

人人都想做开源,但你真的懂开源吗?
近年来,开源迎来了高光时刻。根据 GitHub Octoverse 报告中的数据显示:2018 年 Github 注册的新用户数量是前六年的总和,且在 Github 上的代码仓库已达到 1 亿个。微软 75 亿美元收购 GitHub,IBM 334 亿美元收购红帽…这都在彰显着开源的价值,正如 John Vrionis 之前的预言:“开源软件正在吞噬着整个世界”。
之前,InfoQ 统计了 7 家国内一线互联网公司在 GitHub 上的 50 多个账号和 2800 多个项目,根据统计结果显示:阿里的总项目数为 1243,百度的总项目数为 746,华为的总项目数为 247,360 的总项目数为 221,腾讯的总项目数为 131,美团的总项目数为 131,小米的总项目数为 113。
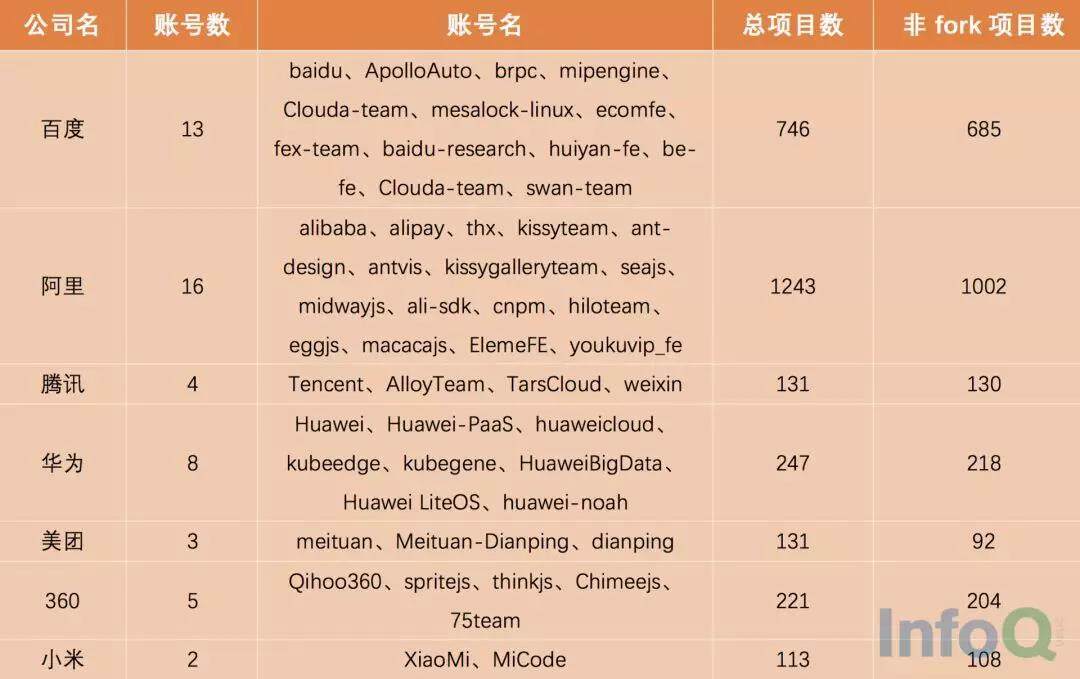
从上图中我们可以看到国内企业和开发者对于开源热情高涨,但是他们真的懂开源吗?真的能够维护好一个开源项目吗?答案是不确定的。为了帮助开发者更好的维护一个开源项目,我采访了 Kyligence 联合创始人兼 CEO 韩卿,他曾带领团队创建了首个由国人主导的 Apache 顶级开源项目——Apache Kylin。
Apache Kylin 是一个开源的大数据 OLAP 引擎,2014 年正式开源,2015 年 11 月毕业成为 Apache 软件基金会 Top-Level 项目,能够在万亿级数据上提供亚秒级的查询响应。目前被全球数千家企业和组织机构用于大数据关键分析应用,其中包括 eBay、思科、沃尔玛、百度、小米、美团、滴滴等公司。2015 年、2016 年,Apache Kylin 获 InfoWord 评选的 Bossie Awards 之“年度最佳开源大数据工具奖”。
Kylin:从“不可能”中诞生的项目
作为第一批互联网公司,eBay 是最早遇到大数据分析效率的公司之一。2013 年,eBay 的大数据分析平台主要使用 Teradata,但难以匹配业务需求,比较费时,一次分析查询可能就需要几分钟甚至十几分钟。每次跑个报表,至少需要一杯咖啡的时间。
除此之外,eBay 当时的大数据分析平台还存在以下问题:
每年的运维费用至少要几百万美金;
分析师团队上千人,每位分析师要搭配多位工程师;
开发周期按月计算,必须以开发项目的方式管理;
分析需求必须从上游数据采集开始,经过数据清洗、数据聚合整理、入分析库,最后对接 BI 工具才能使用;
如果总结一下当时面临的痛点就是“二低一高”:数据准备效率低下、在线分析效率低下、运维费用高昂。为了解决这些痛点,eBay 中国研发中心启动了代号为“杨子”的一系列大数据平台技术创新项目。
在项目预研阶段,eBay 团队重新调研了大部分的商用和开源大数据技术,包括 Teradata、MicroStrategy、SISENSE、Exadata、Impala、Stinger、Presto 等等。当时,eBay 想要实现两个目标,分别是在 PB 级规模数据集上进行亚秒级大数据分析和运行成本低廉,但遗憾的是,已存在的技术方案都不能同时满足这两个目标。
当时,Kylin 创始团队提出了“在 Hadoop 平台上使用 Cube 技术(MOLAP)加速查询”的想法,而这在很多技术专家看来是根本“不可能”的方式,但是 Kylin 团队经过仔细研究验证,认为这是所有不可能中最有可能的方案。2013 年 9 月,Kylin 项目组正式成立。
Kylin:开源快速却不仓促
