
在本月举办的 Apache Kylin Meetup 中,我们邀请到了来自有赞科技的郑生俊来分享 Apache Kylin 在有赞的高性能运维实践:
面对客户增长分析等灵活业务场景,有赞是如何使用 Kylin 提供高质量服务的?
关于 Kylin 查询、构建和故障恢复等性能瓶颈,有赞又有哪些优化?
基于 K8s 弹性资源使用 Spark 构建 Cube 体验如何?
经过有赞测试的 Kylin 4 到底表现如何?性能相较 Kylin on HBase 有何突破?
以下为本次会议实录
本次分享主要包含以下四个部分:
有赞 OLAP 的介绍
Kylin 在有赞多模块应用场景
增强 Kylin 稳定性的经验分享
Kylin 4.0 在有赞的计划
有赞 OLAP 介绍
首先介绍一下有赞 OLAP 的发展历程:
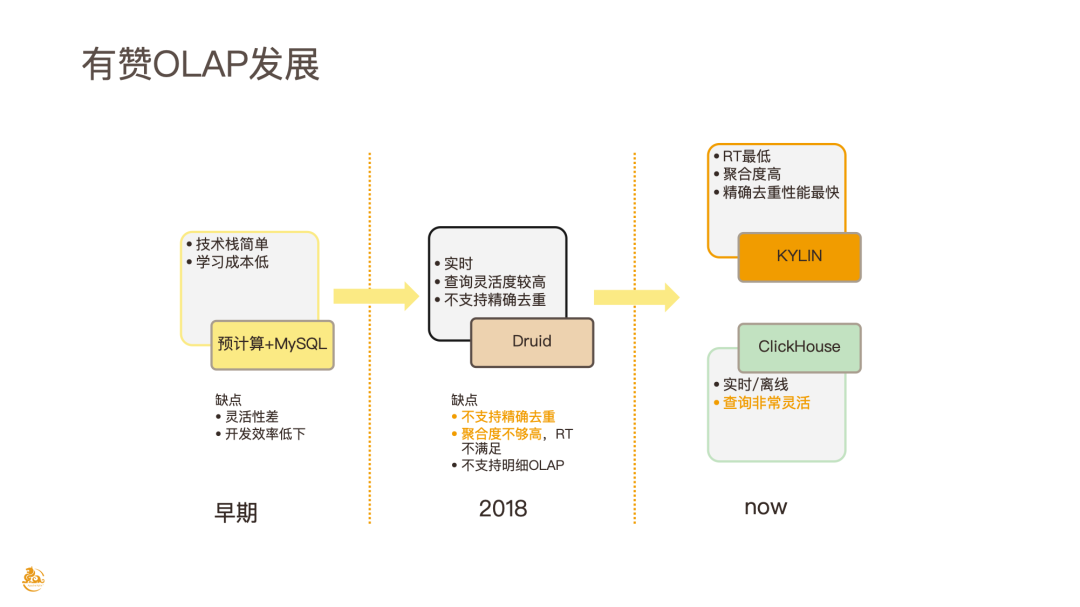
早期 OLAP 平台:预计算 + MySQL
此方式存在灵活性差、开发效率低下等问题。但有赞当时业务处于起步阶段,这种方式技术栈简单,学习成本也很低。
2018 年左右,有赞引进 Druid,但很快就无法满足有赞的业务需求
当时引进 Druid 是因为其支持实时报表的开发,并且查询灵活度比较高。但随着有赞业务越来越复杂,Druid 的缺点也日益明显,首先是不支持精确去重,其次是聚合度不高,还有实时数据的修复必须在 T+1,在 SaaS 场景下 RT(Response Time)和快速恢复无法满足,同时也不支持明细的 ROLAP。
2019 年至今,有赞基本完成了把 Druid 逐步往 Kylin 和 ClickHouse 上迁移的工作
选择 Kylin 的主要原因是:Kylin 的 RT 在所有预计算 OLAP 引擎里是最低的,同时聚合度也比较高,精确去重和非精确去重的性能最强。引入 ClickHouse 则主要是支持明细 OLAP 的查询。有赞目前和将来的 OLAP 就会包含 Kylin 和 ClickHouse 两个技术栈。
Kylin 在有赞的多模块应用场景
目前有赞 OLAP 的业务场景,几乎覆盖了有赞所有的业务板块。简单介绍一下有赞目前的业务情况:
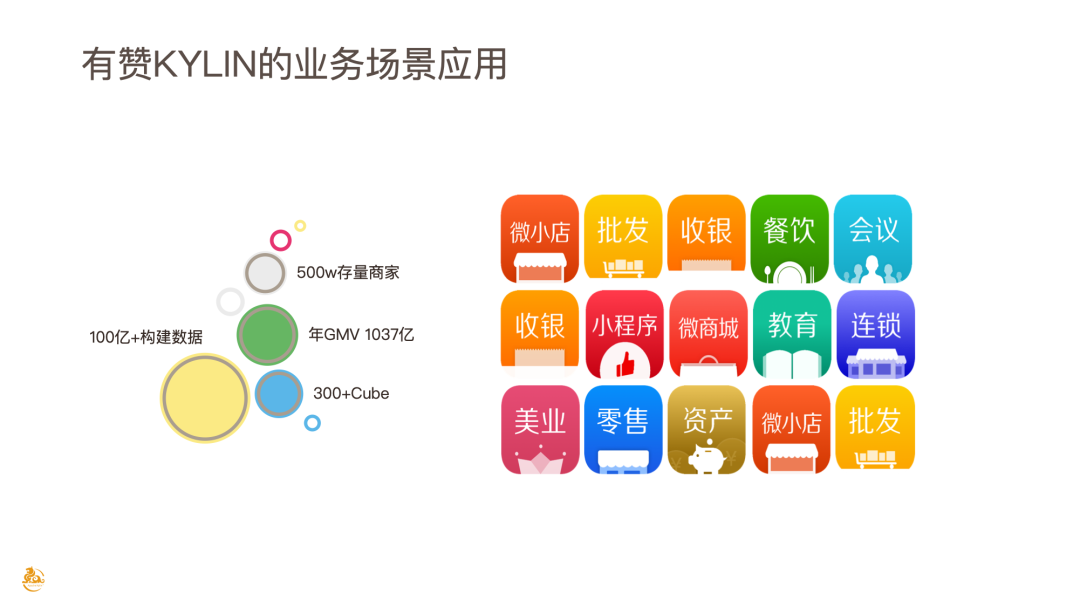
业务量:约 500 万+ 的存量商家;
2020 年 GMV 1037 亿;
在 Kylin 平台构建 300+ Cube;
每日涉入构建数据约 100 亿+(包含埋点、用户行为等数据,也包含交易、财务、库存管理等各种数据。)
有赞 Kylin 业务场景:商家后台报表
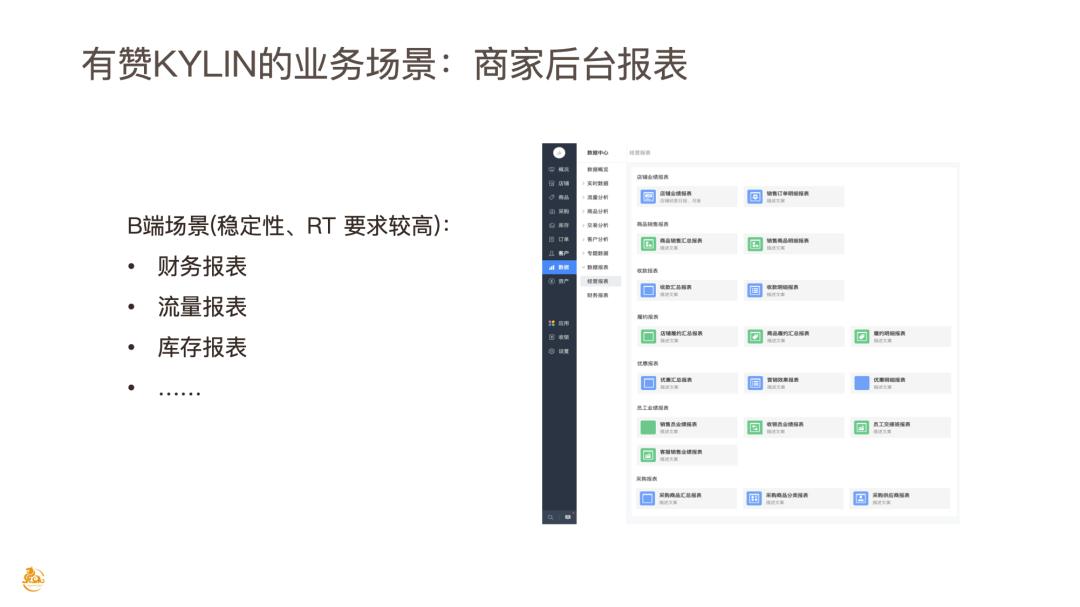
首先介绍 Kylin 在有赞的多模块应用场景。上图为有赞商家后台功能,右侧是有赞商家后台,包括财务报表、流量报表、库存报表、履约、供应链、优惠等营销相关的报表,涉及多个对外场景,是 SaaS 服务的一部分,每天有大量商家关注这些报表数据,因此对 RT 和稳定性的要求非常高的。
有赞 Kylin 业务场景:客户增长分析
以往大家会觉得 Kylin 只能做一些固定场景的,表结构固定、灵活度要求不高的一些业务场景,但其实并非如此。接下来介绍一个比较灵活的应用场景——客户增长分析。
下图左侧是有赞之前产品化的 PRD(Product Requirement Document)图,最上面的产品能支持查询某个部门下的客户的流失、新增情况,同时可以支持跨部门的上卷下钻。
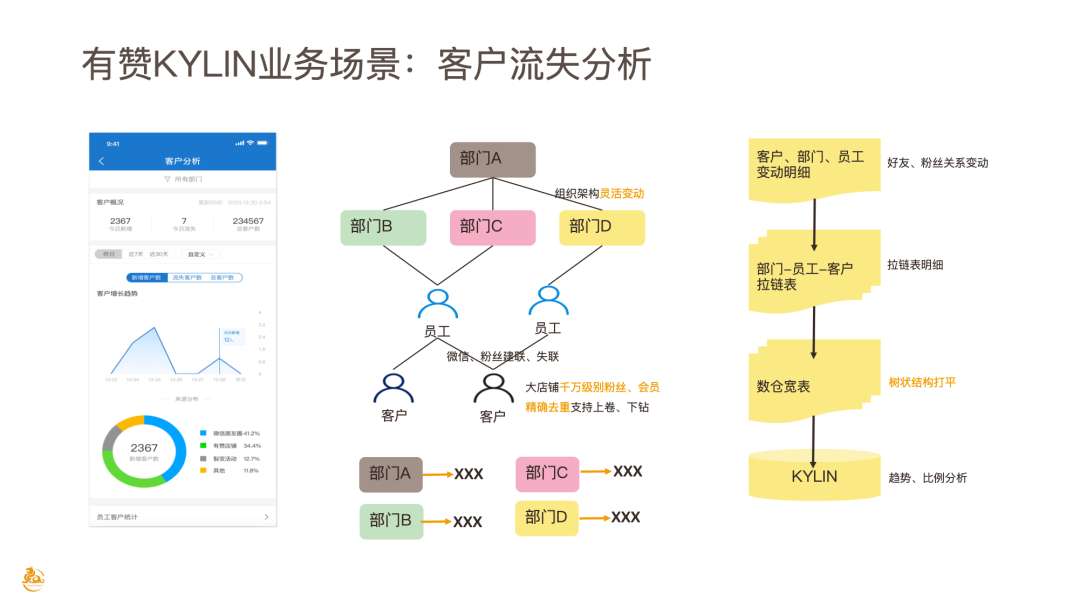
首先简单介绍背后的逻辑结构,存在两个有挑战的地方:
组织架构需要灵活可变动 ;在企业实际场景中,部门的层级和个数是灵活变动的,在这种情况下,如果使用通常的星型数据模型是无法解决这种灵活多变的需求。
对于千万级别粉丝的大店铺,有赞能够 支持秒级以内 RT 的精确去重、上卷和下钻 。
针对第一个问题,有赞选择把树状的部门结构打平,例如部门 A 的新增人数就等于部门 B + 部门 C + 部门 D 新增人数的总和,对此有赞只存一个部门字段,并不会把所有树状结构存到 Kylin 里,这样就能避免表结构要随着部门增加一直变化。
为了实现支持千万级别粉丝会员商家的精确去重、上卷和下钻,有赞采用了 Kylin Bitmap 的精确去重,具体的原理介绍这里不再展开。
