
文档处理技术的演变历程
长期以来,光学字符识别(OCR)技术一直是文档数字化的基石。然而,传统的实现方式在应对当今复杂多样的文档时却显得力不从心。在企业领域,文档的形式多种多样,包括扫描的合同、图像、带有嵌入式表格的电子邮件,甚至是手写笔记。基于模式识别和模板的系统无法跟上时代的步伐。一旦输入与预期的规范有所偏离,性能便会出现明显下降,暴露出其脆弱性。
这种变革是由多种因素共同推动的。首先,非结构化文档类型的爆炸性增长是关键因素之一。企业如今需要处理的文档涵盖了从自由格式的电子邮件到高度格式化的报表等各种类型,而传统系统无法快速适应这些变化。其次,高容量工作流自动化的需求带来了巨大压力,这要求必须将人工干预程度降至最低。最后,现代商业运营的高速性要求能够近乎即时地从文档中提取结构化数据。
当传统系统无法满足需求时,就会产生连锁反应。无法正确提取数据会导致运营延迟、增加人工校正周期,同时还会因监管合规性问题而面临更高的风险。这些挑战需要一种更智能、更具适应性的文档处理方法——一种能够根据上下文解释文档的方法,而不仅仅是根据视觉结构。
真实案例:改进抵押贷款申请工作流程
一家每天处理数千份贷款申请的抵押贷款公司,为我们生动地诠释了这一概念。每一份贷款申请都涉及多种多样的文件,包括工资单、纳税申报表、身份证明、银行对账单和雇主开具的证明信。
这些文件有各种各样的格式,通常是经过扫描、拍摄,或是从各种门户网站下载下来的。其中有许多文件的格式不佳或包含手写内容,使用传统系统处理起来非常困难。
业务方面的挑战是显而易见的。手动审查这些文件需要时间和资源。每一份申请可能需要一到两天才能完成验证,尤其是当团队需要核对收入、匹配签名或验证账户余额时。随着客户对快速审批的期望越来越高,以及严格的监管审查不断加强,这种延迟已成为一个严重的瓶颈。
传统的基于 OCR 的系统虽有一定作用,但当文档与预期布局稍有偏离时,往往会出现故障。表格结构的细微变化或扫描图像模糊不清都可能迫使系统完全依赖于人工干预,这不仅延长了处理时间,还会增加出错的风险。
这正是现代文档智能管道大显身手的地方。通过将工作流拆解为多个模块化阶段,贷款机构能够以更快的速度、更高的准确性处理各类文档。
六阶段文档管道
现代文档智能系统采用了模块化管道架构,每个阶段负责处理特定的任务。这种设计赋予了系统高度的弹性和灵活性,使团队能够根据技术的演进或业务需求的改变轻松升级各个阶段的功能。
这些阶段包括:
数据捕获:从多种来源(如扫描上传、电子邮件附件、移动应用程序和云存储桶)接收文档。像AWS S3触发器或Google Cloud Functions这样的服务通常作为入口点。
分类:确定文档的类型——无论是银行对账单、病历、发票还是纳税申报表。可以利用基于变换器架构的预训练分类器(例如,BERT、RoBERTa)或云原生工具(如Google Document AI)。
