
编者按
坦率地讲,各行各业对如何落地知识图谱这个问题,或多或少都心存一丝疑惑。人类知识和机器可理解的知识有什么区别?知识图谱如何突破自身局限性,从“万事通”转为“科学家”?百分点认知智能实验室在实践探索中,通过利用自然语言处理技术获取结构化的信息抽取能力,探索出了一套行业知识图谱构建流程方法。尤其是基于深度迁移学习,帮助构建法律百科词条、公安文本知识图谱等行业项目中,在实体抽取、关系抽取、事件抽取等方面都取得了理想的实践效果。本文将从概念辨析、技术路径、实践总结,由虚到实、由浅入深引导大家理性看待知识图谱技术的能与不能,以更好地在实践中运筹帷幄。
本文作者:陈肇江、王勋、陈旭、吴永科、苏海波
信息抽取、知识
图谱及自然语言处理
1. 信息抽取的内涵与外延
新基建的大潮涌中,人工智能、大数据与 5G 应用是人们竞相追逐的灯塔,在描绘数字经济时代宏伟蓝图的时候,知识图谱与自然语言处理成为追捧的香饽饽。
如何从海量的文本或网页的原始数据中提取有价值的信息是行业知识图谱构建的关键因素,信息抽取(Information Extraction,IE)作为自然语言处理技术的任务,该任务的重点在于从机器可读取的非结构化或半结构化的文本中抽取信息,最终以结构化的形式进行描述,使信息可以存入数据库以供进一步处理。
在下文探讨信息抽取技术之前,首先厘清几个重要概念的内涵与外延,方便读者更加清晰地理解本文的意图。
1.1 知识与知识图谱:人类知识和机器可理解的知识有什么区别?
哲学家柏拉图把知识定义为确证的真信念(Justified True Belief),满足该定义的知识具有三个要素:合理性(Justified)、真实性(True)、被相信(Believed)[1]。柏拉图三要素原则是哲学界对于知识定义的主流观点,即人类的知识是通过观察、学习和思考有关客观世界的各种现象而获得和总结出的所有事实(Facts)、概念(Concepts)、规则或原则(Rules&Principles)的集合。人类发明了各种手段来描述、表示和传承知识,如自然语言、绘画、音乐、数学语言、物理模型、化学公式等,可见对于客观世界规律的知识化描述对于人类社会发展的重要性[2]。
知识图谱(Knowledge Graph)以结构化的形式描述客观世界中概念、实体及其之间的关系,将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力[3]。知识图谱本质上是以三元组结构(主语-谓语-宾语)表示实体及实体关系的语义网络,谷歌公司于 2012 年重新提出了知识图谱的概念以保持其在智能搜索引擎的领先地位。时任谷歌副总裁阿密特·辛格(Amit Singhal)指出知识图谱是“Things,Not Strings”,在此之前搜索引擎是通过爬取网页并基于关键词返回网页排序结果,而基于知识图谱得到的是与关键词有关联的表示真实世界中的实体的图文描述信息。
在行业的实践中之所以对知识图谱期望太高,是因为人类知识和知识图谱这两个概念容易引起歧义:人类知识包括原理、技能等高级知识,而知识图谱源自语义网络、本体论,借助 RDF 三元组及模式(schema)的形式构建计算机可理解、可计算的实体及实体之间关联的事实性知识库,即 图谱可形象地称作“万事通”而非“科学家” 。
1.2 知识获取、知识抽取与信息抽取的区别与联系
行业用户往往希望,结构化的知识靠 AI 自动化构建,不用介入任何人工,即可产生低成本、高质量的知识,然而这些是不切实际的幻想。因此,这里要正本清源,辨析知识图谱的常规的获取知识方式。
知识获取是组织从某种知识源中总结和抽取有价值的知识的活动(GB/T23703 定义)[4],我们认为,根据该定义,知识获取强调的是获取知识的一种活动,包括从结构化、半结构化和非结构化的信息资源中提取出计算机可理解和计算的结构化数据,以供进一步分析和利用。因此,其范围应包括知识抽取和信息抽取。
