
AI 浪潮席卷之下,企业技术领袖们无不摩拳擦掌,渴望将这些颠覆性技术融入自身的业务核心,抢占智能时代的制高点,不料却被现实狠狠地甩下一记耳光。
PoC 时的惊艳还历历在目——自动报告生成、智能应答客服、代码辅助开发,一切都看起来那么完美。然而,当试图将这些能力嵌入核心业务系统时,医疗团队发现,AI 助手会面不改色地编造根本不存在的药物方案;金融机构意识到,风控模型可能依据过时的条款做出百万级的误判;连最简单的客服场景中,AI 都能把用户引导向一个早已下架的产品。这并非由于某个技术事故,而是生成式 AI 存在已久的幻觉问题。
清华大学计算机系教授指出,大模型在垂直领域知识与实时更新上是有局限的,特别是幻觉问题,已经成为大模型深入企业级应用的掣肘。因此,行业迫切需要一种既保留大模型生成能力,又能对其输出进行确定性约束的方案。

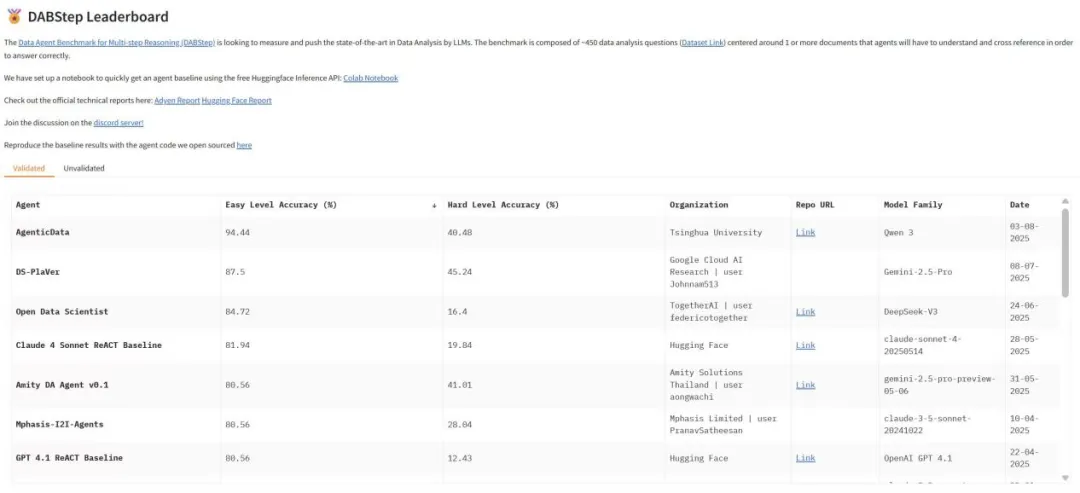
9 月 25 日,由李国良教授作为技术顾问的数智引航团队,正式发布向量数据库 VexDB,能够支持百亿千维向量数据毫秒级查询,召回准确度高达 99% 以上,从数据基础设施层面为 AI 应用构建一个可信的知识基石。近日,在国际权威的 DABSTEP 非结构化数据分析测试中,VexDB 的数据代理系统以领先第二名超 10 个百分点的成绩夺冠,展现出强大的推理、理解和信息整合能力。
“幻觉”为何成为企业级应用的“死穴”
为什么我们需要像 VexDB 这样的向量数据库重构 AI 的信任基因,而非只是算法的迭代?
