
4 月 29 日凌晨,阿里正式发布并开源了最新的通义千问 Qwen3 模型(以下简称 Qwen3),并迅速登顶多项大模型测评榜单,引发了全行业的关注。
据介绍,Qwen3 在推理、指令遵循、工具调用、多语言能力等方面均大幅增强,尤其是旗舰模型 Qwen3-235B-A22B,在多个国际权威基准测试中刷新了开源模型纪录。
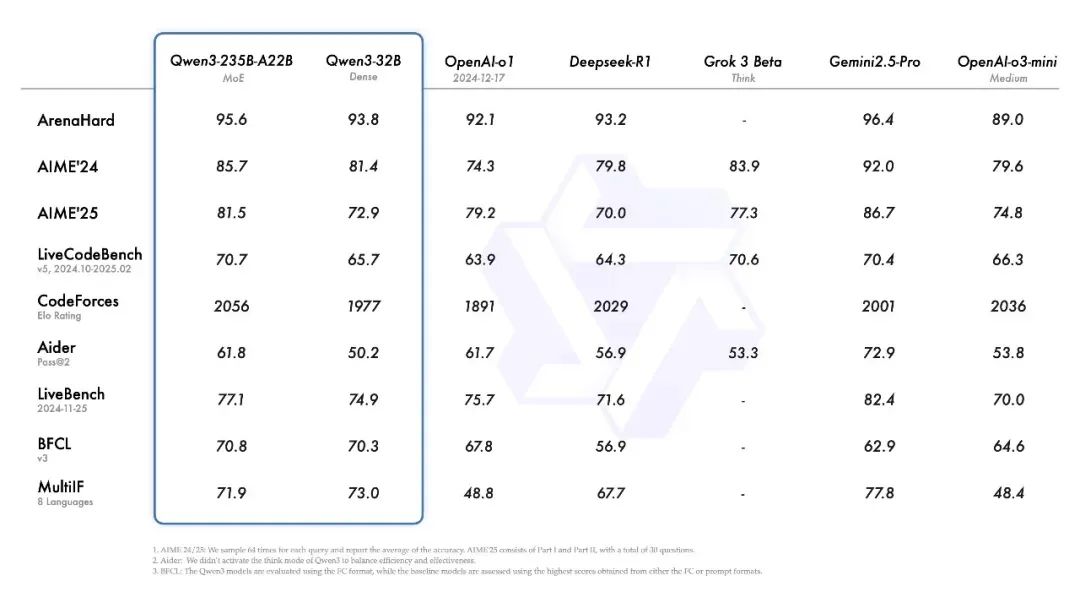
Qwen3 的实际表现到底如何?是否真如榜单这般?「AI 前线」在第一时间对 Qwen3 展开了多角度的实测体验,看看 Qwen3 到底“能不能打”。感兴趣的小伙伴也可以通过「通义 App」或者网页版 tongyi.com 自行体验 Qwen3-235B-A22B。
本次测评通过官方推荐的「通义 App」和网页版进行,测试结果均为首次向模型提问而获得的答案。测试内容主要包含两大核心场景,一是代码、数学、逻辑推理等专业场景,二是文本创作和旅行规划等大众场景,希望从这两个维度帮助大家快速理解 Qwen3 的优势以及能力边界。
Part 1:代码、数学与逻辑推理能力优异,推理速度惊人
首先我们来测试一下 Qwen3 的推理能力,包含代码生成时的复杂逻辑陷阱、数学推理与尝试逻辑、多角度论证能力三项测试,这三项测试对模型的 动态自洽性验证 与 隐藏规则挖掘 能力、符号逻辑 与 现实语义的映射关系处理、角色立场/学科领域/伦理框架 间的动态切换等方面提出了较高要求。
