

如果你用谷歌进行搜索,将会搜到大量关于 机器学习 入门的文章和文献,然而不幸的是,大多数文献都是关于模型训练的,而涉及 如何在生产中为机器学习模型提供服务 的文章并不多,即使有,也往往集中在单一的方法上。在本文中,我将尝试 对生产环境中模型推理的不同选项进行概述——考虑到不同的因素 ,如团队规模/结构、推理模式(RPC 与流)、部署(云与内部)和其他方面。
本文最初发表于 ITNext 博客,经原作者 Javier Ramos 授权,InfoQ 中文站翻译并分享。
引言
人工智能和机器学习是一个热门话题,越来越多的人们正在进入这个领域,这一领域有很大的潜力,而且它正处于发展的早期阶段。我相信,在接下来的几十年里,我们将会不断听到人工智能领域取得的突破。
传统上,这本是一个专门保留给学者的领域,他们拥有开发复杂机器学习模型的数学技能,但却缺乏将这些模型产品化所需的软件工程技能。另一方面,在过去几年中,出现了专注于简化机器学习开发的托管服务和其他框架,允许没有科学博士学位的软件开发人员创建机器学习模型。但是,与拥有专门的数据科学家团队相比,模型的定制水平和性能水平往往要低一些。
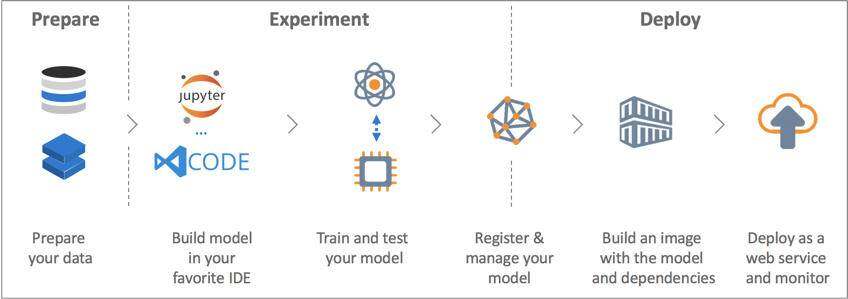
机器学习工作流
注意事项
团队结构
根据你的需求,你可能需要不同的团队结构。如果你不需要对模型进行细粒度控制,而是使用标准的分类/回归模型,你可能更愿意利用现有的机器学习软件工程师,特别是在以下场景中:
使用托管云机器学习服务,如 AWS SageMaker或 GCP AI Platform。
这种方法易于实现 ,并提供了极好的结果,但你会受到提供商能力的限制。此外,它的使用可能会变得昂贵。
另一方面,如果需要尖端的人工智能、高级机器学习调优以及完全控制模型(你是一家人工智能公司),那么你可能希望拥有一支 专门的科学团队 。这种方法可以让你完全控制模型和创新空间,因为大多数竞争者使用的是云提供商的标准工具。然而,这会在工程团队和科学团队之间形成孤岛,使得管理起来相当困难。我们将在后面讨论解决这一问题的不同方法(模型即数据)。
推理类型
一个重要的考虑因素是你打算如何为模型提供服务。最简单的选择是在线 RPC 风格的代码。在这种情况下,将模型作为服务(通常是 HTTP 微服务)运行,你向其发送请求并获得响应。在这种情况下, 托管解决方案极大地简化了模型的部署和监控。
另一个可能也是最常见的用例是使用机器学习模型丰富数据管道 ,例如,向非结构化数据(如 自然语言处理管道中的文本)添加“结构”。这可以用批量或实时来完成。对于批处理,可以使用诸如 SparkML之类的工具。对于流,我们将审查不同的选项,这将是我们的主要关注点,因为流处理更加复杂、更加有趣。特别是如果你需要为模型维护一个特定状态,那么就需要使用有状态流。
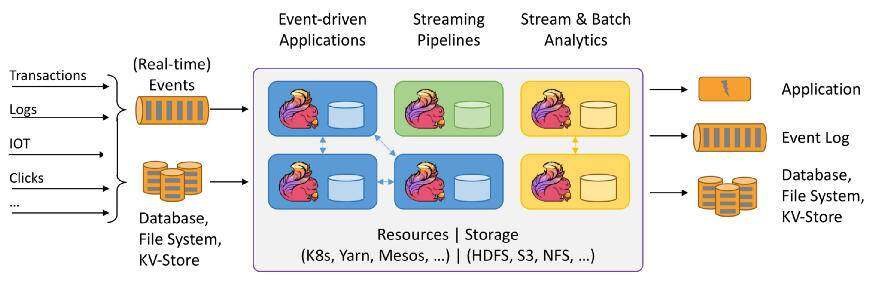
