

欢迎阅读新一期的数据库内核杂谈。这一期接着精读发表在 USENIX 2022 上的DynamoDB技术论文。上一期杂谈介绍了DynamoDB的设计理念和大致的分布式架构。在分布式这块,DynamoDB 使用了多地域多副本架构,并且用 Consensus protocol 来保证数据写的强一致性。这一点上,并无太大创新。一个亮点是当某个副本由于各种故障下线时,为了能快速恢复写 quorum 的多副本设置,DynamoDB 引入了轻量级的 LogReplica 节点(只覆盖接受 WAL 操作,不提供 B-tree 的读取服务)。这一期,我们着重学习 DynamoDB 是如何保证在海量数据的前提下,依然能够维持稳定的低延时(consistent high performance)。
引入 RCU/WCU 来抽象服务 SLA
对于表的一个 partition(作为计算和存储的基本调度单元),DynamoDB 引入了 Read Capacity Unit(RCU)和 Write Capacity Unit(WCU)来控制其相应的吞吐需求。RCU 的定义如下,对于一个至多 4KB 的 item,一个 RCU 保证每秒做一次强一致读。同理,WCU 的定义是对于一个至多 4KB 的 item,一个 WCU 保证每秒做一次写操作。将一个表的所有的 partition 的 RCU 和 WCU 求和,即为这个表的总吞吐需求(考虑到 partition 会动态地被调整,我个人理解,在大部分情况下,一个表的所有 partition 会有一样的 RCU 和 WCU 设置)。一个表的不同 partition 可以被分配到不同的节点上,DynamoDB 就可以根据某个 partition 的 RCU 和 WCU 需求来合理匹配 partition 和资源节点。这就和云原生 K8S 的调度方式很类似了。在 K8S 里,通常,资源被抽象成 CPU 和 Memory,scheduler 需要考虑某个 POD 相对应的 request 和当前 node 的资源剩余,而 DyanmoDB 则把资源抽象成 RCU 和 WCU,scheduler 需要考虑某个 partition 的 RCU 和 WCU 需求和当前 node 的资源剩余。一个 partition 在业务增加的前提下,读写请求会增加,进而产生 partition split,分裂后的 partition 会根据独立的 RCU 和 WCU 进行调度。
DynamoDB 通过 admission control 机制来保证每个节点不会被分配超过其资源总量的 partitions,避免某些高吞吐的 partition 可能影响部署在这个节点上其他 partitions 的读写表现。DynamoDB 会限制单个 partition 的最高 RCU 和 WCU。设计初期,admission control 运行在每个节点上,通过监控这个节点上部署的 partitions 的 RCU 和 WCU,确保 RCU 和 WCU 的求和不超过节点能够承载的上限来保证服务的稳定性。
一个 partition 的 RCU 和 WCU 会随着整个 table 的 RCU/WCU 吞吐改变而改变,或者这个 partition 被分裂成多个子 partitions。当 partition 进行分列时,父 partition 的 RCU 和 WCU 吞吐会平均地分到所有的子 partitions 上。文中也给出了例子:假设,一个 partition 的 WCU 的吞吐上限是 1000,当一个 table 的 WCU 被设置成 3200 时,DynamoDB 会给这个 table 创建 4 个 partition,并且每个 partition 分配 800WCU;当这个 table 的 WCU 被提高到 3600 时,每个 partition 的 WCU 也相应提高到 900;当这个 table 的 WCU 再次被提高到 6000 时,原先的 4 个 partition 会被分裂成 8 个,每个 partition 分配到 750WCU;当这个 table 的 WCU 被降配到 5000 时,每个 partition 的 WCU 会降低到 675。