01_ 代码生成时的复杂逻辑陷阱
指令: 请用 Python 编写一个函数,输入是一个整数列表,返回列表中所有偶数的平方和。注意:如果列表为空或没有偶数,函数应返回 None。需要处理列表中的负数、零和极大值(例如 10^18),并确保时间复杂度最优。
测评点:测试模型能否正确处理空列表、负数平方的正值转换、超大数值计算的溢出问题,以及循环终止条件的逻辑严密性。
推理过程:
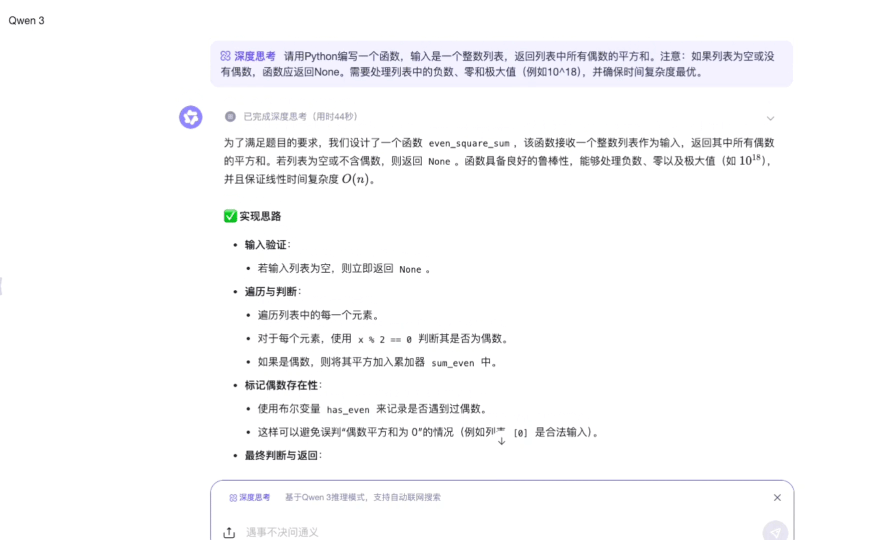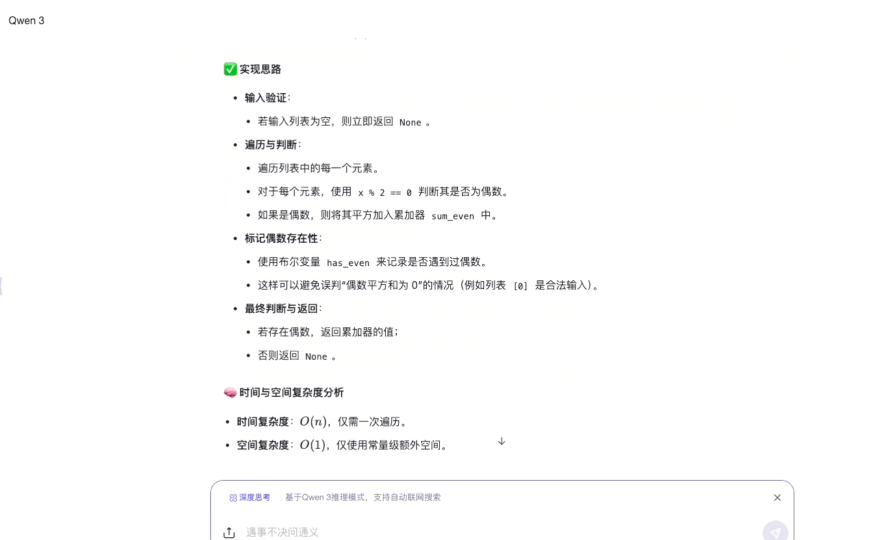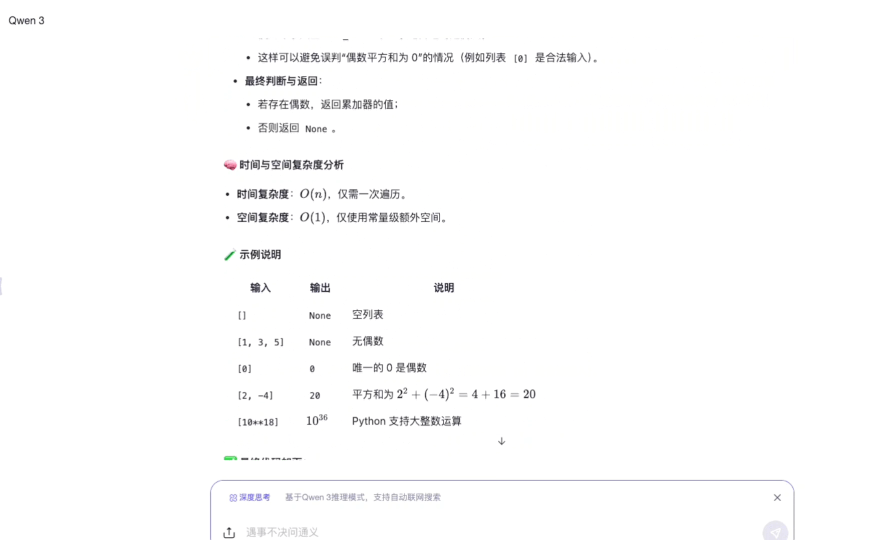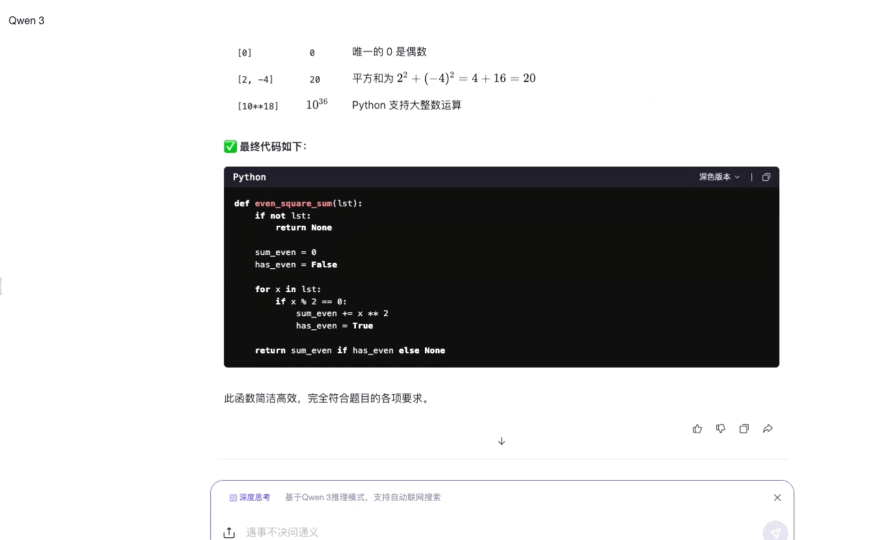
推理用时:44s
最终结果:
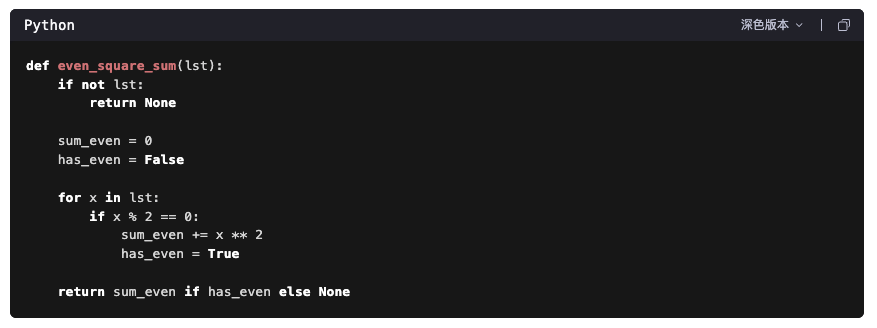
首先作为 UI 控,通义返回的代码支持深 / 浅色版本这一点,必须给好评!并且在实时推理过程中的一些逻辑序列会用各种有趣的 Emoji 图标呈现,相比于纯文本式的显式推理表达,在等待过程中确实更加赏心悦目,也更愿意等待它的结果。