流处理
托管解决方案
你在哪里运行服务?是在内部部署还是在云端?如果你是在 云端 上运行的话,那么有几个服务(比如 AWS SageMaker或 GCP AI Platform)负责模型服务方面以及监控方面,从而使其变得简单得多。如果是内部部署(on-premises)的话,就需要使用企业解决方案(如 Seldon)或数据管道(如 Spark)。然而,这样一来,就需要付出更多的努力 。
模型服务类型
这一点非常重要。部署经过训练的模型的最常见方法,是将你选择的工具保存为二进制格式,将其封包在微服务(例如 Python Flask 应用程序)中,并将其用于推理。托管解决方案简化了这个部署过程,并提供了执行金丝雀版本发布和 A/B 测试的工具,这种方法称为“ 模型即代码 ”( Model as code )。然而,这种方法有几个缺点 ,随着模型数量的增长,微服务的数量成倍增加,因此故障点、延迟等等的数量也随之增加,从而使得管理变得非常困难 。
另一种较新的方法是标准化模型格式,以便可以使用任何编程语言以编程方式使用它,这样就不必将其封装在微服务中。这对于延迟和错误管理是个问题的数据处理流特别有用。因为我们是直接调用模型,所以我们不用担心监控、错误处理等问题。这种方法被称为“ 模型即数据 ”( Model as Data )。

模型即数据
现在,让我们特别关注数据流和模型服务选项“模型即代码”和“模型即数据”。我们将不会关注大数据机器学习功能,如 Spark ML,尽管我们将在用例部分重新讨论它们。
模型即代码
这是部署模型最常见的方式,主要是因为数据科学家不是站点可靠性工程师(SRE),因此他们通常使用自己的工具集(如 Python、R、Jupyter Notebook 等)来训练模型,并使用他们现有知识(通常是 Python)将模型封装在 HTTP 服务中。这是因为最初没有保存模型的标准。由于软件开发人员对机器学习一无所知,因此这个解决方案对他们来说非常有用,因为他们知道如何调用 REST 端点。但是这会给管理所有交互 带来大量的复杂性 ,使得维护变得非常困难。为了缓解这一问题,人们引入了托管解决方案。
一些专注于模型服务的工具有 Seldon、 Clipper或 TensorFlow Serving。
这种方法的 优点 在于:
易于开发。
数据科学家无需关心生产维护和监控,而站点可靠性工程师可以管理服务。
可以实现自动化 。像 AWS SageMaker 等工具负责部署服务、创建 URL、A/B 测试等等。一般来说,像 SageMaker 或 Kubeflow这样的工具可以处理从训练到评估的所有方面。
另一个优点是,我们可以使用度量和其他元数据在应用程序中保持模型状态 。
缺点是:
随着越来越多的模型被添加,监控和维护模型的复杂性也随之增加。
额外的延迟和更多的故障点会影响可靠性。
阻抗失配 :与软件开发人员相比,数据科学家使用的工具集不同,如 R 或 Python。
难以更新模型 。这需要由站点可靠性工程师使用 Kubernetes 的功能通过金丝雀方法推出新版本,但如此一来,就失去了细粒度控制和细粒度度量,因此很难获得关于模型性能的准确和快速反馈。因为模型就是代码,所以很难更新。
很难实现背压和断路器来处理网络故障。这就是为什么在 Spark 或 Flink 等大数据的托管集群中很难使用,因为这些集群不能很好地处理阻塞的 I/O,这也是为这些工具开发机器学习库的原因。
另一个问题是,很难准确地复制在训练阶段获得的结果,因为权重和其他元数据等内容在生产模型中可能不完全相同。
由于额外的延迟和数据大小,它无法扩展到大数据流管道。
下面是一个示例,说明了如何在数据流中调用外部服务进行模型推理:
正如你所见,我们需要引入 Future 来处理阻塞 I/O 和处理故障、指数回退重试、延迟等。因此,一种常见的模式是使用 Sidecar 来处理所有这些逻辑:度量、重试、断路器等。在 Kubernetes 中,这可以使用 Sidecar 容器来完成。
一般而言, 流处理器管道的目标是避免阻塞 I/O ,而“模型即代码”带来了这个障碍,正因为如此,才引入了“模型即数据”。
模型即数据
最近的一种方法是将模型标准化为数据,以便可以在任何编程语言中读取。目前, TensorFlow 已经成为 事实标准 ,新的 SavedModel格式包含了一个完成的 TensorFlow 程序,包括权重和计算。它不需要运行原始的模型构建代码,这使得它对于共享非常有用。
有几个项目尝试将模型标准化为数据, PMML是最著名的格式,使用 XML 表示数据。其他格式有 PFA和 ONNX。
正如我们之前提到的,大多数机器学习实现都是基于作为 REST 服务的运行模型,这可能不适合大容量数据处理或流系统的使用,因为流系统需要重新编码/启动系统以实现模型更新,例如 TensorFlow 或 Flink。“ 模型即数据”非常适合大数据管道 。对于在线推理,实现起来相当简单,你可以将模型存储在任何地方,如 S3、HDFS 等,将其读入内存并调用它。
主要的问题是,我们需要保存模型状态来执行 A/B 测试或更新元数据。对于流处理,这意味着我们需要有 状态流 。此外,我们还需要一种简单的方法来更新模型,而又不会干扰模型服务。为了克服这一点,一种常见的模式是使用 Lightbend 引入的 动态控制流。
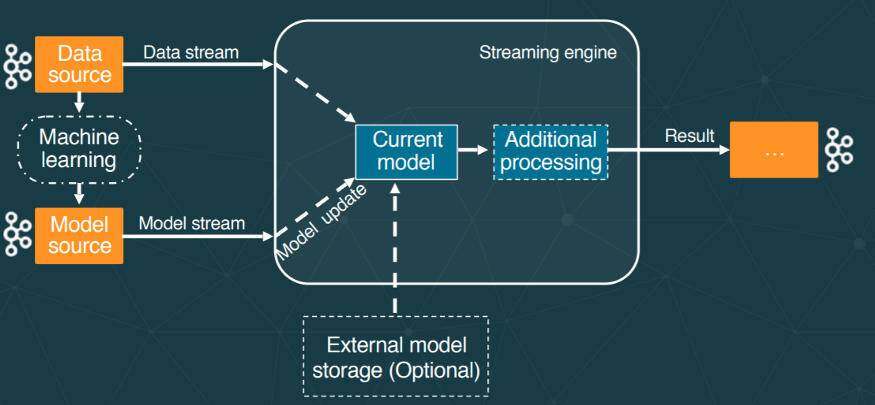
该解决方案提供了状态流处理 ,能够根据服务状态的变化动态更新状态。主流通过对模型的请求来接收数据,从而丰富数据。辅助流用于接收模型更新。整个模型可以序列化并通过网络发送,模型可以存储在内存中。在这个用例中,模型就是状态。或者说,可以从外部源(如 S3)检索模型。
