
号称性能吊打 ChatGPT 的 GPT-4 近日又一次引爆关注。 据 OpenAI 介绍,当任务的复杂性达到阈值时,二者就会显现差异。它的发布是一件新鲜事,但其背后的多模态大模型技术其实已经发展多年。如今,大模型工程应用的能力成为很多企业关注的重点,也是以 ChatGPT 为代表的预训练大模型广受关注的原因。
目前,大模型从自然语言处理已经扩展到多媒体视觉、多模态等多领域。近日,在英伟达 GTC 2023 大会上,快手的技术专家张胜卓、韩青长、李杰以多模态超大模型在快手短视频场景下的落地为例,分享了多模态超大模型落地过程中的难点、技术解决方案和性能收益。InfoQ 对分享内容进行梳理,以飨读者。
主流训练大模型的方法主要会从算法模型架构、分布式并行加速、内存和计算优化三个层面来比较。确定适当的算法和模型架构是大模型训练的第一步。
快手多模态超大模型,采用的是类 T5 的 Encoder + 多 Decoder 架构,通过 Encoder 接受图像、文本多模态语料,学习特征提取能力;通过 Decoder 输出上下文 Embedding 向量,为下游任务提供用户特征信息。
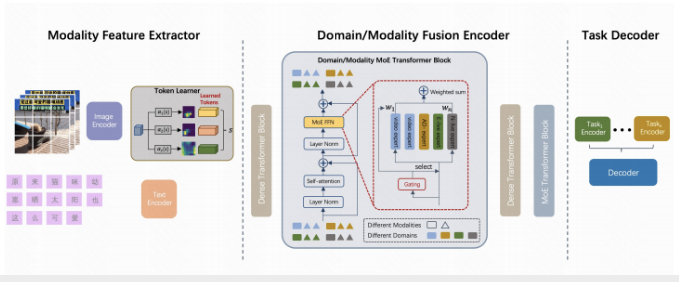
数据规模和模型容量一直以来是决定深度学习发展的关键指标。条件计算的引入实现了可以在不增加计算量的情况下,增加模型参考量。稀疏门控 MoE 是超大型神经网络的条件计算方法之一。
快手多模态超大模型采用的是门控神经网络稀疏 MoE 架构,这种架构实现了模型容量超过 1000 倍的改进,在 GPU 集群的计算效率损失很小,可以实现多场景多任务统一建模的形式。门控网络让快手可以通过对短视频、商业化等不同业务场景构建不同的专家组来选择最合适的专家来处理数据。稀疏门控 MoE 架构吸收信息的能力受限于参数的数量。所以,快手通过扩展专家数量,达到增加模型参数量、提升模型效果指标的目的。目前,快手该模型的专家数量近 200 个,模型参数量达 100B(千亿)。
快手希望多模态大模型可以帮助公司构建通用的理解能力,在推荐、搜索、广告等核心业务上取得一些业务收益。那么,多模态超大模型工程应用为什么这么难?
多模态超大模型工程应用,难在哪?
快手技术团队发现,训练时间漫长、推理效率过低、部署相对复杂是多模态超大模型工程应用的三大拦路虎。
1. 训练时间漫长
2017 年 Transformer 结构提出后,深度学习模型参数突破了 1 亿。2021 年末,Google 发布的 Switch Transformer,首次将模型规模提升至 1.6 万亿。与超高速增长的模型参数量相反,GPU 显存增长有限,有数据显示每 18 个月仅翻了 1.7 倍。模型参数量的增长和硬件的显存的增长之间的差距越来越大。但是,超大的计算量和超大的参数量是训练 AI 大模型训练的必经之路。在千亿模型上训练就需要 1.5TB 显存,但快手当时使用的最新硬件 A100 只有 80GB。
显存不足只是一方面。越大的模型参数就需要越大的规模训练样本和越长的训练时间。就算有算力的增速,不断扩大的训练数据集耗费的训练时间依然是一般业务团队难以承受的漫长。漫长的训练时间带来的是成本不可控的增长。
2. 推理效率过低
大模型的高效推理是实现大模型工程应用落地的关键所在。相对训练环节,推理环节在计算精度、算力消耗量等方面的要求较低,但显存增长速度的限制同样会出现在推理环节。推理速度受限于通信延迟和硬件内存带宽,所以不仅要在保证低延迟的前提下,尽可能节省计算资源,还要尽可能使用现有显存满足推理的需求,提升推理效率。可现实情况是,100B 模型约需 400GB 显存,但快手技术团队当时使用的主流推理卡 A10 显存仅 24GB。
3. 部署相对复杂
部署决定了多模态超大模型能否成功工程应用。常见的大模型部署难点有参数量过大、计算反馈慢等问题。大模型参数复杂,但在实际应用中却不需要那么复杂的参数和计算。一般企业会对大模型进行精剪、蒸馏、压缩,减少大模型的冗余。快手在部署环节也遇到了多模态数据预处理复杂和 CPU/GPU 负载不均衡的问题。
关关难过关关过,快手技术团队是怎么逐步解决这些问题的?
