

笔者从 12 年开始入行,从事 DevOps 研发工作,做过部署系统、监控系统、可观测性相关产品,也做过 SRE 一线和管理工作,对于可观测性的理解和实践,有一些小小的见解,利用本文和大家做一个探讨分享。本文主要内容包括:
可观测性在整个商业体系中的位置和价值
如何快速发现故障,使用哪类指标告警
SRE 在谈论故障定位的时候,谈的是什么
如何找到故障直接原因,找到止损依据
如何让可观测性系统呈现观点,辅助洞察,定位故障
可观测性在整个商业体系中的位置和价值
做一个事,首先得有价值,如果价值太小不值得投入。可观测性也不例外,我们首先分析一下可观测性在整个商业体系中的位置和价值。思考第一个问题:作为在线类产品,我们希望客户/用户有一个好的产品体验,那怎么算一个好的产品体验?
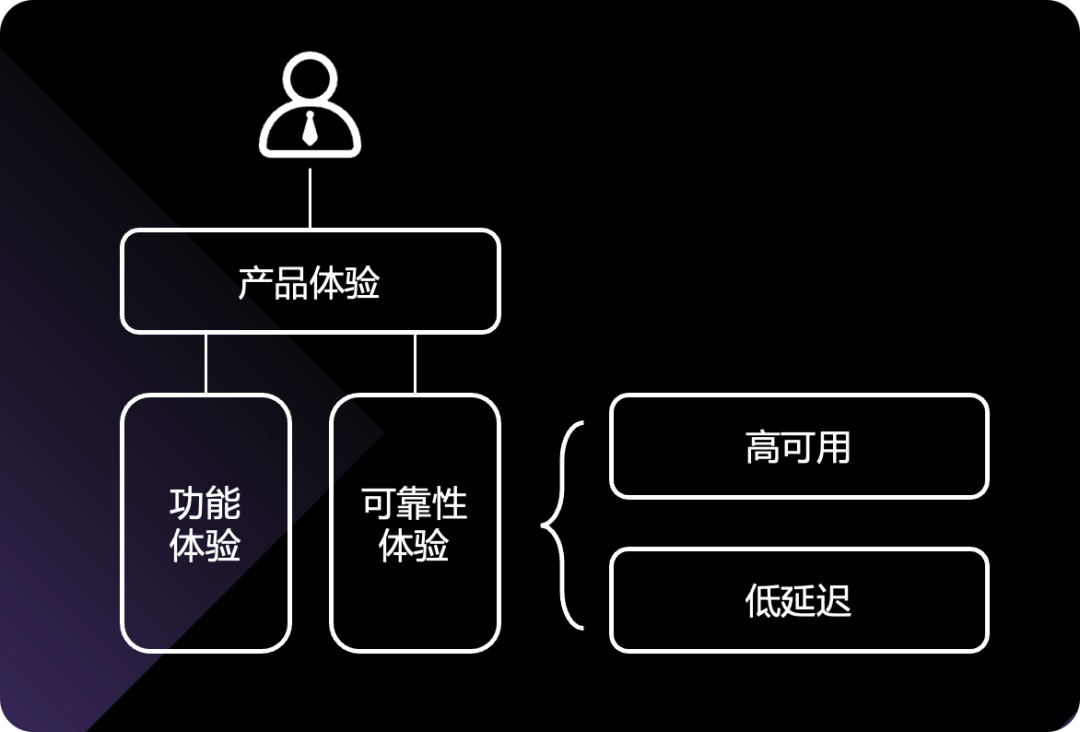
很明显,产品体验包括功能体验和可靠性体验。功能体验依赖产品设计和迭代速度,跟今天的话题关系不大暂且按下不表。可靠性体验呢?可靠性体验核心就是追求高可用、低延迟,通俗讲就是每次打开站点或 app,都不报错,速度嗖嗖的。那如何才能具有好的可靠性体验呢?
其实如果一切正常,就应该是可用且速度快的,除非哪里出了问题,也就是发生了故障,才会报错或者延迟大增。那技术团队要做的,除了持续优化架构和性能,就是不断和故障做斗争了。降低故障发生的频率,降低故障的影响范围,降低故障的恢复时间。归纳为 6 个字:降发生、降影响!