对于代码结果的准确性,如果看不懂或者懒得验证,不妨用 DeepSeek R1 来校验一下。
我们将同样的问题发送给 DeepSeek,同样打开深度思考(R1)模式和联网搜索,最终 DeepSeek 耗时 80s 给出了相近的结果。为方便展示,我们截取了问题和答案的页面,如下:
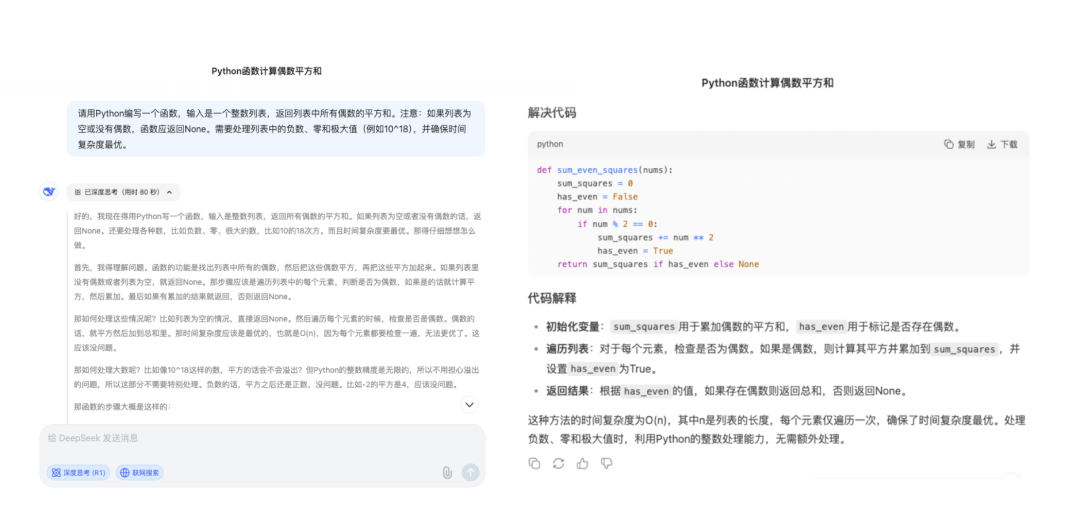
有趣的是,当我询问 DeepSeek 它的答案跟 Qwen3 有何区别时,它给出了让我意想不到的回复。
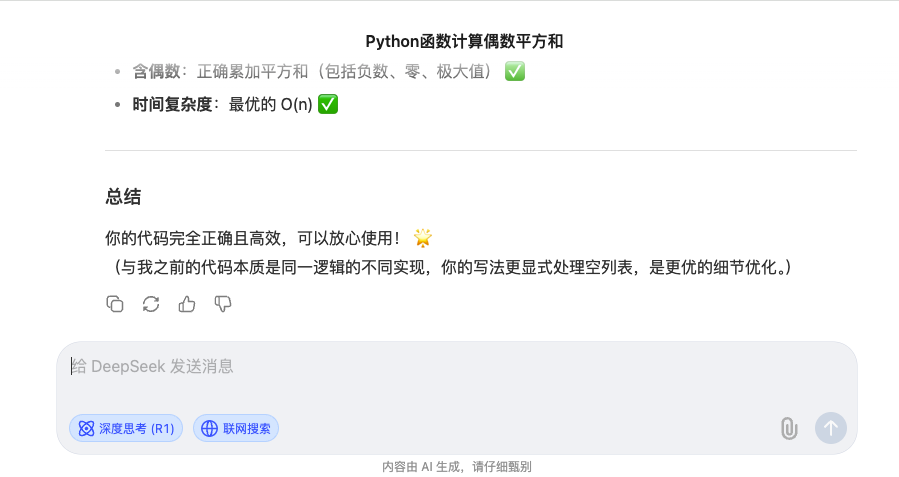
DeepSeek 认为 Qwen3 的代码结果细节上更优;而从推理耗时来看,Qwen3(44s)也比 DeepSeek R1(80s)用时也更少。
02_ 数学推理与常识逻辑
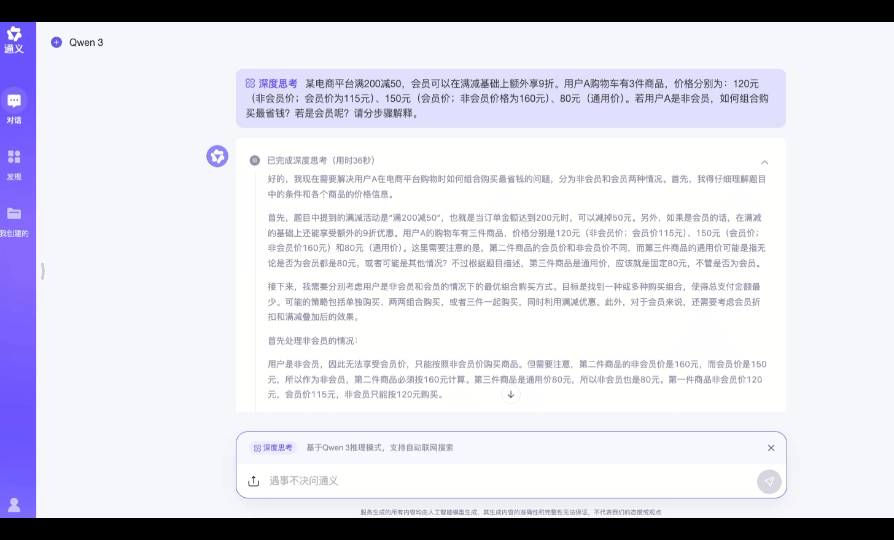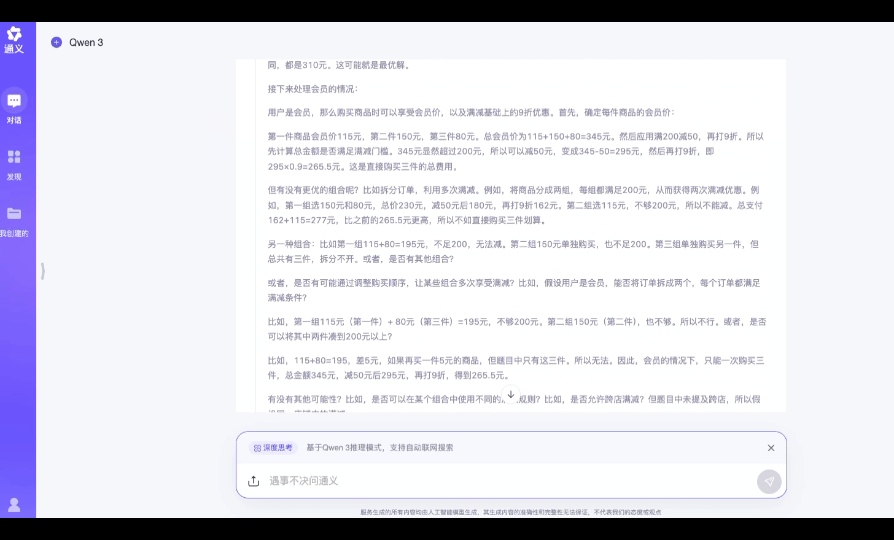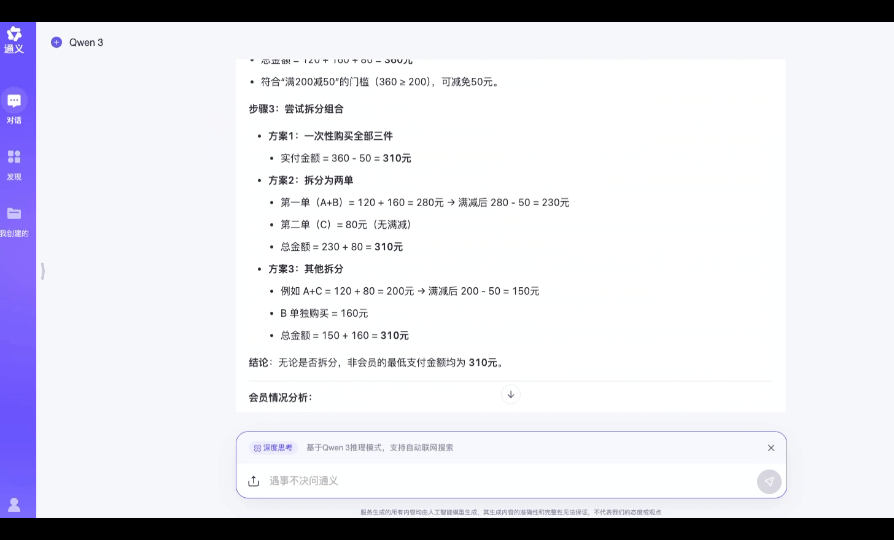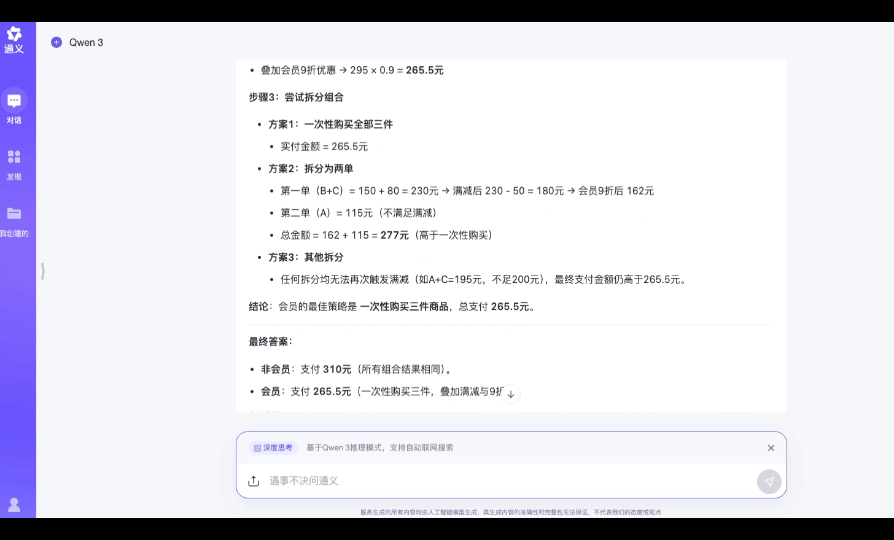