知识抽取 ,即从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱[2]。 信息抽取 ,即从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术[5]。
数据、信息和知识的关系 为:信息是存在于数据(数字、文本、图像等)中的反映客观世界的实体,通过提炼、加工建立实体之间的联系形成了知识,知识是对世界客观规律的归纳和总结。因此,知识抽取在方法上包括了信息抽取和 ETL(数据仓库),但方法不局限于结构化信息的生成或关系数据库模式(schema)的直接转换,还需借助本体库或自动方法归纳新的模式。
在本文中,知识抽取和信息抽取的内涵与外延近乎等价,两者都是应用自然语言技术从文本获取实体、关系、属性和事件知识。
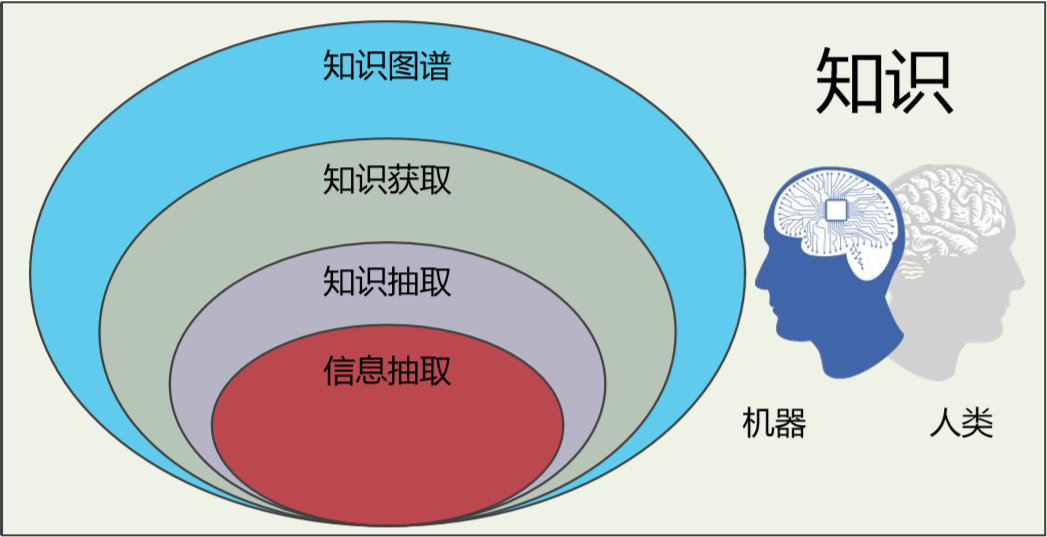
图 1 知识相关概念的包含关系
总的来说,知识、知识图谱、知识获取、知识抽取、信息抽取这些概念逐层递进,以一张韦恩图表示(如图 1 所示):知识的表示、获取和处理是人类特有的能力,知识图谱架起了一座基于人类知识和计算机获取认知能力的桥梁,知识获取涵盖了产生机器可理解的知识的活动,知识抽取强调通过数据模式组织三元组知识,而信息抽取是借助自然语言处理技术生产知识的能力。信息抽取是知识工程、大数据、机器学习、自然语言处理的交叉技术。下文将重点探讨信息抽取在知识图谱的应用与实践。
2. 融合信息抽取的知识图谱构建范式
近年来,自然语言处理技术的飞速发展尤其是深度迁移学习技术给方兴未艾的知识图谱注入了一针“强心剂”。预训练语言模型性能的提升降低了从海量的非结构化文本中获取知识的成本,推动了知识图谱在行业企业的落地应用。
如图 3 所示的体系架构,百分点公司在行业知识图谱的实践应用中,信息抽取技术占据着核心地位。行业知识图谱构建的生命周期历经知识定义、知识获取、知识融合、知识存储、知识应用多个环节,这些过程的每一步都需要专业的信息处理技术与技能才能完成。下面重点阐述信息抽取相关的知识定义及知识获取环节内容。
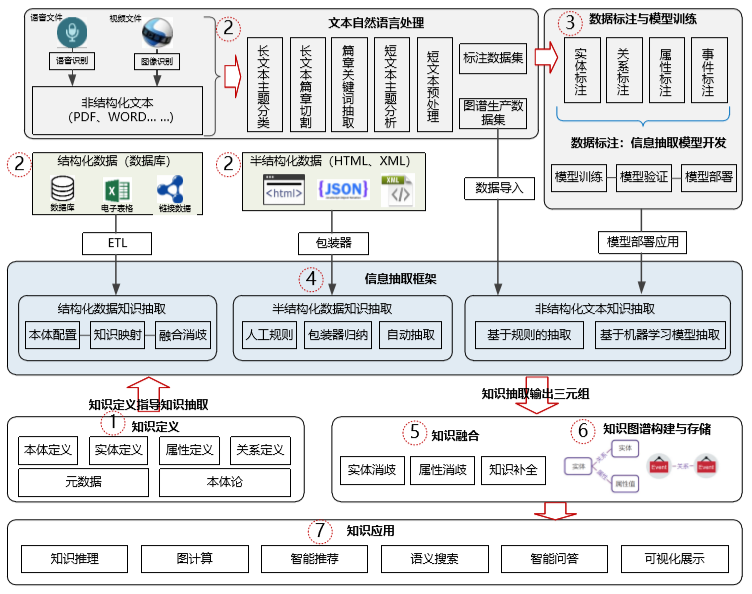
图 2 融合信息抽取的知识图谱构建流程
2.1 知识定义
传统的知识工程研究领域人们以本体、主题词表、元数据、数据模式来建立结构化的知识,在本文知识定义泛指结构化的数据模型,即通过构建图谱模式(schema)规范数据层的表达与存储。数据模型是线状或网状的结构化知识库的概念模板,知识图谱一般采用资源描述框架(RDF)、RDF 模式语言(RDFS)、网络本体语言(OWL)及属性图模型。
(1)RDF 模型
RDF 在形式上以三元组表示实体及实体之间的关系,反映了物理世界中具体的事物及关系,如图 3 所示。
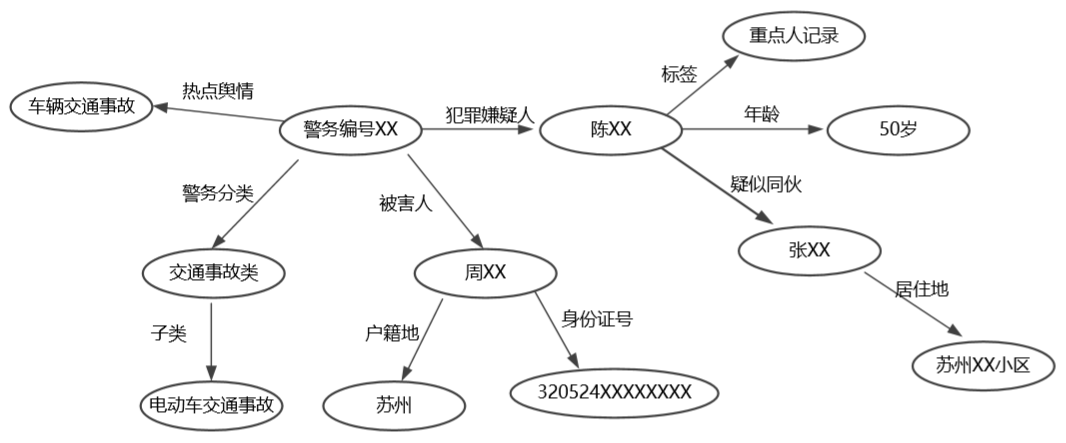
图 3 RDF 数据模型示例
(2)RDFS 模型
RDFS 在 RDF 的基础上定义了类、属性以及关系来描述资源,并且通过属性的定义域和值域来约束资源。RDFS 在数据层的基础上引入了模式层,模式层定义了一种约束规则,而数据层是在这种规则下的一个实例填充,如图 4 所示。
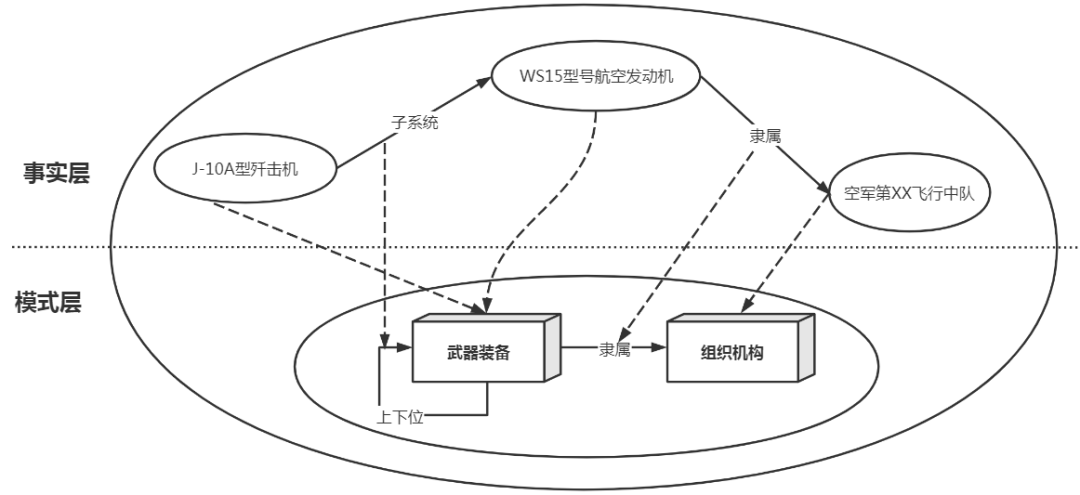
图 4 RDFS 数据模型示例
(3)OWL 模型
OWL 是对 RDFS 关于描述资源词汇的一个扩展,OWL 中添加了额外的预定义词汇来描述资源,具备更好的语义表达能力。
(4)属性图
