

导读:Apache Hudi 是由 Uber 开源的在分布式文件系统上提供对大型分析数据集的摄取、管理以及查询的数据湖框架。2019 年 1 月加入 Apache 孵化器进行孵化,5 月份,Hudi 晋升为 Apache 顶级项目。本文主要从 “增量处理”的角度切入来谈谈 Hudi 对于数据湖的重要性。更多关于 Apache Hudi 的框架功能、特性、使用场景以及最新进展等可关注 QCon 全球软件开发大会(北京站)2020 获悉。
在大数据技术发展的整个历程中,Hadoop 算是稳稳地抓住了这一时代机遇,成为了企业建设大数据基础设施事实上的标准。其中,支撑 Hadoop 生态的分布式文件系统 HDFS 顺势持有数据坐拥天下之利,几乎也顺其自然地成为了事实上的大数据存储系统的接口标准。基于以上的两个坚实的“标准”,Hive 作为在 Hadoop 体系之上以 HDFS 为存储的大数据数仓的基础架构也一直是很多企业的不二选择,但天下却苦这套数仓架构久矣。这其中的原因是多方面的,比如,HDFS 复杂的架构、高昂的成本,冷热分层存储能力的缺失等问题以及长久以来旧版本的 Hive 无法支持真正意义上的 Update/Delete 操作等。
于是,近些年随着云原生架构的兴起,我们看到了 Hadoop 逐渐式微,加上现在拥抱低廉云存储的浪潮,业界涌现出多个跟 HDFS 接口兼容的拥抱云厂商存储的数据湖框架试图改善上面的这些问题。
本文不打算对比各个框架的特性,孰优孰劣其实还得结合需求和场景来评判,而且当下三个开源的数据湖存储框架(Apache Hudi/Iceberg, Delta Lake)离成熟以及稳定的形态还有很长的一段路要走。本文会试图从 “增量处理”的角度切入来谈谈它对于数据湖的重要性。
传统的 Hadoop 数仓体系缺乏增量处理的原语
在移动互联网和物联网的时代,数据延迟到达非常常见。这里我们涉及到两个时间语义的定义:事件时间(event time)及处理时间(processing time)[0]。顾名思义:
事件时间:指事件真实发生的时间;
处理时间:指在系统中观察到(处理)事件的时间;
