

本文《If you’re a developer transitioning into data science, here are your best resources 》最初由 Cecelia Shao 发布于 Kdnuggets 网站,经 Kdnuggets 网站授权由 InfoQ 中文站翻译并分享。
你可能已经从媒体铺天盖地的报道中,了解到数据科学家这个职位有多火。如果你有心的话,就会发现像 Airbnb 和 Uber 这样的科技公司在人才招聘网站上的数据科学家职位一栏下面,统统标着“急聘”字眼。另外,已经有人开始提出这样的疑惑,如果有一天,人人都会写代码了,作为码农,该何去何从?因此很多人萌生了入行或者转行做数据科学家的念头。那么就带来了一个问题,该如何从开发人员成长为数据科学家呢?
如今,似乎每个人都梦想成为数据科学家,从博士生到数据分析师,再到你大学室友,他们都在 LinkedIn 不断地给你发短信,邀请你去“喝杯咖啡”。
也许你已经有了同样的想法,心想:我至少应该去探索一些数据科学的立场,看看数据科学的炒作究竟是关于什么的。也许你看过像 Vicki Boykis 撰写的《Data Science is different now》(《现在数据科学已经不一样了》)这样的文章,文章中说道:
越来越清楚的是,在炒作周期的后期阶段,数据科学正逐渐向工程学靠拢,数据科学家需要的技能越来越不再是可视化和基于统计的,而是更符合传统的计算机科学……。
像单元测试和持续集成这样的概念,很快就成了行话,并成为从事机器学习工程的数据科学家常用的工具集。
或者就像 Tim Hopper 的推文说的那样:
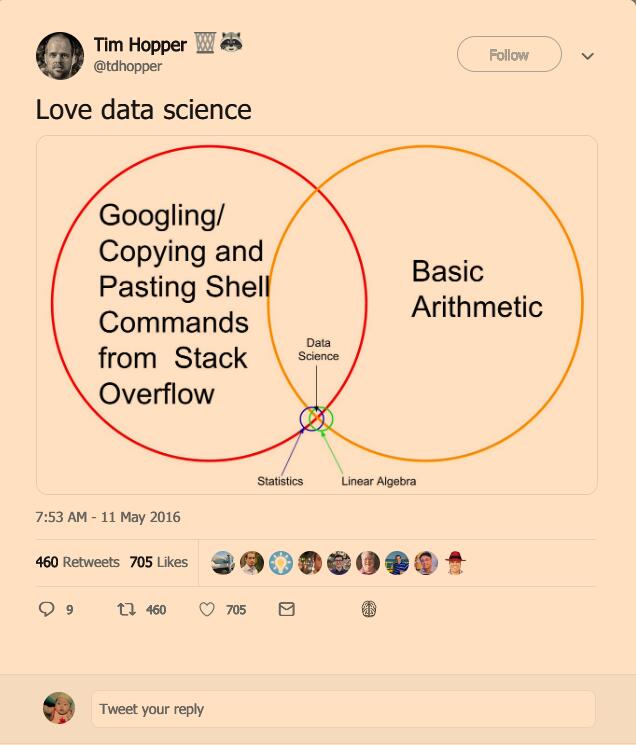
目前尚不清楚的是,如何将软件工程师的经验运用到数据科学的职位上。你可能会遇到的其他一些问题如下:
我应该优先学习什么?
对数据科学家来说,是否存在不同的最佳实践或工具?
我目前掌握的技能是否能够适应数据科学的角色?