整个数据开发的流程如下:首先是好友和粉丝关系的变动,当新增粉丝、微信好友添加,就判断这种事件是客户新增;当微信好友失联、粉丝取消关注,就判断为客户流失。我们将这些明细表存到数仓的拉链表里,通过拉链表来避免同一个用户在同一天时间内关系频繁变动造成的重复计算;然后将这个拉链表通过树状结构打平变成数仓宽表,通过 Kylin 进行预计算;最后在页面上就可以呈现趋势和比例的分析。
以上是有赞中一个比较简单但同时又有一定代表性的场景,我们通过一些 ETL 数据开发就能在 Kylin 里实现这样比较灵活的需求。
Kylin 在有赞的技术实践
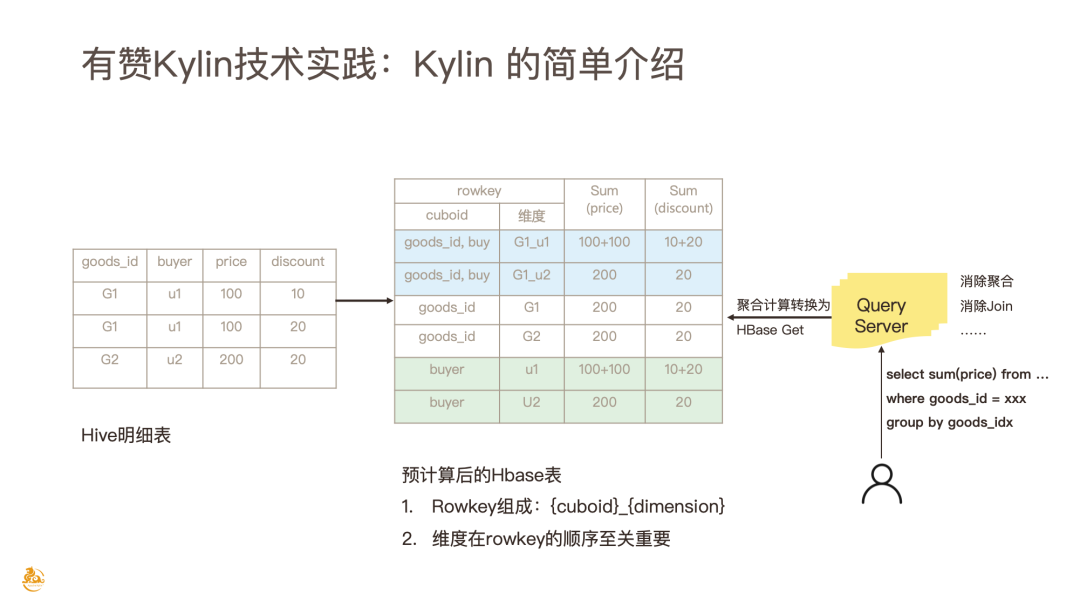
首先来简单介绍一下 Kylin,如上图所示,左侧是一张 Hive 的明细表,通过各种的维度组合,计算出每个维度组合不同度量的值,存在 HBase 里就变成一个经过预计算的,有一定膨胀度的长表了。此时如果有 Select from,Group by 等简单查询就会命中一个 Cuboid。在 Kylin 的 QueryServer 会进行 Calcite 语法规则的优化,包括消除聚合、消除 Join 等,最终转化成一个简单 HBase Get 的操作,通过预计算和优化可以将一个较为复杂的聚合查询转换成一个 HBase Get 查询,可以说 Kylin 有很好的 Response Time,在这里 Rowkey 的维度顺序和查询的重要性是相关的。
接下来介绍一下 Kylin 在有赞的技术实践。有赞内部有一个业务和健康监测机制。有赞的业务使用有以下几个原则:
大数据量查询需要使用分区条件;
固定和区分度大的过滤条件必须在 Rowkey 内顺序靠前;
查询尽量满足 HBase Rowkey 前缀匹配的规则,有赞是在电商行业,做的是 SaaS 场景,店铺 ID 是作为 Rowkey 的第一位,从而保证一个查询落在少量的 Region 内;
查询非必要避免使用精确去重,尽量使用近似去重;
通常要求业务方做一个 Cube 剪枝;
尽量减少 Lookup Snapshot Table 的使用,因为会占用大量的内存。
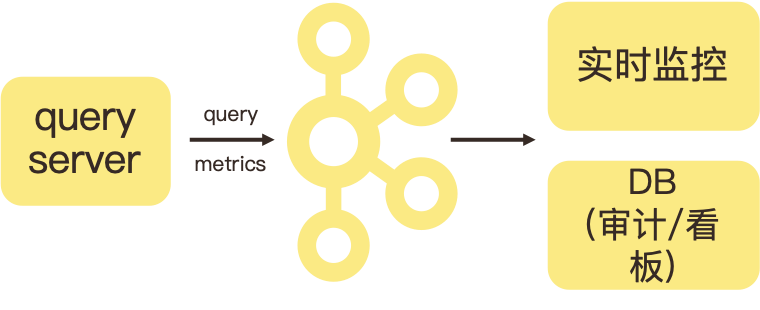
