

我想分享一个将 Next.js 13 的 SSR 和 SSG 功能推到极限的实验。我构建了一个包含 5000 个 SSR 页面的网站,以观察 Next.js 在本地和生产环境中的性能。我在 AWS Amplify 服务团队工作,我想使用我们的 托管服务 来构建和部署这些页面,确保它能处理大量的页面和图片。使用静态参数和动态参数会有多大的差异?如果你需要快速的构建时间,哪个是更优的选择?如果你不关心构建时间,但想要一个运行极快的网站,哪个是更优的选择?让我们来找出答案。
在本文中,你将看到我如何生成 5000 个测试图片和记录,并上传它们,用 AWS Amplify 传送到 Amazon S3 和 Dynamo DB,并构建了一个 Next.js 应用程序来获取数据和图片,在屏幕上呈现它们,部署到 Amplify Hosting 并记录性能影响和差异。
寻找和上传 5000 条数据
简介:如果你不愿意按照本节中的步骤操作,你可以点击以下链接访问我的 5000 条记录 和 5000 张图片。
如何找到 5000 张图片?
我面临的第一个挑战是为每个页面找到 5000 张图片。我没有依赖 Kaggle 等平台的数据集,而是采用了更直接的方法。我从 Unsplash 下载了十张图片,并将它们保存在名为5k_src的本地文件夹中。
如果你使用过 Unsplash,你可能会记得这些原始图像通常是高分辨率大尺寸的,往往超过 1MB。我优化了每个图像,减小其文件大小。确保你有自己的 10 张经过优化的图像集存放在你选择的文件夹中。
一旦我有了 5000 张图像,我就编写了一个脚本来复制这些图像,直到总共有 5000 张。对我来说,每个图像是否独特并不重要,所以我决定使用 10 张不同的图像并复制它们,直到我有 5000 张图像。为了利用这个脚本,你需要为这 10 张图像创建一个 src 文件夹和一个 5k 图像的目标文件夹。创建一个名为 demo 的文件夹,并在其中添加两个文件夹:5k_dest,5k_src。
切换到 demo 文件夹,并在终端中运行以下 CLI 脚本来复制这些图像:
脚本将一个名为 5K_dest 的目标文件夹设置为存储所有复制的图像的位置。它还指定了一个名为 5K_src 的源文件夹,其中包含原始图像。然后,它运行一个循环进行 500 次迭代。
每次迭代都会从源文件夹中复制名为 b.jpg 的图像,并使用唯一的名称,将副本保存在目标文件夹中。新名称包括一个数字(即 i 的值),每次迭代都会增加,从而得到名称为"b1.jpg","b2.jpg"直到"b500.jpg"的图像。
我使用这种方法确保每个图像都有唯一的文件名。通过对每个图像运行此脚本,我得到了总共 5000 张图像。要获取 5000 个重复的图像,你可以在 5k_src 文件夹中对每个图像运行该脚本。
如何找到 5k 条记录?
接下来,我需要生成一个随机记录列表。我使用了一个名为 Mocaroo 的工具,它允许一次最多生成 1000 行记录(对于免费账户)。
在访问 Mocaroo 之后,我清除了所有默认数据,并根据下面的图片添加了新字段。
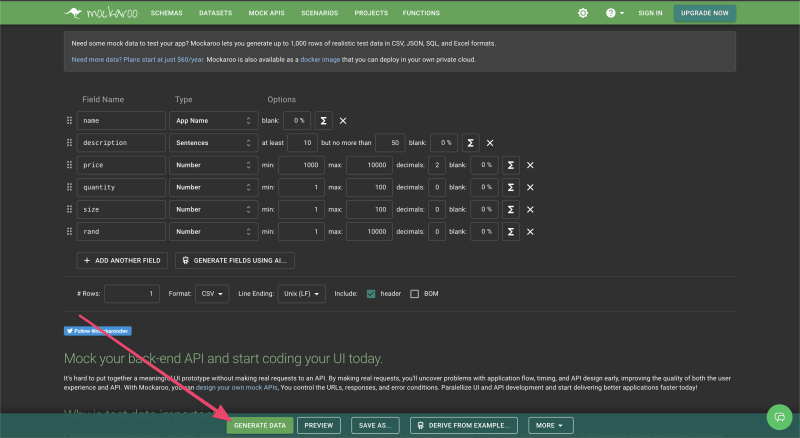
添加新字段后,我将“行”字段设置为 1000,这是 Mockaroo 可以生成的最大值。设置好后,我点击了 5 次“生成数据”,生成了 5 个包含 5000 条记录的 csv 文件。
现在我需要将这 5 个 csv 文件合并,所以我转向了 Google Sheets。如果你也想这样干,可以按照以下步骤进行:
打开 Google Sheets。
创建一个新文件。
点击左上角的“文件”。
点击“导入”,选择“上传”并选择第一个 csv 文件。
第一个 csv 文件上传完成后,重复相同的步骤,但在合并的弹出选项出现时,将其导入到同一个工作表,并追加到工作表的末尾。
导入完成后,我使用了“自动填充”功能,为每条记录添加了图像名称。由于图像是连续的,所以这个操作很简单。
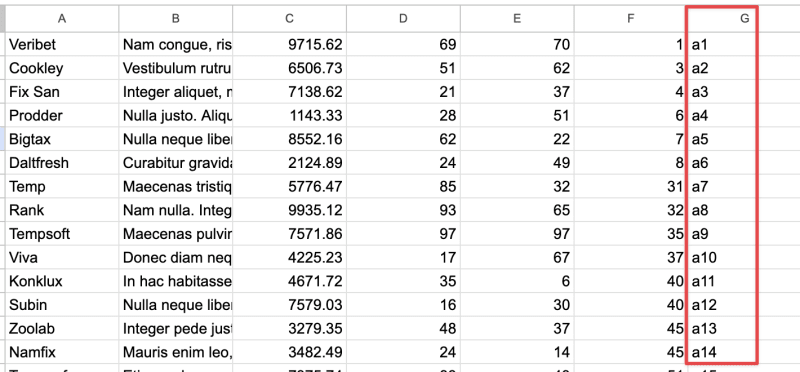
如何上传 5000 张图片到云端?
接下来,我需要将 5000 张图片上传到云端,具体来说是亚马逊简单存储服务(Amazon S3),首先我需要创建一个 AWS Amplify 项目。按照以下步骤进行操作:
导航到你的 AWS 控制台,搜索 AWS Amplify。
选择 AWS Amplify 打开 Amplify 控制台。
在右上角,选择 新建应用 并从下拉菜单中选择 创建一个应用。
给应用程序取一个名称(我称之为 5kpages),然后点击 确认部署。
部署完成后,点击 启动工作室 按钮打开 Amplify 工作室。
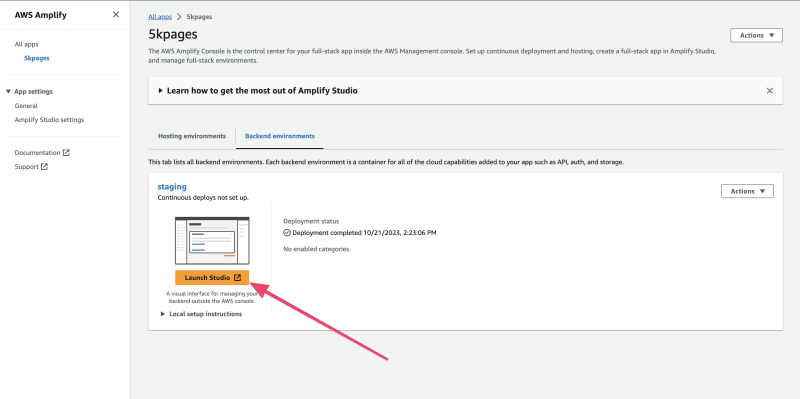
接下来,我需要创建一个存储实例来存储图片。然而,在此之前,我需要设置身份验证。
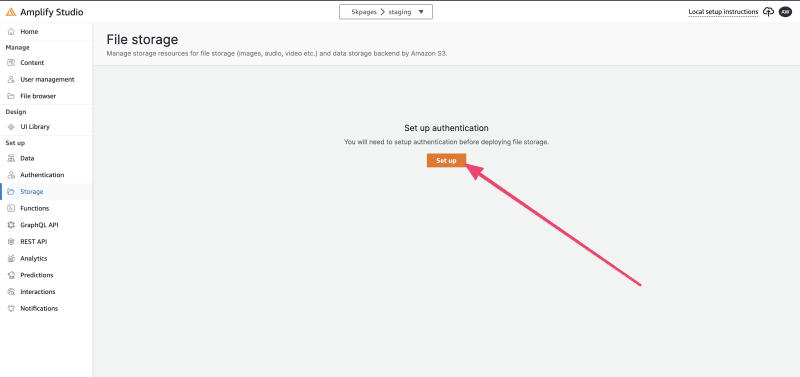
要继续进行身份验证设置,请点击 设置 按钮。由于我们不会在此应用程序中使用身份验证,因此你可以保留所有默认选择;身份验证只是用于使用存储。请继续点击 部署 按钮,确认警告,并选择 确认部署。
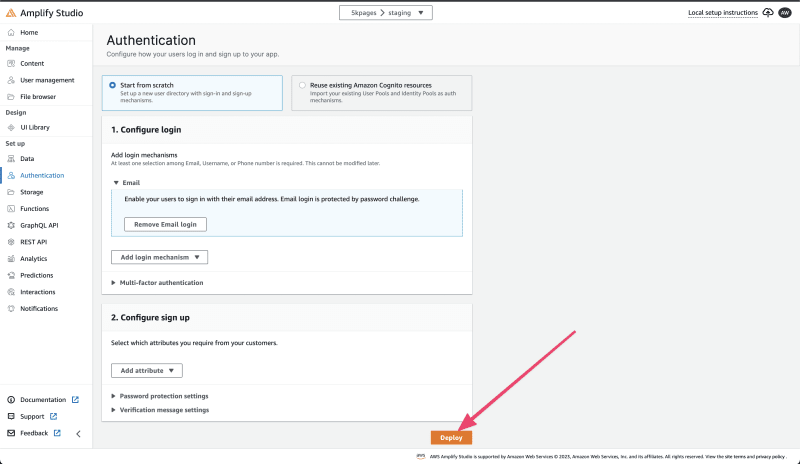
身份验证部署过程可能需要一两分钟的时间。完成后,你将看到一条确认消息,说明身份验证已成功部署。
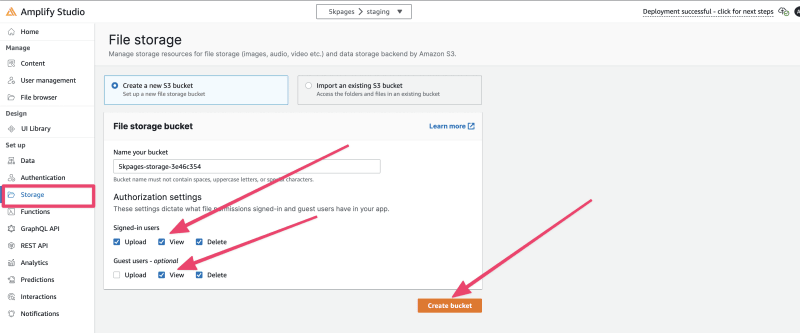
设置完身份验证后,我设置了存储并创建了一个新的 S3 存储桶。要执行此操作,请在屏幕左侧的设置菜单中选择 存储 选项。
在授权设置中,确保已登录的用户具有上传、查看和删除文件的权限,而访客用户只能查看和删除文件。最后,点击 创建存储桶 按钮。
要查看存储桶,你可以返回 Amplify 控制台。搜索 s3,然后选择它。
我将我的存储桶命名为 5kpages。选择你的存储桶以打开它。
上传图片到存储桶,请点击 上传 按钮。

为了将 5k 张图片上传到 S3 存储桶,我将 5k_dest 文件夹拖放到页面上,并点击如下所示的上传按钮。
上传所有图片需要一些时间。
上传完成后,请返回 Amplify 工作室,并在侧边菜单中选择 文件浏览器 选项。在 public 文件夹中,你会看到包含 5,000 张图片的 5k_dest 文件夹。你可以浏览页面来查看这些图片。
如何将 5k 条记录上传到云端?