本文将提供有关数据科学家角色的背景,并阐述为什么你的背景可能适合数据科学,以及作为开发人员,可以采取哪些切实可行的逐步行动,来提升数据科学的水平。
数据科学家与数据工程师
首先,我们应该区分这两个互补的角色:数据科学家和数据工程师。虽然这两个角色都会处理机器学习模型,但他们与这些模型的交互,以及数据科学家和数据工程师的工作需求和性质,其实都存在很大的差异。
注:专业从事机器学习的数据工程师角色,在职位说明中也可能描述为“软件工程师、机器学习”或“机器学习工程师”。
作为机器学习工作流的一部分,数据科学家将执行所需的统计分析,以确定要使用哪几种机器学习方法,然后开始进行原型设计并构建这些模型。
在建模过程之前与之后,机器学习工程师通常会与数据科学家就以下内容进行合作:
构建数据管道以将数据馈送给这些模型;
设计一个工程系统,为这些模型提供服务,以确保模型持续运行的健康状况。
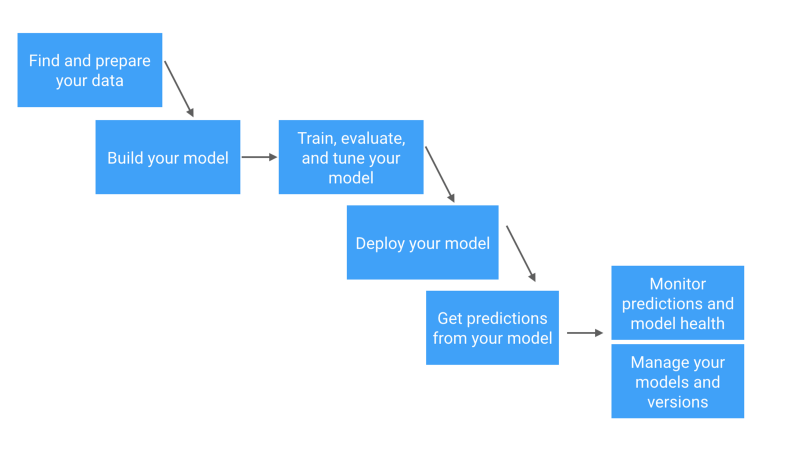
如下图所示,展示了查看这一系列的技能的一种方式:
关于数据科学家和数据工程师之间的区别,在网上有大量的资源,请一定要看看:
Panoply: 《What is the difference between a data engineer and a data scientist?》
(《数据工程师和数据科学家的区别是什么?》)
Springboard:《Machine Learning Engineer vs Data Scientist》
(《机器学习工程师与数据科学家》)
O’Reilly:《Data engineers vs. data scientists》
(《数据工程师与数据科学家》)
作为免责声明,本文主要讨论数据科学家的角色,并对机器学习方面提出了一些要求(尤其是你正在寻找一家较小公司的职位,你可能需要同时担任这两个职位)。
作为开发人员的优势
对每个人都不利的是,围绕机器学东西的课程,如《Introduction to Data Science in Python》(《Python 数据科学导论》)或 Andrew Ng 的 Coursera 课程这样的机器学习课程,并没有包括软件工程的概念和最佳实践,如单元测试、编写模块化可重用代码、CI/CD 或版本控制。甚至一些最先进的机器学习团队仍然没有将这些实践用于他们的机器学习代码,这就导致了一个令人不安的趋势……
Pete Warden 将这一趋势描述为“机器学习再现性危机”:
当涉及到跟踪变化和从头开始重建模型时,我们仍然处于黑暗时代。这太槽糕了,有时候感觉,时光就像回到了以前,我们在没有源代码控制的情况下进行编码的时候。
虽然你可能没有在数据科学家职位描述中明确这些“软件工程”技能都是哪些,作为你知识背景的一部分,如果掌握好这些技能,当你作为数据科学家进行工作的时候,这些技能将如有神助。此外,如果你在应聘数据科学家的面试中,需要回答这些编程问题时,它们就会派上用场了。