怎么做?有没有方法论来指导?我们可以从故障的生命周期着手,来优化生命周期的各个环节,每个环节都做好了,理论上结果就是好的。故障生命周期的梗概图如下:
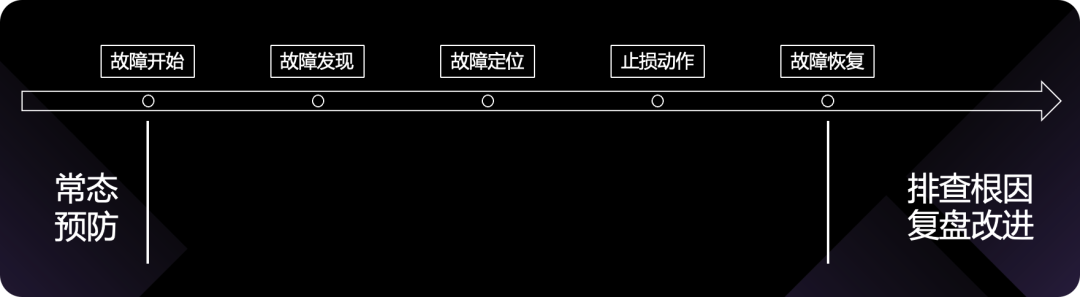
从大面上,可以分成事前、事中、事后三个大的阶段:
事前:及时发现风险,做好架构、预案、演练
事中:及时发现故障,及时定位,及时止损
事后:排查根因,落实复盘改进项
看起来寥寥数语,没有特殊的东西,但实际上每个环节要做好,都不容易。那可观测性,在这整个过程的职能是什么?在哪个环节发挥价值?
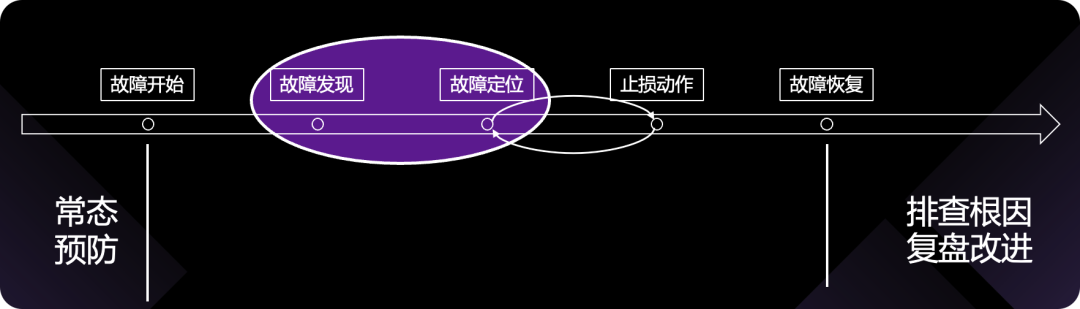
显然,可观测性,是在故障发现、定位环节发挥作用的,核心价值就是帮我们快速发现故障、快速定位故障,进而降低故障的影响。如此,可观测性的位置和价值就很明确了,用一张图概括:
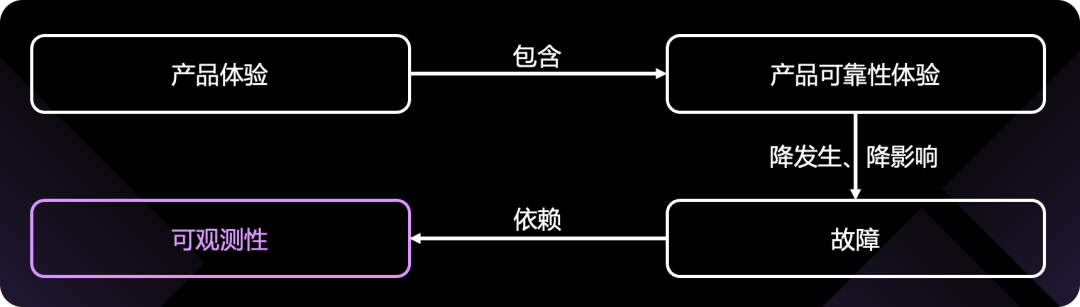
客户/用户需要好的产品体验,好的产品体验包括可靠性体验,要想有好的可靠性体验,就得减少故障,所谓的降发生、降影响,而这,又依赖了可观测性的能力。所以:可观测性最终是服务于产品体验、服务于商业成功的(想不想取得商业成功?根据刚才的分析可观测性可是重点因素哦),核心目标是快速发现、定位故障。
那么,如何快速发现故障?
