
本文是“2021 InfoQ 年度技术盘点与展望”系列文章之一,由 InfoQ 编辑部制作呈现,重点聚焦大数据领域在 2021 年的重要进展、动态,希望能帮助你准确把握 2021 年大数据领域的核心发展脉络,在行业内始终保持足够的技术敏锐度。
“InfoQ 年度技术盘点与展望”是 InfoQ 全年最重要的内容选题之一,将涵盖架构、AI、大数据、大前端、云计算、数据库、中间件、操作系统、开源、编程语言十大领域,后续将聚合延展成专题、迷你书、直播周、合集页面,在 InfoQ 媒体矩阵陆续放出,欢迎大家持续关注。
2021 年,大数据领域发展到哪一阶段?
2021 年是大数据发展的第 21 个年头(从 Google 开始构建大数据平台做搜索业务算起)。针对一个技术领域的发展趋势,参照 Gartner Hype Cycle 来描述会更加直观。
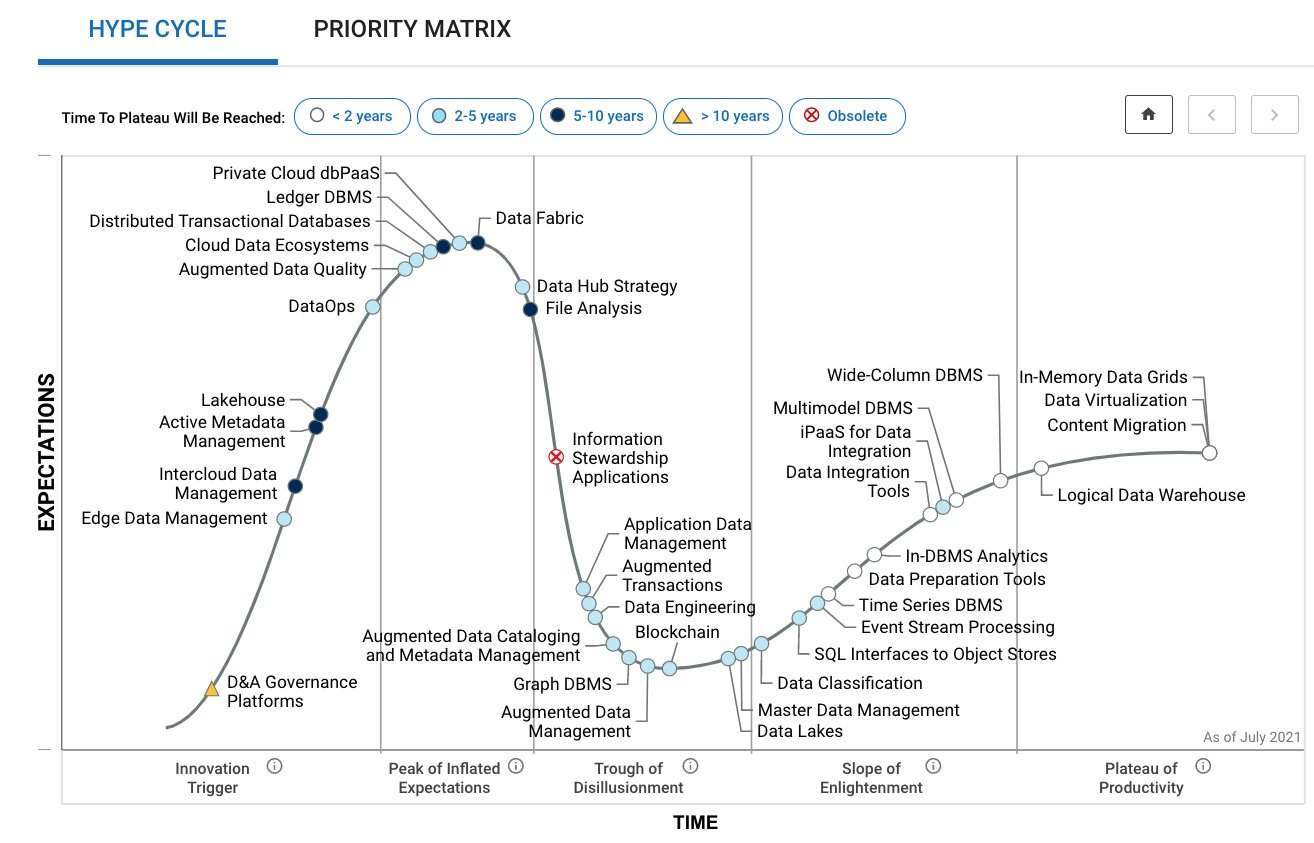
(图:Gartner Hype Cycle mode / Reference: Hype Cycle for Data Management 2021)
Gartner Hype Cycle 把整个发展周期分成 5 个部分,第一个部分叫做“技术的创新期”,在这个点上技术开始兴起,可能只是一个纯粹的小众技术;然后是“技术的狂热期”,每个人都在讨论,很多企业会开始投资;经历了第二个阶段的发展之后,会进入到“技术的冷静期”,大家开始审慎思考,也许这是很酷的技术,但是不是真的有产品和业务价值?很多技术其实在这个阶段之后就衰败了,因为大家可能觉得它并没有太多的用处,或者很难形成进一步的突破。
而有一些技术会走过第三阶段,真正开始进入到“技术的复兴期”,开始有部分技术和产品得到业务认可,形成至少 5%的 Adoption。这些技术最终会走到所谓的“技术的普惠期”,开始有足够好的产品和业务发展。能走到这个阶段的企业和技术,也从红海竞争中存活下来了,他们开始得到更大的市场份额,并形成好的商业价值。
大数据技术体系 1.0 基本建成
最近这几年,大家可以看得到很多因数据而生的创业公司逐步进入到 IPO 阶段,并开始成为市场上的业务营收明星。从这个角度看,大数据平台可以认为已经开始进入复兴期和普惠期。
很多人会问,既然已经走到了第 4/5 阶段,再往后是不是就意味着消亡了?其实并非如此。从图中可以看到,数据领域中不同技术正处在不同阶段,很多新兴技术(例如湖仓一体、边缘计算、区块链账本)开始自第一阶段诞生,在继续推动领域迭代发展,带来蓬勃的生机。
从技术角度看,整个领域进入第 4/5 阶段,意味着技术整体完成了 1.0 的建设。领域内几乎每一个子领域都有相应的技术去匹配,很多领域可能有多个技术同时在发展,然后经过红海竞争之后开始慢慢消亡或胜出。
大数据平台领域技术整体完成 1.0 建设,就会开始向 2.0 的方向演进。这个演进过程通常是 1.0 的替代过程,因此要求 2.0 在技术上做到更好的技术分层和更强的专业化。
数据平台赛道价值显性化,带来大量投资和创业机会