2014 年 9 月底,经过一年时间的研发,Kylin 项目终于在 eBay 内部生产环境中上线了。同一天,Kylin 项目在 GitHub 上开源。
在生产系统应用的第一天就开源该项目,这种速度在开源界也很少见。为什么会这么早就开源?Kylin 团队表示有两个原因:
回馈开源是公司当时的战略,Kylin 从研发之初,就获得公司总部“open source from day one”的指导,因此从立项开始,就一直为开源做着准备。当时的目标是随时可以开源。
其次,从开源项目本身来说,越早开源就越有先发优势,如果不开源,那么等到其它项目开源出来之后就难具备优势了。例如,由雅虎研发并开源的下一代消息系统 Pulsar,虽然业界都认为它会是 Kafka 的强势竞争对手,但是由于出现的时间点比较晚,失去了非常多的优势。
何时开源才合适
相信通过上面 Kylin 的例子,大家都已经明白了项目开源的时间节点很重要,“快速”虽然能让我们有先发优势,但如果没有准备好,只是一味图快,那么开源的项目可能也不会得到很好的发展。通常来说,一个项目在开源之前最好已经有一些成熟案例做支撑,有客户做背书。
如果大家对于项目的开源时间节点还很模糊,那么可以参照以下的 Check List:
产品设计是否符合通用需求;
技术架构是否合理且易于扩展;
产品配套的使用及开发文档是否完善;
产品质量是否过关;
相关市场材料是否完善;
是否已有成功的应用案例。
开源协议的选择
目前业界中有很多现成的不同类型的开源协议,例如 Apache License、BSD License、GPL License 等,大家可以根据自己的需求来选择。
Kylin 是一款分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力,由于大多数 Hadoop 软件都是以 Apache License v2 发行,所以 Kylin 的开源协议就自然选择了 Apache License v2。
那么,其它开源项目又该如何选择开源协议呢?其中最重要的一点就是要根据你对该项目在商业方面的规划做选择。例如,该项目是包装一下就可以买卖,还是允许用户使用但不能包装之后二次销售,再或是可以二次销售但是要署名作者。
之前,由于商业利益的冲突发生了几起修改开源协议的事件,虽说不会影响普通用户的使用,但是对开源项目本身却是一种伤害。所以,建议大家在开源协议的选择上要慎重一点。
申请专利是必选项
知识产权保护在国内往往会被人忽略掉,尤其是作为开源项目,很多人会觉得项目捐赠出去之后,相应的专利也会随之捐赠,专利申请就是鸡肋。
其实不然,事实上专利申请并不是一个攻击武器而是一个防御武器,即使开源项目在申请专利之后捐赠给了开源基金会,专利也会成为这个项目的防护罩。如果有人开发了一个同类型的项目且申请了专利,并以此来攻击你,那么你的项目、业务等都会被带入到不应该产生的麻烦中。所以,无论是对个人还是对公司,申请专利都会是一个很好的保护,同时也因为专利的存在,团队才能更好的维护和发展开源项目。
Kylin:初入 Apache,困难重重
2014 年,在开源一个多月之后,Kylin 再次迈出了发展的一大步:快速进入 Apache 孵化器。这对 Kylin 和 Apache 基金会来说都是一件好事。Apache 基金会当然希望有更多好的开源项目贡献进来,扩大影响力,扩充其生态。同时对于 Kylin 来说,Apache 基金会在开源项目更权威,对项目未来发展更好。

进入 Apache 基金会之后,Kylin 做了哪些事情?
由于 Kylin 是第一个完全由中国人贡献给 Apache 基金会的项目,并没有可借鉴的经验,所以进入基金会之后,Kylin 团队主要是在学习 Apache 的整套规则规范以及相应的各种条件。
Kylin 项目团队做的更多的是解决使用上的障碍,而不是研发。例如,开源项目可能在内部环境中使用得很好,但是用户下载下来,由于环境不一样会出现无法使用的情况。
为了解决使用障碍,2014 年元旦左右,Kylin 项目团队做了一个决定:春节前不做任何新功 能,只完成一个任务,即用户从网站上把 Kylin 下载下来,只需一行命令就可以运行起来。
由于中国网络环境的特殊性,很多依赖包可能无法下载下来。之前 Kylin 团队没有意识到这个问题,所以花了很多时间来查找和解决这个问题。
完善整个产品和技术,和社区、早期用户做更多的交流和完善,解决大家共性的问题。
如何选择开源基金会?
Kylin 选择 Apache 基金会很重要的一个原因是权威和专业,该项目是为了解决大数据问题,是大数据生态中的一员,而整个大数据生态基本都在 Apache 基金会,所以无论是为了大数据生态还是为了更加顺畅的对接其它技术,Apache 基金会都是 Kylin 毫无疑问的选择。
那么,开源项目该如何选择开源基金会呢?首先,一定要选择一些知名度更高、公认度更好的社区,因为这些社区通常会拥有更高的人气和活跃度、拥有更多的社区及用户信任,对项目的发展和成长更加有利。其实,不同的领域都有对应的基金会,比如 Linux 基金会、OpenStack 基金会、Cloud Native 基金会等等,大家可以根据项目的类型来进行选择。
其次,开源基金会的运作方式和开源协议也是很重要的考虑事项,一定要选择和项目开源初衷比较匹配的软件基金会。
基金会开源项目治理模式 VS 开源项目团队维护模式
如果开源项目是由项目团队来维护的话,那么大概率是以公司、团队或者产品经理的个人偏好来推进项目的管理,推进决策的方式。而如果是开源基金会来治理的话,不同的基金会会有各自的治理模式。
以 Apache 基金会为例,Apache 基金会强调透明性、公开讨论及决策,不允许私下决策。基金会鼓励大家通过邮件列表的方式进行集体决策,讨论决策的过程必须能够在邮件列表中透明的公开出来;Apache 投票机制可以进一步规范项目的治理;同时,基金会层面也会有“牧羊人”模式来整体治理相关项目。
项目初期如何扩大知名度,招募贡献者
相信项目初期如何扩大知名度、招募贡献者是每个开源团队都很头疼的事情,韩卿表示可以使用以下两种方式:
第一是要做营销,酒香也怕巷子深,对于开源项目来说最重要的就是加入生态。以 Kylin 为例,它属于大数据生态,那就可以在整个生态中主动去“宣传”,普及 Kylin 是怎样的一个技术,可以解决什么样的问题,使得更多用户认可并能够及时去试验,收集反馈。同时,也可以让早期用户帮忙宣传,使用案例对于大部分技术来说都是非常重要的内容。
第二是精准地找到目标用户。以 Kylin 为例,eBay 是一家互联网公司,它遇到的问题其它互联网公司也可能会遇到。所以,项目团队可以通过社区支持的方式让其它公司一起用起来,积累早期用户和案例,寻找合作创新的场景。只要有了用户,开发者和贡献者基本就不用愁了。
如何撰写开源项目介绍文档
项目介绍文档是外界认识项目的第一道门,所以在撰写方面需要多花一些心思。以 Kylin 为例,首先要有安装文档、Qiuck guide 等基础文档。作为安装文档,一定要尽可能详细,便于用户安装。接下来是快速入门,一个详尽明了的 Sample demo 胜过千言万语。之后随着项目的不断发展,可以做一些分主题的介绍,例如功能介绍、案例介绍等一些细节性文档,方便用户深入了解项目的细节。
其实,写文档最重要的就是搞清楚读者是谁。一般来说,开源读者有两类,一类是用户,另一类是开发者,针对这两类群体写的文档会有所不同。针对用户,要更偏重于该产品的使用、价值和对企业未来的影响;而针对开发者,要清楚的介绍技术架构、技术细节、技术先进性,并以此达到吸引开发者共同开发的目的。
Kylin:顶级项目毕业,漫漫维护之路
2014 年 11 月,Kylin 进入了 Apache 软件基金会孵化,2015 年 11 月作为 Apache 顶级项目毕业,那么在这一年的时间里,Kylin 到底完成了哪些事情?