这个解决方案可以使用有状态解决方案来实现,比如 Akka Streams、 Spark Structured Streaming或者 Flink。现在,让我们来看一看使用 Alla Streams 和 Spark Streaming 的示例。
Akka Streams
Akka Streams是为流处理而构建的底层库。它为构建任何类型的流处理应用程序提供了极大的灵活性。这是一个类似于 Kafka Streams的库,这意味着你拥有完全的控制权,但你必须管理部署,因为它不是 Spark 或 Flink 这样的托管集群。这些应用可以很容易地在 Kubernetes 上运行。有关不同流选项的更多信息,请参阅这篇 博文。 Alpakka可以用来连接 Kafka 或其他来源。
主要思想是有两个 Akka 流,一个用于数据,另一个用于模型更新。多个模型可以链接或并行运行,因此你具有完全的灵活性。你可以使用 Akka DSL 来生成复杂的图,以满足你管理模型之间的依赖关系的需要。 Actor 可用于管理状态,例如,你可以为每个模型版本使用一个 Actor,从而允许对 A/B 测试进行细粒度控制。
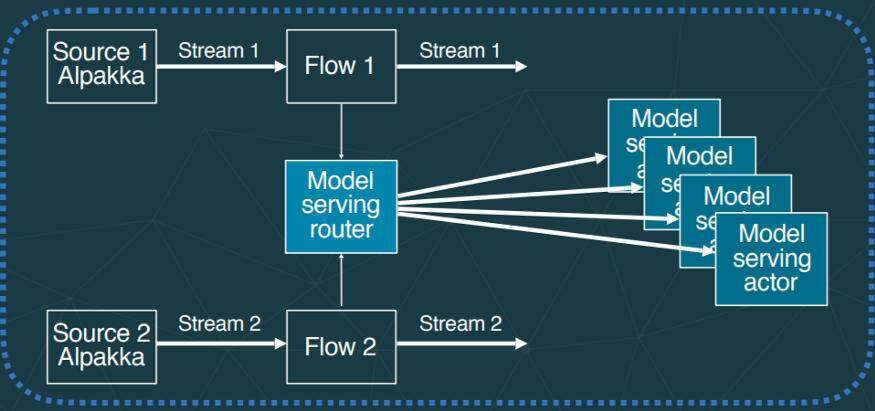
模型服务 Akka Streams
其想法是使用 ask 模式来调用将模型作为其内部状态的 Actor:Consumer.atMostOnceSource(…).via(ActorFlow.ask(1)(…)…
然后,每个 Actor 将存储模型,并在每一条消息上,调用模型并返回结果,我们可以调用多个模型来丰富我们的数据管道。
这样,我们就可以在运行时更新模型,而无需重新部署任何服务。该模型可以实现一个包含 TensorFlow 或 PMML 二进制数据的类。
Spark Structured Streaming
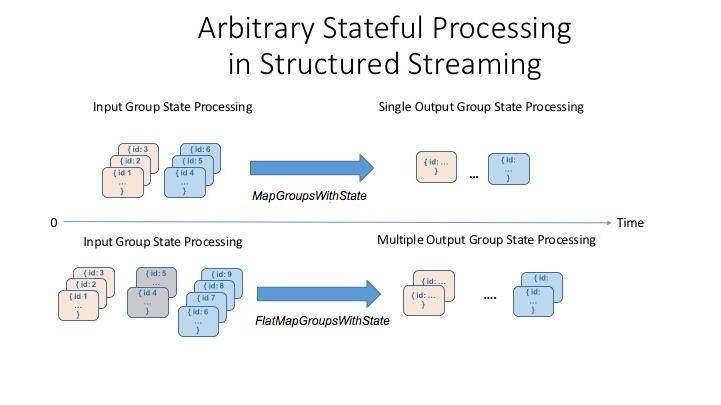
有状态的处理 Spark
动态控制流也可以在 Flink 和 Spark Structured Streaming中实现。在 Spark 中,可以使用联合来连接数据流和模型流。然后使用 mapGroupsWithState对组合流中的数据进行评分。这种方法使用 Spark mini-batching ,这会带来额外的延迟。
另一种较新的方法是使用 Spark Streaming,它可以实现实时模型服务 。
Queryable State可以用来管理有状态应用程序的状态,它允许在不使用任何外部数据源的情况下,访问整个流的状态,因此我们的模型及其元数据等度量可以使用 交互式查询从流外部进行查询。
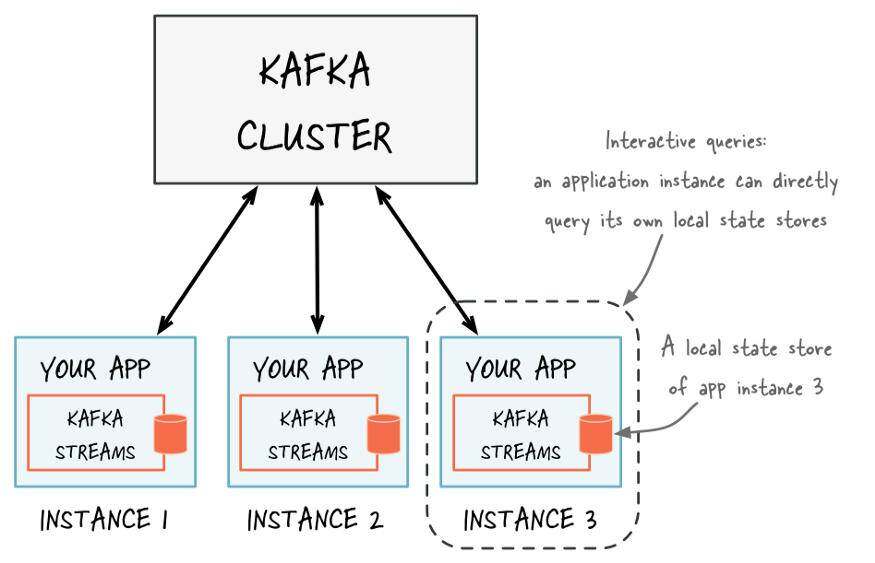
交互式查询
模型即数据的优缺点
优点是:
简化模型管理。
模型标准化。
低延迟。
易于实现,可用选项很多。
当有孤岛时,有助于沟通。
缺点是:
并非所有的机器学习工具都支持当前标准格式 。对于某些用例,你还不能使用这种方法。
