
作为首个中国人主导贡献到 Apache 基金会的顶级项目,Apache Kylin 开源社区在国内外一直都保持着较高活力。在 2019 年 10 月,Apache Kylin 就同来自欧洲的大型跨境电商 OLX Group 在德国柏林一起举办过 Kylin Meetup,并受到众多好评。
在之前举办的 Apache Kylin 5 周年庆典中,OLX Group 荣获最佳应用奖,我们也再次邀请到高级数据工程师 Mateusz Jerzyk 作为代表分享了 Apache Kylin 在 OLX Group 全球数据基础架构中发挥的作用。
以下为会议实录翻译。
大家好,今天很开心可以与大家分享,我们是如何在 OLX Group 应用 Apache Kylin 的。
首先我会简单介绍 OLX Group,之后会向大家展示 Kylin 在我们的全球数据服务基础架构中的作用,最后会分享一些我们的用例。同时,我也会重点介绍我们在使用 Kylin,构建 Cube 时遇到的一些困难以及我们的收获。

OLX Group 简介

OLX Group 是全球互联网巨头 Prosus 公司的一部分。Prosus 是一个全球互联网集团,也是全球最大的技术投资者之一。Prosus 投资了腾讯,Delivery Hero,Udemy 等公司。

OLX Group 为购买,出售和交换产品和服务提供了领先的平台,在全球拥有 20 多个品牌。目前业务覆盖 30 多个国家/地区,在全球设有 35 个以上办事处。OLX 有 7500 多名员工,其中有上千名在产品与技术部门工作。每月都会有 3.5 亿人通过我们的平台购买,出售或交换商品或服务,平均每天用户访问平台会产生超过 40 亿个事件。
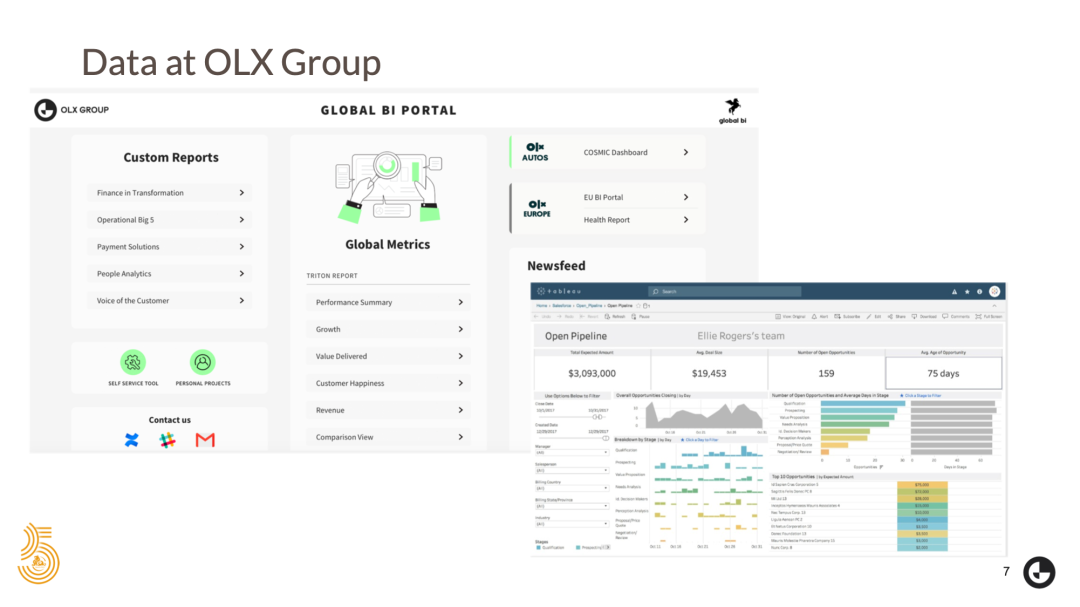
在 OLX Group,我们相信数据的力量。我们每天收集的数据都会影响我们的业务决策。我们会构建各种仪表板,机器学习模型等来辅助决策。