提取:识别并提取键值对、表格或段落。在这里,通常使用LayoutLM这样的布局感知模型或服务(如AWS Textract和Azure Form Recognizer)。
增强:通过将术语链接到已知本体、应用业务规则或查询外部知识图谱,为原始提取的内容添加上下文信息。
验证:使用置信度评分或基于规则的验证器评估提取质量。如有需要,将模糊的内容转给人工审核。
消费:通过 API 或消息队列将结构化输出推送到下游系统(如 ERP、CRM 或分析仪表盘)。
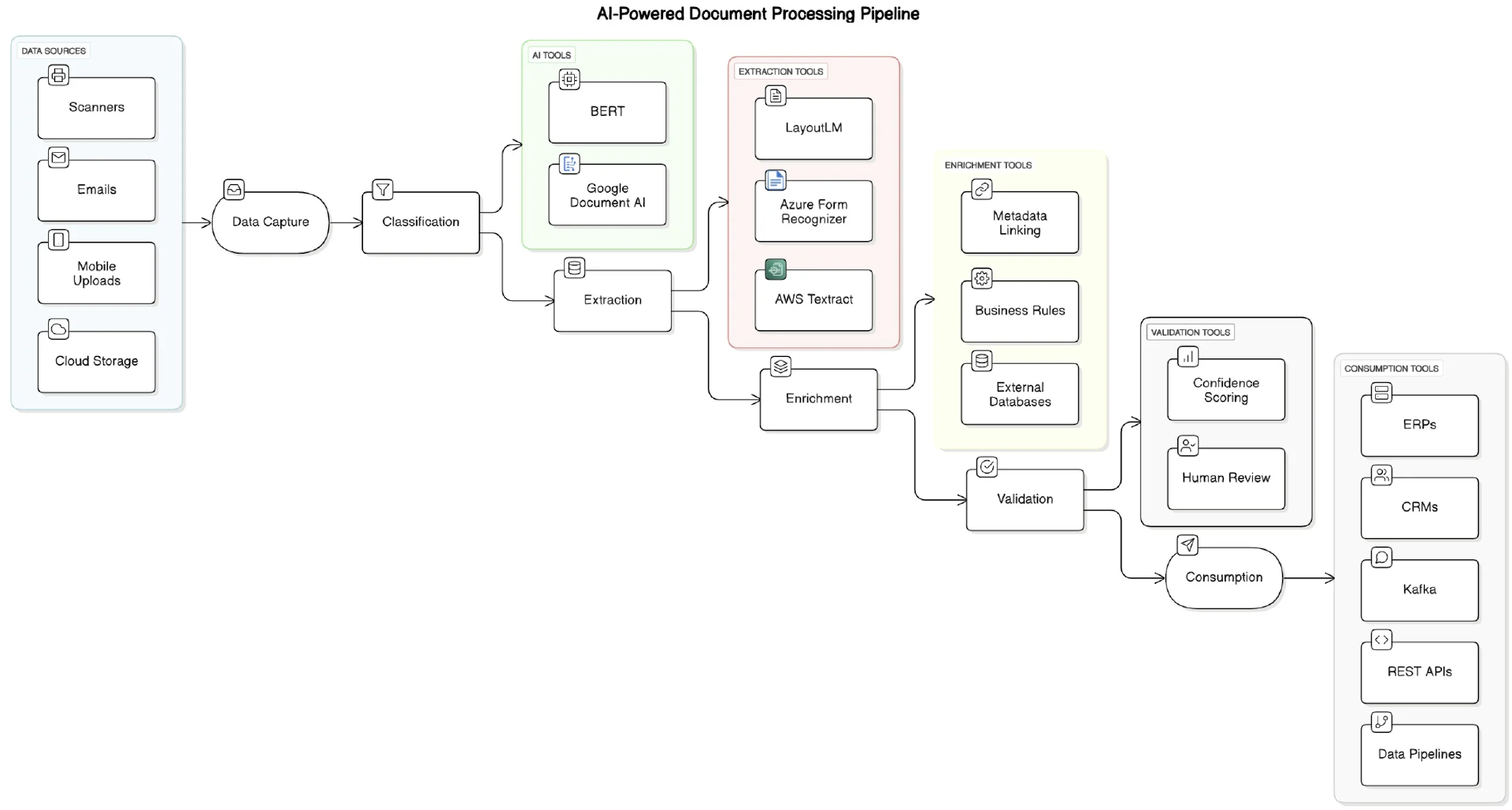
图 1. AI 驱动的文档处理管道
预训练模型:各司其职
尽管云服务供应商和开源工具提供了各种文档 AI 服务,但并不存在一种通用的模型。每种模型都在透明度、调整灵活性、成本和性能等方面存在着不同的权衡。
在抵押贷款行业,团队通常依赖 Textract 从标准文档(如工资单和银行对账单)中提取信息。如果布局清晰且可预测时,它表现良好。但一旦格式变得复杂,它可能会开始抛出不一致或过于详细的输出,这不仅无法提升信息的清晰度,反而增加了干扰。
相反,LayoutLM 可以处理更不规则的输入,如手写的 W2 表格或具有混合布局的文档。Google Document AI 提供了强大的布局理解和稳健的自然语言处理集成能力,但在深度定制方面稍显不足。Azure Form Recognizer 是一个折中的选择,它具备自定义训练能力,不过可能需要对示例进行标记。在开源领域,LayoutLM 在结合空间布局和语言方面展现出强大的能力,但需要 GPU 资源和工程专业知识的支持。对于清晰度较高、复杂度较低的扫描文档,像 Tesseract 和 OpenCV 这样的轻量级选项依然具有很高的实用性。
选择模型组合——即所谓的集成学习,通常是最佳策略。在金融或医疗保健等高度受监管的领域,精确性至关重要。在这种情况下,可以将 LayoutLM 和 Textract 搭配使用,其输出结果可以通过规则引擎或人工审核员进行交叉验证。相比之下,在零售收据解析等场景中,吞吐量比绝对精确性更重要,此时采用 Azure 表单识别器与启发式回退的组合可能就足够了。
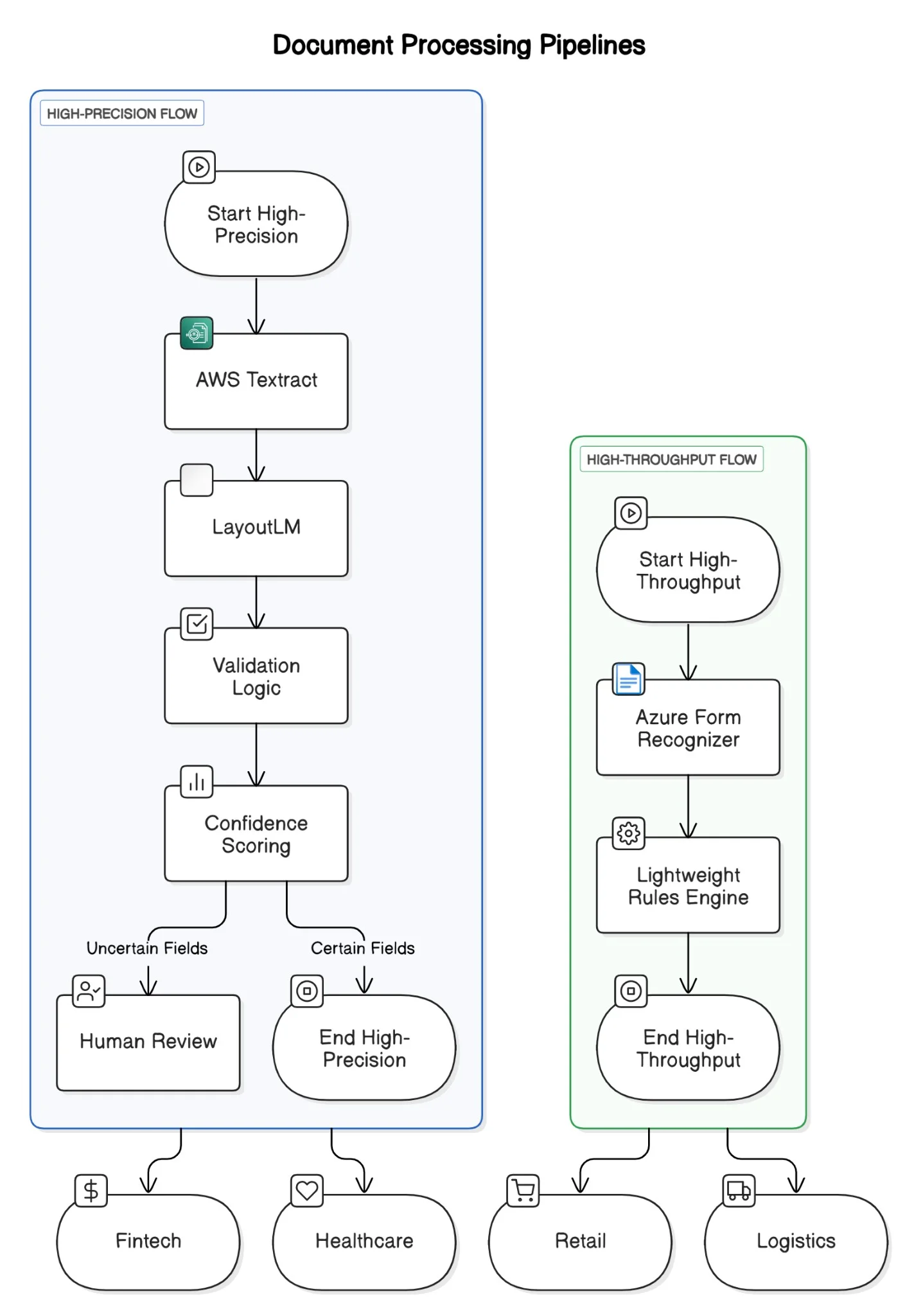
图 2. 文档处理——高精确性与高吞吐量流程
解码文档中的视觉元素
除了文本内容外,许多文档还包含传达关键含义的视觉标记——复选框、表格、签名、印章和徽标。传统的 OCR 通常会忽略或误读这些内容。
计算机视觉技术能够有效填补这一空白。物体检测模型(如YOLO和Faster R-CNN)可以识别复选框或徽标等元素。图像分割技术可用于解析表格和结构化布局。OpenCV 等工具可用于预处理——去除噪声、校正倾斜和增强对比度。在此基础上,LayoutLM 通过将位置编码与语言建模相结合,能够在整个文档范围内保持上下文的连贯性。
这些工具协同作用,使系统不仅能够解读文字内容,还能理解这些文字的呈现方式。
处理非结构化文档
非结构化文档——例如合同、法律备忘录或临床总结——缺乏明确定义的字段。从这类文档中提取信息需要理解其上下文。
这就是自然语言处理(NLP)大显身手的地方。针对特定领域(例如法律、医疗保健)进行微调的预训练语言模型可以识别关键实体,如姓名、日期、药物或义务。句子嵌入技术使系统能够将语义相似的段落组合在一起。将语言线索与布局特征相结合的混合方法取得了最佳效果。
这些技术在受监管的行业中显得尤为重要,因为在这些行业中,细微的上下文或措辞变化会完全改变文档的含义。
云服务:如何选择
基于云的文档 AI 服务让大规模文档处理能力的获取变得前所未有的便捷。用户能够轻松访问一系列强大的工具,包括用于 OCR 任务的预构建 API、文档分类服务、实体提取功能以及文档摘要工具等。这些工具能够快速得出结果,但没有两个平台的功能是完全相同的。不同的供应商专注于各自独特的优势领域,因此选择合适的服务对于构建生产级系统来说至关重要。
接下来我们对主要的供应商进行深入对比,并综合考量技术限制,做出能够有效支持业务目标的架构决策。
AWS Textract
对于那些已经融入 AWS 生态系统的企业来说,亚马逊的 Textract 服务是一个比较流行的选择。它在结构化表单和表格提取方面表现出色。其主要功能包括:
自动检测键值对、表格和复选框;
与 AWS Lambda、S3、Comprehend 和 Step Functions 等服务无缝集成;
对表单的布局有一定的识别能力。
不过 Textract 有时候会生成冗长且略显冗余的输出,在处理视觉上较为复杂或质量退化的文档时会存在不一致的情况。此外,如果需要处理大量的页面,尤其是使用AnalyzeDocument(对表格/表单单独收费)等功能时,成本可能会迅速增加。
最适合用于:金融服务或人力资源领域中的那些表单密集的工作流程,例如处理发票、收据、贷款申请或 W-2 文件等。
Google Document AI
谷歌的产品专注于特定文档类型的预训练处理器(例如发票、身份文件、W9 表单),并与谷歌的自然语言处理平台紧密集成。其主要优势包括:
强大的语言语义解析和上下文理解能力;
适用于非结构化和半结构化文档;
对于多语言和手写输入,OCR 识别准确度较高。
不过,由于模型透明度有限且缺乏足够的定制性,谷歌文档 AI 对于那些需要精细控制微调行为的组织来说吸引力不足。在处理已知且受支持的文档类型时,谷歌文档 AI 表现出色,但在处理新格式时灵活性较差。
最适合用于:寻求针对常见文档类型提供现成智能解决方案的企业,特别是在物流、旅行和客户服务等行业。
Azure AI Document Intelligence
微软的 Azure 文档智能(之前的表单识别器)以其定制训练能力脱颖而出。主要优势包括:
能够使用标记和未标记数据(无监督学习)训练模型;
支持表单字段、表格和选择标记;
文档分类、布局 API 和模型版本控制。
Azure 还提供模型生命周期管理集成能力,非常适合围绕文档处理构建 MLOps 管道的内部 DevOps 团队。不过它仍然需要大量的数据准备工作,并且可能对模板变化具有一定的敏感性。
最适合用于:追求灵活性与易用性平衡的组织,例如医疗保健、保险和合规性要求高的行业。
何时采用混合方法以及为什么
完全依赖单一云提供商可能会产生盲点。在现实场景中,大多数企业采用了混合策略,将预训练 API 的高效便捷性与定制化模型的精准度和可控性相结合,并从中受益。
以抵押贷款贷款人为例,他们可能会将 Textract 与自定义训练模型和人工审核环节相结合,用于验证自雇申请人的收入等高风险场景。这种分层式的方法,不仅有助于确保数据的准确性,同时也能有效管理合规风险。
例如:
使用 AWS Textract 或 Azure 表单识别器从标准表单中提取结构化字段。
对于需要精细布局或特定领域语义的文档,使用 LayoutLM 等开源模型进行增强。
引入验证层,对置信度进行评分,并将不确定的输出转给人工审核员或自定义模型。
混入 Google Document AI,用于长文档的语义分类、摘要或实体关联。
此外,使用Apache Airflow、Kubernetes或Azure Logic Apps等编排工具,可以有效地将这些服务整合为一个协调一致且具备高度可扩展性的数据处理管道。
将代码映射到文档智能管道
示例应用程序展示了图 1 中讨论的六阶段管道的关键阶段:
# modular_pipeline/# ├── capture.py# ├── classify.py# ├── extract.py# ├── enrich.py# ├── validate.py# ├── consume.py第 1 步 数据捕获 – 模拟 S3 上传触发器
# capture.pydef simulate_data_capture(): return { "bucket": "mortgage-uploads", "object_key": "paystubs/applicant_1234.pdf" }第 2 步 分类 – 基于文件路径的简单分类
# classify.pydef classify_document(object_key): if "paystubs" in object_key: return "Pay Stub" return "Unknown Document"第 3 步 提取 – 模拟 Textract 输出
# extract.pyimport boto3def extract_data(bucket, object_key): textract = boto3.client('textract') response = textract.analyze_document( Document={'S3Object': {'Bucket': bucket, 'Name': object_key}}, FeatureTypes=["FORMS"] ) extracted = {} for block in response['Blocks']: if block['BlockType'] == 'KEY_VALUE_SET': key = block.get('Key', 'Unknown') val = block.get('Value', 'Unknown') confidence = block.get('Confidence', 100) extracted[key] = {"value": val, "confidence": confidence} return extracted第 4 步 增强 – 基于规则的逻辑(例如,推断支付频率)
# enrich.pydef enrich_data(extracted_data): enriched_data = extracted_data.copy() try: income = int(enriched_data["Gross Income"]["value"].replace("$", "").replace(",", "")) enriched_data["Pay Frequency"] = "Monthly" if income > 5000 else "Biweekly" except: enriched_data["Pay Frequency"] = "Unknown" return enriched_data第 5 步 验证 – 置信度评分
# validate.pydef validate_data(enriched_data): if isinstance(info, dict) and info.get("confidence", 100) < 85: return True # review required return False第 6 步 消费 – 下游集成或手动审核决策
# consume.pydef consume_data(enriched_data, review_required): if review_required: return "Flagged for manual review" else: return f"Data stored: {enriched_data}"这个工作流可以被轻松扩展以支持更多文档类型,可以集成布局感知模型,如 LayoutLM,并接入 Airflow 或 Step Functions 等编排系统,从而实现生产规模的部署。
适用于现实世界的可伸缩架构
可伸缩性并不是锦上添花,而是必需品。系统必须能够应对批量加载、实时提交以及介于两者之间的各种情况。
例如,在利率波动或政策公告发布期间,抵押贷款业务流程常常会遭遇流量的骤然激增。此时,采用基于微服务的架构和像 Kafka 这样的队列系统有助于吸收负载并保持平稳的吞吐量。
健壮的架构通常具有以下特点:
用于隔离每个管道阶段的微服务架构;
用于解耦通信的 Kafka 或 Pub/Sub 队列;
用于容器编排和实现可伸缩性的 Kubernetes;
用于缓存常见查找或推理结果的 Redis;
用于处理原始文件和结构化输出的对象和关系数据存储。
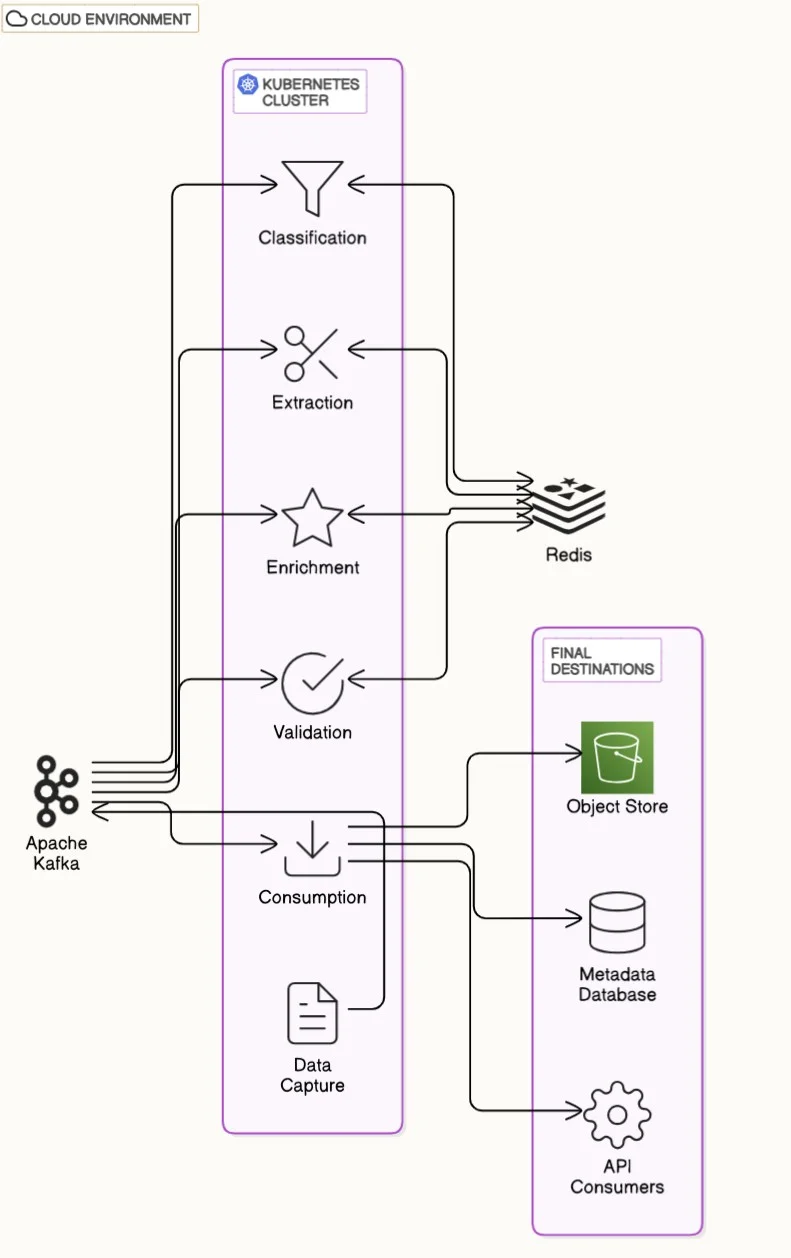
图 3. 文档处理 - 使用事件驱动架构实现可伸缩性
实现时实际会面临的挑战
在现实环境中部署此类系统时往往会暴露出一些棘手的问题:
安全性:在传输过程中和静止状态下加密文档,尤其是涉及个人身份信息(PII)时。
数据标注:特定领域的训练数据整理成本高昂。
运营成本:OCR 和 NLP 推理可能是计算密集型的。
质量保证:在字段级别评估准确性,而不只是根据整体成功与否来判断质量。
人工参与:对于容易出错或高风险的提取,人工审核依然重要。
行业案例研究
J.P. Morgan 的 COiN(合同智能)平台利用人工智能将复杂法律合同的审查时间从每年 36 万小时缩短到几秒。这一创新之举极大提升了银行合同管理的效率与准确性。
Pennymac将文档处理时间从数小时缩短到几分钟。
文档智能的未来
文档智能领域正在经历一场深刻的变革,从简单的字段提取迈向语义理解与持续学习的新时代。新兴技术使系统不仅能够阅读文档,还能理解其结构、意图以及在特定情境中的相关性。以下是塑造企业级文档处理未来的四大关键创新:
多模态 AI 模型实现更丰富的理解
传统的文档处理系统主要依赖文本数据,通常会结合基本的布局信息。然而,下一代文档 AI 系统会利用多模态学习,并结合三种关键输入:
文本(语义内容)
布局(元素之间的空间关系)
视觉特征(图像、复选框、徽标、印章)
一些模型,如LayoutLMv3和DocFormer正在这一领域大放异彩,它们将这些不同模态的信息嵌入到统一的表示框架中。这极大提升了系统对复杂格式文档的处理准确性,例如表单、报告、医疗处方和合同等。例如,如果仅靠文本信息,系统无法判断复选框是否被选中,或者签名如何在视觉上锚定相关内容,而这些恰恰需要多模态上下文。