产品的 Release:进入 Apache 之后,Kylin 发布的最早版本是 Release v0.7,在经历了四、五个版本之后,2015 年 10 月,Kylin 发布了 Release v1.0,这标志着 Kylin 产品相对稳定了;
用户的成长:外部用户对开源产品来说是很重要的。Kylin 从 Apache 基金会毕业时,真正把它运行在系统上的用户已经有 5 家了,包括百度地图、网易、美团等。
贡献者的增长:在 Apache 基金会孵化期间,Kylin 吸引了三四个核心贡献者,邮件列表中的用户有上百人。
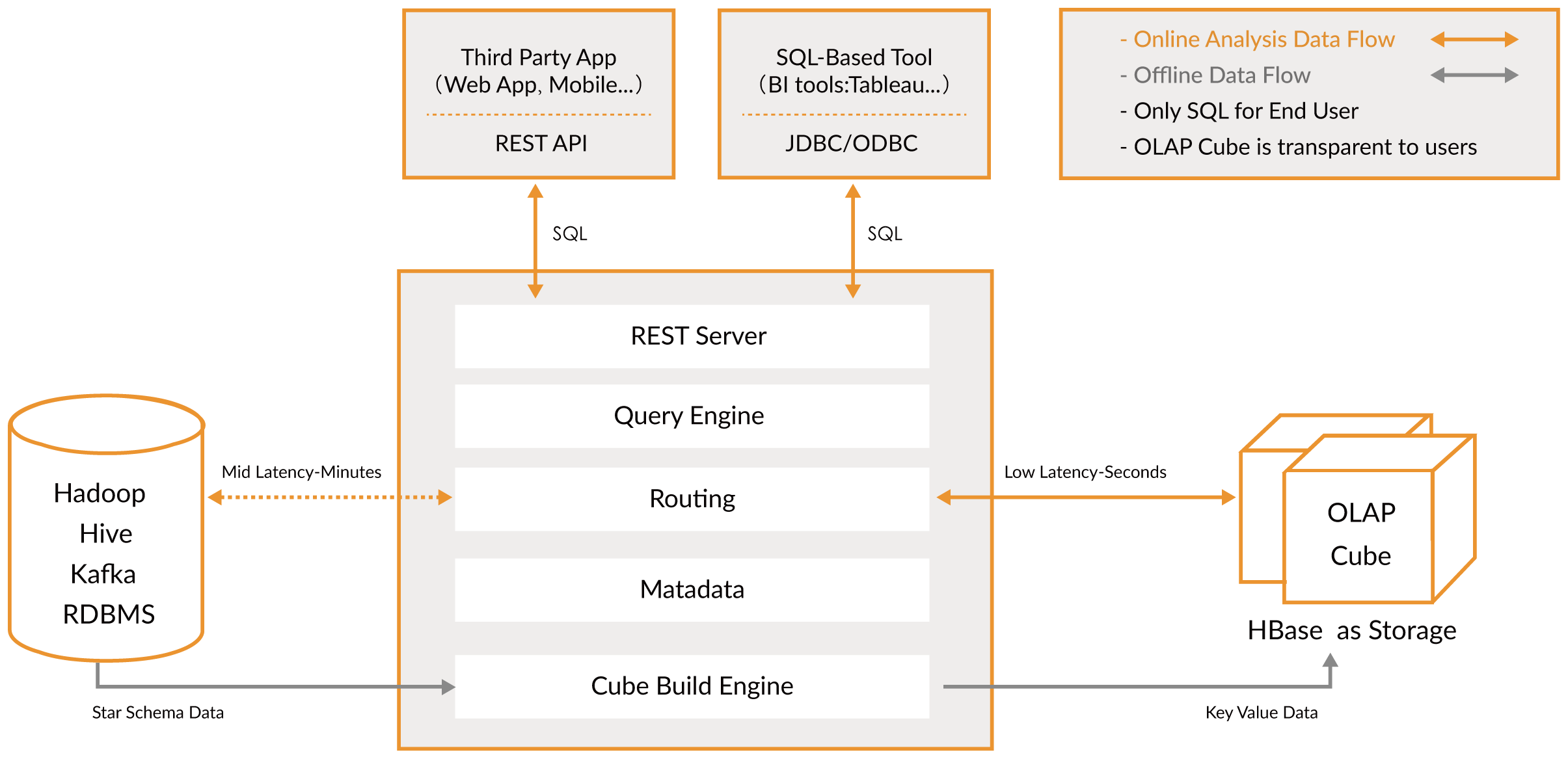
如果从技术角度来看,Kylin 之前技术架构比较紧凑,耦合度比较高,数据源必须是 Hive,必须在 Hadoop 上做构建,在 HBase 上做存储,但后来 Kylin 团队对技术架构做了调整,耦合度变得更低,架构更开放,可以对接各种技术,例如数据源可以是 Kafka,构建也可以是 Spark,存储引擎引入了新技术。
从社区角度来看,社区成员的构成更加多样了,当 Kylin 项目从 Apache 孵化器中毕业时,eBay、美团、京东、网易等多个公司都有非常大的贡献和参与。另外,经过一年多的磨合,社区对于 Apache 邮件列表的沟通方式更加熟悉了,沟通效率提高了。
如何贡献一个改进到 Kylin 项目?
