

本文讨论 Uber 技术栈较底层的部分,关注其余内容请参考下篇“ The Edge and Beyond ”。
Uber 技术
Uber 的使命是要让交通可靠得像人人随处可用的自来水一样。要实现这个使命,我们生成并处理着非常复杂的数据,再把它们用平台的方式梳理得整整齐齐的,让司机可以获得订单,让乘客自由出行。
截图为 2016 年春季纽约、中国和印度的 Uber 乘客 App 界面
我们希望能把 Uber 的 App UI 设计得简单易用,而后台支撑系统可以很复杂,来处理复杂的交互和大量的请求。为了支撑业务量的快速增长,我们把最初的单体架构拆散成了许多小块以方便扩展。在有了数百个相互依赖的微服务之后,现在要想画出一张Uber 系统的工作流程图已经相当困难,而且还演进得非常快。在这个上下两篇的系列文章中我们也只能简介2016 年春天的架构。
Uber 技术的挑战:没有免费用户和飞速发展
与许多非常成功的软件公司一样,我们也面临着相同的全球发展问题,但不同的是:1)我们才刚成立六年,所以我们还没能完全解决;2)我们的业务是实时地和真实世界打交道的。
2015 年四月,Uber 运营的 300 个城市在地图上的分布情况
与“免费 + 增值服务”的模式不同,Uber 只有付费用户:过去是乘客和司机,现在又增加了外卖和导游。人们要靠我们提供的技术来赚钱和去他们要去的地方,所以我们没有可以停歇的时间。我们非常看重系统可用性和可扩展性。
随着我们的业务扩展到越来越多的城市,我们的服务也伴随着一同扩展。我们技术栈的易伸缩性鼓励不同技术之间的比较和竞争,这样最好的方案才能最终胜出,而且胜出的也不一定必须是唯一的方案。如果已经有非常好用的工具了,我们就会拿来用,直到超出了它的承受范围。当我们需要更强大的东西时,我们就自己开发。在过去的几年里Uber 技术团队已经表现出了非常棒的适应性、创造力和纪律性。在2016 年,我们有更大的计划。当你读到这篇文章时,肯定有很多东西已经变了,但这毕竟也是我们曾经的技术栈的一个快照。通过我们的描述,希望你能理解我们关于使用工具和技术的想法。