每个 partition 分配均匀的 RCU/WCU 吞吐是基于数据访问是平均地分摊到所有的 partition 上这个前提。然而,文中指出,实际情况下,往往并非如此,无论是时间维度上,还是 key-range 维度上,访问方式都不是均匀的。这类问题属于热数据部均匀(hot partition)。症状是,数据访问只集中在非常一小部分热点数据(这些数据可能就属于一个 partition)。在这种不均匀的访问前提下,分裂一个 partition 并且均分吞吐可能导致热数据的吞吐量反而减少,进而导致性能下降:访问请求会被限流,拒绝,导致上层服务不可用。但从整体表的吞吐分配来看,还远没有达到请求的分配上限。在这种情况下,从用户角度来看就是整个表的吞吐不够,解决方法就是增加吞吐。虽然能解决问题,但对用户体验(从收费角度),以及正确的资源利用率上来看,都是不良的。
Bursting & Adapative Capacity
为了解决上述问题,DynamoDB 从 local 的 admission control 出发,引入了两个新的机制,bursting(短期吞吐超额)和 adaptive capacity(动态容量)。
Bursting 专门用来对付不均匀的热数据访问,通过暂时地对某个 partition 的吞吐进行扩容来吸收短期地高频访问。这个临时扩容称作是 busrting capacity。当某个 partition 的 allocated capacity(AC)被用完时,DynamoDB 允许访问该 partition 的请求打到 bursting capacity(BC)上(文中写了最多允许 300 秒的访问)。为了确保 bursting capacity 的稳定服务,DynamoDB 会确保该计算节点上还有空闲的计算资源。计算节点的 capacity 是通过多个 token bucket(https://en.wikipedia.org/wiki/Token_bucket)来管理:每个 partition 分配两个 token bucket,一个是 allocated capacity, 另一个是 bursting capacity;还有一个全局的 token bucket 来保证节点级别的访问。当一个读或者写操作打到一个计算节点上,如果对应 partition 的 AC token bucket 还有 token 剩余,这个操作会被接受,对应的 partition AC token bucket 和 node token bucket 都会减少一个 token。当这个 partition 的 AC token bucket 被用完时,必须满足 BC token bucket 和 node token bucket 都有剩余,操作才会被允许 burst。这边读操作和写操作还有区别:读操作只需要满足当前计算节点的 node token bucket,而写操作需要保证所有副本的 node token bucket 都有剩余。这是不是表示,在写操作的时候,还需要一次额外的 RPC 来获取其他副本节点的 node token bucket 呢?文中给了解释,leader 节点会在 consensus protocol 交流中持续获取其他节点的 node token bucket 信息。
相比于 bursting 用来解决单个 partition 的短期吞吐超标,adaptive capacity(AC)用来解决更长时间的,跨多个 partitions 的吞吐超标。AC 持续监控每个表的分配的吞吐配额以及使用情况。当发现某个表出现了 throttling 现象,但整体 capacity 并没有用完时(此时说明某些 partitions 的操作请求已经超额,且 bursting 都没能解决这个问题),AC 就会提升受影响的 partitions 的吞吐配额。但文中也指出,这个配额提升受到这个表的总吞吐配额的限制(我理解,这和 DynamoDB 作为 SAAS 服务的 SLA 也相关),这些 partitions 的配额提升会被降低如果整体配额已经超过这个表的总 capacity。Autoadmin 子系统会确保被提升的 partitions 被分配到拥有足够计算资源的节点上来保证 capacity。当然,文中也指出,和 bursting 一样,adapative capacity 也是一种 best effort 来解决绝大部分(文中用的数字是 99.99%)的操作 throttling。
