
机器学习在行业中的应用变得越来越流行,从而成为了软件开发的常规武器。行业的关注点,也逐渐从机器学习能做什么,过渡到如何有效地管理机器学习项目的交付流程上来。
然而相对于传统软件开发,例如 Web 服务或者 Mobile 应用来说,这类程序的开发、部署和持续改进也更加的复杂。但好在经过不断的实践,行业总结出了一套敏捷的工程化流程,供大家在持续交付时遵循和参照。
在 Thoughtworks 技术雷达峰会上,徐昊就《机器学习的工程化》发表了主题演讲,InfoQ 也借此机会对徐昊进行了采访,进一步探讨了该主题。本文根据演讲和采访内容整理而成,有删节。
采访嘉宾简介:
徐昊,Thoughtworks 中国区 CTO。Thoughtworks 全球技术策略顾问、中国区首席咨询师,同时也是北京 Java 用户组(BJUG: Beijing Java User Group)和 Agile China 创始人。他从 2003 年起开始实践极限编程等敏捷方法,2005 年开始,多次以敏捷教练的角色帮助国内外多个团队实施极限编程。他在 Scrum 和 FDD 等敏捷方法、以及敏捷交付和敏捷项目管理等方面的经验极为丰富。目前,他主要致力于大规模团队(300-500 人)内的敏捷实践和管理再造,以及对企业级技术应用趋势和技术战略的研究。
为什么我们需要“机器学习工程化”?
数据都是一个企业的真正资产,未来企业都应该是数据驱动的。数字化转型潮流中,企业因担心跟竞争对手拉开差距,更为普遍地将机器学习应用到了各种业务场景中。在实际生产环境当中让机器学习产生价值还是一件比较复杂的事,虽然目前业界已经能让算法科学家的模型生效了,但也还存在一些挑战。
现在绝大部分企业机器学习后面的系统,都可以当作一个复杂子系统,是一个跟业务系统单独隔离开的系统。之前大家在讲机器学习的时候,很多人畅想业务数据能够自己适应应用的变化,机器学习和企业软件能得到结合,但实际情况跟这种终极理想状态相比,两者之间距离还比较遥远,业界还没有真正能够找到将机器学习和业务系统真正结合在一起的道路。很多时候机器学习仍然是作为一种外在的能力,插入到企业业务的主流程当中。
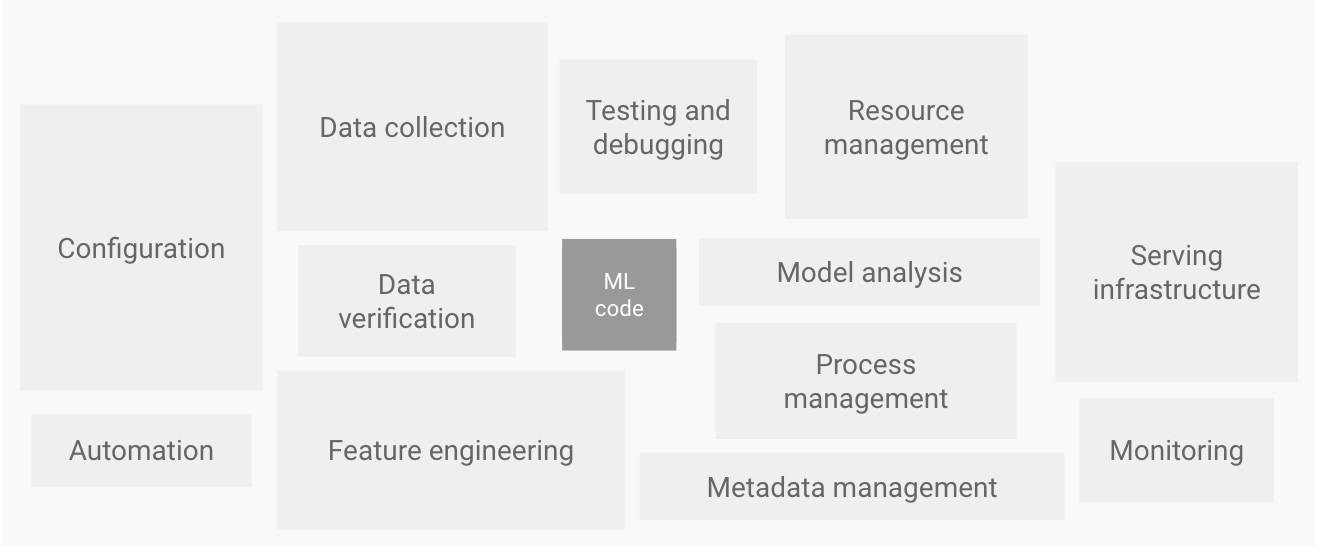
(图片源自网络)