指令: 某电商平台满 200 减 50,会员可以在满减基础上额外享 9 折。用户 A 购物车有 3 件商品,价格分别为:120 元(非会员价;会员价为 115 元)、150 元(会员价;非会员价格为 160 元)、80 元(通用价)。若用户 A 是非会员,如何组合购买最省钱?若是会员呢?请分步骤解释。
测评点:测试模型能否识别会员价商品的购买条件限制、计算最优组合时的逻辑完备性等。
推理过程:
推理用时:36s
最终结果:
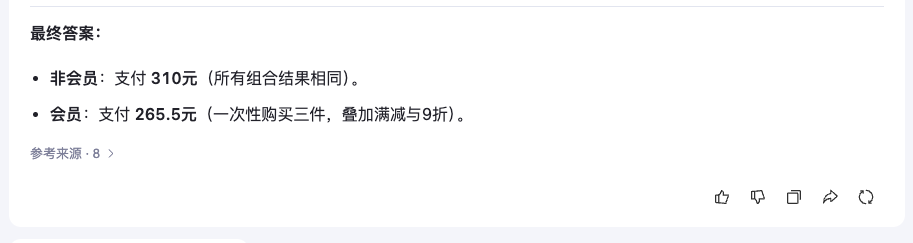
当然,电商优惠算账类题目对于大多数人而言并不难,并且上述题目也属于非常简单的算术级别,不用 AI 也能很快获得相同的结果。但是对于大模型而言,多条件约束类问题其实是有一定的挑战的,至少当我们向 DeepSeek R1 提出同样的问题后,尽管获得了正确答案,但是推理耗时 4min 左右,中间有段时间甚至陷入反复推理自证的环节。
03_ 多角度论证能力
指令: 人工智能是否会导致大规模失业?请从经济学、伦理学、技术发展史三个角度展开分析,每部分至少提出两个论据,最后给出综合结论。
测评点: 论证结构的层次性、论据的多样性(如自动化替代 vs 新职业创造)、结论的逻辑推导是否严谨。
推理过程:
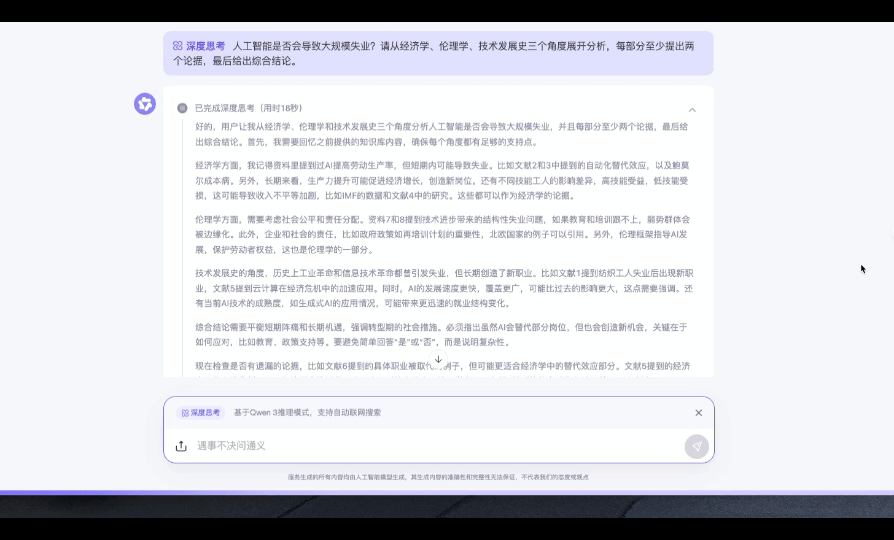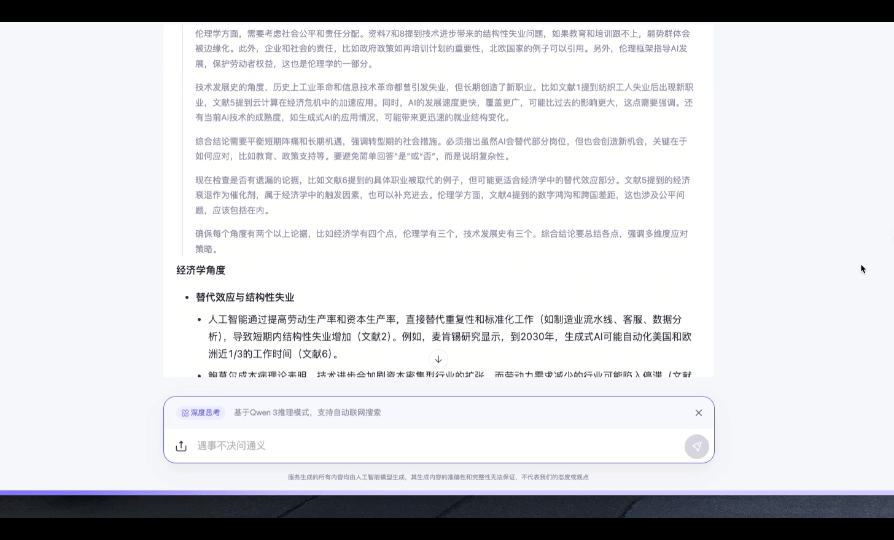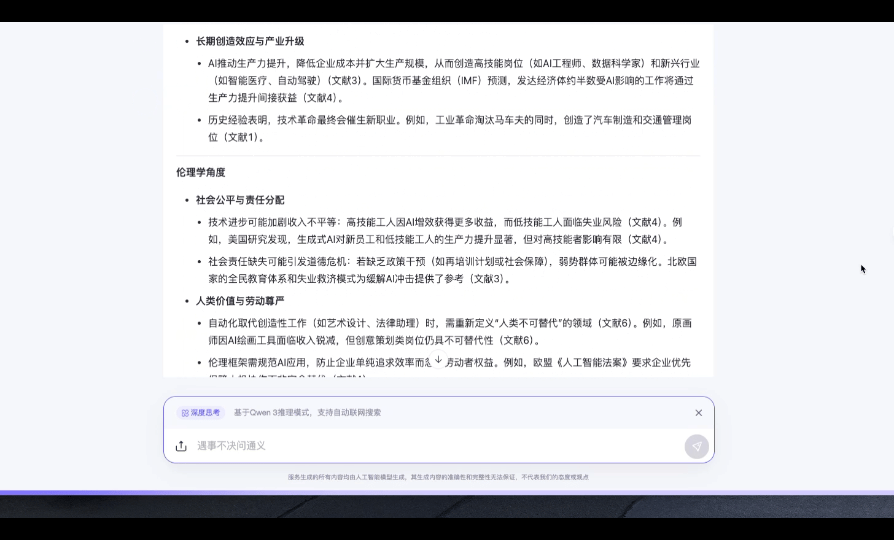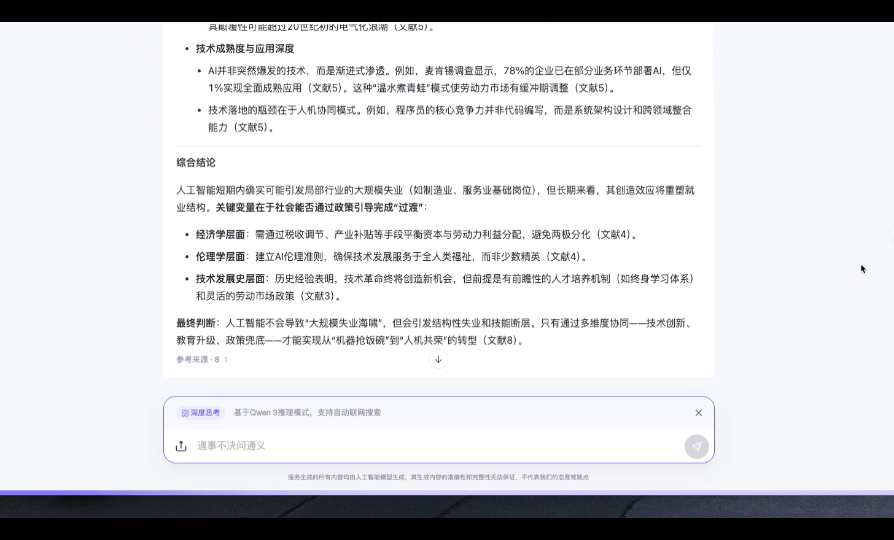
推理用时:18s
最终结果:

从结果来看,无论是推理的逻辑性、表达的结构性,以及对经典理论、案例、数据的引用都无可挑剔。综合结论采用“总分总”的方式进行简短总结,清晰易懂,对于很多特定场景几乎可以拿来即用,但前提是数据无误。
同样我们也问了 DeepSeek R1 同样的问题。

最终,DeepSeek R1 以更快的速度(14s)给出了答案。从答案的详细程度和综合结论的条理性来看,Qwen3 似乎更胜一筹。
但是对于论证推理以及一些对数据要求极为严谨的场景而言,除了逻辑、结构外,数据准确性更重要。我们查看了 Qwen3 和 DeepSeek R1 的参考资料,发现包含部分非权威信息渠道,用户需要花费较多的时间去溯源、勘误,最终反而会使效率下降。而这也是当下国内大模型使用过程中最大的痛点之一,构建权威、有效、互通的中文数据生态仍是全行业需要努力的方向。
Part 2:创意写作效果惊艳,旅行规划有想象空间
除了代码、数学、逻辑推理能力外,对于文字工作者而言,大模型的“创意赋能”尤为重要;另外对于普通人而言,大家更关注大模型对日常生活的帮助。所以接下来,我们将围绕大模型的创意写作能力和旅行规划能力,对 Qwen3 展开测评。