理想情况下,事件时间和处理时间是一致的,但现实情况中,它们可能会有或多或少的偏差,我们常将其称之为“时间倾斜”(Time Skew)。无论对于低延迟的流计算还是常见的批处理,事件时间及处理时间和迟到数据的处理都是一个常见且棘手的问题[0]。通常,为了保证正确性,当我们严格遵循“事件时间”语义时,迟到的数据会触发对时间窗口(对于 Hadoop 数仓中的批处理而言通常就是 Hive 分区)的重新计算[1],尽管这些“窗口”的结果可能已经被计算完成甚至已经与终端用户进行过了交互。而重新计算,在流式处理中通常使用可扩展的键值存储结构,在记录/事件层面增量地处理,并基于点查询和更新进行优化。然而,在 Hadoop 中,重新计算通常意味着重写整个(不可变的)Hive 分区(或者简而言之是一个 HDFS 中的文件夹),并且重新触发所有已经消费过那个 Hive 分区数据的级联任务的重新计算。
在支撑海量数据的 Hadoop 数仓中,很多长尾的业务仍然对于冷数据的更新有着很强的需求。但长久以来,Hadoop 数仓中的单个分区中的数据被设计为不可更新的,如果需要更新,则需要重写整个分区。这会严重损害整个生态系统的效率。而从延迟和资源利用率的角度来看,在 Hadoop 上的这些操作都会产生昂贵的开销。这一开销通常也会级联地传导到整个 Hadoop 的数据处理 Pipeline 中,最终导致延迟增加了数小时。
针对以上提到的两个问题,如果 Hadoop 数仓支持细粒度的增量处理,则可以使我们更有效地将变更包含到已有的 Hive 分区中,并且为下游的表数据消费者提供一个仅获取变更数据的方式。对于有效地支持增量处理,我们可以将其分解为以下两个原语操作:
更新插入(upsert):从概念上讲,重写整个分区可以被视作一个非常低效的更新插入操作,最终会写入比原始数据本身多得多的数据。因此,对(批量)更新插入的支持被视为非常重要的功能。事实上,像 Kudu 和 Hive 事务的确是朝着这一方向发展的。谷歌的 Mesa(谷歌的数据仓库系统)论文[3]也谈论了几项技术,可以被应用到快速数据摄入的场景里。
增量消费:尽管更新插入可以解决快速地向一个分区发布新数据的问题,但下游的数据消费者并不知道从过去的哪一个时刻开始哪些数据被改变了。通常,消费者只能通过扫描整个分区/数据表并重新计算所有数据来得知改变的数据,这需要花费相当多的时间和资源。因此,我们也需要一种机制来更加高效地获取从上次分区被消费的时间点开始改变过的数据记录。
有了上面这两种原语操作,你可以通过更新插入一个数据集,然后从中增量地消费,并建立另外一个(也是增量的)数据集来解决我们上面提到的两个问题并支持很多常见的案例,从而可以支持端到端的增量处理并降低端到端的延迟。这两个原语互相结合,解锁了基于 DFS 抽象的流/增量处理的能力。