如何快速发现故障,使用哪类指标告警
要想能够快速发现故障,得先定义什么是故障!简单来看,产品体验受损,就是故障!比如:
电商产品:用户无法下单、无法支付、无法查看商品、无法查看历史订单
存储系统:用户无法读、无法写、或者读写延迟过高
流媒体产品:无法开启播放、无法拉流、无法浏览视频信息
既然能够定义如何算是产品体验受损,那就可以梳理出相关的监控指标,比如:
电商产品:订单量、支付量、商品/订单访问成功率/延迟
存储系统:读/写成功率、读/写延迟
流媒体产品:播放量和成功率、拉流延迟、视频浏览成功率/延迟等
大家有没有发现这类指标的特点?显然,都是可以量化客户体验的指标,这类指标我们称为结果类指标(后面会介绍原因类指标),大面上可以分为两类,一类是业务指标,另一类是 SLO 指标。
一般公司做监控的时候,可能会意识到要做 SLO 指标的监控,容易忽略业务类指标的监控。其实,业务类指标才是老板更为关注的指标,而且,SLO 指标正常的时候,业务指标未必正常。比如客户到服务端的网络出问题了,服务端的成功率、延迟指标都是正常的,但是客户无法下单,订单量会下跌。所以,一定要重视业务指标体系的构建和监控。
听起来,业务指标和 BI 数据很像有没有?确实,最大的相同点是:都是老板关注的,哈哈。不同点呢?BI 数据对准确性要求很高,对实时性要求没有那么高,而业务指标监控,对准确性要求没有那么高(只要能发现数据趋势出问题了就可以了),对实时性要求很高,毕竟是用来发现故障的,如果实时性太差,黄花菜都凉了。
指标体系的构建,除了结果类指标,与之对应的还有原因类指标。都需要,但是我们配置告警的时候,一般是针对结果类指标来配置。因为产品的核心业务功能是可枚举的,每个功能对应的结果类指标就是可枚举的,做好结果类指标的告警,就可以保证告警是全的,做到有故障必有告警!举个例子:实时交易类系统,交易量突然下跌。
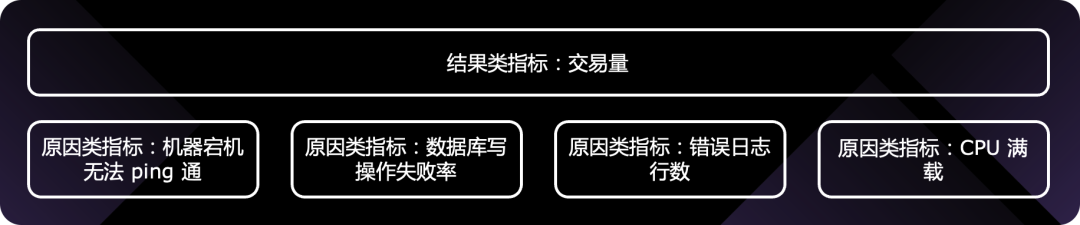
如果,面向原因类指标配置告警,则永远无法配全,无法做到有故障必有告警!实际上,原因类指标不必一定要配置告警,出故障的时候可观测,其实也基本够了。
如上,要构建可观测性体系,首先要建立完备的指标体系,其中非常关键的是结果类指标,即业务指标和 SLO 指标,结果类指标配合告警系统可以快速发现故障!从这里也可以看出,监控(monitoring)和可观测性(observability)是相辅相成的,非替代关系。
OK,既然可以发现故障了,下一步就是定位故障了。
SRE 在谈论故障定位的时候,谈的是什么
在讨论这个问题之前。先分享一个信息层级的概念。说:信息分 4 个层级,最底下是数据,杂乱无章,比如海量的指标、日志、链路追踪的数据;数据上面是特征,比如最大值、最小值、同环比等,比如 5 个服务实例,延迟的最大的是哪个,这叫数据特征;特征上面是观点,从故障定位场景来举例,比如根据特征数据分析之后发现,数据库没有问题,依赖的第三方服务也没问题,这就是观点;观点之上就是洞察,或称洞见,综合所有观点,得出故障定位结论,得知具体是哪个模块的什么原因导致了本次故障,就是最终洞察。画个图示例一下:

要想得到最终的洞察(定位到故障),首先要依赖底层的数据完备性,否则就是巧妇难为无米之炊!但是故障原因五花八门,数据能全么?做过 SRE 或者运维的朋友肯定感触颇深,故障可能是电源模块坏了、机房空调坏了、机柜压住网线了、供电不稳、某个盘故障了、中间件配置错了、被黑客攻击了、分布式中间件脑裂了、写日志 hang 住了、程序配置错了、程序连接第三方的地址错配成线下地址了、DNS 配错了、证书过期了、代码 Bug 了、疏漏了某个罕见用户流程…等等等等。
