

本文是本系列文章的第二部分,将介绍我们的 NLP 即服务系统 HAL 的架构。要想大概了解我们构建该系统的动机和应用示例,请阅读第一部分。
系统架构
第一部分已经讨论过,HAL 用于为 Condé Nast 各个品牌的用例和应用程序赋能,从推荐系统与参与度到受众定位、数据产品和编辑类产品。
为了处理这些不同的用例,我们需要一个能够组合分析并引入新的分析器的系统。该系统应该能够将分析器在不同的用例中重用,还要提供灵活、抽象的输出和处理流。为了实现这种灵活性以及分析重用,我们不仅将 HAL 设计成了一个内容分析处理框架,还将其设计成了一套使用预训练或自定义训练模型的 in-JVM 和 out-of-JVM 分析器。
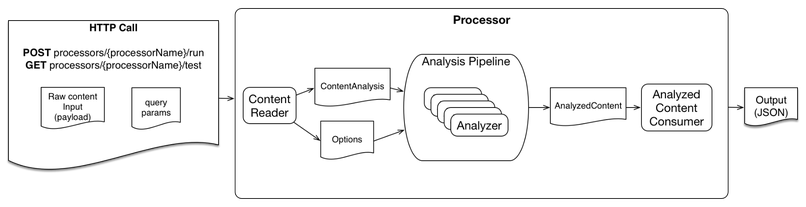
HAL 处理流程高级视图
HAL 的接口是一个简单的 HTTP 服务——希望提取特性的消费者通过路由将负载直接 POST 到一个指定的 Processor 。该 Processor 对象会直接映射到相关路由。Processor 定义了一个 ProcessorEngine 实例,通过类构建器的连贯接口(fluent interface)。
下面是 Processor 其中一个实现的示例——该实现用于处理来自 Copilot(Condé Nast 专有 CMS)的内容。
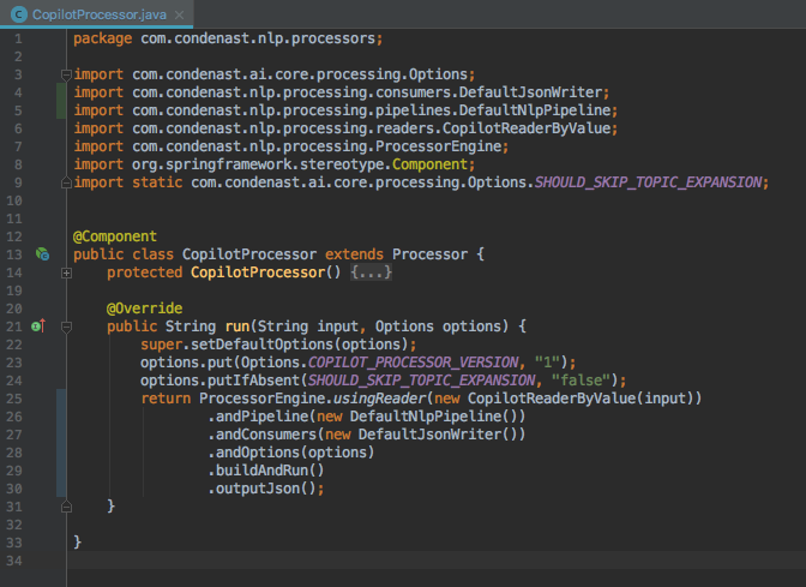
CopilotProcessor 类
ProcessorEngine 实例搭配使用三个实现了以下接口的对象:
内容读取器:负责将输入请求的格式转换成标准化的 ContentAnalysis 对象,该对象即所有分析器将要标注的文档对象。不同的实现允许读取不同种类的输入,例如普通文本、Copilot 内容 JSON 或 URL。该接口实现了抽象化的目标,将不同的输入映射到了标准化的 ContentAnalysis 对象,其中包含供所有分析器使用的映射地图。
分析管道:负责定义有向无环图处理流,编排多个分析器。针对不同的用途和用例,我们有不同类型的管道。所有管道的输出都是一个 AnalyzedContent 对象,该对象是不同用例的标准化输出对象,类似 ContentAnalysis 表示标准化输入。分析管道接口实现了抽象化不同处理流的目标,重用分析器,为不同用例提供一个标准化的知识表示对象,即 AnalyzedContent。
