
2024 年 10 月,智源研究院发布了全球首个原生多模态世界模型悟界·Emu3,该模型只基于下一个 token 预测,无需扩散模型或组合方法,实现图像、文本、视频的大一统。模型一经上线便在技术社区引发了热议。
一年后,智源发布悟界·Emu3.5,在“Next-Token Prediction”范式的基础上,模拟人类自然学习方式,以自回归架构实现了对多模态序列的“Next-State Prediction (NSP)”,获得了可泛化的世界建模能力。
智源研究院院长王仲远表示,世界模型的核心是预测下一个时空状态,这种预测对具身智能至关重要,且不局限于视频或图像形式。他解释道,人类面对真实世界场景时,会形成多模态理解(如看到靠边的咖啡会预判掉落风险),机器人执行相关操作(如抓取咖啡)时,需要精准把控力度、方向等细节。

论文介绍:https://arxiv.org/pdf/2510.26583
Emu3.5 在各方面能力上实现了全面提升。它具备三大特点:一是从意图到规划,模型能够理解高层级的人类意图(如“如何制作一艘宇宙飞船”“如何做咖啡拉花”),并自主生成详细、连贯的多步骤行动路径;二是动态世界模拟,模型在统一框架内无缝融合了对世界的理解、规划与模拟,能够预测物理动态、时空演化和长时程因果关系;三是可成为泛化交互基础:其涌现出的因果推理和规划能力,为 AI 与人类及物理环境进行泛化交互(如具身操控)提供了关键的认知基础。
“我们认为,Emu3.5 很可能开启了第三个 Scaling 范式。”王仲远说道。
随着大语言模型的成功,行业探索出语言预训练的 Scaling 范式,即通过提升模型参数量、数据量与算力,实现性能的显著优化。但随着文本数据逐渐耗尽,过去两年行业将重点转向后训练与推理阶段的 Scaling 范式,这一方向也成功进一步激发了模型潜力,取得了良好效果。但多模态领域长期以来始终缺乏成熟的 Scaling 范式。“从 Emu3 到 Emu3.5 的演进,我们首次证明了多模态领域同样存在这样的 Scaling 可能性,”王仲远表示,其核心依据有三点:
1. Emu3.5 架构采用自回归设计,实现了多模态数据的大一统,能够大规模复用现有计算基础设施;
2. Emu3.5 首次在多模态领域落地自回归架构下的大规模强化学习技术,行业已具备成熟解决方案,这为多模态大模型的 Scaling up 提供了关键支撑;
