

英伟达过去近 20 年间一直积蓄着软硬件力量,为 2023 年 AI 大爆发这一历史性时刻做好了准备。他们能够成为这场风暴的核心绝非偶然。
乘着 AI 这股东风,英伟达“赢麻了”
英伟达是一家主要生产图形处理单元(简称 GPU)的厂商。但今时今日看来,“图形”这个表述已经不太准确,GPU 真正擅长的其实是工作量巨大的浮点数学运算。其早期用途就是支撑起计算机上搭配的高帧率与高分辨率显示器,也是图形处理这种说法的由来。毕竟在那个时代,这就是 GPU 最常见的应用场景。
大约在 2005 年左右,英伟达敏锐意识到图形虽然确实在疯狂吞噬浮点算力,但却绝对不是唯一的实际应用场景。于是他们踏上了一段漫长的研发旅程,积蓄下的力量也让他们成为如今这场 AI 风暴的绝对核心。从 2007 年的 CUDA 开始,英伟达开发的软件允许更多人使用GPU处理图形之外的更多工作负载。
2012 年,英伟达的投入得到了初步回报。全球首个高质量图像识别 AI,也就是 AlexNet,正是建立在英伟达的 GPU 加软件之上,还成功在一年一度的 ImageNet 竞赛中碾压其他竞争对手。从那时起,英伟达的软硬件组合就成为除谷歌之外,所有厂商开展 AI 研究时的默认配置。
接下来,英伟达又把后续 GPU 研发划分成两条赛道:其一是 PC 端与加密货币采矿设备,其二则是数据中心 GPU。PC 端的 GPU 产品相当昂贵,最高售价可达 1600 美元左右;数据中心 GPU 的价格则更加夸张,往往高达 1 万到 1.5 万美元,甚至出现过 4 万美元的旗舰单卡。英伟达的数据中心 GPU 拥有约 75%的毛利空间,在硬件领域简直是前所未闻。
但这也是一家厂商在 AI 软硬件领域获得实质性垄断地位后,自然能够摘取的胜利果实。2012 年之后还有另一件大事,就是英伟达的 GPU 和软件让AI模型的体量获得了指数级增长。

这里的 Y 轴递增为对数尺度,因此在右端的“现代”部分呈现出的其实是恐怖的指数级增长。
在 2012 年之前的几年间,模型体量大致按照摩尔定律每两年增加一倍。但从 2012 年开始,每家技术企业都开始用英伟达GPU 研究机器学习,模型体量折线也开始一路飙升,每 3 到 4 个月就翻一番。这样的速度一路持续到 ChatGPT 亮相。期间出现的最大模型就是 AlphaGo,它最擅长的是在棋坪之上狂虐人类选手。甚至一直到 2021 年,当时最大的 AI 模型还只能玩玩游戏。
模型大小很重要,因为在生产环境中构建和运行这些模型的成本,也随着模型体量呈现出指数级增长。GPT-4 的体量就是同族大哥 GPT-3.5 的 3 到 6 倍。但OpenAI为 GPT-4 API 开出的订阅费却要高出 15 到 60 倍。另外需要强调,OpenAI 开放的并不是 GPT-4 的最佳版本。负责托管 OpenAI 大语言模型的微软 Azure 拿不出足够的 GPU 来支撑这项业务,所以大部分手头拮据的客户暂时还与最强大语言模型无缘。不止如此,GPU 供应短缺还阻碍着其他种种服务的实现。
我们举个简单的例子。请 ChatGPT 为即将召开的美联储会议写首诗,输入 3 句提示词,让它输出一首 28 行诗。看看这样一项简单任务,在 OpenAI API 上要花多少钱:
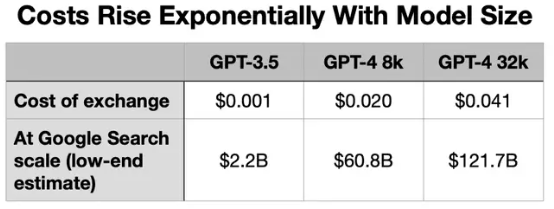
谷歌上一次公布搜索指数还是在 2012 年,当时的搜索量为 1.2 万亿次。这里采取较为保守的数字:3 万亿次。(采用 ChatGPT Plus、token 计算软件、OpenAI API 计费标准)
