
Anthropic 近日发布故障报告,揭示近期 Claude 模型输出质量间歇性下降的根源在于三个独立的基础设施漏洞。Anthropic 表示目前已解决所有问题,且在改进内部流程以防类似事件发生。此事也引发社区对三大硬件平台服务运行难点的关注。
2025 年 8 月至 9 月初,Claude AI 用户陆续反馈模型响应质量下降或表现不稳定。最初看似普通的性能波动,实际并非由大流量或高需求引发,而是被追溯至三个分别影响底层基础设施、路由逻辑和编译流程的独立基础设施漏洞。团队解释称:
我们从未因流量、时段或负载而降低模型质量。用户反馈的问题完全源于基础设施漏洞(..……)每个漏洞在不同平台以不同频率引发不同问题,导致其线索错综复杂。
团队披露的三重故障包括:上下文窗口路由错误,导致 8 月 31 日的峰值时段影响了 16% 的 Sonnet 4 请求;由于 Claude API 的 TPU 服务器配置错误,在令牌生成过程中触发了故障,导致输出内容损坏,影响了 8 月 25 日至 28 日期间对 Opus 4.1 和 Opus 4 的请求,以及 8 月 25 日至 9 月 2 日期间对 Sonnet 4 的请求;最后,因为编译器中的一个潜在缺陷所导致的近似 top-k XLA:TPU 错误编译问题,影响了针对 Claude Haiku 3.5 的请求,持续时间近两周。Anthropic 补充道:
我们将 Claude 部署在 AWS Trainium、英伟达 GPU 和谷歌 TPU 三大硬件平台。各硬件平台特性迥异且需专门优化,尽管如此,我们的模型实现严格遵循统一等效的标准。
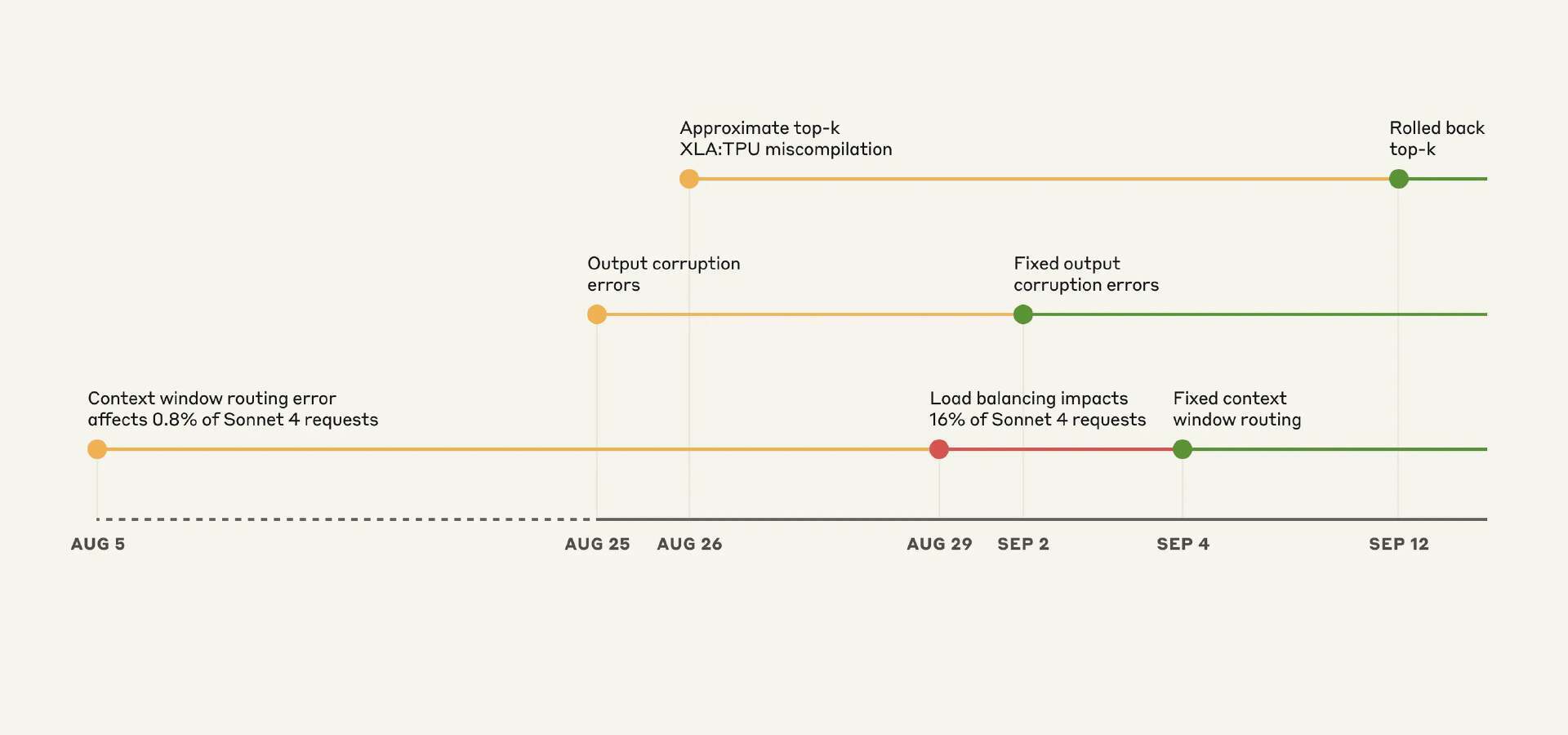
来源:Anthropic 博客 blog
Anthropic 的可靠性负责人 Todd Underwood 在领英上回应了这些问题:
这个夏天我们在可靠性方面表现不佳。早在这些问题出现之前,七八月就已持续出现容量与可靠性故障(..……)我对此深表歉意,团队正全力提供兼具高质量与高可用的最佳模型。
OpenAI 技术团队成员 Clive Chan 评论:
机器学习基础设施运维难度极高,向参与问题定位与报告撰写的同仁致敬。
Anthropic 致力于让所有硬件平台都对用户透明化,确保无论什么平台的请求都能获得同等质量响应,其硬件复杂度意味着每次基础设施变更都需全平台验证。Google DeepMind 高级 AI 开发者关系工程师 Philipp Schmid 指出:
大规模模型服务本已困难,在三大硬件平台(AWS Trainium、英伟达 GPU、谷歌 TPU)上维持严格等效更是难上加难。令人质疑硬件灵活性是否值得以开发速度和用户体验为代价。
Hacker News 用户 Mike Hearn 分析:
最值得注意的是单元测试的明显缺失。针对 XLA 编译漏洞的测试仅打印了结果,这更像是一个复现案例,而不是那种由测试框架执行、并且会跟踪覆盖率的单元测试。而后续的改进措施,也仅仅是更激进地依赖评估手段。
这家 AI 公司承诺将推行更灵敏的评估机制,在更多环节加入质量检验,并开发新工具在保护隐私前提下高效分析社区反馈。
原文链接:
https://www.infoq.com/news/2025/10/anthropic-infrastructure-bugs/




