
为了更好地评估大型语言模型(LLM)的编码能力,来自斯坦福、普林斯顿和康奈尔的研究人员开发了一个新的基准测试。这个新的基准测试名为 CodeClash,它让多个LLM在多轮比赛中展开较量,旨在评估在突破定义狭窄的特定任务范畴后,它们实现竞争性高阶目标的能力。
研究人员认为,仅在明确指定的任务上评估编码 LLM,例如修复 Bug、实现算法或编写测试,不足以评估它们应对现实世界软件开发挑战的能力。
与维护任务不同,开发人员需要实现高阶目标,例如提高用户留存率、增加收入或降低成本。这需要完全不同的能力;工程师必须一层层地将这些目标分解为可操作的步骤,对它们进行优先级排序,并就应采取哪些解决方案作出决策。
为了使 LLM 评估过程更接近现实世界中以目标为导向的软件工程,研究人员开发了 CodeClash,这是一个旨在反映开发周期迭代性质的基准测试。在开发过程中,它会根据现实世界的反馈提出、部署和完善变更,然后才进入下一步。在 CodeClash 中,LLM 争相构建能够实现高阶目标的最佳代码库:
多个 LM 系统在多轮比赛中构建实现高阶目标的最佳代码库。这些代码库实现的解决方案会在代码竞技场中展开角逐,例如 BattleSnake(基于网格的生存游戏)、Poker(不限注德州扑克)和 RoboCode(坦克大战)。
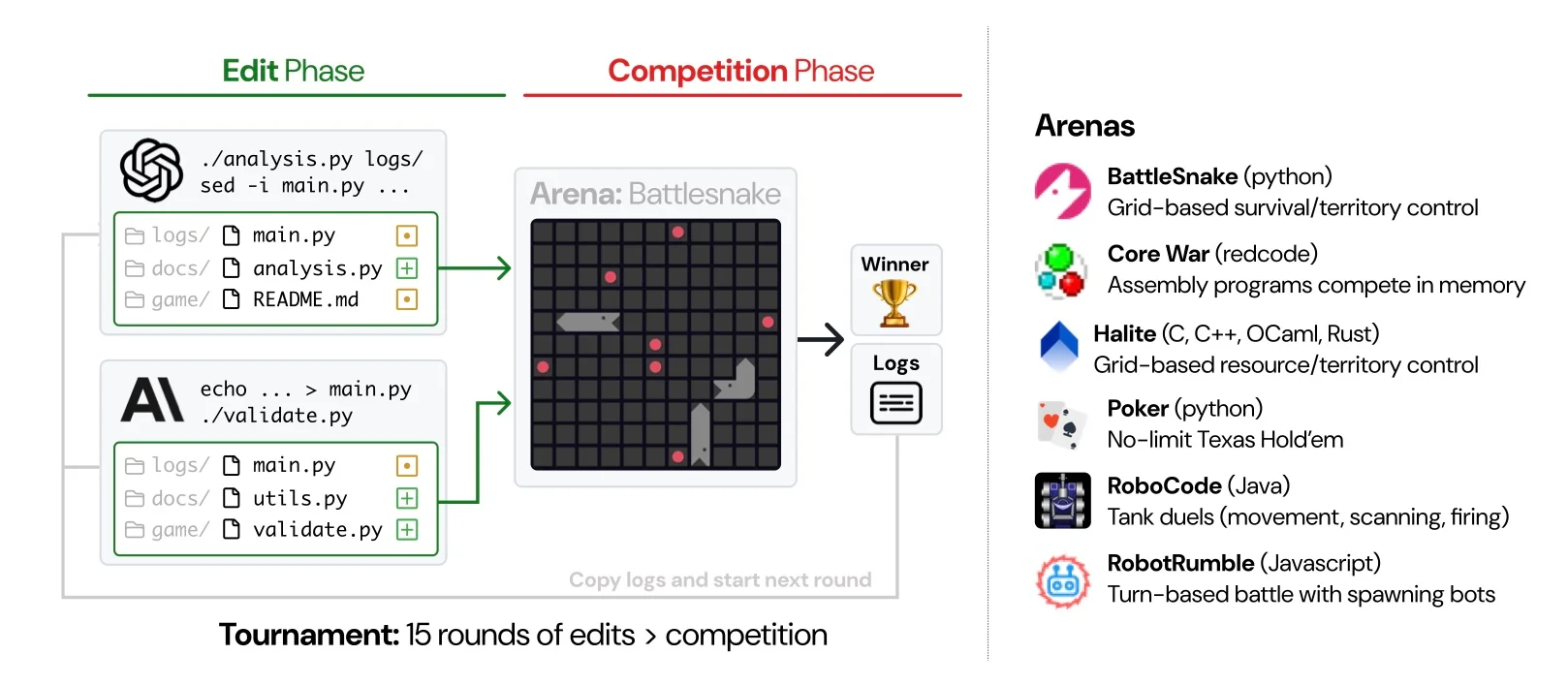
每一步包括两个阶段:编辑阶段(LLM 编辑代码库)和比赛阶段(代码库将在代码竞技场中相互评估)。代码竞技场根据分数最大化、资源获取或生存等目标来确定胜者。
一开始,只为 LM 代理提供简要的环境描述。虽然起始代码库中有竞技场机制、示例机器人和推荐策略这样的信息,但模型必须主动发现它们。
每轮结束时,比赛日志都会记录到日志库中,供 LLM 挖掘见解,并为下一轮比赛做好更充分的准备,其目标是全面提升代码库质量,同时增强相对于对手的竞争力。
通过这种方法,研究团队进行了 1680 场比赛,涉及 8 个 LLM,包括 Claude Sonnet 4.5、GPT 5、Gemini 2.5 Pro、Qwen3-Coder、Grok Code Fast 等。没有哪个模型在所有竞技场中都始终优于其他模型,不过总体来看,来自 Anthropic 和 OpenAI 的模型稍微有些优势。这在一对一和多代理比赛中都成立,只是在后一个场景中波动性更大些。例如,6 人比赛的获胜者只获得总分数的 28.6%,而在一对一挑战中为 78.0%。
研究人员还评估了模型分析其他 LLM 生成的代码库的能力。在这种情况中,GPT 5 被证明是最佳模型,优于 Claude Sonnet 4.5。然而,分析表明,检查对手的代码并不会自动转化为竞争优势。
尽管这项研究很有说服力,但研究人员承认,当前的实验环境规模还小于典型的现实系统。因此,未来研究将致力于处理更庞大的代码库并支持多重竞争目标。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://www.infoq.com/news/2025/11/codeclash-competitive-llm-coding/




