

深度学习诞生 10 年,LLM (大语言模型技术)终于带来 AI 平民化。ChatGPT 爆火后,AIGC 浪潮席卷全球。AI 作画、AI 写歌、AI 生成视频…… 全球大厂纷纷推出 AIGC 应用,让 AI 变得“触手可及”。从技术角度看,基于海量数据构建的大模型能够进行相对独立的推理和判断,让企业看到了 AI 与 Data 的技术融合已经成为当下重要的发展趋势之一。
如今,AI 与企业的数据基础设施融合到了什么程度?企业是否要选择一款 AI 数据平台?AI for Data 如今在企业生产中发挥着怎样的价值?为了探讨问题的答案,InfoQ 联合云器科技策划了《极客有约》特别版——《再谈数据架构》系列直播。第二期,我们邀请到了 前阿里巴巴副总裁贾扬清、云器科技联合创始人 & CTO 关涛 以及 OtterTune 联合创始人张伯翰,畅谈以下话题:
数据库、大数据和 AI,哪个更重要?
“AI for Data”与“Data for AI”有何不同?
企业数据平台要不要结合 AI?
“模型即数据”?模型平台可以完全替代数据平台吗?
企业需要怎样的一体化的 AI 数据平台?
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
数据库、大数据和 AI,哪个更重要?
贾扬清:数据库、大数据和 AI 齐头并进、相辅相成。这一轮大模型创业公司当中,有很多公司首先要招数据处理、数据清洗、数据标注、数据挖掘等等这一系列的工程师——又回到了数据上。
张伯翰:数据库、大数据和 AI 三者之间两两融合。当 AI 数据量特别大的时候就需要去考虑分布式模型训练,这是大数据和 AI 融合要考虑的点。AI 和数据库之间的关系要从 Data for AI 和 AI for Data 两个角度来看。
关涛:数据平台需要把 AI 作为“一等公民”支持,而不是只做数仓,这就是 Data for AI 的关键。同时,DBA 的这种人工调优的模式并不高效,怎么解放人力 / 提升效率?AI for Data 就是一个关键项。
InfoQ:数据库、大数据和 AI 都是当下热门的技术方向,三者之间的关系是怎样的?
贾扬清:我觉得数据跟 AI 一直是相辅相成的关系。2015-2016 年,行业内认为做 AI 还是应该关注计算和算法,寻找更优的模型在现有数据库 / 数据集上面进行更好地统计。ImageNet 数据集应该是大家第一次认识到:数据能够赋能 AI 做更加宽广的探索。ImageNet 以及当时一系列的自然语言、语音等模块的数据让行业在神经网络方面有更多的探索。