Uber 的技术栈
我们先想像一棵树,而不是一堆的限制条件。统观 Uber 使用的技术栈,可以看到一些通用技术(就象一棵树干),每个团队使用得各有侧重(树枝)。所有东西都出自相同的本源,但工具和服务在各个不同方面发挥出完全不同的作用。

我们从底层开始讲起。
底层:平台
上篇关注Uber 技术平台,即所有支撑着更广泛的其它Uber 技术团队的东西。平台团队打造和维护这些技术,让其他团队可以更好地构建程序和功能,以及你使用的App。
基础设施和存储
我们的业务运行在混合云模型上,使用不同的云服务提供商和多处同时提供服务的数据中心。如果一个数据中心出了故障,我们的核心Trip 数据会自动完成故障转移,切换到另一个数据中心继续提供服务。我们会尽量把每个城市的数据放到离它地理上最近的数据中心,但每个城市的数据都会在另一个不同的数据中心有备份。这意味着我们所有的数据中心都在同时提供着在线的Trip 数据服务,我们并没有传统意义上的“备份”数据中心。要在这样的基础设施上部署程序,我们同时使用了各种内部工具和 Terraform 。
我们对存储的需求随着业务量的增长而变化。公司刚创立时我们只有一个Postgres 数据库实例,但当我们快速发展之后,我们需要增大可用的磁盘存储量和减小系统响应时间。
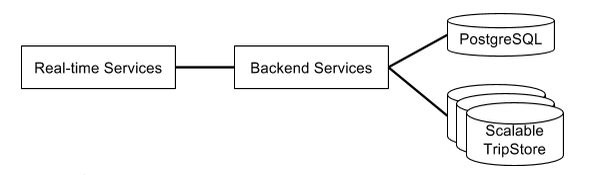
2014 年夏天, Mezzanine 项目把系统重构成了上图所示的高级架构。
我们现在使用 Schemaless(基于 MySQL 自行研发), Riak 和 Cassandra 。Schemaless 用于数据持久化存储,Riak 和 Cassandra 满足高可用性和低延迟的需求。慢慢地,Schemaless 实例会替换掉单个的 MySQL 和 Postgres 实例,而 Cassandra 会因为速度和性能而替换掉 Riak。我们使用 Hadoop 来存储和分析复杂数据。在这些数据库之上,我们西雅图的工程师们还在开发着一个新的实时数据平台。
