

本文最初发布于 towardsdatascience.com 网站,经原作者授权由 InfoQ 中文站翻译并分享。
Netflix 正在将古老的电视行业带入互联网时代。Netflix 允许用户随时通过各种互联网连接的设备流式传输庞大的电影和电视节目片库中的数据。公司的主要收入来自用户的订阅费用。那么,Netflix 的推荐系统在其日益壮大的过程中扮演了什么样的角色呢?
Netflix 是一家总部位于美国的媒体服务提供商。它使用订阅模式来提供影片流媒体服务。它提供的内容包括电视节目、内部制作的内容以及电影等。一开始,Netflix 曾经出售过 DVD,并通过邮件系统提供出租服务。一年后他们不再销售 DVD 了,但租赁服务继续做了下去。2010 年,他们转向了互联网并开始提供流媒体服务。从那时起直到今天,Netflix 已成长为世界上最好、最大的流媒体服务之一。
Netflix 的核心资产
Netflix 的核心资产是他们的技术,特别是他们的推荐系统。推荐系统的研究是信息过滤系统的一个分支。信息过滤系统负责在数据流到达用户之前移除无关紧要的部分。推荐系统负责向用户推荐产品或为项目分配评级。它们多被 YouTube、Spotify 和Netflix等公司用来为观众生成播放列表。亚马逊使用推荐系统向用户推荐产品。大多数推荐系统使用用户的使用历史来研究用户特性。推荐系统有两种主要的工作方法,分别是协作过滤和内容过滤。协作过滤使用的基础概念是,过去喜欢某些东西的人将来也会喜欢相同的体验。基于内容的过滤方法适合的场景是,系统了解关于商品的信息,但不了解用户信息。它被用作针对用户的分类工具。它会建模一个分类器,根据用户对一件商品的喜好和反感的特征进行建模。
为什么要做大数据项目?
Netflix 的商业模式只用了一年时间就从出租/出售 DVD 变成了全球范围的流媒体传输。与有线电视不同,互联网电视是无处不在的。Netflix 希望观众能够受益于流媒体服务提供的众多选项。有线电视的内容是高度地域化的。但互联网电视的内容目录中有各种各样的商品,它们来自不同流派、不同地域,可以满足观众多种多样的口味。
在 Netflix 出售 DVD 时,他们面临的推荐问题是要预测用户给予 DVD 的星数,从 1 星到 5 星。这是他们唯一投入大量资源关注的任务,因为这是他们已经从观看过视频的会员那里收到的唯一反馈。他们不会了解任何观看体验和统计数据,完全无法从观众的观看过程中得到反馈。当 Netflix 转变为流媒体服务提供商时,他们就获得了会员的庞大活动数据。这些数据包括与设备相关的详细信息、一天中的观看时间、每周的观看时间以及观看频率。随着订阅和观看 Netflix 内容的人数增加,这项任务演变成为了一个大数据项目。
Netflix 想要回答什么问题?
Netflix 的主要任务就是向用户推荐下一个内容。他们想回答的唯一问题是“如何尽可能地为用户提供个性化的 Netflix 体验?”。尽管这只是一个问题,但它几乎是 Netflix 需要应对的全部任务。内容推荐已经深入到了整个网站的方方面面。
当你登录 Netflix 时,推荐系统就开始工作了。例如,登录后看到的第一个页面由 10 行标题组成,列出的是你接下来最有可能观看的 10 个视频。感知是他们个性化系统的另一个重要部分。他们让观众知道 Netflix 会逐渐适应用户的口味。他们希望客户给网站发送反馈,同时也要建立对整个系统的信任。他们解释了为什么网站认为你会观看某些内容。他们使用“基于你对……的兴趣”“根据你的喜好创建了这一行内容”等短语赢得用户信任。相似性是个性化的另一个要素。
Netflix 从广义上将相似性概念化,例如影片、会员、流派等之间的相似性。他们使用诸如“立刻观看类似的内容”“与……很相似”之类的短语。搜索也是 Netflix 推荐系统的一个非常重要的层面。