数据湖在存储规模上远超数据仓库,虽然在功能的定义上两者各有侧重但存在相当的交集(当然这仍然存在着争论以及定义和实现偏离的问题,这不是本文试图去探讨的话题)。无论如何,数据湖将借助更廉价的存储支撑更大的分析型数据集,因此增量处理对于它同样非常重要。接下来我们就来探讨一下,增量处理对于数据湖的意义。
增量处理对于数据湖的意义
增量天然契合流的语义
早有论述表明:变更的日志(也就是我们所理解的常规意义上的“流”)和表之间存在着“二象性”[2]。

这一论述的核心是:如果有变更日志,你可以应用这些变更生成数据表并得到当前状态。如果你对一张表进行更新,你可以记录这些变更,并把所有的”变更日志”发布到表的状态信息中。 这个可互转的性质,简称为“流表二象性”。
对“流表二象性”更通俗一点的理解:当业务系统在修改 MySQL 表中的数据时,MySQL 会将这些修改反映为 Binlog,如果我们将这些持续的 Binlog(流)发布到 Kafka 的 Topic 中,然后让下游的处理系统订阅该 Topic,使用状态存储逐步累积中间结果,这个中间结果的当前状态就反应为表的当前快照。
如果数据湖上可以引入上面我们提到的支持增量处理的两个原语,那么上面这个可以反映“流表二象性”的 Pipeline 在数据湖上也一样是适用的。基于第一个原语,数据湖同样可以摄入 Kafka 中的 Binlog 日志流,然后将这些 Binlog 日志流存入到数据湖上的“表”。基于第二个原语,这些表又将更新插入的记录识别为“ Binlog ”流用于支持后续级联任务的增量消费。
当然由于数据湖中的数据需要落地到最终的文件/对象存储,考虑到吞吐以及写性能的权衡,数据湖上的 Binlog 反应的是流上的一段时间内的小批次的变更日志。例如,Apache Hudi 社区正在进一步尝试提供针对不同 Commit(一个 Commit 指代一批数据的写入提交)之间类似于 Binlog 一样的增量视图,形如下图:
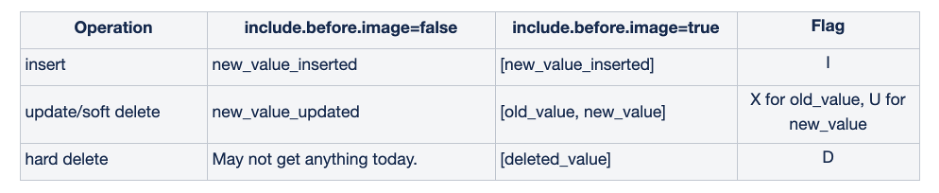
备注“Flag”一栏的标识:
I: Insert;
D: Delete;
U: After image of Update;
X: Before image of Update;
基于上面的论述,我们可以认为增量处理跟流是天然契合的,而且我们可以在数据湖上自然地将它们衔接起来。
分析型场景需要增量处理