我们用Redis 作缓存和队列。 Twemproxy 实现了一致性哈希算法,提供了缓存层的扩展性而又没有牺牲缓存命中率。 Celery 的团队就是用这些 Redis 实例来处理异步工作流操作的。
日志
我们的服务会与彼此及手机进行交互,这些交互信息对于内部技术调试以及业务上的动态调价等功能都非常有价值。为了支持日志功能,我们使用了好多套 Kafka 集群,在数据被 Kafka 淘汰之前会最终归档到 Hadoop 和 Web 服务的文件存储。数据还会被各种服务实时消费掉,并在 ELK 上为搜索和可视化功能创建索引(ELK 是 Elasticsearch , Logstash 和 Kibana 的缩写)。
App 部署
借助于 Aurora 的长时间运行服务和定时任务,我们用 Mesos 的 Docker 容器来做微服务的一致性可伸缩配置。我们有个基础设施团队——应用平台组——实现了一个模板库,可以把服务构建成可部署的 Docker 镜像。
路由和服务发现
我们的面向服务架构(SOA)让服务发现和路由功能变得对Uber 的成功至关重要。服务必须能在我们的复杂网络中与彼此通信。我们用了 HAProxy 和 Hyperbahn 来一起解决这个问题。Hyperbahn 是 Uber 开发的一系列开源软件之一: Ringpop 、 TChannel 和 Hyperbahn 都是要为服务网络增加自动化、智能性和提高性能。
传统的服务会用本地的 HAProxy 实例来把 JSON 包通过 HTTP 请求传送到其它服务,从前端的 Web 服务器和 Nginx 到后端服务器。这样清晰的数据传送方式就让查错变得简单,这在去年我们做的演进到新系统的几次升级中起到了关键作用。
然而,在可调试功能之上,我们更看重长期可靠性。在速度和可靠性方面,我们还可以用 HTTP 之外的 SPDY、HTTP/2 和 TChannel 等协议和 Thrift 或 Protobuf 等接口定义语言来方便我们演进系统。Ringpop 是个一致性哈希层,提供了应用层的协作和自愈功能。Hyperbahn 让服务可以简单可靠的进行相互通信,即使服务是用 Mesos 动态调度的。