快手多模态超大模型落地技术方案
1. 混合并行训练
“训练是我们大模型应用的第一步,也是耗时最久、难度考验最大的一部分。”快手大模型训练和优化专家张胜卓表示。为了优化训练环节,快手采取了混合并行训练的方式,通过并行策略的选择和加速技术的提升来提升训练质量和效率。
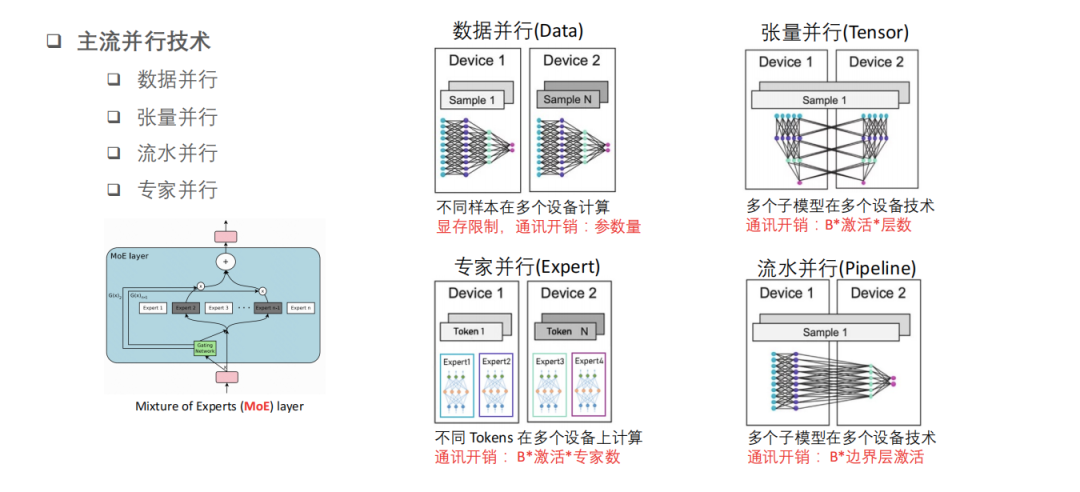
目前主流的并行策略包括数据并行技术、张量并行技术、流水并行技术和专家并行技术。快手技术团队在实施混合并行训练时,也发现一些需要考虑的问题。
第一,数据并行技术可以将数据分成不同的样本,用不同的设备同时做计算,让每个设备都有一个完整的模型。这样带来的问题是,单个设备上模型可以加载,但是受到显存的制约。所以在多个机器之间并行的时候,快手技术团队通过 AllReduce 来实现多机 / 多卡之间的梯度同步。
第二,在更新模型的时候,卡与卡之间激活传输产生的通讯开销几乎是一个参数量级别,所以如果把模型做水平方向的拆分,子模型同时并行在多张设备上,就需要考虑层与层之间做计算时的依赖关系(激活开销)。
第三,流水并行,指的是在垂直面上切分,把不同的层切成不同子模块,并行在不同的卡上。流水并行是在模型上做并行,并行开销在不同设备上的边界上。常见的流水并行切分策略,一种是通过参数量,保证参数在不同的卡上面相对来讲比较平衡;另一种是基于规则,把不同的 Transformer Layer,按 Transformer Layer 来切分。前者容易忽略不同层算力和计算需求不一样,后者在相同规则的 layer 之间,算力是平行的。
但是这里又会出现新的问题,由于在复杂模型场景下,layer 的种类非常多,用简单规则很难匹配,粒度太粗、规则太简单,很难覆盖快手的真实场景。
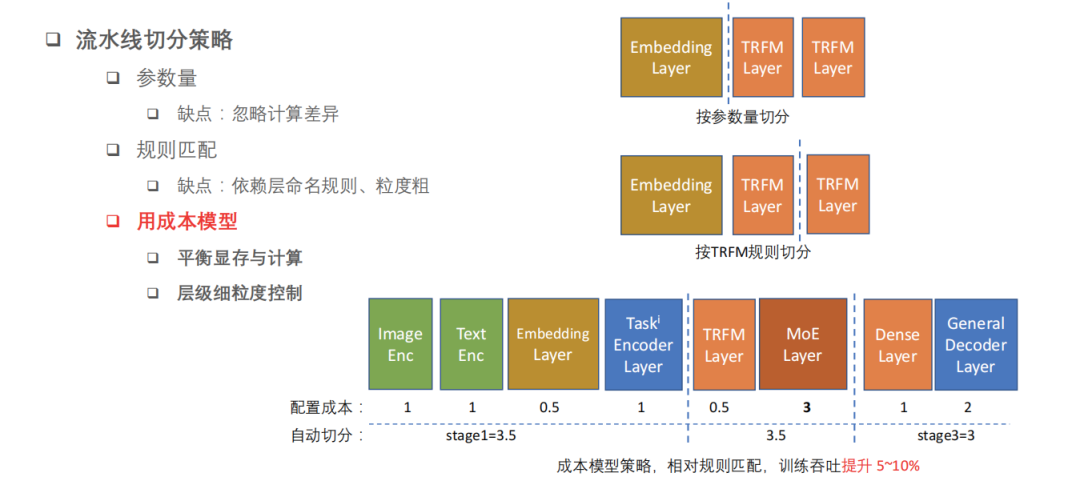