在数仓中,无论是维度建模还是关系建模理论,通常都是基于分层的设计思想来建设[4]。体现到技术实现上,则是通过工作流调度引擎串联起多个层次的 ETL 任务形成一整条长 Pipeline 的多个阶段(步骤),如下图所示:
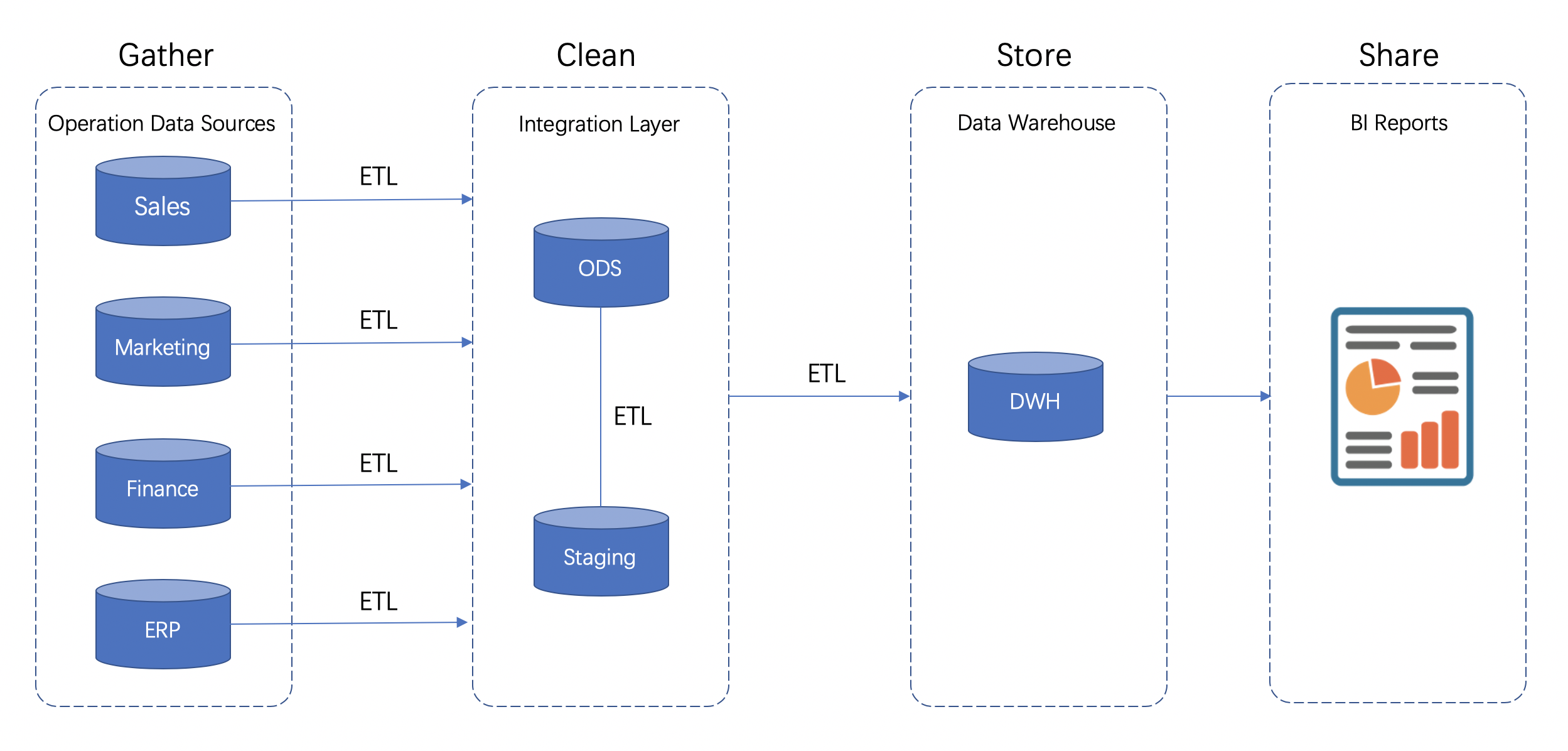
作为数据仓库的主要应用,在 OLAP 领域对于常规的(针对无变更或少量变更的)业务场景,现在业界已经有一些框架专注于各自擅长的场景提供高效的分析能力。但在 Hadoop 数仓体系中,针对业务数据频繁变更的分析场景始终没有一个很好的解决方案。
例如,我们考虑出行业务的订单状态更新场景,这个场景存在典型的长尾效应:你无法知道一个用户的订单是在明天结单、一个月后结单还是一年后结单。在这个场景中,订单表是主数据表,但通常我们会基于这个表衍生出其他的派生表来支持各种业务场景的建模。最初的更新发生在 ODS 层的订单表上,但这些衍生表都需要被级联更新。
对于该场景,在此之前,一旦有变更发生,人们通常需要在 ODS 层的 Hive 订单表中找到待更新数据所处的分区,对该分区进行全量更新,随后这些衍生表相关数据的分区都需要被级联地更新。
是的,肯定有人会想到,Kudu 对 Upsert 的支持可以解决旧版本 Hive 缺失第一个增量原语的问题。但 Kudu 这个存储引擎有它自身的局限性:
性能上:对硬件本身有额外的要求;
生态上:如适配主流的大数据计算框架、机器学习框架方面,远不及 Hive 有优势;
成本上:需要专门的维护成本、开销;
没有解决上面提到的增量处理的第二个原语:增量消费的问题。
总结而言,增量处理在 Hadoop 生态的数据湖上有以下几点优势:
性能的提升:摄取数据通常需要处理更新、删除以及强制唯一键约束。由于增量原语支持记录级更新,它能为这些操作带来数量级的性能提升。
更快的 ETL /派生 Pipelines:从外部系统摄入数据后,下一步需要使用 Apache Spark/Apache Hive 或者任何其他的数据处理框架来 ETL 这些数据用于诸如数据仓库、机器学习等应用场景。通常,这些处理再次依赖以代码或 SQL 表示的批处理作业。而通过使用增量查询而不是快照查询来查询一个或多个输入表,可以大大加速此类数据管道,从而仅处理来自上游表的增量更改,然后 Upsert 或者 Delete 目标派生表。与原始数据摄取类似,为减少建模表的数据延迟,ETL 作业也只需从原始表中逐步地提取已更改的数据,并更新先前派生的输出表,而不是每隔几小时重建整个输出表。
