

全球 AI 市场正在快速增长,据权威机构调查,到 2020 年,全球 AI 市场规模将达到 6800 亿美元。人工智能给不同行业带来无数机会的同时,也给企业基础架构带来了巨大的变化和挑战。AI 时代对基础架构的要求与从前有何不同?面向 AI 的基础架构应该怎么做?本文整理自百度副总裁侯震宇在QCon全球软件开发大会(北京站)2019上的主题演讲,他在演讲中分享了百度在 AI 基础架构方面进行的尝试和探索。
非常高兴能够在 QCon 十周年之际来到这里,跟大家分享百度在 AI 方面都做了哪些基础性工作。就如刚才主持人所说,大家都相信 AI 是一个巨大的浪潮、AI 是又一次工业革命、AI 会给整个产业链赋能很多很多,但是 AI 的基础架构本身应该怎么做,这是我今天主要想跟大家分享的。
今天分享的主要内容包括:AI 对基础架构的挑战、面向 AI 的基础架构方案,特别是在计算层、连接层我们正在做的一些工作。
AI 对基础架构的挑战
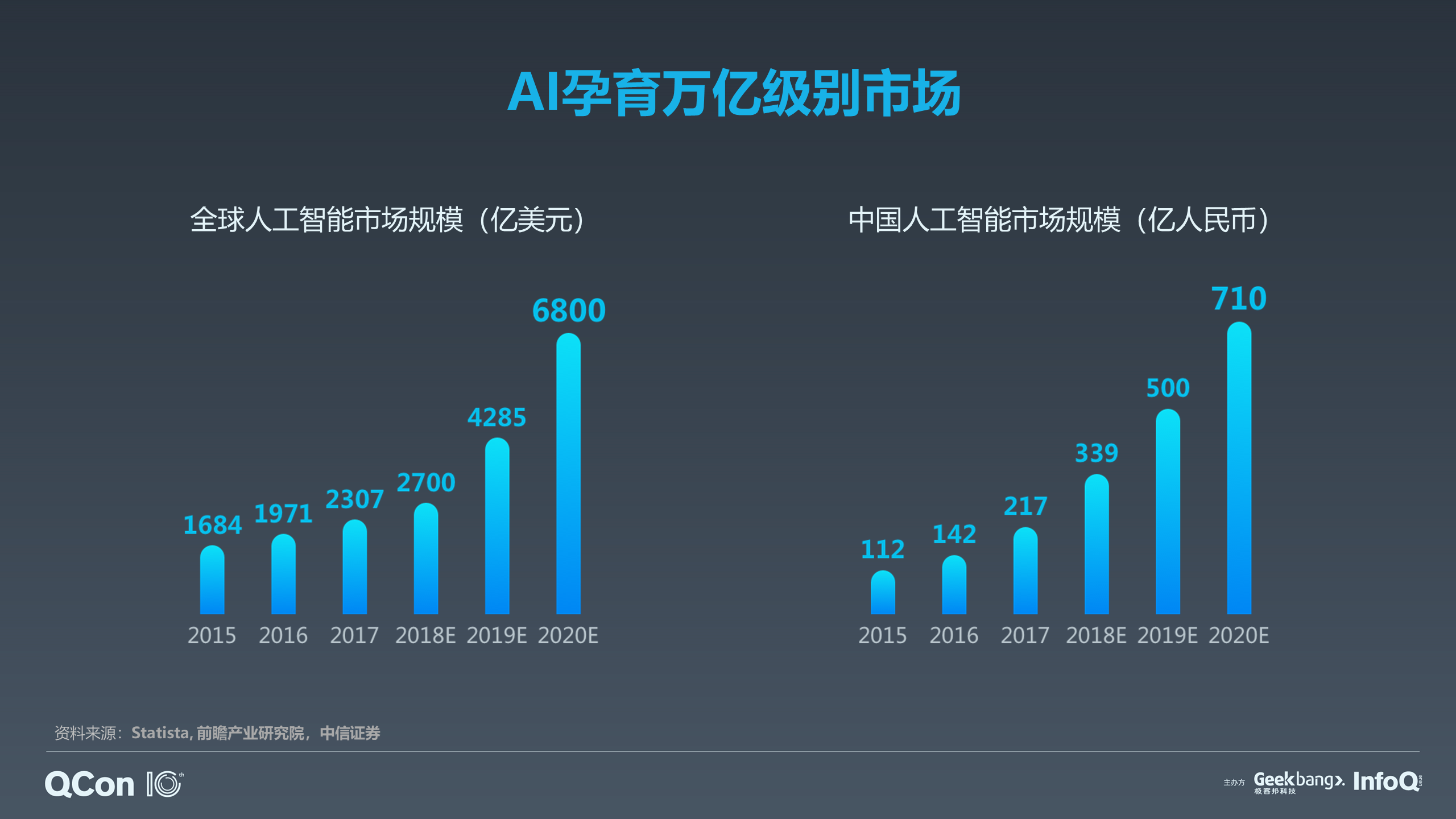
AI 是一个巨大的浪潮,我们通过一些权威机构的调研可以看到,全球 AI 市场巨大,而且增速非常非常快。从 2015 开始到 2020 年,全球 AI 市场规模将达到 6800 亿美元,其中中国市场的增长非常快,全球市场和中国市场的增长曲线差不多,但其实中国的 AI 市场没有那么大,到 2020 年预计将达到 710 亿人民币。中国仍然是全球第二大潜在的 AI 市场。
为什么会有这样的差别呢?我们可以看到,中国的 2C 互联网几大巨头,其实与美国那边没有什么明显的差距,或者基本是站在同一条线上。但是我们整个传统行业,包括工业现代化方面,与世界先进水平还有很大的差距。现在各大公司都在大谈产业互联网,AI 带动互联网行业技术创新、AI 赋能传统产业,这是我们接下来面临的巨大机遇、也是我们面临的巨大挑战。

