

导读:过去 7 年,上汽通用一直在大数据技术方面不断做新的尝试,这个尝试的根本目标之一是解决制造业的传统数据仓库无法支撑海量数据加载、分析的问题。
上汽通用的大数据开发经理徐雷,结合多年来负责上汽通用大数据平台的建设以及相关开发工作经验,在 7 月 12 日的 Kylin Data Summit 上,为大家深入讲解了这几年上汽通用大数据平台的设计、演进、发展历程。

上汽通用大数据开发经理 徐雷
根据徐雷的演讲,上汽通用自 2013 年开始搭建 Hadoop,开启大数据平台的建设步伐,到 2015 年,上汽通用已经把 Hadoop 定位成企业级的应用平台,2016 至 2017 年尝试将 Hadoop 与数仓进行融合……
这两年上汽通用又开始根据一些实时业务场景完善实时计算能力,同时,对于“大数据技术与传统的数据仓库应该如何融合?制造业目前关心的与物联网相关场景和技术结合的点有哪些?”等问题,上汽通用也在探索中前进。
上汽通用的大数据平台演进历程解析
大数据开端:搭建 Hadoop+Kafka 大数据架构
搭建 Hadoop 平台前,上汽通用已经有很多车联网的场景,比如说安吉星系统,还有专门负责做车辆研发的车联网技术,它们会把上汽通用汽车上的信号数据采集后传送到传统数据仓库,这样下来每天采集到的数据量非常大,数据分析的挑战也非常大,传统数仓无法支撑这种需求。
针对这样的情况,上汽通用从 2013 年开始搭建 Hadoop+Kafka 大数据架构。在这套大数据架构下,我们构建了一套专门针对工程车辆的信号分析平台,在线实时查看车辆的位置及每个点的信号情况、车况信息,而这些数据也可以为工程部门对车况信息提供一些报表数据,这样就等于原来不能做的基于车辆的信号数据分析基本上都能做了,而且整个数据传输的问题包括数据处理的问题也得到了解决。
