

你好,我是郑晔,《10x程序员工作法》专栏作者,火币网首席架构师。
程序员是一个忙碌的职业,与这个职业联系在一起的词儿,通常是忙碌、加班、熬夜、过劳、亚健康……当忙碌成为了主旋律,“高效”一词就自然浮出了水面。
可是,程序员工作效率是由编程能力决定的吗?答案是“未必”。
这些年,我一直在研究一件事儿:为什么那些大师级程序员,可以兼顾 N 倍于一般人的工作,还有条不紊?他们究竟用了什么工作法?根据我的观察与总结,他们往往绕不开四个工作原则。
在「大师级程序员,都用哪些工作法?(上)」中,我给大家介绍了“以终为始”和“任务分解”这两个工作原则,相信你对 DoD、精益创业、微操作等有了一定的认知。下面,我给大家继续介绍另外两个工作原则:沟通反馈和自动化。
沟通反馈
可视化:技术雷达
ThoughtWorks 技术雷达用来追踪技术,通过可视化的方式给程序员提供了一种更系统、直观地了解新技术的方式。
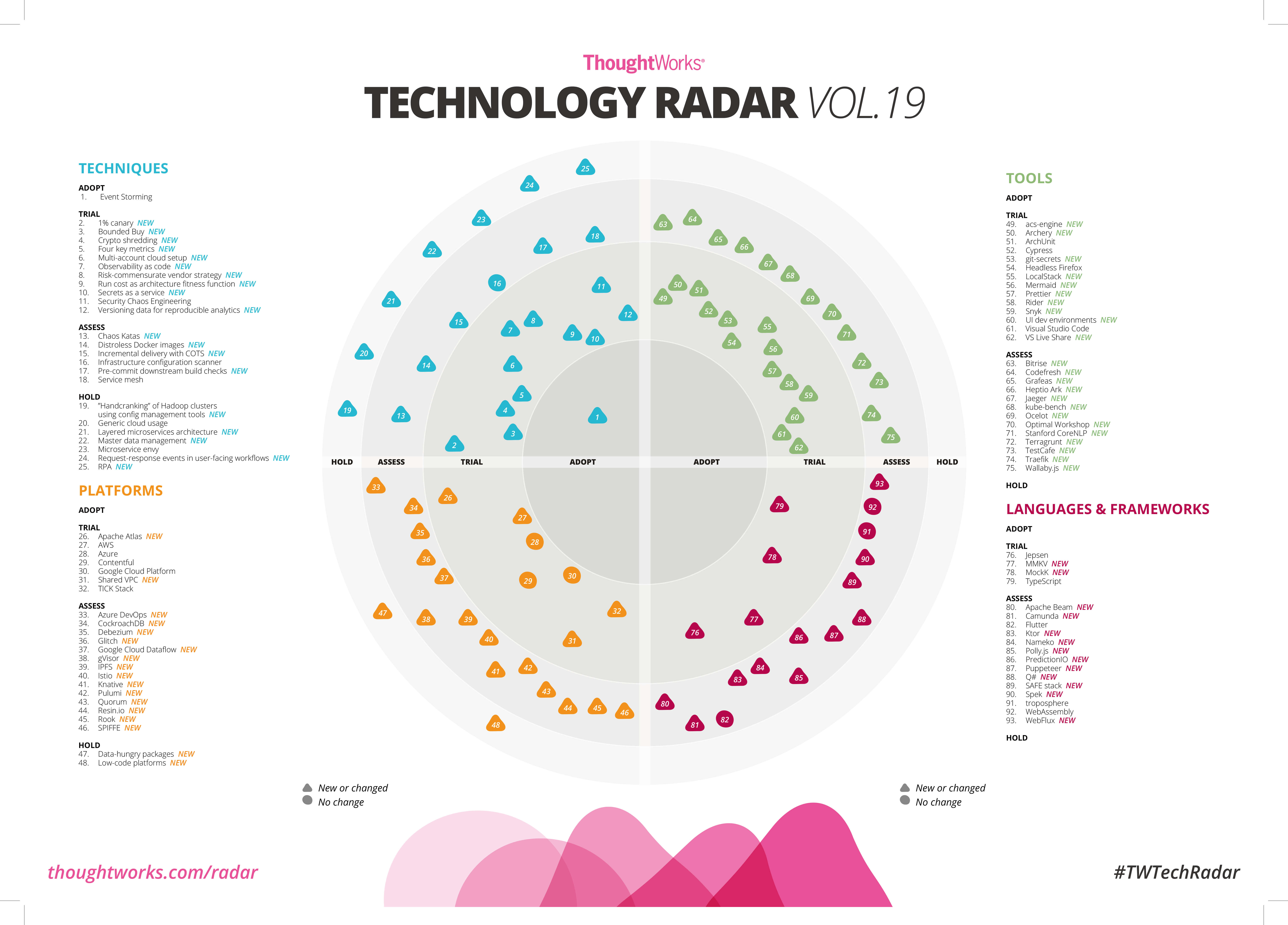
在雷达图中,组织技术的方式也并不复杂。每一项技术表示为一个 blip,也就是雷达上的一个光点。然后用“象限”(quadrant)和“圆环”(ring)组织这些 blip。
其中,象限表示一个 blip 的种类,目前有四个种类:技术、平台、工具和语言与框架。圆环表示一个 blip 在技术采纳生命周期中所处的阶段,目前这个生命周期包含四个阶段:采用(Adopt)、试验(Trial)、评估(Assess)和暂缓(Hold)。
雷达图是一种很好的将知识分类组织的形式,它可以让你一目了然地看到了解所有知识点,并根据自己的需要,决定是否深入了解。
比如,每次技术雷达发布之后,我会特别关注一下“采用”和“**暂缓”两项。“采用”**表示强烈推荐,我会去对比一下自己在实际应用中是否用到了,比如,在 2018 年 11 月的技术雷达中,事件风暴(Event Storming)放到了“采用”中。
“暂缓”则表示新项目别再用这项技术了,这会给我提个醒,这项技术可能已经有了更优秀的替代品,比如,Java 世界中最常见的构建工具 Maven 很早就放到了“暂缓”中,但时至今日,很多人启动新项目依然会选择 Maven,多半是不了解技术趋势。
在我看来,雷达图不仅仅适用于组织,也可以适用于团队。
我也曾经按照雷达图的方式将自己的团队用到的技术组织起来。把最需要了解的技术必须放在内环,比如:一个 Java 项目,我会要求程序员了解 Java,向外扩展的就是你在这个团队内工作会逐渐接触到的技术,像 Docker 这种与部署相关的知识。至于最外面一层,就是被我们放弃掉的技术,比如,Maven。
这样一来,团队成员可以更清晰地了解到团队中所用的技术。当有新人加入团队时,这个雷达可以帮助新人迅速地抓住重点,他的学习路径就是从内环向外学习。
Fail Fast
写程序有一个重要的原则叫 Fail Fast,遇到问题,尽早报错。