在机器学习的应用场景中,机器学习代码只占一小部分,无论是自动驾驶、信用卡风控还是图像识别,90%以上是来自于工程领域的人。工程师们需要将算法科学家的模型应用到具体的软件环境中,知道如何跟算法科学家做交互。实际上,在现实环境中部署模型时,科学家给出的模型通常会失效,因为无法适应环境的动态变化或描述环境的数据的变化。由于机器学习模型的生产被认为是算法科学家独立的技能,为了取得成功,我们需要一个混合团队。目前的情况是,一个成功的团队可能包括数据科学家或 ML 工程师、 DevOps 工程师和数据工程师。工程师需要不断在生产环境中健康模型的质量,频繁重新训练生产模型,并尝试新的实现以生成模型。
为了战胜此手动过程的挑战,MLOps 就起到了作用,通过设置 CI/CD 系统以快速测试、构建和部署机器学习训练流水线。通过机器学习工程化,自动重新训练和部署新模型,从而达到弥合工程师和算法科学家之间的鸿沟的目的。
为什么机器学习难以“工程化”?
在传统软件开发中,以团队多人合作方式,追求“高效协同”和“质量可控”,让项目的质量、进度、成本都在可控范围内,这就是“工程化”能力。反过来说,当一个项目不够工程化的时候,实际上有两种情况。
第一种是依赖于个体活动,不需要与其他人一起协同合作的时候,那么其实它就是一个弱工程化体现。“其实大家也可以反思一下,哪怕是对于应用开发,团队里有些个人可能他会更强调自己个人贡献和个人活动,而忽略了团队之间交互,其实这也是一种弱工程化的体现。虽然并不是说我们做应用开发,就一定全部是工程化的,但当它是弱协同、强个体的时候,那么就一定是缺乏工程化的体现。”
第二种是启发性的探索活动。工程化的活动是指我们已经知道要去什么地方,这件事情可能之前大家干过,或者是知道行业里面有其他人实施过,我们只要按照步骤和方法把它拆解成小的步骤和方式就一定可以一样完成。而所谓启发式的探索活动是指我们并不知道事情如何实现,不知道事情完成的大概过程和顺序,我们需要不停的试错和探索,甚至还不能确定是否能达成最终目标。我们就认为这种情况不是一个可以完全工程化的过程,是一种弱工程化的体现。
那么机器学习就是一个非常典型的非工程化的场景,因为它极大的依赖于数据科学家的个人能力,过程也充满了探索。机器学习需要在数据上不断地进行实验和探索。就算深度学习已经降低了对特征工程的要求,但是对 hyper parameter 的调整,到底选择多少层网络,采用一个什么样的网络架构等等,都主要是依赖于科学家的个人经验。
为什么机器学习工程化需要新的工具体系?