尚处于标准化的早期阶段。
用例
概括一下,让我们通过不同的用例来回顾我们的选项:
你没有专门的数据科学家团队,而是在云端中运行服务,并且希望构建你自己的分类/回归模型,供你的服务使用:在这种情况下,请使用你的云托管服务,例如 AWS SageMaker 或 GCP Kubeflow。
你需要从图片中检测文本,或创建聊天框,或翻译文本,或者一般来说,任何高级的机器学习服务。在这种情况下,请使用托管服务。所有云提供商都提供图像识别、文本到语音、翻译、计算机视觉等等。
你有一个使用 Spark、Flink 或任何其他集群的现有数据管道。你希望使用众所周知的有监督或无监督的模型来丰富数据。你没有专门的数据科学家团队。在这种情况下,请使用已经集成在平台中的 SparkML 或 FlinkML ,无论你是在内部部署还是在云端中运行,都很容易使用。
你有一支专门的数据科学家团队,你可以以内部部署的方式运行你的服务。你不需要流处理。在这种情况下,请使用 Seldon或任何其他模型服务来提供服务。
你没有专门的数据科学家团队,你只能以内部部署的形式运行你的服务。你以前没有相关经验。在这种情况下,请迁移到云端或组建一支数据科学家团队。
你有一支专门的数据科学家团队,你需要丰富你的数据流管道,需要节省成本,而云解决方案过于昂贵。在这种情况下,尽可能使用模型即代码的动态流。通常,当你有孤岛时, 模型即数据是一个更好的选择。
对于数据流,只要 PMML或 TensorFlow 支持你的用例,就可以尝试将模型用作动态流的数据。如果不支持的话,请使用支持背压和重试的 Akka 流。
结论
根据用例的不同,我们已经看到了部署机器学习模型的不同选项。如果可能的话, 想办法打破孤岛 ,让数据科学家和工程师一起工作。 考虑到数据量和数据速度 ,如果低延迟是你的优先选择,那么请使用 Akka Streams ,如果你有大量数据的话,请使用 Spark、Flink 或 GCP DataFlow。如果你无法打破孤岛的话,那么模型即数据是一个更好的选择。
探索并使用你的云提供商人工智能平台 ,这将会大大简化你的部署。如果预算很重要,或者你是一家人工智能公司,并且你想完全控制你的模型,那么只有执行你自己的模型。
我非常推荐 Lightbend 的 这本书。还可以查阅这篇关于动态流的 文章。最重要的是, 不要忽视生产你的模型服务过程的重要性 ,这一点 非常重要 。
作者介绍:
Javier Ramos,是一位拥有 20 多年的软件工程师。曾在许多公司担任过 DevOps 专家和大数据工程师,尤为关注机器学习。
原文链接:
https://itnext.io/machine-learning-model-serving-options-1edf790d917

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论