这是我们能够看得到的,AI 在几大领域上存在的机会,每个市场都非常巨大。比如在自动驾驶或者智能交通领域,大家都知道百度在自动驾驶方面在全球一直是领先的,百度 Apollo 已成为目前全球涵盖产业最为丰富、最为全面的自动驾驶平台,我们跟众多的车厂都展开了合作。同时,我们在车路协同、智能红绿灯等方面也做了很多工作,这是 AI 在智能交通或者说智能驾驶方面的应用。如果自动驾驶未来能够跑在更多城市道路上,或者能够应用到更多工业场景,比如物流、农业等,那么这个市场其实是非常巨大的。
传统的安防领域接下来也需要大量的 AI 能力,使整体安防效果大幅提升。当然还有 AI 家居、智慧生活,比如百度的小度音箱,我们能够将小度音箱当作人工助手,对它提问题,让它去操作家中的智能设备,小度音箱这一年来的增长也非常快。另外还有 AI+教育,如智慧课堂、AR 教育;AI+医疗层面,百度的智能小程序去年也推出了智能分诊功能,和北大医院在智能分诊小程序上也有合作。

刚才谈到的这些业务场景,我们要如何去支持呢?百度构建了一套体系完整、功能全面的人工智能技术开放平台——百度大脑核心技术及开放平台,百度大脑已经对外开放了 171 项 AI 能力,从最下层的框架到上层的平台,包含百度训练出来的各种 AI 能力,包括在端上的各种产品。我们可以帮助众多的传统企业、帮助众多开发者迅速利用这些在百度内部已经验证过的 AI 能力和技术,让应用或者产品迅速插上 AI 的翅膀。
AI 给基础架构带来了巨大的变化和挑战,我们需要从端到端来提供 AI 计算能力。就如刚刚胡喜提到的,这是一个非常好的需要整个体系架构发生大变化的时代,我非常认同。整个 AI 的能力,从最开始的数据收集,前端到后端,到训练的整个过程,然后迭代,包括训练过程中前向计算到后向计算与参数更新。整个调参过程中包含了大量的计算、大量的数据处理,包括大量原始数据,到处理过程中上亿的特征数据,其实对数据的访问要求非常高,本质上最起码是一个非常高的 IO 密集的计算。
以前所谓的大数据时代,当时数据处理的特点是需要用海量数据来帮助计算,而现在在 AI 这个时代,我们不仅要处理海量数据。现在和以前对存储系统、计算系统的要求是非常不一样的,以前可能更多核心要素追求是整个系统的综合能力,而现在核心在于包括小文件的访问、小文件的存储,所以天生是一个 IO 密集型的计算。
同时现在有大量的 AI 训练任务,这些任务的迭代速度或者循环训练的次数非常多,需要跨节点、跨系统之间高速运转,所以当一张卡或者一台机器无法处理的时候,会从一个纯粹的 IO 密集型计算,转化成通信密集型计算,这是一个非常有意思的话题。几乎所有做系统的人都知道,我们做系统的时候很大一部分工作要考虑系统瓶颈的转化,从而使整个系统更加平滑。
为什么有很多平台用了非常昂贵的 GPU 卡,但是这些 GPU 卡使用率并不高,同时我们却有大量的任务在等待?如果仔细去研究一下,很多时候其实是 GPU 空闲但数据处于通信的状态。
另外,AI 推理当前更多直接在端侧设备上进行,因此会有大吞吐和低延时的要求,而低延时是一个典型的通信领域问题,因此这对于整体技术或者系统的要求,相交之前的大数据时代也发生了变化。
面向 AI 的基础架构方案
伴随着 AI 时代,5G 马上也要来临了。5G 真正推广应用之后,我们会拥有更大的接入带宽,就会有更多数据流进入到数据中心,也会有更多的 AI 能力下放到端侧和边缘侧。在 AI+5G 时代,计算是无处不在的,计算是所有系统的灵魂,计算会发生在数据中心、Cloud,也会发生在边缘,发生在我们的手机或者是说智能音箱里面,或者在无人车里面等等。所以这个架构是我们接下来要重点研究的计算的方向,计算会根据在这三个地方不同的功耗、价格以及需求带来计算的连接。
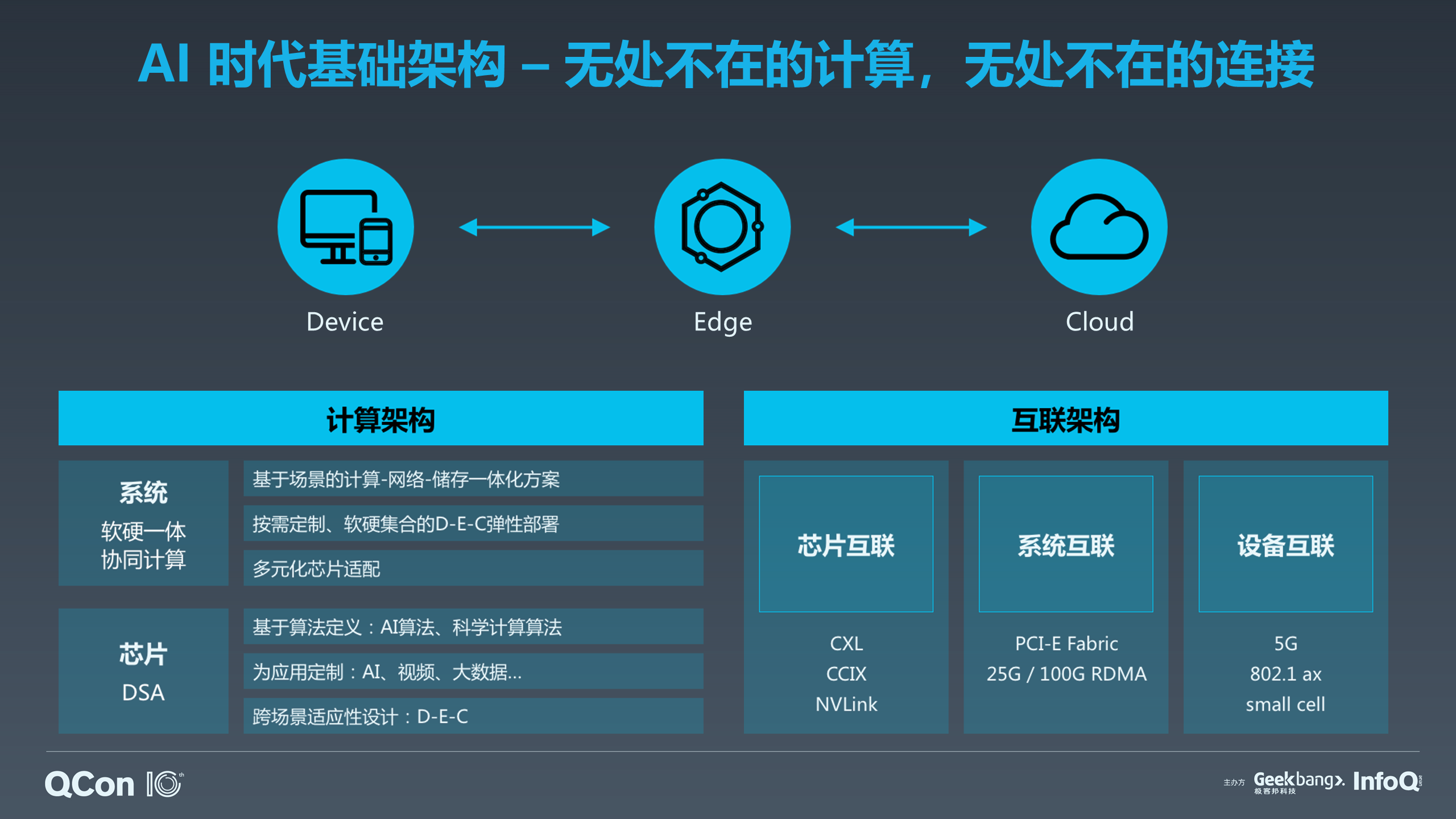
按照刚才所谓的 Device、Edge、Cloud 场景区分,我们在芯片层面上也应该考虑通过软件来定义芯片应该如何为 AI 加速。现在大量的 AI 芯片更多的都是这样的芯片,这就是我们现在整个 AI 的体系结构,从芯片的层面到关注到 5G 给我们带来的整体变化。
后面芯片的互联,我们要想训练一个超大模型,就需要有多张卡,同时在芯片层面上我们再高一层或者大一层。系统层面、节点层面的互联,数据中心的内容在几年前如果达到万兆在当时可能已经觉得很快了。但接下来面临 AI 高密度的通信计算,我们需要百 G 网络来支持我们更多的节点互联,从而实现整个计算的通信。
大家可以看到,往往新型的互联技术或者新型通信技术巨大的变革,可以给我们的体系结构带来巨大的变革。我们设计中存在的方方面面的问题会被新型的互联技术拉宽,当带宽变得更大的时候,我们软件的设计就应该不同,体系结构就应该变得不同。
刚才胡喜总谈到,做技术的人都应该有情怀,我高度认同这一点,特别是在座偏基础研究、偏基础工程的工程师,我们必须要有一种情怀,要知道技术能够改变世界,要知道整个大的技术浪潮已经来临,需要通过我们自己的努力把技术实现出来,来支撑我们走下去。我们做基础架构的人不应该只看到在市面上各种应用的孵化,而是应该看到技术的变化,以及它可能带来的问题。
无处不在的计算
计算首先发生在芯片层,从基础的计算单元进入到整个机器,再进入到机房 Cloud,再进入到整个边缘端大的计算里面,计算无处不在。
去年百度发布了昆仑芯片,在 D—E—C 三端上,我们对于芯片的性能指标会有不同的要求。不能指望一个手机或者一个智能音箱,能够做到像数据中心这么好的基础性能。根据实际的场景和应用的特点,我们会把考虑如何把计算的能力在 Cloud、在 APP 上最好地发挥出来,这其中很重要的一环是要基于我们自己打造的芯片。百度既有 AI 芯片,也有 AI 框架和各种各样的 AI 解决方案,我们提供的是整个全栈式的服务。
芯片现在很火,AI 计算需要更多的数据、需要更大的计算力,我们认为这些都是在一些特定领域上的。我们现在更加关注的是在特定领域的场景里面,体系架构有什么变化(Domain Specific Architecture,DSA),百度昆仑芯片就是在这个大的思考下设计出来的。

这是我们整个 AI 的系统,其实这下面还缺少刚刚谈到芯片层。再往上是我们自研的 X-MAN。我们把很多 CPU 卡插到一个 GPU 里面,来实现巨大的 AI 计算能力,把它通过网线再连到普通的机器里面,为 AI 训练加速,它能够使更大规模的模拟训练成为可能。另外,它在整体的成本上是更优的。我们去年实现了 8 小时上线一万台机器的世界纪录,8 小时一万台机器其实就是基于百度整个机柜达到 30 个节点,普通服务器插网线 8 小时都插不了 1 万台。
除了加速还有高性能存储,这些加上机房构成了我们整体的基础设施。
再往上是性能加速。我前面其实也谈到了,现在很多人买非常昂贵的 GPU 卡,但是发现运维上不去,这一块我们有通信优化和整体的性能优化。再往上是集群层面,我们可以调度大量的机器,在这上面实现智能调度、资源分配。另外我们也做了 Auto Compiler,现在是体系结构的黄金时代,我们需要更多有情怀的技术人去研究、去做底层技术,包括体系结构、交易系统这些可能最底层的技术,才可能实现高智能的 AI 计算,第一是高效,第二可能才能使我们更大规模的模型成为可能。
基于刚才谈到的芯片、基础设施、优化基础实验平台,再往上就是百度的 PaddlePaddle 深度学习平台。再往上就是我们的 AI 业务,包括视觉、音乐等等多样化的 AI 负载跟 PaddlePaddle 都是分不开的。
AI 的变化激发了我们对整个基础架构进行重新思考和设计。早前的存储系统已经无法很好地满足我们的需求,这是第一点。第二点,现在有更多新型设备出现了。百度可能是最早的几家,我不敢说是最早的一家,至少是最早的几家用这个技术,我第一次接触到是 2006 年,我们很快在搜索那边就开始使用 SSD 100 不同的接口去替代我们产品的 SaaS 平台。现在其实像 SSD 的性能和价格又有区分,针对不同的硬件,我们会有相应的互联网技术,可以把整个大的存储做成一个存储模式,真正做到计算和存储更好地分离开,这样存储资源的效率会变得更高。当然,一旦存储和计算分离开,我们就需要更高速的互联。我们希望 NVMe 这些节点能够互联起来,下面是我们硬件上的架构。
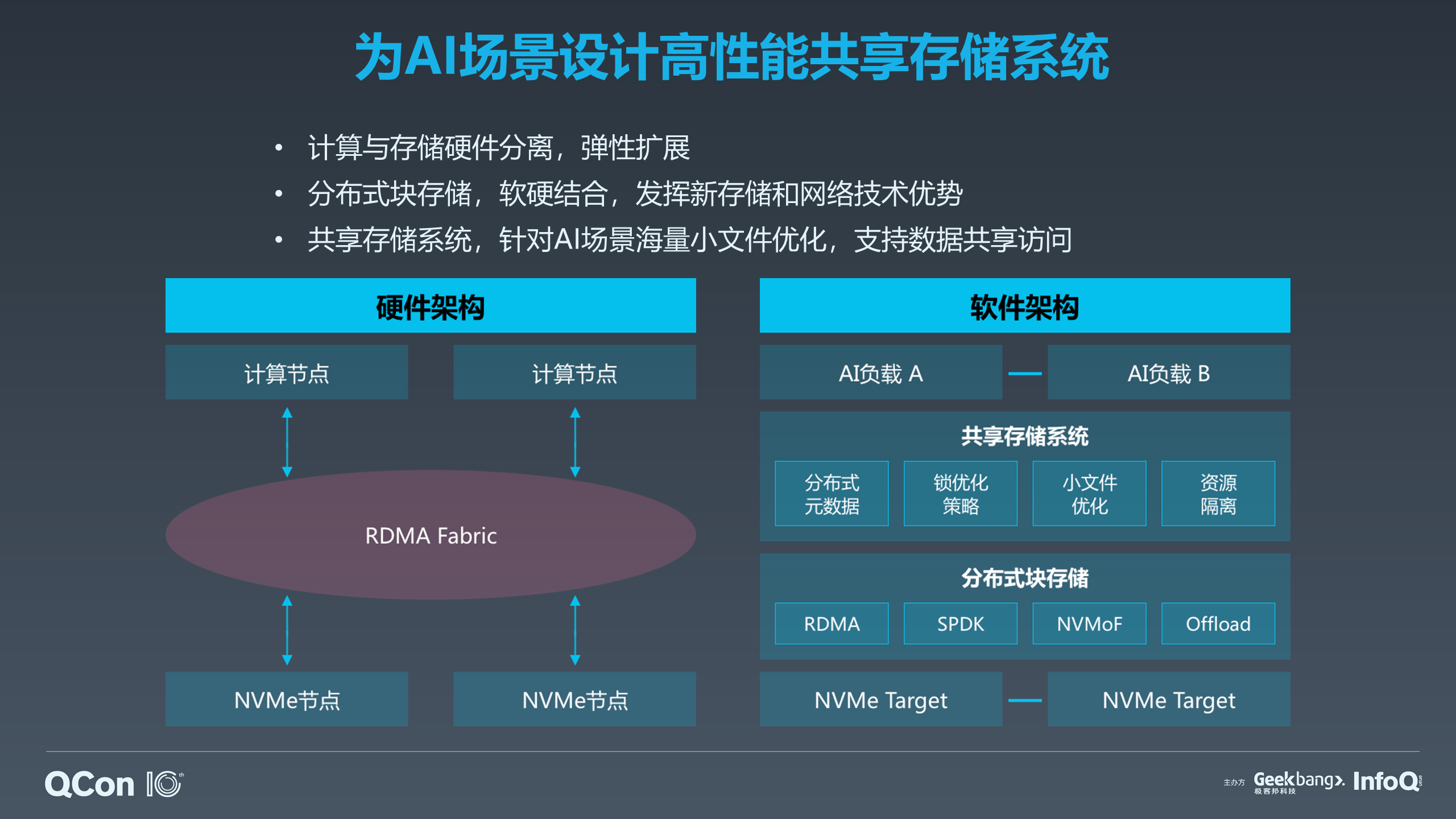
另外,我们在软件层面上,在这些硬件的基础之上也要做分层,我们会在上面做基本的块来接管物理设备,让物理设备从软件上全部屏蔽掉。再往上可以做共享存储系统,包括基于高速内核来处理小文件,或者说冷备等等,根据我们对计算成本的不同要求,我们会对存储系统进行整体优化。
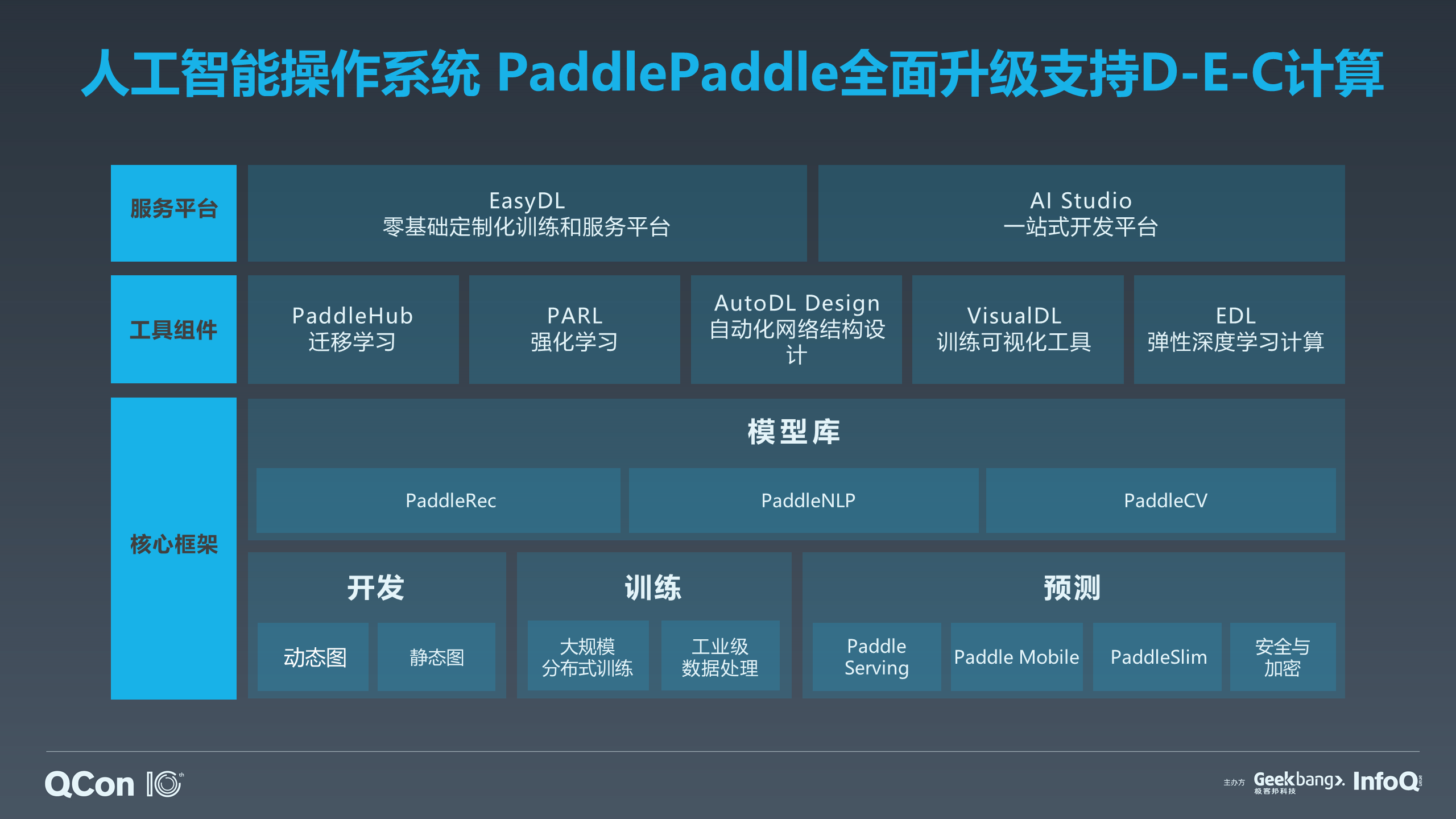
PaddlePaddle 百度自研的深度学习框架,上图是它的整体架构。我们上周还公布了一个 1 亿人民币的基金,支持整个 PaddlePaddle 的运营和推广。PaddlePaddle 支持训练和开发,这是 AI 经典的两大块,包括训练层刚刚谈到的超大规模训练,以及到预测层。另外,除了运行侧,PaddlePaddle 也提供了非常好的面向动态图、静态图开发的组件。在 AI 时代,不止是加速器、计算资源非常贵,AI 工程师也很贵,所以我们希望更好地应用计算资源,让工程师发挥出更大的价值,因此我们也提供了更多的工具。
在基础框架层面上,我们有大量的已经内嵌在 PaddlePaddle 框架里面的模型库,包括 PaddleRec、PaddleNLP、PaddleCV 等,其中包括很多百度内部正在使用的模型都随着 PaddlePaddle 全部开放出来。再往上我们有面向迁移学习、强化学习等方向的工具软件,包括 EDL 等,这些工具操作非常简单,可以让大家更低门槛的使用机器学习技术。
再往上我们有整套 AI 的开放平台,包括 EasyDL 零基础定制化训练和服务平台和 AI Studio 一站式开发平台。
计算无处不在,从芯片再到 Cloud 集群,再到边缘计算。边缘计算的三大驱动因素包括:低延时、数据本地化/隐私、计算多维度化。现在更多的计算逐步在地点上发生变化,计算更多发生在边缘节点上,而不只是发生在最核心的中央处理器 CPU 上面,也会发生在往外的加速节点上,甚至是智能网卡上,所以整个计算会越来越分散,需要良好的能力去支撑,从而让无处不在的支撑变得更加高效,但是同时这些计算又能够形成我们整个大的业务主流。
无处不在的连接
刚刚谈到计算无处不在,但是其实真正可能推动巨大变革的往往是互联技术,互联使计算连接起来实现更大的计算力,能够使数据流动产生很多的价值。所以其实连接也无处不在,这个连接既涉及到芯片间的互联,也涉及到系统间的互联,也涉及到数据中心内部的互联、数据外部的互联,也包括终端、5G 边缘的互联。
在芯片及系统内部的互联,我们会使用 NVLink、PCIe 或 CCIX 等。此外,不久以前,百度宣布同微软、Facebook 展开合作,联合制定 OAM (OCP Accelerator Module) 标准。该标准用于指导 AI 硬件加速模块和系统设计,也是用以实现更多芯片卡之间的互联。除了芯片互联,我们在整个 Cloud 数据内部,会将基础资源、计算资源等全部分开,实现 CPU+Memory 池,实现高速的存储、廉价的存储等更多存储池,实现节点平台、机柜、Pod 整个的互通互联,以及必要的安全,最终实现整个资源的共享,使整个计算能力更大。这就是我们在互联方面正在做的一些事情。
百度内部整个基础网络架构,从机柜到数据中心到 Spine 这个层面的交换机等,实现了数据中心内部的高速互联、数据中心无收敛点的互联。同时在基础网络层面上,我们会将刚才谈到的这些加速能力和技术结合进来,使我们基础设施最底层的网络能够面向更大型的计算。
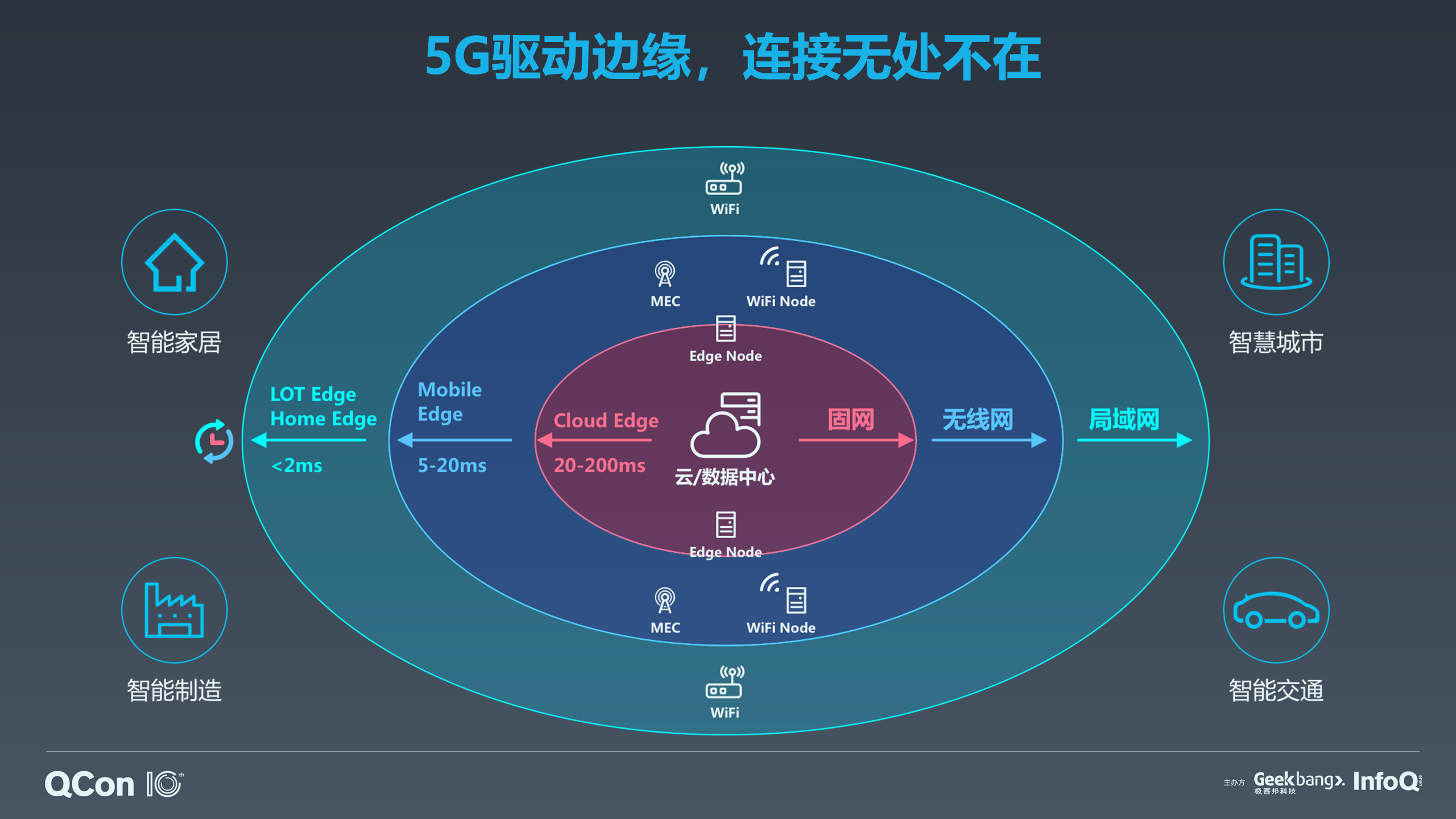
在 5G 和 AI 相结合的时代,计算无处不在,连接也无处不在。上图展示的是一个时延圈,从数据中心到各种场景。IOT、手机、智能家居等到实际应用的通信延迟通常小于 2 毫秒;而运营商,比如 5G 里 MEC 的这些边缘节点,一般到实际应用的延迟在 20 毫秒内;大型的数据中心到终端的用户之间的通信延迟则一般在 20-100 或者 200 毫秒,超过 100 毫秒以上可能就无法特别好地为用户提供在线服务了。针对这么大的时延圈我们会采用不同的通信技术,比如中心侧我们可能有 MEC 的计算节点,在 IoT 有 NBLot 等技术,能够让我们更好地实现通信,支持智慧城市、智能家居等应用场景。
通过时延圈来布局整体的 AI 计算力的分布,通过在内部、在边缘节点上的 AI 加速能力,来使我们整体的 AI 计算力变得更大。现在其实是一个拼计算能力的时代,算力为王,但是我们也一定要看时延圈来决定。
以上这些是百度在面向 5G 大的浪潮之下,为 AI 计算提供的一些基础设施,我们正在做和我们计划做的工作。
我们相信,未来整个计算无处不在,互联无处不在,通过我们的工作也可以让 AI 无处不在。而我们要做的就是让 AI 的基础架构“无”影随行,所谓“无”指的是我们希望所有的服务都以平台的形式、云的形式提供给大家,大家不需要关注下面到底是什么样的技术,而用一个更加简单、更加易用的接口来实现百度 AI 能力的普惠。
演讲嘉宾介绍
侯震宇,百度副总裁,负责基础技术体系工程团队的管理工作。侯震宇是百度贴吧、知道、空间、网盘、基础架构部等业务的奠基工程师之一。在 2019 年初的春晚活动中,侯震宇带领团队实现了中国互联网春晚活动的首次顺畅运营。
在即将于 5 月 25~28 日举行的 QCon 广州 2019,将有更多来自蚂蚁金服的专家带来分享。戳这里,了解更多详情!

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论