我们现在已经迁移到了一种发布- 订阅的模式(将更新发布给订阅者)上来,而不是传统的为查看是否有状态改变而要不断轮询方法。HTTP/2 和SPDY 都更容易实现这种推的模式。如果改用推的模式,Uber App 很多现有的基于轮询的模式都会有性能上的飞跃。
开发与部署
很多内部操作都依赖 Phabricator ,从代码审查到生成文档,到流程自动化。我们用 OpenGrok 来查找代码。对于 Uber 开源的项目,我们直接用 GitHub 来跟进问题和做代码审查。
Uber 技术团队一直致力于让开发活动尽可能地模拟实际生产,所以我们大多数时候都在云服务提供商的虚拟机或者开发者的笔记本电脑上进行开发。我们构建了自己的内部部署系统来管理构建活动。 Jenkins 用作持续集成。我们把 Packer 、 Vagrant 、 Boto 和 Unison 组合在一起来打造在虚拟机上进行构建、管理和开发的工具。我们用 Clusto 来做开发的清单管理,用 Puppet 管理系统配置。
我们也一直努力打造和维持稳定的沟通渠道,不止是服务之间,更是在工程师之间。就信息发现功能来说,我们用 uBlame( git-blame 的改进版) 来跟踪哪个团队管理着哪种特定服务,用 Whober 来查询名字、相片、联系方式、组织架构等。我们内部的文档服务器会用 Sphinx 自动从存储服务器的信息中构建文档。企业级告警服务会提醒值班的工程师保持系统正常运行。许多开发者都在笔记本电脑上运行 OSX,大多数生产环境服务器上运行的 Linux 都是 Debian Jessie。
开发语言
在底层 Uber 工程师主要用的是 Python、Node.js、Go 和 Java。最早只用了两种语言:Marketplace 团队用的是 Node.js,其他人用的是 Python。到现在 Uber 运行的大多数服务仍是用这些最初的语言写的。