数据普惠化并不是一个新话题,但领域规模和增长情况究竟怎样,一直未有明确的判断(在 Snowflake 上市之前,主流商业数据平台发展情况均被云厂商隐藏在后台)。一年前上市的 Snowflake,将数据平台这个领域的商业价值第一次完整地暴露给公众。其 10 亿美金以上的营收规模、110%的高增长率和 70%的高毛利率(与 Tesla 对比,据最新财报,Tesla 的增长率和毛利率分别为 57%和 30.5%),让公众和投资者第一次通过数据看到数据领域的价值和发展前景。这进而在接下来一年引爆了一轮围绕数据平台领域的投资和创业热潮。
2021 年 6 月 25 日,Apache Kafka 商业化公司 Confluent 正式登陆纳斯达克,首日开涨 25%,市值超过 110 亿美元。
2021 年 8 月 29 日,Apache Iceberg 的创建者 Ryan Blue、Dan Weeks 和 Netflix 数据架构总监 Jason Reid 宣布从风投 a16z 处拿到了 A 轮融资,正式成立围绕 Apache Iceberg 构建新型数据平台的商业公司 Tabular。
2021 年 8 月 31 日,大数据初创公司 Databricks 宣布获得 16 亿美元 H 轮融资,最新估值飙升至 380 亿美元,距离上一轮 10 亿美元的G轮融资仅仅过去 7 个月时间。
2021 年 9 月 20 日,ClickHouse 的创建者 Alexey 正式从 Yandex 独立出来并成立了一个公司:ClickHouse, Inc。同时 ClickHouse 公司获得由 Index Ventures 和 Benchmark 领投的 5000 万美元 A 轮融资,Yandex 也参与其中。
2021 年 10 月 12 日,基于开源的 Apache Pulsar 的商业化公司StreamNative 宣布获得 2300 万美元 A 轮融资。
2021 年,Clickhouse、Tebula(Apache Iceberg 背后的商业公司)、Firebolt 以及国内诸多新兴创业公司为这一领域带来了很好的讨论度。2022 年,也许会成为企业级大数据平台/服务一个新兴周期的“元年”。
客户开始明确分层,带来平台架构的不同取舍
处于技术发展不同阶段的客户,对于技术的诉求通常不同,大数据平台技术也不例外。随着领域技术冷静期到来,越来越多企业开始放弃自建平台,转而采购商业化云产品/服务,以实现规模灵活和总成本低的目标。
笔者在之前多年的工作中,接触/支持过很多不同类型的客户,客户大致可以分成如下三类:
头部互联网技术公司,以 Top30-50 一线互联网公司为代表。技术栈上,以自建平台为主,且大部分公司采用以开源为基础的自建方式(其中少数 Top10 头部厂商会投资 0 到 1 自研)。
中腰部技术公司,其中又可以细分为两类:
中腰部互联网公司,这类型公司大多数诞生于云时代(近 8 年),通常处于成长期并聚焦自身业务发展,对基础设施投资有限,同时追求更低的 TCO(包含硬件和人力的总成本),倾向直接采用公共云平台架构并购买 PaaS 服务。(注:这类型客户是 SnowFlake 的典型客户)。
有技术能力的非互联网公司,以银行/通信等领域企业为主。因监管或者资管要求,通常采用专有云或者混合云模式,企业具备数据开发人员,能够在数据平台上完成数据应用/解决方案的开发。这类型客户通常负责关键业务,对平台的企业级能力(包括稳定性、安全性、免运维能力)要求很高。
纯甲方应用型客户,以线下大型非技术型企业为主。这类型客户通常没有数据开发和应用建设的经验和团队,对数据类应用的需求多通过与合作伙伴(ISV)合作或者外包方式完成。对技术栈和技术选型通常不敏感,但对稳定性要求很高。
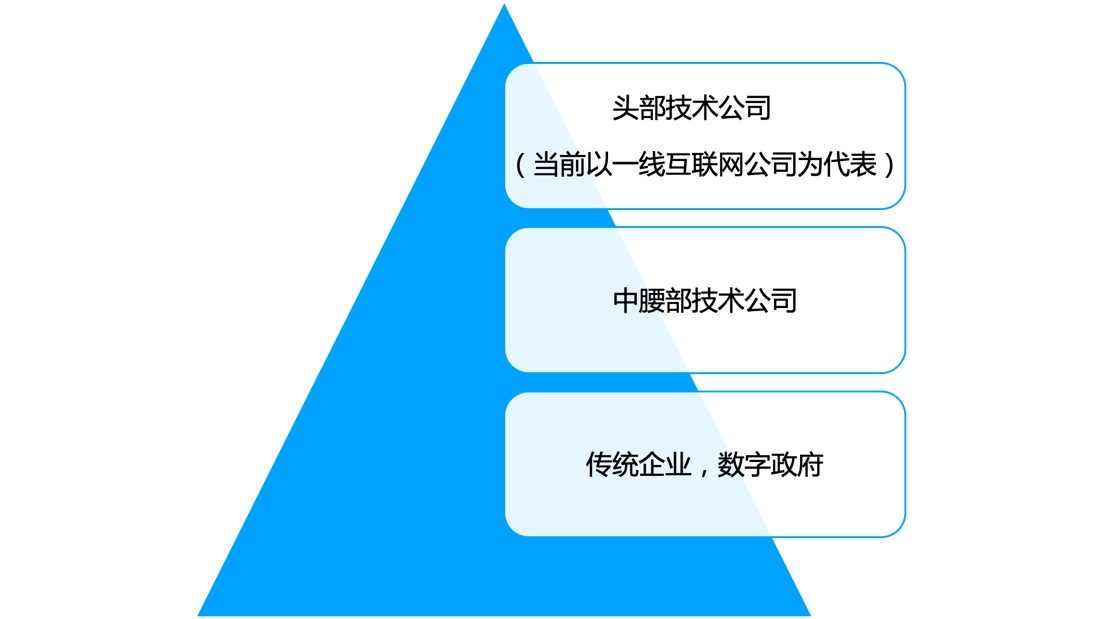
客户的分层,必然会带来平台架构设计的不同取舍。
从技术架构角度看,第一代大数据技术(以 Hadoop 为基础)基本做到“能用/可用”,完成了 0 到 1 的奠基。Snowflake 等新兴产品,开始推动数据平台从“能用/可用”向“高效/易用”进化(进而让更多不太精通数据技术的人/企业能用上数据平台)。
2021 年的很多趋势已经预示,2022 年数据平台技术领域注定火热。
正值 2021 年末,应 InfoQ 编辑邀约,笔者尝试结合自身经历和经验,总结 2021 的技术热点、领域趋势和面临的挑战。下文部分内容来源于笔者 2021 年 11 月在 ArchSummit全球架构师峰会(深圳站)2021 主论坛的演讲。
大数据领域仍然处于发展期,部分技术收敛,但新方向和新技术层出不穷。本文内容和个人经历相关,洞察来自个人视角,难免有缺失或者偏颇,同时限于篇幅,也很难面面俱到。仅作抛砖引玉,希望和同业共同探讨。
当下技术架构的五个热点
引擎架构的进化,向进一步解耦和池化发展
整个大数据领域里有非常多不同的引擎设计。整个引擎的架构,可以分成三种体系:Shared-Nothing(MPP)、Shared-Data、Shared-Everything。目前架构整体在向更解耦和灵活的 Shared-Everything 架构演进。
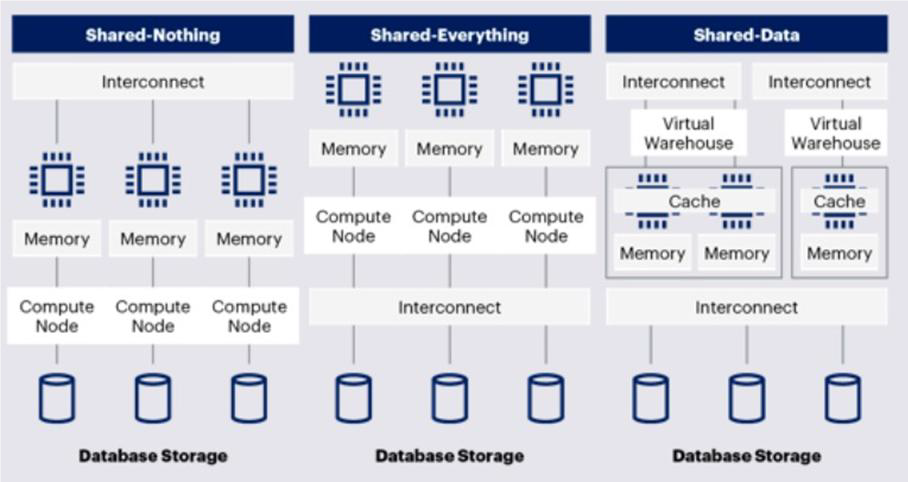
(图:三种大数据体系架构)
第一种 Shared-Nothing 架构,是从传统数据库做分布式演化而来,也叫做 MPP 模式。它的优点在于存储计算一体化之后带来很好的性能优化。但因其数据和计算的绑定,会带来扩展性和弹性问题,整体在转向 Shared-Data 架构。
第二种 Shared-Data 架构是 MPP 架构的演进,通过计算与存储系统解耦(即存储计算分离),存储完全做成一个独立的池化形态,不仅做到了存储器的分离,还做到存储的共享。它解决了 MPP 架构耦合导致的扩展性问题,因而得到广泛欢迎,Snowflake 是其中的代表。