有赞的健康检测机制会在 Kylin QueryServer 端加一些 Query metrics 实时发送到 Kafka,之后会有一个任务去监控各种 metrics, DB 会有一些 Cube 信息,比如膨胀率等,再录到 DB 做一些审计和看板。
接下来介绍有赞遇到的一些性能的瓶颈点是如何优化的,主要从查询、构建和故障恢复等三个方面进行介绍。
查询:In 查询优化
背景: 有赞的微商城和零售是两套不同的业务体系,在技术栈统一的过程中,是需要将线上和线下的数据放到一个 Cube,导致单个 Cube 的数据量从原来的几十几百 G 上升到几百 T。
在这种场景下,需要查询上百甚至上千家子店铺,往往是用 in 作为查询条件,in 后会有几百个店铺 ID,再加上时间维度组合,就会在 Kylin 里转化成很多小区间的 HBase 的 Rowkey scan,这些小查询叫作 Fuzzykey scan。当这些小查询超过了一定量值,Kylin 会进行优化,把不连续的小区间查询转换化成一个大范围的 HBase scan,但在数据量膨胀很多的情况下,可能会导致原本需要扫描的数据量乘以几千倍,甚至几万倍。
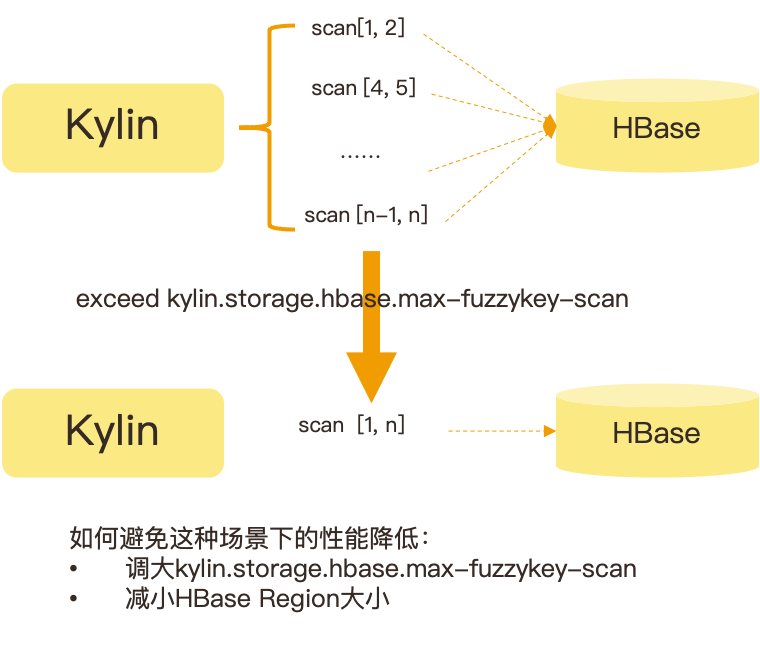
为了避免这种查询场景下性能的损耗,有赞通过以下方式来解决:
其一,调大 Max 跟 Fuzzykey scan 之间的阈值,因为这个阈值默认是 200,当查询指定了几十家门店,再加上指定几天的时间,阈值就很容易就超过 200;
其二,减小 HBase Region 大小。
通过以上两种优化方式,有赞做到了在 Cube 数据量增加几百倍的情况下,in 查询的 RT 依旧能得到保证。
查询:使用 LRU Cache 缓存维度字典
有赞遇到的第二个查询 RT 不稳定的原因是在维度字典。Kylin 维度字典包括 Kylin 2 和 Kylin 3 的维度字典,是使用 Guava Loading Cache 去实现,Guava 的 Loading Cache 默认是一个 LRU 的 Cache,但存在一个问题,就是目前的 Cache 是基于 Soft Reference,实际上很容易被 GC(Garbage Collection)去清理的,一旦被 GC 清理,字典就需要从 HBase 去加载,当字典超过 10M,会从 HDFS 去加载,这样就导致这个查询的 RT 是不稳定的。