所以,快手技术团队使用了成本模型的方式,把显存和计算作为两个主要的约束做一些平衡,同时考虑显存不会 OOM(显存不足)的场景下,怎么能够把计算做到相对平均,在流水线上面能够没有显著的计算瓶颈。这样做的好处在于,可以达到更细颗粒度的控制。快手技术团队通过这个成本模型来实现自动化的并行切分,相对于简单的规则匹配,性能显著提升了 5%-15%。
第四,专家并行是针对于 MoE 架构才有的,不同的 Token 会经过 gate 网络进入不同的专家网络上面输出,再到不同的设备上面。所以在不同的设备上面还有通讯,它的通讯量跟激活值 + 专家数有关系。
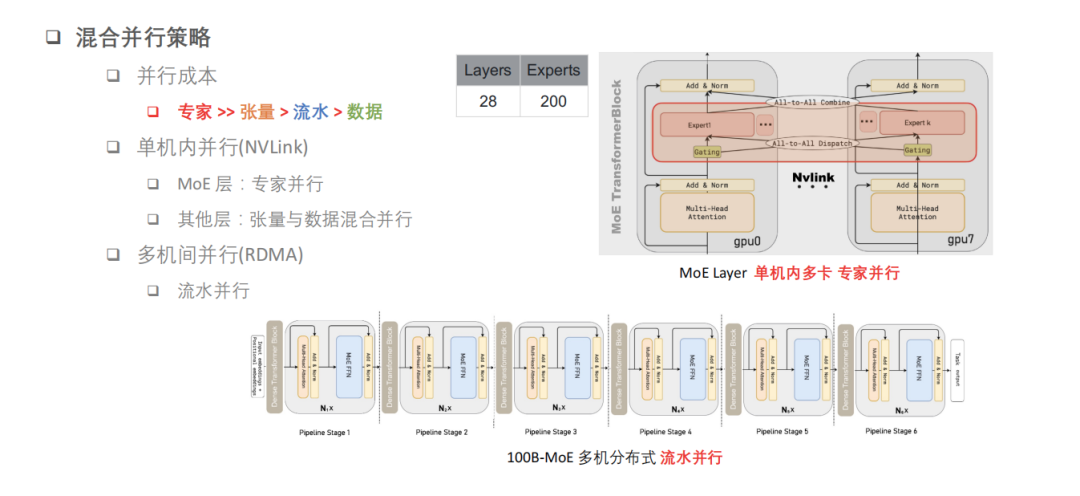
基于此,快手制定了如下的并行策略。
对于千亿模型,由于硬件条件使用的训练环境是单机 8 卡 A100,通过 NVLink 来高速互联。所以快手会优先考虑,把并行成本最高的这部分专家并行放在单机多卡之间。
另外,把张量并行和数据并行放在单机多卡,应用于其他层上,这样单机内部通过高速互联可以形成专家的并行、张量和数据的混合并行。另外,快手技术团队在不同的机器之间为了降低通讯量,使用了流水并行,相当于把不同的层切分成不同的 stage,构建这样一个流水线。
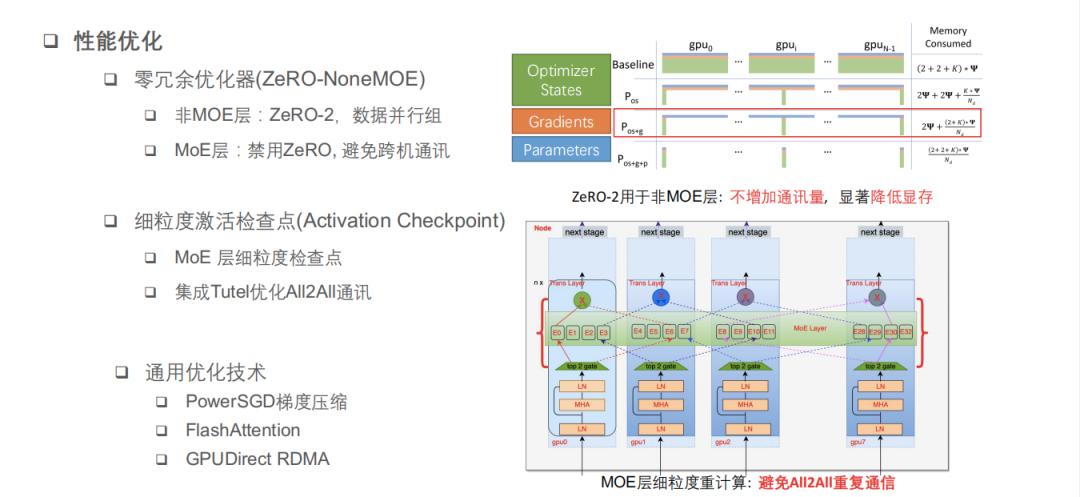
除了并行策略,快手还从加速技术方面降低整体训练耗时。
一方面,快手使用了零冗余优化器,在非 MoE 层上面使用了 ZeRO—2,把 optimizer states 数据和 gradients 数据做了一些零冗余的切分。在不增加通信量的情况下,可以降低 GPU 的显存占用。在 MoE 层禁用了 ZeRO,避免掉跨机之间做通讯的情况。
另一方面,快手做了一些 Activation Checkpoint 的细粒度控制。“比如我们在 MoE 层 E 前向的时候会产生一次 ALL2ALL 的通讯,我们得到 MoE 层的输出,如果这时候在反向的时候再做重计算的话,它会重新触发一次 ALL2ALL 的通讯,实际上显存的占用和通讯成本的考量来看,ALL2ALL 成本会更大。所以我们会把 MoE 的细粒度检测点关掉,只在不需要 ALL2ALL 的层上面做一些 Activation Checkpoint。”另外,快手技术团队也集成了一些 ALL2ALL 通信优化库,优化通信性能。