属性图数据模型由顶点、边及其属性构成,图数据库通常是指基于属性图模型的图数据库[6]。属性图与 RDF 图最大的区别在于:RDF 图可以更好地支持多值属性;RDF 图不支持两顶点间多个相同类型的边;RDF 图不支持边属性。
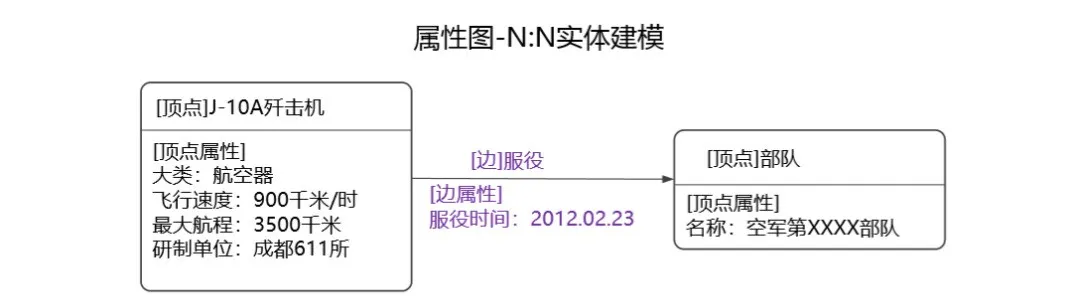
图 5 属性图数据模型
知识定义与信息模型的概念类似,可借鉴元数据和本体论技术,描述定义域的实体类型及其属性、关系和实体上的允许操作,常见的流行方法包括自上而下(Top-down)的构建方式、自下而上(Bottom-up)的构建方式。自上而下,即由行业专家预先定义图谱模式,再以模式组织数据层资源建设;自下而上,即通过信息抽取技术从文本中抽取出实体,再依赖大数据挖掘、机器学习技术分析实体的语义关联关系来构建模式。自上而下显然更加准确,然而自下而上代表着数据驱动的自动图谱构建模式,不论是哪一种方法知识定义应是信息抽取的前提条件。
2.2 知识获取
按数据源类型划分,知识获取包括从结构化、半结构化和非结构化的数据中获取知识。
从结构化数据中获取知识,需把关系数据库中的数据转换成 RDF 形式的知识,可使用开源工具 D2RQ 等将关系数据库转换为 RDF,但难点在于难以自动与图谱模式结合与映射,需要依赖人工编写映射规则;从半结构化的网页数据获取知识主要采用包装器方法,而对于行文格式稳定的文本可视作半结构化数据,可通过格式解析、基于规则的方法进行抽取。
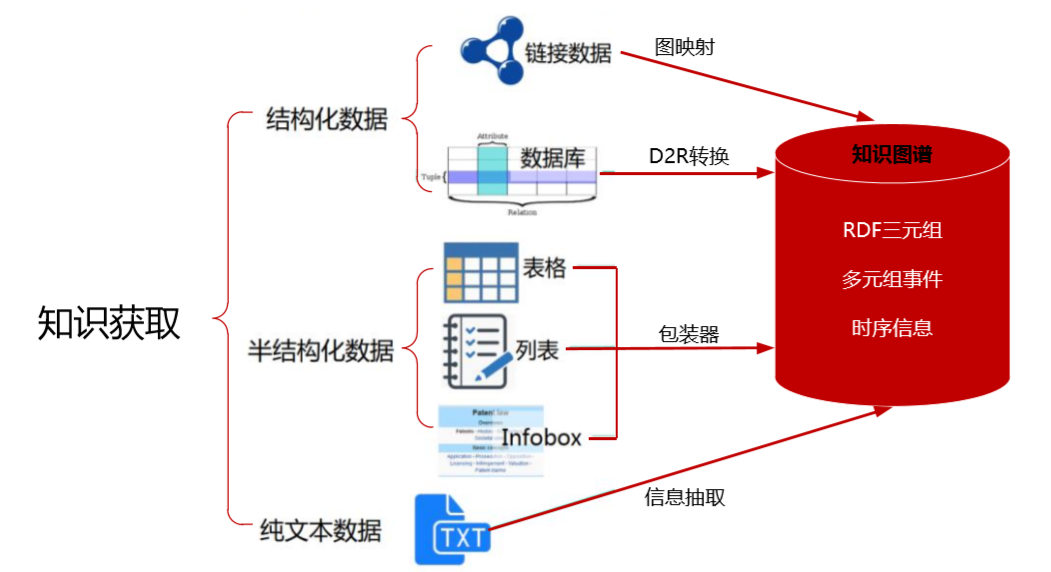
图 6 知识获取[7]
对于非结构化的文本数据,抽取的知识包括实体、关系、属性、事件。
对应的研究问题有四个 :一是实体抽取,也即命名实体识别,实体包括概念、组织机构、人名、地名、时间等;二是关系抽取,即两个实体之间的关联性知识等,包括上下位、类属关系等;三是属性抽取,即实体或关系的特征信息,关系反映实体与外部的联系,而属性体现实体的内部特征;四是事件抽取,事件是发生在某个特定时间点或时间段、某个特定地域范围内,由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变[8]。
非结构化数据的抽取问题,研究的人比较多,对于具体的语料环境,采取的技术也不尽相同。对于纯文本一般按照篇、章、段、句进行文本切割,基于主题词对文本分类、聚类预处理,并由人工开展数据标注与模型训练,最后集成多种信息抽取模型抽取知识。
基于信息抽取算法
构建百分点行业知识图谱
知识定义是信息抽取的前提条件,结合当前结构化、半结构化和非结构化信息抽取的理论、工具和经典算法,百分点通过创新实践,探索出了一套行业知识图谱构建流程方法。
1. 结构化信息抽取
行业知识图谱的构建过程往往需要将业务系统的部分关系型数据库的数据抽取出来,并转换为 RDF 模型或属性图模型的形式存入图谱数据库中,这种从关系型数据库接入数据、预处理并映射为图谱模式的抽取方式称为结构化信息抽取。
W3C 为此制定了两个知识映射标准语言:R2RML 及直接映射(DM),DM 和 R2RML 映射语言用于定义关系数据库中的数据如何转换为 RDF 数据的各种规则,具体包括 URI 的生成、RDF 类和属性的定义、空节点的处理、数据间关联关系的表达等[9]。
直接映射将关系型数据库中的一张表映射为 RDF 的类(Class),表中的列映射为属性(Property),表的一行映射为一个资源或实体并创建资源标识符,单元格值映射为属性值[9]。直接映射可将关系数据库表结构和数据直接转换为 RDF 图,但直接映射仅仅提供简单转换能力。而 R2RML 映射语言可灵活定制从关系型数据库数据实例转换为 RDF 数据集的映射规则,符合 R2RML 映射算法的工具输入是关系数据库检索数据的逻辑表,逻辑表通过三元组映射转换为具有相同数据模式的 RDF 并作为输出结果。
2. 半结构化信息抽取