数据源:
根据 Netflix 技术博客,Netflix 推荐系统的数据源包括:
一组由会员提供的数以十亿计的评级数据。每天会新增超过一百万的评分。
他们在许多方面都使用了一种流行度指标,但具体的计算方式各有不同。例如,他们会每小时、每天或每周计算一次。他们还通过地理位置或其他相似性指标来区分会员的类型。这些都是计算受欢迎程度的一些不同维度。
与流相关的数据,例如持续时间、播放时间、设备类型、星期几,以及其他与上下文相关的信息。
用户每天添加到待观看队列中的模式和内容标题,这方面的数据每天数以百万计。
所有与内容目录中的标题相关的元数据,例如导演、演员、题材、评分和来自不同平台的评论。
最近,他们还添加了用户的社交数据,以便提取与用户和他们的朋友相关的社交特性,从而提供更好的建议。
与 Netflix 订户或成员的搜索动作相关的文本信息。
除了内部数据源,他们还使用外部数据,例如票房信息、好评度和评论家评论。
他们在预测模型中使用了人口统计、文化、语言和其他常见数据等特性。
数据规模有多大
从 2006 年到 2009 年,Netflix 举办了一场大型竞赛,要求人们设计一种算法,将其著名的内部推荐系统“Cinematch”的效率提高 10%。谁提供了最好的改进措施就将获得 100 万美元的奖励。提供给参赛者的数据集包括了 1 亿个用户评分。
具体来说,这个数据集包括 480189 个用户对 17770 部影片的 100480507 个评分。
2009 年,该奖项被授予了名为 BellKor’s PragmaticChaos 的团队。自那以后,Netflix 表示,该算法已扩展到了可处理网站 50 亿评级数据的规模。因此,据悉,Netflix 推荐系统的数据集是由所有内容标题的信息组成,总数超过 50 亿。
有哪些数据访问权、数据隐私和数据质量问题?
如 2020 年的 Netflix Prize 所述,尽管 Netflix 试图匿名化自己的数据集并充分保护用户的隐私,但围绕着与 Netflix 竞争力相关的数据仍存在许多隐私问题。2007 年,奥斯丁大学的研究人员通过匹配 IMDB 中的评分数据,找出了匿名 Netflix 数据集中的用户信息。2009 年,与该问题相关的四个人针对 Netflix 提起诉讼,理由是它违反了美国的公平贸易法和《视频隐私保护法案》。此后,Netflix 取消了 2010 年及以后的竞赛。
面临的技术和非技术性挑战?
在非技术性挑战上,根据 Maddodi 等人所述,2019,Netflix 在早年遭受了巨大的损失,但随着互联网用户的增加,Netflix 改变了其企业商业模式,从 2007 年开始由传统的 DVD 租赁转变为在线视频流媒体服务。Netflix 精明地预见了迪士尼和亚马逊等竞争对手的到来,因此从一开始就对数据科学研究投入了大量资源。这些努力中的大多数成果仍在为 Netflix 带来回报,并帮助它保持着流媒体行业的领军地位。
Netflix 的团队在构建系统时,在技术上面临的一些挑战包括:
融合不同的模型以预测单一的输出。
优化整体的 RMSE。
模型的自动化参数调优也是一个挑战。
捕获统计相关性受到的全球化影响。
捕获跨时区效应和工作日效应。
检测短期变化是由于多个人共享同一帐户还是一个人的情绪变化引起的。
至于与推荐相关的搜索服务,在 Netflix 工程师发表的一篇论文中提到的挑战有:
从推荐器系统的视角来看,某个视频是不可用的。
检测、报告和替换不可用的实体。
搜索词的长度通常很短,这使 Netflix 很难理解用户正在搜索的内容。
实现即时搜索,做到在用户点击的瞬间就提供良好的结果是一个挑战。
使用不同的索引方案和指标来优化用户体验。
为什么这是一个“大数据”问题?
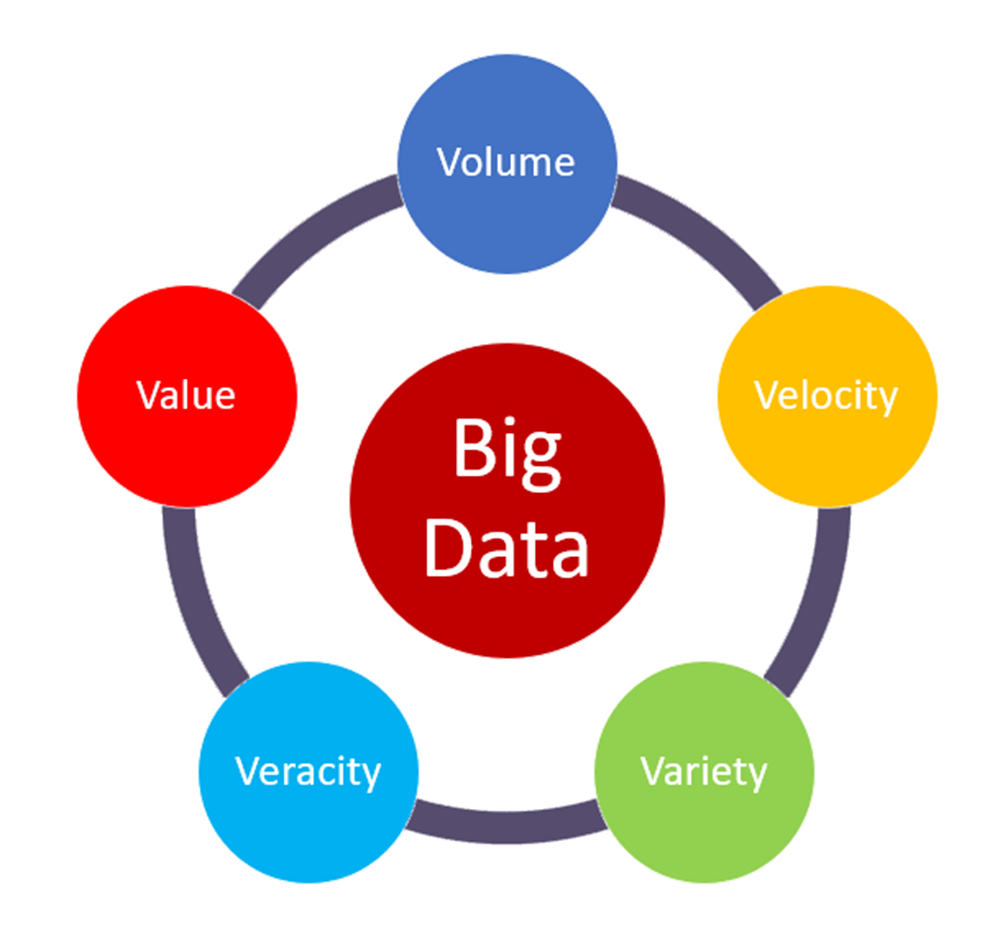
大数据的五个大 V
数量(Volume):截至 2019 年 5 月,Netflix 拥有约 13,612 部影片。仅仅美区片库就包含 5087 个影片标题。截至 2016 年,Netflix 已完成向Amazon Web Services的迁移。他们的数十 PB 数据已移至 AWS,其中包含了工程数据、公司数据和其他文档。根据 AutomatedInsights 的数据,可以估算出 Netflix 仅视频资料就存储了约 105TB 的数据。但是,由于推荐算法需要合并上述所有信息,因此他们的推荐算法数据集估计会非常大。拿 Netflix Prize 任务来说,提供给用户的数据约为 2GB。这些数据仅包含 1 亿部影片的评分。当时,Netflix 承认自己拥有的评分数据为 50 亿规模。粗略估计,这意味着约 10,000GB 的存储容量。而今天 Netflix 的评分数据规模会比上述数字还要大。
速度(Velocity):到 2019 年底,Netflix 拥有 100 万订阅用户和 1.59 亿观众。观众每次在 Netflix 上观看内容时,网站都会收集他们的使用情况统计信息,例如观看历史记录、内容评分、其他有相似口味的用户、与他们的服务相关的偏好、与影片相关的信息(例如演员、流派、导演、发行年份,等等)。此外,他们还会收集有关数据生成时间、观看内容的设备类型、观看时长的数据。平均每个 Netflix 订户每天观看 2 个小时的视频内容。虽然官方并没有公开明确过,但据信 Netflix 会从用户那里收集大量信息。Netflix 平均每天会流传输大约 200 万小时的内容。
准确性(Veracity):准确性指标受偏差、噪声和数据异常影响。以 Netflix Prize 挑战来说,其数据就存在很大差异。并非所有影片都能得到个体平等的评价。有一部影片只有 3 个评分,而有一个用户对 17,000 多部影片打出了评分。根据信息的类型和数量,Netflix 数据肯定会包含很多异常、偏差和噪音。
多样性(Variety):Netflix 表示自己以结构化格式收集大多数数据,例如一天中的具体时间、观看时长、受欢迎程度、社交数据、与搜索相关的信息、与流相关的数据等。但是,Netflix 也可能使用非结构化数据。Netflix 很大方地承认了他们会根据个性化数据提供视频缩略图。这意味着即使是同一视频,对于不同的人也会呈现不同的缩略图。由此可见,他们可能在处理图像和过滤器。
使用了哪些硬件/软件资源来推进项目?

Netflix 技术栈
为了构建推荐系统并执行大规模分析任务,Netflix 在硬件和软件上都投入了大量资源。很早以前,Netflix 就提出了一种处理这一任务的架构。
它执行推荐任务时具体分为三个阶段。根据 Netflix 技术博客的介绍,离线计算是适用于数据的,但与用户的实时分析无关。执行时间比较宽松,并且算法是分批训练的,并不要求在固定的时间间隔内处理一定的数据量。但是系统需要经常训练以整合最新信息。模型训练和结果批处理之类的任务都是离线执行的。由于他们需要处理大量数据,因此通过 Pig 或 Hive 在 Hadoop 中运行任务有很好的效率提升。结果必须发布出来,不仅要得到 HDFS 的支持,还必须得到 S3 和 Cassandra 等其他数据库的支持。为此,Netflix 开发了内部工具 Hermes。它也是一个像 Kafka 这样的发布-订阅框架,但还提供了其他一些功能,例如“多 DC 支持、跟踪机制、JSON 到 Avro 的转换以及称为 Hermes 控制台的 GUI”。他们想要一种可以透明有效地监视、警告和处理错误的工具。在 Netflix,近线层包含脱机计算的结果和其他中间结果。他们使用了 Cassandra、MySQL 和 EVCache。重要的不是存储的数据量,而是存储数据的效率。Netflix 的实时事件流由内部开发的名为 Manhattan 的工具支持。它非常接近 Twitter 的 Storm,但是根据 Netflix 的多种内部要求,它可以满足不同的需求。Netflix 使用带有 Chukwa 日志系统的 Hadoop 来管理数据流。Netflix 严重依赖 Amazon Web Services 来满足其硬件要求。更具体地说,他们使用易于扩展且几乎完美容错的 EC2 实例。他们所有的基础架构都在云中的 AWS 上运行。
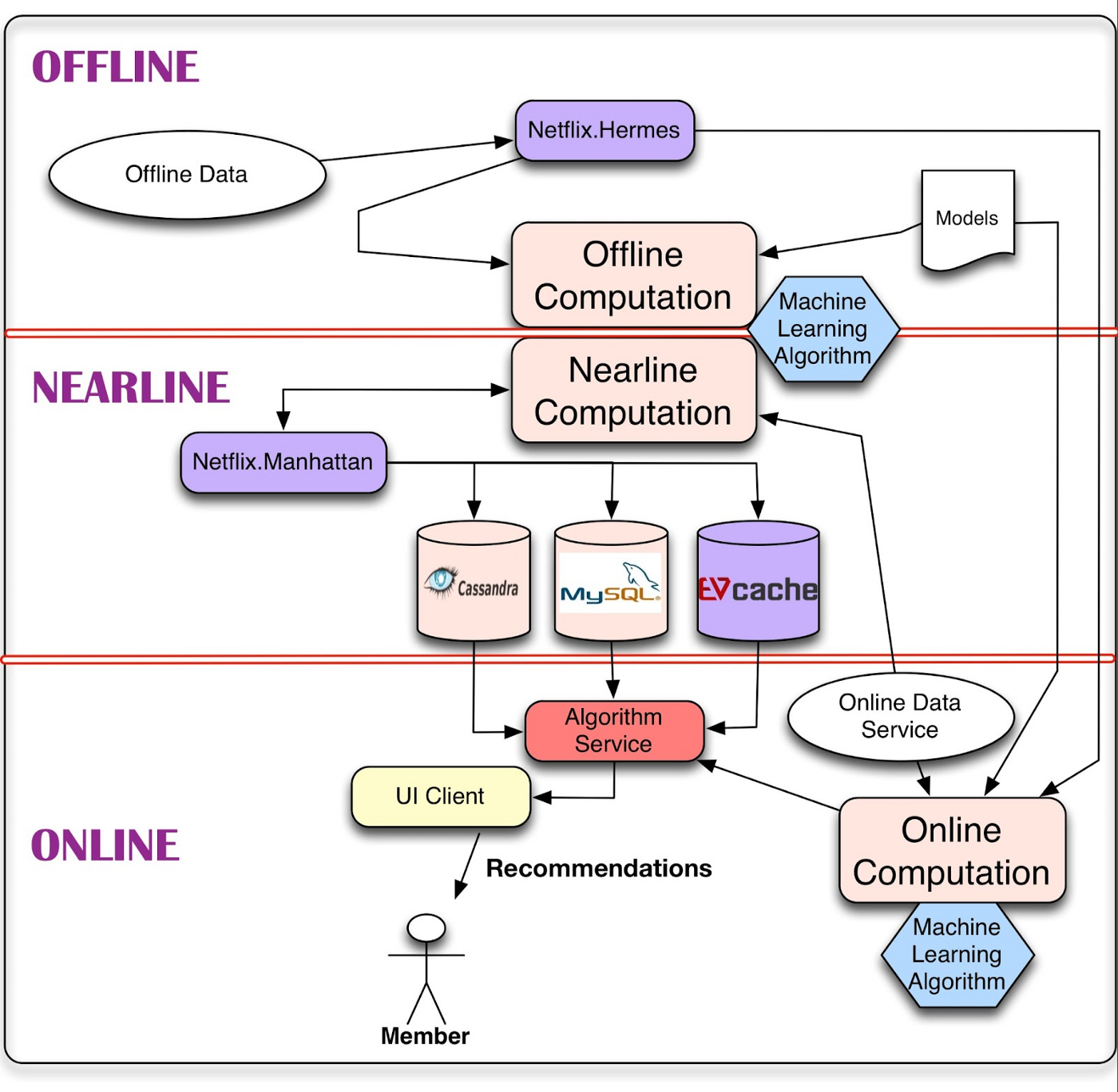
Netflix 的个性化和推荐系统架构