随着越来越多特定行业的预训练模型的出现,组织能够在小型数据集上对这些模型进行微调,无需进行大规模的标注工作即可取得行业领先的成果。
上下文推理与自动摘要
只是提取数据还远远不够,组织需要的是能够对文档内容进行推理、理解其中的含义、进行推断并提供切实可行的见解的系统。这一转变推动了以下领域的发展:
自动摘要,模型能够将长文档提炼成摘要(例如,从 20 页的法律合同中总结出关键的义务和风险点)。
上下文理解,系统综合考虑周围文本、特定领域的本体论以及历史模式,并推断出意图和关系。
例如,在处理保险索赔时,仅提取日期和保单号码是不够的——系统还必须根据文档的上下文和过去的案例判断索赔是否合法、紧急或是否具有欺诈性。用结构化内容微调过的GPT风格的变换器在这一过程中发挥着重要作用。
基于置信度和风险的智能工作流编排
目前的 AI 文档处理管道系统通常对所有输入都应用相同的规则,不过未来的系统将引入智能路由机制,根据提取数据的置信度水平以及与错误相关的业务风险动态调整处理路径。
以下是现实世界中的策略示例:
抵押贷款处理系统:能够自动将提取置信度低或数据值不一致的文档转至人工审核。
零售系统:在处理低价值交易(例如收据扫描)时接受置信度较低的结果。
这种自适应路由机制由置信度评分、业务规则引擎以及风险加权决策树的协同作用,确保人力被应用于真正增值的地方。
通过持续的人工参与学习来提升准确性
随着文档模板的演变、法规的变化以及用户期望的转移,静态模型会随着时间推移而退化。文档智能的下一阶段将拥抱人机反馈循环,其中手动审核和异常处理的见解将被系统地重新整合到模型重新训练中。
这包括:
捕获人工审核员所做的更正;
记录模型失败或弃权的边缘情况;
使用弱监督或强化学习来提升未来的性能。
支持主动学习管道的平台——其中人工输入能够直接指导模型细化——优于那些需要定期手动重新训练的平台。在可追溯性、透明性和准确性不容妥协的受监管环境中,这一点尤其关键。
总之,文档智能的本质并非取代人类,而是通过具备越来越强的情境感知能力、自我改进能力和智能设计的系统来增强人类的能力。从单纯“阅读”文档到理解并推理内容的转变,这不仅仅是技术上的演进,更是那些追求无妥协自动化的企业的战略必然选择。
在你的组织中应用文档智能
将关键文档类型映射到六阶段管道。
确定哪些云服务和开源工具符合你的准确性、成本和合规性需求。
建立反馈循环,持续改进模型。
根据置信度阈值和业务风险优先考虑智能路由机制。
提前布局可观测性、缓存和编排,实现生产规模的部署。
参考资料:
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/articles/ocr-ai-document-processing/