在 Hadoop 平台上搭建数据仓库
Hadoop 平台搭建之后,像 DMP、用户行为分析系统、智能推荐系统等等上汽通用都有尝试去做,同时,我们还将 Hadoop 变成了上汽通用的企业级平台。成为企业级平台后,下一步目标就是用 Hadoop 构建数据仓库了。
在调研了包括 IBM 等传统 IT 巨头在内的许多公司后,我们发现大家理解的大数据与数据湖非常像,它和数据仓库的关系更多的是按需提取,同时,数据仓库放不下的数据会回到 Hadoop 中。在这个概念中,数仓容量略小、成本较高,只存放高价值的数据;而 Hadoop 的定位更像是廉价存储,什么样的数据都可以放,但是开发成本很大,也存在一些查询性能、更新等缺陷和问题。
尽管如此,我们还是做了一个决定:将所有数据都统一加载到 Hadoop 上。
Hadoop + Kyligence 解决高并发难题
我们在 Hadoop 上构建了数仓和数据提示,数仓在传统的关系型数据库和 Hadoop 之间同步,将上汽通用在用的 Data Stage 和 Hadoop 打通了,打通后,在当时时间不长、数据量与业务量不大的情况下,Data Stage 操作传统的数据,Hadoop 里面的数据则用 Hive 和 Spark 做,Impala 做 BI 查询,整个搭配用起来效果还不错。
但时间一长问题就暴露出来了。首先是 Hadoop 和传统数仓之间的数据同步成本比较高,其次是 Impala 不支持高并发,因此并发量上去之后查询性会显著下降,再者由于涉及到非常多的技术组件,运维成本很高,为此我们又在这个架构上做了一些其它的尝试。
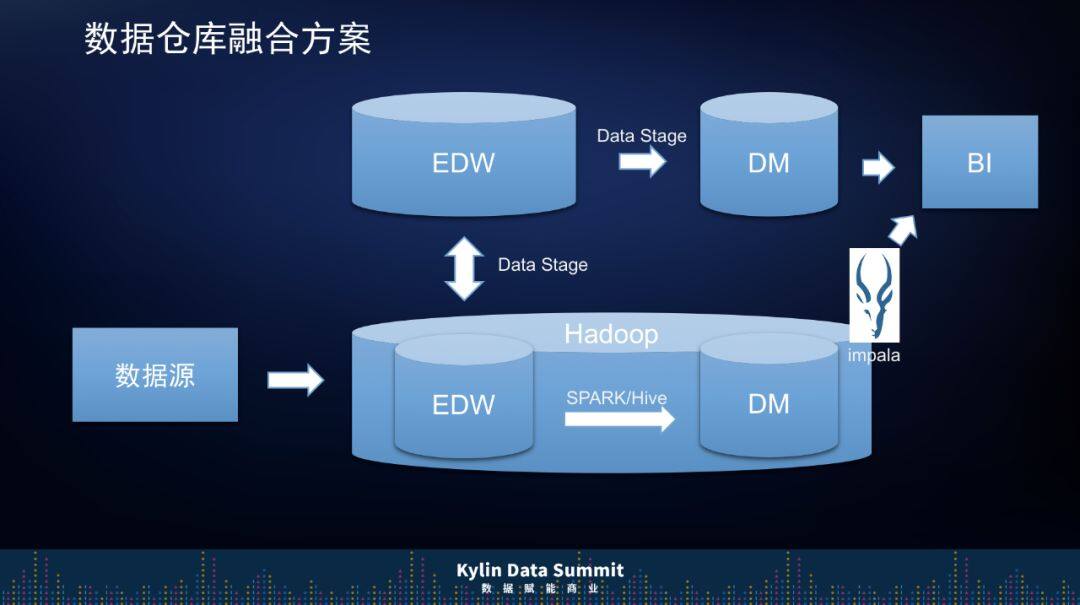