统一存储:基于以上两个优点,在现有数据湖之上进行更快速、更轻量的处理意味着仅出于访问近实时数据的目的,不再需要专门的存储或数据集市。
接下来,我们以两个简单的示例来说明增量处理如何在分析型场景中加快处理的 Pipeline[9]。首先,数据投影就是最常见且容易理解的案例:
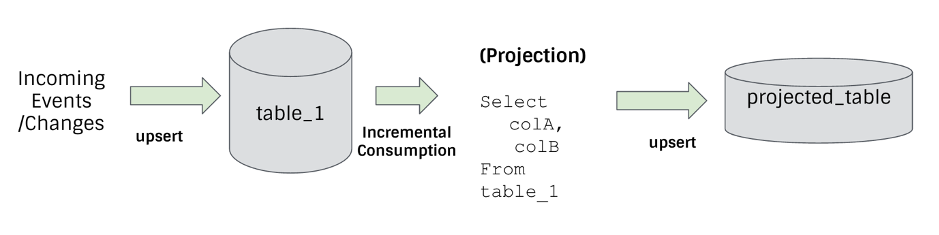
这个简单的的例子展示了:通过更新插入新的变更到表 1(table_1),并通过增量消费建立一个简单的投影表(projected_table),我们可以更高效地以较低的延迟来操作简单的投影。
接下来,更复杂一点的场景,我们可以借助于增量处理来支持流计算框架所支持的流和批的连接,和流-流的连接(只不过需要增加一些额外的逻辑来做窗口对齐):
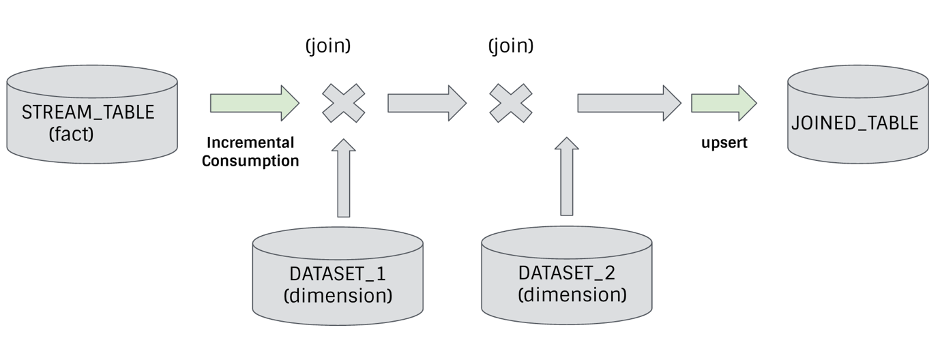
上图的示例将一个事实表连接到多个维度表,从而建立一个连接过的表,这个案例是我们可以节省硬件花费的同时显著地降低延迟的不多见的场景之一。
准实时场景资源/效率的权衡
增量地处理 Mini 批次中的新数据能更加有效地使用组织中的资源。让我们参考一个具体的例子,我们有一个 Kafka 事件流以每秒一万条的速度涌入,我们想要计算过去 15 分钟在一些维度上消息的数量。很多流式处理管道使用一个外部结果存储系统(例如 RocksDB, Cassandra, ElasticSearch)来保存聚合的计数结果,并让在 YARN/Mesos 等资源管理器里的容器持续运行,这在小于五分钟的延迟窗口的场景下是很合理的。实际上,典型的 YARN 容器本身就存在一定的启动开销。此外,为了提升写操作到结果存储系统上的性能,我们通常先缓存结果再进行批量更新,这种协议都需要容器持续地运行。
然而在准实时处理的场景里,这些选择可能不是最佳的。为了达到同样的效果,你可以使用短生命周期的容器并且优化整体的资源利用率。例如,流式处理器在 15 分钟内可能需要对结果存储系统执行六百万次更新。但是在增量批处理模式里,我们只需要对累积的数据执行一次内存中的合并同时仅对结果存储系统进行一次更新,这时只会使用资源容器五分钟。相比纯粹的流处理模式,增量批处理模式有数倍的 CPU 效率提升,在更新到结果存储的方面有几个数量级的效率提升。基本上,这种处理方式按需获取资源,而不用长时间运行时一边等待数据进行即时计算,一边吞噬 CPU 和内存。