用Go 和Java 主要是出于高性能的考虑。Java 利用了开源生态系统,并与Hadoop 和别的分析工具等结合得非常好。Go 可以带给我们高效、简单和高运行时效率。
在把最早期的代码拆成微服务时我们就开始慢慢替换掉原有的Python 代码了。异步编程模式让我们有了更好的吞吐量。我们把 Tornado 和 Python 一起使用,但 Go 对并发的原生支持对许多非常重视高性能的新服务来说也非常合适。
必要时我们会用 C 和 C++ 来写些工具(比如在系统级的高效和快速的代码)。我们会使用这些语言写的工具,比如 HAProxy 就是其中之一,但大多数情况下我们不会用它们。
当然,比较高些层级的代码就不是用 Java、Go、Python 和 Node.js 写的了。
测试
为保证服务可以处理我们生产环境的需求,我们开发了两个内部工具:Hailstorm 和 uDestroy。Hailstorm 用来做集成测试,在非繁忙时间模拟峰值压力。uDestroy 会故意搞坏一些东西,来测试我们对非预期故障的处理。
我们的员工都会先使用测试版的App 来不断测试新功能,然后才会交到用户手中。我们有个App 反馈器,用于记录发布给用户之间遇到的所有问题。每当我们为Uber App 生成新版本时,这个功能都会让我们去Phabricator 上加一个修复问题的任务。
可靠性
每个写后台服务的工程师都要为他的代码负责。不管谁写的代码搞坏了生产环境的东西,值班人员就会给他打电话。我们用 Nagios 来做监控告警,绑定到一个告警系统上。
现场可靠性工程师的任务是保证最高的可用性和每天10 亿次叫车服务,他们会关注于创造和满足服务运行所需要的条件。
这里有个2016 年二月的技术讨论视频,谈到了Uber 的现场可靠性保证。
可观测性
可观测性是要保证 Uber 作为一个整体,或者它的各个不同部分都是正常工作的。这个功能主要由我们纽约团队开发,有许多个系统来作为Uber 遍布全世界的技术系统的眼睛、耳朵和免疫系统等。
遥感勘测
我们用Go 语言开发了 M3 来收集和存储 Uber 技术系统(每台服务器、每个服务和每一行代码)的各项指标。
收集到数据之后,我们会查看趋势。我们修改了 Grafana 来更容易的通过仪表盘和图形来展示和上下文紧密相关的信息。每个看着仪表盘的工程师都有自己想观察的东西,有的是某个特别城市或区域的数据,有的是若干个实验,或者是某个新产品的数据。我们给 Grafana 加上了数据分片的功能。
异常检测
我们自行研发了异常检测工具Argos ,用于把输入指标和基于历史数据生成的预测模型做对比,判断当前数据是否超出了正常的界限。
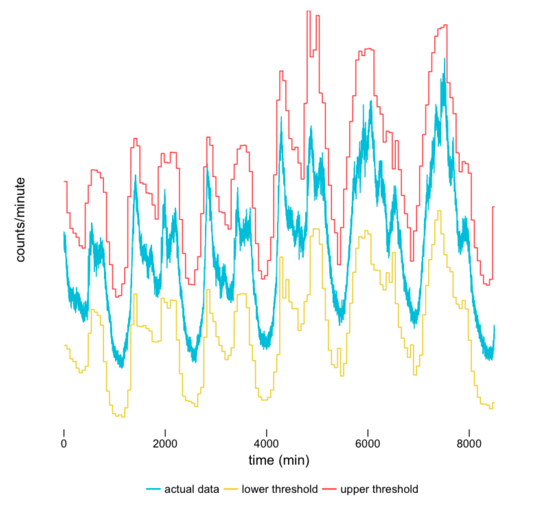
我们把由异常值检测算法每小时算出的动态阈值(红线和黄线)与输入数据做对比。我们还画上了实际的每分钟产生的真实数据(蓝线),这部分当然不能提前画上。这些阈值都会紧密的跟进着实际指标的模式。
根据指标做出的反应
Uber 的工程师们在看到了实时信息和阈值(不管是静态的还是 Argos 动态生成的)之后,就可以用工具μMonitor 来采取行动了。如果某个数据流越界了,也就是说 Trip 数据在某个城市下降到某个阈值之下了,这条信息就会被发送给常见行为网关。这是我们自动响应系统的功能。除了在发生故障时给工程师们打电话之外,它也会做些事情来缩短故障持续时间。如果某次部署发生问题,回滚操作也是自动的。
我们有许多观测工具都是限于 Uber 内部使用的,因为它们和我们的基础设施太相关了。不过我们也希望能把通用部分抽象并开源出来。
创造性地使用数据
Storm 和 Spark 会把数据流处理成有用的业务指标。我们的数据可视化团队也有可重用的架构和应用来处理可视化数据。
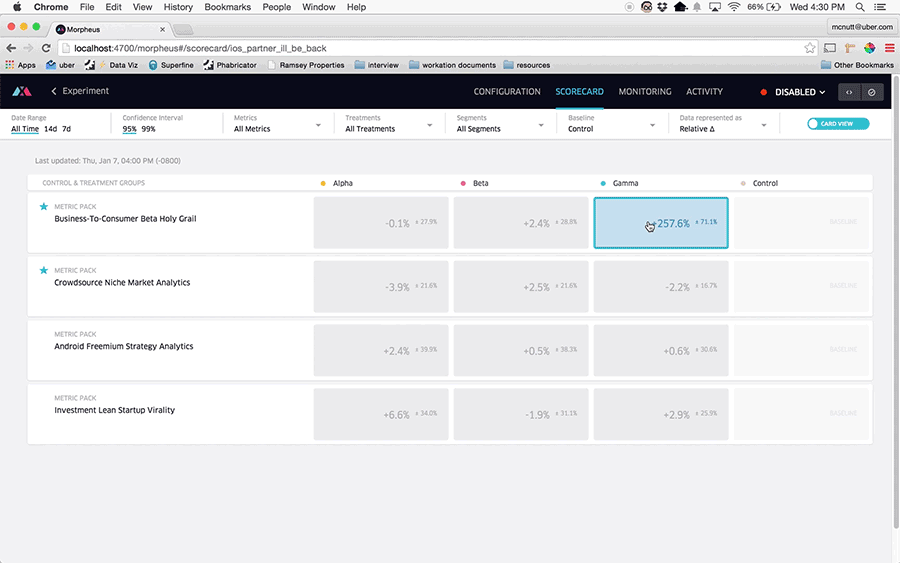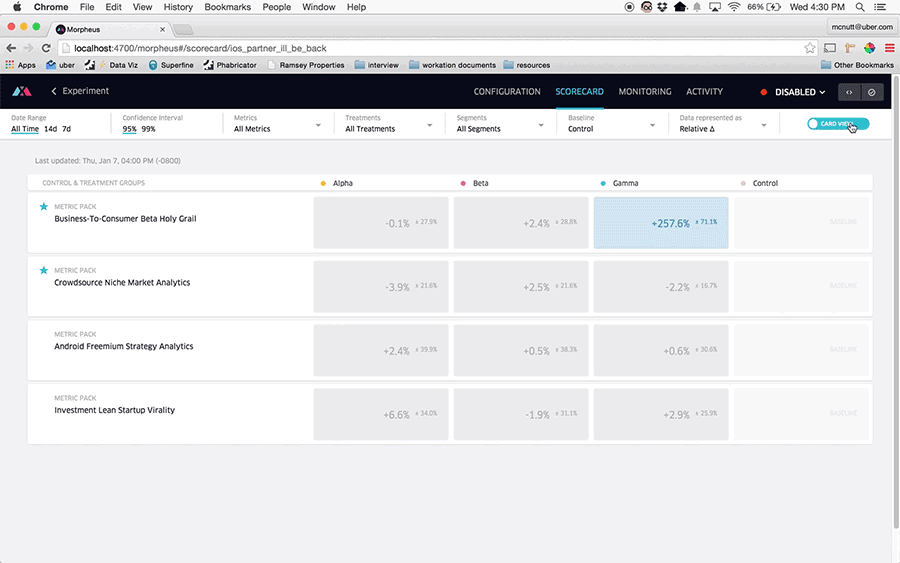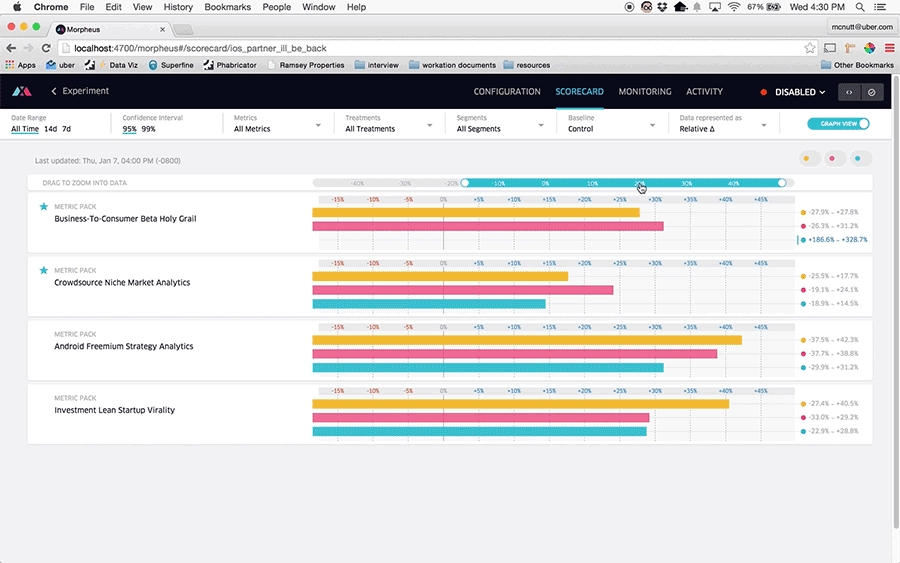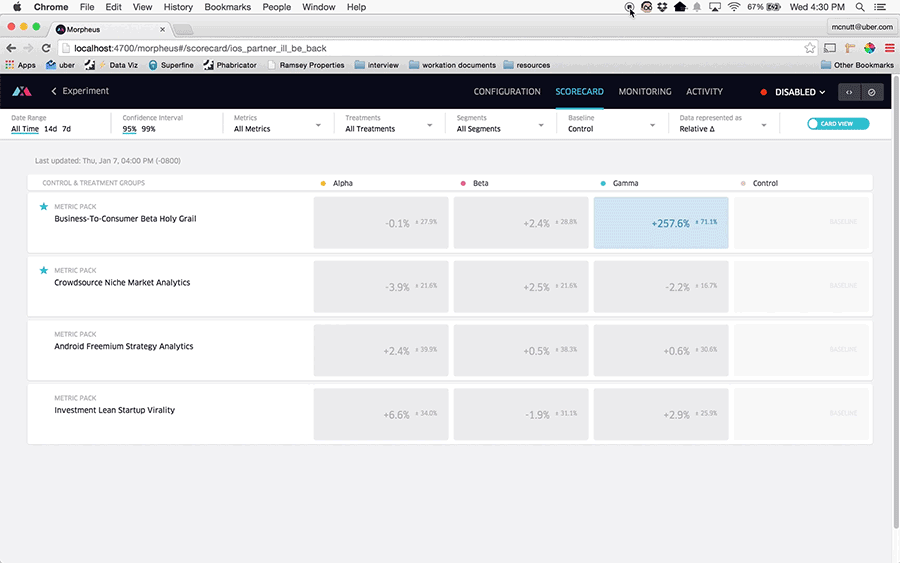
表格和置信区间的可视化增强了我们的 A/B 测试平台 Morpheus 的功能
地图和实验团队都依靠数据可视化技术来把数据变成清晰、可感知的信息。城市运营团队可以直接实时地看到他们的司机以车的形式在地图上移动,而不是枯燥地做些 SQL 查询来了解情况。
我们用 JavaScript( ES5 和 ES6 )和 React 来构建了数据产品,作为我们的核心工具。我们也在我们的可视化模块中使用了各种标准图像技术: SVG 、 Canvas 2D 和 WebGL 等。我们已经开源了许多库,比如我们就是依赖 react-map-gl 来做地图可视化的:
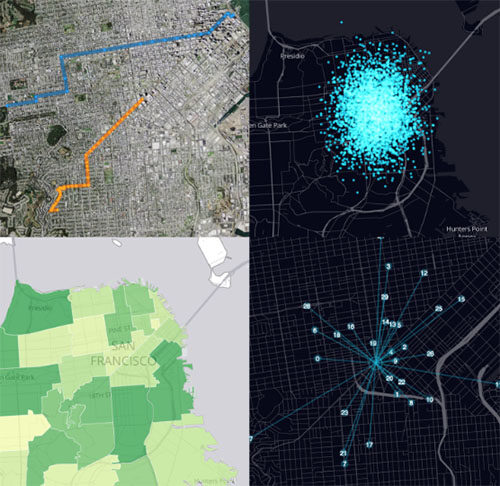
可视化证明了 react-map-gl 的功能,这是一个由 Uber 数据可视化团队开发的 MapboxGL-js 的封装器
我们也开发了可视化框架,让诸如 R、Shiny 和 Python 等也可以访问我们的图表组件。我们希望有在浏览器中可以运行得非常流畅的高密度数据可视化技术。要达到这样的目标,我们开发了开源的基于WebGL 的可视化工具。
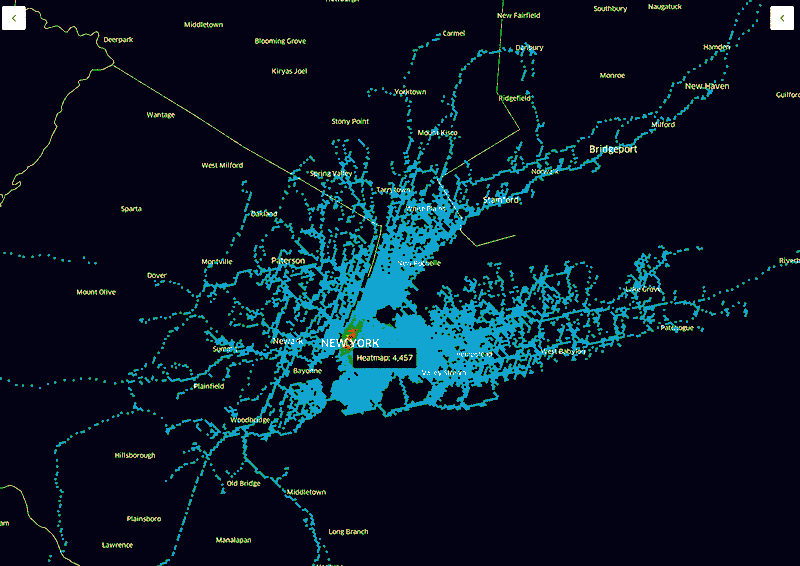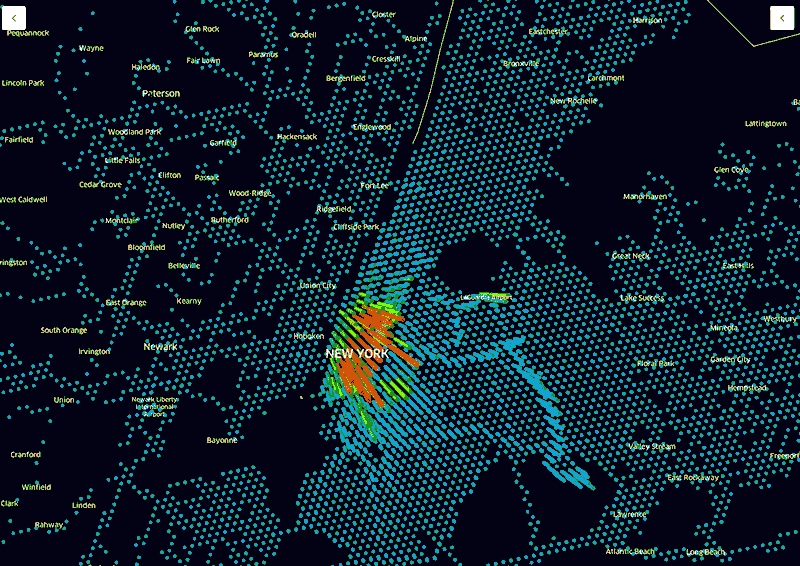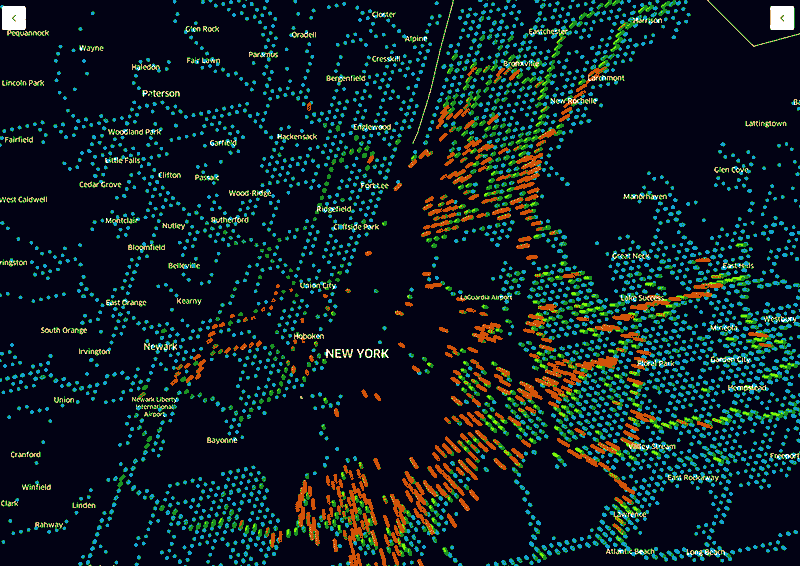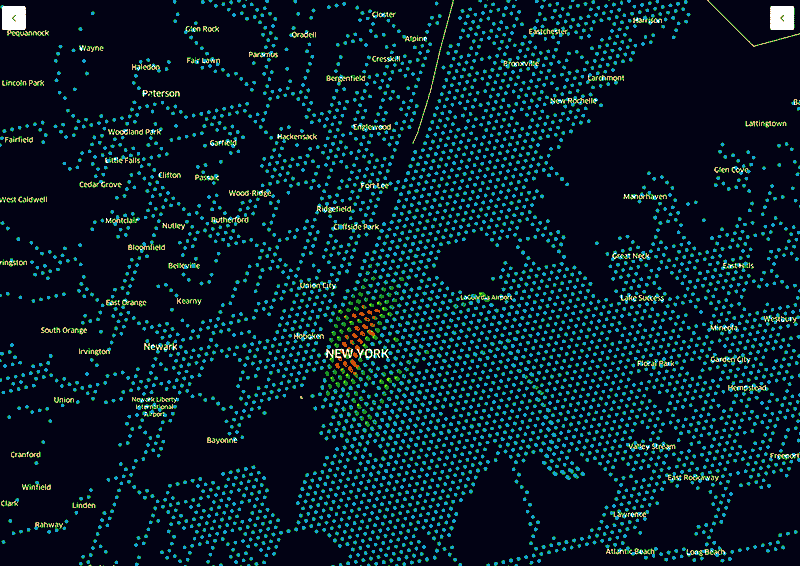
一张Uber 热度地图显示了正在载客的车辆的密度。然后我们还可以把顶层的百分比数据移除掉来看底层数据。
地图
Uber 地图团队非常重视数据、算法和与地图数据、展示、路由、收集和推荐地址和位置等功能相关的工具集。地图服务主要是基于 Java 技术开发的。