3. 从 Emu3 到 Emu3.5,模型性能实现显著跃升,目前 Emu3.5 已达到产品级水准,后续将向行业开放。
王仲远介绍,此次团队研发的核心思路是回归第一性原理。这源于对人类学习本质的认知:人类的学习并非从文本开始,每个人自出生起,对世界的认知(包括与他人的交流、物理世界的运行规律),都是以视觉为起点建立的。当前视频形态的存在,恰好为模型学习世界知识提供了优质载体:通过视频,模型能够有效掌握世界的内在运行规律、因果关系、逻辑推理逻辑,以及各类物理常识。
世界多模态模型探索
市面上多数模型仍将“多模态理解”与“多模态生成”拆分处理。其中,多模态理解类模型多采用组合式架构,例如以大语言模型为基础,先完成语言能力学习,再叠加多模态学习。但这种模式存在明显问题:模型易出现“遗忘现象”,其记忆能力不足的问题至今未得到妥善解决;同时,Agent 在处理相关任务时如何优化表现等,都是企业场景落地过程中必须突破的关键难点。
Emu 系列模型采用了自回归架构,使其可扩展性更强。它的 Next Token,可以是视觉和文字的 Token,且性能无损。王仲远特别提到,它的强推理、长时序一致性,能给具身智能带来根本性的改变。
相比之下,当前主流模型架构(如 DiT 架构)虽已在特定场景中取得亮眼成果,但其设计本质上限制了模型的泛化能力与任务迁移能力。换言之,这类架构更偏向针对具体问题的“精巧解决方案”,而非能够跨场景、跨模态实现自适应学习的通用智能系统。
在多模态发展方向上,智源认为,无论是聚焦 Emu3.5 本身,还是从更长时间尺度回望,它都代表了一条切实可行的多模态智能发展路径。
“悟界·Emu3.5 是 AI 大模型领域一项至关重要的原始创新。它并非单纯的算法创新,也不是单一的工程创新,而是融合了算法、工程架构、数据训练范式与模型思想的综合性创新。此类创新恰恰只有智源这样的机构能够实现——因为智源是一种介于高校与企业之间的中间态组织,这种独特的组织形态,为开展跨维度、多层面的综合性创新提供了必要条件。”王仲远表示。
三大技术创新
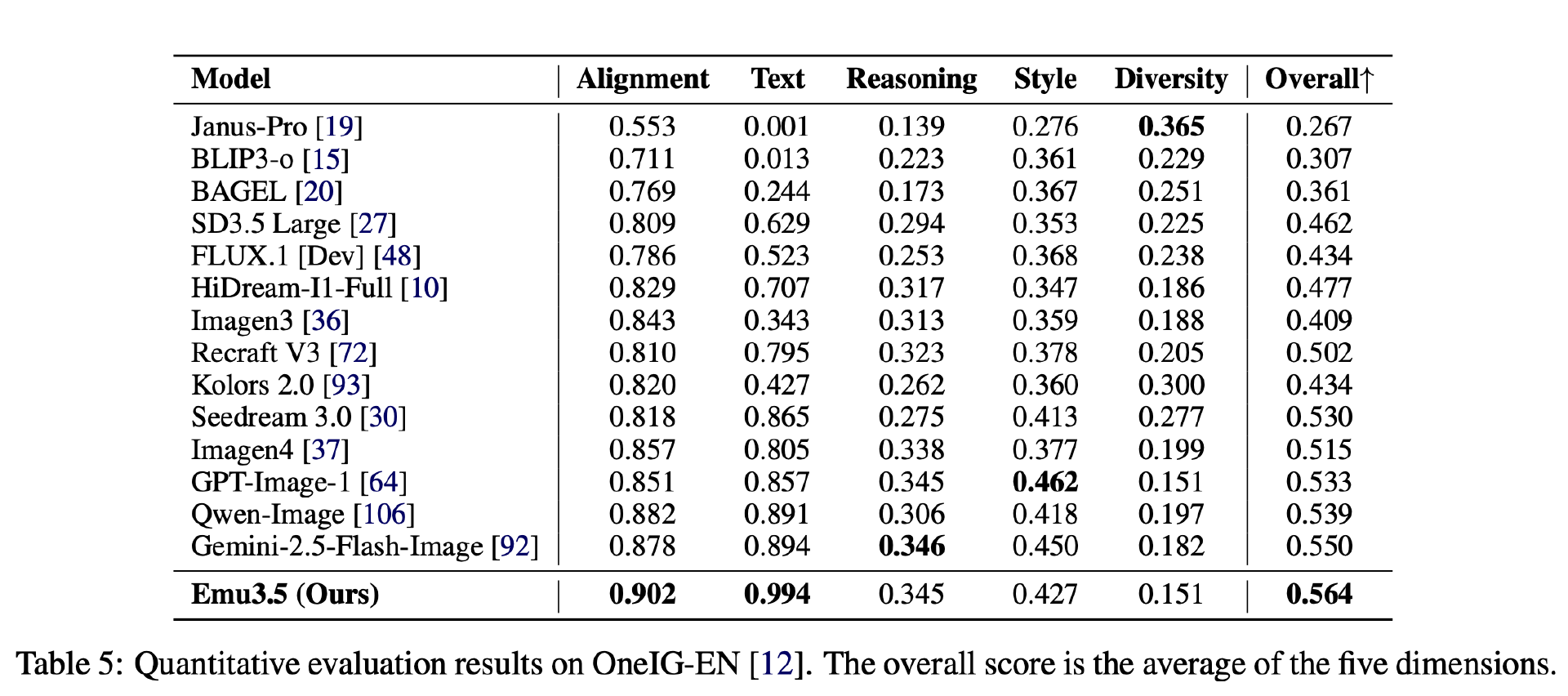