第三种架构叫做 Shared-Everything,这类架构是随着大数据技术兴起的。不仅仅是存储共享,所有的资源都统一共享。通过进一步解耦带来更好的扩展性、灵活性和资源利用效率。Hadoop/Spark、Google BigQuery、阿里云 MaxCompute 等系统都采用了这种架构。
面向未来,我们可能会看到独立的分布式内存池(Disaggregated Memory Pool)、分布式 Cache 池等等。
面向云原生、云中立的系统架构设计
(图:CloudNative Applications,来源:https://www.vamsitalkstech.com/architecture/the-seven-characteristics-of-cloud-native-architectures/)
第一点中谈到的资源解耦和存储计算分离其实离不开云技术,因为云技术实现了更好的规模化、弹性扩展性,并以及集约化带来了更低的成本,所以它会全面替代 IDC。因此现在几乎所有数据平台的设计已经不再是面向硬件直接设计的,而且是面向云平台。
目前云基础平台的 IaaS 层经过十几年发展,已经逐步标准化和统一化。基本以对象存储、基于 Kubenates+容器的资源调度、VPC 云网络为统一标准。因此 IaaS 之上的数据平台可以设计得越来越“云中立”。
特别值得一提的是,因为各种原因,很多客户实际还是需要线下自建机房,但当代线下 IDC 的建设其实也会用到云的技术和思想,比如说做分层的解耦,把 IaaS 层的各个层次区分清晰,实际也促进了整个数据平台设计逐步深化并变得更为全面。
数据湖与数据仓库技术相互融合:湖仓一体
上面谈到的两点主要是从系统架构角度出发,但整个大数据平台的发展实际上还涉及另外一个维度,就是数据组织和管理,这就不得不谈到两个概念,一个叫做数据湖,一个叫做数据仓库。
关系型数据仓库在过去几十年一直是主流技术,现在业界大多数企业级产品几乎都是这个形态,比如 AWS 的 RedShift、谷歌的 BigQuery、Snowflake 都是以数据仓库的形态提供服务。
同时,以开源 Hadoop 为轴的大数据体系是以数据湖的形态发展起来的,它强调的是存储与计算分离,以及各种组件灵活组合。比如存储系统、资源调度系统、多种不同的计算引擎其实都可以灵活地组合。
这两种不同的数据技术和形态在过去十年里一直并行发展,而且两边的发展趋势都不错。有些人会问,开源的技术几乎都更偏向数据湖,然后企业级的付费服务更偏向于数据仓库,背后有什么原因吗?其实是这样的:很多企业级平台面向的是企业级用户,这些用户很多原来是数据库的用户,对数仓系统更熟悉,同时,企业级数据服务的设计更偏向于托管化和更好的数据组织方式,因此数据仓库的体系其实更适合这类场景。而开源体系更偏向灵活组装、偏模块化,更匹配数据湖的技术发展。
在过去大概两三年的时间里,这两项技术开始出现非常强的相互融合的趋势,各自吸取对方的长处,进入到湖仓一体这样一个时代,这是当前的第三个技术热点。
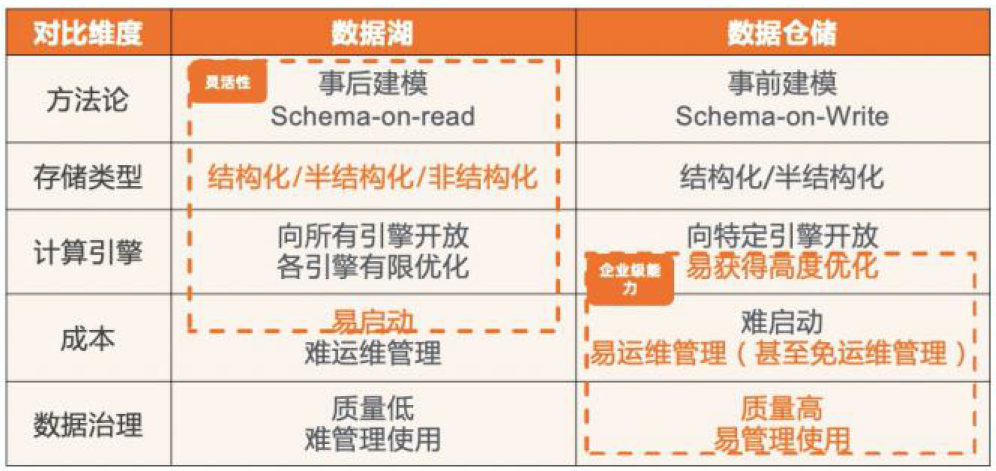
(图:数据湖与数仓技术优势对比)
这里稍微介绍一下两种设计的不同,上图按照 5 个维度对比了数据湖和数据仓库体系。