分析结果消费者:将 AnalyzedContent 转换成响应格式。该接口实现了为不同用例提供不同输出格式的抽象化目标。对于绝大多数用例,我们使用 AnalyzedContent 的一种默认的 JSON 语义表示,它在各种媒体类型间都保持一致。下文提取出的特征一节里提供了 JSON 表示的示例。
标注和分析器
上文已经提到,分析管道基于 Java 8 CompletableFuture实现了一个简单的 in-JVM、可并行的有向无环图流。节点会交换代表已标注文档的 ContentAnalysis 对象。每个标准器都可以消费 ContentAnalysis,以及向 ContentAnalysis 贡献标注。基于标注的模型在GATE、Apache UIMA、Stanford CoreNLP等自然语言处理库和框架中非常常见。
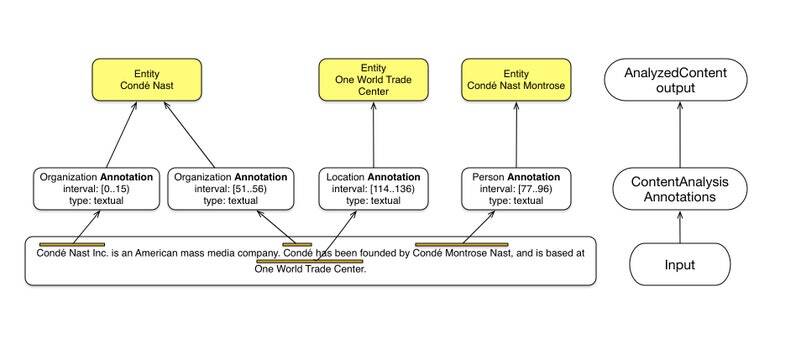
标注模型示例
内容读取器将输入转换成 ContentAnalysis 对象,不同格式和模式的输入数据(JSON、HTML、普通文本等)都采用同样的方式标注。
接下来,每个分析器都可以消费和生成标注。在上面这个简单的例子里,文本中不同类型的命名实体都使用文本偏移量标注了出来。最后生成的 AnalyzedContent 输出,将不同的提及(mention)聚合成了文档中提取出的推断知识。
每条标注是对文档的一个说明,如:
文档 XYZ 中从 0 到 15 的文本表示组织
标注也可以是文档层面的,比如在主题提取时:
文档 XYZ 的主题是商业
每个分析器都可以消费前述标注,作为其模型的输入。该模型可以创建其他标注,并把他们添加到 ContentAnalysis 对象。
然后下游分析器就可以消费那些新生成的标注作为输入,以此类推。
语言知识金字塔
这个过程类似于语言知识金字塔,层次较低的抽象构成了层次较高的抽象的输入知识(标注)。
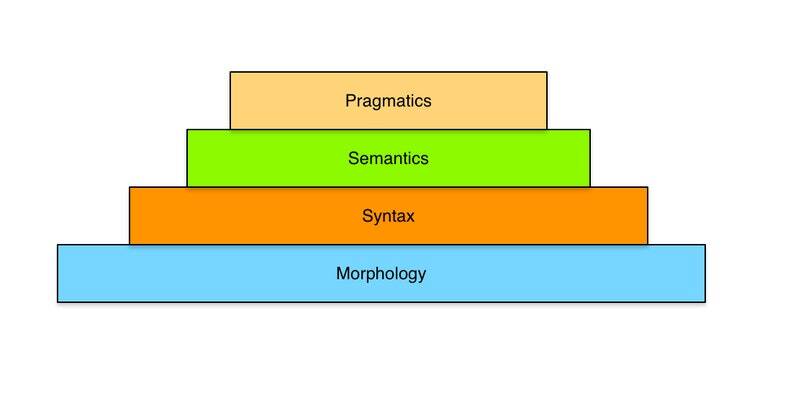
语言知识模型金字塔
