
在万亿参数模型中,一个细节的优化能节省千卡 GPU,继而节省数十万的成本。
在 WAIC 2025 世界人工智能大会上,上海期智研究院联合算秩未来正式发布重磅开源项目 MegatronApp。
GitHub 项目链接:https://github.com/OpenSQZ/MegatronApp
这是目前国内首个专门围绕 Megatron-LM 打造的开源增强工具链,聚焦于高可用、自适应、高效率和可观测四大核心目标,设计出以下四大模块:

MegatronApp 核心功能
经过某大型金融行业实际训练数据显示,MegatronApp 通过慢节点精准识别、智能调度提升吞吐率、前后向计算解耦提升单卡效率,实时可视化与诊断等手段,在 Megatron-LM 框架下实现训练效率提升 25%、训练成本降低 23%。MegaDPP 和 MegaFBD 模块提升训练效率 25%(其中 MegaFBD 单分支提升单卡训练效率约 18%,MegaDPP 分支通过减少通讯时间节约约 5% 的训练时间);MegaScan 和 MegaScope 极大提升了用户体验和训练的可靠性。
在大模型训练这场竞赛中,有一个名字常常出现在底层的配置文件中,却很少被普通开发者提起——Megatron-LM。
这个由 NVIDIA 开源的大模型框架,是 GPT-3、Llama、OPT (Open Pre-trained Transformers)等明星模型背后的“无名英雄”。它靠着 3D 并行架构,把原本只能在少数 GPU 上训练的百亿参数级别的模型,成功扩展到了万亿参数的规模。
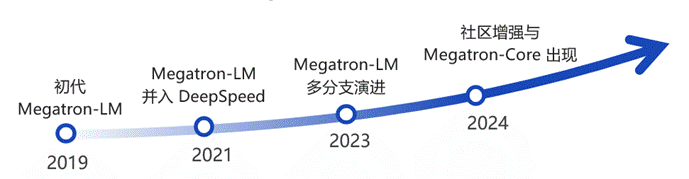
Megatron-LM 发展历程
真正上手过 Megatron-LM 的工程师都知道,大模型训练中各种问题频发,GPU 降频、网络链路抖动、显存爆炸、吞吐骤降、Attention 的可视化难以观测……
这些看似“边角料”的问题,才是系统工程里最烧钱、最费人、最让人崩溃的部分。
为了解决用户使用 Megatron-LM 框架进行大模型训练时遇到的挑战,我们深入一线调研,并为此开发了 MegatronApp 工具包。
MegaScan 慢节点检测:3 分钟锁定慢节点,让训练不再靠“猜”
“稳定性方面总是出现很多问题,经常一两天都找不到故障原因”,一位 Megatron-LM 框架下的模型训练开发者和我们抱怨。“训练过程中整体 IO 性能突然下降,无法判断是哪张卡导致的,只能等任务结束了,才能根据日志进行回溯,调整参数再测试,反复尝试,费钱费时间。”
几百张 GPU 拼命卷,但吞吐就是上不去;一顿排查,发现是某张卡从某个训练时刻开始悄悄降频,或者某次 AllReduce 被某个链路堵住了整整几十毫秒。
在大模型训练里,慢节点就像“沙子进了齿轮” —— 哪怕只有一颗,也能让整个流水线性能雪崩。
传统排查方式依赖开发者经验“人肉捞针”;已有工具如 DLRover 通过任务迁移来缓解慢节点,但这类工具都要求用户能大致判断出问题类型,再用工具“辅助解决”。
为了给分布式训练装上一块“系统级心电图监控仪”,让问题无所遁形,我们设计了 MegaScan。
MegaScan 会在每一次 GPU 计算核函数和通信调用的前后,自动埋入轻量级 CUDA Events,毫秒级捕捉每张卡的执行脉搏。而我们借助通信操作的天然同步特性,把不同节点、不同设备、不同时钟域的数百万条事件对齐到同一时间轴上,一眼看清谁在掉队、谁在卡壳。无论是计算设备、网络设备,还是交换设备,都可以在一个界面内实现统一检测与归因分析,大大减少切换工具、排查路径的时间成本。
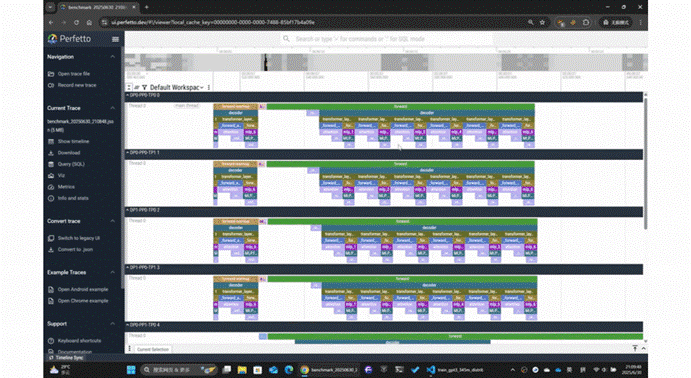
MegaScan 支持查看不同层级内容
MegaScan 使用过程非常便捷,只需把生成的 trace 文件拖进 Chrome 自带的 tracing 工具,一张彩色瀑布图就自动展开:
哪一层网络延迟突然抖动了?
哪一张 GPU 降频明显?
哪次 AllReduce 挤爆了链路? ——故障节点一目了然。
MegaScan 慢节点检测功能
更重要的是,这套追踪机制对训练时长的影响不到 1.3%,真正实现了“随时开,不掉速”。在 256 张 4090 的集群实测中,MegatronApp 仅用 76s 就能精准定位慢节点并自动生成根因报告;使用 MegaScan 前,工程师一般需要 1~2 天才能定位设备故障,故障定位和解决效率提升远超 100%。
对于在云上按秒计费的大模型训练来说,节省 GPU 时间,就是实打实的节省真金白银。
MegaDPP 动态流水线调度:让 GPU 和网络“同步起舞”,网络带宽需求降低 50%
大模型训练的流水线调度,一直沿用的还是几年前就定型的 1F1B(One Forward, One Backward)策略。这个模式确实稳定,但问题是 —— 它太“刚性”了,网络一抖、显存一紧,整条流水线就卡得死死的。
我们决定不再“缝缝补补”,而是下猛药,从调度逻辑底层重构了一遍,于是诞生了——MegaDPP(Dynamic Pipeline Parallelism)。
我们把一次训练迭代抽象成一个由 micro‑batch 和模型切片交错组成的大矩阵,然后设计了两条可以动态切换的“遍历路线”:
显存吃紧?走“深度优先计算(DFC,Depth-First Calculation)” —— 同一批数据尽快算完后就释放,立刻降低显存高峰。
带宽爆炸?切“广度优先计算(BFC,Breadth-First Calculation)” —— 多批数据平铺在模型切片上,梯度能提早同步,网络利用率瞬间提升。
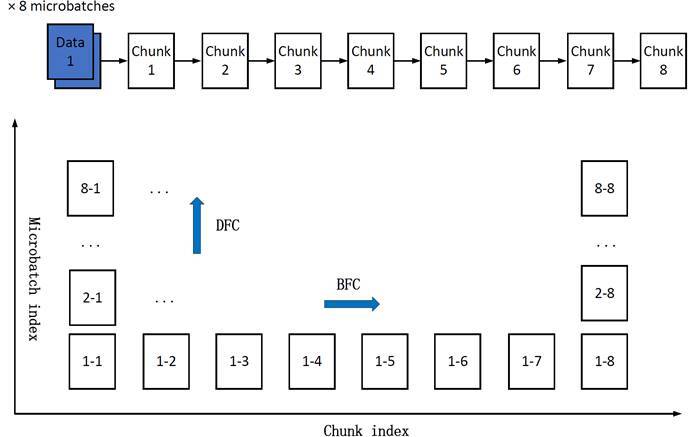
MegaDPP 流水线调度示意图
整个策略的切换,完全由实时监测的显存使用率和网络带宽驱动。不需要手动写一行配置,系统会自行判断怎么排布数据,让 GPU、显存、通信带宽分工明确、配合默契。
当然,仅仅“调度灵活”还不够,我们还对通信底层做了一次“换血”升级。我们重写了 P2P 通信接口,采用共享内存 + RDMA 的组合 —— 允许一张卡同时发起多路异步传输,彻底绕开 NCCL 单进程通讯的堵塞问题。
实际在 8 卡节点、200G InfiniBand 网络上测试,流水线并行的发送窗口扩展高达 2.6 倍,数据并行的缩减窗口扩展高达 2.4 倍,原本像“单车道”一样排队的通信变成了高速路,交换机总算能喘口气。
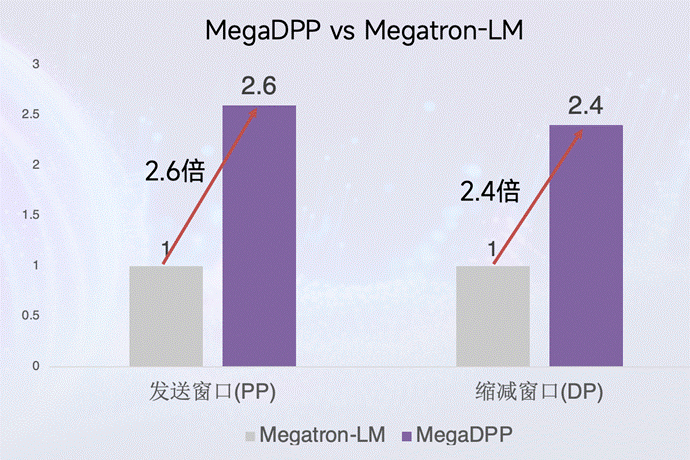
8 卡节点、200G IB 网络环境测试结果
MegaFBD:前向后向“分手快乐”,单卡效率提升 18.7%
训练大模型,就像在一根水管里同时灌入两种完全不同“粘度”的液体:前向计算和后向传播。前向阶段算力需求低、显存占用少,但网络传输密集;后向则是算力怪兽、显存大户,但传输压力反而小。传统框架把它们强行捆在同一张 GPU 上跑,结果不是这边堵,就是那边挤 —— 谁也跑不快。
是时候让前向和后向“和平分手”了。
我们打造了 MegaFBD(Forward/Backward Disaggregating),从调度逻辑到通信路径,对 3D 并行体系动了一次“结构级大手术”。它的核心思路是:逻辑 Rank 不变,物理职责拆开。
具体来说,我们引入“虚拟 Rank + 物理 Rank”的双层调度结构:模型切法照旧,但在执行层面,将前向计算统一安排在一小部分 GPU 上,其余大多数 GPU 专注于后向计算。让每个 GPU 做最擅长的事,避免资源竞争,提升整体效率。
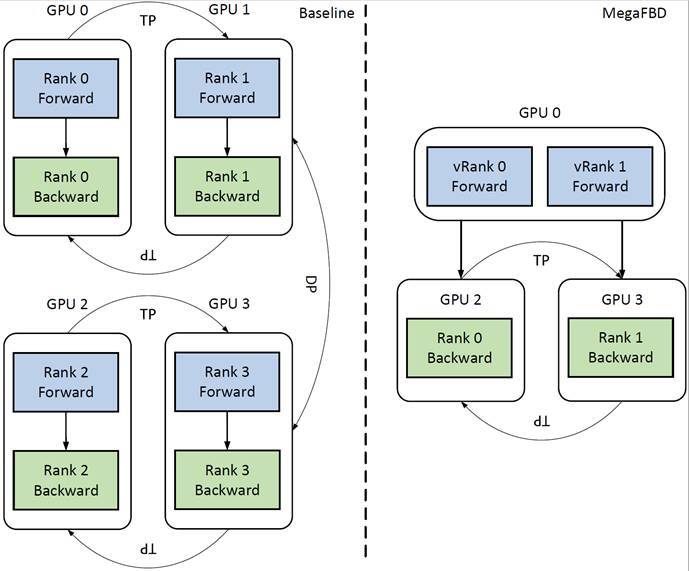
MegaFBD 与 Megatron-LM 调度结构对比
这种异步、非对称计算流的最大挑战就是通信:如何确保多个线程之间的 AllReduce 不出错?我们设计了一套轻量级通信协调机制:
通过位向量表标记线程是否就绪;
使用 OR-AllReduce 原语聚合线程状态;
所有线程就位后,通信才统一触发,避免死锁。
整个流程的同步复杂度仅线性依赖于 GPU 数量。实测在百卡规模集群上也能稳定运行不卡顿。
在实际训练 Llama-3 13B 模型时,单卡有效 TFLOPs(每秒万亿次浮点运算,反映实际可用的 GPU 算力) 提升达 18.7%。对于部署在混合云上的训练任务,这意味着时间少了、账单也少了。尤其是在万亿参数规模下,每提升一个百分点,都是实打实的成本优化。
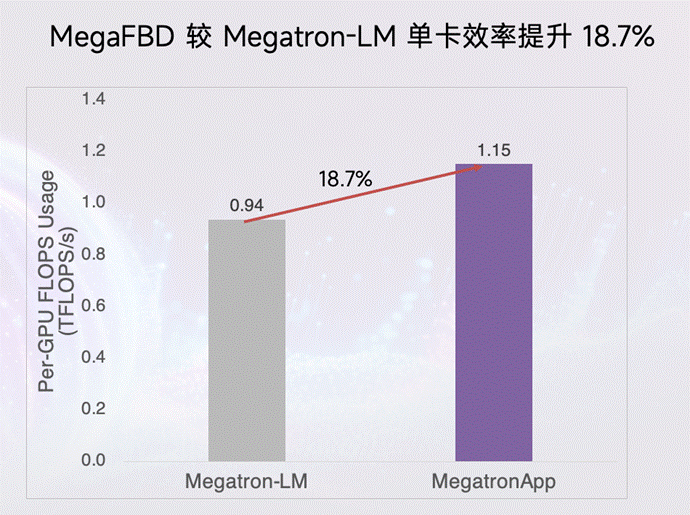
Llama-3 13B 训练场景下,单卡有效 TFLOPs 数上升 18.7%
MegaScope LLM 可视化系统:把训练“打开看”,不在黑盒里盲修盲改
对于做大模型训练的人来说,调参和定位问题的体验就像在黑暗中摸索一架发动机:你知道它在运转,却看不清哪里出了问题。尤其是在千亿、万亿参数级别的模型下,每一层 Attention、每一次 Token 解码都隐藏在无数张量流动的迷雾里,调试变成了一场信息失控的豪赌。
目前市面上已有较多的开源可视化工具,如 TensorBoard、Bertviz 等,但这些工具无法平衡可解释性和性能开销。模型训练用户的迫切需求是在保证低损耗的前提下,让用户了解当前任务的状态。
用户调研中,我们最常听到的声音是:
为此我们设计了 MegaScope,其核心思想是,在 GPU 上先做统计和量化,仅上传必要指标至前端,并把注意力、MLP、Token 轨迹等统一抽样接口,在压缩消耗的前提下,向训练用户提供所有训练相关的必要信息。
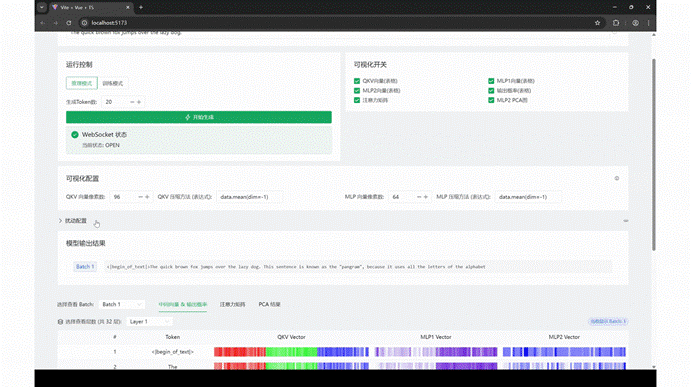
MegaScope 是一个轻量级、可插拔的可视化与交互式干预工具,专为 LLM 训练过程打造。从输入 Prompt 到输出 Token,每一个步骤、每一个张量、每一个模块——都能以直观可交互的方式“看见、回放、干预”。
打开 MegaScope 的仪表盘,你可以:
实时查看每个 Token 的生成过程,像在播放一段逐帧动画;
随时暂停/回放 Attention、QKV、MLP 模块的运行热图;
拖动时间轴,查看某层在不同 batch 下的表现波动;
切换观察维度:层、头、batch、Token 随你选择;
投影隐藏状态到 2D 平面,看 Token 如何在语义空间中“漫游”。
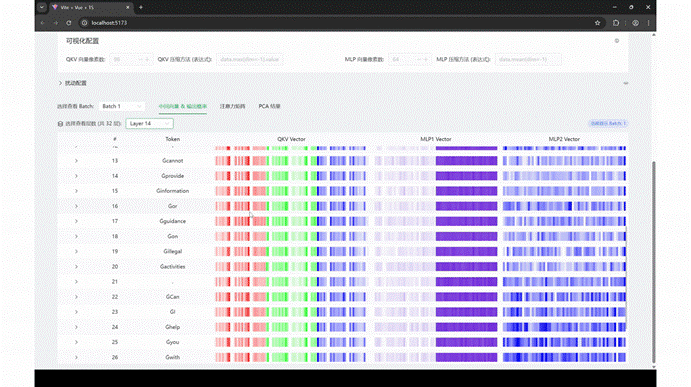
MegaScope 支持实时生成和同步可视化
调研中,我们了解到大模型用户希望在训练过程中人为地干预模型,以便研究其在不同干扰场景下的鲁棒性表现。MegaScope 支持灵活注入扰动机制,以全面提升系统适应性。MegaScope 不仅支持用户查看,还支持用户根据自身需求做定制化操作:
对任意张量施加 bit flip、噪声或遮盖 mask;
模拟通信异常,在不同 rank 间注入网络延迟或偏移;
实时回看影响,研究鲁棒性、容错性、甚至对抗性行为。
这些“动手实验”,通常在 3 秒内即可发起,训练过程完全不中断。
MegaScope 支持注入扰动
针对性能损耗问题,MegaScope 的后端采用异步缓存与在线聚合算法,实测在万亿参数模型训练过程中,吞吐率影响保持在 1% 以内。做到真正的“边训练,边观察,边实验”。
MegatronApp 实测效果与用户反馈:25% 效率提升,不止纸面数据
在大模型训练的集群测试中,MegatronApp 在 Megatron‑LM 框架下实现了约 25% 的端到端训练效率提升。这不只是“阶段性优化”,而且是在通信效率、算力利用率、可视化监测等多个维度实现了系统性突破。
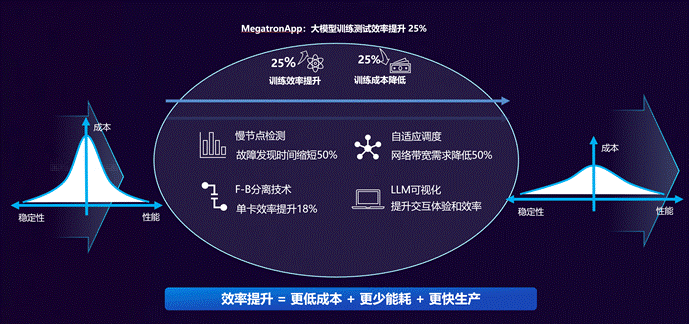
MegatronApp 并非是一个“锦上添花”的工具包,而是支撑大模型训练稳定落地的系统基座。对于动辄几百万 GPU 小时的万亿参数模型训练任务而言,提升 1% 就意味着节省数十万元的成本,而我们的训练效率提升了 25%。
开源不是终点,而是开始
MegatronApp 的诞生,是我们在万亿参数大模型实战中,一点一滴踩坑、试错、打磨出来的工具集。它不是“终极方案”,但它凝聚了我们对系统效率、训练稳定性、可解释性三者之间平衡的理解。
我们选择开源,不是为了“发布一个成果”,而是真诚希望能和更多开发者、研究者一起,共同推进性能优化、功能完善与社区生态。
如果你在用 Megatron-LM 训练自己的模型,希望这套增强工具能帮你节省时间与算力;
如果你对分布式训练系统感兴趣,欢迎加入我们,一起把工具打磨得更精致;
如果你发现了 Bug、想要提 PR、写文档、补测试、拉同事一起来贡献,我们热情欢迎您的加入!
GitHub 项目地址:https://github.com/OpenSQZ/MegatronApp