这么多可能的故障原因,要通过可观测性数据分析出来,这数据能全么?比如代码 Bug,要想能根据可观测性数据分析出是哪一行代码的问题,岂不是要像在 IDE 里调试那样,每一行代码的输入输出都得拿到啊,这成本谁扛得住啊,性能损耗谁扛得住啊…
如果我们的目标只是定位直接原因,找到止损依据尽快止损,这个底层数据需求就少多了。比如我们不需要知道是哪行代码出了问题,我们只要知道是某个模块做了变更导致了故障,就可以去止损(这个场景的止损动作就是回滚)了。再比如,多活的服务,有时仅仅知道是 A 机房的问题就可以了,把流量切到 B 机房就可以解决。
综上,个人观点:使用可观测性数据定位根因,几无可能 100%覆盖全部场景!因为数据就不可能全!但如果只是用可观测性数据定位直接原因,找到止损依据,则 100%是可以做到的,而这,才是我们应该努力的方向。
当 SRE 在谈论故障定位的时候,其实谈论的时是如何找到直接原因,尽快止损。而根因,可以留在复盘阶段慢慢找的。
如何找到故障的直接原因
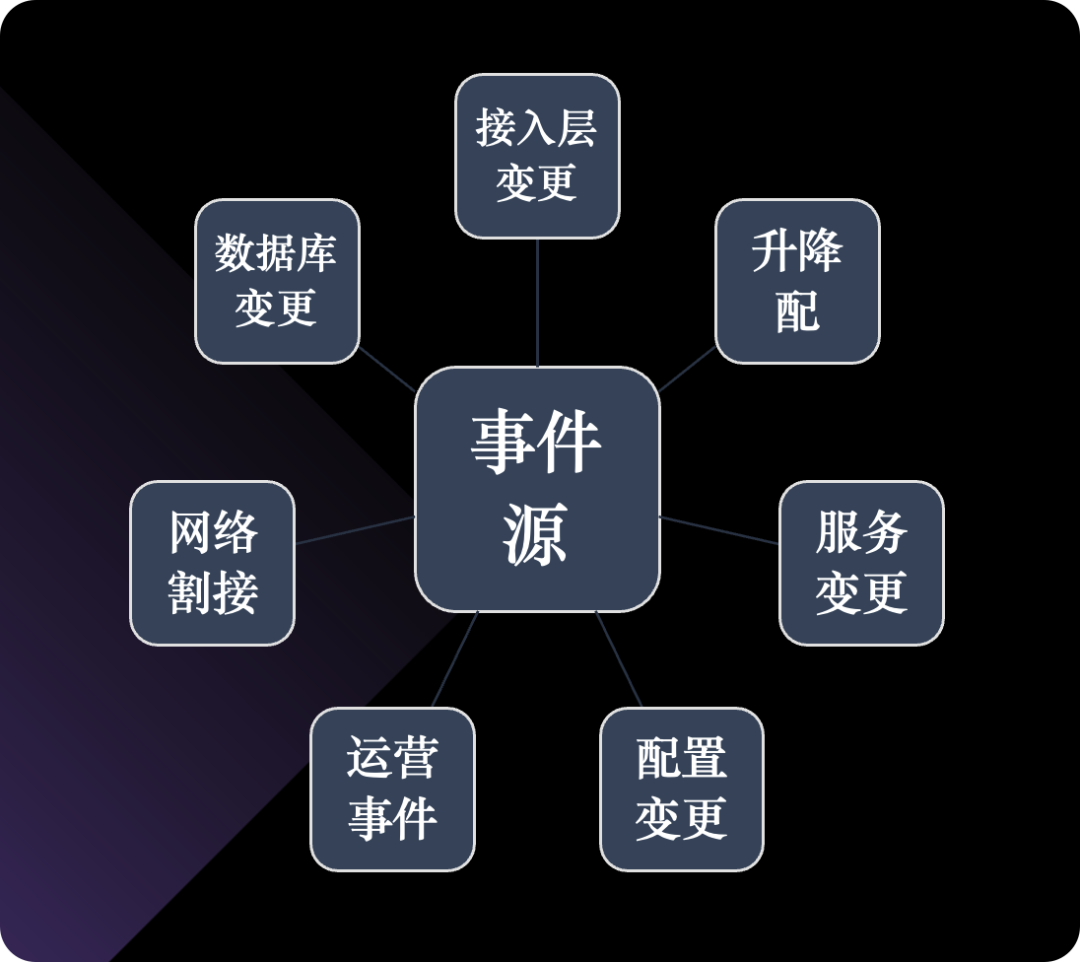
回答这个问题之前,我们先来看看一个服务要想正常运行,依赖了哪些内容,或者说一个服务如果出故障,可能会是哪里的问题。如果我们能够枚举故障类别,那么我们就可以针对每个类别去分析,找到故障的直接原因。
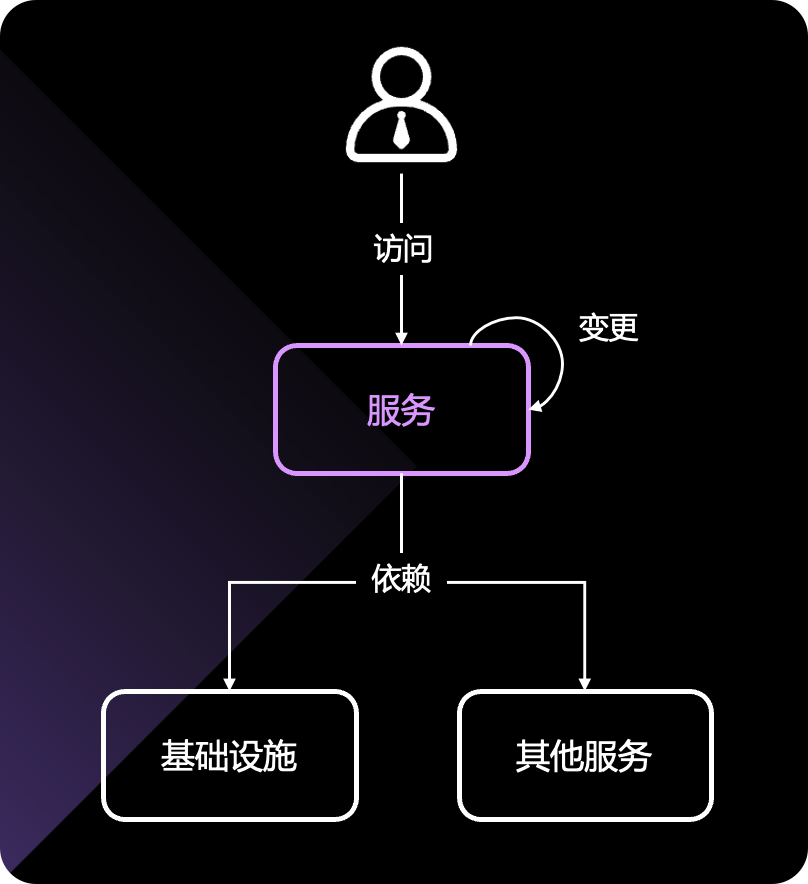
首先,依赖的基础设施(基础网络、硬件、Runtime 环境)不能出问题,依赖的第三方其他服务不能出问题,这两个方面大家比较容易理解,不多说了。还有就是服务本身的变更,比如二进制变更、配置的变更、部署方式的变更、流量接入方式的变更,等等,也可能引发问题。最后就是上游访问的方式,比如流量突增,显然也可能会带来故障。
那针对这些故障场景,我们应该去看哪些数据呢?这其实就是可观测性数据底座的建设方向。