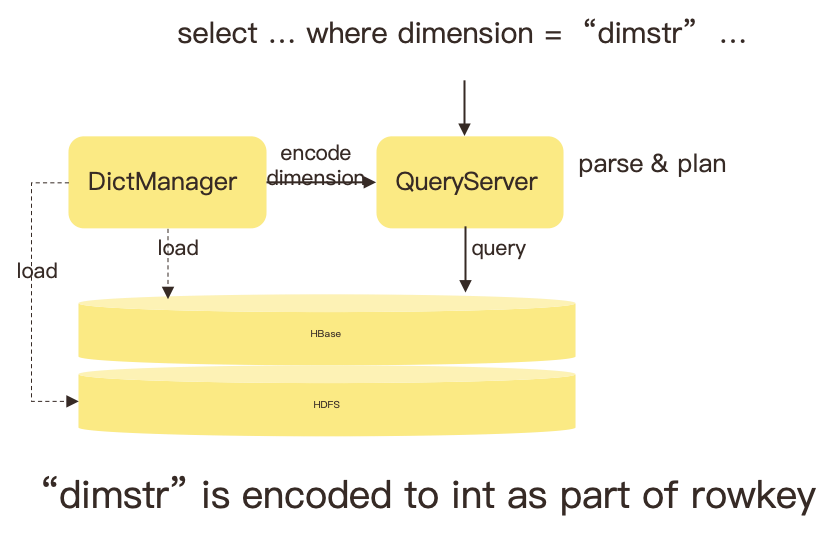
针对以上问题,有赞进行了优化,从而支持字典 Cache 缓存的 stress,例如 soft、wake 和 stress 等,目的是让字典不会被 GC 清理,技术团队可以通过控制缓存数量来实现内存控制。
接下来第二部分,会介绍有赞在 Kylin 构建方面的实践与优化。
构建:EncodeBaseCuboid 优化
背景: Kylin 在 EncodeBaseCuboid 的过程中,同时也是 Spark 构建 Cuboid 数据的第一步,会逐行逐列进行字典编码,将字典编码的维度、精确去重字段转换为整型。当 Cube 中有多个高基数、需要字典编码的列存在时,效率会变得低下,因为构建一行的过程中会涉及到不同列字典换进换出,降低构建的效率。
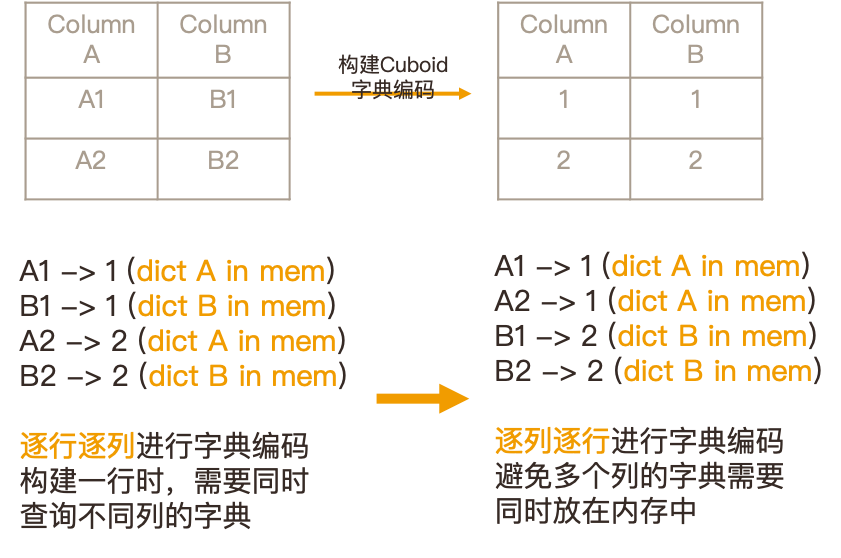
如上图所示,有赞在构建过程做了一些优化,将逐行逐列的编码改为逐列逐行的编码,会先构建 Column A1,对 A 列进行编码,把 A1 编码成 1,A2 编码成 2,从而避免在构建一行的时候,内存中的字典需要在不停的列之间进行切换,从而提升构建效率。在有赞一个多个基数较大的维度字典、全局字典的场景中,经过优化,构建时间从原本的一个多小时提速到仅需 20 分钟。
关于细节的实现可以关注:
https://issues.apache.org/jira/browse/KYLIN-4941
构建:重刷数据时限流策略
背景: 有赞的主要的离线计算集群规模在数万 CPU 左右,计算量大、计算资源充足;线上查询基于独立集群,规模较小,这就导致构建与查询集群资源不对等,刷数需要限流避免对线上集群产生影响。
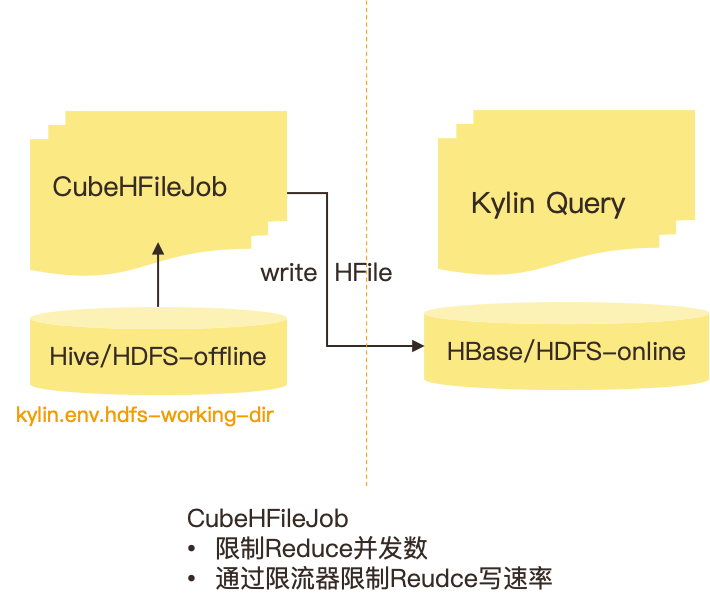
有赞针对刷数任务,扩展了一个基于写 HFile 的限流策略。这个限流策略可以配置一个 Job 在生成 HFlile 的过程中,能够使用的流量。大致的实现思路是:在 Kylin 构建中,写 HFile 的 Reduce Tasks 数目在上几个阶段根据 Segment Statistics 就已经确定了;我们通过这个流量除以 Reduce 的并发数,获取到每一个 Reduce 允许的流量限制,再通过限流器在 Reduce 中的写入过程进行限速。通过以上优化,我们能够做到在刷数据的时候,保持前期较快的构建速度,同时在最终写 HFile 的时候,又有一定程度的限速,保证在线查询的稳定性。
接下来介绍一下有赞故障恢复相关的优化。
故障恢复:基于 K8s 弹性资源构建 Cube
背景: 之前故障恢复需要重刷数据,往往耗费一、两个小时。在商家较多的情况下,很容易就接收到大量商家的投诉,给有赞的服务质量带来许多挑战。
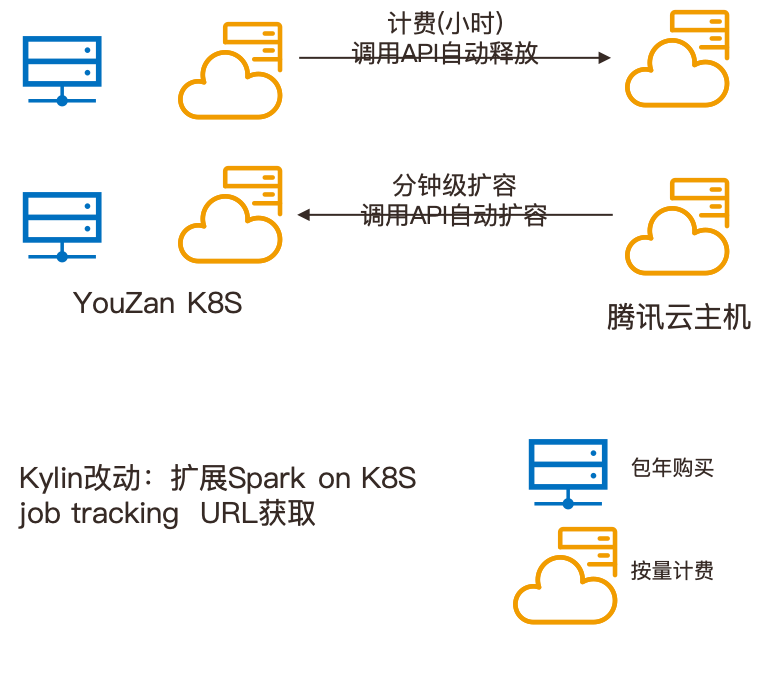
Kylin 构建是支持 Spark 的,至于是 Spark on YARN 还是 Spark on K8s 对 Kylin 是透明的,唯一有差别是 Job Tracking URL 的获取需要定制化。出于资源的弹性伸缩和混部诉求,有赞基于 Spark on K8s 来构建 Cube,关于云主机的弹性伸缩和混部,有兴趣的读者可以参考有赞这篇技术文章: Spark on K8s 在有赞的实践
除了基于 K8s 弹性资源构建 Cube,有赞还遇到了一些比较有挑战的故障恢复的场景。
故障恢复:元数据修复避免重新构建
背景: 在 Cube Build 过程中或者 Merge 过程中,Job 分为多个阶段。会存在某些异常场景导致一个构建任务被多个 Job 实例获取,最终导致元数据错误,无法查询到数据。对于合并跨度大的 Segment,重刷数据耗时长。
如何快速修复此故障?经过有赞团队的研究和发现,查询相关的元数据基本包含 4 个元数据信息:
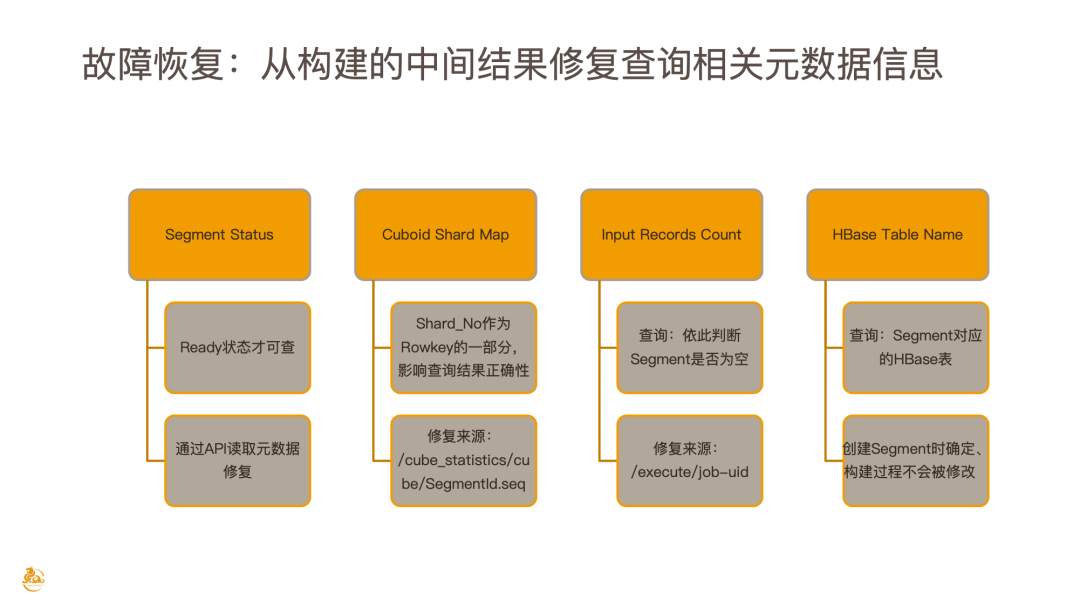
首先是 Segment Status,比较容易修复,通过 API 把 Segment 的 Status 置为 Ready 就完成了;
第二部分是 Cuboid Shard Map,这也是比较重要的一部分,当维度里有空的 Shardby,这个 Shardby Number 就会作为 Rowkey 的一部分,如果 Cuboid Shardby Number 不正确,就会影响查询的准确性。比较幸运的是 Kylin 在构建的过程中会把一些 Cube statistics 信息存到构建的临时文件,读取这个临时文件去更新 Cuboid Shard Map,就可以保证元数据是准确的。
第三部分是 Input Records Count,这个实际上是 KylinQureyServer 用来判断 Segment 是否为空的依据,只要这个 Input Records Count 不为 0,就能被查询到,其修复来源也是存储在 HDFS Job 的临时构建目录里。
最后一部分是 HBase Segment 对应的 HBase Table Name,此信息在 Segment 创建时就已确定,创建过程中任何一个步骤都不会再去修改 HBase 对应的 Storage Identifier,所以这部分元数据是不需要去修复的。
通过以上这几个修复步骤,即使在元数据错乱更新的情况下,也无需重算元数据,就能快速恢复。其实目前 Kylin 社区也有一些用户遇到同样类型的元数据更新混乱的场景,但是总体概率不高,许多都和自身的硬件以及机器情况有关。如果公司的基础运维能力和监控体系足够完善,其实是完全可以避免的。
接下来简单分享一些有赞踩过的坑,其中比较有代表性的就是全局字典的构建错误。
踩坑:全局字典构建错误
背景: 由于全局字典乱序,Merge Segment 时,合并字典出错。原因在于为了避免字典树某个节点过大,会对节点进行 Split。
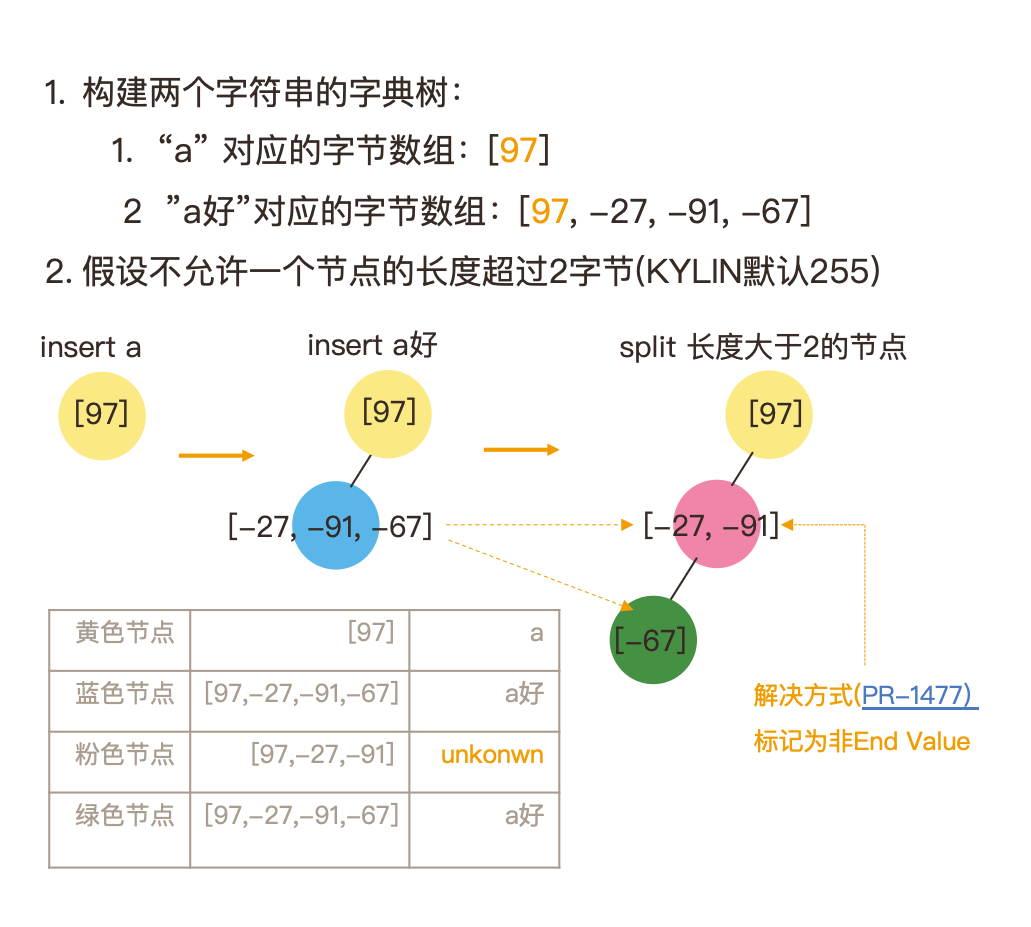
根本原因如下:
Split 的两个节点产生两个字典值
Split 超过一个字节的 UTF-8 的字符串会导致 Split 后的字串无序,归并排序失败
详情请访问:
https://issues.apache.org/jira/browse/KYLIN-4810
Kylin 4.0 在有赞的计划
最后分享 Kylin 4.0 在有赞的计划,目前主要分为五个阶段:
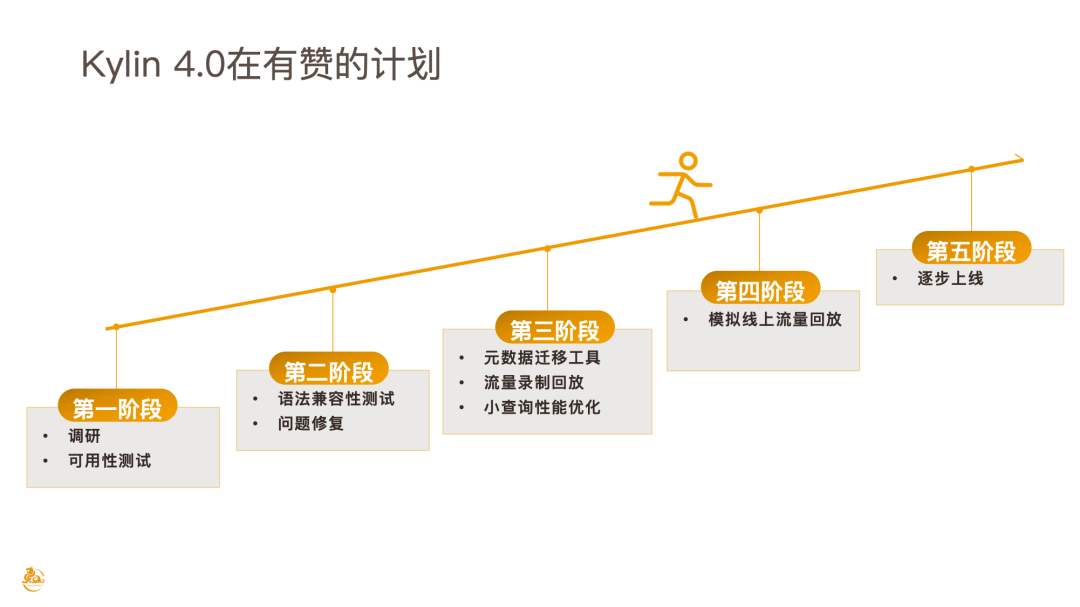
第一阶段就是 原理调研和可用性测试 ,这个阶段历时较久,首先有赞调研了 Kylin 4 的构建和查询原理,当然 Kylin 4 是基于 Spark,有一定的学习成本;