半结构化数据是一种特殊的结构化数据形式,该形式的数据不符合关系数据库或其他形式的数据表形式结构,但又包含标签或其他标记来分离语义元素并保持记录和数据字段的层次结构[9]。针对网页数据的信息抽取技术较为成熟,可依网页结构化的不同程度分别采用人工方法、半自动或全自动的方法开发包装器进行信息抽取。
基于有监督学习的包装器归纳方法,首先从已标注的训练数据中学习网页信息抽取规则,然后对具有相同结构的网页数据进行抽取,一般的开发流程遵循“网页清洗、数据标注、包装器空间生成、评估”四个步骤,该方法依赖人工长期维护更新包装器。手工方法开发包装器首先通过人工分析网页的结构和代码,并编写网页的数据抽取表达式;表达式的形式一般可以是 XPath 表达式、css 选择器的表达式等,该方法适合简单、结构稳定的网站的抽取。
3. 非结构化信息抽取
3.1 信息抽取框架
如前文所述,非结构化文本的信息抽取主要包括命名实体识别、属性抽取、关系抽取、事件抽取等四个任务。命名实体识别是知识图谱构建和知识获取的基础和关键,属性抽取可看做实体和属性值之间的一种名词性关系而转化为关系抽取,因此信息抽取可归纳为实体抽取、关系抽取和事件抽取三大任务。
3.2 命名实体识别
目前为止, 命名实体识别主流方法 可概括为:基于词典和规则的方法、基于统计机器学习的方法、基于深度学习、迁移学习的方法等[10],如图 7 所示。在项目实际应用中一般应结合词典或规则、深度学习等多种方法,充分利用不同方法的优势抽取不同类型的实体,从而提高准确率和效率。在中文分词领域,国内科研机构推出多种分词工具(基于规则和词典为主)已被广泛使用,例如哈工大 LTP、中科院计算所 NLPIR、清华大学 THULAC 和 jieba 分词等。
基于统计机器学习的方法可细分为两类 :第一类,分类方法,即首先识别出文本中所有命名实体的边界,再对这些命名实体进行分类;第二类,序列化标注方法,即对于文本中每个词可以有若干个候选的类别标签,每个标签对应于其在各类命名实体中所处的位置,通过对文本中的每个词进行序列化的自动标注(也即分类),再将自动标注的标签进行整合,最终获得有若干个词构成的命名实体及其类别[11]。序列化标注曾经是最普遍并且有效的方法,典型模型包括条件随机场(CRF)、隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMM)、最大熵(ME)、支持向量机(SVM)等。
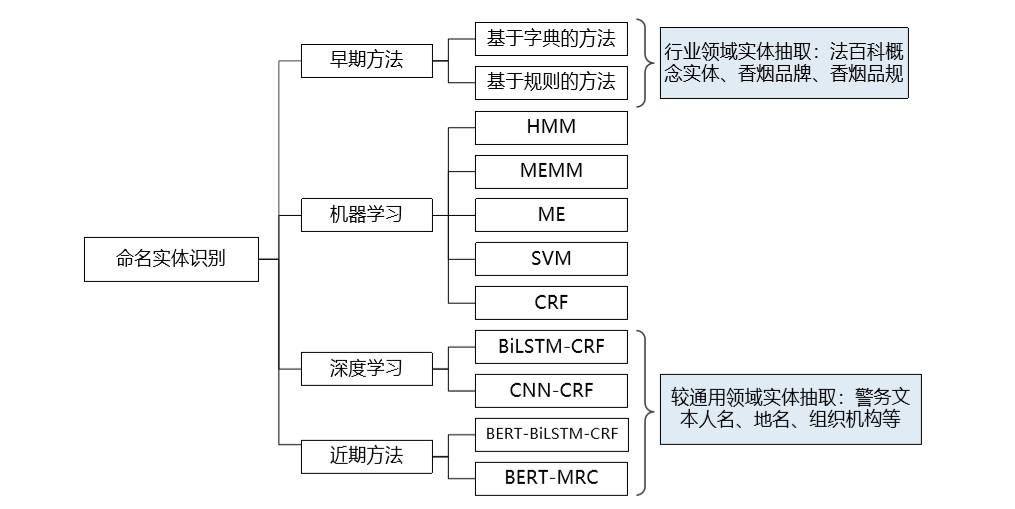
图 7 命名实体识别常见算法
深度学习、迁移学习使用低维、实值、稠密的向量形式表示字、词、句,再使用 RNN/CNN/注意力机制等深层网络获取文本特征表示,避免了传统命名实体识别人工特征工程耗时耗力的问题,且得到了更好的效果,目前常用的框架方法有 BiLSTM-CRF、BERT-CRF/BERT-BiLSTM-CRF。
在百分点的知识图谱构建应用中,法律百科概念词条领域实体,采用基于词典和规则的方法从文本中抽取实体类知识,具有更高的准确率;而抽取人名、地名、组织机构等,由于无法构建完整的词典且规则很难适应数据变化,采用基于序列标注的命名实体抽取模型 BiLSTM-CRF 或者 BERT-CRF 实现。
3.3 关系抽取
从前文可知,关系抽取指三元组抽取,实体间的关系形式化地描述为关系三元组(主语,谓语,宾语),其中主语和宾语指的是实体,谓语指的是实体间的关系。早期的关系抽取方法包括基于规则的关系抽取方法、基于词典驱动的关系抽取方法、基于本体的关系抽取方法[12]。基于机器学习的抽取方法以数据是否被标注作为标准进行分类,包括:有监督的关系抽取算法、半监督的关系抽取算法、无监督的关系抽取算法[12],如图 8 所示。