第一个维度是方法论,数据湖其实是一个文件存储系统,用户可以往里面放任何一种文件或者数据,它的一个典型特点是事后建模,它的方法论是用户先把数据放上来,然后再考虑如何使用,也叫做 SchemaOnRead。数据仓库正好相反,它是事前建模的模式,当你在把数据推进数据仓库的时候,要求先 CreateTable/Schema,这是方法论上的不同。
在存储的形态上,数据湖存储的是文件,数据仓库存储的是表(具体表如何存储对用户不可见)。数据仓库是面向结构化关系表达设计的,因此面向 AI 这种非结构化数据,存在很大挑战,它几乎不支持音视图类型的数据。而数据湖可以存储所有类型,更灵活更有优势。
面向计算引擎,数据湖天然是一种更开放的架构,适配更容易,但是几乎也很难做到非常好的端到端优化。举个例子,当客户把数据上传到数据湖上,可能是一个行存的 Log 文件格式,上层的分析引擎几乎很难跟它做非常好的优化分析(因为非列存、缺乏统计信息和索引的支持)。而数据仓库因为是偏端到端的设计,很难做到开放,但是端到端的优化更容易。
从成本层面看,数据湖非常容易上手,它就是个存储系统,你只要把数据放上去就形成了一个数据湖。但随着数据量的增长,运维管理会越来越困难,所以有很多数据湖最终有可能变成数据沼泽(比如,大家也不知道这个数据属于谁,该被谁来用,能不能删掉,应该怎么治理),这是数据湖面临的一个问题。
而数据仓库在把数据上传之前要事先建模,而且大多数数据仓库建立之初要有一个有关整体数据模型的顶层设计,所以数据仓库的启动的成本很高。但是这种很好的顶设规划,会使数据仓库在日后扩展时的运维和管理成本变得更低,使得它长线的成本优势变得非常明显。从这个层面看,数据仓库的数据质量高,也容易管理和治理,数据湖相对难一些。
从上述五个对比维度去看数据湖和数据仓库,这两个体系可以说是硬币的两个面。现在很多厂商开始考虑怎么在数据湖上应用更多数据仓库技术,反过来数据仓库厂商也希望用数据湖的技术使自己更开放,这两个技术在互相学习和融合,最终催生了一个新的技术热点,也就是湖仓一体。
实际上湖仓一体有两个流派,第一个流派是以数仓这种方式诞生的,它是一个左右派,左边是一个数据仓库,右边是一个数据湖,中间以高速网络相连形成一个反对式的联动;第二个流派是从数据湖向数仓演进,整体架构是在数据湖上搭建数据仓库。这两个流派的代表分别是 AWS Redshift/阿里云 MaxCompute,以及 Databricks,目前这两个流派都还在发展中。
虽然湖仓一体是目前的热点,但它仍然是一个新兴方向,还有非常多未知的问题要解决。
AI 成为数据平台的一等公民
大数据平台的发展在很长一段时间几乎都是以分析(BI)为轴的,主流接口是 SQL,侧重结构化的数据和二维关系表达的运算模式。数据来源以历史数据为主,在之上做统计和分析。例如,统计今年圣诞节某电商平台各个厂商总销售额,这其实是一个基于历史信息的统计。但如果我们希望知道:明年同期营收大概是怎样的?数据分析几乎很难回答这个问题,它需要机器学习算法做一个向前的预测。所以从这个层面看,数据分析和 BI 更侧重于历史数据的总结,而算法/AI 具备越来越好的面向未来做预测的能力,也能给大家带来更多决策支撑。