增量处理便于统一数据湖上架构
数据处理无论是在数仓中还是在数据湖中,都是不可回避的一个问题。数据处理涉及到计算引擎的选择以及架构的设计,目前业界主流的有两种架构:Lambda 以及 Kappa 架构,每个架构都有各自的特点以及存在的问题,围绕这些架构的衍生版本也层出不穷[5]。
现实中,很多企业仍然维持着 Lambda 架构的实现,典型的 Lambda 架构针对数据处理部分有两个模块:速度层和批处理层[6]。
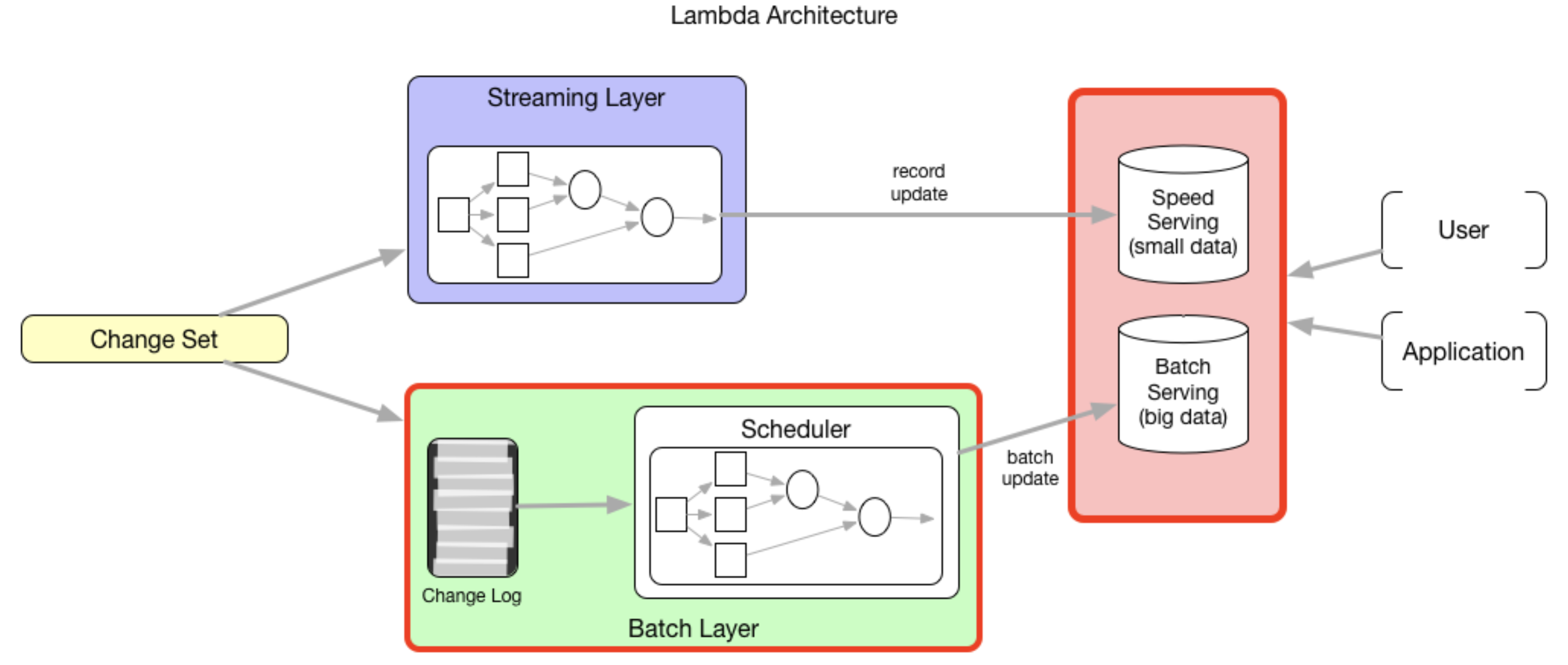
它们通常是两个独立的实现(从代码到基础设施)。例如,Flink(之前是 Storm)是速度层上的一个热门选项,而 MapReduce/Spark 可以作为批处理层来提供服务。实际上,人们经常依赖速度层来提供更新的结果(可能并不准确),而一旦数据被认为是完整了之后,通过批处理层在稍后的时间里来纠正速度层的结果。而借助于增量处理,我们有机会以统一的方式在代码层面和基础设施层面来针对批处理以及准实时处理实现 Lambda 架构。形如下图:
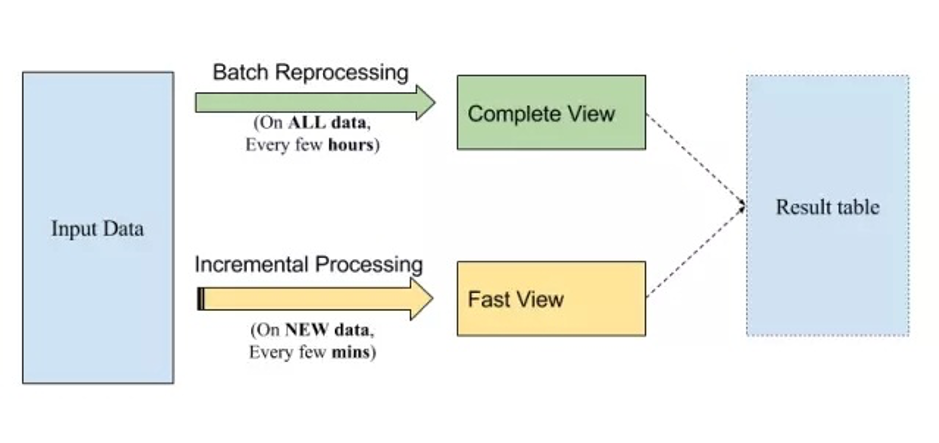
正如我们所说的,你可以使用 SQL 或者类似 Spark 这样的批处理框架来一致地实现你的处理逻辑。结果表增量地被建立,像流式处理那样在“新数据”上执行 SQL 来产生结果的快速视图。同样的 SQL 可以在全量数据上周期性地执行,来纠正任何不准确的结果(记住,连接操作总是棘手的!),并产生一个更加“完整”的结果视图。在这两种情况下,我们都将使用同样的基础设施来执行计算,这可以降低总体运营成本和复杂度。
抛开 Lambda 架构,就算在 Kappa 架构中,增量处理的第一个原语(更新插入)也发挥着重要的作用,Uber 基于此提出了 Kappa + 架构[7]。Kappa 架构倡导一个单独的流式计算层足以成为数据处理的通用解决方案。虽然批处理层在这个模型中被去掉了,但是在服务层仍然存在两个问题[8]:
如今很多流式处理引擎都支持行级的数据处理,这就要求我们的服务层也需要能够支持行级更新的能力;
对于数据摄取延时、扫描性能与计算资源和操作复杂性的权衡是无法避免的。
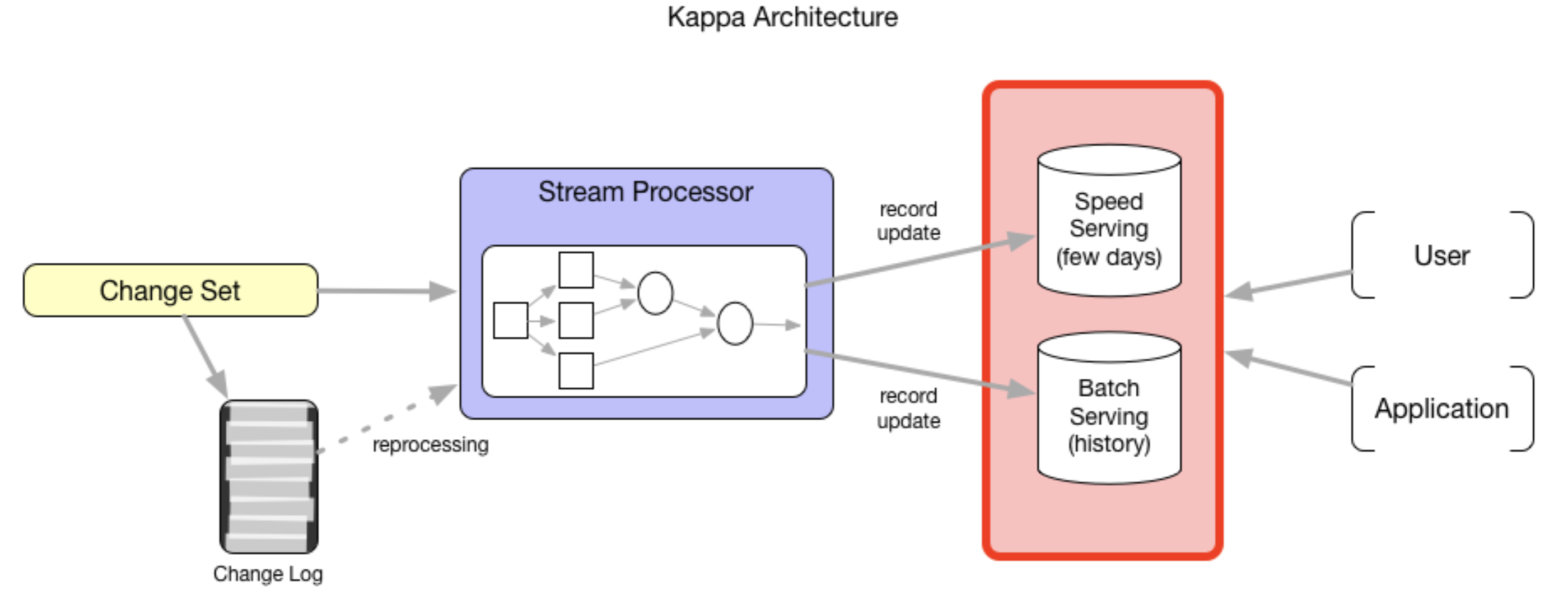