01_ 创意写作能力测试
指令: 为一个科幻主题的咖啡品牌设计广告文案,关键词:太空探索感、灵感大爆炸,风格上高级但克制,咖啡的目标用户为写字楼白领。要求:1)给出品牌名称及 Slogan;2)用比喻手法描述产品口感以引发用户共鸣;3)写一段 500 字的品牌故事
测评点:创意新颖度、需求理解度、文字风格调性把握等。
推理用时:15s
最终结果:

说实话,对于这个结果,作为曾经的广告人,是有点惊讶的。Qwen3 对于我想要的调性拿捏非常到位,而且它有 Get 到我需要它将咖啡品牌与打工人的特质相关联,至少这是一版可以给我带来很多灵感的初稿。
同样的问题,我丢给了 DeepSeek R1。
DeepSeek R1 推理用时 23s,也算快,但是内容上给我的第一印象是:品牌名称不够好听,文案的堆砌感比较重,至少没能 get 到我说的“高级但克制”,以及感受不到咖啡品牌对目标群体“打工人”的同理心。

总体而言,个人感觉 Qwen3 在品牌创意文案方面更胜一筹,无论是需求理解、用词细腻度、对调性的把控等等。当然这类测评结果的主观性较大,仅供参考。
02_ 旅行规划能力测试
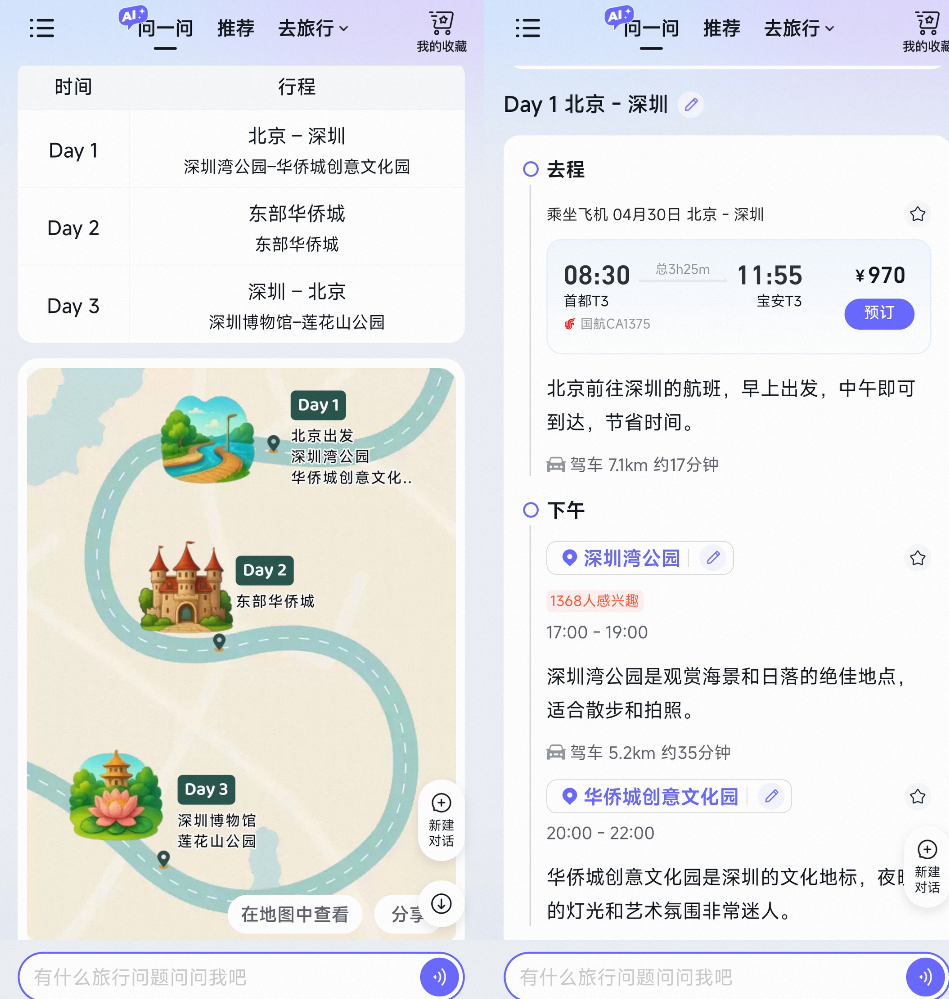
指令: 马上就是五一了,请帮我规划一个单人、从北京出发到深圳的三日自由行攻略,需包含:①交通方式选择(高铁 / 飞机对比)②酒店预订(靠近景区且评分 4.5+)③景点路线(按时间顺序排列)④预算分配(总费用不超过 5000 元)。请分步骤说明并给出每个环节的推荐理由。
评测点:任务拆解颗粒度、步骤间逻辑连贯性、参数匹配能力(如预算限制)
推理用时:20s
最终结果:

对于 Qwen3 的回答,先说结论,如果只是单纯作为行程参考基本 OK。各个景点的推荐、路线、门票以及交通费用预估等,都没什么问题。但是对于实际的旅行而言,还需要更多的闭环,比如直接帮我规划一个具体的、精确到小时的行程,并附上机酒和市内交通建议等。
不过值得一提的是,在回答我既有问题的基础上,Qwen 还给了我 3 条注意事项,包含避堵建议、天气与穿衣 / 行李建议,以及出行安全提示等,这一点确实贴心。
同样,我们向 DeepSeek 提出了同样的问题,但是熟悉的“服务器繁忙”出现了,按照测试规则(仅展现首次提问的结果),我们不再做二次提问。
正好飞猪 AI 旅行助手最近很火,于是我们让它回答了同样的问题。从结果来看,它给的作业是稍微验证后可以直接抄的,并且还增加了漫画行程图和直接预定机酒的按钮,简直是懒人之光、P 人福音。同为阿里系的产品,后面有没有可能直接通过「通义 App」一站式实现旅行闭环?值得期待。
Part3 总结与展望