从下往上,每一层都有从具体媒体和语言中提取出来的更高层次的抽象。例如,在 Morphological 层,我们关心的是组成句子的词以及词与词之间的关系。这一层与媒体(语音 vs. 文本 vs.图像)和语言(基于字母的语言 vs. 基于象形表意文字的语言)非常接近。举例来说,这一层的分析器有 Tokenizer、Language Identifier、Lemmatizer等。
在 Syntax 层,我们更多关注的是一个句子中词之间的关系,即句子是什么结构的,每个词在其中承担了什么角色。通常,这一层的分析器需要前一层提供的信息,尤其是分词。举例来说,这一层的分析器有 Part of Speech Tagger(确定一个词是名词、动词还是限定词,诸如此类) 、Dependency Parser (定义一个句子中词的角色以及词之间的关系,例如,一个词是 Subject 还是 Object,和哪个动词相关联)等。
一旦系统推断出了句法结构,它就可以脱离具体的媒体和语言,开始在语义层面理解句子的“意思”了。前文图中关于不同类型实体的标注(任务、地点、组织等)就是Named Entity分析器的输出示例。通常,这些模型会将前一层中 Part Of Speech Tagger 及其他分析器的输出作为输入。
最后是 Pragmatic 层,这一层试图从整体上理解文本。举例来说,这一层的分析器有Topic建模、Coreference/Anaphora解析、Summarization等。
合而为一
在 HAL 中,分析器之间的标注流是由一个 DAG 流管理的。下面的代码片段是为 DefaultNlpPipeline(适用于我们大部分自然语言处理用例)定义的 DAG 流:

DefaultNlpPipeline 类
下图是上述 DefaultNlpPipeline 代码的 DAG 流表示,以及分析器之间的相关标注:
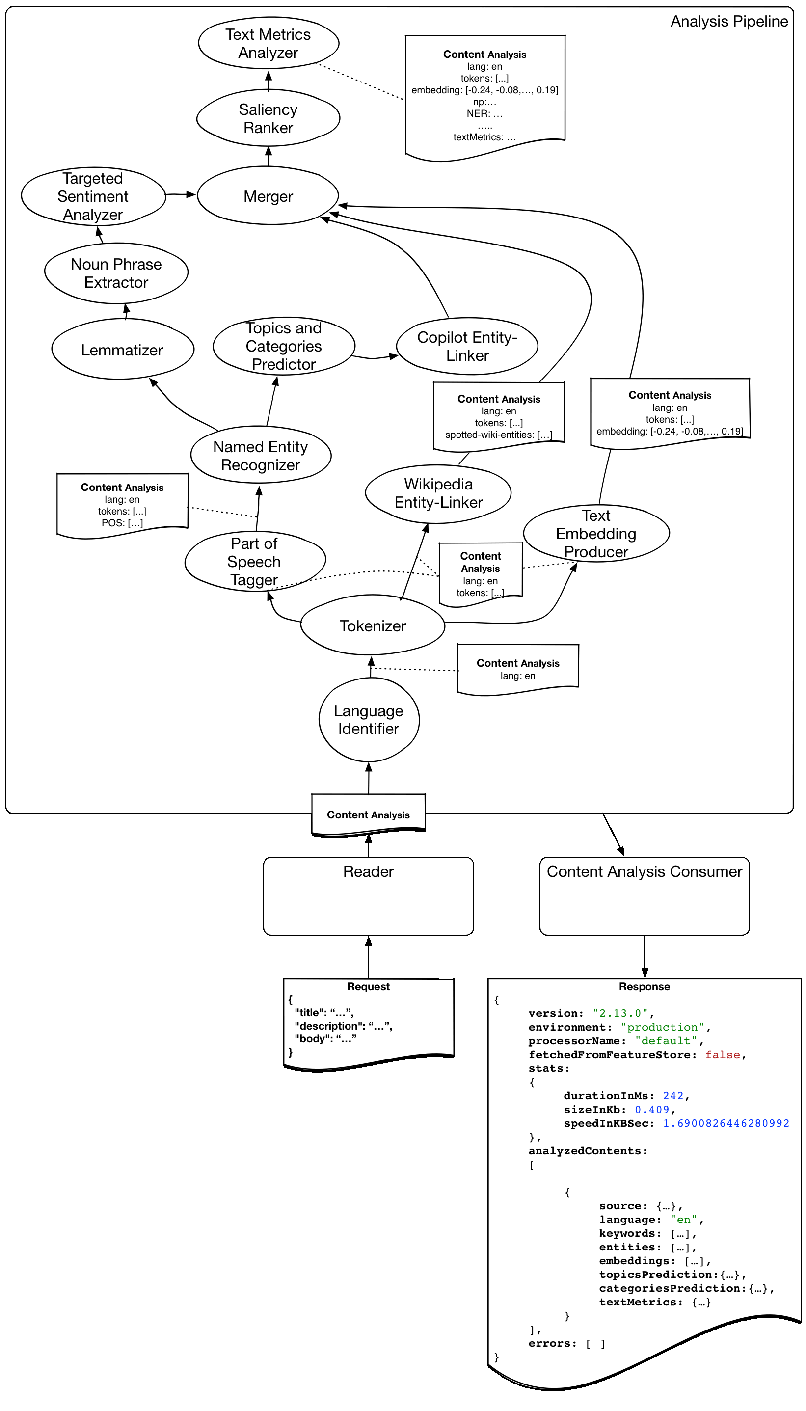
带标注的默认 NLP 管道 DAG 流
图的顶点代表分析器实现,例如 Language Identifier 或 Copilot Entity Linker。边代表 ContentAnalysis 对象状态及其标注在分析器之间传递。正如之前说过的那样,每个分析器都可以消费来自上游分析器的标注,并生成新的标注供下游使用。上图是管道中一个经过简化的边与标注的示例(实际会更多)。