总体来说,如果要贡献一个改进到 Kylin 项目,那么需要经历如下流程:
第一步:报告 JIRA,描述具体的问题或功能,并在下面进行讨论;
第二步:fork Kylin 代码,进行开发,完善 test case,通过单元测试和集成测试。代码需满足相应的规范,包括格式、名称规范等;
第三步:生成 patch 或 pull request,并关联 JIRA;
第四步:由社区 committer 来 review patch,review 通过后,合并进入主分支,再 cherry-pick 到各个维护分支;
第五步:更新 JIRA,发布等。
其中,第一步到第三步由贡献者来完成,第四和第五步由社区维护者来完成。对于贡献者来说,工作量主要在于描述问题以及生成 patch,而对于社区维护者来说,主要负责后续工作。
如何进行代码迭代与功能审核?
开源项目的代码迭代是整个项目发展的核心,那么代码迭代时应该注意哪些事项呢?
从开发者角度来说,开源项目是大家共同来贡献和维护的,没有任何一个人需要为产品的稳定性或质量来负责。所以,每个贡献者是有义务去保证每个 PR 测试的完备性,尤其是在提交 PR 之前需要做很多 review 工作。
除此之外,提交之后还需要做事后抽验。开源软件和商业软件有很多不同,商业软件要考虑生产环境上的可用性,而开源软件可以做更多的创新和尝试,开发者可以在某个版本上测试一些新技术,并搜集用户反馈,在下一个版本中进行完善。
在功能审核方面,Kylin 团队主要遵循两条原则:第一是功能必须具有通用性,可以解决大部分用户面临的问题,而不是单个用户的定制化需求;第二是功能是否可以兼容过去的产品版本。如果这个功能特别好,但兼容性差,团队会通过软件配置等方式来改善兼容性。如果兼容性的问题暂时没有办法解决,那么这个功能将不被采纳。
在代码审核方面,Kylin 不仅有人工 review 和投票机制,还有自动化的单元测试和集成测试。对于出现的问题,Kylin 会有人工 review 来发现,同时也会用自动化测试来确保新加入的功能不会破坏之前的功能。
针对外部贡献的代码,Kylin 团队会先做人工判断,如果暂时无法判断,就去 Jackson 上跑一遍集成测试,通过之后作为一个新的 feature 发布。如果这是一个比较大的 feature,Kylin 会要求对方提供实际应用的数据,例如是否已经应用在生产环境,是否有可量化的数据来证明性能的提高程度。
项目开发者之间如何沟通?
Apache 基金会的官方沟通方式是邮件列表,各个项目的内部沟通都需要通过邮件的方式来进行。新产品的发布、新功能的增加或者产品的升级都必须在社区邮件中留有痕迹,如果没有在邮件列表中讨论过的事情,那么它就不应该发生。
在中国,很多人都习惯于使用微信群或者 QQ 群等方式进行沟通,那么这些方式是否适合开源项目的内部沟通?针对这个问题,韩卿表示:“微信群、QQ 群这样的方式不适合开源项目的维护,Apache 基金会之所以规定所有的交流都要在邮件列表中进行,是因为这些邮件列表会被归档、被搜索引擎搜索到。如果把这些内容放到某些群里是无法被第三方索引到的,甚至都不能被后来的开发者看到。对于国际社区来说,封闭的群以及非英文讨论是极其不友好的,这会导致整个社区越来越弱。”
电子邮件是最平等且障碍最少的一种交流方式,它可以将以往的内容都沉淀下来。不论是后来加入项目的开发者,还是错过了某些会议的开发者,都可以通过邮件列表平等的获取到自己需要的信息。另外,使用电子邮件也代表了对项目开发者的尊重,没有任何一个开发者有义务 7*24 小时待命为大家解决问题,如果将问题描述在邮件列表中,开发者可以在空闲的时刻查看并解决该问题。
如果有人就是喜欢在群里沟通问题,那该怎么办呢?Kylin 的做法是只回答一种类型的问题,即这个问题之前已经有用户在社区的邮件列表中提交过,但是提问的人因为某些原因没有获知这一点,那么 Kylin 团队就会告知提问者该问题已在邮件列表中讨论过。
路线图如何规划才能不偏离“轨道”?