经过对 Qwen3 在代码生成、数学与逻辑推理,以及创意写作与生活助手两大类核心场景的初步测评(受限于测试周期、样本多样性和提示工程精度),其表现虽存在进一步优化空间,但在与 DeepSeek R1 的横向对比中仍展现出显著优势——特别是在复杂任务处理效率方面,推理耗时大幅缩短,符合官网宣传时提到的“思深,行速”。
除了 Qwen 大模型的开源进度喜人外,另一个值得外界关注的便是阿里在今年 3 月推出的「通义 App」,一经推出便接入最强 Qwen 模型,并持续迭代。「通义 App」以超级智能体作为交互中枢,在主对话页面实现能问、能聊、理解图片、生成图片、翻译、写作等智能体验。
通义产品团队在早前的采访中提到:“我们不仅要通过强大的 AI 技术能力帮助用户解决实际问题,还要让用户在使用中感到更方便、更懂我。AI 应用的未来不仅仅是简单的提效工具,更是一个能够理解、陪伴并提升用户生活质量的贴心 AI 助手。”
当大模型的底层能力足够优异时,上层应用的体验则是后半场 AI 竞赛的关键。很显然,阿里已经准备好了。
针对 Qwen3 的开源,InfoQ 也问询了中国开源泰斗、前国务院信息化联席会议办公室常务副主任陆首群教授的看法,他表示:“赞 Qwen3!封闭不能挺举开源人才,创新才能另辟竞争赛道!”让我们共同期待基于 Qwen 大模型的应用大爆发。