价格之所以大幅上涨,原因就在于英伟达的数据中心 GPU 太过紧俏。受资源所限,第三列中的 GPT-4 32k 服务目前仍无法全面推开。
虽然大语言模型在最初的研究阶段,就已经确立了体量越大、成本越高的基本趋势,但生产层面的大规模推理带来了更加夸张的资源需求和设施开销。于是突然之间,AI 技术的基本经济逻辑发生了变化。过去十年间,每个人都在用英伟达的软硬件搞模型研究,所以如今钱都被英伟达给赚走了。
是的,我是说所有的钱:

微软季度财报
多年以来,随着收入的快速增长,微软在其智能云领域建立起强大的市场影响力。但随着被迫大量采购 GPU 以支撑ChatGPT的生产应用时,好日子正式宣告结束。微软的云运营利润率已经连续四个季度下降,原因自然就是英伟达数据中心 GPU 那高达 75%的毛利率。
面对英伟达 DGX H100 这样一台 AI 服务器时,我们会发现其中的利润分配极其不均衡。

英伟达产品中各第三方组件的估算成本
作为 AI 服务器领域的绝对主力,英伟达 DGX H100 总体销售额的约九成都落进了芯片巨头的口袋。这甚至还没算英伟达认证授权设备的钱。
如果大家碰巧想打造自己的高性能服务器,可以选择回避英伟达认证、搭载廉价 CPU,或者压缩内存/存储空间的方式来降低成本。当然,回避英伟达网络 DPU,换成博通或者 Mellanox(好像也跟英伟达有关系)等更便宜的硬件似乎也行,但这可能会导致性能瓶颈。但无论怎么节约,8 个 H100 GPU 和负责 GPU 互连的 4 个 NVSwitch 肯定躲不掉,光这些就要花掉你近 18 万美元。
钱确实都被英伟达给赚了,他们花了近 20 年时间为 2023 年的 AI 大爆发积蓄力量。虽然巨额利润让英伟达成为市场上的众矢之的,但其捍卫 AI 硬件主导权的护城河就是英伟达掌握着唯一完整的软硬件组合,而且这套组合是研究人员们自 2012 年以来就长期依赖的默认选项。随着我们将这些超大体量模型投入生产,这个默认选项正令每家参与厂商都“血流不止”。
那么,业界又有怎样的应对之道?目前来看主要分三点:
硬件:采用“AI 加速器”这类替代性硬件,以低得多的成本执行相同的工作。
模型体量:在近期开发中,研究人员正努力在更小的模型上达成更好的效果,借此显著降低对 GPU 算力的需求。
软件:将训练和推理负载从硬件上剥离出来,抽干英伟达的护城河。
AI 加速器:暗渡陈仓之策
AI 加速器其实是多种不同硬件类型的松散组合。这项技术始于 2015 年,当时谷歌的 AI 训练需求已经超过了英伟达的 GPU 供应能力。因此在同年,谷歌首次公布了供内部使用的张量处理单元(TPU)。目前 TPU 2、3 和 4 版已经在 Google Cloud 上开放租用,在执行相同工作负载时能比云 GPU 节约 40%到 50%成本。
这些加速器拥有多种设计方式,但底层技术逻辑是相同的——以计算成本更低的整数运算,模拟处理成本极高的浮点运算。这虽然会导致数学精度降低,但大量研究表明除科学应用之外,大多数 AI 模型并不需要英伟达GPU 提供的极高精度。
所以这就像是在作弊,但效果似乎不错。现在我们已经看到了 AMD/Xilinx、高通和英特尔等厂商的 AI 加速器,再加上 Google Cloud 的原研 TPU。亚马逊旗下的 AWS 也开发出了自己的加速顺。另据报道,微软也打算为 Azure 研发加速器,可能会与 AMD 合作分担 OpenAI 的工作负载。
但这一步也得走得小心谨慎。一方面,厂商们希望慢慢从英伟达手中夺回业务利润;另一方面,在可预见的未来,各厂商仍须采购大量英伟达 GPU。只有长袖善舞者才能在这样微妙的局面下始终占据主动地位。