在谈及开源项目的路线图时,韩卿表示:“开源项目不应该是一个大而全的东西,而应该是一个精而专的东西,是整个生态的一部分。所以,开源项目的路线图要坚持初心,不能朝三暮四,今天觉得这个方向好,明天又认为另一个方向有前景。”
对于路线图来说,有两个方面的输入是很重要的,第一个方面来自核心团队,他们要对整个技术的未来发展方向有一个明确的认知和把握;第二个方面来自用户,用户会给你最多的支持,也会给你最好的方向,不过,也不能完全被用户需求所左右。
以 Kylin 为例,其定位是大数据平台上的 OLAP 引擎,所以在未来的发展路线图中规划了以下功能:
支持 Hadoop 3.0;
完全使用 Spark 的 构建引擎;
支持即席查询;
更好的存储引擎;
支持实时数据分析的 Lambda 架构。
Kylin:商业化不是个简单事儿
2016 年 3 月,Apache Kylin 核心团队创立了 Kyligence 公司,向客户提供基于 Apache Kylin 的 AI 增强的数据管理和分析平台,帮助企业构建从本地到多云架构上的数据服务,完成了开源项目商业化的转身。
那么对开源项目来说,开源版本和商业版本之间的界限应该如何划分?以 Kylin 为例,其团队在切分开源版本和商业版本时的考量是:开源版本一定是一个功能完备的项目,不会存在任何阉割。而商业版本会提供一些更加高级的功能,例如企业级特性,这些特性可能一般的互联网公司不太需要,但是在传统行业的企业中有很大需求。
何时做商业化才合适?
在什么时间节点做商业化才最合适呢?可能不同的团队有不同的考量,韩卿认为如果开源项目发展到了以下两个阶段,就可以考虑商业化了。
第一是当开源用户需要服务的时候。开源解决的是功能性的问题,项目团队提供这个功能给大家使用,但能不能用好是需要用户自己去解决的。而商业化除了解决功能性问题,还要解决服务问题。如果用户用不好,那么就需要有人来帮助他用好。所以,当你听到越来越多的用户需要服务时,那么商业化的时机就相对成熟了。
第二是当非互联网用户增多的时候。传统行业一般都有通过购买新技术和新产品来快速提升竞争力的习惯。所以,当一个开源项目出现了非互联网客户增长的趋势,那么这时就是商业化的好时机。
商业化的形式有很多种,例如提供服务、提供配套插件等等,那么哪种方式会是商业化成功的捷径呢?韩卿认为:“提供服务,提供插件,提供商业版本…都只是商业化的一个实现方式。商业化想要成功,首先要想清楚商业化的本质是什么?也就是客户为什么会愿意花钱?你能带给客户的第一价值是什么?”
商业化之后,如何保持社区的活跃度?
据了解,Kylin 现在的版本更新周期一般是 0 到 3 个月会出小版本,半年到一年左右会出一个大版本,版本更新依赖于社区的发展情况和贡献者的投入。
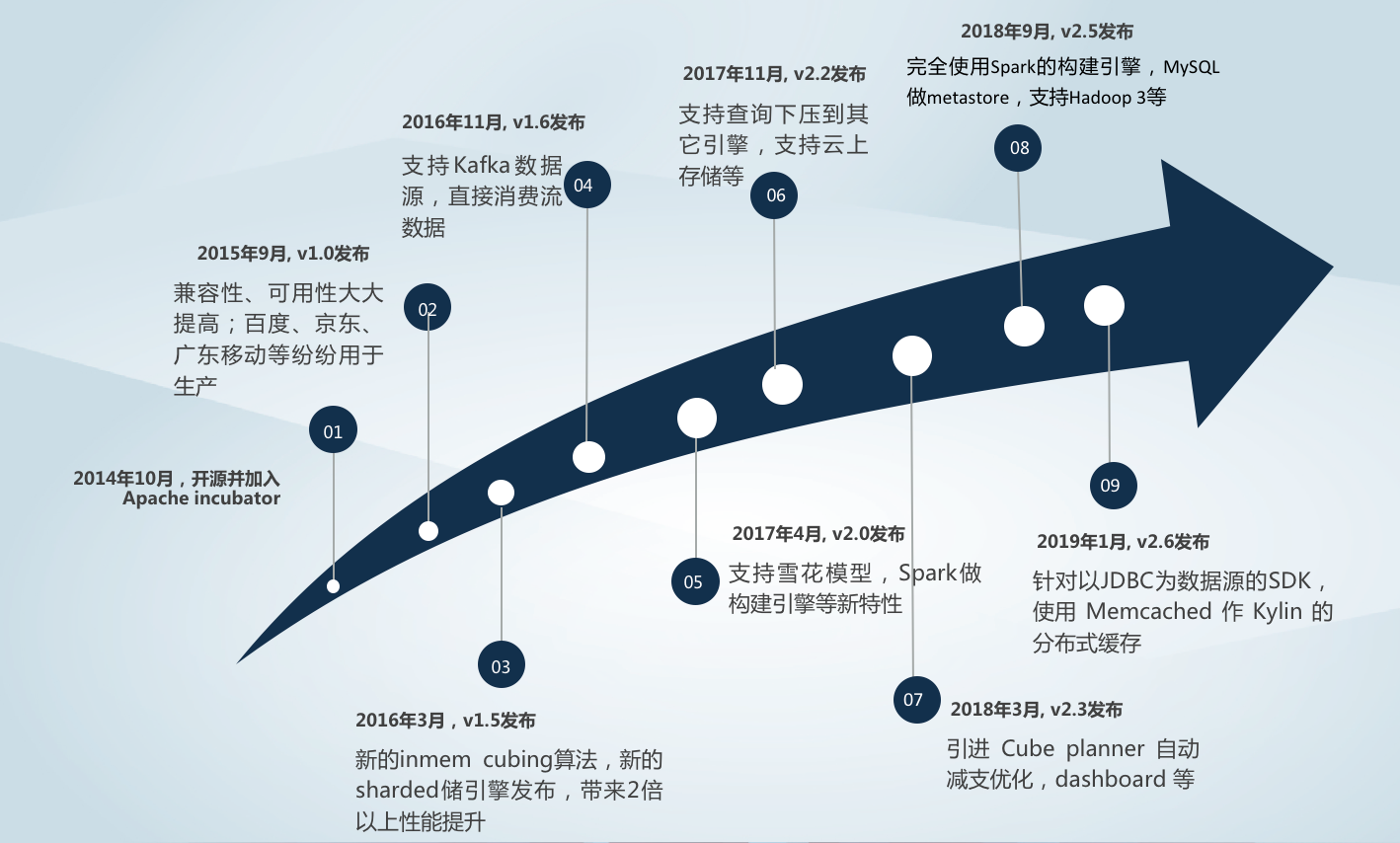
商业化之后,如何保证项目的更新周期呢? 以 Kylin 为例,Kyligence 是有一个专门的团队在持续向社区贡献,并且会和 eBay、美团、滴滴、小米等相关 committer 深入合作,以实现更多的功能。整体来看,项目的更新周期与商业化之前并无差别,只是随着项目越来越成熟稳定,新的东西可能会越来越少,发布周期会有所延长,但也会保持一个节奏。
怎么保持社区的活跃?其实开源项目的生命力来自于社区,所以要维持活跃度就要不断地拓展社区用户。如何拓展呢?韩卿也给我们支了两招:“首先,我们要不断的加大市场投入和研发力量投入,使得更多的人可以使用好开源项目,进一步降低门槛;其次,在线下也要和活跃的用户保持紧密的沟通,积极和用户交流想法,鼓励使用者不仅要把产品用起来,还要把更多的东西贡献回来,不断促进项目的演进和发展。”
Kylin 典型的商业案例
太平洋财产险的业财一体化分析平台是 Kylin 项目商业化的典型案例。当时太平洋财产险面临的痛点是传统的数据仓库设施和平台由于本身技术架构的局限性,无法处理快速增长的数据,无法解决不同业务线的数据孤岛问题,也无法满足对海量数据中各类维度和指标进行灵活高效分析的需求。
而基于 Kyligence 企业级大数据 OLAP 引擎搭建的业财一体化大数据平台,在数据层抽取了太平洋财产险公司 3.7 亿个保单数据,构建了多层级多维度的业务分析模型;在技术层,该平台在 Hadoop 集群上部署了企业级大数据 OLAP 引擎 KAP,通过预计算技术,可以高效利用 Spark 或 Hadoop 分布式计算引擎 MapReduce;在应用层,提供了支持标准 SQL 接口的 JDBC 和 ODBC 驱动,无缝集成企业已有的 BI 前端工具。
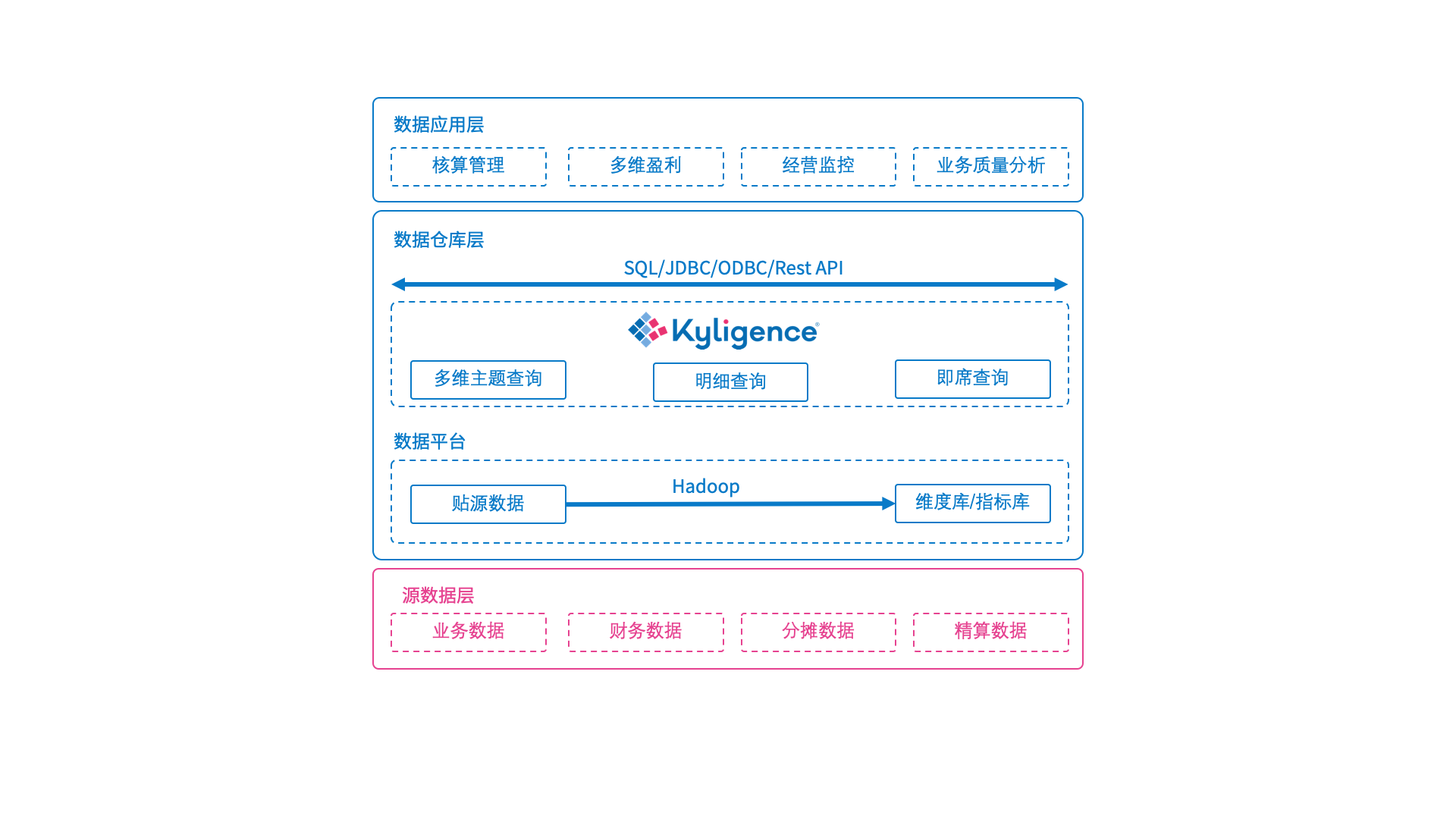
据了解,目前该系统已实现 40 个维度、300 个指标的分析规模,并且已经开放给 1000 多个总分公司机构、4000 多名分析用户使用,多维统计分析报表查询响应时效也从“半小时”级提升到“秒”级。[1]
Apache 基金会对开源项目商业化有何限制?
Apache 基金会对商业化比较友好,但也有其原则。
Apache 基金会很重要的一个理念是供应商的独立性,也就是说 Apache 基金会和旗下的项目不会受任何一个商业公司的影响。例如,Apache 项目在对外宣传时,是不能夹带任何有关商业公司的信息,开源官网上也不能挂商业公司的相关信息做引导。
值得注意的是,Apache 项目是独立的,所有贡献只认个人,不认公司。所以,从 Apache 项目的官方数据中是无法得知在某个开源项目中哪个公司做的贡献最多。
结语
开源项目起源于开发者对技术的热情,但只凭一腔热情是无法维护好一个开源项目的。国内有不少开发者会在业余时间做一些个人爱好的开源项目,但是真正能够对业界产生影响的开源项目少之又少。这并不是说国内开发者技不如人,而是他们对于开源的理解还很有局限,如何维护一个开源项目对他们来说还是一个黑盒,希望这篇文章能够给对开源项目真正有热情的国内开发者带来一些启迪。
参考文档:
[1] 中国太保:基于大数据OLAP技术的业财一体化分析应用

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论