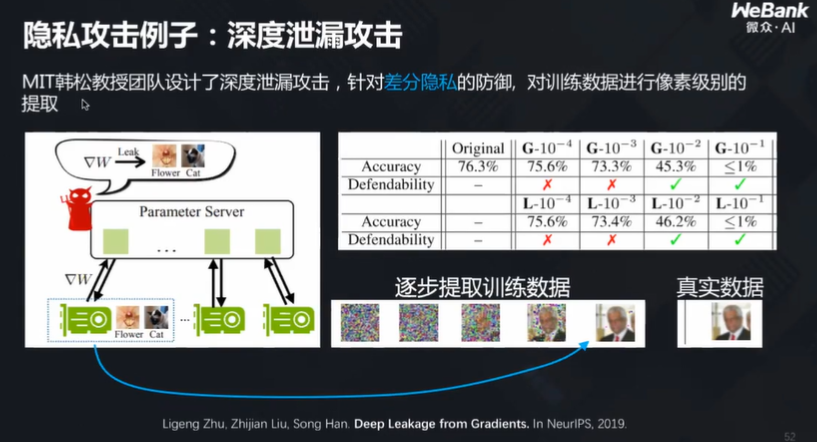
而微众银行团队则通过一系列尝试,从理论上证明了可以在不影响模型效果的同时,完全防御深度泄露攻击:

定律 3:AI 要对人类解释自己

杨强教授表示,AI 要可解释,不仅要让人明白在它做什么,更要让不同的人明白它在做什么。
比如风险评估系统,就要对不同的人做不同的解释,对银监机构、对普通用户等等不同人群都要有合理的解释。
他介绍到,目前主要的可解释方法与关系有如下几种:
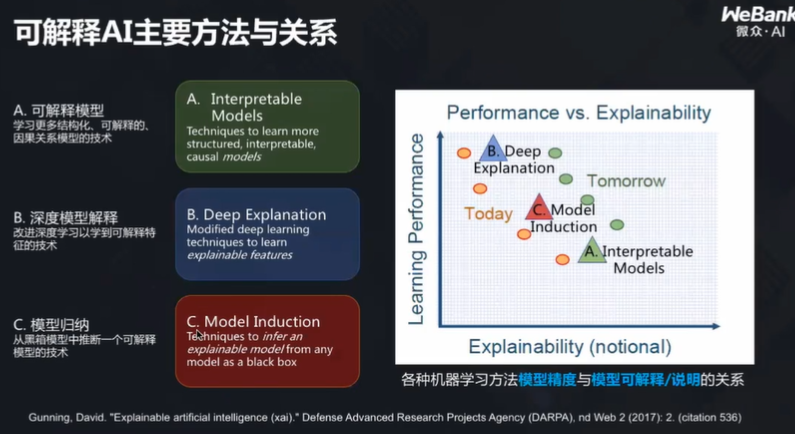
可解释模型

从上图可以看出,不同的模型各有优缺点,一句话来概括就是:没有一个模型机能高效又能高度可解释。
深度模型的解释
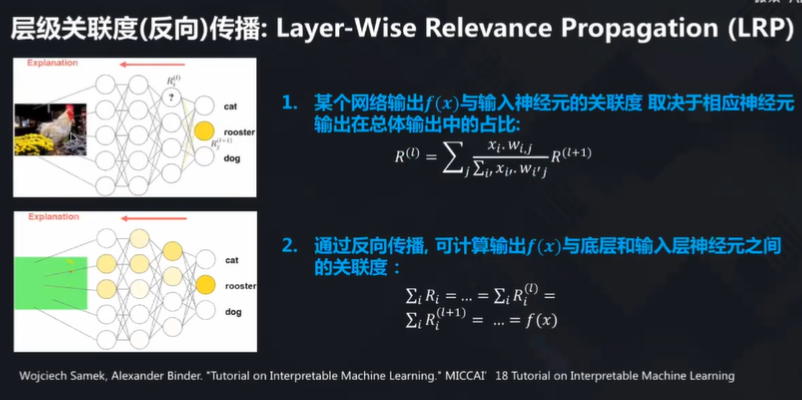
杨强教授在这一段举例进行说明:从上图看,如何知道哪些像素是可以解释这张图上的动物是一个公鸡的?在模型里又是如何找到高度适配的像素?通过反向传播的方法,可以解决相关的问题(当然不只有一种方法)。
模型归纳

左图中,如何解释模型将哈士奇识别成狼?通过模型无关的局部解释,可以发现是因为背景雪地的缘故,才使得模型出现了误判的情况。

最后,杨强教授也介绍称,目前 IEEE 已经新成立一个标准组,用来提供和促进可解释 AI 技术的普及与落地,并着力推进面向业界的机器学习可解释标准。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


InfoQ编辑

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论