想从另一个角度来了解一些有趣的观点,请阅读 Trey Causey 撰写的文章《Software development skills for data scientists》(《数据科学家必备的软件开发技能》),在这篇文章中,他建议数据科学家应该学会“编写更好的代码,与软件开发人员进行更好的互动,最终为你节省时间,免去麻烦。”
提升数据科学的水平
如果你有拥有良好的软件工程背景基础,这当然是一件好事。但如果你要成为数据科学家的话,那么下一步应该要做什么呢?Josh Will 在 Twitter 上对数据科学家下了半开玩笑的定义,出人意料的准确。
他的这则推文提示了如果你对数据科学家的角色或职业感兴趣,你应该去了解的主题之一:统计学。
在下一节中,我们将介绍以下资源:
获取机器学习专业知识
获取行业知识
机器学习栈中的工具
技能和资格
获取机器学习专门知识
最有效的方法是围绕概率和统计学,构建基于理论的知识组合,以及掌握在 GPU/ 分布式计算上的数据整理或训练模型等方面的应用技能。
构建你要获取的知识框架的一种方法是参照机器学习工作流。
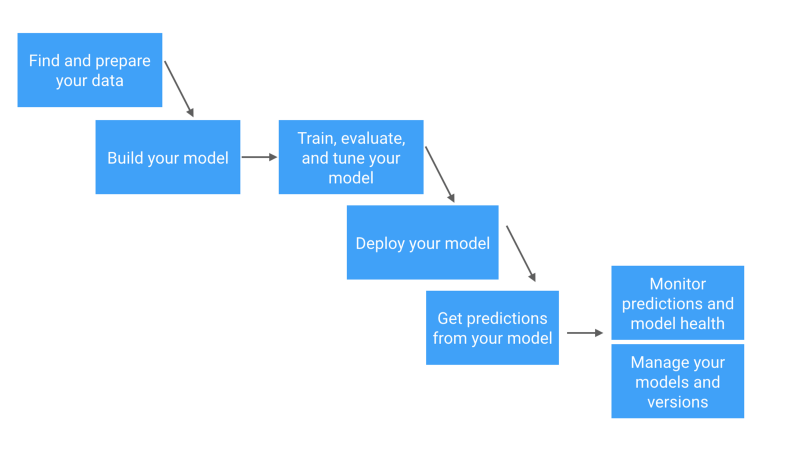
机器学习工作流的简化视图
请参阅 Skymind AI 的详细工作流。
这里我们列出了一些有关机器学习的最佳资源。考虑到篇幅所限及阅读时间,我们不可能罗列出详细的清单,我们也没有提到那些非常受欢迎的资源,如 Andrew Ng 的 Coursera 课程或 Kaggle 等。
课程:
Fast.ai MOOC(免费课程,教授码农实践深度学习、深度学习的前沿技术、计算线性代数和机器学习入门等非常实用的技能。)
Khan Academy(可汗学院)
YouTube 频道:3Blue1Brown 和 mathematicalmonk
Udacity Courses(优达学城)(包括《Preprocessing for Machine Learning in Python》(《用 Python 进行机器学习预处理》))
教科书:
我们在网上找到了大部分免费的 PDF 文档。
(《黑客的概率规划与贝叶斯方法》)
(《概率与随机过程》)
(《统计学习的要素》)
(《学好线性代数》)
(《线性代数导论》)
(《算法设计》)
指南手册:
(《Google 开发者机器学习指南》)
《Machine Learning Mastery Guides》 (《机器学习精通指南》)(要获得很好的起点,请参阅 《Python Machine Learning Mini-Course》《Python 机器学习迷你课程》)
Pyimagesearch 网站 (用于计算机视觉)
线下聚会:
这些线下聚会主要在美国纽约市举办。
要获得一个很酷的起点,请阅读 Will Wolf 著的《Open-Source Machine Learning Masters》(《开源机器学习大师》),你可以了解如何通过学习特定主体和项目来安排时间,并开展项目以低成本的方式在偏远地区来展示你的专业知识。
获取行业专业知识
如果你想进入某个特定行业,比如医疗保健、金融服务、消费品、零售业等等,那么了解这个行业与数据和机器学习相关的痛点和发展是非常有价值的。