具体来看,Emu3.5 首先在约 13 万亿 tokens 上进行两阶段端到端预训练,第二阶段进一步提升视觉分辨率多样性、数据质量和标注丰富度,提供更精准的多模态监督。两阶段训练使模型能在统一生成框架下自然处理交错视觉-语言输入并生成交错输出。随后,模型在 1500 亿样本上进行有监督微调(SFT)以构建统一多模态生成接口,再通过大规模强化学习提升多模态推理与生成能力。最后,利用少量(数十亿 tokens)SFT 和自蒸馏数据,通过 DiDA 技术快速适配高效推理。
首先,在预训练环节,Emu3.5 消耗了超过 10T Token,这主要得益于其易拓展的架构以及海量长视频数据的支撑。这也是 Emu3.5 与之前版本的主要区别:大部分数据是长视频而不是文字主导。
视觉-语言交错数据来源于多样化视频(含开源数据集、公开网络视频及第三方合作获取视频),共包含约 6300 万条视频,平均时长 6.5 分钟,总时长约 790 年。数据覆盖教育、科技、教育、娱乐、体育、游戏、旅游、动画等多个领域,全面捕捉真实世界和想象场景。
值得关注的是,当前 Emu3.5 仅为 340 亿参数规模,所使用的视频数据累计时长达 790 年,却仅占全互联网公开视频数据的不到 1%。这意味着,无论是训练数据量、参数规模的拓展,还是未来向 MOE 架构的演化,所有在语言大模型上已验证的 Scaling up 路径与能力,都有望在多模态领域重新实现。
“训练过程稳定性极佳,即便在各类下游未见过场景的验证损失中,也能观察到随着计算量增加,模型效果持续稳定提升,这也印证了原生多模态的 Scaling 范式有效性。”智源研究员王鑫龙表示。
第二项核心技术是大规模原生多模态强化学习。
GPT-o1 和 DeepSeekR1 通过强化学习极大增强了语言能力,但该技术应用于更长的多模态场景时会面临诸多问题。而依托易拓展的自回归架构与整体范式,Emu3.5 可轻松实现统一多任务的多模态强化学习。
智源团队构建了包含不同奖励的综合奖励系统,为多样化下游任务提供全面统一的指导。该奖励系统具备通用性、任务特异性和统一性三项核心特性,这种多维度奖励系统确保 Emu3.5 可以平衡多种质量标准,更重要的是,避免单一奖励过拟合,实现多任务的一致提升,且不会损害单个任务的性能。
通过多模态强化学习,模型能够模仿多模态交互,将众多多模态任务统一在相同的交互形式下,既包括复杂文生图,也涵盖具备强推理能力的图像编辑(文字与图像均为生成内容)。