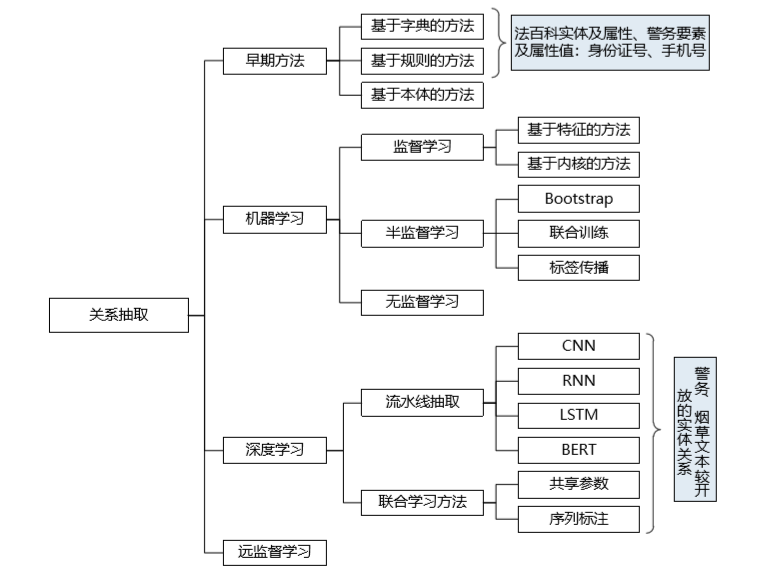
图 8 关系抽取常见算法
有监督的机器学习方法将一般的二元关系抽取视为分类问题,通常需预先了解语料库中所有可能的目标关系的种类,并通过人工对数据进行标注,建立训练语料库,使用标注数据训练的分类器对新的候选实体及其关系进行预测、判断。
同样地,传统机器学习的关系抽取方法选择的人工特征工程十分繁杂,而深度学习的关系抽取方法通过训练大量数据自动获得模型,无需人工提取特征。深度学习经过多年的发展,逐渐被研究者应用在实体关系抽取方面,有监督的关系抽取方法主要有流水线学习(Pipeline)和联合学习(Joint)两种。
(1)流水线式关系抽取方法
该方法将关系抽取分为两阶段任务:第一阶段对输入的句子进行命名实体识别;第二阶段对命名实体进行两两组合,再进行关系分类,把存在关系的三元组作为输出结果[12]。流水线方法将实体识别、关系抽取分为两个独立的过程,关系抽取依赖实体抽取的结果,容易造成误差累积。
当前深度学习的关系抽取主要聚焦在有监督学习的句子级别的关系抽取,根据使用的编码器以及是否使用依存句法树,可以大致将相关系统划分为三种:基于卷积神经网络的关系抽取,基于循环神经网络的关系抽取和基于依存句法树的关系抽取。
(2)实体关系联合学习抽取方法
实体关系联合学习方法主要包括以下两种:
a. 基于共享参数的方法: 典型方法有 BiLSTM、BiLSTM+Attention 等,命名实体识别和关系抽取两阶段任务通过共享编码层在训练过程中产生的共享参数相互依赖,最终训练得到最佳的全局参数。流水线方法中存在的错误累积传播问题和忽视两阶段子任务间关系依赖的问题在该方法中可得到改善,并提高模型的鲁棒性。
b. 基于序列标注的方法: 由于基于共享参数的方法容易产生信息冗余,如果将命名实体识别和实体关系抽取融合成一个序列标注问题,可同时识别出实体和关系,值得注意的是应使用新的标注策略标注(实体位置、关系类型、关系角色)[13]。该方法利用一个端到端的神经网络模型抽取出实体之间的关系三元组,减少了无效实体对模型的影响,提高了关系抽取的召回率和准确率。
在百分点的知识图谱构建应用中,构建法律百科概念词条图谱时从法律文件、权威案例和法律图书抽取概念实体的定义(可视作属性抽取)等行文格式较为规范、固定的文本抽取三元组采用基于模板的方法;警务文本的警务要素及内容抽取等较为开放的关系抽取采用 BERT 作为多分类器的关系分类抽取或序列标注方法。
3.4 事件抽取
“事件”被用于描述事情的发生或事务状态的改变,而事件抽取任务则是一种从自然语言文本中提取出具有事件框架的结构化信息的方法。具体地,一个事件的主要组成如表 1 所示。
表 1 事件组成框架[14]
从上述定义可以看出,实体、触发词、事件论元以及事件类型四者相互之间存在着包含或约束的关系。其中,实体是一种适用于所有文本的概念,但在自动内容抽取(Automatic Content Extraction,ACE)评测会议标准定义的事件中,实体是事件论元的主要组成。值得注意的是,实体本身的类型并不代表着其作为论元时在事件中的角色。事件论元的角色只与事件类型和触发词有关。事件论元的角色可以通过与事件句内触发词或其他实体的关系挖掘而确定。一般事件类型具有该类型下的事件模板,当中包含了固定的事件论元角色[14]。此外,由于触发词是事件发生的标志,因此事件类型的判别往往通过触发词的识别完成。事件抽取任务主要包含两个部分:
(1)事件类型检测
通常触发词与事件类型之间存在着对应关系,因此对事件类型的判定可通过触发词的识别和匹配实现。
(2)事件论元识别
在确定了事件类型后,根据该类型所具有的事件模板找到事件参与者的角色,再通过语义关系解析从事件句中挖掘相关论元。因此,基于 ACE 标准的完整事件抽取架构包括:文本预处理、事件类型检测和事件论元识别,如图 9 所示。