一个专业建议:你可以去浏览垂直特定的人工智能初创公司的官网,看看他们是如何定位自己的价值主张,以及他们打算将机器学习在哪里发挥作用。这将为你提供研究机器学习特定领域的想法,以及展示你工作的项目主题。
我们可以举一个例子:假设我们对医疗保健的工作感兴趣。
通过 Google 快速搜索“machine learning healthcare”,我在 Healthcareweekly.com 上找到了《Best Healthcare Startups to Watch for in 2019(《2019 年最值得关注的医疗保健初创公司榜单》)。
你还可以在 Crunchbase 或 AngelList 以“healthcare”作为关键词进行快速搜索。
让我们以榜单上的一家公司 BenevolentAI 为例。
BenevolentAI 的网站上写道:
我们是一家人工智能公司,具有从早期药物发现到后期临床开发的端到端能力。BenevolentAI 将计算医学和高级人工智能的力量与开放系统和云计算的原理相结合,改变了药物的设计、开发、测试和上市方式。
我们构建了 BenvolentAI 平台,以便更好地了解疾病,并从大量生物医学信息中设计出新的、改进现有的治疗方法。我们相信,我们的技术能够让科学家更快速、更经济地开发药物。
每 30 秒钟就有一篇新的论文发表,但科学家目前只使用了现有知识的一小部分来了解疾病的原因并提出新的治疗方法。我们的平台摄取、“阅读”并将从书面文档、数据库和实验结果中提取的大量信息进行语境化。它能够在这些完全不同的、复杂的数据源中进行无限多的演绎和推理,识别并创建关系、趋势和模式,这些对人类来说,是不可能单独完成的任务。
你马上就会发现,BenvolentAI 正在使用自然语言处理(NLP),如果他们正在识别疾病和治疗研究之间的关系,他们可能会使用一些知识图谱。
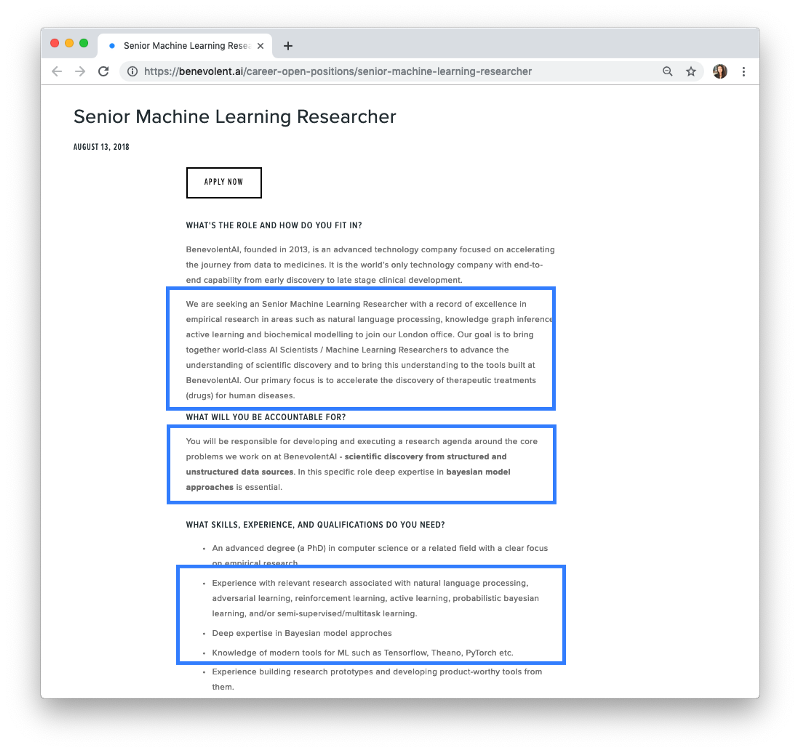
如果你浏览 BenvolentAI 的招聘页面的话,你会发现他们正在招聘一名高级机器学习研究员。这是一个高级职位,所以它并不是一个完美的例子,但是,让我们看看他们对这一职位要求具备的技能和资格都有哪些:
自然语言处理、知识图谱推理、主动学习和生化建模
结构化和非结构化数据源
贝叶斯模型方法
熟悉机器学习的现代工具
这里给你提供一些下一步该怎么做的步骤:
使用结构化数据
使用非结构化数据
在知识图谱中对关系进行分类(请参阅这个很好的资源)
学习贝叶斯概率和建模方法
处理自然语言处理项目(即文本数据)
我们并不建议你向通过搜索找到的公司应聘职位,而是查看它们如何描述客户痛点、公司的价值主张,以及他们在职务说明中列出哪些技能来指导你的研究。
机器学习栈的工具
在 BenvolentAI 高级机器学习研究员的职位描述中,他们要求“熟悉机器学习的现代工具,如 TensorFlow、PyTorch 等等。”
学习这些用于机器学习的现代工具似乎让人望而生畏,因为这个领域总是在变化。要将学习过程分解为可管理的部分,请记住从上面提到的机器学习工作流中锚定你的想法:“什么工具可以帮助我处理工作流的这一部分?”
