

本文公众号发布时标题为:《抛弃Hadoop,数据湖才能重获新生》
连数据湖都开始放弃 Hadoop 了?
十年前,Hadoop 是解决大规模数据分析的“白热化”方法,如今却被企业加速抛弃。曾经顶级的 Hadoop 供应商都在为生存而战,Cloudera 于本月完成了私有化过程,黯然退市。MapR 被 HPE 收购,成为 HPE Ezmeral 平台的一部分,该平台尚未在调查中显示所占据的市场份额。
从数据湖方向发力的 Databricks,却逃脱了“过时”的命运,于今年宣布获得 16 亿美元的融资。另一个大数据领域的新星——云数仓 Snowflake,去年一上市就创下近 12 年来最大 IPO 金额,成为行业领跑者。
行业日新月异,十年时间大数据的领导势力已经经历了一轮更替。面对新的浪潮,我们需要做的是将行业趋势和技术联系起来,思考技术之间的关联和背后不变的本质。
Databricks 和 Snowflake 做对了什么?
Hadoop 和数据湖都是 2006 年开始兴起的概念。为什么同时期兴起,经历十多年发展,Hadoop 逐渐衰落,数据湖反而迎来了热潮?
网络上有个说法:“公有云玩家”以零成本赠送 Hadoop 产品,加速了 Hortonworks 和 Cloudera 等厂商的衰落。但像 Snowflake 这样的新兴企业,它最大的合作伙伴却是 AWS 等云厂商。作为云厂商的生态系统合作伙伴,Snowflake 推动了大量 Amazon EC2 /S3 的销售。
在我们看来,Hadoop 只是数据湖的一种实现,而新一代数据湖通过拥抱云计算和开源社区,经历了新生。
Databricks 和 Snowflake 都抓住了 OLAP 的数据分析场景,基于兴起的云技术在数据存储和数据消费之间构建了新的中间数据抽象层(Data Virtualization),即屏蔽了底层系统的异构性,又提供了远超 Hadoop 生态系统的用户体验。这是他们能够成功的根本原因。或者用一句话描述,就是利用公有云的 Infrastructure,来做自己的“cloud on cloud”商业模式。
在云计算的背景下,计算存储相分离的设计概念逐渐清晰,促进了现代数据湖和数据仓库的架构在数据存储和数据消费端的进一步解耦以及业界标准接口的规范化,这使得开源社区通过这些标准接口贡献新技术的发展成为可能。
同时,公有云计算平台的出现,某种程度上加速了数据的垄断和计算需求的集中,推动业界对于数据以及数据处理做出更明确的需求定义,针对性地投入开源项目,以社区这种更灵活开放的方式促进技术发展,再反哺公有平台的进化和发展。
由云计算和开源合作推动相辅相成,才孵化出一系列有利于数据湖和数据仓库发展的突破性技术,孙骜表示 。
传统的关系型数据库,如 Oracle、DB2、MySQL、SQL SERVER 等采用行式存储法,而一些新兴分布式数据库所采用的列式存储相较于行式存储能加速 OLAP 工作负载的性能,这已经是众所周知的事实。但在我们看来,更加革命性的变化是列式存储格式的标准化。Parquet 和 ORC 的列式存储格式都是 2013 年发明的,随着时间的推移,它们已经被接受为业界通用的列式存储格式。数据是有惯性的,要对数据进行迁移和格式转换都需要算力来克服惯性;而数据的标准化格式意味着用户不再被某一特定的 OLAP 系统所绑定(locked in),而是可以根据需要,选择最合适的引擎来处理自己的数据。
第二大突破性技术是分布式查询引擎的出现,如 SparkSQL、Presto 等。随着数据存储由中心式向分布式演进,如何在分布式系统之上提供快速高效的查询功能成为一大挑战,而众多 MPP 架构的查询引擎的出现很好地解决了这个问题。SQL 查询不再是传统数据库或者数据仓库的独门秘籍。
在解决了分布式查询的问题之后,下一个问题是,对于存储于数据湖中的数据,很多是非结构化的和半结构化的,如何对它们进行有效地组织和查询呢?在 2016 到 2017 年之间,Delta Lake、Iceberg、Hudi 相继诞生。这些类似的产品在相近的时间同时出现,表明它们都解决了业界所亟需解决的问题。这个问题就是,传统数据湖是为大数据、大数据集而构建的,它不擅长进行真正快速的 SQL 查询,并没有提供有效的方法将数据组织成表的结构。由此,在缺乏有效的数据组织和查询能力的情况下,数据湖就很容易变成数据沼泽(data swamp)。
利用云基础架构,是成功关键
如果仔细了解一下 Databricks 和 Snowflake 的发展历程,可以发现两者的出发点有所不同。Databricks 是立足于数据湖,进行了向数据仓库方向的演化,提出了湖仓一体的理念;而 Snowflake 在创建之初就是为了提供现代版的数据仓库,近些年来也开始引入数据湖的概念,但本质上说它提供的还是一个数据仓库。
Snowflake 利用云技术革新了传统数据仓库。它提供了一个基于公有云的、完全托管的数据仓库,把传统的软硬件一体的消费模式改造为了软件服务的模式(Software as a Service)。
无论是存储还是计算,Snowflake 都利用了公有云提供的基础设施,从而使任何人都可以在云端使用数据仓库服务。
另一方面,传统的数据湖在数据分析上存在不足,不能很好地提供 OLAP 场景的支持。因此,Databricks 通过 Delta Lake 提供的表结构和 Spark 提供的计算引擎,构建了一套完整的基于数据湖的 OLAP 解决方案。Databricks 的愿景是基于数据湖提供包括 AI 和 BI 在内的企业数据分析业务的一站式解决方案。
与 Snowflake 相似的是,Databricks 也充分利用了云基础架构提供的存储和计算服务,在其上构建了入门成本低、定价随使用而弹性扩展的软件服务方案。
存储正在经历新一轮革命:从 Hadoop 到对象存储
数据湖和 Hadoop 并不是竞争关系。作为一种架构,数据湖会将其它技术整合到一起,而 Hadoop 则成为了一种可以用来构建数据湖的组件。换句话说,Hadoop 和数据湖的关系是互补的,在可预见的未来,随着数据湖继续流行,Hadoop 还将继续存在。
然而,数据湖会抛弃 Hadoop 转而支持其他技术吗?这最终有可能会发生,因为作为一种综合性技术架构,除了 Hadoop HDFS 之外,数据湖还可以选择“对象存储”作为它的核心存储。
现在越来越多的,像 Databricks、Snowflake 这样的数据平台类创业公司选择采用对象存储作为存储的核心。从头开始搭建一个分布式存储很难,其中的坑只有踩过的人才知道。所谓“计算出了问题大不了重试,而数据出了问题则是真出了问题”。所以很多数据平台类创业公司如 Databricks、Snowflake 等都会借着计算存储分离的趋势,选择公有云提供的存储服务作为它们的数据和元数据存储,而公有云上最通用的分布式存储就是对象存储。例如 Databricks 的论文标题就是“Delta Lake: High Performance ACID Table Storage over Cloud Object Stores”。
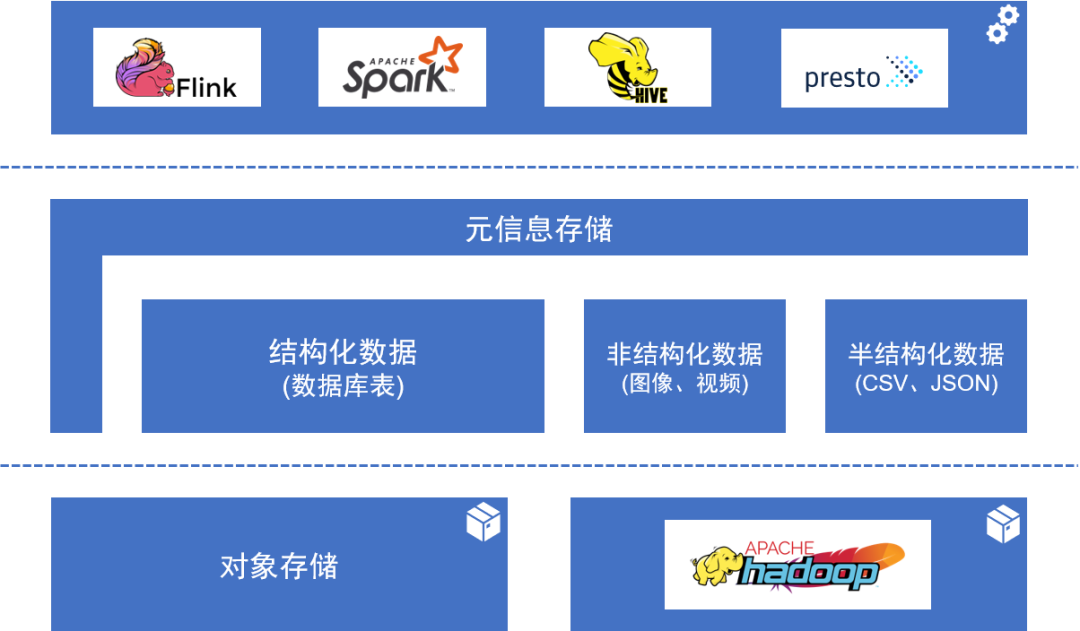
典型的数据湖架构
为什么他们会选择采用对象存储作为存储的核心?
滕昱表示采用对象存储作为存储的核心主要因素有四个。
从技术角度来说,首先,对象存储即为非结构化存储,数据以原始对象的形式存在。这点贴合数据湖对于先存储原始数据,再读取完整数据信息后续分析的要求。
其次,对象存储拥有更先进的分布式系统架构,在可扩展性和跨站点部署上,比传统存储更具优势。由于对象存储简化了文件系统中的一些特性,没有原生的层级目录树结构,对象之间几乎没有关联性,因此对象存储的元数据设计能更为简单,能够提供更好的扩展性。此外,数据湖业务往往也需要底层存储提供多站点备份和访问的功能,而绝大部分对象存储原生支持多站点部署。通常用户只要配置数据的复制规则,对象存储就会建立起互联的通道,将增量和 / 或存量数据进行同步。对于配置了规则的数据,你可以在其中任何一个站点进行访问,由于跨站点的数据具备最终一致性,在有限可预期的时间内,用户会获取到最新的数据。AWS 在 Storage Day 上刚刚宣布的“S3 Multi-Region Access Points”就是一例。
第三,在协议层面,由 AWS 提出的 S3 协议已经是对象存储事实上的通用协议,这个协议在设计之初就考虑到了云存储的场景,可以说对象存储在协议层就是云原生的协议,在数据接口的选择和使用上更具灵活性。
第四,对象存储本身就是应云存储而生,一开始起家的用户场景即为二级存储备份场景,本身就具备了低价的特性。
因此,对象存储是云时代的产物,支持原始数据存储、分布式可扩展、高灵活性、低价,都是对象存储之所以被选择的原因。可以预计在未来会有更多的数据业务完全基于对象存储而构建。
数据湖存储架构落地实践
从技术上说,无论是数据仓库、数据湖还是 S3 存储,都是数据存储的一种方式,所以从某种程度上来说,存储行业正在迅速演变为数据业务行业。在数据湖的探索上,孙骜也分享了一些戴尔科技集团 OSA(Object, Stream and Analytics)团队的实践经验。
市场上的很多数据平台公司还是利用 s3a 协议而非原生的 s3 协议来访问对象存储的服务。例如 Databricks 虽然在他们的论文中提到他们在对象存储之上提供了一层表结构的服务,即 Delta Lake。但实际上 Delta Lake 与底层对象存储交互的协议仍然用的是 s3a,即对象存储版本的 HDFS 协议。
但是,从对象存储的角度来看,s3a 协议由于多了一层协议转换,并不能完全发挥高性能对象存储的延时和吞吐量的优势。因此,OSA 研发团队认为基于原生 s3 协议构建数据平台的存储访问层应该能大大提升存储层的访问能力。
同时,对象存储的部署方式也需要从单一的公有云变成混合云 / 多云的混合架构。“Latency matters”,如何在尽可能接近数据产生端进行实时、近实时处理是下一代数据湖需要直面的问题。更灵活的架构也会帮助企业级用户打消对于数据平台锁定的担忧(locked in/lock down)。
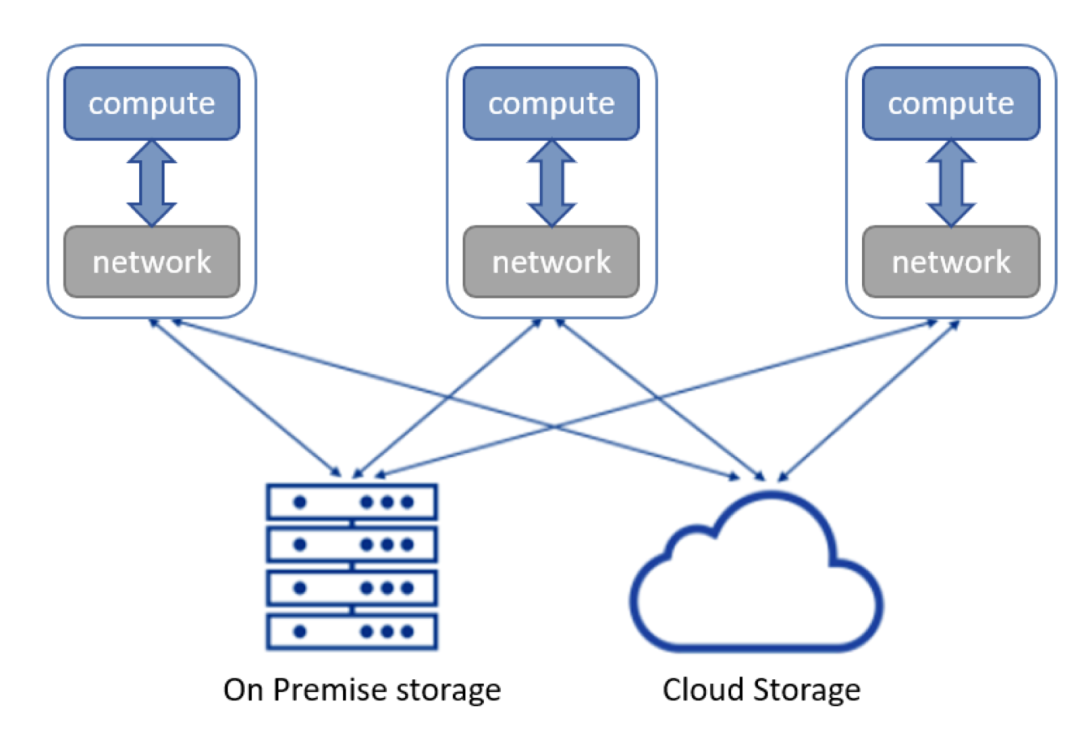
新一代数据平台的基本架构都是存算分离,即计算层和存储层是松耦合的。计算层无状态,所有的数据、元数据以及计算产生的中间数据都会存储于存储层之中。这一架构的优势包括更好的扩展性(计算、存储独立扩展),更好的可用性(计算层的失效不影响存储,因此能够很快恢复),以及更低的成本。为了适应存算分离的架构,对象存储本身也需要进一步发展。
在这个发展趋势中 OSA 的产品研发也经历了从软件定义(Software Defined)到云原生(Cloud Native)的改造,来适应数据平台的需要。
“尽管我们从一开始就使用了 Scale-out 架构,基于标准 x86 服务器构建,所以很早我们就认为自己已经做到了软件定义。但是在实践中,我们发现部署在服务器上的存储产品还有复杂的运维问题、动态扩展问题等等,带来的用户体验并不完美。与此同时,以容器、Kubernetes 为代表的技术的出现,颠覆了原来的软件定义存储,可以让存储做到云原生,从提供存储产品转型为提供存储服务(Storage as a Service)。Kubernetes 提供了强大的集群管理功能,而容器提供了低开销的资源隔离和控制方案。”
借助于这两大技术,OSA 研发团队彻底革新了对象存储的技术栈,用微服务的方式拆分巨型单体服务,将存算分离的架构应用到对象存储内部。通过划分各个存储服务的边界,制订服务合约,将需要直接访问磁盘 IO 的功能集中到一两个服务中,实现了绝大多数服务的无状态化。改造之后,对象存储能够轻松运行在资源相对有限的边缘节点之上。元数据服务可以根据计算负载单独扩容,而不受限于底层存储资源。改造之后,对象存储本身也是 Kubernetes 所托管的诸多服务之一,只要集群中有足够的计算和存储资源,对象存储就能根据 IO 负载来动态地 Scale up 或者 Scale down,达到完全的弹性,而这也是云原生存储的最终目标之一。
所以孙骜认为,想要适应存算分离的大趋势,不是简单地把现有存储对接到计算层就可以完成的,存储本身要经历新一轮架构革命才能更好地服务于计算层。
技术并非完美,当前对象存储存在的四个挑战
在架构之外,数据平台型业务也给对象存储的特性提出了若干新的挑战。
第一个挑战是数据分析型业务所需要的性能要远高于数据备份的场景,对象存储需要能够提供与计算需求相匹配的大带宽与低延时。闪存技术的发展、NVMe over Fabrics 标准的提出使得高性能对象存储成为可能。在选择网络的时候,建议选择基于以太网的 RoCE 或者 TCP 协议作为网络传输层,能同时兼顾性能、成本和部署的灵活性。同时,要完全发挥 NVMe 闪存的高并发性,也需要对数据链路做彻底的异步化和无锁化改造,并且 OSA 研发团队倾向于选择用户态编程模型,因为它对内核的依赖小,对云原生环境下的复杂部署更友好。
此外,在写入模式上,虽然追加写是在硬盘时代提出的思想,但在闪存时代依然是一个优秀的选择。由于闪存的物理特性,闪存的固件需要对内部的块做后台的垃圾扫描和回收,一旦闪存找不到完全空闲的块,那再次写入就会需要经过读取 - 修改 - 写入的路径,会大大影响闪存的写入性能。追加写的方式能够减少碎片,减轻闪存后台垃圾回收的压力。同时,对于新兴的低成本、高密度的 QLC 闪存而言,追加写也是绝佳的搭档。
另一方面,对象存储还需要根据业务场景来优化性能。例如,高带宽指的不仅仅是性能测试时能达到的带宽,因为传统性能测试往往使用 GB 级别甚至更大的对象,达到高带宽相对容易。然而,在数据分析的场景中,所要处理的是中等或者较大的对象(32Kb -1024Kb 级别),在这样的业务场景中,很可能带宽瓶颈不在底层的 NVMe 吞吐率上,而在元数据服务或者读写流水线的衔接上,这就需要依据数据分析的业务特征在读写全链路上优化对象存储的带宽和延迟。
第二个挑战来自于数据分析所包含的众多元数据操作。因此对象存储不仅要能够提供大带宽,还要在处理小对象和元数据操作如 list 时提供足够的性能。这就比较考验对象存储的元数据管理能力。
孙骜认为,“根据我们的经验,基于 B-tree 的某些高效变种来存储元数据在写放大、读延时等方面依然要优于 LSM tree。”
工业界更常用的 Bw-tree 就是一例。Bw-tree 整体上仍然是一棵 B-tree,但是其中的每个节点则借鉴了 LSM tree 的 log structured 设计,每个节点有一个 base record 和一组 delta log。Bw-tree 还引入了 logical page 和 physical page 的概念,两者通过一张 mapping table 进行关联。
通过这些设计,Bw-tree 能够避免过于频繁的 page split/merge 操作以及 dirty page 向上的传导性,提高了写入的效率,又避免了 LSM tree 在后台进行的大量分层 merge 操作。同时,整棵树在点查询和区域查询的效率上依然接近传统 B-tree,优于 LSM tree。
第三个挑战是对象存储如何兼顾性能和成本。数据湖中存储了庞大的企业数据,但在任一时间点,可能只有一小部分数据是被数据分析业务所需要的。如果所有数据都放在性能最优的物理介质上(比如非易失性内存),那么成本将变得过高,失去了云存储的经济性,而如果在对象存储的前端再加一层 cache 层,无疑也会增加整个系统的复杂度。因此如何有效识别冷热数据,并将它们分区放置是对象存储需要解决的问题。
第一种简单的方式,是把选择权交给用户。用户通过设置一些固定的规则(如根据写入时间、最后访问时间等)触发数据在不同介质之间的迁移。第二种方式,是通过对历史访问数据的分析,让存储系统来预测单个对象的生命周期,实现某种程度上的智能分层。更高级的方式,则是让存储系统能够识别计算负载的模式特征,根据模式特征识别不同对象之间的关联性,根据一组对象的访问特点来决定分层策略。例如,如果某个工作负载的特征是依次读取某一组对象,那么存储层就可以提前预取将要被访问的对象,来进一步加速计算。
第四个挑战是对象存储如何与开源生态相结合。现阶段比较成熟的在数据湖之上提供表结构的开源产品是 Delta Lake、Iceberg 和 Hudi。对这三款产品 OSA 研发团队做了一些预研和实验。Hudi 基于 Hadoop 生态系统,特别是和 Hive 有深度绑定。Delta Lake 的设计非常优秀,不过由于是 Databricks 的产品,它还有一个不开源的商业版,许多高级特性只有在商业版上才提供。同样由于 Databricks 的关系,在计算层上,Delta Lake 和 Apache Spark 深度绑定。
与前两者相比,Iceberg 的接口抽象特别清晰,灵活性也可以完美适配,在计算层也可以跟 Apache Flink、Apache Spark 等计算层解决方案无缝集成。因此,作为长期企业级对象存储解决方案的提供者,在对这些开源方案进行对比研究后,在现阶段 OSA 研发团队选择了 Apache Iceberg 作为其开源解决方案的组成部分,未来也不排除将和更多的开源产品集成,为客户提供完整的解决方案。
为了更好地适配底层的对象存储,OSA 研发团队为 Iceberg 做了一个通用的 S3 表管理组件(S3 Catalog)。在 S3 的标准 API 中,上传数据需要预先知道对象的大小,因此在追加上传的场景下,其调用方法无法像 HDFS 那样简洁。所以在具体实现中,追加写的操作需要在本地预先处理,并以整体上传。第二,利用第三方锁的实现,解决了对象存储中不支持原子重命名操作的挑战。
除此之外,OSA 研发团队还提供了一个基于 Dell EMC 商业对象存储 ECS 的专属表管理组件(ECS Catalog)。ECS 支持 Append 语义,使用 Append 的操作可以完美应对顺序写入未知长度文件的场景。ECS 还支持类 compare-and-swap (CAS) 语义。在并发提交的场景下,ECS 支持使用 If-Match 和 If-None-Match 对对象进行 CAS 操作,来实现原子化重命名的操作。
超越数据湖,展望新一代数据平台
在滕昱看来,下一代数据平台有更广阔的范畴和视角,超越当前人们对数据湖的理解。
它将不光涵盖传统的数据中心或者云端部署的范畴,结合日益发展的边缘计算,将来的数据平台将会涵盖从传感器到边缘节点到数据中心到云端一整套生态系统。
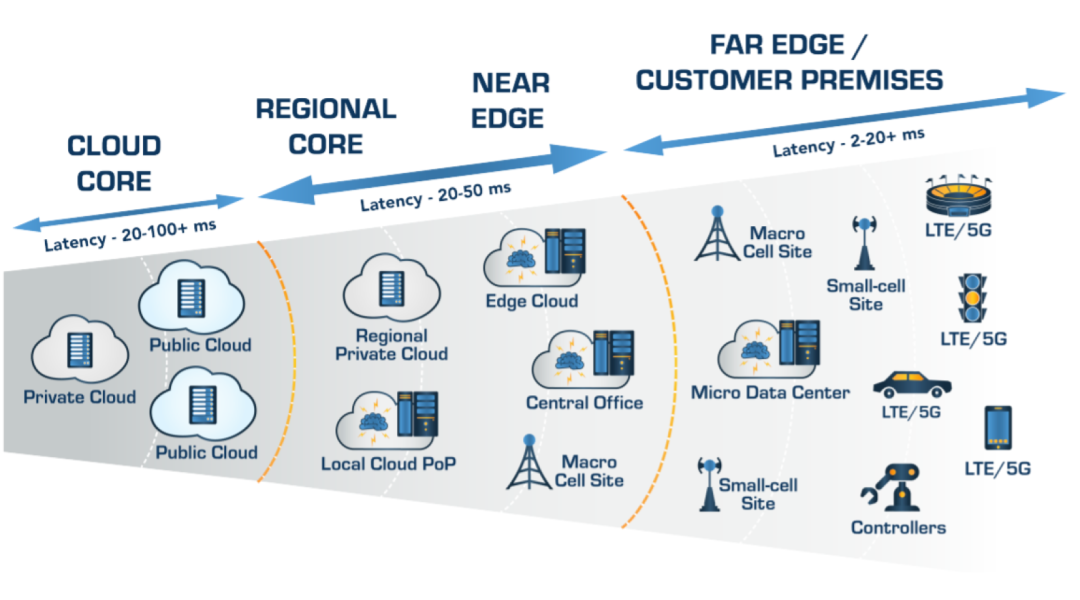
Source: VMware 调研白皮书《基于全栈云基础架构,构建企业级业务创新平台》
在这套生态系统上,数据是主角。平台的使用者会慢慢弱化对底层系统的依赖,而更多地关注于数据处理管道和基于业务逻辑的数据处理逻辑需求的定义。基于此,平台对于使用者的专业性要求也会逐渐降低,越来越多的人能够利用数据平台从数据中获取信息价值。
存算分离将是下一代数据平台的标准架构。
存储层将更统一,而计算层根据负载也将拥有更多的灵活性。和传统数据湖相似,数据依旧会统一存储在数据湖中,先存储后消费。但是,对于数据的结构化定义要求会越来越不重要,数据清洗或结构化的转化将更多地由平台智能化或者根据更人性化的配置定义完成。至于数据在各个环节中的存储,也将隐藏在平台内部。数据孤岛将逐渐消亡,原因很简单,如果数据湖本身能够提供足够好的 OLAP 支持,为什么还要把数据拷贝一份再放到数据仓库中呢?
在计算层面,数据平台应该是完全开放的。
根据具体的业务需要,用户可以自行选择灵活度更高的 Spark 或者 Flink 计算框架,或者是集成度更好的一体化方案。下一代数据平台也应该提供强大的跨表查询能力。无论数据是直接存储在对象存储中、存储在 Iceberg 等表结构中、还是存储在外部的数据库中,数据平台都支持对这些表进行联合查询。
存储和计算之间会进化出新的数据抽象层(现在正在发生)。
更多统一的业界标准如 Iceberg 等,会越来越多地出现。数据产生者和数据消费者基于这层抽象层协同合作。通过这层数据抽象层,数据平台会慢慢将各个角色的数据消费者从系统部署与理解的细节中解脱出来,以关注业务逻辑本身。
正如 Iceberg 创始人之一 Ryan Blue 所说,数据平台的使用者应该更多关心自己的数据和数据产品,把剩下的问题交给数据平台基础架构去解决。
同时从应用场景上来说,在传统的离线数据分析场景之外,实时数据分析的业务场景正在增加。以 Spark micro batch 为代表的近实时框架可以解决一部分的业务需求,但对于延时要求更高的场景,实时分析的框架还有待发展。以流式存储为依托的实时分析框架依然是个尚待开发的领域。另外,目前的数据平台对结构化和半结构化数据已经有了比较好的支持,但对于非结构化数据,如何为它们建立高效的索引来加速查询和分析,依然是业界悬而未决的难题。
滕昱认为,未来的数据平台应该是涵盖传感器、边缘节点、数据中心和云端,存储计算相分离,依赖数据抽象层,为多种多样的数据产生和消费者,提供集成了离线分析、近实时分析和实时分析数据处理链路的统一平台,提供更简单和标准化的接口供用户使用,让用户聚焦于从数据中获取价值。
嘉宾简介:
滕昱,Pravega 中国社区创始人,戴尔科技集团 OSA(Object, Stream and Analytics)软件开发总监。自 2007 年加入戴尔科技集团中国研发集团以来,一直专注于分布式系统领域,先后参与了前后 2 代 Dell EMC 对象存储产品的研发及商业化工作,正在积极拥抱新的混合云 / 多云和实时流处理时代。从 2016 年开始,参与 Pravega 开源项目,活跃在多个开源社区。
孙骜,技术团队杰出成员(Distinguished Member of Technical Staff),负责戴尔科技集团分布式对象存储系统架构设计和开发。
雷璐,高级主管工程师(Senior Principal Engineer),专注于戴尔科技集团流处理平台 SDP(Streaming Data Platform)系统架构的设计和开发。
本文选自《中国卓越技术团队访谈录》(2021 年第五季),扫描二维码查看更多独家专访↓

《中国顶尖技术团队访谈录》品牌升级,现正式更名为《中国卓越技术团队访谈录》,这是 InfoQ 打造的重磅内容产品,以各个国内优秀企业的 IT 技术团队为线索策划系列采访,希望向外界传递杰出技术团队的做事方法 / 技术实践,让开发者了解他们的知识积累、技术演进、产品锤炼与团队文化等,并从中获得有价值的见解。
如果你身处传统企业经历了完整的数字化转型过程或者正在互联网公司进行创新技术的研发,并希望 InfoQ 可以关注并采访你所在的技术团队,可以添加微信:whitecrow-tina,请注明来意及公司名称。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论