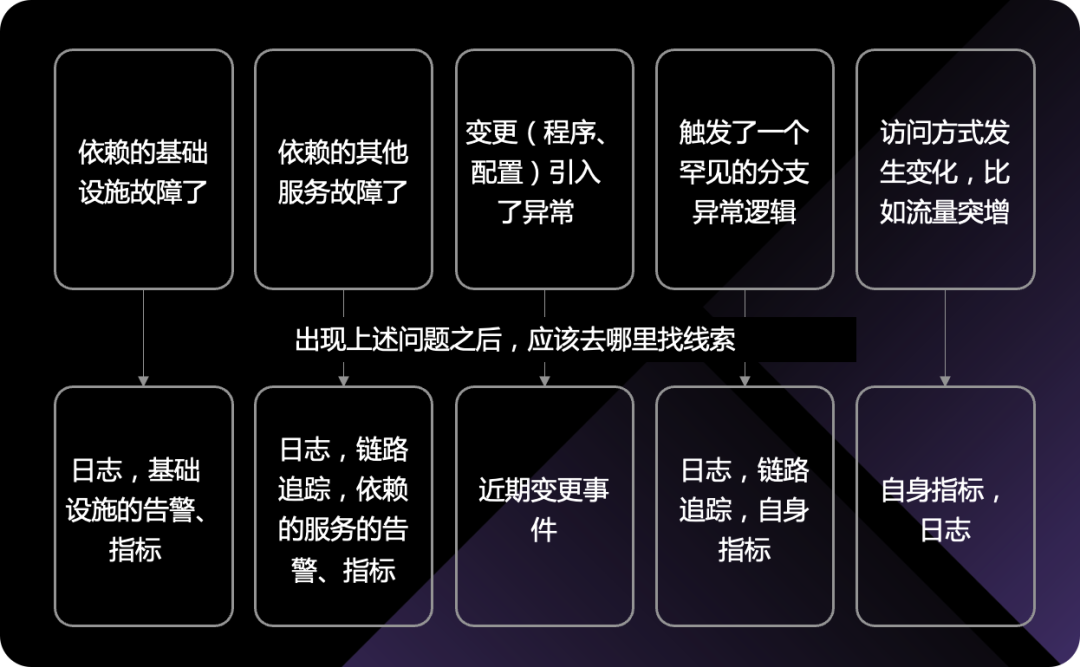
咦?说来说去,还是要建立 metrics、logs、traces、events?是的,但不仅是,只有数据还远远不够,我们需要通过平台工具,通过数据运营整理,帮助用户找到数据特征,建立初步观点,最终形成洞察定位故障直接原因。还记得那张信息层级的图吧:

网上有人批评可观测性三支柱的说法,核心要点是:不能只关注 raw data,就像一道菜,只有原料还不能称之为一道菜,没有炊具、菜谱、厨师,无法最终产出那道菜(客人要的是那道菜,那道菜才是结果,应该没有哪个餐厅说,你看我原料都有,完活了,让客人吃吧,应该没有这样的餐厅…)。
Martin Mao 曾经也写过一篇文章《Beyond the 3 Pillars of Observability》来论述这个事情。
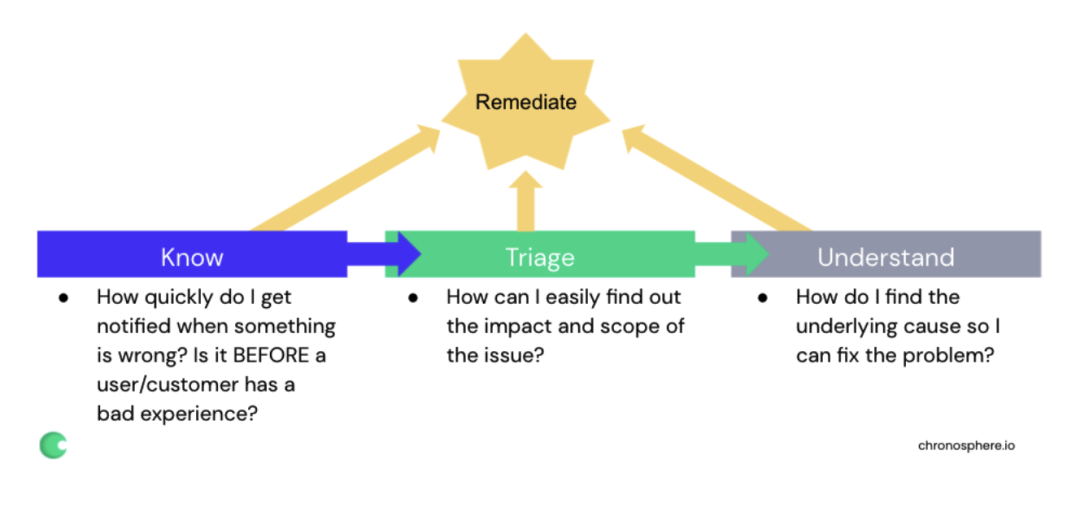
他的核心观点是:只关注三支柱 raw data,认为有了三支柱数据就建立了可观测性,是不对的,我们更应该面向结果来思考如何构建整个体系,Martin Mao 认为,所谓的结果,就是 Remediate,就是止损!英雄所见略同。
可观测性体系具体要如何做才能辅助技术团队止损
还是参考刚才信息层级的图,有了 raw data 数据底座之后,可观测性体系还需要利用平台能力、通过数据运营整理,呈现数据特征、帮用户建立初步观点,最终形成洞察,定位故障直接原因。
可观测性体系要告诉我故障模块
这应该是可观测性体系提供给客户/用户的第一个观点,故障发生了,现在都是微服务的,你得一目了然的告诉我具体是哪个模块故障了不是。总不能让我写一条有一条的 promql,看一个又一个监控大盘,才能找到故障模块吧。故障处理可是要争分夺秒的,一个一个查看太浪费时间了。