但是如果我们的业务场景对时延的要求并不是那么高,比如能接受 10 分钟左右的延迟。且如果我们可以在 HDFS 上快速的进行数据摄取和数据准备的基础上,有效的连接和将更新传播到上层建模数据集的能力,服务层中的 Speed Serving 就不必要了。那么服务层就可以得到统一,大大降低系统整体的复杂度和资源消耗。
以上,我们介绍了增量处理对于数据湖的意义。接下来,我们介绍一下增量处理的实现与支持情况。目前开源的三个数据湖框架中(Apache Hudi/Iceberg,Delta Lake),对增量处理提供良好支持的只有 Apache Hudi。这完全植根于当时 Uber 在 Hadoop 数据湖上进行数据分析所遇到的痛点而研发的一个框架。那么,接下来,我们来介绍一下 Hudi 是如何支持增量处理的。
Hudi 对增量处理的支持
Apache Hudi (Hadoop Upserts Deletes and Incremental Processing) 是 Apache 基金会的顶级项目。它使得您能在 Hadoop 兼容的存储之上处理超大规模的数据,同时它还提供两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。
从其命名时将字母”I”寓意为”Incremental Processing”,就可以看到它将支持增量处理放在很重要的位置上。本文最初我们提到的支持增量处理的两个原语,体现在 Apache Hudi 中如下的两个方面:
Update/Delete 操作:Hudi 使用细粒度的文件/记录级别索引来支持 Update/Delete 记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
变更流:Hudi 对获取数据变更提供了完备的支持,可以从给定的时间点获取给定表中已 Updated/Inserted/Deleted 的所有记录的增量流。
变更流的具体实现是“增量视图”,Hudi 是当前的三个开源数据湖框架里唯一一个支持增量视图特性的框架。下面的示例代码段向我们展示了如何查询增量视图:
上面这段代码段,创建了一个 Hudi 行程增量表 (hudi_trips_incremental),然后查询该增量表中在 beginTime 提交时间之后且费用大于 20.0 的所有变更记录。基于该查询,你可以在批处理数据上创作增量数据管道。
总结
本文我们首先通过阐述了在传统的 Hadoop 数仓中,由于数据完整性和延迟之间的权衡以及一些强依赖更新的长尾应用缺乏增量处理的原语,从而导致的诸多问题。接着,我们介绍了引入增量处理必须具备至少两个原语:更新插入以及增量消费,并说明了这两个原语为什么能够解决前文阐述的这些问题。
然后,我们介绍了为什么增量处理对于数据湖同样有重要的意义。数据湖和数仓在数据处理上有很多共通的部分,在数仓中由于缺失增量处理所导致的一些“痛点”,在数据湖中同样存在。我们从增量处理天然契合流的语义、分析型场景的需要、准实时场景资源/效率的权衡以及统一湖上架构四个方面阐述了它对于数据湖的意义。
最后,我们介绍了开源数据湖存储框架 Apache Hudi 对于增量处理的支持以及简单案例。
[0]: https://www.oreilly.com/radar/the-world-beyond-batch-streaming-101
[3]: https://research.google/pubs/pub42851/
[4]: https://en.wikipedia.org/wiki/Data_warehouse#Design_methods
[5]: https://www.infoq.cn/article/Uo4pFswlMzBVhq*Y2tB9
[6]: https://en.wikipedia.org/wiki/Lambda_architecture
[8]: https://eng.uber.com/hoodie/
[9]: https://www.oreilly.com/content/ubers-case-for-incremental-processing-on-hadoop/
作者介绍:
杨华,T3 出行大数据平台负责人,Apache Hudi committer & PMC member。Apache Flink 活跃贡献者,Apache Kylin 的 Flink Cube Engine 作者。前腾讯高级工程师,曾主导 Flink 框架在腾讯落地,经历了 Flink 从零到支撑日均近 20 万亿消息处理规模的全过程。
在QCon北京2020的分享中,杨华老师将会对 Hudi 框架的功能、特性以及使用场景进行全面且系统地介绍,同时也会介绍 Hudi 在 T3 出行相关场景中的实践以及社区里正在进行的 Hudi 与 Flink 计算引擎集成相关的工作。点击了解详情。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论