机器学习项目跟一般软件不同,一般软件代码和数据分得非常清楚,项目开发构造的是代码,和生产环境结合之后才能产生一些数据。而机器学习在生产环境中,本身就是一个对数据加工的过程,所以没有办法像传统软件一样将代码和数据分开。看上去机器学习软件是代码组成,但实际上起到更重要的作用的是数据。
加上本身的弱工程化特性,所以机器学习是比较难以工程化的。但过去短短的几年间,我们把已经驯服了一个看上去来完全不能工程化的实验性品类,变成了一种能够和其他开发方法一样可以相互协同的常规化操作,从一种个人活动慢慢变成一种团队的活动,让它的结果越来越可控,然后更多地接入到了企业的生态中,“这个其实是一个非常有意思的过程。”
对比传统软件工程化的流程来看,机器学习工程化的第一步还是构建一个协同性的开发过程。这个起点源自版本控制,保证在构造的过程中,工程师的产物彼此之间是可以共享的,有明确的产物可以让团队有人员流动的情况下进行工作交接。很多的公司和机构的开发工程化实际上都是从有严格可追溯的版本控制开始的。
机器学习工程化的第二步是打通生产环境和开发环境之间的隔离,从开发环境到生产环境之后,工程师知道如何进行数据和模型的更新,在生产环境中进行运营和维护。这些跟传统意义上的开发都是一样的,都要将它变成一个协同性的团队活动,但是这里面的内容和工具呈现的形式会差别比较大。
拿版本控制举例来说,传统软件开发控制的数据量并不大,并且一个代码库几 G、几十 G 的规模就算很大了。数据量很小,代码也都是文本形态的,对于代码的变更是很容易理解的,所以在传统软件版本管理中,以代码行的修改作为变更要素。
但在机器学习中这些就不一样了,机器学习不仅仅包含代码,还包含模型、数据。机器学习首先得关注数据,数据格式和形态不一定是纯文本的,可以有图片、声音等,以图片像素或声音片段来进行修改。机器学习的数据是不会停止变化的,并无法控制它会如何变化。所以我们不需要每一个更改都定义一个版本,可以将整个数据看成一个跟时间相关的流,把很多天的数据变化算成一个时间段,作为一个版本。所以对比起来,数据对于版本的定义和代码对于版本的定义有很大的差异,这也是我们需要新工具的原因。
为什么 MLOps 不能简单类比 DevOps
2018 年开始出现了机器学习版本控制软件 DVC,DVC 从这时开始又反过来促进我们去思考数据科学工作流程。在开发流程中,开发代码或模型只是第一步。最大的努力在于使每个步骤都可以在生产中奏效,包含版本控制、模型服务和部署、集成测试、实验跟踪等各方面,让他们在最少的干预下能够重复自动运行。
当将以上所有工程化内容梳理清楚之后,我们还需要将这些步骤紧系在一起,这就是持续交付的业务流程设置工具起作用的地方。于是,MLOps 的概念就出现了,它让全流程变得更顺畅、更加持续,让机器学习越来越工程化。
MLOps 是一个 DevOps、数据科学和软件工程的交叉学科,是在生产中部署和可靠维护机器学习系统的一组实践和工具,“但和 DevOps 差别挺大,两者不能简单地进行类比”。
在传统软件开发领域,DevOps 实践能够在几分钟内将软件交付到生产环境并保持其可靠运行。在 DevOps 之前,软件开发方法是开发完软件,交给运维团队。运营中心看管着机器以及其它实际的物理执行架构。在云时代以后,机器的启动可以通过软件控制,开发人员就不再需要运维的人去做这件事情了,这就产生了 DevOps 运动。DevOps 主要控制的是机器,对于软件的升级也就仅仅是看作有一个机器要安装一个新的版本。
而机器学习工程化方面,它是代码加数据,利用数据训练神经网络,关注的是神经网络的参数调整,再将其部署到生产环境中进行试验。数据科学家从样本数据开始,在 Jupyter notebooks 上工作,或使用 AutoML 工具来识别模式和训练模型,但训练端环境和执行端环境可能没有直接的关联关系。当数据科学团队尝试将模型部署到生产中时,他们发现现实世界的数据是不同的,无法对不断变化的数据使用相同的数据和方法。
所以在实际开发中,开发人员需要不断重新采集数据,或对模型进行训练,或是对参数进行调整,再重新发布,MLOps 主要解决的问题是怎么把训练好的结果放到生产环境当中去。负责在生产环境下运行的和设计神经网络可能不是一组人,所以 MLOps 可能认为是一个这样的自动化过程,是通过一个流程把大家的工作串在一起。
对于 MLOps 而言,它反而不太关注机器是什么样子,更多的是关注现在的机器学习参数如何划分,神经网络的结构是否要调整,参数是如何调整的,等等。
MLOps 对本身执行的硬件环境关注是相对比较少的。他们唯一相近的地方都是在生产环境下对于最终的产物进行运维的过程,只能说在概念上仅此是相似的,而从工程实践来说差别是非常大的。
MLOps 只是起点
“机器学习工程化目前还处于早期阶段。”
现在我们终于不再去谈网络模型、谈特征工程这些跟机器学习本身算法相关的了。企业开始关注的是如何让机器学习算法,从开发环境过渡到生产环境,形成一套有效的流程,让所有人围绕这套流程来工作。MLOps 的出现,让人工智能朝着越来越成熟的工程化迈进了重要的一步。
这是一门全新且令人兴奋的学科,其工具和实践可能会快速发展。这还是一个开端,不是终点,徐昊认为,这说明了“我们工程界又驯服了一个新技术,让人工智能够在特定领域里提供一个更好的解决方案。”