特别要提的是,非结构化数据的处理过去其实一直是瓶颈,但 10 年前诞生的深度学习技术突破了这样一个瓶颈。所以在过去五年里,算法类负载在数据中心里从一个很低的比例增长到了 10 %-30%。AI 正成为数据平台的一等公民。
既然 AI 成为一等公民,面向 AI 的平台设计和优化就开始变得关键。从存储到元数据到计算模式都需要重新思考。从这个层面上说,笔者认为当下技术发展的第四个热点是平台如何更好地支撑 AI。
“1+N+1”的系统架构
一个数据平台通常包括多个组件,不同的组合会带来多种系统架构形态。经过多年发展,笔者看到很多大厂和云上的客户最终迭代诞生出来了“1+N+1”这样一个系统架构。
第一个 1,代表存储和资源的统一。从底层看,统一的存储系统把数据统一在一起,它有可能是数仓,有可能是数据湖,甚至有可能是湖仓一体的。然后再向上是统一调度层,所有的资源统一(很多大厂的混部项目,都是为了统一资源池)。
中间的 N 指代的是多种运算引擎和模式,例如批处理、流处理、机器学习、图计算等等,不同的计算引擎共享底层的数据和资源池。
最后一个 1,是指统一的接入层和数据开发应用层,这个层次是可选的。有些企业选择统一入口管理的架构,做更好的权限管理等。有些企业和厂商选择不再收敛了,引擎可以被各种团队或者各种用户独立使用。
面向未来的四个发展趋势
实现从离线到实时的全频谱
批处理、流处理、交互分析领域已经基本成熟,最近两年,以 Apache Delta、Hudi 为代表的近实时化技术逐渐兴起,给了用户在数据新鲜度和资源消耗平衡中的一个新选择(更偏重成本)。从批处理、流处理到交互分析,每个系统都有各自的特点,但场景相互交织。用户如果想要搭建一套完整的平台,往往需要自己组合多个系统,这种组合工作给用户带来了额外的挑战。
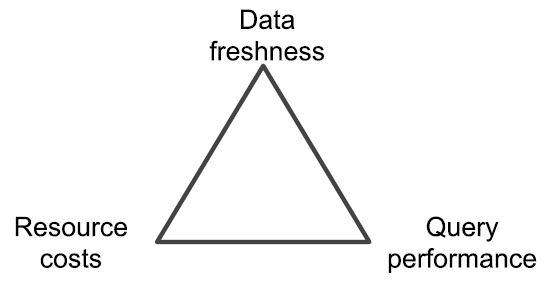
面向未来,新一代数据平台系统需要形成一个从离线到实时的全频谱计算能力,并在 Data Freshness、Resource Costs 和 Query Performance 的不可能三角里边给用户提供多种不同平衡的选择。面向未来的系统应该能够做到一套系统一套数据一套资源,针对上述三个方向的不同平衡点,为用户提供多种选项,实现从离线到实时的全频谱。
IoT 类数据处理成为新热点
目前大数据系统处理的数据主要来源是人的行为的数据日志。比如说人的浏览记录、用户在手机上对 App 的点击等操作,都会以日志的形式传到系统里,反馈给推荐系统、广告系统。
面向未来,随着通信(5G)技术和硬件设备的智能化,大量硬件设备的数据会接入进来,硬件设备的数量慢慢会超过人的数量,这些数据会超过人产生的数据,形成一个更大数据规模、更低数据密度的新数据来源。