此外,快手技术团队还采用了一些通用的优化技术,比如使用了 PowerSGD 梯度压缩算法,可以来提升多机之间的线性扩展比;集成了 FlashAttention 的优化,除了降低显存之外,也提升了计算性能;在 GPUDirect RDMA 等方面也使用了一些技术。
2. 优化显存和实现高效推理
快手多模态大模型的推理优化基于自研的推理引擎开发的。据悉,之所以选择自研推理引擎,一方面是因为在 DeepSpeed 上推理的成本有点高,而且难以集成量化、手写算子等自定义优化;另一方面,由于多模态大模型是一个非标准的网络,还有可能涉及到多卡推理,目前的 TensorRT 生态对多卡推理支持的并不太好。所以,快手自研发了一套推理引擎来作为 TensorRT 的补充方案。
快手的这套推理引擎有着高性能、高易用性和支持多卡推理的特点。
高性能方面,这套推理引擎支持一些常见的优化的手段,包括内存池的复用、MoE 和一些常见算子的融合、通过 Transformer 里变长序列的计算减少 padding 混合精度,以及 FP16 和 INT8 的混合精度。
高易用性方面,这套引擎提供了 Operator 和 Tensor 的抽象分装。Operator 实现了像类似 TensorRT 的一个 plugin,用户只需要自定义一些接口就可以;在 C++ 里提供了类似 PyTorch 的一个 API,开发者可以像在 PyTorch 里一样把这些 OP 搭建成一个模型,还可以通过参数来修改网络的结构,实现新 OP 和网络的成本比较低。Tensor 实现了一些新建、拷贝、Delete 等接口的便利性。
支持多卡推理方面,通过 Pipeline 并行、Tensor 并行和专家并行实现。
大模态大模型如何选择?
据韩青长介绍,一个千亿模型在 FP32 精度下大概要占 400GB 左右的显存。快手主要的推理机器是两卡 A10,加起来也只有 48GB 的显存,所以就需要模型压缩技术。
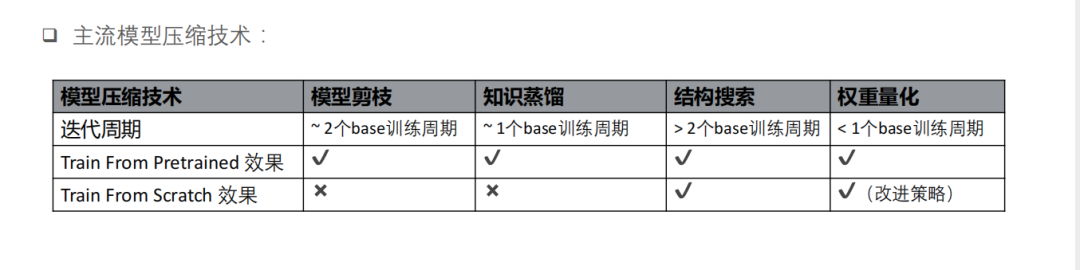
主流的模型压缩技术主要有模型剪枝、知识蒸馏、结构搜索和权重量化等。快手技术团队对比这些压缩技术发现,在迭代周期上模型剪枝大概需要 2 个 base 的训练周期,知识蒸馏需要 1 个 base 的训练周期,结构搜索是大于 2 个 base 训练周期,而权重量化是小于 1 个 base 训练周期,仅在这一项上权重量化优势比较明显。另外,权重量化在 Train From Pretrained 和 Train From Scratch 上效果都会比较好,基于以上这些信息的考量快手选择权重量化作为压缩手段。权重量化对于模型精度几乎是无损的。
量化效果如何保证?
快手采用的是 QAT 量化训练,通过在训练的时候插入一些伪量化的算子来模拟量化,学习一些量化的 scale,并把这些 scale 传给推理端,推理的时候只需要根据 QAT 学习到的 scale 执行量化的卷积算子以及反量化的计算就可以了。
此外,针对 Transformer 类大模型的权重量化策略,快手通过 QAT 量化训练提升效果,并结合推理算子融合规则插入量化算子。
第一,使用 QAT 量化训练的时候来提升训练效果。一是对称和非对称的量化方式搭配;二是选择多种策略选择最优的量化截断区间,来减少量化损失。第二,结合推理算子融合规则插入量化算子,比如已知在推理时 bias 会被融合进一些别的算子中,那么在 QAT 的时候就不去对 bias 进行量化,这样就能够提升模型推理速度,同时保证模型效果。
最终,快手通过 INT8 量化,将模型参数从 400GB 减小到 100GB。虽然压缩后的 100GB 距离目标的 48GB 还很远,但是已初见成效。
为了进一步实现目标,快手基于模型结构设计提出了权重选择性加载的策略,一方面通过对同一模型,在不同场景下只加载对应 group 的 MoE 权重,节省显存;另一方面优化模型加载机制,轮流为每个 op 加载权重,避免将所有权重拷贝到 host memory,节约实例内存。
层层手段下,快手成功将单场景部署的模型参数减小到了 40GB 以下。但是,主流推理卡(A10 24GB 显存)还是放不下,快手技术团队还需要继续想办法。
多卡推理或许是解决的办法。快手依照各部分的计算时间和参数量设计模型切分策略,选择流水线并行的方式,将模型和数据进行切分,以流水线形式计算,提高 GPU 利用率。
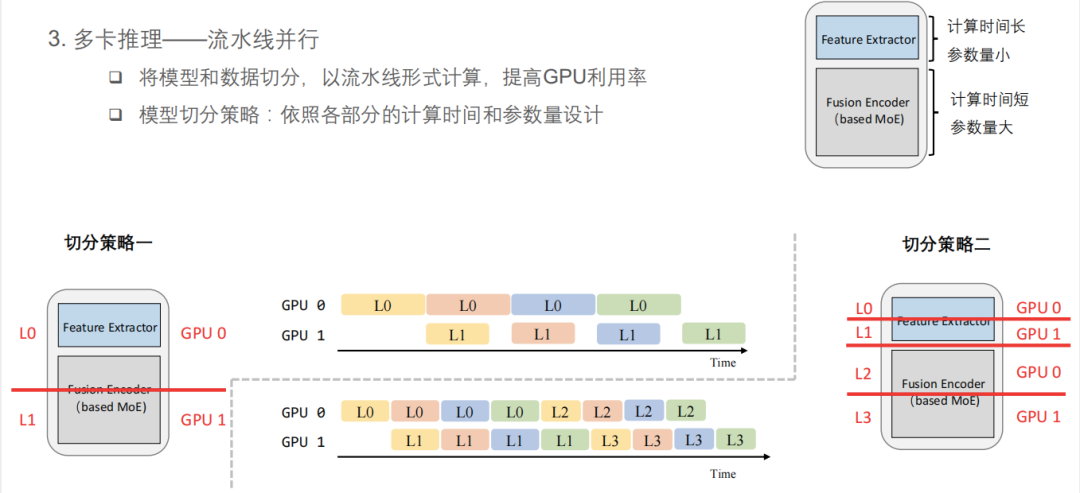
整个模型结构分为两部分,前部是 Feature Extractor,计算时间长、参数量小;后部是 Encoder,包含 MoE 的结构,计算时间短、但参数量大。快手的切分策略是在 Encoder 的靠前位置切一刀,将两部分别放在 GPU0 和 GPU1 上。从上图的 timeline 可以看到,两张卡的任务分配并不够均匀,明显 GPU1 的利用率比较低。因此,快手提出了一种改进的“切分策略二”——将 Feature Extractor 和 Encoder 各自平均分成两半,整个模型分成四部分,分别依次放在 GPU0/GPU1、GPU0/GPU1 上,实现任务分配更加均匀,提高两张卡的利用率。虽然这样做会增加一些通讯开销,但由于通讯量比较小,开销在可控范围内。
至此,显存的问题终于得到了解决。
计算的角度,如何优化推理呢?快手的答案是 MoE 实现优化和算子融合。
模型中的特殊结构主要是 MoE,快手技术团队首先按照 DeepSpeed 的方式对 MoE 进行了实现,但发现了两个可改进点:
第一,padding 引起冗余计算,计算量和存储量都与 capacity 参数成正比,capacity 参数是在实际计算过程中根据输入求出来的一个参数,这个 capacity 参数对于某些输入可能会很大,这样的情况下会浪费非常多的计算量和存储空间。
第二,DeepSpeed 方案是串行执行 expert 计算的,需要依次启动多个 kernel,GPU 利用率比较低。快手技术团队在测试的时候发现,这个实现下的 MoE 计算占比大约 70%—80%,而且非常容易 OOM(显存不足)。
快手技术团队着手优化 MoE 部分的实现,优化这两个问题。
第一,将所有 Token 进行重排,不依赖 Padding,避免无效计算。在实测中他们发现,对于一些样例输入计算量能够节省到原来的几分之一甚至几十分之一。第二,在一个 Grouped GEMM kernel 中并行完成所有 Expert 的计算,提高 SM 利用率。下图中的 Expert0 对应有 3 个 Token,Expert1 对应有 2 个 Token,Expert2 对应有 1 个 Token,其实这可以算是三个矩阵乘,并且三个矩阵乘的计算规模不一致,而 Grouped GEMM 就是专门解决这样问题的,它可以用来同时计算 N 个规模不一致的 GEMM。
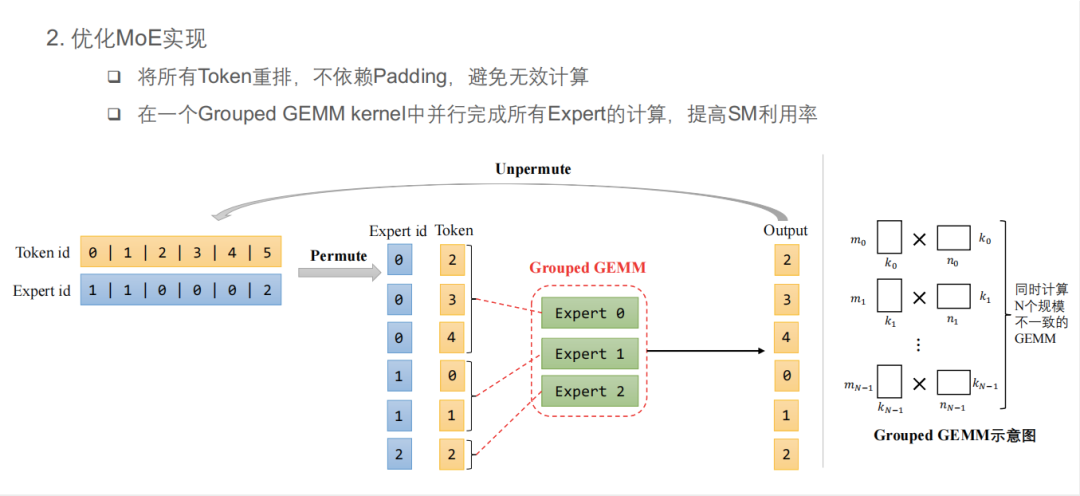
算子融合不仅可以节省一些访存量,还可以减少 kernel launch 的时间。快手技术团队从 MoE 算子融合和通用算子融合两方面来考虑算子融合的事情。
由于 MoE 部分使用了 INT8 量化,所以在两次 Grouped GEMM 前后及中间会有很多算子,如 Permute、Quantize、Dequantize、GELU、Unpermute。快手技术团队最终确定的方案是通用一些 Transformer 常用的算子融合,比如 LayerNorm、QKV GEMM 融合、Bias 和其它一些残差以及 LayerNorm 的融合,将这些连续的 element-wise 算子全都合成一个,整个 MoE 部分的 kernel 数量可以减少到 5 个。
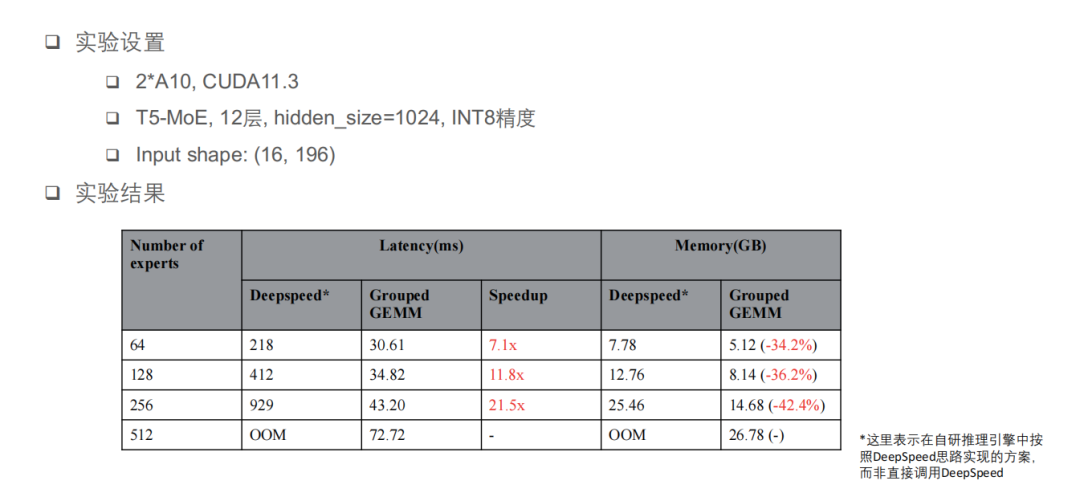
上图就是 MoE 优化后的一个实验结果,对比的对象分别是 DeepSpeed 的实现和 Grouped GEMM 的实现。“这里强调一下,这里并不是说直接调用 DeepSpeed,而是说在我们的自研推理引擎中按照 DeepSpeed 思路实现了一个方案。主要是 DeepSpeed 不支持 INT8,而且在两卡 A10 上是跑不起来的。这里的环境是两卡 A10,均为 INT8 精度。”可以看到,Grouped GEMM 在 Latency 上会取得 7—21 倍的加速比,显存占用可以降低 30%-40%,为大模型的推理上线创造了条件。
3. 优化模型部署
前文提到,部署决定了多模态超大模型能否成功工程应用。快手在部署环节也遇到了多模态数据预处理复杂和 CPU/GPU 负载不均衡的问题。
快手技术团队在部署时发现,为了追求最优性能,需要从 Python 训练代码迁移到 C++ 的线上服务代码,在迁移过程中容易出现各种差异,尤其是 CV 方面的预处理,如 Python 的 PIL 库等。为了解决图像预处理时 Python 库和 openCV 存在的 diff 以及加速期预处理,快手技术团队使用 SIMD 和 CUDA 分别实现了一套图像预处理库。
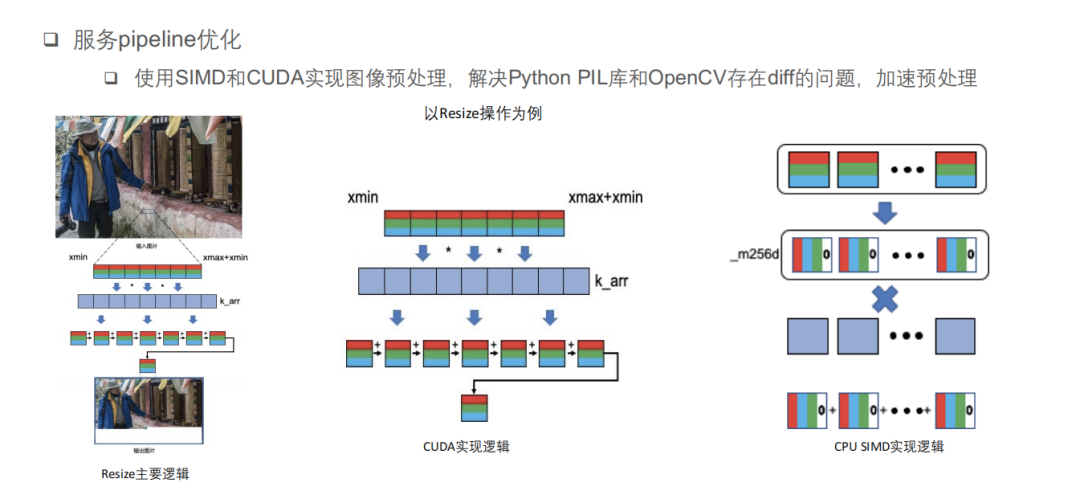
以计算引起 diff 的 Resize 操作为例,Resize 主要操作是通过不同的差值算法对图像进行缩放,主要操作是一个重采样的过程,对于目标图像上的一个点选取其源头中的采样区间,通过与不同的差值算法相乘、相加得到,这种乘、加操作非常适合 CPU SIMD 和 GPU CUDA 进行加速,CUDA 主要利用其现有模型进行加速,而 SIMD 采用了 AVX 并行指令集,将 RGB 通道的数据存入寄存器中,与差值系数进行并行的乘、加操作,实现线上结果与 Python 结果一致。