Kylin 在数据架构中的作用
接下来我来介绍一下 Kylin 在我们的数据基础架构中的作用。先介绍一下 OLX 的数据流。首先,我们会使用一些内部工具从产品数据库和设备中收集数据。所有数据都存储在数据湖中,作为我们的数据存储区。
在这里需要特别提及的是,我们已经建立了一个数据湖,但只有公司内部的少数人才能访问它,也是完全符合数据保护法案的。
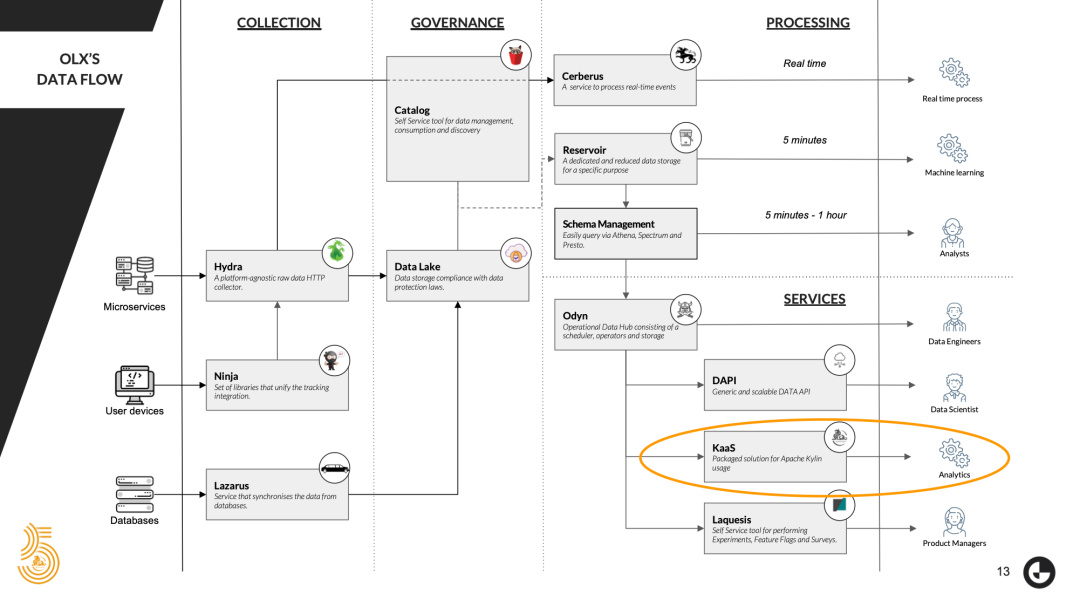
在收集和治理数据之后,OLX 中的每个团队都可以向专用的精简数据存储(称为存储库)请求一些数据。这样,我们就可以完全控制我们数据的使用。
最后,我们会使用 Odyn 的数据处理运营数据中心的功能。用户可以计划自己的 ETL 和/或其他工作负载,并将结果存储回存储库中。这些处理好的数据已准备好接入用作加速分析查询的加速层的 Apache Kylin。
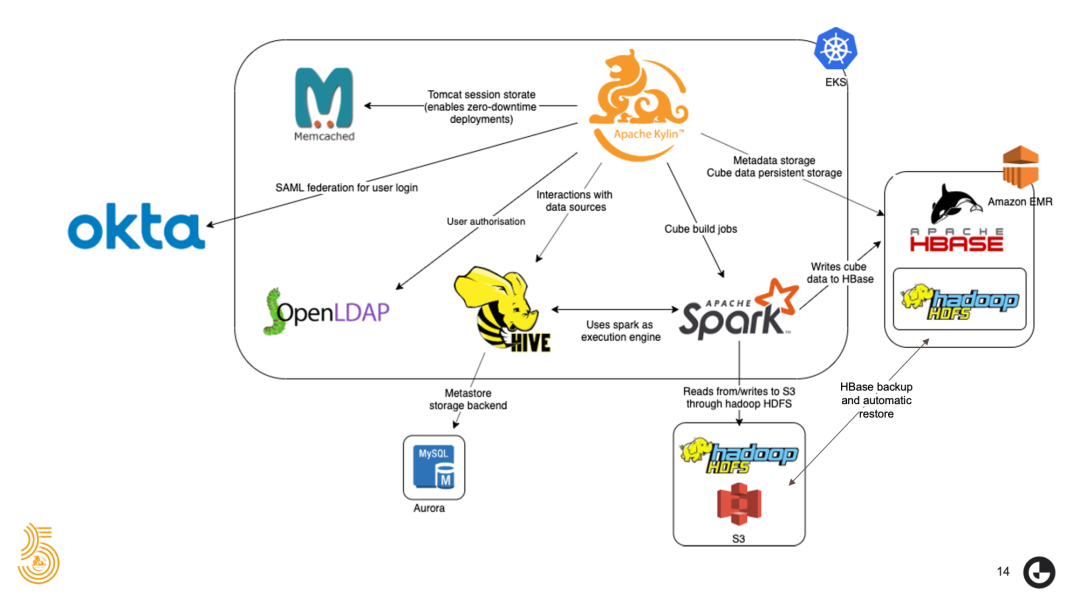
现在我们来关注 Kylin 在 OLX Group 数据架构中的作用。大家可以看到我们的 Apache Kylin 平台设置的流程。 我们使用 Kubernetes 来部署 Apache Kylin,Spark 和 Hive。 值得一提的是,为了将 Apache Hive 在 Kubernetes 上用起来,OLX Group 会将 Apache Spark 作为引擎的一部分。同时,我们使用 Amazon EMR 将 Amazon Kylin 的 HBase 集群与 Hadoop HDFS 托管在一起,并且将数据备份到 S3 中。该数据架构还拥有一个自动还原过程,当发现部署中发生崩溃时,该过程可以随时从 S3 恢复所有环境。OLX Group 将 OKTA 用作用户登录的 SAML 联邦身份认证,也把 OpenLDAP 用于用户授权。我们会将 Tomcat 会话存储在 Memcached 中,来将部署的停机时间降至零。该数据架构使用 Amazon Aurora 存储 Hive 元存储数据。
