

1 实验室为什么要采用 TPU
百分点认知智能实验室应用预训练语言模型的方法主要有两种。一种方式是通过互联网上开源的预训练语言模型,如 BERT 和 XLNet 等,并根据上游任务建立相应的模型进行 finetune。另外一种方式,在遇到对效果要求很高的 NLP 任务上,实验室会根据目标语料进行预训练语言模型的增量或重新训练,通过新生成的预训练模型,实验室在文本分类、信息抽取、问题等价性等方面均取得了重要的进展。
然而,预训练的语言模型也带来了一定的问题,在传统的 word embedding 加 LSTM 或 CNN 为主的模型训练当中,模型的参数很少会超过千万级,而这样的模型只用一块或几块 GPU 即可在短时间内完成训练。相比之下,base 版本的 BERT 模型有 1.5 亿个参数,而 large 版本的则超过 3 亿,这样的模型即使仅仅根据任务 finetune 也可能需要数日,而重新训练则更是需要以月为单位计算。
计算成本开销的增大,不但增加了应用该模型的困难,同时也为 NLP 算法工程师的工作方式带来了一定的挑战。由于使用预训练语言模型需要经过大量的调参,所以这使得算法工程师的工作面临着两难的决策。
一方面,如果采用串行的方法进行调参,则 NLP 算法工程师需要花费大量的时间进行等待,从而严重降低了其单位时间的产出。另一方面,如果采用并行的方式进行调参,则消耗的算力会显著的增加。因此,在预训练语言模型已经改变 NLP 领域的时代,如何探索出一种高效省钱的 NLP 算法工作流程,将是 NLP 算法研究员和工程师面临的普遍问题。
值得注意的是,这个问题并非是单纯的增加 GPU 数量就可以解决的,其原因在于在一些训练任务中,并非增加 batchsize 也可以达到同样的效果。因此在理想状况下,NLPer 需要的是在短期内可以显著减少预训练语言模型计算时间的高效芯片,而不仅仅是大量的简单的堆叠现有的芯片。
为了尝试解决这个问题,百分点认知智能实验室在国内首先与谷歌合作,对其提供的 TPU 进行比较全面的测评,并取得了积极的效果。由于 TPU 的中文文档和用例相对匮乏,我们首先对 TPU 进行简单的介绍。
2 关于 TPU 的简单介绍
TPU 即谷歌推出的 Tensor ProcessingUnit,一个只专注于神经网络计算的处理器。TPU 的主要功能是矩阵运算,是一个单线程芯片,不需要考虑缓存、分支预测、多道处理等问题的处理器,其可以在单个时钟周期内处理数十万次矩阵运算,而 GPU 在单个时钟周期内只可以处理数百到数千的计算。
此外,GPU 作为“图像处理器”,其基本的硬件架构仍然要能够支持图像相关运算中所存在的各种需求,这意味着 GPU 多少受到其固有架构的桎梏,这些机制的存在使得预测 GPU 的处理性能和利用率变得比较困难,故在现实使用中,使 GPU 达到理论计算峰值是比较困难的。
而相比于 GPU,TPU 的实际运算表现要比 GPU 更加稳定,除此之外,TPU 对于数据的读取也进行了大量的优化,所以当所涉及的运算包含大量的矩阵计算时,TPU 在训练的优势就显现出来了。
因为 BERT 模型是 multi-head dot-product attention,所以从数学上而言,BERT 不论是前向传播还以后向传播计算都包含了大量矩阵运算,这使得 TPU 天生就非常适合计算 BERT 等神经网络。
当然任何理论分析都是没有 Benchmark 有说服力的。那么 TPU 效果究竟如何呢?下面我们来展现一下百分点认知智能实验室对 TPU 的测评结果。
3 实验室使用 TPU 的结果
如上文所述,TPU 在训练 BERT 模型中到底有怎样的优势呢?我们分别就重新预训练语言模型和 finetune 语言模型的任务进行了比对。
实验室采用了 500M 的文本语料,并根据主流的 BERT BASE 版模型的参数要求:首先将文本数据 mask 十遍产生预训练数据,然后采用了序列长度为 128、12 层、768 维等参数进行 500k 步训练。
本实验室使用 TPUV2-8 进行计算并与主流 GPU 从运算时间和花费上进行对比,结果如下:
实验室分别使用了 TPU 和 GPU 对 BERT 模型进行 500K 步训练,通过与主流的 GPU Tesla V100*8 对比发现,使用 GPU 进行训练花费了大约 7 天时间,而是 用 TPU 进行训练仅需要了 1.2 天即可完成。同时,在 总费用成本上也是大量的缩减。
TPU 在 BERT 预训练模型的运算时间和总成本上完胜了当前的主流的 GPU。这里我们采用了已经训练好的 BERT 模型在 10 万条数据上进行十轮的 finetune 再次进行对比,结果如下:
实验室现在使用 TPU 作为加速硬件的方法对 BERT 模型进行十轮的 fintune,如上表所示,通过和现在主流的 GPUTesla V100*8 进行对比发现:TPU 完成 fintune 仅仅需要约 10min 的时间,而 GPU 完成同样的 finetune 需要超过一个小时的时间,这项技术大大提升了实验室在 NLP 领域进行神经网络计算的效率,而且从总花费的角度上来看,使用 TPU 的成本只有 GPU 的 3.5%左右。
因此,TPU 的超高效率和低廉价格将神经网络计算变得更加“亲民”了,TPU 可以从根本解决了中小公司算力要求高但经费不足的顾虑,曾经那种需要几十台 GPU 几天时间的 BERT 预训练由一个 TPU 一天可以轻松解决。这让所有的中小型企业也可以拥有之前所缺少的强大算力。
4 使用 TPU 的经验总结
下面是实验室对使用 TPU 的一个经验总结,希望大家可以借此排坑。
我们以租用 TPU V2 八核心为例,系统的说明一下创建虚拟机实例和 TPU 实例的方法。进入到谷歌云的首页,其页面应类似于如下:
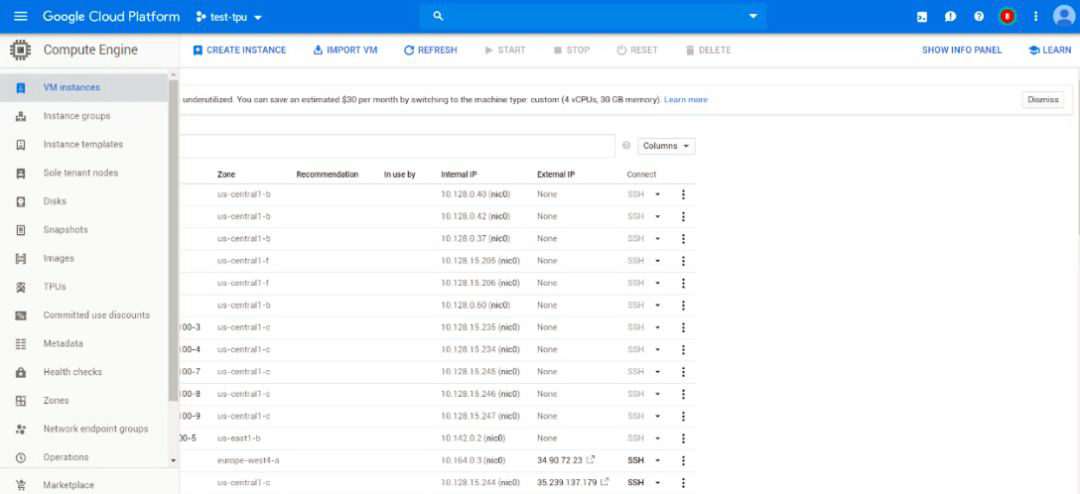
图一:谷歌云初始页面
首先需要创建一个 VM 实例,在选项中进行现存、内存数量、系统镜像等配置。
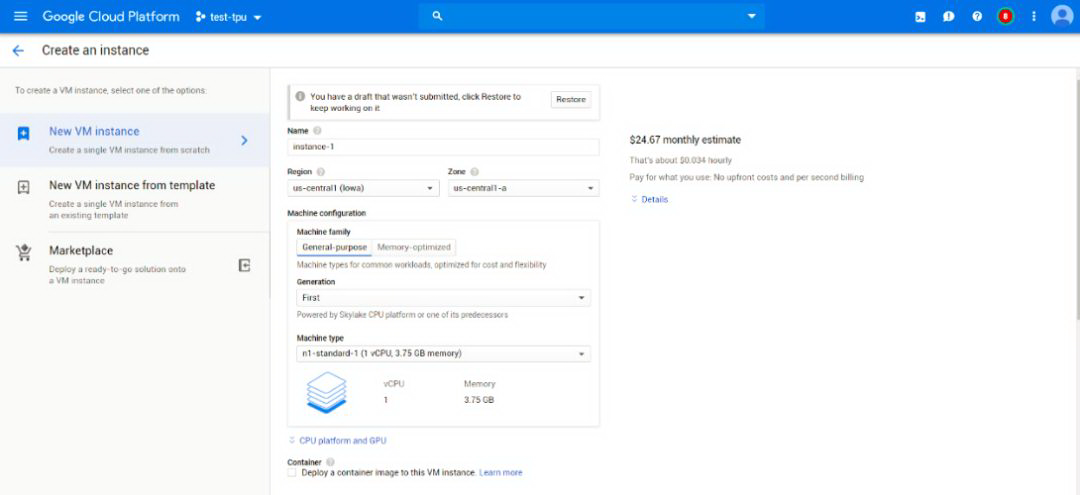
图二:创建 VM 实例的界面
在该页面的选项中,有几个是比较重要的。
Machinetype。该选项决定了 VM 实例的线程数和内存数量的配置。一般来说,在配置系统阶段,只选用最小的线程数和内存数量即可。而如果开始租用 TPU,由于读写 TensorFlowcheckpoint 由 CPU 完成,且网络带宽与线程数成正比,在 TPU 开始训练后,不宜选用过小的线程数。
BootDisk。该选项指定了系统的镜像。如果需要使用 TPU 进行计算,则要选择支持 TPU 的镜像。目前而言,TPU 支持两种深度学习框架,即 TensorFlow 和 PyTorch。相比较而言,TensorFlow 的支持会更为成熟,而 PyTorch 的支持则具有一定的实验性。建议目前还是选用 TensorFlow 框架。
在 Identityand API access 一项中,如果不存在部署的问题,建议选择 Allow full access to all Cloud APIs 一项。
接下来创建 TPU 界面:
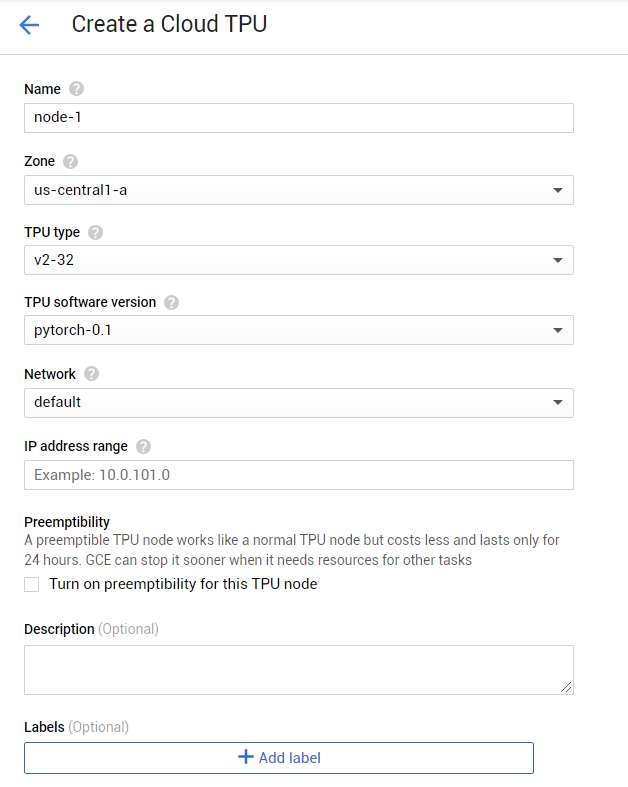
图三:创建 TPU 界面
在创建 TPU 的页面,有几个选项值得说明:
TPUtype 一项中,会出现 v2-8,v3-8,v3-32 等选项的说明(注意不同的区域提供不同型号的 TPU)。其中 v2 或 v3 为 tpu 的型号,-8 或-32 则为核心数量。最小的核心数量为 8 核心。在该模式下,我们可以选用抢占式的模式。而对于大于 8 核心的选项,则意味着 TPUpod。该模式尚不支持抢占式(但是抢占式正在谷歌内部进行内测)。
IPaddress range 一项中,如不涉及到部署,则可以填写 10.1.x.0,其中 x 为大于 101 的数字(如 102,103 等)。值得注意的是,如果之前已有 TPU 填写了某范畴,而新创建的 TPU 的 IP 地址范畴和之也有重叠,则新创建的 TPU 会覆盖掉原先的实例。
Preemptibility 一项为是否采用抢占式实例的选项。如前文所述,只有 V2-8 和 V3-8 两种型号支持创建抢占式实例。
如果以上选项均已设定完毕,则可以点击 CREATE 按钮创建 TPU 实例,然后就可以顺利运行 TPU 程序了。
5 实验室使用 TPU 的心得
我们在上文中介绍的 VM 实例和 TPU 实例的管理方式为众多方法中的一种,除去以上办法外,还可以通过命令行模型 ctpuup 等创建 TPU 实例,对此我们不再做详细介绍。下面我们重点结合实验室在此期间使用 TPU 的经验,和大家分享心得,帮助大家排雷。
首先大家需要注意的是 TPU 创建完毕并开始运行,即使没有实际的程序运行也会发生扣费。我们实验室建议在开启 TPU 之前,就先将代码在本地环境中调通,避免没有必要的费用流失。从实验室运行 TPU 的实战经历来看,我们建议使用 TensorFlow 的 Estimator 框架,因为我们只需在创建 Estimator 时将普通的 Estimator 改为 TPU Estimator,即可使用 TPU 进行 BERT 神经网络预训练。这样大大减少了实验室的工作量。
在进行 BERT 模型训练过程中,batch_size 的大小直接影响模型训练的性能,通过对 google TPU 了解得知,每个 TPU 包含了 8 个 core,建议设置 batch_size 大小为 8 的倍数。同时 google 推出了 TPU 的 pod 模式以满足用户对更大算力的追求,实际上就是将多个 TPU 进行封装成一个整体供用户使用,比如 V3-32,就是用 4 个 V3 的 TPU,因此我们建议 batch_size 的大小能被整体 core 的数目整除即可,这样可以最大效率的利用 TPU。
当然除此之外,在实战中我们还需要处理较大的文件在 VM 中的问题,因为这样会消耗大量硬盘资源以及增加运算成本,实验室用到了 Buckets—一个价格相对亲民的存储方式来提升资源运用的效率,我们建议将较大的文件(如 BERT 文件的初始权重)存储在 bucket 当中,该步骤较为简单,故我们省略详细介绍,有需要可以进一步阅读https://cloud.google.com/storage/docs/creating-buckets。
6 实验室对 TPU 的建议
实验室在经过一段时间的使用后,TPU 虽然在多个方面上完胜 GPU,但是我们认为 TPU 还是有很多可改进的地方:
TPU 的使用门槛很高,TPU 自开发以来,拥有较少的代码示例和文档,官方提供的实例也不够完善,对于初学者不够友好。尤其由于 TensorFlow 静态图的本质,这使得基于 TPU 的 Debug 比较困难;
究其根本 TPU 是围绕 TensorFlow 框架设计的硬件,实际使用过程中 TPU 硬件和 TensorFlow 版本具有较大的相互依赖性,大大减少了其可兼容性,使得使用其他人工智能框架的项目很难高效低成本地运用 TPU 进行运算;
由于 TensorFlow 本身是基于静态图的,而 TPU 从本质上也只能支持静态图,这使得需要依赖于动态图的应用难以在 TPU 上运行。这类应用包括 semantic parsing 和图网络等。
当然在 TPU 新技术的引进下,实验室会迎来新的转机和工作模式。随着计算效率的提高,实验室的算法研究员可以将冗长的计算等待时间极大缩短,并且提升整体实验室的研究效率,增强实验项目的可控性。之前,研究员因为考虑到时间成本问题,会采用多个假设并行验证的工作方式。因为每个实验都有风险出现问题,并行实验会使得研究员无法估测每个验证的具体成功率,很有可能耗费大量算力后空手而归。如今,研究员可以将所有假设串联并一一快速验证,显著提高实验的效率,大大降低了项目的成本风险,增加可预测性。
整体上来说,实验室认为 TPU 结合 BERT 模型是一个不错的开始,大大减少了我们预训练模型的时间,显著提升了 BERT 模型整体运算的效率,大幅度降低了硬件资源的算力成本。在这方面实验室还会进一步研究和探索,让我们期待未来更多的实践成果。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论