我们将原来的数仓和数据集市都整合到 Hadoop 之上,将 Hadoop 作为上汽通用未来的底层数据存储技术,同时,利用 Kyligence 的智能大数据分析平台做明细数据的聚合结果,为业务提供数据服务。这样做不仅解决了高并发问题和查询性能的问题,还摒弃了一些传统技术,降低了技术复杂度,比如说我们用 Spark/Hive 代替了 Data Stage,ETL 的作业数也下降了。
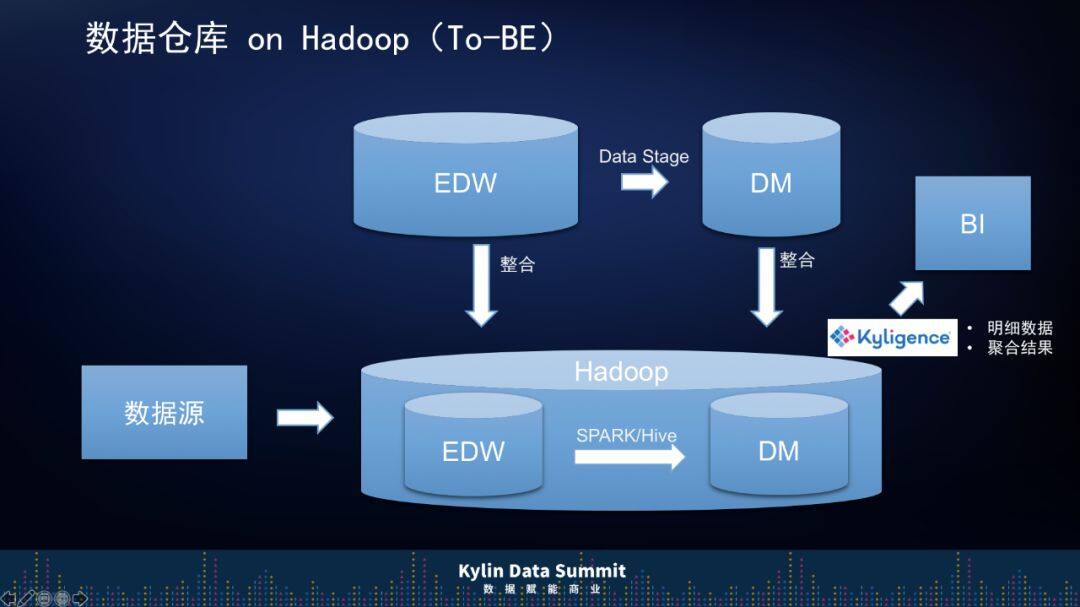
原来传统数仓做的很多事情是,数据集市不光有数据清洗的 ETL 工作,还有很多指标计算的 ETL 工作,都使用 Kyligence 的智能大数据分析平台的话,我们指标的计算就可以更多的以模型规范约定,不需要做很多指标计算的工作了,这样开发成本也会下降。
上汽通用大数据中台的搭建
经过几年的实践,我们对于企业数字化转型面临的挑战认识得越来越深刻,总结下来有三块:数据服务化、分析平民化、数据资产化。
所谓数据服务化是指数据即服务(DaaS)。今天,大家都在提业务中台、数据中台,其实通过强大的数据、算法去服务中台,满足各类应用差异化的数据应用需求是非常重要的。
分析平民化主要指自主分析的普及化。此前,数仓的分析流程都有需求提出、IT 开发、成果落地的一个过程,项目周期上长则半年、短则几周;现在,我们希望这种运营模式转化成 IT 能够更快速地支持业务,为用户提供一站式的数据探索、机器学习、AI 平台,实现数据选取、授权、访问及各类工具算法一条龙服务,打造自主分析的场景
数据资产化是指充分挖掘数据价值,让数据变成对业务有价值的资产,而不是数据垃圾。
围绕这些概念,我们想构建一个灵活的、自助的、高性能的数据中台,它与传统数仓最大的区别就在服务接口层面和数据资产层面,包括数据砂箱、自助分析的平台、数据中台存储等几块地方。
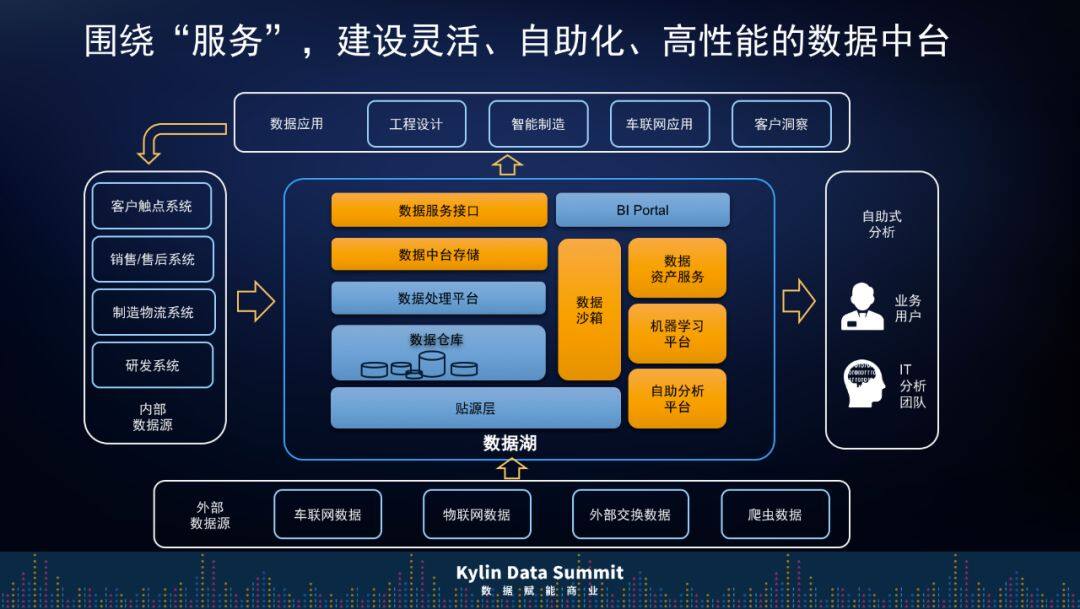