我们拥有和 OLX 其余数据基础架构完全集成的 Apache Kylin。分析师和非技术用户可以使用一致、全面监控、稳定且可扩展的跨团队环境,轻松顺畅地构建多维数据集并使用 Apache Kylin。我们还为 Apache Kylin 提供了量身定制的每日 HBase 备份和自动还原功能。
Kylin 实践分享
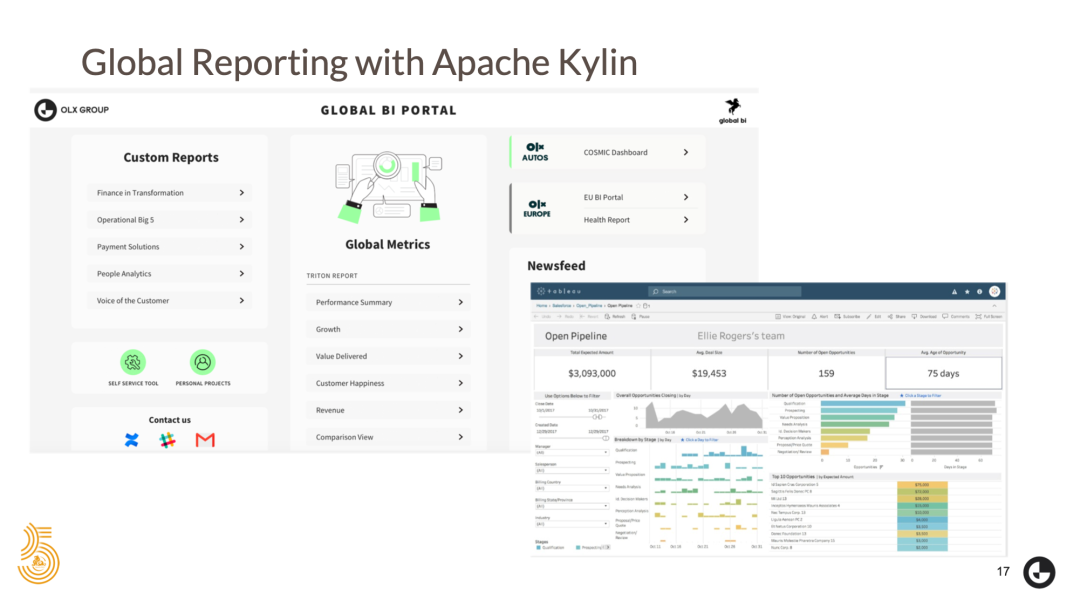
接下来我来分享一些案例和使用 Kylin 时遇到的一些困难。如前所述,我们在多个地方使用数据。 我们遇到的第一个困难就是为我们的全局报表构建一组仪表板。 我们的目标是使它们能够以亚秒级的延迟快速查询,而且还具有足够的灵活性以计算给定过滤条件下的非累加度量。同时也能与 Tableau(我们的主要可视化工具)配合使用。
另一个具体问题是建立自助服务分析平台。 与仪表板不同,在自助服务工具中,我们无法真正预测用户将如何准确使用度量和维度,这意味着我们不知道 Cube 应当提供的查询。因此,Cube 的目标是更加灵活。在这种情况下,我们可以接受边缘情况下较慢的响应时间。
最后,我想向大家分享一些数字。到 2020 年 11 月,我们在生产中使用了 39 个 Cube,支持 Tableau 用,目前有超过 300 位分析师在使用,执行了将近 40 万次分析查询,返回了超过 5,000 亿行的数据,并扫描了 500 TB 以上的数据。
作者介绍:
Mateusz Jerzyk,OLX Group 数据基础架构团队高级数据工程师。2019 年曾协助举办柏林站 Apache Kylin Meetup。
本文转载自公众号 ApacheKylin(ID:apachekylin)。
原文链接:




