

本文整理自九章云极 DataCanvas 技术副总裁于建岗在 DIVE 全球基础软件创新大会 2022 的演讲分享。
以下为于建岗的演讲精华,经编辑。
在金融业数字化应用以及转型过程中,从传统的关系型数据库的数仓建设到基于大数据的批式处理,再到现在对于基于实时处理的业务应用发展历程中,如何建设面向流批一体,数据湖存储,实时数仓,实时风控、指标引擎和规则引擎成为新一代发展迫切需要解决的问题。本文将从计算引擎,存储架构中和大家一起探讨如何帮助金融从业者从数字建设上满足实时场景的需求。
九章云极 DataCanvas 简介
九章云极成立于 2013 年。我们专注于自动化的数据科学平台的持续开发与建设,从 AutoML 到面向 AI 从业者提供一整套的开发平台,主要为金融企业、金融科技,还有政府、工业、制造业做智能化升级和转型提供配套服务。

九章云极很多的产品都是我们自主研发的产品矩阵。目前已经为政府、金融、通信、航空、交通、教育、地产、互联网等行业提供了很多的 AI 能力建设。九章云极 DataCanvas 的大数据 AI 平台不仅仅提供了自动化机器学习的建模和计算引擎,同时也面向业务分析师提供服务,比如说像一些金融从业者,他们更希望提供一些 low code 低代码的分析服务,做一些面向业务的数据建模方面的服务,为此,我们提供自动化模型的创建,包括面向业务的自动化建模,还有基于业务场景的解决方案等方面的一些应用的支持。
这是我们新一代的自动化数据科学平台,主要有两款产品。第一个是 DataCanvas APS 机器学习平台,它是一个贯穿了整个机器学习的 AI 模型的全生命周期的开发平台。它不仅仅包括数据准备、数据抽取、特征抽取、模型构建、训练、发布,还包括服务监控,提供 AI 中台能力这么一整套服务,当前我们也在做一些 ModelOps 方面的探索和产品。
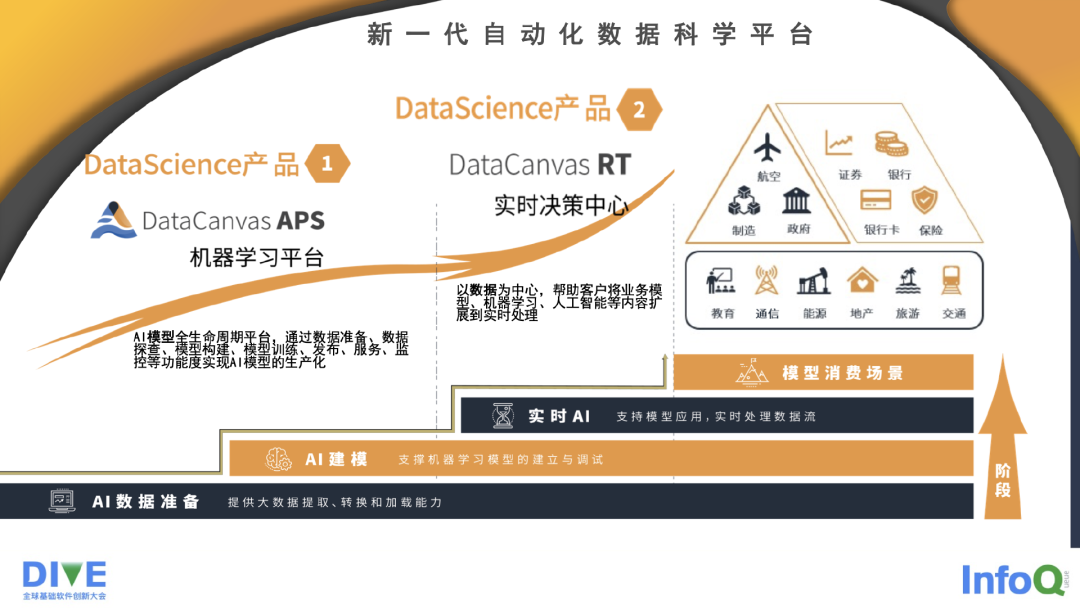
第二个方面就是本次分享的主题——DataCanvas RT,我们的实时决策中心平台。它主要是以实时数据处理、计算为中心,能够帮助客户把原有的业务模式从离线的计算过渡到实时计算方面来,而不仅仅是数据的实时计算,还包括实时的机器学习,实时的建模服务。
我们的核心消费场景,不仅仅面向了金融、证券、银行、保险这方面的金融业务,同时我们在非银业务方面也开拓了很多的市场,包括为通信、交通,工业、企业制造等提供服务。
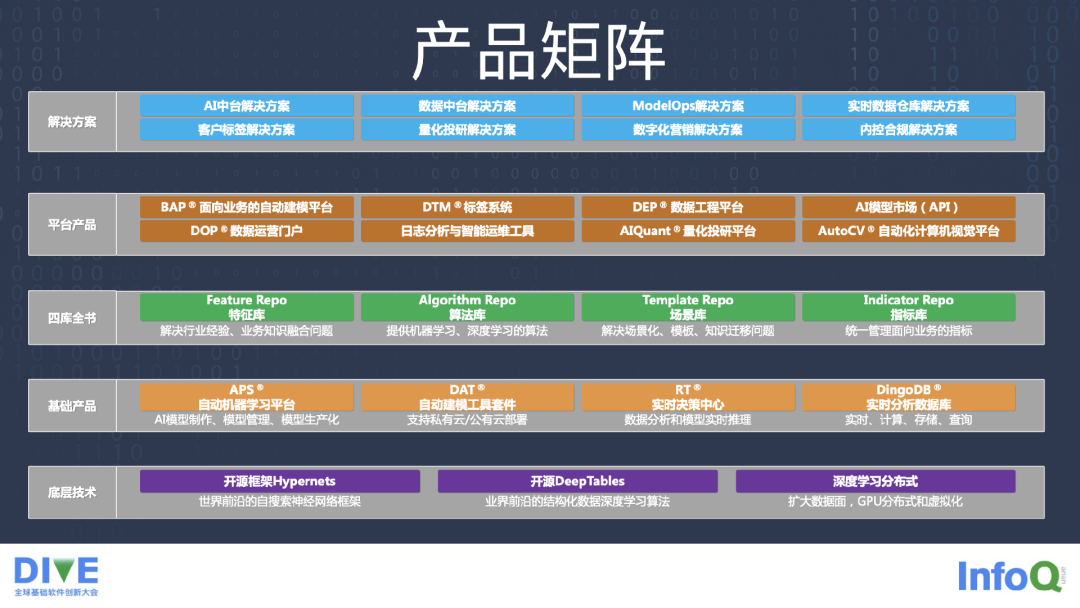
下图是九章云极 DataCanvas 的产品矩阵。
金融行业实景
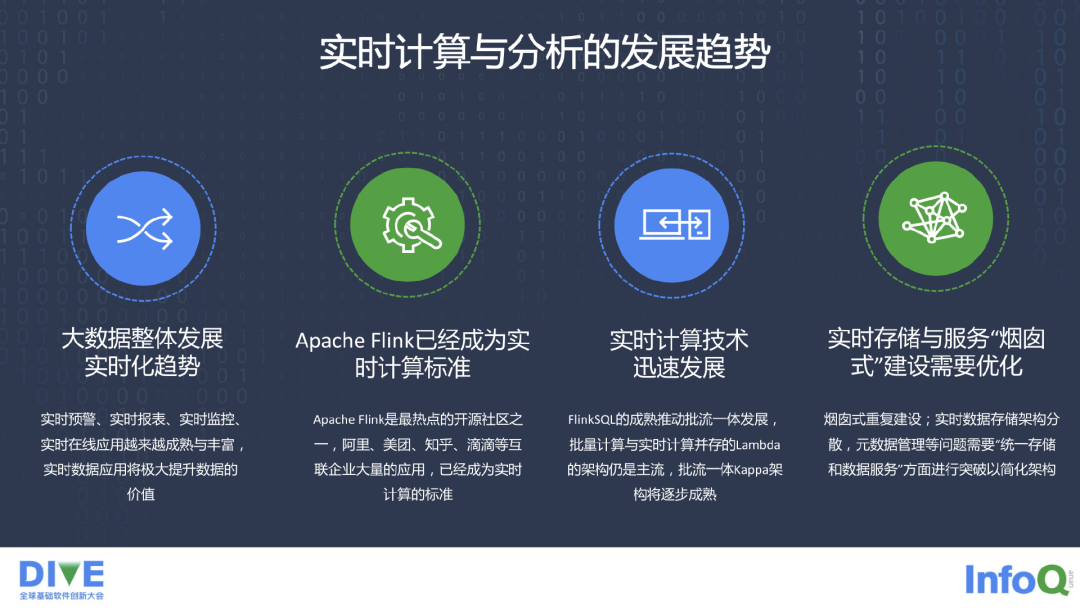
现阶段,大数据技术在金融领域的应用呈现出几个特点。
第一是实时计算与分析。大数据的发展也十几年了,现在大家逐步地在做实时计算,最早从基于 Apache,基于 Hadoop 的 MapReduce,基于 Spark 的处理,甚至于 Spark 提供了 Storm 的平台去做一些流式的处理,到现在很多我们所服务的一些机构和企业,他们对于实时计算提出了更多的要求,比如需要实时预警,实时报表,甚至于在 BI 方面的、实时报表方面的快速处理,实时的监控,实时的计算。比如说在银行做实时事中阻断,这都为实时计算的发展提出了切切实实的业务方面需求的紧迫性。
第二个方面是在 Apache Flink 方面,目前大家也知道,它已经成为了实时计算所谓的一个标准,不管是头部的互联网公司,还是很多创业公司,当然也包括我们,基本上 Flink 已经成为了一个大多数公司在实时计算方面的选择。
第三点是,实时计算的技术发展非常迅速,我们做实时计算,是希望能够把存储和计算分开来做。在计算上,我们希望不仅仅是为了从业者、开发者来去做,我们有大量的基于过去的离线数仓,或者过去的离线计算的一些从业者,他们对 SQL 方面的一些工作比较熟悉,我们期望 Flink、 SQL 这块还是能够把他们的原有的一些技术的沉淀和技术的能力,能够更好地去结合到实时计算方面的一些应用上去,也能够简化他们的学习曲线。
第四点,既然讲到了实时,并不是要对过去做的离线计算做一个纠正,或者是说要抛弃它,现在实时和离线应该是并存状态,或者说一个更好的说法是,怎么能够更好统一存储和服务。我们不可避免地要涉猎这方面的事情,而且是比较重要的事情,做到避免烟囱式的重复建设,这对我们来讲也是非常重要的一个需求。
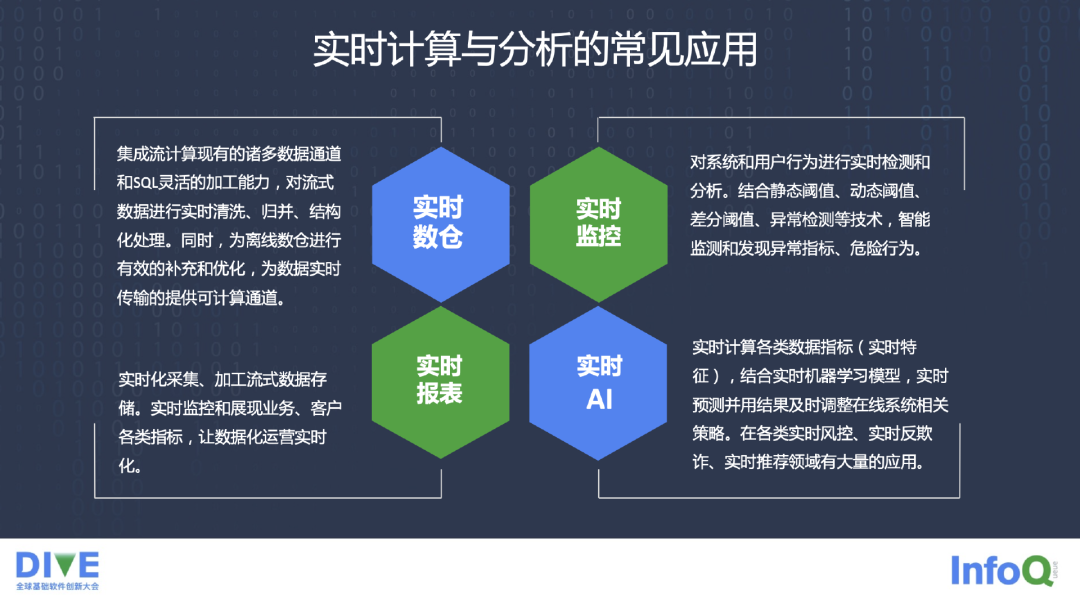
实时计算的一些常见的应用,一个是实时报表的 BI。第二是实时监控,很多监控是希望能够实时传过来,不希望在过了很长时间以后才出来监控,现在大家都普遍希望能够在毫秒级别去做一些事情。
第三是实时数仓,金融机构的数仓建设发展了这么多年,数仓里有大量的人才,数仓的分层,数仓的建模的理论,如何对前端业务通过数据的分析、建模的分析,把数仓一层一层建起来,这个过程耗费了大量的人力和知识体系。在实时计算这种场景下,实时数仓也越来越迫切。
第四是实时 AI,既然做了实时的处理,做了实时数据的采集和实时数据的计算,我们最终还是希望用 AI,用建模服务,用模型的一些服务更多为业务去用 AI 来赋能。实时的、AI 的建模服务,就比较顺理成章成为实时计算与分析的一些应用了。
业务场景的分类,大致分成三类。我们有几个比较通俗的字,第一个叫做搬,第二个叫做算,第三个叫做存。第一个是类似于实时 ETL 场景的一些应用,比如以前用 Hadoop 来做 ETL,现在我们更希望用实时的方式来实现 ETL,我们叫做搬,就是搬数据,数据从一个 Source 去搬到一个 Sink 里面,这中间需要做一些计算,做一些实时的处理。
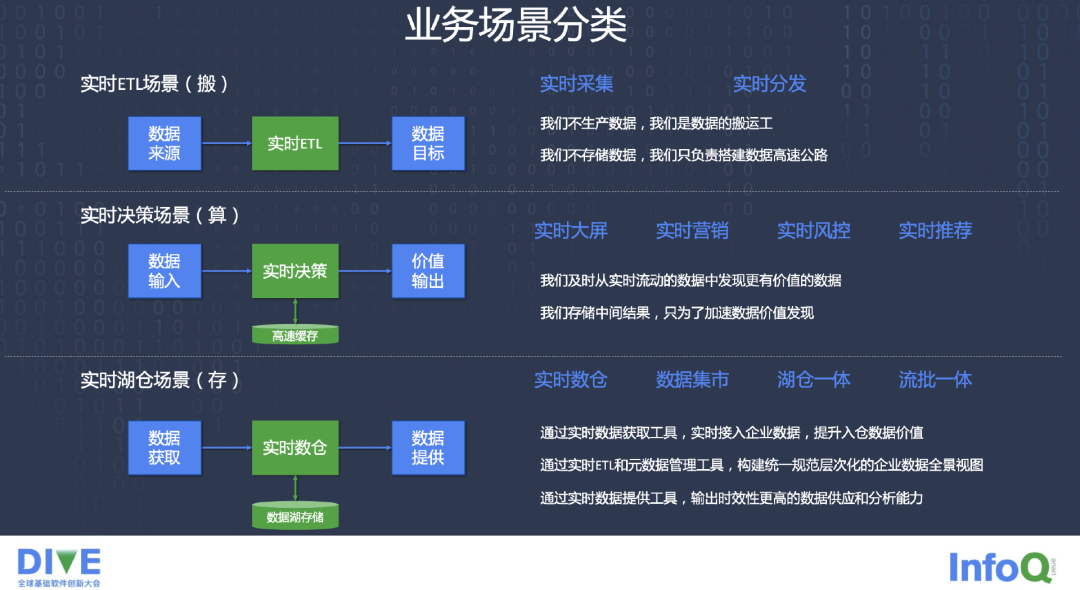
第二个实时决策的场景,包括要做实时的营销,实时的风控,要做决策引擎,要做规则引擎。我们就不仅仅是搬一个数据了,不仅仅是做 ETL 了,需要把数据在这里面进行一定方式的加工,再通过实时的方式去做价值的输出。
第三个就是存了,计算和存储比较重点的针对的解决方案,就是实时数仓的建设。而且特别是现在数据湖建设大家也开始摸索起来了,原来基本上是存在于自己的 Hadoop 上,或者是存在于自己的硬件的设备上。在数据湖这块,更希望能够使用大量的以 Object 为存储的廉价存储方式,在兼顾离线和实时方面怎么能做一些实时数仓,为企业做企业数据的价值服务。
目前很多企业的典型解决方案,批量计算和实时计算已经是两条线,这也是大家常说的 Lambda 场景,批量计算原来的一条线还是从 MR、Spark、Hive 存到 HDFS 上,然后做一些 Batch job,后边会经过一些 Query 引擎,包括 Drill,Presto,Query 等方面的工作。在应用方面,业务上我们有实时大屏、预警监控、实时报表和营销推荐等方面的应用。
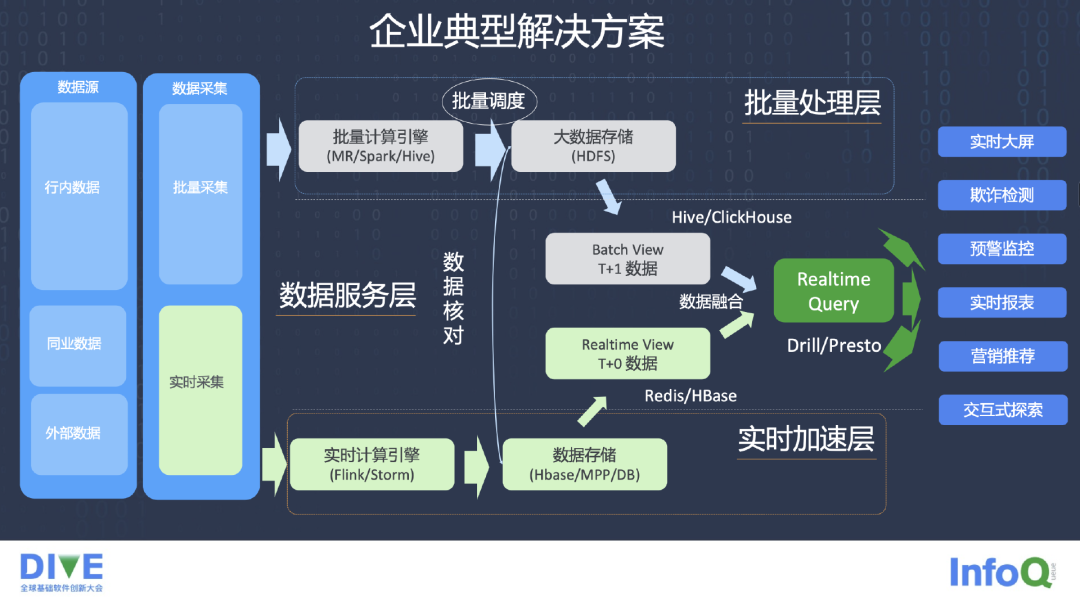
第二条线是基于 Flink 和 Storm 的实时的计算引擎,我们同时也存到比如 HBase 或者其他的 MPP 的存储数据结构上去,或者 DB 上去,去做 T+0 数据的 View。在这个方面,我们要做大量的数据的核对,而且把很多工作交到了数据应用层,在数据应用层,怎么去解决核对数据的问题。由于需要两套代码来做同样的一个业务的需求,造成了很大的麻烦,即使写 SQL 取数据也是两套不同的 SQL,企业逐渐地意识到这种解决方案存在很大的问题。
总结而言,上述方案存在一些痛点,第一是数据融合难,批计算、实时计算如何融合;第二是数据的一致性,数据多引擎的复制、存储,这不仅仅浪费了数据存储的介质,也为数据的一致性提供了很多难以解决的痛点。第三时数据服务能力很弱,这样做并发能力不高。此外是在目前的状态之下,服务、计算、存储很难一体化。

九章云极 DataCanvas 实时产品介绍
本部分重点介绍一下,在看到上述需求和痛点后,九章云极是如何做一款实时的产品的。
九章云极的 DataCanvasRT,从 Alpha,到 Beta,现在已经是到 3.0 的版本了,我们做了很多的关键特性。
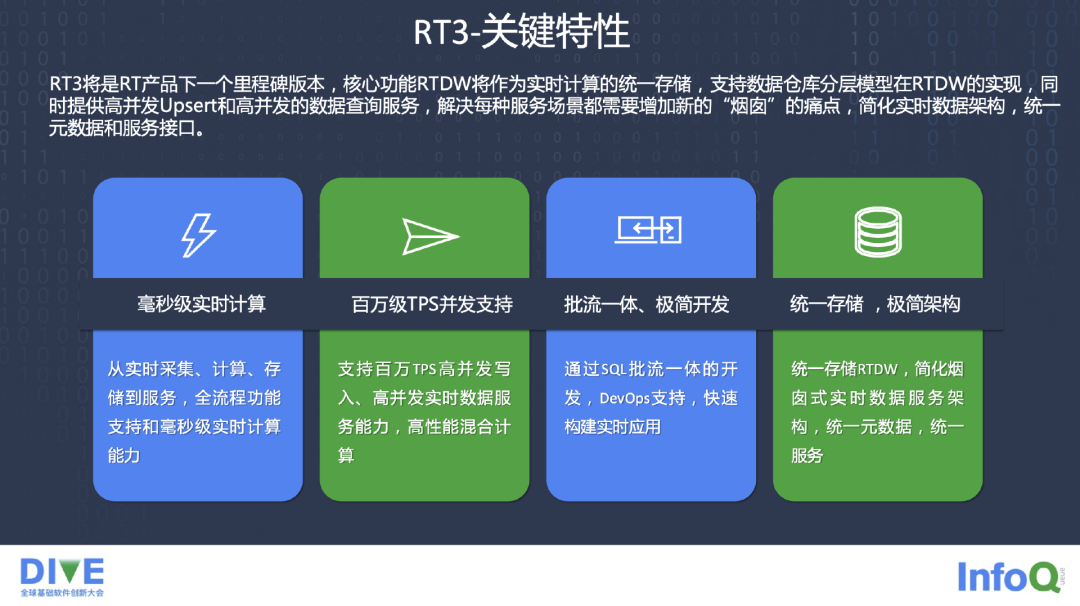
第一,RT 产品是毫秒级的实时计算,从实时的采集,采集包括了常用的一些 File,还有大量的 CDC 的 Connector,从现在常存的 Database 里实时地通过 Binlog 方式来采集数据,同样我们也还有其他的一些 Connector 去存储数据。
第二是百万级的 TPS,因为实时需要大量的查询,我们在 TPS 这块提供了并发的支持。第三个比较重点的就是批流一体,希望能把开发做到极简化,通过 SQL 的批流一体的开发,同时 DevOps 方面支持快速构建实时的应用,RT 也是基于 K8S 来部署的。第四,我们做了自己的统一的存储 DingoDB,不仅提供列存储,同时也提供行存储,不仅提供点查,也提供 AP 的一些服务,在 Sering 和 AP 方面能够提供统一的支持。
RT 的 3.0 技术架构,最底层是实时的采集,中间是 RTDW 存储层,存储层分为 ODS、DWD、DWS 等层。其中,元数据管理很重要,因为牵扯到存储管理、批处理和流处理等方面的元数据的统一化。上面的统一开发分为实时计算、实时分析、时时决策、实时 ETL。
实时计算包括窗口计算、规则计算。有些规则的计算,希望能够通过实时的方式来运行,而不是扔到 Kafka 里面,接收方从 Kafka 里面拿到数据再做计算,这样在实时性方面就满足不了要求。
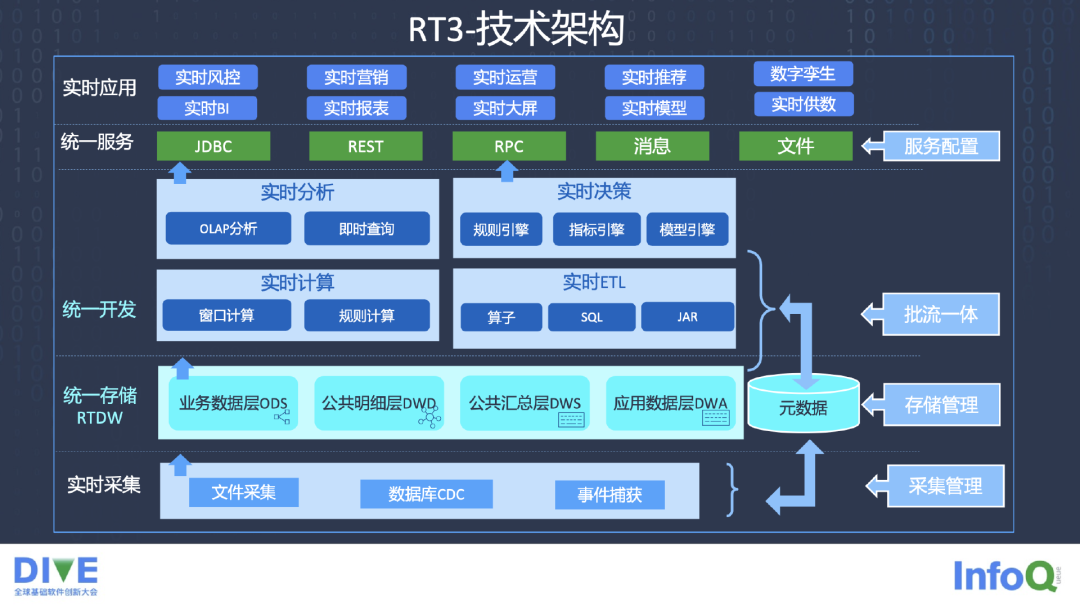
实时分析,同时支持 OLAP 分析,包括支持 Clickhouse,包括支持 RT 存储,也支持 AP 大量的查询。实时的决策,规则引擎、指标引擎,模型引擎这三个引擎在里面做决策支撑的工作。
实时 ETL 提供一些算子,基于 Flink 开发一些算子、模板,还有基于 Flink SQL 的一些支持,同时也支持以 jar 包的方式用实时 ETL 做很多的工作,比较友好。
我们也提供统一的服务接口,不管是 REST 接口,还是 RPC,还是 JDBC 方面服务的接口都支持。
在逻辑架构方面,我们的实时数仓对数据资产、数据项目进行分层,右侧的 DIM 维度表作为支撑。后面有一站式的开发平台,既满足开发人员,也满足前端的业务人员在上面做流式的作业和查询的服务,最终为业务提供实时的数据服务。
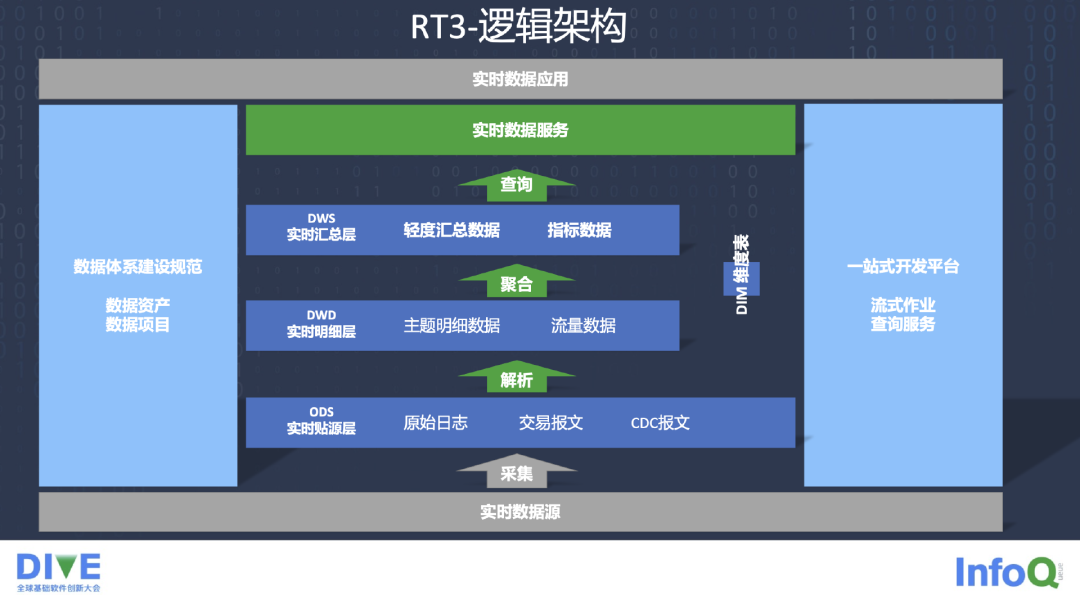
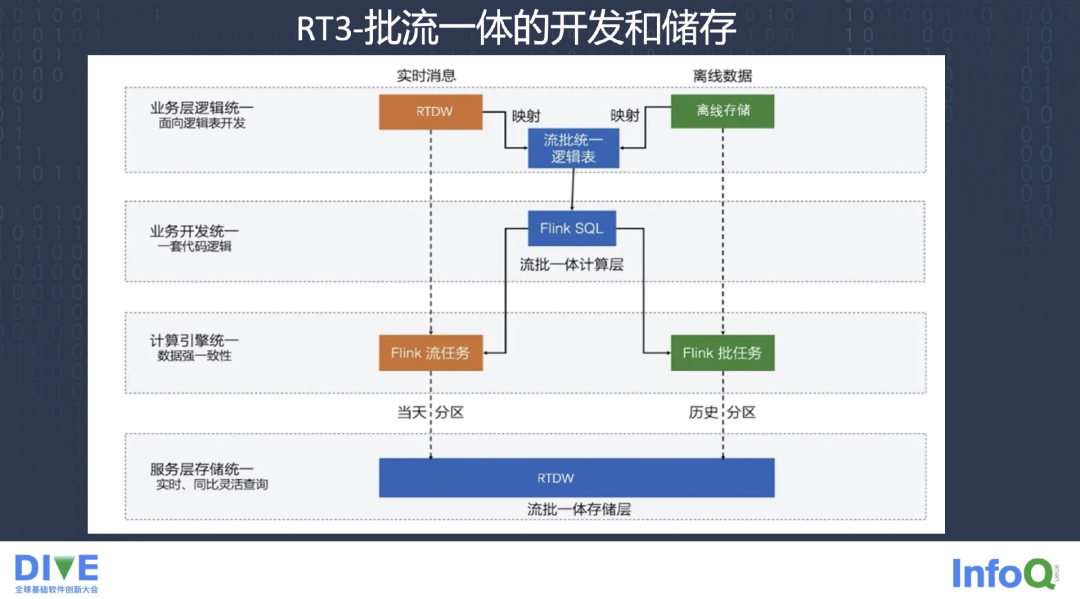