这些分析器有些是在 JVM 中运行,有些是在 JVM 外运行,有些是定制的,有些是使用开源组件或由供应商实现的。不同的流并行运行,然后合并。
规范化标注模型是所有分析器之间的通用语。通过这种方式,我们可以利用不同来源的分析器来增加和丰富分析内容。
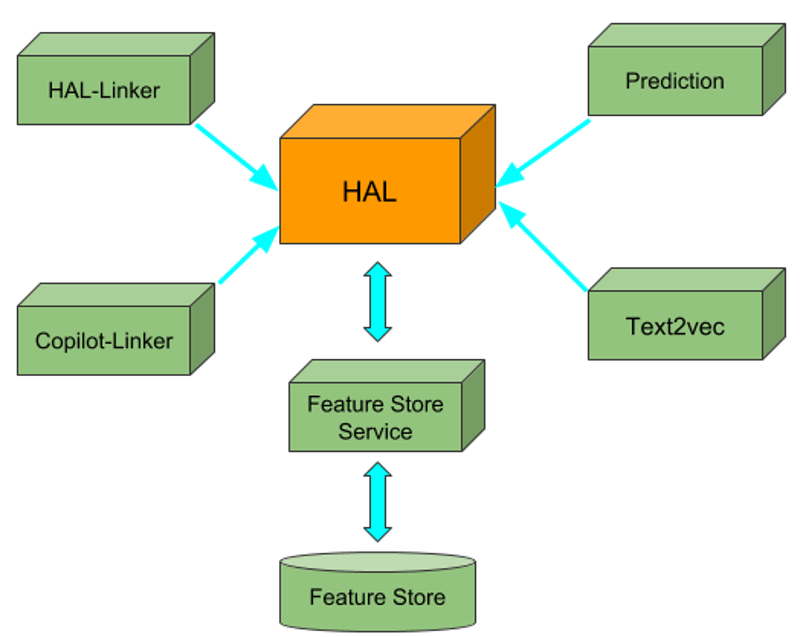
HAL 生态系统
在 HAL 项目开始的时候,其中许多分析器在云服务中并不存在,但 2018 年,我们看到“商品化”自然语言处理服务的爆炸式增长。在确定供应商的服务可以提供更好的质量、更多的特征或更低的成本时,HAL 利用了其中一些现成的分析器。不过,对于某些特征,如果云 API 比较贵或质量不高,抑或是没有这样的云服务,我们仍然会使用自定义模型或开源模型。
提取出的特征
HAL 以不同的方式返回内容分析的输出,通过不同的 AnalyzedContent 消费者实现来支持不同的场景。不过,默认响应(大多数用例都使用这种)是一个包含以下数据的 JSON 文档——注意,以下是英语中可用的特征,其他语言的话,特征可能会少一些:
折叠后的 HAL 输出
language:由标注器 Language Identifier 提取,这是一个 in-JVM 开源模型;
keywords:一个按显著性排名的名词短语列表,由 in-JVM 模型Keywords Extractor 的自定义构建所提取;

提取出的关键词
entities:是一个命名实体列表,如人物、地点或组织,对于英语和德语,我们使用了一个开源的 in-JVM 分析器,对于其他语言,则使用供应商的服务;

提取出的实体
linkedData:提取出的实体和短语最终通过两个不同的实体链接器链接到两个特定的知识库,链接数据使用了schema.org JSON-LD格式:
Copilot-Linker:自定义的 out-of-JVM 分析器,可以链接到我们内部的 CMS 系统 Copilot,这也是一个由我们的编辑录入的知识库。Copilot 不仅可以对文章、相册或典型的内容类型进行建模,还可以对人物、餐厅、主题以及其他许多基于实体的内容类型及其关系进行建模。Copilot-linker 可以用于本系列文章第一部分的“自动链接”用例。