很多人以构建健壮系统为由,兼容了很多奇怪的问题,反而会把系统中的 Bug 隐藏起来。靠 debug 来定位问题是最为费时费力的一种做法,别怕系统有问题,有问题早点报出来。
举个例子,我做了一个查询服务,可以让你根据月份查询一些信息,一年有 12 个月,查询参数就是从 1 到 12。
问题来了,参数校验应该在哪做呢?如果什么都不做,这个查询参数就会穿透系统,传到你的数据库上。如果传入的参数是合法的,当然没有任何问题,这个查询会返回一个正常的结果。但如果这个参数是无意义的,比如传“13”,那这个查询依然会传到数据库上。
事实上,很多不经心的系统就是这么做的,一旦系统出了什么状况,你很难判断问题的根源。在这个极度简化的例子里,你可以一眼看出问题出在输入参数上,一旦系统稍具规模,请求来自不同的地方,这些请求最终都汇集到数据库上,识别来源的难度就会大幅度增加。尤其是系统并发起来,很难从日志中找出这个请求的来源。
你可能会说,“为了方便服务对不同数据来源进行识别,可以给每个请求加上一个唯一的请求 ID 吧?”看,系统就是这么变复杂的,我经常调侃这种解决方案,就是没有困难创造困难也要上。当然,即便以后加上请求 ID,理由也不是这个。
稍有经验的人都知道,参数校验应该放在入口的位置上,不合法的请求就不让它往后走了。这种把可能预见的失败拦在外面的做法就是 Fail Fast,有问题不可怕,让失败尽早到来。
上面这个例子很简单,我再给你举一个例子。如果配置文件缺少了一个重要参数,比如,缺少了数据库最大连接数,你打算怎么处理?很多人会选择给一个缺省值,这就不是 Fail Fast 的做法。既然是重要参数,少了就报错,这才叫 Fail Fast。
自动化
SOLID 原则
《敏捷软件开发:原则、实践与模式》的作者 Robert Martin 提出的面向对象设计原则:SOLID,为软件设计的目标“高内聚、低耦合”提供了很好的指导。“SOLID”其实是五个设计原则的缩写,分别是
单一职责原则(Single responsibility principle,SRP)
开放封闭原则(Open–closed principle,OCP)
Liskov 替换原则(Liskov substitution principle,LSP)
接口隔离原则(Interface segregation principle,ISP)
依赖倒置原则(Dependency inversion principle,DIP)
什么是单一职责原则呢?Robert Martin 把单一职责原则的定义修改成“一个模块应该仅对一类 actor 负责”,这里的 actor 可以理解为对系统有共同需求的人。
这可能不是很好理解,我举个例子你就懂了。在一个工资管理系统中,有个 Employee 类,它里面有三个方法:
calculatePay(),计算工资,这是财务部门关心的。
reportHours(),统计工作时长,这是人力部门关心的。
save(),保存数据,这是技术部门关心的。
之所以三个方法在一个类里面,因为它们的某些行为是类似的,比如计算工资和统计工作时长都需要计算正常工作时间,为了避免重复,团队引入了新的方法:regularHours()。
接下来,财务部门要修改正常工作时间的统计方法,但人力部门不需要修改。负责修改的程序员只看到了 calculatePay() 调用了 regularHours(),完成了他的工作,财务部门验收通过。但上线运行之后,人力部门产生了错误的报表。
如果你问程序员,为什么要把 calculatePay() 和 reportHours()放在一个类里,程序员会告诉你,因为它们都用到了 Employee 这个类的数据。
但是,它们是在为不同的 actor 服务,所以,任何一个 actor 有了新的需求,这个类都需要改,它也就很容易就成为修改的重灾区。更关键的是,很快它就会复杂到没人知道一共有哪些模块与它相关,改起来会影响到谁,程序员也就越发不愿意维护这段代码了。
人的大脑容量有限,太复杂的东西理解不了。所以,我们唯一能做的就是把复杂的事情变简单。我在“任务分解”模块中不断强调把事情拆小,同样的道理在写代码中也适用。单一职责原则就给了你一个指导原则,可以按照不同的 actor 分解代码。
领域分层
分层,实际上是在构建抽象,构建抽象,最核心的一步是构建出你的核心模型,核心模型就是表达你业务的那部分代码。换句话说,别的东西都可以变,这部分不能变。
这么说有点抽象,我们回到前面提到的三层架构的演变:REST 服务的兴起,让 Controller 逐渐退出了历史舞台,资源层取而代之。换句话说,访问服务的方式可能会变。
放到计算机编程的发展中,这种趋势就更明显了,从命令行到网络,从 CS(Client-Server) 到 BS(Browser-Server),从浏览器到移动端。所以,怎么访问不应该是你关注的核心。同样, 关系型数据库也不是你关注的核心,它只是今天的主流而已。从前用文件,今天还有各种 NoSQL。
如此说来,三层架构中的两层重要性都不是那么高,最重要的是剩下的部分,我们习惯上称之为服务层,但这个名字并不能很好地反映它的作用,更恰当的说法是“领域模型”(Domain Model),它便是我们的核心模型,也是我们做软件设计时,真正应该着力的地方。
为什么“服务层”不是好的说法呢?这里会遗漏领域模型中一个重要的组成部分:领域对象。很多人理解领域对象有一个严重的误区,认为领域对象属于数据层。数据存储只是领域对象的一种用途,它更重要的用途还是用在各种领域服务中。
由此还引出另一个常见的设计错误,领域对象中只包含数据访问,也就是常说的 getter 和 setter,而没有任何逻辑。如果只用于数据存储,只有数据访问就够了,但如果是领域对象,就应该有业务逻辑。比如,给一个用户修改密码,用户这个对象上应该有一个 changePassword 方法,而不是每次去 setPassword。
出自第35讲| 总是在说MVC分层架构,但你真的理解分层吗?

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论