底层的流批一体的存储层 RTDW,上面做了 Flink 的一些流任务,Flink 的一些批任务,提供 Flink SQL 查询操作,还有一些算子的操作,最后是流批统一的逻辑表。因为流批统一做表上的映射,元数据管理有一些要放到离线存储,有一些是实时推送。
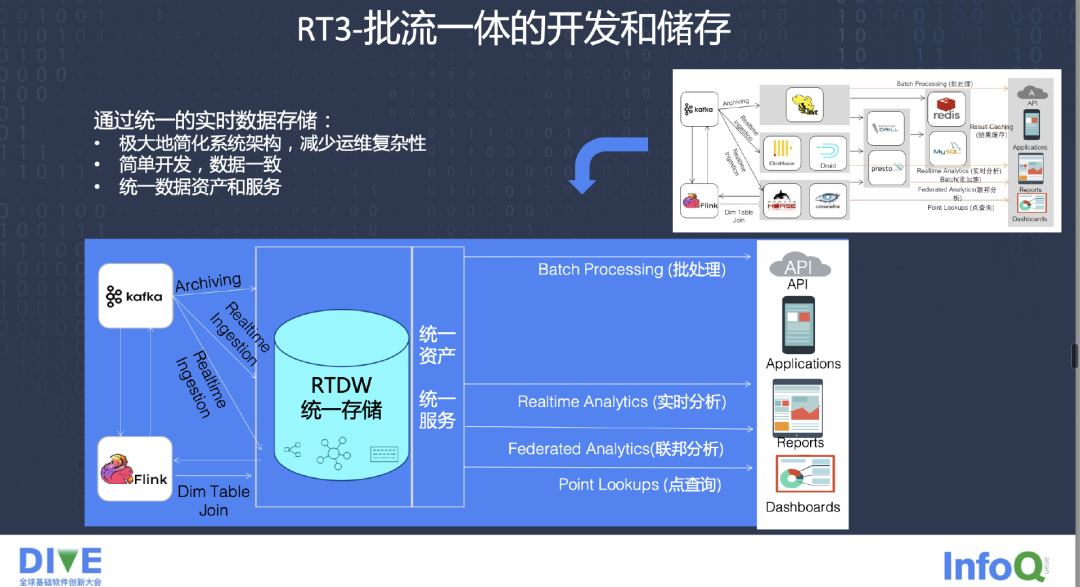
最早的 Lambda 架构带来了很多难点和痛点,现在通过 RT3.0 的方式,统一资产、统一服务,统一基于 Flink 的流计算的接入,去解决后面几种不同的 Application 的需求,包括实时分析、点查、批处理,BI Dashboard、实时计算。
目前大家很多都讲到了数据湖的形态,在可预见的几年之内,我们认为大数据发展需要统一计算存储服务。我们希望能够把实时数仓和数据湖并列,相互交互,为企业提供实时的、海量的数据的交换,甚至于数字化的服务。
传统的数据仓库慢慢要过渡到实时的数仓,在这一块我们也做了一些工作,从数据源进来以后实时数据入湖,Delta 数据入湖,入湖后,RT 做加工关联,在这个过程中根据业务的需求,比如实时数仓建模的思想,建模的理论,数据分层的理论,映射到对应的业务需求,来建设数仓模型。最后进行数据归档,我们还面向一些应用提供数据沙箱类服务。

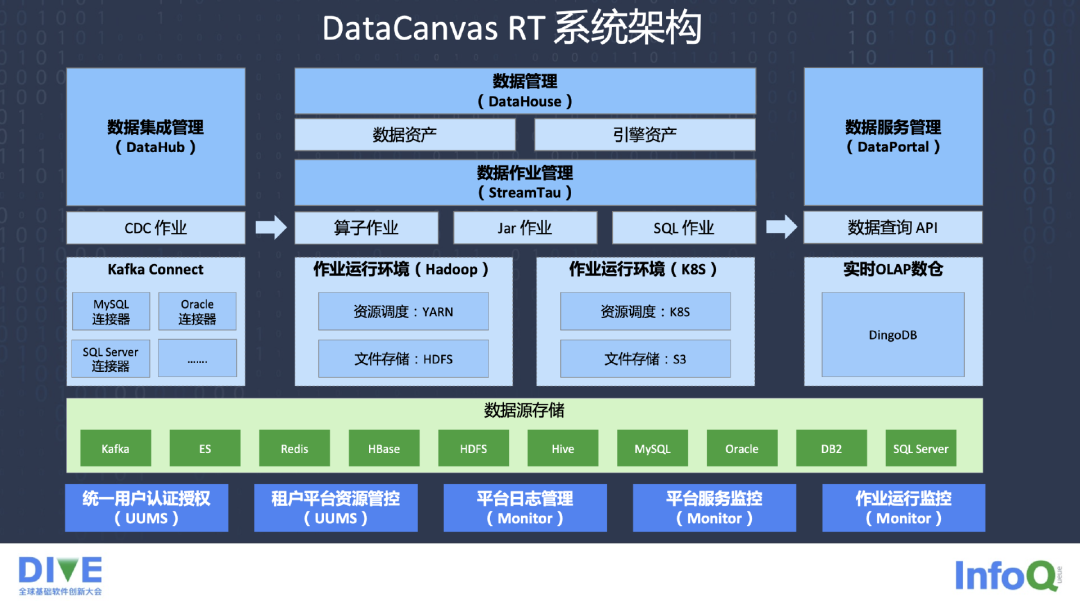
下图是 DataCanvas RT 系统的架构,有 DataHub,CDC 作业等管理 CDC Connector,Kafka Connector 会连接很多原来的关系型数据库,负责取数据。中间的计算和引擎是分离的,有自己的作业管理,包括算子作业,Jar 作业,还有 SQL 作业。
在部署方面,我们支持基于 Hadoop 部署,或者是更 Prefer 基于 K8S 的一种调度,基于云原生做了部署服务。在数据服务管理上,DataPortal 数据查询的 API 对外提供服务,我们基于 DingoDB 做了自己的 OLAP 数仓,大家都知道用 Clickhouse 多多少少都有一些不同的问题去解决,所以我们自己开发了 DingoDB 来应对这些问题。
下面简单介绍下 DingoDB。DingoDB 是什么,我们为什么要开发 DingoDB?
我们希望做到批流一体,希望做到统一的数据存储,基于分布式的对象存储提供了历史数据,离线的数据和实时数据的一体化的持久化的存储。第二我们提供了统一的数据服务,提供几套服务接口,希望提供高并发的、毫秒级的数据查询。
数据计算、数据存储、数据服务等都是 One Data 的理念,One Data Storage,One Data Server,对外不需过多考虑存储处理。离线系统和在线系统,同时兼顾这方面的需求。
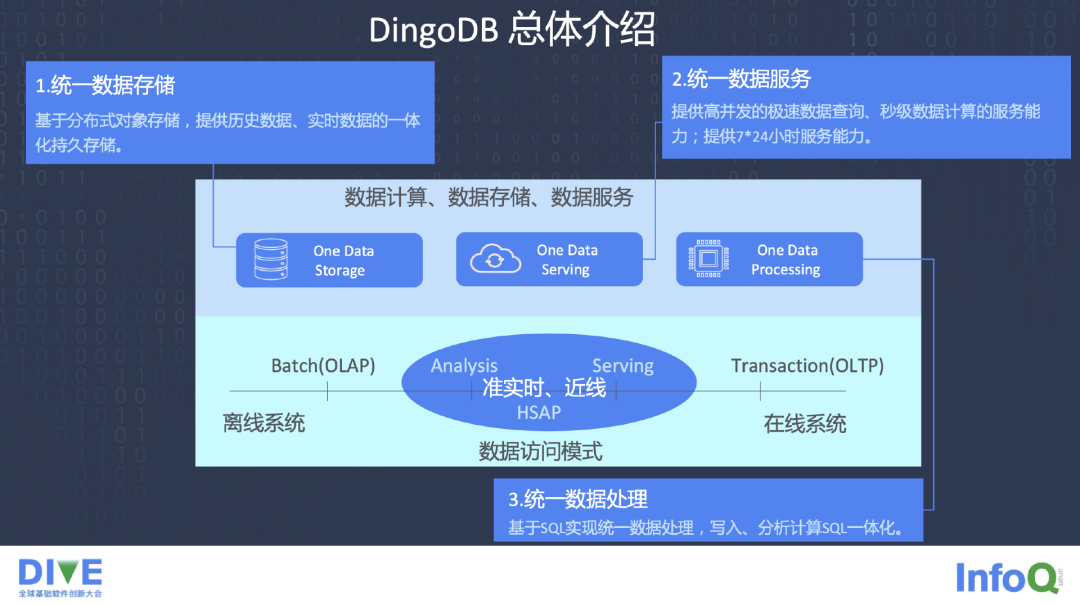
DingoDB 具有很多技术亮点,第一是存算分离。第二,考虑到冷数据和热数据的存储,冷数据更多存储在分布式里面,热数据更多存在本地,能提供一些快速的数据交换服务。
DingoDB 同时提供丰富多样的 Connector,数据的接入,包括 CDC Connector,File Connector,同时我们提供弹性扩容,因为都基于 K8S,基于一些动态集群管理去开发的 DingoDB。智能优化器方面不只是支持行,也支持列,支持混合存储模式切换。
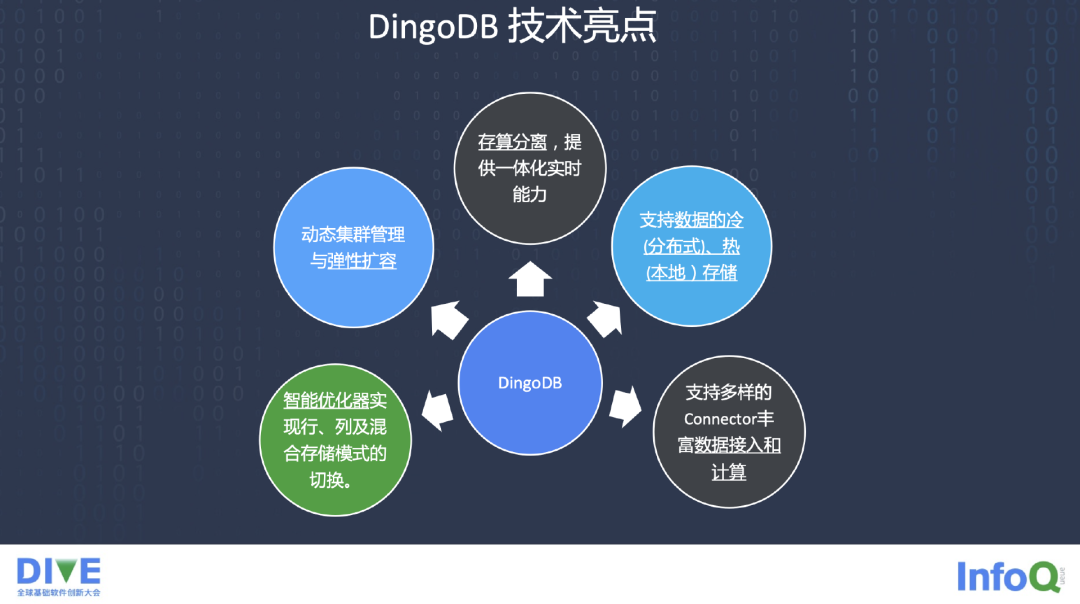
DingoDB 是存储分析的服务一体化的引擎,最底层支持 S3 的存储,也支持 Storage。上面是 Local 的 Storage,包括热数据和冷数据。实时的 Serving,一些分析引擎是分布式的方式。中间是 Dingo 的 Storage Cache Layer,这里面做计算。上面是 Computer Layer,做一些优化,做一些 Scheduler,Meta Data 的一些 Service 也会在里面去做,保证元数据一体化的列和行的存储,还有 Route Table 提供路由服务。