Global Admission Control
虽然通过引入 bursting 和 adaptive capacity,DynamoDB 解决了绝大部分的数据不均匀访问带来的 throttling 问题,但这两种方案也都有应用限制。Bursting 只针对短期的单个 partition 访问超标,且依赖当前 partition 所在的节点有足够多的计算资源。Adapative Capacity 属于对应措施,只有当 throttling 已经发生后才会被实施。此时,上层应用可能已经经历了短暂的服务不稳定。这两种解决方法都是因为 DynamoDB 的 admission control 都是作用在单个 partition 上(local admission control)。
为了解决 local admission control 的问题,DynamoDB 引入了 global admission control 机制(GAC)。GAC 的实现依然是依赖 token bucket 来实现:GAC 会监控每个表的全局 token bucket 来判断 capacity 用量。每个 request router service(参考 DynamoDB 架构图)会对每个表维护一个 local 的有时效性(time-limited)的 token bucket 来判断是否接受相应表的操作请求,同时,会很频繁地和 GAC 交互来更新最新的 token bucket 信息(频率在几秒级别)。当一个操作打到 request router, 它会先从 local token bucket 中 deduct token 来判断请求是否能被接受。最终,当 request router 会用光所有的 token(或者这些 token 过期了),它会向 GAC 请求更多的 tokens。如此,GAC 会保证即使是不均匀的数据访问,也能用完某个表的全局 capacity。
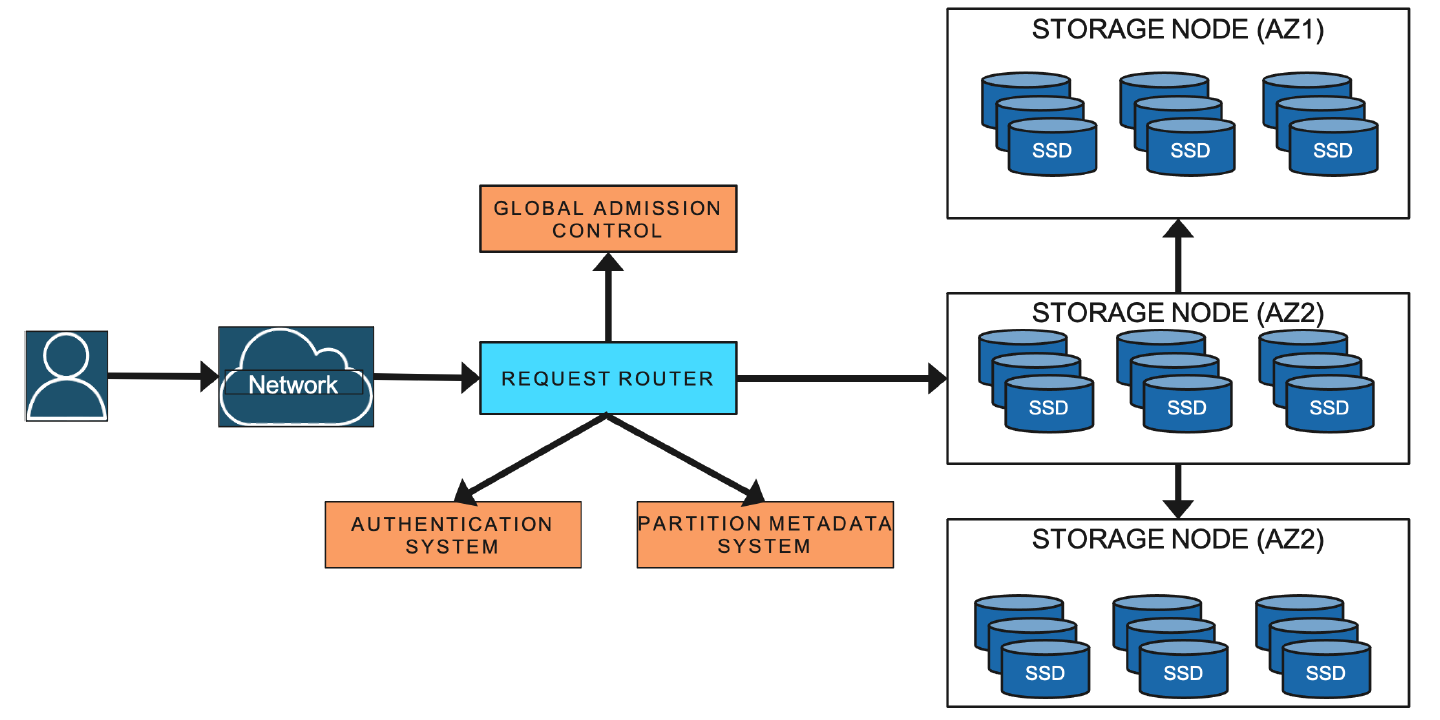
DynamoDB architecture
文中也提到了,虽然引入了 GAC,但是 partition-level 的 local token bucket 机制依然被保留来确保计算节点的资源利用始终在一个安全的水位线上。
Balancing Consumed Capacity
Bursting 机制需要 DynamoDB 对于计算资源 capacity 的管控精细和高效。此外,由于 DynamoDB 的计算节点会运行在不同的硬件环境上(这些硬件环境有非常大的吞吐和存储的差异)。最新的存储节点可以支持千级别的 partition replicas。这些 partitions 会属于不同的表,不同的 partitions 也有不同的 access pattern。没有 bursting 和动态 capacity 调整,partition 调度方案相对来说容易一些(和 k8s 根据 pod 的 CPU,memory request 来分配计算节点类似)。Bursting 机制会导致某个 partition 的访问量超过 allocated capacity,如果一个节点同时有多个 partition 需要 bursting,这时候节点和调度就会更加困难。 文中写了,DynamoDB 建立了一个系统,通过主动监控所有表的 partitions 的读写请求量,来判断某些 partition 是否会更有可能出发 bursting 或者 AC,并且主动地调度这些 partitions 到资源更充足和合理的计算节点上。