这要从大模型的幻觉问题谈起。从技术本质来看,大模型幻觉源于其生成机制的内在缺陷。作为一种基于统计概率的内容生成工具,大模型通过学习海量训练数据的模式来预测下一个最可能的词元,而非进行真正的逻辑推理或事实核查。这种机制使其即使在缺乏真实依据的情况下,也能生成语法正确但内容虚假的信息。
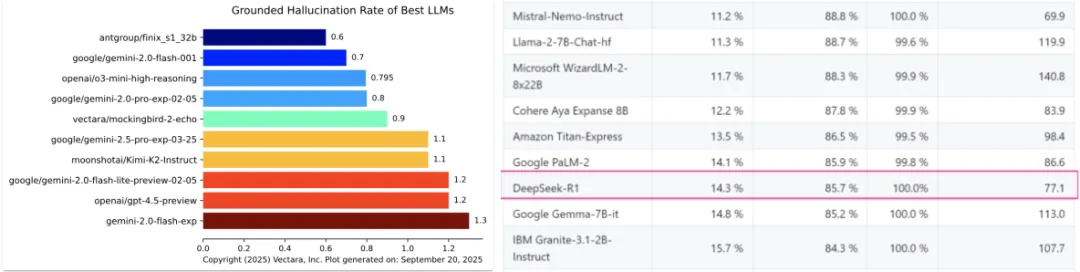
在用于大模型幻觉测试的基准 HHEM 测试中,所有测试模型都出现了不同程度的幻觉问题。
Google/gemini-2.0-Flash-001、OpenAI/o3-mini-high-reasoning 等模型幻觉率低于 1%、OpenAI/gpt-4.5-preview 幻觉率为 1.2%, 而 DeepSeek-R1 的幻觉率达到了惊人的 14.3%,也就是意味着大约每 7 次摘要,就会有 1 次产生幻觉。
当这种技术缺陷延伸到企业级应用场景时,模型幻觉便从单纯的技术问题升级为致命的业务风险。
某医疗信息化头部企业高级副总裁指出,在 AI 应用的过程中,用户的首选担忧就是模型的可信度问题,因为医疗领域专业性强、AI 应用门槛高,而通用大模型缺乏医院私域知识,很容易产生“模型幻觉”,轻则误导诊断,重则引发医患纠纷。
不仅医疗行业深受其扰,在金融领域,基于虚假信息的风险评估会导致巨额资金损失;在法律、客服等高频交互场景,不准确的信息输出则会严重损害客户信任,甚至引发品牌声誉危机。
解决幻觉问题,不再只是技术团队的优化目标,而是 AI 技术真正融入企业核心业务流程的准入资格。只有构建可信的 AI 基础设施,企业才能放心地将 AI 部署到关乎业务命脉的关键场景中。
RAG 解决方案成为企业级 AI 应用落地的趋势
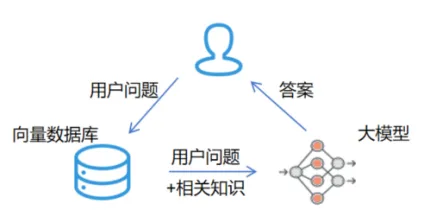
为解决大模型幻觉问题,业界逐渐形成了以 RAG(检索增强生成)为代表的知识增强范式。RAG 并非通过修改模型底层算法抑制幻觉,而是通过引入外部知识源,将大模型的生成过程约束在可控、可信的范围之内。
其典型工作流程可概括为:将企业私域知识,如诊疗指南、产品文档等进行切片、向量化,并存入检索库;在用户提问时,系统实时检索最相关的知识片段,并将其与大模型指令共同构成提示词,从而引导模型生成基于事实的可靠结果。
RAG 有效规避了仅靠模型自身参数凭空生成答案的风险,但是 RAG 也有性能瓶颈,集中在数据处理、检索、结果整合三大环节,且性能问题直接影响业务落地。例如,电商场景中,RAG 驱动的智能客服若检索响应超过 2 秒,用户咨询流失率会上升 30%。
因此,RAG 检索的准确性决定了模型所见上下文的真实性,检索的速度影响了用户体验,而检索的稳定性则直接关系到整个 AI 服务能否持续可用。如某金融 RAG 项目,通过数据去重与分层,检索效率提升 40%,召回准确率从 72% 提升至 89%。
可以说,RAG 系统的能力天花板,不再仅仅取决于大模型本身的性能,更依赖于背后检索组件的强大与可靠。正因如此,问题的核心已从“如何让模型更好地生成”悄然转变为“如何更快、更准、更稳地检索”。
传统关系型数据库虽然擅长处理结构化数据的精确查询,但在处理非结构化数据的语义搜索时却力不从心,因此,向量数据库的必要性日益凸显。
用一个简单的比喻来解释,传统数据库像一个按索引号严格整理的书库,你必须提供精确的信息,比如“我要找书名为《RAG 技术详解》的书”,但如果你问它:“找一本关于如何让 AI 不胡说八道的书”,它会直接卡住。而向量数据库则像一个精通所有领域、理解语义的超级图书管理员,这位管理员会理解你问题的意思,然后在向量空间里寻找所有和“AI”、“准确性”相关的书籍。即使这些书的标题里根本没有“不胡说八道”这几个字。他会把模型幻觉相关的书籍都找出来给你,因为它们意思相近。向量数据库是专门为高维向量相似性搜索而设计,能够将文本、图像等非结构化数据转换为向量表示,并通过计算向量之间的距离来度量语义相似性。这种能力使其成为 RAG 架构中不可或缺的核心组件,为 AI 应用提供了高效、准确的知识检索能力。