在后文中,我们还会聊聊阻碍硬件发展的最大因素——英伟达的软件护城河。
模型体量:小即是美
2012 年以来,AI 模型的体量开始迅速膨胀,每 3 到 4 个月就翻一番。经过多年积累,模型体量已经极为惊人。以 OpenAI 为例:
GPT-1 (2018 年): 多达 1.17 亿参数
GPT-2 (2019 年): 多达 15 亿参数
GPT-3 (2020 年): 多达 1750 亿参数
GPT-4 (2023 年): OpenAI 没有公布,但可能已经达到万亿级别这样的体量在研究阶段还能承受,但到生产应用阶段已经开始产生恐怖的成本。受到 Azure 设施端 GPU 供应能力的限制,OpenAI 甚至无法将 GPT-4 的最佳版本对外开放。
这些根本就不是秘密,从去年秋季开始,每个人都已经感受到了新的发展方向。“越大越好”在商业环境中没有任何意义,“小即是美”才是 AI 时代的新母题。
而这一切的开端,就是 ChatGPT 公布的那一刻。之前不少大大小小的公司都在做自然语言处理,ChatGPT 如同一记响亮的耳光,昭示世人什么叫更大更好、什么叫引领时代。恐慌情绪也由此开始蔓延。
去年,Stability AI 的开源 Stable Diffusion 图像生成模型得到了人们的普遍关注。不少厂商很快决定开源自家模型,看看能不能在社区的支持下更上一层楼。Facebook 就是其中之一,他们开源了自家 LLaMA 语言模型,其参数规模高达 650 亿,约为 GPT-3 的三分之一,比 GPT-4 小 9 到 18 倍。之后,斯坦福大学的研究人员又开发出了 Alpaca 版本,能够在几乎所有硬件上运行。
转机就此出现。
只有拥有关注和热度,社区的开源开发速度往往相当惊人。如今,已经有大量应用程序被构建在 Alpaca 和其他开放模型之上。人们还在努力提升模型性能的同时,想办法控制它们的参数体量。
最重要的是,这些模型已经开始在消费级硬件,包括个人电脑甚至是智能手机上运行。而且它们完全免费,于是基础模型领域的分界线不再按企业划分,而是呈现出商业与开源两大阵营。
谷歌当然也注意到了这股趋势。本届 I/O 大会上,他们就公布了一套比前代更小、但性能却更强的语言模型。
LaMDA (2021 年): 多达 1370 亿参数
PaLM (2022 年): 多达 5400 亿参数
PaLM 2 (2023 年): 根据未经证实的内部消息,参数多达 3400 亿,基本符合谷歌所谓比上代模型“明显更小”的说法这是我印象中 AI 模型第一次小型化转变。其中最小的 PaLM 2 模型甚至能够运行在 PC 或智能手机之上。
必须承认,GPT-4 仍然是最好最强的语言模型,但也是体量最大、运行成本最高的方案。这对英伟达有利,但也激起了业界打造高性能小模型的热情。谷歌已经迈出了第一步,开源贡献者也在微调自己的领域模型,而且主要以 LLaMA/Alpaca 为底材。
随着更多工作负载运行在消费级硬件之上,英伟达也必须接受市场对 GPU 算力的依赖度日益降低的现实。
软件:抽干护城河
非英伟达阵营的 AI 软件基础设施既不够完善又有严重的碎片化问题,在这样的硬件上构建系统往往会把人带进死胡同。唯一的例外就是谷歌,他们自 2015 年开始就在围绕 TPU 构建内部工具,并用实际行动证明这条路绝对走得通。
对英伟达来说,目前业务优势中最重要的部分并不是硬件——那只是表象,只是赚钱的载体。真正的核心,是他们研究了近 20 年的软件。软硬件之间的紧密结合,才形成了英伟达如今这坚不可摧的技术护城河。然而,高昂的生产运营开销已经令客户们不堪重负。