/filters:no_upscale()/articles/ocr-ai-document-processing/en/resources/98figure-1-1745916137123.jpg?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE3NDc5Njg1MTEsImZpbGVHVUlEIjoicG1reGQyZFhXMGlueUJrTiIsImlhdCI6MTc0Nzk2ODIxMSwiaXNzIjoidXBsb2FkZXJfYWNjZXNzX3Jlc291cmNlIiwicGFhIjoiYWxsOmFsbDoiLCJ1c2VySWQiOjk3MTk2NjMxfQ.ppSldZjlIjrtHXeSUethO9U74oXZeaT-5WTFnLCnpLA){kind=link}
/filters:no_upscale()/articles/ocr-ai-document-processing/en/resources/77figure-2-1746076957670.jpg?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE3NDc5Njg1MTEsImZpbGVHVUlEIjoicG1reGQyZFhXMGlueUJrTiIsImlhdCI6MTc0Nzk2ODIxMSwiaXNzIjoidXBsb2FkZXJfYWNjZXNzX3Jlc291cmNlIiwicGFhIjoiYWxsOmFsbDoiLCJ1c2VySWQiOjk3MTk2NjMxfQ.ppSldZjlIjrtHXeSUethO9U74oXZeaT-5WTFnLCnpLA){kind=link}
/filters:no_upscale()/articles/ocr-ai-document-processing/en/resources/66figure-3-1745916137123.jpg?accessToken=eyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE3NDc5Njg1MTEsImZpbGVHVUlEIjoicG1reGQyZFhXMGlueUJrTiIsImlhdCI6MTc0Nzk2ODIxMSwiaXNzIjoidXBsb2FkZXJfYWNjZXNzX3Jlc291cmNlIiwicGFhIjoiYWxsOmFsbDoiLCJ1c2VySWQiOjk3MTk2NjMxfQ.ppSldZjlIjrtHXeSUethO9U74oXZeaT-5WTFnLCnpLA){kind=link}