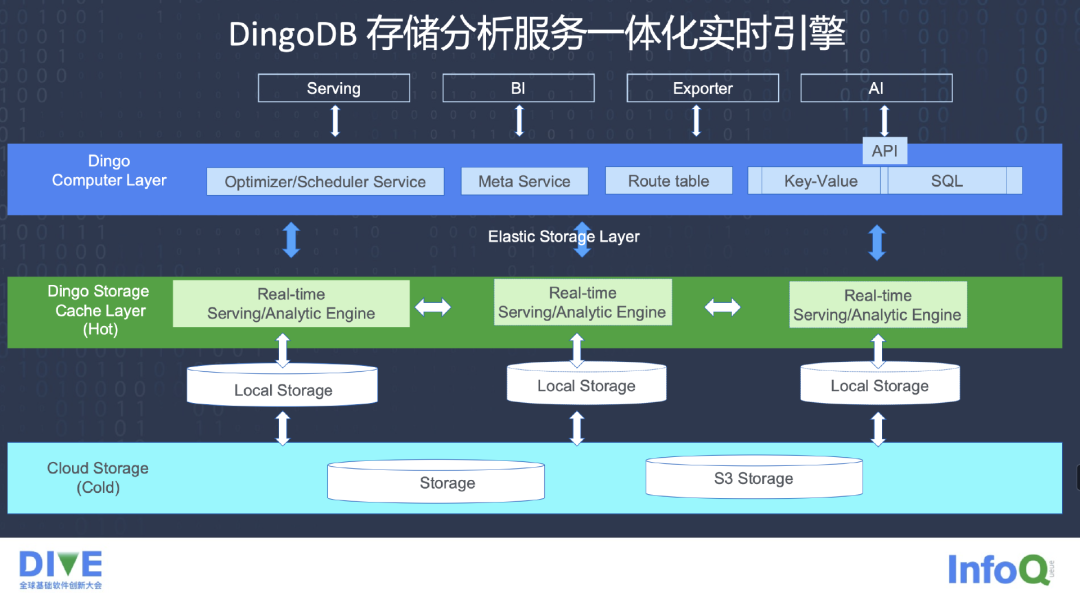
下图是 DingoDB 的逻辑架构,我们支持 Insert、Update、Upsert、Delete、Query 的一些 Request,Meta Cluster 里有自己的 Coordinator。我们有自己的 Row Format,还有 Column Format 提供基于行和列的一些服务。最下面是基于分布式存储的 File 系统,最底层有一些安全管理的 Layer,承担一些安全与 User 管理方面的工作。
九章云极 DataCanvas 解决方案架构
在湖仓一体方面,我们做了一些流批融合的架构,通过统一的流式的接入,利用 Flink 的 CDC 检查,CheckPoint 的机制来提供断点恢复的能力。数据湖层面,我们支持多种异构数据源的接入,既支持流的,也支持批的,一套系统、一个技术栈能支持两套的需求。
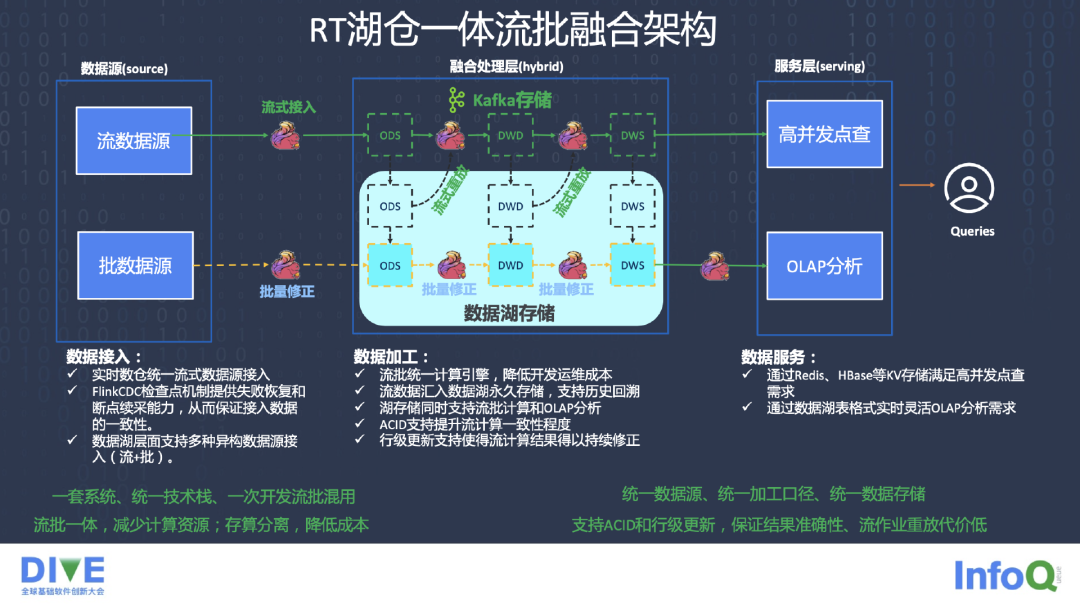
在数据加工方面,我们的统一的计算引擎可以降低开发的运维成本,流数据汇入湖里永久存储,同时也支持一些历史的回溯,湖存储的同时能够支持一些 OLAP 的分析,也支持 ACID,行级的更新支持使得流计算结果得以修正。数据服务方面,通过一些数据湖的表格的方式提供灵活的 OLAP 的服务,也提供 Redis、HBase 等 KV 的方式存储,满足高并发的点查的运行的需求。
相关阅读:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论