这一块量最大的服务是 Gurafu ,它通过许多精细的路由选项来提供了许多处理道路地图数据的功能,提高了效率和准确性。Gurafu 前端是µETA,它在原始 ETA 之上加了个业务逻辑层。Gurafu 和µETA 都是基于 DropWizard 框架开发的 Web 服务。
我们的业务和客户都非常依赖高度精确的 ETA 数据,所以地图服务工程师会花费很多时间来保证这些系统运行得正确。我们会作 ETA 错误分析,来找出并修复出错的源头。在精确性之外,这个问题的级别也是很重要的:每一秒,整个公司的系统都会基于 ETA 信息做出非常大量的决策。由于这些请求的延迟不能超过 5 毫秒,那算法效率也就成了个大问题。我们要关注各种细节问题,比如分配内存的方法、并行计算和对服务器磁盘或数据中心网络等低速资源的访问。
地图服务也在支撑着所有乘客和司机 App 中搜索框底层的后台服务技术,包括自动补齐搜索引擎、预测引擎、反向地理编码服务等。自动补齐搜索引擎提供了对地点和地址的本地搜索功能。预测引擎使用机器学习算法来基于用户历史和其他信息预测乘客的目的地。预测要能占到用户输入目的地的大概 50%。反向地理编码服务根据 GPS 信息来判断乘客的位置,再辅助以各种其它信息,根据整体行程对乘客的上车地点做出推荐。
除了这些,我们的文章还会涉及到与你的手机相关的技术。请继续关注我们的下篇。Uber 的技术和面临的挑战都可能会变化,我们的使命和克服困难的文化不会变。你想成为这个团队的一分子吗?
另外,感谢Conor Myhrvold, Botswana 的图片:“Chapman’s Baobab”。
Baobab(猴面包树)以它们的生命力强、长寿、粗厚的树干和树枝而闻名。喀拉哈里沙漠中的这棵猴面包树也是非洲最古老的树之一。
本文翻译自:“ THE UBER ENGINEERING TECH STACK, PART I: THE FOUNDATION ”,作者LUCIE LOZINSKI,已获得原网站授权。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论