既然要一目了然,初始页面上的内容不能太多,从技术角度来看,一般模块都是有层级关系的,首先是系统,然后是子系统,然后是模块。所以,初始页面应该展示系统的健康状况,如果某个系统有问题,应该可以点击进去查看详情(这个过程称为下钻),下钻到子系统,再下钻到模块,最终找到故障模块。
那如何衡量一个模块是否健康呢?这其实就可以使用 SLO/SLI 这套体系,每个模块都有几个 SLI,每个 SLI 异常,这个模块就可以定义为异常,进而定义子系统异常、系统异常,这个过程也有种故障冒泡上浮的感觉。
我以我们的产品来举例这种效果图:

这样的系统我们称为灭火图,最上层是一个个的系统卡片,如果有问题就会有个飘红的小火苗,点击详情进入,可以看到相关子系统,点击故障子系统,可以看到模块以及核心接口的列表,进而可以定位到故障模块或核心接口。产品通过颜色做引导,而且具备层级关系,即可做到一目了然。
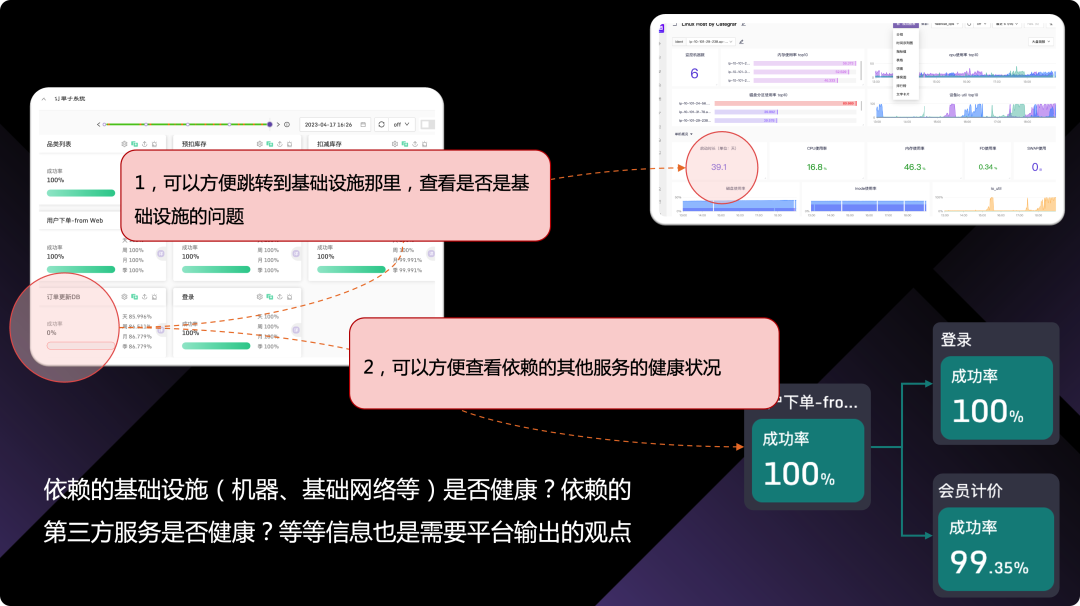
可观测性体系要告诉我故障模块的各项依赖是否健康
模块依赖的数据库、中间件、基础网络、机器硬件、第三方服务等等,都会影响模块的健康状况。所以,当模块异常的时候,我们需要知道各项依赖是否健康,如果依赖也异常,那么模块异常的直接原因基本可以断定是异常的依赖项导致的。
要用可观测性产品建立这样的视图,核心有两点,一个是依赖的关联关系,一个是依赖项的 SLO 视图(通常体现为 metrics 仪表盘)。下图是一个逻辑示意图:
可观测性体系要告诉我是否是变更导致的
线上故障,大概 70% 都是变更导致的,所以运维行业中流传一句话叫:“变更是万恶之源”。所以,当故障发生的时候,我们需要知道是否是变更导致的,如果是变更导致的,就要尽快止损。