因此我认为在过去十年当中,我们其实是在数据和另外一个系统的红利上面来寻找更多更好的算法,比如 CNN、RNN、LSTM,包括现在比较流行的 GPT 等一系列的算法。如今,算法又发展到了一个新高度。基于像 Transformer 这样的模式,算法能够有能力来处理,或者说理解、压缩更多数据了。
所以大家可以看到,这一轮行业内的大模型创业公司当中,有很多公司首先要招数据处理、数据清洗、数据标注、数据挖掘等等这一系列的工程师——又回到了数据上。随着数据量越来越大,算法越来越复杂,系统变得越来越重要。
2011 年行业内讨论大模型的时候,有一种说法叫做:参数服务器 (Parameter server)。当时,大家以类似互联网的传统思维来做大模型:用一堆相对而言性能比较差、不稳定的机器来解决共同训练的问题。但是随着算法越来越多、越来越复杂,传统的高性能计算系统变得越来越流行。
如今,我们会发现所有人都在买 GPU 机器。系统变得越来越大并且和传统的高性能计算的结合程度越来越深之后,我们能够以更加高的效率来处理一系列的数据和一些算法,我觉得这个是今天我们看到的,数据、人工智能和系统这三块齐头并进的一个状态。
其实一直以来,人工智能和数据领域都有融合的部分。在互联网时代,人工智能和数据领域融合的地方叫做广告搜索和推荐。
张伯翰:数据库、大数据和 AI 都是现在比较火的话题,我觉得三者之间是两两融合的关系。数据库和大数据方面,像 Databricks、Snowflake 主要在做 Data warehouse 或者 ETL 的数据处理,也在往 AI 方面发展,方向上都是往数据方面融合的。谈及大数据和 AI 的融合,其实我们可以看到 Spark 也做了很多 AI 方向的布局,如 SparkML。我觉得大数据是平台化的,当 AI 数据量特别大的时候就需要去考虑分布式模型训练,这是大数据和 AI 融合要考虑的点。
AI 和数据库之间的关系分为两类,一个 DB for AI,另一个是 AI for DB。目前,有些企业在数据库内部做一些机器学习方面的一些工作,可以省去 ETL 或者是各种数据倒来倒去的操作,这个是 AI for DB。我觉得这方面还是挺有市场需求的,因为很多时候企业不需要很复杂的 AI 模型,仅需要去做一些简单的数据处理和预测工作。我是做数据库的,所以主要关注 AI for DB。企业想利用 AI 来优化数据库,可以通过一些训练的数据去学习优化数据库的经验和规则、自动大规模优化数据库。