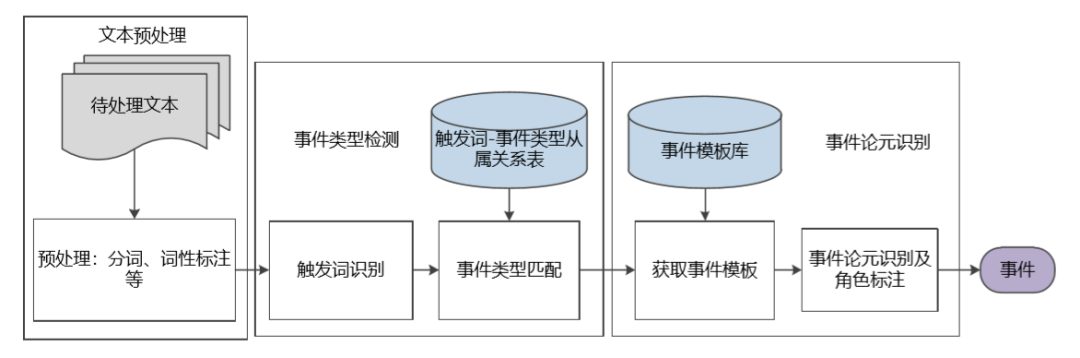
图 9 基于 ACE 标准的事件抽取任务架构[13]
在百分点的知识图谱构建应用中,警情文本的要素抽取符合事件论元抽取理论,该类非结构化的文本包含社会安全类、事故灾难类等事件类型及子类型,警务专家为子类型在内的所有事件类型制定了参考的事件模板,汇总触发词、事件类型和事件论元及角色。下文 3.3 节将给出基于事件论元的警情事件要素结构化案例介绍。
百分点信息抽取算法
创新应用及实践效果
1. 基于模板的法百科信息抽取方法
(1)应用场景:法律百科概念词条图谱信息抽取
法律百科概念词条图谱信息抽取主要目的是构建法律行业的百科全书,以便于用户查找专业法律词条知识。数据共分为三个来源数据,分别是法律文件、权威案例和法律图书,需要从数据中提取对应领域的专业词条名称及对应的相关释义。例如:从法律文件中提取“警用车船”词条,并给出对应的释义:车船税法第三条第三项所称的警用车船,是指公安机关、国家安全机关、监狱、劳动教养管理机关和人民法院、人民检察院领取警用牌照的车辆和执行警务的专用船舶。法百科词条构建及管理界面示例如图 10 所示。
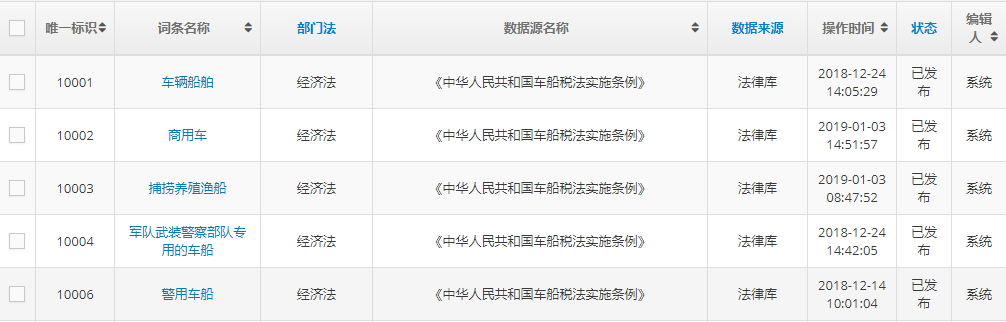
图 10 法百科词条构建及管理界面示例
(2)基于模板的知识抽取
通过人工研究法律文件、权威案例等法律领域的专业词条的写作规律和句式结构,分析法律相关概念实体与概念定义之间的特征,构建抽取的语言模板,通过模板从文本中匹配出实体之间的关系,该方法在构建法律词条这一特定领域内,可以取得较好的结果。
(3)应用效果
在相关文本数据上进行了足量的数据标注,并基于此对信息抽取进行了相关指标的考评,结果如表 2 所示,词条名称及释义整体准确率超过 90%。
表 2 法百科词条抽取评价指标
2. 基于有监督学习的警务文本信息抽取
2.1 基于序列标注框架的命名实体识别
(1)应用场景:警务文本命名实体识别
警务文本包括案件叙述性文本描述数据,如案件卷宗、审讯笔录/口供、简要案情等等类型的数据,文本涉及到的与业务分析和研判相关的案发场所、嫌疑人特征等核心要素,通常可转化为自然语言处理中的实体识别问题。警务系统业务中有研判价值的实体通常包括:姓名、地址、组织机构、联系方式、公民身份号码、时间等。对于警务文本中的身份证号、手机号实体,应采用基于规则或基于词典的方法进行命名实体识别。而文本中的人名、地名、组织机构名称等实体信息在文本中的表述形式是多样并且难以完整列举,当前主要采用基于序列标注的有监督学习抽取方法。命名实体识别采用前文介绍的基于规则的方法及基于 BERT+CRF 序列标注模型进行抽取。
(2)BiLSTM/BERT+CRF 模型架构
百分点在基于深度学习、迁移学习的实体识别实践中沉淀了两套经典的模型:BiLSTM+CRF 模型架构、BERT+CRF 模型架构。两套架构自底向上遵循词编码器、序列编码器、序列解码器三层结构。BiLSTM+CRF 模型架构的词编码器采用 Word Embedding,序列编码器采用 BiLSTM,序列解码器采用 CRF 模型,模型架构如图 11 所示。
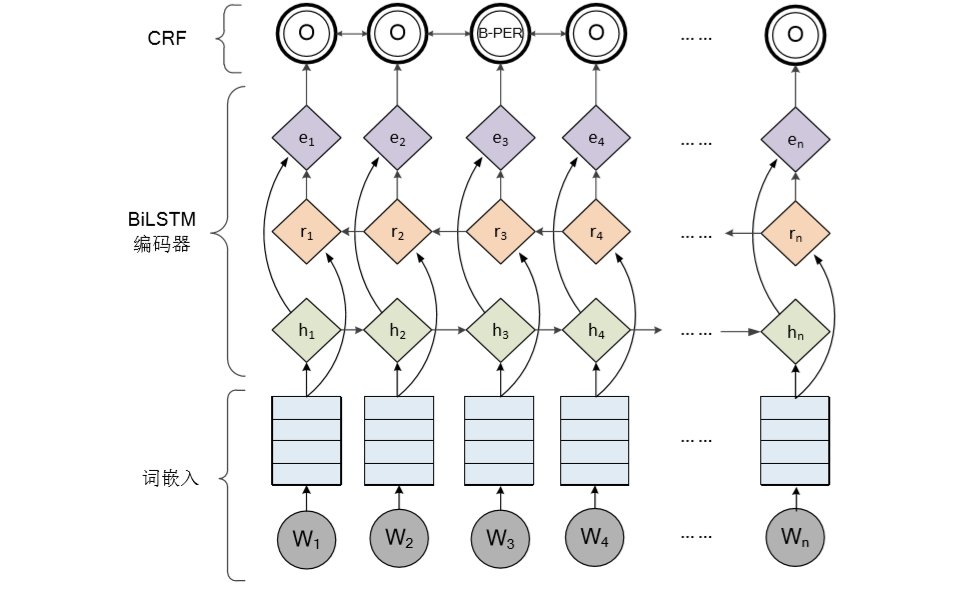
图 11 BiLSTM+CRF 序列标注模型架构
BERT+CRF 模型架构词编码器采用 WordPiece、字符位置编码器采用正弦位置嵌入(Postional Embedding)及句子嵌入(Segment Embedding)、序列编码器采用 Transformer 结构,序列解码器采用 CRF 模型,模型架构如图 12 所示。
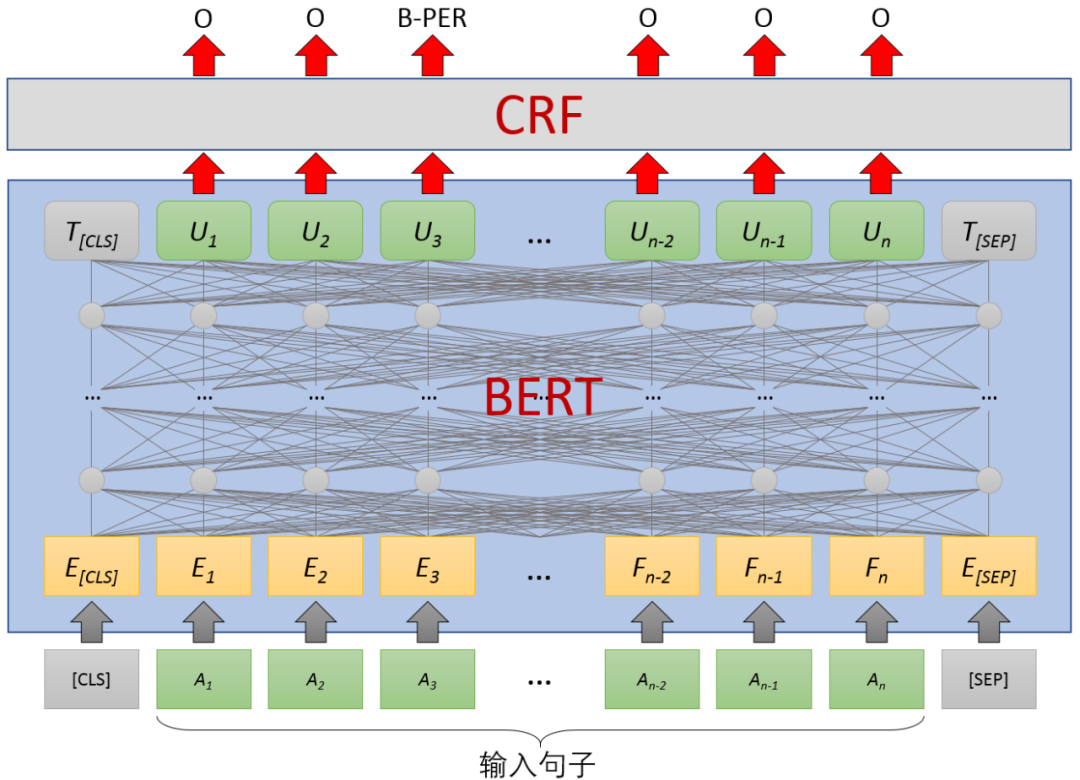