多年以来,非英伟达研究人员会各自根据需求编写软件,这种一盘散沙的组织形式根本拿不出统一且稳定的生产环境,也是颠覆英伟达霸权中最困难的一环。
目前同类最佳方案来自 Chris Lattner 创立的 Modular 公司。Lattner 在软件行业可谓是传奇人物,在研究生期间编写的 LLVM 成为目前各类主流软件编译器的基础。LLVM 的创新核心在于其模块化结构,能够扩展至任意编程语言和硬件平台。他曾在苹果主导创立了Swift编程语言团队,随后又在谷歌、特斯拉和 SiFive 任职。Modular 公司也在 A 轮融资中获得了谷歌的资助。
Modular 目前的一大工作重点是打造推理引擎,也就是负责在生产环境中运行模型的部分,且同样采用 LLVM 那样的模块化设计。它能够扩展至一切开发框架、云或硬件平台。无论模型本身如何构建,都可被放入模块化推理引擎之内,并在云端的任意硬件上运行……至少 Modular 公司承诺如此。
此举堪称釜底抽薪,誓要抽干英伟达的护城河,攻下皇城夺其鸟位。
英伟达的反击之战
英伟达正独力对抗整个世界,对手不只有自己的客户,还有客户的客户。而英伟达的思路非常简单——永不自满、永不止步。关注英伟达近期展会的朋友,一定都能感受到这种居安思危的强烈信念。
但有时候倾覆可能就有一瞬之间,而且真正的对手并不是看得见的洪水猛兽,而是看不见的涓流渗透——也就是那些更便宜、性能极差但却无处不在的普通硬件。
历史上类似的经典案例是IBM与英特尔之争。1970 年代,IBM 的客户发现英特尔等厂商正着手打造“微型计算机”,但因为性能太差而表示不感兴趣。IBM 相信了客户的判断,认为不必管它。可英特尔的芯片在业余爱好者群体中掀起狂潮,健康的现金流也支撑起芯片巨头不断投资并改进自家 CPU。
随着首款 PC 电子表格软件 Visicalc 的面世,英特尔的微型计算机突然间足以胜任商业应用。IBM 客户立马改旗易帜,就连 IBM 自己也成为英特尔的第一位大客户。之后的故事,大家应该都知道了。
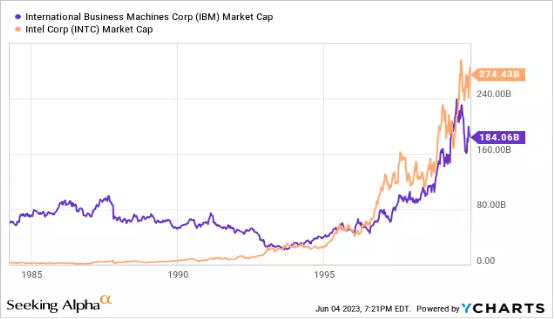
所以在我看来,英伟达也得拿出自己的 AI 加速器来护住自己的侧翼,哪怕削弱利润和增长空间也在所不惜。如果英伟达不做,就一定会有其他厂商出来做这件事。
英伟达的估值
网上各色讨论不绝于耳
英伟达的估值如今绝对是热门议题。按照最乐观的假设,英伟达的市场估值也至少相当于 50 年的经营收益。但这么理想的状况只可能存在于理论模型当中。
2023 年的英伟达,其实与 1999 到 2000 年的思科颇为相似:
成为新一波技术的领先硬件基础设施供应商:1999 年的互联网与 2023 年的人工智能
尽管都保持着快速增长,但思科在 2000 年的市盈率已达到 200+(即经营 200 多年才能赚到市场估值),而英伟达上周五的市盈率为 204 倍。
一位推特用户分享的数据显示,过去十年回报率最高的十大科技股中,英伟达以 10519%居首。排名第二的是 AMD,回报率达 4342%;特斯拉以 2756%的回报率名列第三。

但随着 2001 年经济衰退的结束,对思科的看涨风潮也很快偃旗息鼓。下面来看思科在那个时期的股价变化:

必须承认,估值非常重要。但十多年来的宽松金融环境已经基本结束,至少目前来看没有恢复的迹象。而思科也再没能回到 2000 年时的巅峰状态。
当然,二者之间还有不少具体差异。思科虽然是当时毫无争议的市场领导者,但一直面临着激烈竞争。而目前的英伟达仍堪称天下无敌。只是这种无知状态能持续多久,是否足以支持截至上周那高达万亿美元的恐怖估值?