Wiki-linker:开源 out-of-JVM 分析器,可以链接到维基百科的文章。如下所示,Person 实体类型使用 JSON-LD schema.org 语义模式既链接到了维基百科,也链接到了 Copilot 知识库:

关联实体
topicsPrediction 和 categoriesPrediction:这是一个 out-of-JVM 分析器,使用我们内部的 Prediction API(使用我们自定义构建的 LDA Topic Models)来预测文章主题。主题广泛应用于下游数据产品、回流产品、报表以及一些试验性搜索流量预测模型。
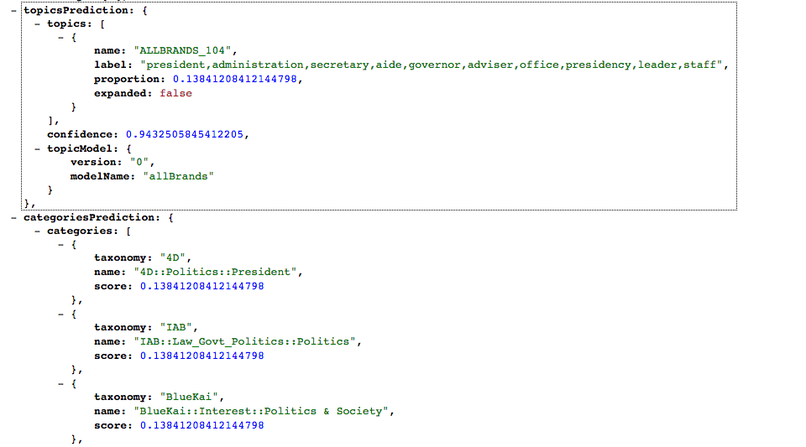
LDA 主题
embeddings:内容的数值向量表示,用于计算内容相似度,从而实现推荐或受众定位的目的。我们有一个自定义的 out-of-JVM 分析器和模型负责计算向量并生成特征。它使用doc2vec算法来生成向量,该算法是由DeepLearning4j 库提供的。
文本嵌入
textMetrics: 关于文本的句法和语法指标,由自定义的 in-JVM 分析器计算生成。

文本指标
在构建这个 HAL 默认的 JSON 响应时,我们试图建立一个多模态知识表示模型,从而达到将内容分析输出模型用于不同用例、内容类型和分析类型的目的。
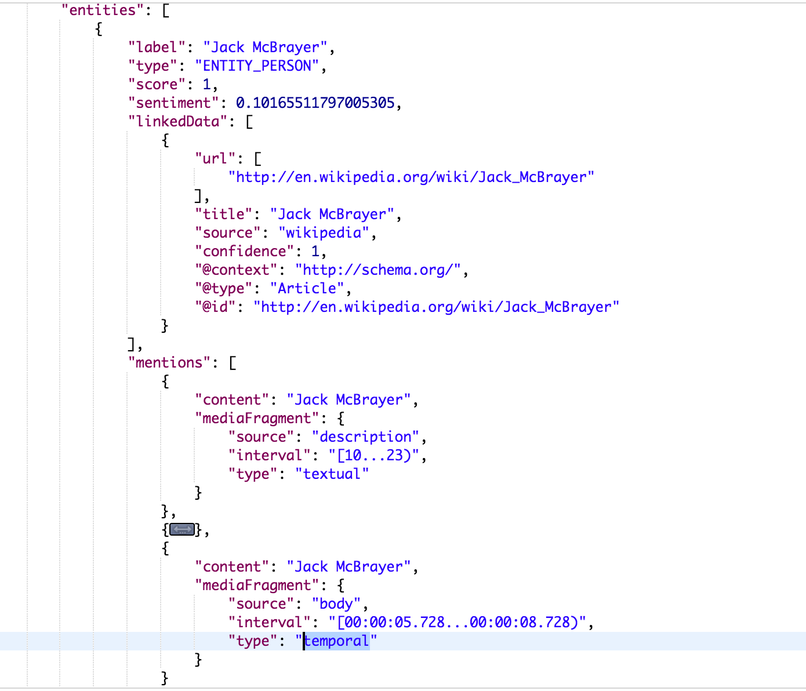
多模态实体提取
让我们用一个例子来说明下多模态分析表示。有一个实体 Jack McBrayer,我们通过 speech-to-text 组件从音频片段中识别到了,从文本片段中也识别到了。type: textual interval 使用文本跨度偏移量来标记在文本中被提及的位置,而 type: temporal interval 使用时间跨度来标记实体在音频中被提及的位置。
HAL 聚合分析器会将上述信息整合到一个实体中,生成的 JSON 对象包含上述所有“提及”,并独立于媒体源,通过维基链接器链接到维基百科知识库条目。除了文本和音频外,我们将在内容管理系统的下一个版本中通过 type: spatial interval 使用边界框来引用实体、主题及其他特征在图像中的提及。通过这种方式,系统将更接近于消费包含多种媒体类型的内容时真实的用户体验。