同时,设备产生的数据特性不同,比如大多数时候设备数据并没有太多意义和价值,只有出问题的时候数据才会产生波动,在这种情况下如何有效收集设备产生的数据,如何处理这种海量的无法全量上云、需要在边端做一定处理的数据,就成了新的需求。为了解决这些问题,云边端协同的计算模式会成为热点,统称 IoT。
数据安全、共享与隐私保护的矛盾需要新解法
数据本身已经成为一种资产,有非常好的资产变现或产生额外价值的能力和需求。同时数据很可能涉及隐私泄露(前段时间国家发布了数据安全相关的保护法规),这就形成了有关数据安全、隐私保护和数据共享的矛盾。如何在保证数据安全和隐私的情况下,做到更好的数据共享和数据变现成为新热点。
数据安全不仅仅是一个权限问题,还涉及很复杂的系统架构,包括权限管理、用户隔离、存储加密、异地备份、敏感数据/风险行为的识别等等。数据安全共享这个方向包括两个核心场景:一方数据对外共享,多方数据共同计算。
一方数据共享,典型场景是企业自己拥有完整的数据产权,同时又希望通过共享获得价值。目前在主流的云数仓产品里,很多平台都开始提供数据共享方案,比如说 Snowflake 推出的 DataSharing 功能。
多方数据共同计算,典型场景是每一方可能都不具备完整数据,但希望跟不同的数据源通过数据求交或共享的形式获得价值,这就是多方的数据交叉计算或者叫联邦计算。这里面包含两项核心技术,一个是基于隐私计算的数据交互,一个是基于联邦学习(Federated Learning)的数据交互。不论是一方域内多租的安全模式,还是跨域多方的安全共享模式,目前都是领域热点。
AI for System (DW Automation)
随着大数据领域逐步发展和普惠化,主流客户其实都可以做到 PB 级的数据规模,甚至很多客户可以达到百 PB 规模。国内最大的互联网公司,内部数据量均在 EB 级别,作业量在每天百万级别以上。
面对这么大的数据规模,传统 DBA 以人为轴的数据管理和优化方式不再胜任。这种复杂的数据组织和优化需要更多基于机器学习、深度学习的自动化技术来完成。比如,通过机器学习自动进行数据分层,依据访问的统计判断什么样的数据更重要、什么样的数据其实不重要,哪些作业可以放在冷存储上,哪些是关键作业需要放在更高优先级的存储上。
当作业量达到百万量级时,这些决策应该由机器来自动完成,而不应该由人来完成。
这个方向在学术届非常火热,已经有大量研究工作和论文发表(例如,Learned Index、CloudView 自动中间结果统计,Ottertune 参数自动化调优等等)。工业界也有很多这方面的工作在推进,不过主要集中在大厂里面,因为这部分工作需要海量数据支持。
目前这个方向整体处在相对早期的阶段,如果我们用自动驾驶类比 AutoDW,现在大多数系统可能都处在 L1 或者 L2 的水平,有些系统能达到初步的 L3,未来还有非常大的发展空间和潜力。
三个未解的挑战
如上所述,初代大数据体系已经基本建成。同时,在笔者看来,还有很多未解问题摆在从业者面前。
疑问 1:引擎多样化,最终是否能诞生一套 OneSizeForAll 引擎满足多样的计算需求,并兼顾通用性和效率?