图 12 BERT+CRF 序列标注模型架构
在序列标注的命名实体识别模型中,对于每个单词都需要预测一个多元分类问题。在经过序列编码器之后,每个单词都有一个向量表示,为了预测每个单词对应的标签,需要序列解码器来完成从序列向量到对应预测标签的转换。这两套模型的序列解码器都采用 CRF 模型作为解码器。
(3)警务文本实体抽取应用效果
警务文本的命名实体识别评价指标如表 3 所示。
表 3 警务文本命名实体识别指标
2.2 基于关系分类的关系抽取
(1)应用场景:警务文本关系抽取
由于警务文本数据关注的是以人为核心的实体,因此当文本中出现一个以上的人员及其相关实体信息时候,需要在提取的姓名、性别、地址、联系方式、公民身份号码的基础上梳理清楚各个实体之间的对应关系或从属关系。简单而言就是将人名实体找到其对应的地址、公民身份号码、联系方式、性别等人员属性,可以表示为五元组<姓名,性别,公民身份证号,手机号,关联地址>。N 元组本质上可以拆分成多个三元组,因此警务文本中的 N 元组关系对抽取形式如表 4 所示。
表 4 警务文本 N 元组关系对
(2)基于 BERT 的关系分类模型
BERT 通过大型跨域语料库使用遮蔽语言模型和下一句预测任务共同预训练文本表示。警务文本信息抽取对 BERT 的应用方法如图 13 所示,模型的输入序列的整体结构为:{[CLS],w1,w2,…,wn, [SEP],s1,s2,…,si, [SEP],o1,o2,…,oj, [SEP]},w 为句子序列,s 和 o 为实体序列。序列经过 BERT 分词处理,将字符转换为字 id,然后映射到字嵌入向量,字嵌入向量 E 表示为 E={E1,E2,…,En}。经过多层 Transformer 的 Encoder 编码,最后得到句子的编码向量。取“[CLS]”这个特殊开始字符对应的向量(“[CLS]”的编码表示经常用于判断下一个句子)将编码序列的第一个结果作为关系抽取的语义向量。该语义向量在关系分类器层,经过一层全连接层,然后使用 softmax 函数计算关系概率。
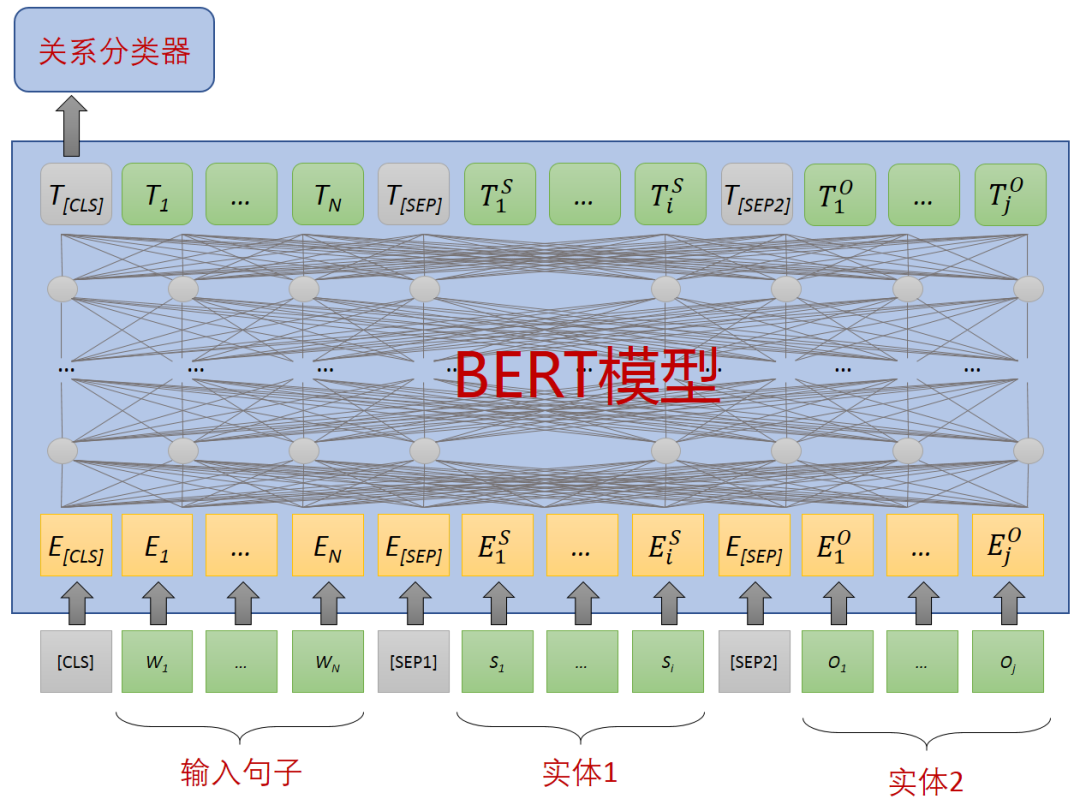
图 13 基于 BERT 的关系分类模型
(3)关系抽取应用效果
警务文本的关系抽取如图 14 所示(示例数据是模拟的,已经完全脱敏):
图 14 警务文本信息抽取输入示例
关系抽取结果如图 15 所示(示例数据是模拟的,已经完全脱敏):

图 15 警务文本信息抽取结果实例
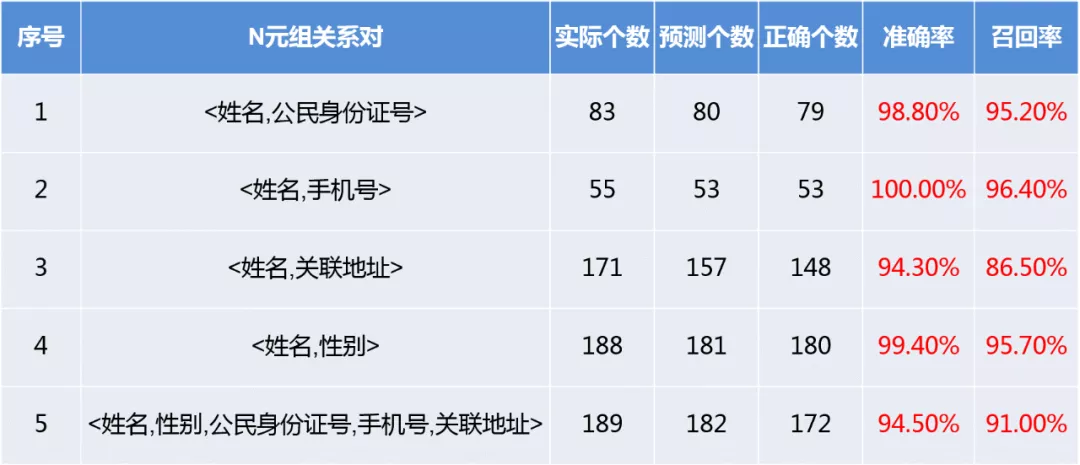
在相关警务文本数据上进行了足量的数据标注,并基于此对实体抽取和关系抽取的 N 元组进行了相关指标的考评,结果如表 5 所示,采用流水线式的命名实体识别及关系抽取整体的准确率和召回率在 95%以上。
表 5 警务文本信息抽取评测指标
3. 警情事件论元联合信息抽取
3.1 应用场景:警情事件论元抽取
警情事件识别与抽取是构建警情知识图谱的重要环节,目的是从非结构化警情文本中识别出描述事件的句子,并从中抽取出与事件描述相关的信息(事件元素、因果关系),最后以结构化的形式存储。警情文本的事件类型包括社会安全类、事故灾难类、网络舆情类、治安和刑事案件类、公共卫生类等 5 大类。
事件类型还可根据警情业务进一步细分为子类型,比如社会安全类可分为社会安全事件、涉稳事件、涉外事件、恐怖主义事件等 4 小类。事件发生子类的事件采用 2.3.4 节表示方法,将事件表示为实体、触发词、事件论元以及事件类型组成的复合知识单元。如图 16 所示(示例数据是模拟的,已经完全脱敏),警情案件文本按照图 9 所示流程识别触发词为“家门被撬”后判别事件类型为盗窃案件,最终抽取出事件论元及角色实现文本结构化分析。

图 16 警情案件事件论元抽取例子