第二阶段是 语法兼容性测试 。有赞基于标准的压测,基于 YCSB 去进行修改,来支持在 Kylin 上去跑,这个过程中,也发现了一些语法兼容性问题和其他 BUG,例如 PreparedStatement 在新版本不支持,还有分页查询场景常用到的 Limit/Offset 也不支持等,这些问题我们陆续修复了;第二阶段完成之后,我们团队认为 Kylin 4 基本上是一个完备的,可用的,具备灰度上生产资格的版本。
第三阶段开始着手去 迁移元数据 ,准备把目前机器上的元数据迁移到 Kylin 4,由于是新版本,我们做了一些比较保守的方案,把线上所有的 Kylin 2 、Kylin 3 的流量录制下来,再回放到 Kylin 4。在这个过程中,我们也发现小查询的性能实际上是不够优化的,和 Kylin 2、Kylin 3 还是有一定差距的,有赞团队也花费了很多时间和精力去优化小查询, 目前基本做到了和 Kylin on HBase 相当的性能 ,不过还存在可优化的空间。如果优化完成,有赞团队会再去分享如何让 Kylin 4 的性能接近 Kylin on HBase,此处说的小查询是指命中 HBase Cuboid 这种类型的小/点查询。
第四阶段有赞会把线上所有的 300+ Cube 构建到新的集群,去把线上的流量做一个 双跑 的方式去回放到一个新的集群,
第五个阶段就是 逐步的去迁流量 ,逐步的去下线旧版本。
在这里分享一下,为什么有赞目前会选择 Kylin 4 呢?
其实有一个很重要的原因,有赞的大商家越来越多,场景也越来越复杂,对大查询的性能 Kylin on HBase 已经无法满足,并且 Kylin 4 在构建这部分也换了一个算法,性能相较旧版本也有很大的提升,选择使用 Kylin 4 其实就是有赞现阶段业务发展的需要。
作者介绍:
郑生俊,有赞数据中台-数据基础平台负责人,主要负责有赞离线计算、实时计算、OLAP 和在线存储。Kylin 社区活跃贡献者,推动了 Kylin 4.0 在有赞的实践与优化。
本文转载自公众号 ApacheKylin(ID:apachekylin)。
原文链接:




