

本文介绍了微软新提出的 PipeDream,旨在使深度学习网络训练并行化水平更高,进而提高训练效率。
深度神经网络(DNNs:Deep Neural Networks)已经在大量应用中取得了巨大进展,这些应用包括图像分类、翻译、语言建模以及视频字幕等。但 DNN 训练极其耗时,需要多个加速器高效地并行化。
在论文“PipeDream: Greneralized Pipeline Parallelism for DNN Training”(该论文发表于第 27 届 ACM 操作系统原理研讨会:SOSP 2019)中,微软系统研究小组的研究员,与来自卡内基梅隆大学和斯坦福大学的同事和学生们一起提出了一种 DNN 并行化训练的新方法。正如论文里在大量模型上展示的那样,这套被称为 PipeDream 的系统比传统的训练方法快了最多 4.3 倍。
DNN 训练是在前向和后向通道计算中迭代进行的。在每轮迭代中,训练过程循环处理输入数据的一个 minibatch,并且更新模型参数。最常见的 DNN 并行化训练方法是一种被称为数据并行化的方法(见下图 1),这种方法把输入数据分散到各个 workers(加速器)中运行。
不幸的是,尽管在数据并行化加速方面有一些性能优化的进展,但若要放在云基础设施上训练就会产生很大的通信开销。而且,GPU 计算速度的飞快提升,更进一步地把所有模型训练的耗时瓶颈转向了通信环节。
不那么常见的并行化训练形式是模型的并行化(见下图 1),是把算子分散到各个 worker 上计算的,这在以往通常用于训练大型 DNN 模型。模型并行化也遇到了挑战:它不能高效地利用硬件资源,并且需要程序员决定怎样按照给定的硬件资源来分割特定的模型,这其实无形中加重了程序员的负担。
PipeDream 是微软研究院Fiddle项目开发的一个系统,它引入了流水线并行化,这是一种 DNN 并行化训练的新方法,结合了传统的 batch 内并行化(模型并行化和数据并行化)和 batch 间并行化(流水线)。
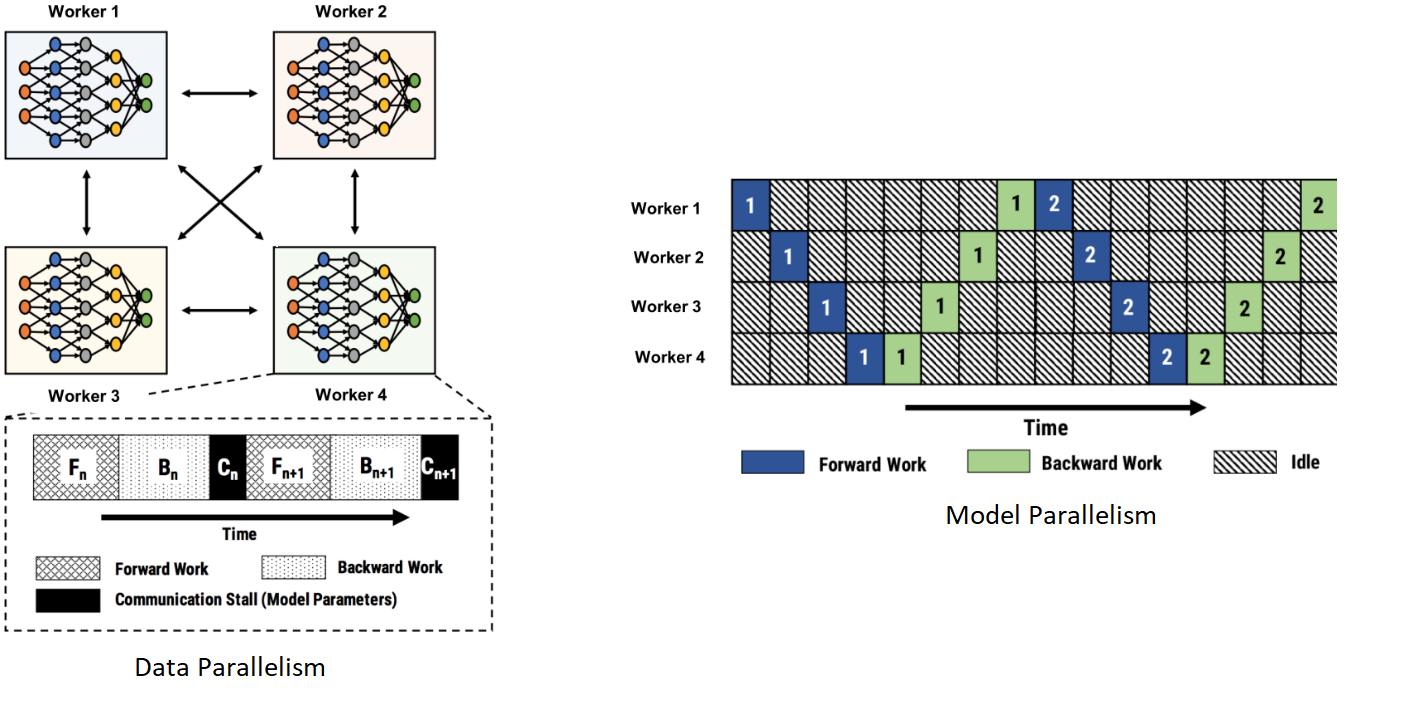
图 1:传统的 batch 内并行化训练方式(如数据并行化和模型并行化)对硬件利用率太低。左图中,数据并行化中的单个 worker 在交换梯度数据时不得不进行通信等待。右图是模型并行化,worker 之间只能同时处理一个 minibatch,这大大限制了硬件利用率。
使用流水线并行化训练来解决 batch 内的并行化限制
PipeDream 重新审视了模型的并行化,希望以此来优化性能,这与以往的动机不同,以前模型并行化是因为训练大型模型时,训练过程受限于数据集的大小。PipeDream 使用多个输入数据的流水线作业,来克服模型并行训练时硬件效率限制的问题。典型的流水线并行化设置涉及到不同 stage 之间 layer 的分割,每个 stage 都会被复制并且并行运行数据。流水线会被注入多个 batch,以使流水线满负荷运行在稳定状态。在大部分情况下,流水线并行化训练比数据并行化训练需要通信的数据要少很多,因为它只需要在两个 stage 边界之间传输 activation 和梯度。在稳定状态下,所有的 workers 时刻都在运转,不像模型并行化训练中会有停下来等待的时候(如下图所示)。
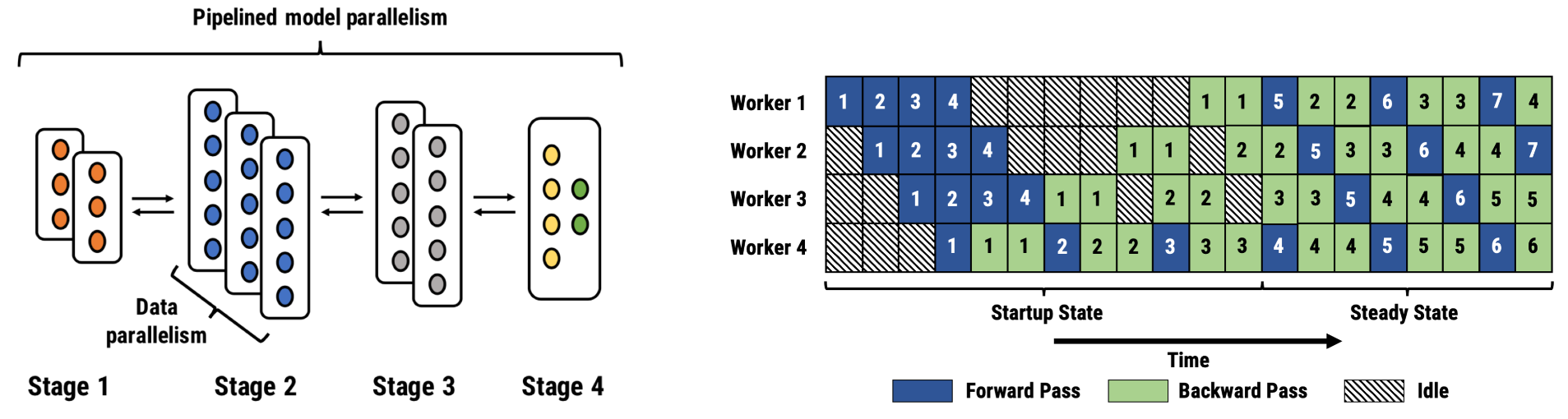
图 2:左图中,我们展示了一个流水线并行化的例子,8 块 GPU 被分配到 4 个 stage 中。通信只用于 stage 边界的 actiavtion 和梯度上。stage 1,2 和 3 通过对其各自的 stage 进行复制来保证流水线的负载平衡。右图展示了具有 4 个 worker 的一个流水线,展示了启动阶段和稳定阶段。在这个例子中,后向处理花费的时间是前向处理的两倍。
在 PipeDream 中克服流水线并行化训练的挑战
为了获得流水线并行化训练的潜在收益,PipeDream 必须克服三个主要挑战:
首先,PipeDream 必须在不同的输入数据间,协调双向流水线的工作。
然后,PipeDream 必须管理后向通道里的权重版本,从而在数值上能够正确计算梯度,并且在后向通道里使用的权重版本必须和前向通道里使用的相同。
最后,PipeDream 需要流水线里的所有 stage 都花费大致相同的计算时间,这是为了使流水线得到最大的通量(因为最慢的 stage 会成为流水线通量的瓶颈)。
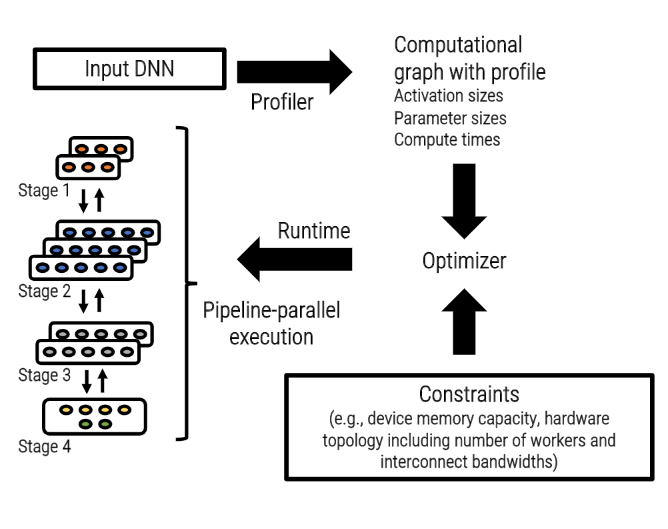
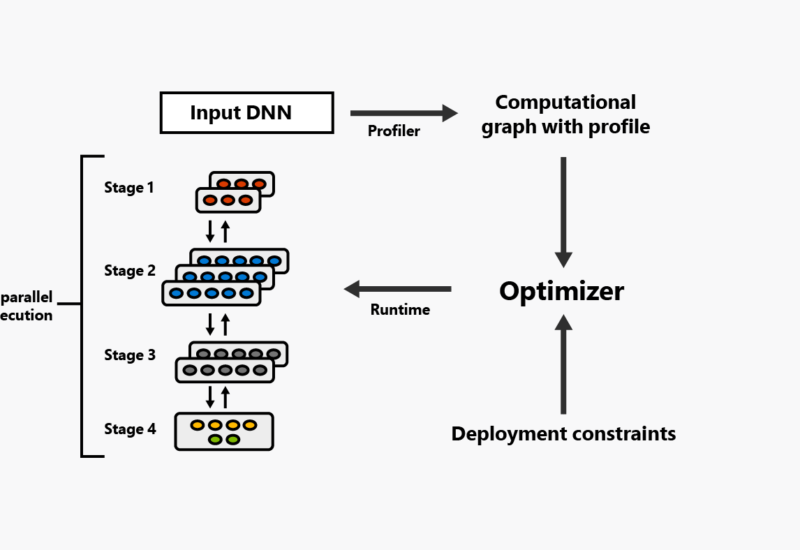
图 3:PipeDream 工作流程概览
图 3 展示了 PipeDream 工作流程的顶层概览。给定一个模型和硬件部署方式,PipeDream 在单个 GPU 上进行短暂的运行时性能分析后,可以自动决定怎样分割这些 DNN 算子,如何平衡不同 stage 之间的计算负载,而同时尽可能减少目标平台上的通信量。PipeDream 即使是在不同的模型(不同点体现在计算和通信方面)和不同的平台上(不同点体现在互联的网络拓扑和分层带宽上)也能够有效的均衡负载。
由于 DNN 并不总是在可用的 worker 间进行均等分割,所以 PipeDream 可能在某些 stage 上使用数据并行化——多个 worker 会被分配到给定的 stage 上,并行化地处理不同的 minibatch。PipeDream 使用称作 1F1B 的调度算法来使硬件保持满负荷运转,同时还能达到类似数据并行化的语义。
在 1F1B 的稳定状态下,每个 worker 为它所在的 stage 严格地切换前向和后向通道,保证资源的高利用率(可忽略的流水线暂停,没有流水线 flush),即使在常见情况下,后向通道花费的时间多于前向通道时也是如此。上面的图 2 已经通过例子展示了这一点。与数据并行化不同,1F1B 还使用不同版本的权重来维持统计有效性。最后,PipeDream 扩展了 1F1B,在数据并行 stage 上引入了循环调度策略,保证了后向通道计算的梯度被引流至前向通道对应的 worker 上。
PipeDream 是基于 PyTorch(PipeDream 的早期版本使用 Caffe)构建出来的。我们的评估围绕着 DNN 模型、数据集和硬件配置的不同组合进行,证实了 PipeDream 流水线并行化所带来的训练时间上的收益。相比于数据并行化训练,PipeDream 在多 GPU 机器上达到了很高的精确度,性能方面,在图像分类上有 5.3 倍提升,机器翻译上 3.1 倍提升,语言建模任务有 4.3 倍提升,视频字幕模型则有 3 倍提升。PipeDream 比模型并行化有 2.6 至 15 倍的性能提升,相比混合并行化有 1.9 倍提升。
如果你对 PipeDream 更多细节感兴趣,可以在 GitHub 上找到源码。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论