解决预处理 diff 之后,快手技术团队对部署方式进行了优化。
对于多模态的数据输入,快手技术团队在预处理阶段进行了并行处理,预处理之后得到的特征数据经过 AutoBatching 尽量凑到最大的 Batch size 数据送入 GPU 进行模型推理,以最大化利用 GPU 的性能,推理结果送入后处理队列等待处理。整个过程中 CPU 和 GPU 都能同时满负荷运行。
在线上大规模部署时,为了满足最佳的 GPU 的吞吐,使单次推理的 Batch size 尽量大,将预处理和 Batching 使用的 CPU 机器单独部署,使用更少的节点进行 Batching 操作,以聚合更大的 Batch size,增大流量低峰期的 GPU 数据输入 Batch size,尽量压榨 GPU 性能,配合线上的动态扩缩容机制能够大大提供流量低峰期的资源利用率。
4. 整体收益
在训练层面,快手技术团队基于 DeepSpeed 做了一些深度优化,集成 Megatron、Xformers、Tutel 等高性能库,最终可以实现大模型高效训练。在业务收益方面,相对于快手原本的 10B-T5 模型,100B-MoE 参数量扩大了 10 倍,样本扩大 16 倍,最终只增加了 75% 的训练卡时,在业务指标获得了显著提升。
在优化部署模型后,相比于第一个版本上线的 10B—T5 模型,快手 100B—MoE 模型上线之后的模型指标大大提升,在性能上模型变大 10 倍的情况下,在 Batch size 等于 16 的情况下折算到单卡 T4 依旧有不错的加速比,线上实际部署时机器资源在相同的流量情况下节省了将近 60%。
多模态超大模型工程应用,AI 商业化吹响号角?
据悉,不仅仅是技术层面上探索出了大模型从训练到落地的技术实现道路,快手多模态超大模型技术在快手公司内部的推荐、搜索、直播、商业化、电商等多个场景落地,以较低的资源成本取得了显著的业务收益。
在 ChatGPT 和 GPT-4 带动下,AIGC 大火。就连 Adobe 都推出了名为“萤火虫”(Firefly)的创意生成式 AI,正式杀入 AIGC 商业化赛道。可以预见,随着 AI 技术的进一步发展,大模型以及多模态模型的商业化应用将进一步加速。我们也期待看到更多多模态大模型工程应用案例的出现。