3.2 事件论元角色联合抽取模型
在实践应用中百分点参考分层二进制标注框架(Hierarchical Binary Tagging)[15],将论元抽取视作事件触发词与事件论元的映射关系,模型的整体结构如图 17 所示,主要包括如下几个部分:
(1)BERT 编码器:通过 BERT 得到每个词的词表征,把 BERT 的输出当作词向量使用;
(2)事件论元标注器:该部分用于识别所有可能的事件论元。其通过对每一个位置的编码结果用两个分类器(全连接层)进行分类,来判断其是否是事件论元的开始或结束位置,激活函数为 Sigmoid。
(3)事件角色标注器:针对每一个事件论元,都需要对其进行之后的事件论元的角色进行预测。由图中可知,其与事件论元标注器基本一致,主要区别在于每一个事件类型独享一组事件论元角色分类器,同时还要将事件论元作为特征和 BERT 词向量拼接后作为输入。
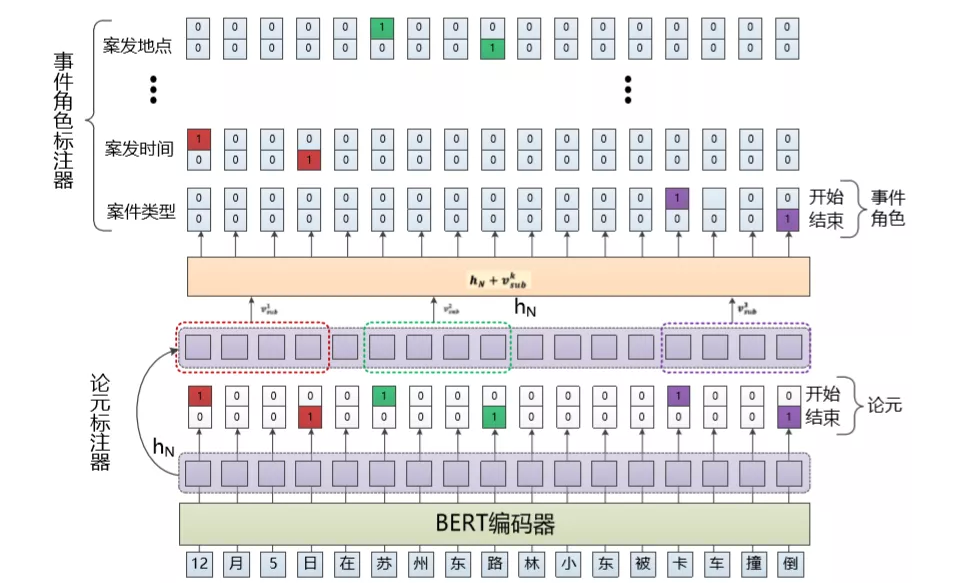
图 17 事件论元、角色联合抽取
警情文本事件论元角色联合信息抽取在大多数人工标注数据集及实际应用中取得了较好的结果,在效果较差的某些事件类型的文本中通过增加人工标注数据可提升模型的准确率。
总结与展望
本文首先辨析了知识获取、知识抽取、信息抽取类似概念本质的区别与联系,然后总结了百分点行业知识图谱构建流程方法,指出知识定义是信息抽取的前提条件,在此基础上介绍了当前结构化、半结构化和非结构化信息抽取的理论、工具和经典算法。文末结合百分点公司在法律百科词条、警务文本实际图谱构建项目中,介绍信息抽取算法应用方法和效果,帮助读者深入了解信息抽取的实践应用状况。总的来说,信息抽取对构建行业知识图谱具有重要的价值,同时面临着巨大的挑战,应充分借助深度迁移学习的发展带来的机遇,一方面发展数据智能标注技术降低人工标注成本,另一方面突破模型对于标注数据数量的依赖,并在更多的实际业务需求中进行实践和应用。
参考资料
[1]中国中文信息学会.知识图谱发展报告(2018)
[2]中国电子技术标准化研究院.知识图谱标准化白皮书,2019 年
[3]清华大学人工智能研究院.人工智能之知识图谱,2019 年第 2 期
[4]GB/T 23703.2 知识管理 第 2 部分:术语
[5]赵军,刘康,周有光等.开放式文本信息抽取. 中科院自动化所,中文信息学报,2011 年
[6]图数据库白皮书.中国信息通信研究院云计算与大数据研究所.2019 年
[7]王昊奋.行业知识图谱构建与应用 101.PlantData
[8]陈玉博.事件抽取与金融事件图谱构建.中科院自动化所,2018 年
[9]王昊奋,漆桂林,陈华钧.知识图谱方法、实践与应用.电子工业出版社
[10]黄晴雁,牟永敏.命名实体识别方法研究进展.现代计算机,2018 年 12 月
[11]刘浏,王东波.命名实体识别研究综述.情报学报,2018 年
[12]李冬梅,张扬等.实体关系抽取方法研究综述.计算机研究与发展,2019 年 6 月
[13]Suncong Zhend 等.JointExtraction of Entities and Relations Based on a Novel Tagging Scheme.中科院自动化所,ACL2017
[14]邹馨仪.基于深度学习的金融事件抽取技术研究.电子科技大学,2017 年
[15]Zhepei Wei 等.ANovel Cascade Binary Tagging Framework for Relational Triple Extraction,吉林大学.2020ACL
本文转载自公众号百分点(ID:baifendian_com)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论