特征库
受Uber关于Michelangelo的博文启发,内容分析输出最近保存到了一个经过策划的存储中。该存储用于保存由不同模型(包括 HAL 分析器)生成的内容、用户和实验的机器学习特征。
特征库服务旨在提供一个统一的、经过策划的持久化特征库,并提供一个可以跨团队使用的、既支持在线也支持离线特征消费的 API。在线的例子如推荐(包括借助Multi-Armed Bandit求解算法自动优化)和二次排序;离线场景如批量分析、报表和新模型训练。
此外,对于没有变化的内容(如发送到 HAL 的请求),特征库可以避免重复的、成本高昂的特征提取,保证新鲜度和完整性。在使用昂贵的计算或外部供应商的分析器提取特征时,存储库的这项能力还特别有助于节省成本。
要了解更多关于存储库服务的信息,请阅读这篇博文。
演进
我们已在计划改进内容分析系统。特别地,我们认为,HAL 及其自然语言处理功能应该成为一个更成熟的内容分析系统的一部分。该系统不仅能够分析内容的文本部分,而且要更贴近用户体验。特别地,新系统应该能够分析用户访问的 URL 中的所有内容,包括图像、文本、视频、相册等,而不仅仅是将其看成一段文本。而且,系统还应该考虑它们在页面和用户消费中的相互关系,并把那种理解综合到一个多模式知识表示中。
内容分析成熟度
可以从以下 3 个维度来评价内容分析的成熟度水平:
内容类型维度:系统能够分析的内容类型数,如图像、视频、文本、音频。为了在这方面有一个快速的提升,我们想利用最近兴起的图像和视频云分析服务。此外,在垂直领域,我们也开始研究自定义的试验性图像分析模型,更多信息请阅读博文:手袋品牌和颜色检测。
含义维度:系统能够理解的内容含义越来越多,不仅是理解更多的语义,举例来说,还有情绪或内容风格的理解。这个成熟度水平评价维度适用于所有内容类型。
整体性维度:从用户的整体体验出发分析内容的能力,因此要考虑用户所消费的内容中包含的文本、图像和视频,以及不同类型的内容在特定布局中的关系。在多媒体文档里,含义往往是嵌入在相互补充的多种形式里。
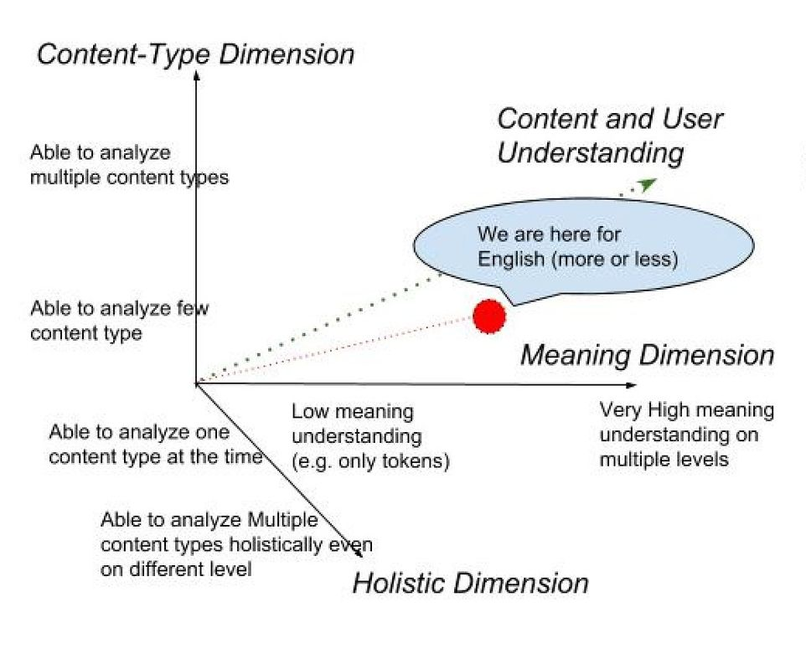
内容分析演进维度
演进后的系统架构应该能够根据用户需求和使用场景单独提升某个维度的成熟度。
多模式知识表示已经就绪,和上面提到过的一样,跨多种内容类型。它应该可以帮助我们定义一致的输出,提升系统的可用性,使下游系统更容易依附于内容特征的共享表示。
在 Condé Nast 构建的这样一个全球性平台上,对于不同的语言,内容分析系统的成熟度水平难免会存在差异。
互操作性的演进
另一个演进方向是与其他系统的互操作性。虽然已经有一个简单的 HTTP API 可以帮助我们将 HAL 快速集成到其他系统中,使其得以推广应用,让其他系统获益,但是,在流或离线场景中,当在多个下游系统中使用时就会变得复杂而低效。
我们正在研究将提取出的特征发布到一个Kafka主题。我们已经将点击流和内容事件发布到 Kafka。除了已提取特征主题外,下游系统将能够集成 Event-Driven API 而不是 Request-Response API 来获取所有主要实体的事件流:上下文、已提取的特征、用户、实验以及它们之间的交互。
小结
在生产中使用软件解决方案的其中一个主要好处是,我们可以更好地理解问题域并获得更多的知识,这反过来又催生了更好的解决方案。这种情况在复杂的软件项目中会经常出现。
Condé Nast 几年前开始开发一个专有内容分析系统,并将其与 Copilot 及底层内容 API、消费者应用程序、Spire(我们的专有用户精准定位平台)集成。现在,不管是消费者角度,还是从编辑和广告商角度,内容分析在传媒行业的应用都让我们对真实的问题领域有了更好的理解。
我们正在努力改善直接从专有内容 API 透明地使用内容分析的能力,以便下游服务可以快速、透明地消费那些智能特性。例如,自动优化、个性化、推荐或内容生成支持。
在 Spire 和数据产品方面,我们正以流和批量方式改进已提取特征的消费,简化数据分析和模型生成。
请继续关注这篇文章中提到的其他主题的更多细节,比如我们开发的自定义分析器、推荐系统和特征库服务。
查看英文原文:Natural Language Processing and Content Analysis at Condé Nast, Part 2: System Architecture

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论