以前的数仓是面向少数用户解决特定问题的,现在要解决各种应用的问题,同时满足各种自助分析的需求,所以上汽通用做数据规划的时候有一个策略叫“Hyper Ingestion”。根据这个策略我们把所有相关数据统一放在数据湖的贴源层,原数据的信息也同步在数据资产平台上,这样可以缩短数据的访问过程,方便对数据定义进行快速分析。同时,我们也关注数据的接口问题,不光希望对外提供服务,也希望可以回收各种触点的数据,形成一个闭环。
上汽通用大数据中台整体架构
接下来我们从技术层面来看看我们的数据中台具体是怎么去搭建架构的。整个架构基本上分为 3 层:
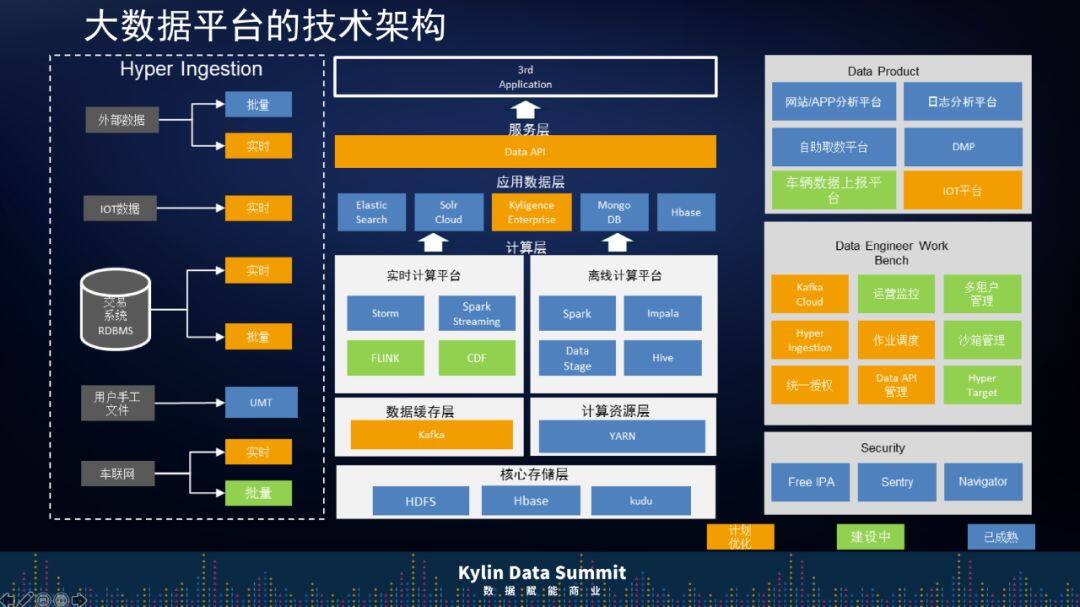
第一层是 Hyper Ingestion,它对接的是上汽通用能收集到的各类数据源:无论是外界的、批量的、实时的、IOT 的数据,还是关系型数据库的数据。在这之上有实时计算平台和离线计算平台,这个平台引入了 Kyligence Enterprise 满足多维 OLAP 查询及高并发访问的需求,在 Kyligence 之上还有一个上汽通用自己发开的统一的数据对外出口服务层 Data API,用以实现应用数据层的快速接入。
大数据平台赋能业务自助分析
以前,业务提出需求后,IT 要从从需求分析开始,到开发交付、分析结果展现,整个周期全程跟进,不管是对业务还是对 IT 而已,都意味着极大的人力和时间成本,但上汽通用更希望开发人员聚焦在业务的实现上,而不用关注底层的数据组件,因此自助分析成为大势所趋。
这点在上汽通用的大数据平台建好后得到了实现。有了大数据平台后,IT 扮演的角色是针对每种业务场景建沙箱,在业务人员提出需求后,灵活地将业务需要的数据放到沙箱中,业务只要有分析能力和分析人员,就可以通过沙箱快速得到分析结果,IT 在这个过程中提供的是工具、分析方法和数据的支持,业务灵活度包括交付的周期都有很大的变化。
物联网时代的大数据挑战
上汽通用从 2017 年开始规划物联网平台。此前,上汽通用绝大部分的分析需求是造车的质量分析、外部客户反馈的舆情数据分析,但随着工业互联网的发展,物联网的分析需求逐步产生并增多,例如制造业通过能耗分析知道什么时候可以把电源切断,什么时候启动降低能耗等,这就需要加装非常多的传感器去采集数据,帮助最后做分析。
实时分析:IOT 技术平台建设+Kyligence 实时构建
2018 年,上汽通用开始正式建设 IOT 技术平台,在这个平台的底层我们可以提供 SDK、MQTT 协议、HPPT 协议的接入,在前面会有一个网关可以在互联网上搜数据,对权限进行控制,同时还做了一些软路由,消息可以通过这些路由到后台的 Hbase,而 Hbase 会做一些报文的解析、设备的管理、Schema 的定义等。
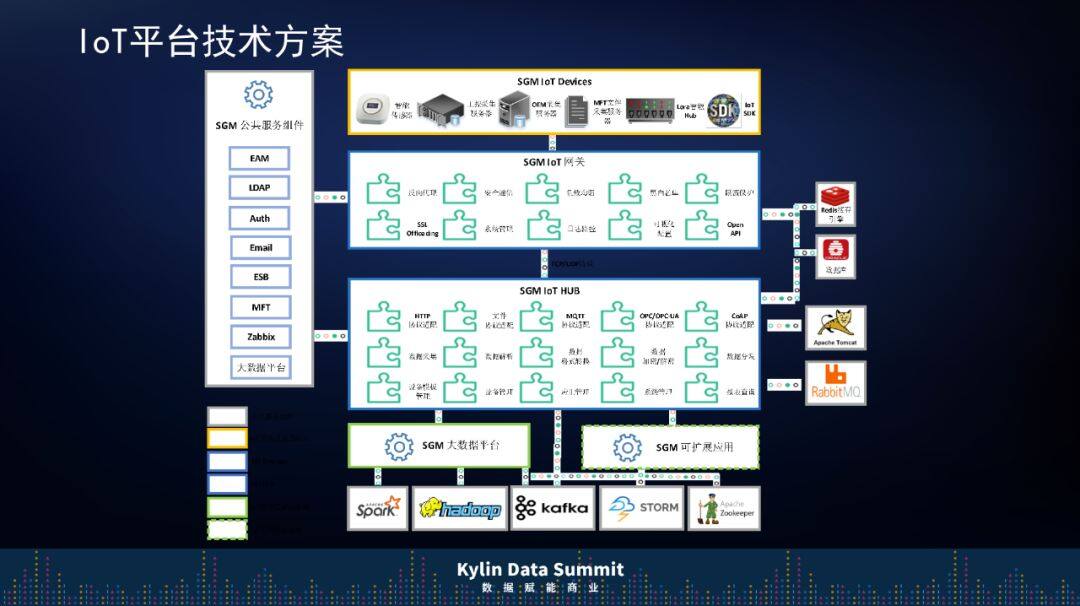
这里重点介绍一下 IOT 架构里面比较关键的 schema。接触过 Kafka 的都知道,最早使用 Kafka 的时候大家把它当成消息平台在用,在传输数据环节用 Kafka 存储我们收到的消息,不过 IOT 平台要考虑的点不是简简单单的数据留存问题,还有将 Kafka 作为一个实时的数据 HUB 通道,对各种应用提供选择。
所以整个 IOT 依赖于 Kafka 的消息是不是有一个很好的 schema 管理。我们研究了 Kafka 的架构后发现它包含了一套 schema 管理的组件工具,这套工具的好处是所有在外部接入的数据会在 Kafka 层面像数据库一样定义这套 schema,所有消费方会基于 schema 进行后端应用开发,上游如果任何的消息报文只要和 schema 不匹配就会被拒绝掉,所以后来我们就引进了这套组件。
整个 IOT 数据接入之后,我们也开始做一些应用。去年,上汽通用和 Kyligence 做了一些试点,我们将物联网的数据接到 Kafka 之后,通过 Kyligence 实时构建 Hadoop 的方法,做实时的报表,这件事情以前我们觉得很难,但现在方便很多了,只要订阅一下就可以快速地构建 Cube,目前时效性很不错。
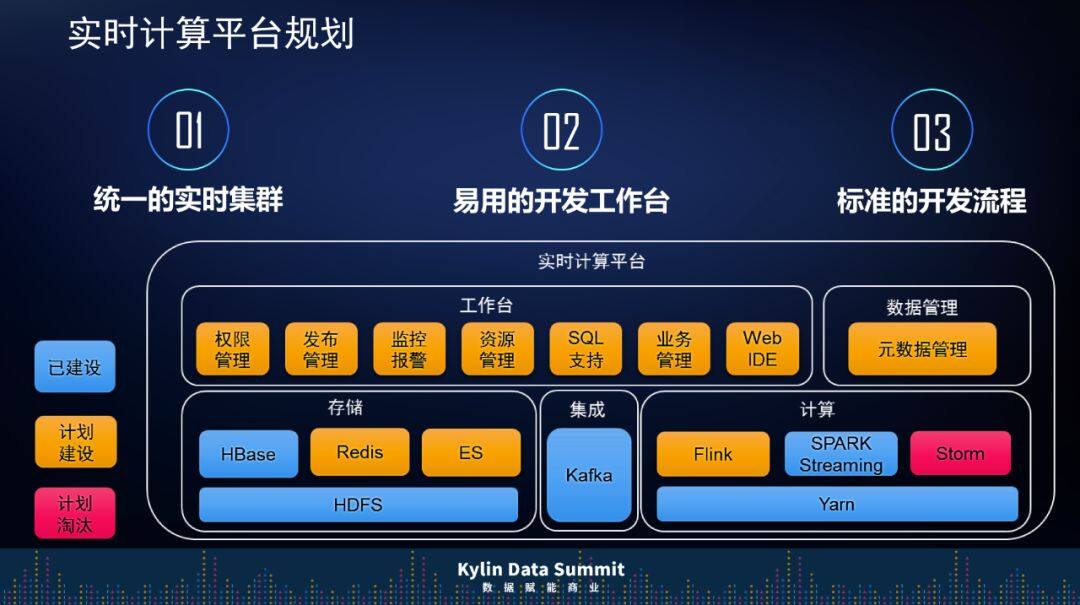
实时是未来新方向
当然,前面也提到了,由于上汽通用车联网业务的发展在不断加快,实时成为我们目前和未来都需要大力去做的事情。我们现在更多的想规划一个统一的实时集群,包括是不是也能够做一个工作台在上面做二次开发,提供标准流程。原来我们有一个 Storm 集群,当前的阶段是首先把 Storm 淘汰掉,因为不想组件太多,第二我们想引入 Flink,看能不能解决 Spark Streamig 的不足,在上层存储上我们会用 Redis 做一些快速的实时查询。当然我们会一步步来,先把一些监控报警、发布管理等这些东西做掉。
以上就是上汽通用在大数据平台建设的过程,在这个过程中我们走了不少弯路,但最终发现,要真正做好大数据平台,有几件事一定要做好:第一,把整个开发标准标准化;第二,在这个标准上可以通过配置产生的,要配置化;第三,能够服务自主化的,能够自己做的尽量让它自己做。
原文地址:
https://mp.weixin.qq.com/s/x3Z0b3sYQNw7_cwrSLRcuQ

暂无签名

中国卓越技术团队访谈录(2022 年第二季)
本迷你书精选了微软 Edge、蚂蚁可信原生、明源云、文因互联、Babylon.js 等技术团队在技术落地、团队建...











评论