核心引擎解密:下一代向量数据库与技术实践
随着大模型应用进入深水区,向量检索的需求不断攀升。根据 GM Insights 报告,2024 年全球向量数据库市场规模为 22 亿美元,预计 2025-2034 年将以 21.9% 的复合年增长率增长,到 2034 年市场规模将达到 151 亿美元。这一增长背后反映的是企业对于可靠 AI 基础设施的迫切需求。
当前市场中,向量数据库产品虽已形成多元化布局,但能真正适配企业级复杂业务场景的方案仍属稀缺。企业对向量数据库的期待,早已超越 “实现相似性检索” 的基础功能,而是要求其在动态数据更新、海量数据存储、多模态语义理解、跨场景高可用等维度具备 “工业级” 能力,能够在业务规模扩张、数据类型迭代、并发请求激增的情况下,始终保持稳定的检索精度与响应效率。
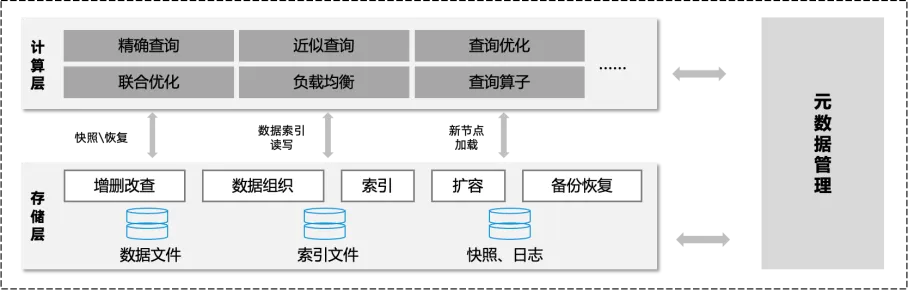
近日,清华团队最新发布的 VexDB,正是为应对这一需求而来。作为新一代向量数据库系统,VexDB 在以下几个关键技术维度上实现了突破:
高精度、多路召回机制:企业业务往往要求在极大语义跨度下保持准确性。VexDB 支持稠密向量检索、稀疏向量检索和标量过滤,并通过 SQL 层即可实现多路召回,显著提升端到端检索质量。在实际业务测试中,VexDB 可将疾病诊断场景下的召回准确率提高至 99% 以上。
百亿规模、毫秒响应:针对大模型对外部知识的“高频、小体量”调用特征,VexDB 设计了结合 HNSW 层级索引与磁盘级 DiskANN 的 GraphIndex 结构,支持千维高精度向量在百亿数据集上实现毫秒级响应。同时,通过软硬件协同优化,进一步降低查询时延。
动态更新与高可用架构:相比静态索引系统,企业实际数据往往每天都在变化。VexDB 支持原地更新和实时索引刷新,结合一主多备及跨 Region 容灾设计,能够满足高并发场景下的数据一致性与业务连续性需求。这些能力的整合,不仅解决了技术侧的检索瓶颈,也为大模型可信生成提供了扎实的数据支撑。从过去半年产业实践来看,向量数据库正经历从 RAG 工具向 AI 数据基础设施平台的演进。其价值已不再局限于提升召回率,而是在 AI 全生命周期中承担起更复杂的角色:
知识资产管理器:支持版本控制、向量质量评估、数据更新溯源;
多模态语义连接器:打通文本、图像、音频等异构数据的语义索引;
Agent 中枢引擎:为企业智能体提供统一的语义检索与记忆机制;
隐私计算边界守门人:通过私有化部署与权限控制保障数据安全。
向量数据库的技术价值,最终需通过产业实践验证,目前已有许多企业将向量数据库视为新一代知识操作系统的核心组件。Gartner 预测到 2026 年,将有 30% 的公司使用具有基础模型的向量数据库,而 2022 年这一比例仅为 2%。
据悉,VexDB 已在医疗、通信、金融、制造等领域实现深度应用,为企业 AI 转型提供了 “技术可落地、效果可量化” 的解决方案。
例如某头部信息化企业基于 VexDB 构建了端到端的 RAG 诊疗辅助系统,通过“离线预存 + 热门缓存”机制,既保障了“私域数据不出院”的安全规范,又大幅降低大模型调用成本。该系统在智能病历场景中实现突破,将病历生成时间从 20 多分钟缩短至 8 分钟内,效率提升超 60%。
在通信行业,某运营商利用 VexDB 构建企业级智能中枢,赋能营销导购与云盘服务两大核心场景。该系统通过多模态向量检索技术,精准解析用户意图,使客户转化率提升 30%,方案产出耗时减少 60%。在云盘检索中,用户仅需自然语言描述即可精准匹配目标内容,体验满意度超 90%,真正实现所说即所得的智能化服务。

这些行业实践充分证明,VexDB 不仅能够解决大模型幻觉问题,更能够为企业提供端到端的 AI 应用支撑能力。通过将向量数据库与行业知识深度结合,企业正在构建起兼具智能性和可靠性的新一代业务系统,真正实现 AI 技术与核心业务的深度融合。
VexDB 现已推出开发版(免费)和商用版两个版本。感兴趣的朋友,欢迎扫码加入 VexDB 技术交流群。