例如,精准呈现“一步步拿出手机”“倒水”等动作,体现对现实世界的理解;还能实现交互式探索(室内、室外、想象或真实场景)及问题操作,这些能力定义了下一代原生多模态模型的核心方向。
第三项技术是推理加速领域的实用突破。
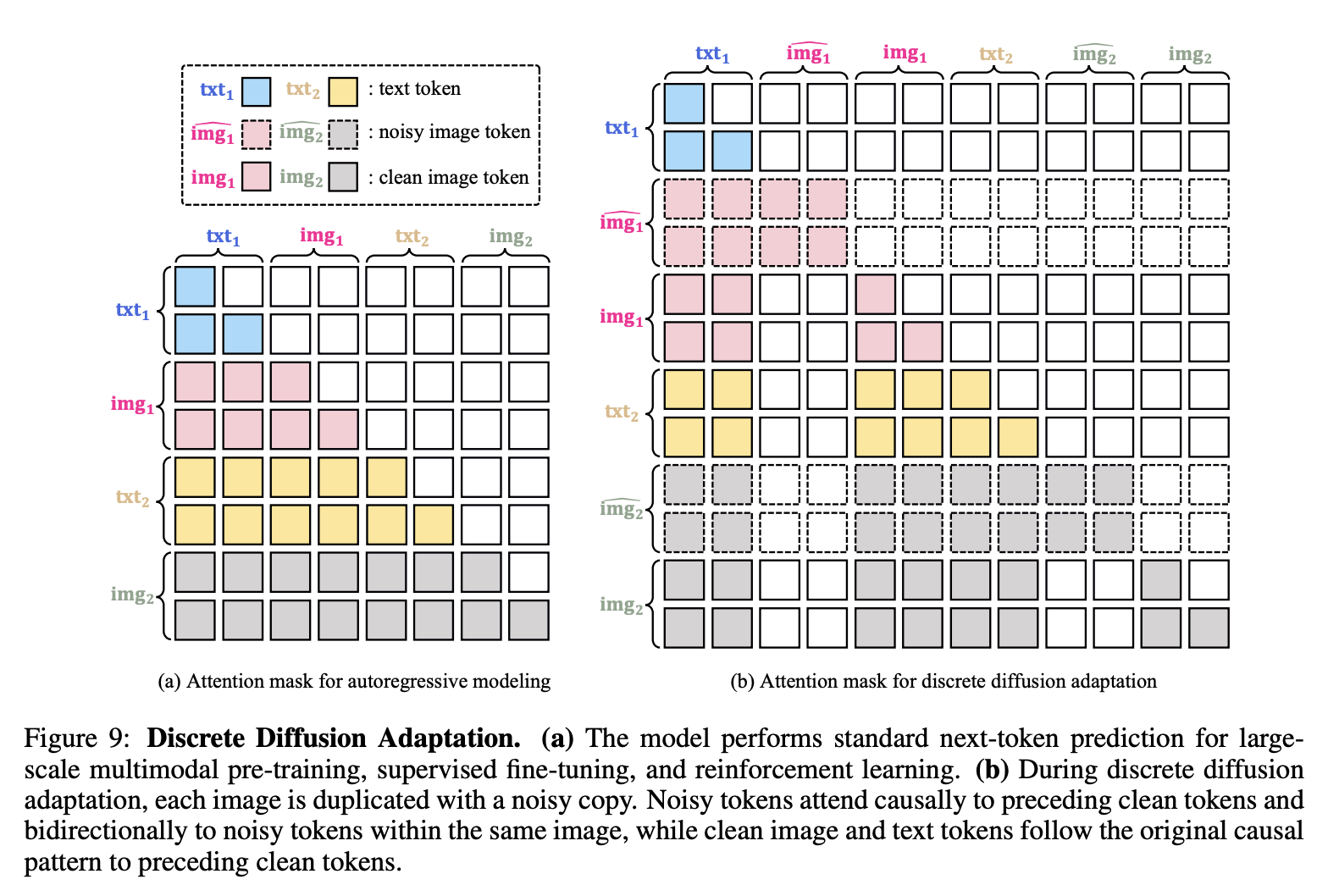
自回归模型相较于扩散模型,原本存在推理速度劣势。对此,智源通过自研的 DiDa 技术,无损预测下一个 Token 并将推理速度提升了 20 倍,最终使自回归架构的模型性能能够媲美 Diffusion 架构模型。
DiDA 是一种轻量级自适应方法,在不改变模型文本生成能力的前提下,来加速自回归图像生成。基于预训练自回归模型,DiDA 将离散扩散公式扩展至视觉 token,使模型将图像生成从序列解码转换为并行生成。具体而言,DiDA 在视觉 token 上实现离散扩散过程,整个图像 token 序列一次性初始化,通过一系列离散去噪步骤逐步优化,恢复目标图像。这种设计在不损失输出质量的前提下,实现推理速度的显著提升。
“原来的原生多模态的成本极高的,这一次 20 倍的加速,把原生多模态的成本砍下来了。” 王鑫龙说道。
值得关注的是,这是首次通过 Token 预测方法,实现了可媲美闭源系统最强图像生成的能力,而该能力仅为 Emu3.5 图形能力的一部分。这一突破背后,得益于上述多项核心技术的革新,使得 Emu3.5 在生成性能与速度上均能与顶尖闭源系统相媲美。
结束语
智源认为,世界模型不仅是视频生成,更多的是对整个世界因果关系、时空、物理建模的能力。
“我们更愿意把悟界·Emu3.5 称作为多模态世界大模型,因为它具备了多模态的理解能力和多模态的生成能力。它实际上能够理解时空、长时序、一致性,能够有因果推断,所以 Emu3.5 是一个非常独特的模型。可能很难直接单一的跟任何一个模型去比较。”王仲远说道。
王仲远认为,Emu3.5 的意义在于,可能开创了一个新的大模型的赛道。“虽然业内对世界模型有很多的讨论,但人们最初的讨论是,我们的人类大脑里面应该存在着一个这样的世界模型,它能够理解基本的世界运行规律,包括物理常识、时间空间知识等,能够帮助我们解决日常生活中看似非常简单、但现在对于机器人来讲非常困难的问题。”