要了解这个机器学习工作流的每个步骤都有哪些工具,请参阅 Roger Huang 撰写的《Introduction to the Machine Learning Stack》(《机器学习栈导论》),这篇文章涵盖了 Docker、Comet.ml 和 dask-ml。
从战术上来说,Python 和 R 是数据科学家使用的最常见的编程语言,你可能会遇到专为数据科学应用而设计的附加软件包,如 NumPy 和 SciPy,以及 natplotlib。这些语言是解释运行的,而不是编译运行,如此一来,数据科学家可以自由地专注于问题,而不必被语言的细微差别分心。为了理解数据结构作为类的实现,投入时间学习面向对象程序设计是值得的。
为了赶上像 TensorFlow、Keras 和 PyTorch 这样的机器学习框架,请务必查看它们的文档,并尝试端到端地实现它们的教程。
不管怎么说,你要确保你正在构建的项目展示了这些用于数据收集和整理、机器学习实验管理和建模的现代工具。
为了给你的项目带来一些灵感,请查看 Edouard Harris 的文章《The cold start problem: how to build your machine learning portfolio》(《冷启动问题:如何构建你的机器学习组合》)。
技能和资格
我们将这部分留到文章最后一节,因为这一节汇总了前几节的大部分信息,但特别针对数据科学面试准备进行了阐述。在数据科学家的面试中,有六个主要话题:
编码
结果
SQL
A/B 测试
机器学习
概率 (请参阅《Probability versus Statistics》(《概率与统计》)。
你会注意到其中一个主题(结果)与其他主题不同。对于数据科学职位来说,关于技术概念和结果的交流,以及业务指标和影响是至关重要的。
以下是数据科学面试问题的一些有用的汇总:
(《(120 个数据科学面试问题》)
(《数据科学面试问题与答案》)
(《数据科学面试中的危险信号》)
《I interviewed at five top companies in Silicon Valley in five days, and luckily got five job offers》
(《五天内我参加了硅谷五家顶级公司的面试,幸运的是,我得到了五份工作机会》)
你会注意到,我们收录了《Red Flags in Data Science Interviews》这篇文章,当你应聘职位时,你会遇到一些这样的公司,它们仍然在构建数据基础架构,或者可能对自己的数据科学团队如何适应更大的公司价值缺乏扎实的理解。
这些公司可能仍在需求层次上向上攀升。
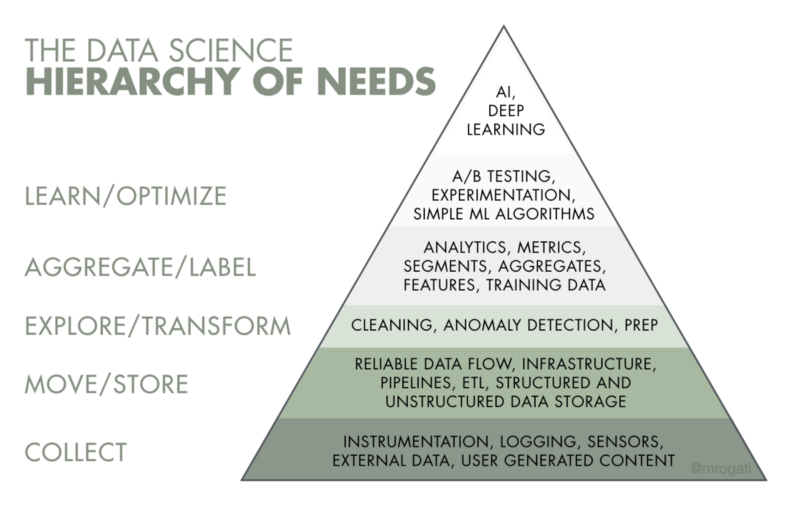
流行的人工智能需求层次。来源:Monica Rogati
对于一些关于数据科学面试的一些期望,我建议你阅读 Tim Hopper 写的文章《Some Reflections on Being Turned Down for a Lot of Data Science Jobs》(《关于大量数据科学工作被拒的几点思考》)。
感谢阅读本文,希望本文能够帮助你了解数据科学是否你应该考虑的职业,以及如何开始这段旅程!
英文原文:
[https://www.kdnuggets.com/2019/06/developer-transitioning-data-science-best-resources.html

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论