如果迭代比较快,每周的变更数量会很多,那么如何快速定位到是哪个变更导致的故障呢?这需要可观测性产品提供一些数据特征给用户,用户才能方便分析。典型的是在时间维度上做文章。把故障和变更放到一张图上,在时间维度上做对比,比如从故障时刻往前看 1 小时,看看有没有变更,如果有,那个变更很可能就是罪魁祸首。示意图如下:
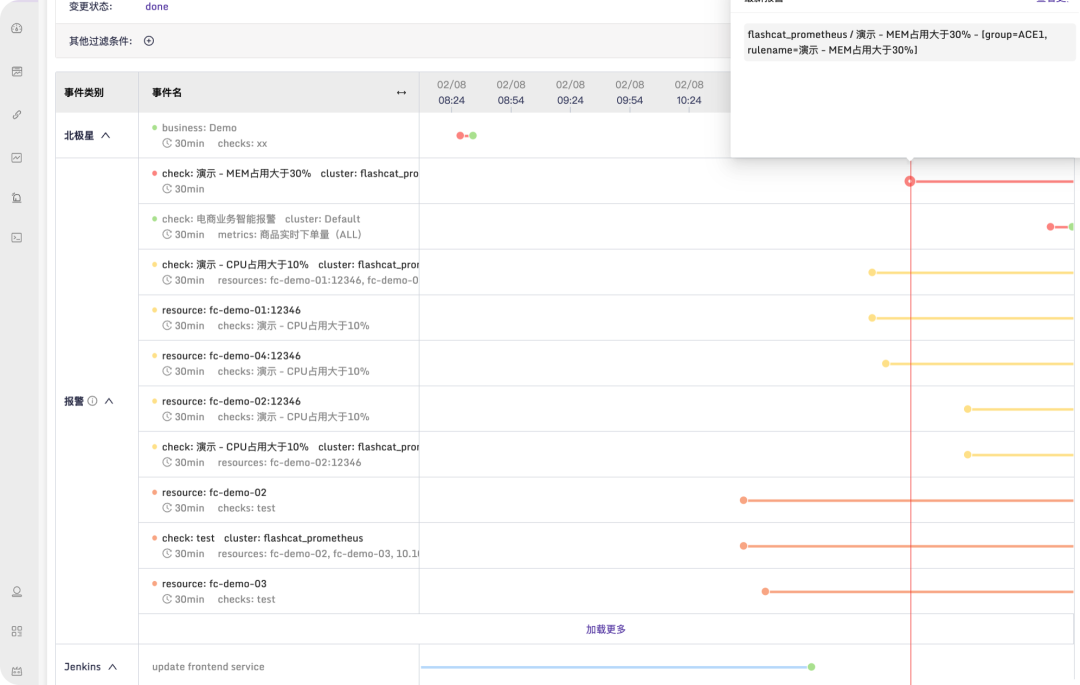
注意,这里的变更不仅仅是代码变更,还包括配置变更、机器变更、网络变更等等,变更事件收集得越全,越有价值。
上面,我举例了三个可观测性产品需要为用户输出的观点:
可观测性体系要告诉我故障模块
可观测性体系要告诉我故障模块的各项依赖是否健康
可观测性体系要告诉我是否是变更导致的
当然,还有其他观点可以输出,比如是否是容量不足导致的故障,大家可以自行思考看看还可以让可观测体系输出哪些观点。但是,罗马不是一天建成的,在某个阶段,可观测性体系输出的观点有限,不足以帮我们定位故障,此时,可观测性体系还可以做什么呢?
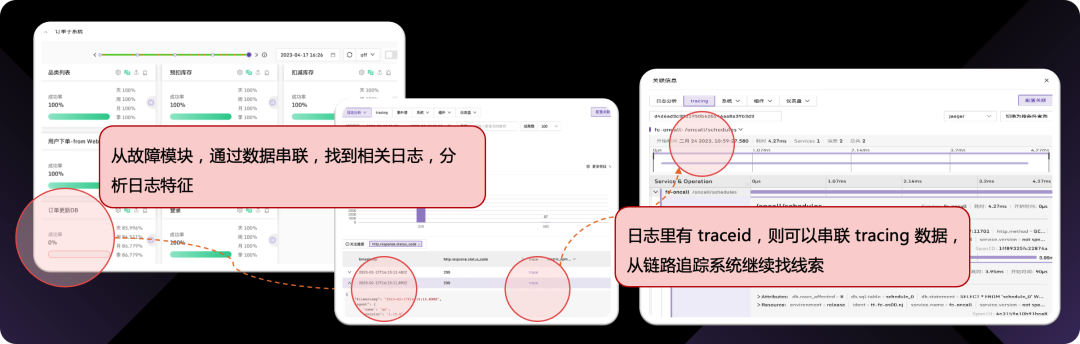
至少,还需要提供工具帮我们分析数据特征,别让用户陷入海量散乱的可观测性 raw data 中。这需要多维分析引导能力、数据串联打通能力。举一个数据串联的例子:
总结
可观测性体系不能仅仅只有散乱的数据,而应让数据呈现特征,让特征呈现观点,让特征和观点辅助洞察:洞悉故障直接原因,完成止损!这才是建设可观测性体系的核心目标。
作者简介:
秦晓辉,Open-Falcon、Nightingale 创始研发,极客时间《运维监控系统实战笔记》作者,公众号 SRETalk 主理人,快猫星云创业合伙人,创业方向是稳定性保障方向。如果你有兴趣来《运维百家讲坛》输出一些自己的宝贵经验和见解,欢迎联系我,联系方式如下:18612185520(微信同号)。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 2 条评论