关涛:伯翰通常把 Snowflake 定义到数据库领域里边,我把他可能更细分到 BigData;数据库领域更像指代 transactional Processing(事务处理),所以我把像 Oracle 这类的公司定义成数据库的公司,然后把 Snowflake、Databricks 定义成大数据的公司,其他还有一些公司归属于 AI 类。
三个领域从发展阶段看,如下图所示。横轴可以理解为时间,共 5 个阶段;纵轴可以理解为影响力和预期;图上的曲线表现了技术发展到高热度期、发展期以及普惠期的过程。
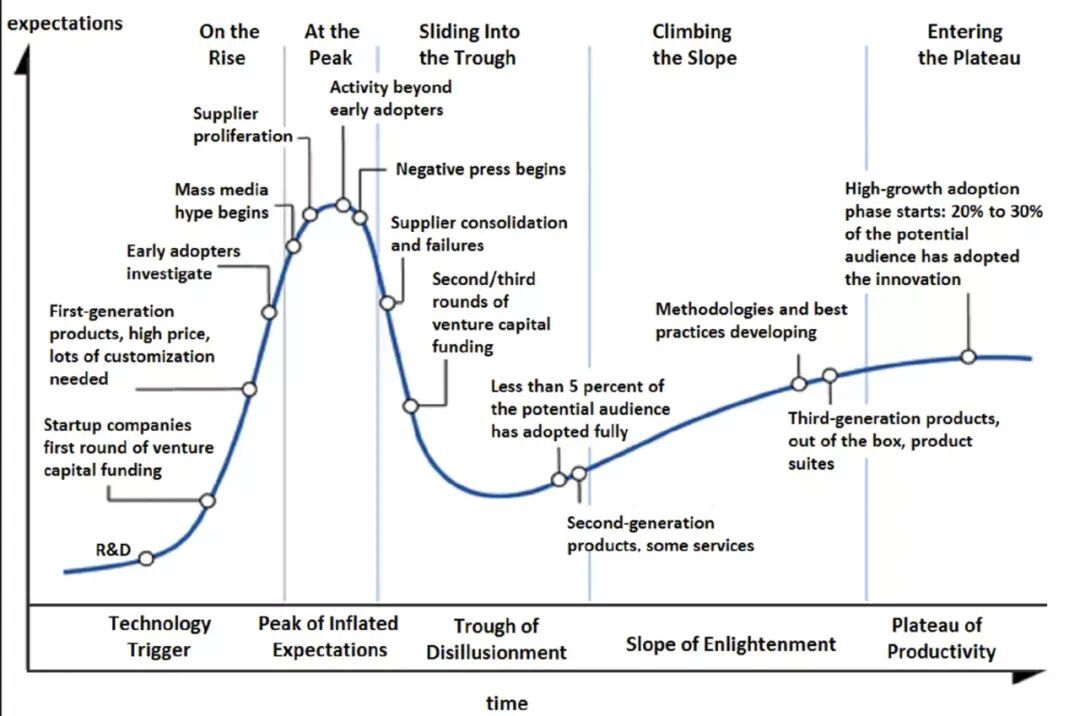
数据库发展了 50 年,如果以 Oracle 为代表,那么它处在下图中的红圈位置,表示如今处在普惠期。BigData 发展了 20 年,大概在绿圈的位置。其中,美国大数据市场可能从发展期可能到了普惠期,中国大数据市场可能从爬升期开始到了发展期。
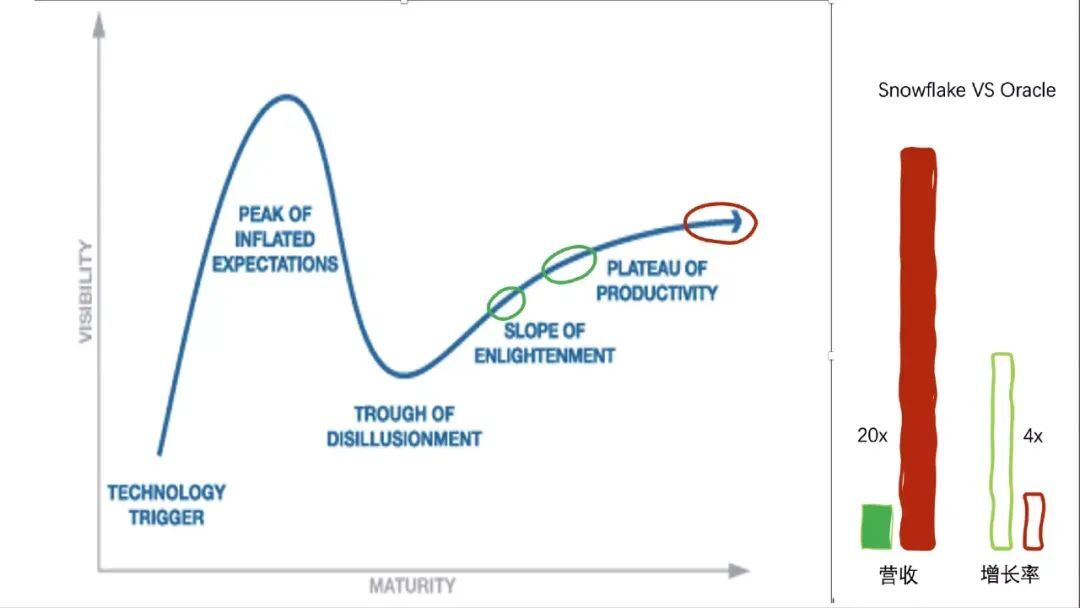
对比这两张图,你会发现:数据库发展了 50 年,从营收层面看,Oracle 的营收实际上是 Snowflake 的 20 倍。当一个领域进入到普惠期的时候,它会有非常高的市场占有率。如果从增长率的角度来看,Oracle 低一些,大概 17%;Snowflake 是 Oracle 的 4 倍,大概 60% 多。如果按照这个增速的话,理论上大概也许 8 年半到 9 年的时候,Snowflake 能超越 Oracle。技术的发展过程可见一斑。
我们用一个例子来理解这三者的融合关系。在视频直播推荐场景,我们发现很多客户需要通过 AI 的方式把很多非结构化的数据抽取出来用于推荐,同时沉淀结构化的用户画像数据存放在数据库中。这两个数据一定要融合在一起,因为推荐系统左边是推荐的内容,右边是客户的客群,只有通过推荐的内容在客群上做圈选融合在一起,才能做出推荐系统。我们发现,企业需要用 AI 的能力去做部分的数据计算,同时需要用数据系统做很多计算。
伯翰刚才讲了两个大的方向,一个方向叫做 Data for AI,一个叫做 AI for Data。前者大家可能比较好理解,刚才我举的那个推荐的例子就是这样;后者其实是 AI for system 的一个子集,伯翰他们做的是 AI for Database,还有 AI for BigData system,甚至 AI for AI system。
AI for Data 实际上是目前比较火的一个创业方向。很多人觉得 DBA 的这种靠人工调优的模式其实不太适用,而且大数据模型其实带来了更好的人的智能体的能力,它真的可以替代人做很多事情。怎么解放人力?AI for Data 就是一个关键项。
“AI for Data”与“Data for AI”有何不同?
贾扬清:我更关注 Data for AI 中海量异构数据存储和管理,AI 计算范式的支持,以及 Data 和 AI 结合带来的新产品形态。
张伯翰:我发现 DBA 越来越少了,如果数据库能自己调优自己的话,对整个行业是一个很好的事。从更深的技术角度来看,依赖经验和通过 AI 机器学习经验,两者并不是二选一的情况,而是相互补充的。
贾扬清:AI for Data 可能是大家在通用系统领域相对比较容易理解的一个事情,因为任何一个系统都有非常多的需要调优、管控等等的工作。以前大家靠经验或者一些指标来判断什么时候拉起机器做计算,现在大家可以基于时序的统计数据等方式加上一个预测的算法来做,相当于现在把以前的一些需要在系统里面做决策的过程,交给 AI 来简化。
我自己更关注 Data for AI 的三方面问题。
第一,海量异构数据存储和管理。
第二,对 AI 计算范式的支持。Data for AI 在 AI 算法内部不只是作为一个 Data Provider,也有很多的应用。
譬如说我们在做大模型,包括在做广告推荐的时候,经常会遇到一个算法或者一个模块叫做 embedding。embedding 的意思是我们把很多的文本变成一个高维的数据的向量,把它放到一个很大的 KV 里头去做。以前我在 Facebook 的时候,也遇到过这样的情况:我自己来管理哪些 embedding 更热,哪些 embedding 更冷,然后来做 cache 等等。
后来,我们发现这就是一个标准的 KV 数据库,以前 KV 数据库里面所有的应用、想法、思路,都可以相应地互通过来。这件事情让我意识到,Data for AI 在 AI 算法内部不光只是作为一个 Data Provider,也有很多的应用。
第三,Data 和 AI 的结合产生了新的各种各样的产品形态,比如最近大家比较关注的向量数据库。其实早在 2017 年的时候,我们在 Facebook 的时候和 AI 的研究院一块做了一个算法叫做 Faiss,应该叫 Facebook Approximate Nearest Neighbor Search。今天,很多的向量数据库的背后也都是用 Faiss 来做它的一个核心引擎。Faiss 更多专注在计算,需要叠加更多内容才能变成一个向量数据库产品。
向量数据库公司 Pinecone 融了很多钱,那么它的业务空间有多大,它是否和传统的数据库之间有足够的 differentiate。这个事情目前我们还不太确定,但是我们比较确定的一点是,因为各种新的计算模式的产生,使得我们在数据库的领域和 AI 的领域有更多的结合,结合出一个“两边都像,但是两边都得用到,和以前的形态都不太一样”这样一种新的产品形态。
张伯翰:AI for Data 的做法其实就是通过机器学习或者 AI,或者模型去学习那些规则。我是做 AI for Database 的,其实是 AI for system 的一个子集,也可以是 AI for Spark,AI for TensorFlow,我们目前主要是做 AI for PostgreSQL and AI for MySQL,做数据库的调优。
Oracle 几年前宣布了自治化数据库,大概的意思是使用 AI 让数据库更加智能,减少 DBA 的负担,相当于自己优化自己。MySQL 也做了自己的自治化数据库。将 AI 与自动优化结合不仅是数据库厂商的一个技术方向,也是客户认可的趋势。我发现 DBA 越来越少了,如果数据库能自己调优自己的话,对整个行业是一个很好的事。从更深的技术角度来看,依赖经验和通过 AI 机器学习经验,两者并不是二选一的情况,而是相互补充的。客户关注的是可靠性和可解释性,其中可解释性非常重要,我认为不可能是只使用 AI 就能胜任的。
此外,我们发现很多机器学习的一些实践,在 AI for Databricks 实践,最后发现难点并不是 AI 的模型,而是怎么去和数据库结合,怎么收集这些训练数据,怎么把推荐自动地放到数据库上。比如,有些参数的调整是需要重启数据库才能生效的,但是大部分的生产数据库不可能支持重启数据库改参数,因为这样会有挺多的宕机时间,风险较大。这个难点是我们创业这段时间看到的,也是我们数据库公司重点在做的方向。我们做的事情就是让一个完全不懂数据库的人能更好地去优化数据库,能更快解决数据库的问题。
企业数据平台要不要结合 AI?
关涛:与 AI 结合其实是很新的一个技术方向,也还远没有定型,平台建设容易踏空 / 落后。所以,企业数据平台的设计需要考虑面向未来的扩展,比如开放性和可插拔 AI 计算能力。
关涛:湖仓一体的架构是下一代数据平台的必选项。系统设计的简单化(一体化)是终极目标。
关涛:大家都会觉得关系型的计算模型可能不够,需要有更多 AI 的能力。从这个角度出发看企业的痛点,我大概总结了三点。
第一,现在传统数仓架构其实并不能够很好地支撑 AI。当前很多企业的数据基础设施不是为 AI 设计的,还是只面向数据。从数据库出发,数据库是纯结构化数据然后做关系计算的,你让一个比如说 MySQL 去存音视图的数据其实不太合适。很多数据库甚至很多数仓的设计都偏重于结构化数据分析结构,它们对新的存储介质的支持,对新的计算介质的支持,还有对 AI 的计算范式的支持其实都不够好。
第二,AI 的整个工具链自有特色,让建设、维护和系统本身的复杂度越来越高。你会发现因为 AI 的 workload 进来之后,AI 会使得原有的数据平台的系统设计更复杂。这会让系统变成一个非常专家和 Geek 的系统,让一个公司里可能只有少数的几个人能够 touch 它。这意味着,这个系统能够真正被用起来的机会很少。
第三,因为与 AI 结合其实是很新的一个技术方向,也还远没有定型,平台建设容易踏空 / 落后。面向未来的系统的终态,最终很难有一个定论。包括像 Snowflake 和 Databricks,他们 AI 方向的收购和合作也是刚刚展开。所以 企业数据平台设计需要考虑面向未来的扩展,比如开放性和可插拔 AI 计算能力。
对于这三个痛点,我也有两点建议:
第一,未来的设计这个系统一定是要把存储和计算考虑进去,要支撑多种不同的负载,要支持结构化、半结构化和非结构化的数据存储,要支持其他的计算模型,简而言之就是你的存储体系要是能开放的。所以,湖仓架构可能是做数据平台建设上可能必须要考虑的一个点,这个数据平台要兼顾效率和多样性。
第二,因为 Large Language Model 和 AI 的很多技术还是非常新,还在不断地变化,可以说可能是按星期为维度在做迭代,在平台的 Infra 的迭代中,不可能保持一样的迭代速度,因为对于公司来讲成本太高了,保证自己的平台有良好的扩展性就好了。扩展性包括刚刚提到的数据开放性和管理以及计算灵活且能够扩展。
我们云器科技当前在做的产品就是为了解决这些问题,所以在底层架构里采用了湖仓的架构。虽然当时大语言模型热度并没有那么高,但我们依然选定了这个方向做了开放的设计。我们的数据虽然放在数仓里,但它是开放的,数据可以被其他的引擎消费,所以从这个层面,我们在做平台扩展性的设计的时候其实兼顾了这一点。计算灵活可扩展方面,我们支持比如说 Python 的代码和 SQL 的混编,保证计算的开放和管理,保证平台具有扩展性,能够面向未来更多的技术突破做迭代。
目前,云器科技不会做大语言模型,但会和做大语言模型的公司合作,更好地做支持。
模型平台可以完全替代数据平台吗?
贾扬清:无论是数据平台还是 AI 平台都没法来用自己的经验解决对方的问题。数据平台和模型平台是相互结合的关系。
关涛:数据库 / 大数据系统已经是一个必选项了,AI 可能目前还是可选项。
关涛:好的数据平台架构三个标准:1) 能容纳管理异构数据 2) 能支持多种计算形态 3) 非技术人员能*直接*用起来平台(需要平台非常简单易用)。
InfoQ:有一种说法是叫数据即模型,所以这是否意味着对于企业而言不需要数据平台了,直接用模型平台就可以了?
贾扬清:这个是个挺好的问题,从技术跟业务这两个角度可能回答会稍微不一样一点,我就拿 Snowflake 和 Databricks 最近他们的一些动作来解释。
从技术的角度来看,其实目前数据和 AI 的计算是分开的。数据这一块我们更关注 IO 数据等等这一系列的事情;AI 这一块我们更加关注计算,比如说利用像 GPU 这种,高性能计算的资源来做数据的分析等等。这也是为什么从技术上来讲,今天 无论是数据平台还是 AI 平台都没法来用自己的经验解决对方的问题,因为技术上这两个其实就是很不一样的。这也是为什么说 Databricks 没法自己原生地长出一个 AI 东西来,Snowflake 长不出来。
从应用的角度或者从需求的角度来讲,其实的确用户会越来越多地把数据分析的需求跟 AI 的需求结合起来。从产品的角度来讲,单纯做数据是比较困难的,单纯做 AI 也比较困难。这也是为什么传统的数据公司也会需要有 AI 的能力。大家在解决这个问题的时候发现,技术和产品不能分别单独来看,想要拥有完整的产品体验,要么选择合作,要么选择购买。当然这是我个人的一个观点,并不一定对,Databricks 的收购以及 Snowflake 和英伟达合作,一定程度上也是说找到一个自己的 counterpart,然后能够来一起解决这样一个统一的产品问题。
回到你的问题,我觉得就是 数据平台跟模型平台肯定都需要,而且很有可能是一个相互结合的关系。把它放在企业内部,有点像采购不同的标准化的组件,然后把自己的业务做好的过程。
InfoQ:企业如何判断是否要进行数据架构或者说数据平台的升级和迭代?
贾扬清:我觉得可能从两个角度,第一个角度,目前在做大数据和 AI 的创业企业处在“前狼后虎”的状态中,不仅需要有大量的资源来做大模型,还需要找到大模型落地场景并且与其他系统相连接。
我在硅谷,在全球其他地方都看见了这样的一个情况:企业在看到 AI 的可能性的时候,提出 AI 战略,也有业务工程师、数据工程师、算法工程师、数据科学家,也听到了很多开源大模型,但是都无法用起来。
大家都在看着大模型“临渊羡鱼”。虽然开源的模型企业都有,但是和业务系统的对接很难。如果说有那么一个解决方案,能够让企业里面的业务工程师、数据工程师不懂 AI,也不知道 GPU 是什么东西,但是能够 5 分钟之内甚至 5 秒钟之内拉起一个 HuggingFace 大模型;一个钟头之后,把现有的数据应用和这个模型跑起来,能先溜一溜;一天之内 hopefully 能够连接到业务系统,看看到底效果怎么样。这样的话我们尝试的这个飞轮转起来之后,就能够从今天的一个抽象的大模型,到将来有更多的人能够把大模型跟应用结合起来,这样不断地来迭代来搞出东西来。
所以除了训练一个模型之外,怎么样让大量的对于 AI 系统、对于 GPU、对于 AI 算法、数学没有那么深的理解,但是对自己的业务有很深的理解的企业能够更加快地接触到这些模型,能够非常大规模地、非常高效地、非常迅速地拉起这些模型,把它对接到业务里面去,这是一个挺大的机会。
模型是企业自己,算法是企业自己的,数据是企业自己的,但是工具是标准化地提供的,20 年前这个工具叫数据库,Oracle、IBM 都提供了这个数据库;十几年前这个工具叫云;AI 来了之后也有新一波的 AI 工具。
张伯翰:我觉得还是取决于公司的业务,还有数据的结构。现在开源数据库还是非常流行的,如果是个开源系统的话内部阻力会小很多,我觉得这个也是个大趋势。
关涛:其实数据是个资产,怎么能释放资产价值,实际上是现在每个企业都关心的问题。数据库系统已经是一个必选项了,AI 可能目前还是可选项,大家都愿意可能去尝试它。其实之前我一直被问到一个问题,包括在阿里的时候也被问到这样的问题,因为我作为数据平台的建设者,他说你从你的评估标准看,你觉得我们的数据平台究竟是一个什么样的水平?我觉得有以下 3 个标准:
第一,数据平台究竟能够容纳什么样的数据。如果一个企业其实它有机会能采到很多的数据,但不能把这个数据保存或者用起来的话,这个平台价值会下降。
第二,什么样的计算能力能够让这些数据的价值体现出来,这个就涉及刚才的观点了,除了关系计算、SQL 的模式以外,AI 的计算能力包括传统算法。大语言模型这些能力,其实都是用来释放数据价值的。
第三,有多少人能够把这个用起来。运营人员、销售人员是不是能够直接使用数据,是一个企业的数据平台是否够先进、够现代的一个标准。
基于这些标准出发面向未来去看的话,我们发现随着底层系统越来越复杂,越来越多的企业大多数情况下都会用很多 AI 的算法去做调优,因为这种方式其实会使得你上层的用户变得非常简单。
所以从这个视角看一个企业的数据平台在发展过程中,应该关注三点:第一,数据存储是不是足够丰富;第二,能否很好地扩展支撑更多的算力;第三,数据平台是否足够简单,能够使运维成本降低,让更多人能更好地用起来。
企业需要怎样的一体化的 AI 数据平台?
贾扬清:一体化的 AI 数据平台最重要的一点其实就是好用和快捷。当一个平台做得越来越简单的时候,业务企业可能就不需要数据科学家了。
关涛:CEO 要业务价值,CTO 要降本增效,业务团队需要简单易用。企业应该根据业务体量,选择合适的多云、湖仓架构的一体化数据平台,同时能支持 Data 和 AI。
InfoQ:我们发现,CEO 关注的是企业的整体的发展,看到了技术趋势;CTO 关注企业整体的数据架构和业务结合。有的企业没有数据科学家团队,由产品总监在牵头关注 AI 大模型等新技术趋势。那么,企业内部谁在进行 AI 落地技术和业务的决策?
关涛:这是一个特别好的问题。你刚才提到的这三类型的人代表企业三种不同的角色,三种不同的角色的人确实关注点不一样,CEO 更关注的是这样的一个平台,怎么能够帮助企业更好地实现价值,他甚至不太关注说你这个平台是个自建的还是购买的,只要你的性价比足够达标就好了。他更关注怎么能让更多的人把这个平台用起来使得企业能更受益。这种情况通常是会推动平台向前演进的。
CTO 的角色可能并不完全一样。我们跟很多企业的 CTO 沟通发现,他们提的第一个需求往往都是降本。这个可能跟当前的经济状态也相关,他想的就是说我怎么能够以更低的成本得到更好的价值,这是 CTO 的视角。
业务视角其实要来得更直接,比如说我们跟一个企业做合作想出一个报表的时候,把需求提一个单子给他们,这个单子流转到他们那边去排个期,排期回来再把这个单子拿回来,最终我们收回来这个数据,这个周期大概需要 3 天的时间。他们来跟我们聊,能不能更简化这个过程甚至说能不能直接就做这件事情。
这件事情其实就数据平台本身来讲,如果你会写 SQL 的话,这个事情并不特别复杂。这里面涉及一些数据建模的问题,也可以通过 Data for AI 这种 AI for Data 这种方式来解决。剩下那半边我能不能更快地做这个迭代,现在其实答案很可能是 yes,我们能够通过不编程的方式直接和平台做交互,慢慢正在变成现实。
很多企业其实没有数据科学家这个岗位,很可能是因为当一个平台做得越来越简单的时候,这个岗位有可能都会被人工智能或者系统来替代。
InfoQ:很多时候企业的发展其实是数据在驱动。业务视角看,数据科学家往业务方向走一走,走着走着可能就变成这个业务里面的 CEO 了。我刚才其实是举了 3 个例子,CEO、CTO、数据科学家,其实代表的是企业可能是不同的规模,业务的多元化和单一化也决定着企业的结构可能是怎么样的。那么,企业怎么去选择一体化的 AI 数据平台?
贾扬清:我觉得企业今天其实在一个迅速变化的过程当中,最重要的一点其实就是好用和快捷。所以说在选择数据平台还是 AI 的平台的时候,能否迅速地能够上手,能否迅速能够让自己的团队对接用起来然后去尝试业务效果,是今天更加重要的一个点。
张伯翰:我从一个创业者的角度来说一下,我觉得这个完全取决于公司的体量。资源有限的时候,你一定得关注最核心的业务。这也是侧面反映了扬清说的一点就是好用。
关涛:其实前面聊得很充分,我给几个具体的建议:
第一,建议用云。云其实是一个非常灵活的基础设施,可以让你今天买一个信息流,明天就不用它了。这种灵活性其实会使得企业的架构迭代变得特别简单。所以第一个建议是要用云,最好其实是多云的,有分层解耦的这样一个设计。
第二,湖仓架构现在应该是个必选项。
第三,关注企业的体量。中小企业选择一个更简单、更容易上手的平台其实更重要。Infra 建设目标是为了业务服务,最重要的是你的业务,你关注在你的业务上选一个你最合用的平台就好。
InfoQ:咱们今天的圆桌基本上到这里就到最终结束的时间了,听我们同事说在 7 月 20 号云器科技其实是有一个新产品的发布会的,关涛老师要不要提前给我们剧透一下?
关涛:谢谢主持人,最后打一个小广告。云器科技是成立了一年半的数据平台服务的提供商,我们的主打的技术口号是多云和一体化,希望给用户提供全托管的企业级的极致简单的数据平台,我们能同时地支持数据和 AI 的负载。
我们在 7 月 20 号会举办首次产品发布会,主题是 “Single Engine· All Data”,如果大家希望找到我们的话,可以搜索云器科技就能找到我们的网站和公众号。7 月 20 号,欢迎大家来听我们的发布会,谢谢!


腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论