Partition Split For Consumption
虽然 bursting 机制,AC 机制,GAC 机制都视图解决某些 partition 的读写操作激增带来的 throttling 问题,但不能很好地解决因为数据量逐步变大带来的读写操作的增加。为了解决这类问题,DynamoDB 会观察某个 partition 消耗的吞吐,如果持续超过一定水位,就会对这个 partition 触发分裂(split)。key range 的拆分会根据访问的频次来找到最佳的分裂点(我猜测是根据数据 histogram 的方法)。一次 partition 分裂通常可以在几分钟内完成。文中也指出,如果 DynamoDB 发现 access pattern 比较特殊,导致整体的吞吐不会因为 partition 分裂而带来提升,比如,极端情况下就是一个 single-item hot access。这种情况下就不会触发 partition 分裂。
On-Demand Provisioning
文中也提到了相比于最初需要用户自己配置硬件环境以及传统云原生种以计算资源(CPU,memory)作为配置参数的设定,DynamoDB 引入的 RCU,WCU 对于用户来说比较新。且很多用户也很难准确地预估某些表配置多少的 RCU 或者 WCU 比较合适。DynamoDB 也提供了 on-demand provisioning 功能。通过监控表的读写 traffic patterns 和 capacity 用来,然后通过一些 heuristic 算法来配置相应的 capacity。比如一个 heuristic 实现就是配置成两倍原先的 peak traffic。
总结
这一期,我们聚焦在了 DynamoDB,在超大规模,超多租户的前提下,如何保障稳定的低延时服务(consistent low latency)。最大的亮点我认为就是引入了 RCU 和 WCU 吞吐预期的概念来规划服务 SLA,而不是单纯去追求 QPS,latency。能够提供稳定的,满足需求的延时远比追求极致性能要重要,特别是对于云服务来说。这对通用的大规模系统设计都很有启发。基于 RCU/WCU,DynamoDB 也推出了 bursting,adaptive capacity,global admission control,partition split for consumption,以及 on-demand provisioning 等功能来巩固稳定性:通过提前对 partition 分配好 quota 并通过 autoadmin 严格保证资源充足;在计算节点上预留资源来支持短暂的 QPS 激增;支持全局 capacity control 并主动监控 capacity 的使用情况来提前 relocate partition 和 split partition 来最大化减少服务被 throttle 的概率。下一期,我们会继续讨论 DynamoDB 的高可用(durability)和灾备恢复(failover)的实践。
内核杂谈微信群和知识星球
内核杂谈有个微信群,大家会在上面讨论数据库相关话题。目前群人数超过 300 多了,所以已经不能分享群名片加入了,可以添加我的微信(zhongxiangu)或者是内核杂谈编辑的微信(wyp_34358),备注:内核杂谈。
除了数据库内核的专题 blog,我还会 push 自己分享每天看到的有趣的 IT 新闻,放在我的知识星球里(免费的,为爱发电),欢迎加入。
相关阅读:
数据库内核杂谈(二十三)- Hologres,支持 Hybrid serving/analytical Processing 的数据引擎
数据库内核杂谈(二十四)- Hologres,支持 Hybrid serving/analytical Processing 的数据引擎

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论