我还发现,思科的发展轨迹跟 Gartner 的技术成熟度曲线高度重合。
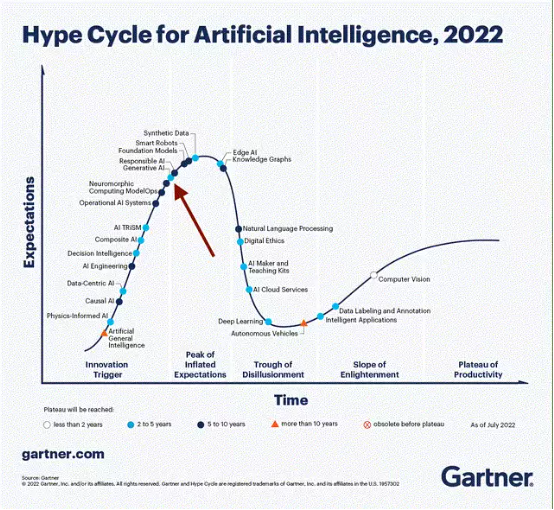
请注意 Gartner 整理的生成式 AI 技术成熟度曲线。
这张图表发布于 2022 年 7 月,也就是 ChatGPT 掀起全球热潮之前。可以看到,Gartner 认为生成式 AI 已经接近“预期峰值”。
英伟达要想让自己的市场估值继续增长,就必须想办法消弭以下五大风险。
加密货币挖矿收入已经永远无法恢复。这一点在估值中并未体现,但我认为极有可能发生。
AI 投资与加密货币投资一样属于金融泡沫。我认为这种可能性很低,但至少应该把这个因素计入估值结果。
英伟达在 AI 硬件领域的主导地位遭到颠覆,被迫压缩现有毛利率。从长远来看,发生这种风险的可能性极大,毕竟这背后可是个万亿美元的问题。具体时间可能是在 2025 年、2030 年,或者是 2035 年。
今年年底或明年年初可能出现经济衰退,发生几率可能高达 50%。
摩尔定律再次陷入瓶颈,在突破之前进一步提升性能的成本会更高,毕竟硅材料的物理极限就摆在那里。在 2020 年成为唯一真神之前,我对英伟达一直相当看好。虽然如今的英伟达仍然遵循着自己的商业逻辑和经营规则,但我已经无法理解哪怕是最乐观情况下也高达 50 年的市盈率到底有什么依据。
所以作为行业中的一员,我会密切关注这场有趣的商业冲突,也迫不及待想看到接下来会发生什么。技术市场乃至整个世界一直瞬息万变,只有时间能够给出最终答案。
原文链接:
https://seekingalpha.com/article/4609485-ai-nvidia-is-taking-all-the-money
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


加V:busulishang4668

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 1 条评论