Netflix 在数据科学领域投入了大量资源。他们是一家数据驱动的公司,几乎在每个级别上都使用数据分析进行决策。根据 Vanderbilt 的资料,该公司的硅谷总部大约有 800 名工程师。Netflix 还聘用了一些最聪明的人才,其数据科学家的平均薪水很高。公司拥有很多在数据工程、深度学习、机器学习、人工智能和视频流工程方面具有专业知识的工程师。
带来了怎样的价值?
在推荐系统的帮助下,用户与 Netflix 的总体互动率有所提高。这进一步降低了订阅取消率,增加了流媒体平均观看时间。
订户的每月客户流失率非常低,大部分是由于支付网关交易失败所致,而不是由于客户主动选择取消服务。
个性化和推荐系统每年为 Netflix 节省超过 10 亿美元。
人们今天观看的内容中有 75%是由他们的推荐系统提供的。
成员满意度随着推荐系统的发展和进化而增加。
关于 Netflix Prize 任务,获胜算法能够提升预测收视率,并将“影片匹配度”提高 10.06%。根据 Netflix 技术博客,奇异值分解能够将 RMSE 降低到 89.14%,而受限玻尔兹曼机可以将 RMSE 降低到 89.90%。它们共同将 RMSE 降低到了 88%。
项目成功了吗?
在数据科学技术领域的投资已使 Netflix 成为视频流媒体行业中的翘楚。个性化和推荐系统每年可为该公司节省 10 亿美元。而且,这也是吸引新订户加入该平台的重要因素之一。此外,关于 Netflix 竞赛的获奖算法,其许多组件如今仍在公司的推荐系统中使用。因此,该系统可以被认为是成功的。
作者介绍:
Chaithanya Pramodh Kasula,乔治梅森大学研究生研究助理,专注机器学习、深度学习领域研究。
原文链接:
https://towardsdatascience.com/netflix-recommender-system-a-big-data-case-study-19cfa6d56ff5
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

加V:busulishang4668

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论