现在大家几乎还是通过拼接不同引擎来搭建自己的计算平台。如果采用开源系统,可能就是 Spark 做批处理、Flink 做流处理、Clickhouse 做交互分析,这是最简单的一套。再复杂一点,可能还要部署 HBase 做 KV 查询,用 ElasticSearch 做文本检索。虽然每个单独产品都已经比较成熟,但整个系统的复杂度非常高。因此很多客户期待能简化架构,用一套 OneSizeForAll 的系统解决多个场景问题,这也是面向从业者的一个关键挑战。
疑问 2:基于开源自建与直接选购企业级产品,谁更能获得用户的认可?
很多客户都问过笔者这样一个问题:我是应该用开源系统自建一个大数据平台,还是应该去买一个企业级服务?
于我而言,这个答案可能需要结合客户分层来看。如前文讲到的,不同层次的客户可能会选择不同产品,开源自建软件几乎都是免费的,但是你可能需要一个独立的团队去支撑这样一个大数据平台的部署和运维,带来了相对较高的维护成本(一个简单的经验公式是,对于百台规模的平台,基于开源软件自建的总 TCO=物理硬件成本+开发和维护人力成本 =物理硬件成本*2)。
对于头部的互联网技术公司,大多在数据基础设施方面有大量投入且具备较高的技术能力,能够组装和改造好开源产品,形成为自己量身定制的平台。而且他们规模比较大,人力边际成本低。
对于很多非头部互联网企业,直接购买 SaaS 化的企业级平台,综合成本反而更低。同时还能享受到更好的性能、安全性、稳定性和兜底能力。但也会面临技术黑盒以及改造的高成本(需要平台厂商来做)问题。
Snowflake 作为开箱即用的全托管平台大受欢迎,Databricks 以开源生态为主线也形成了广泛客户群体。“散件组装攒机”VS “直接买笔记本电脑”,最终答案还是在客户手里。
疑问 3:关系模型之外,是否会发展出其他主流计算范式?
数据库和数仓已经发展了 40 多年,主流的计算范式就是二维关系表达。近 10 年,深度学习带来了一个新的计算方式。那除此以外,还有没有一个更新一代的计算方式会产生?
图计算是目前最被看好的方向,它是点边模型,与二维关系表达并不相同。但是数据库技术发展过程中也诞生了图计算模式,并且已经发展多年,但目前仍然不是主流。笔者并不确定,随着图学习 GraphEmbedding 技术的兴起,图计算是否能焕发新生变成一个主流的计算范式。但是我们仍然期待随着大数据体系的发展,能够看到更多计算范式诞生,并进一步推动数据价值发掘。
写在最后
笔者引用了 19 世纪物理学的一个说法作为开篇的题目。19 世纪末期,物理学界普遍认为物理学的体系几乎已经建成,但头上仍有两朵乌云。事实上那两朵乌云是现代物理学诞生最重要的两个标志,也就是量子力学和相对论,它们标志着经典物理学向现代物理学的演进。
笔者用这个题目做完 2021 的总结,也是希望能表达类似的观点:以 Hadoop 为基础的第一代大数据体系架构已基本建成,但是面向未来的更现代的数据平台架构仍有非常多的疑问还没有得到解答。值此年终年初,期待能和所有的读者/从业者一起,把大数据平台体系向新一代推进。
作者介绍:
关涛,分布式系统和数据研发平台专家。2006 年至今,经历了大数据平台技术发展后 15 年,是大数据核心技术最早期的研究和实践者之一。曾任阿里巴巴技术委员会计算平台组负责人,阿里云架构组大数据组负责人,阿里云通用计算平台(MaxCompute/Dataworks)负责人。微软 Azure 云大数据平台研发经理。深度主导/参与微软和阿里云大多数核心大数据平台项目的初创和迭代发展。ArchSummit 全球架构师峰会(深圳站)2021 明星讲师和优秀出品人。
如果你对大数据领域的技术发展有其他观察和看法,欢迎在文末留言,或加入 InfoQ 写作平台话题讨论。后续,迷你书、专题将集合发布于 InfoQ 官网,将 InfoQ 添加进收藏夹,精彩不错过。
我们还准备了 2021 年度技术盘点交流群,欢迎各位小伙伴进群讨论!

2021 InfoQ 年度技术展望直播周将在元旦前后两周持续输出精彩内容,关注 InfoQ 视频号,与行业技术大牛连麦~