在上传图片之后,下一步是将 5,000 条记录上传到 Amazon DynamoDB。请按照以下步骤进行操作:
返回 Amplify 控制台。
从侧边菜单中选择 数据。
点击“+ 添加模型”按钮。
填写如下图所示的字段。
填写字段后,点击 保存并部署 按钮。
创建模型后,转到 Amplify 控制台并搜索 DynamoDB。在侧边菜单中点击 表格,你将找到一个项目数为 0 的产品表。复制表格的名称,然后转到终端以创建一个 Node 应用程序。
在创建 Node 应用程序之前,我需要从 Google Sheets 下载 5kproducts.csv 记录文件。
要下载该文件,请按照以下步骤进行操作:
打开包含 5000 条记录的 Google Sheets。
单击左上角的“文件”。
选择“下载”,然后选择“下载为 CSV”。
下载完文件后,创建一个新文件夹并将其命名为 5kdyno 或其他任何名称。将下载的 CSV 文件放入此文件夹中。接下来,在文件夹中创建一个 package.json 文件,并将以下内容添加到其中:
请在终端中运行以下命令来安装这些依赖项:
请在文件夹中创建一个 index.js 文件,并将以下内容添加到其中:
第一件你可能注意到的事情是,我没有向 Dynamo DB 客户端传递任何凭据。你可以查看这个 AWS 文档来指导如何为你的计算机设置凭据。
接下来,我创建了一个 DynamoDBClient 的实例,并使用这个实例创建了一个 DynamoDBDocumentClient。这个客户端提供了一个更高级的接口来操作 DynamoDB。然后,我声明了一个异步函数叫做 main,并设置了一个流来逐行读取文件 5kproducts.csv,并将这个流传输到一个 CSV 解析器中。之后,我循环遍历每一行解析出来的 CSV 文件,并将每一行日志记录到控制台。
PutCommand 使用 CSV 中的行创建了一个写入操作到 DynamoDB 表中。最后,我使用客户端将写入操作发送到 DynamoDB。
不要忘记将 TableName 替换为你创建的表名称。
现在,如果你打开终端并运行命令 node index.js,你会看到它正在写入指定的表中。
这个过程可能需要几分钟才能完成,但一旦完成,返回到 DynamoDB 并刷新页面。点击“浏览表项目”,你应该能够看到数据库中的项目。
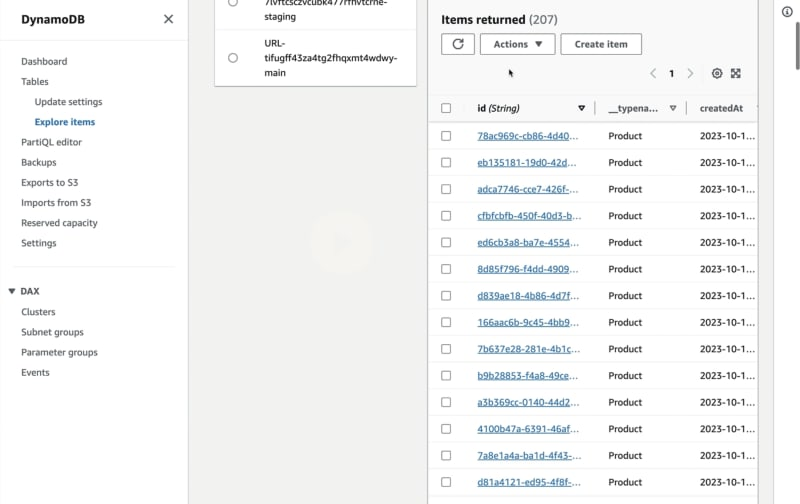
现在,如果你返回到 Amplify,并从侧边菜单中点击“内容”部分,你将能够看到传入的内容。
在浏览器上渲染数据
在将图像和记录上传到云端之后,我需要做的下一件事就是在网站上显示产品列表。为了实现这一目标,我创建了一个 Next.js 应用程序。并非从头开始,我创建了一个起始项目,其中包含了 Tailwind 配置和其他设置。你可以通过在终端中运行以下 Degit 命令来克隆它:
起始项目包含三个组件和一个 ui/button 组件。其中一个组件是 ProductList,它接收 items,循环遍历它们并渲染。在 ProductList 组件内部,使用 S3Image 组件从 S3 获取图像。此外,该项目还包括一个管理分页的 Pagination 组件。
之后,运行以下命令安装依赖项:
接下来我做的事情是配置 Amplify,以便我们可以访问上传的数据和图片。为此,请返回 Amplify Studio,并复制显示的 pull 命令。
在你的项目目录中,将复制的命令粘贴到终端中,然后执行复制的命令。
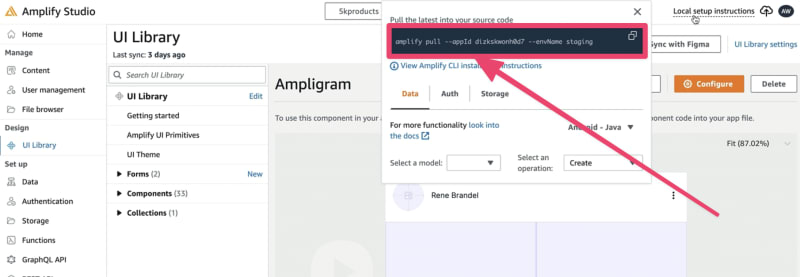
运行该命令时,你将被重定向到 Web 浏览器以授权 CLI 访问。在那里,点击“是”以与 Amplify Studio 进行身份验证。
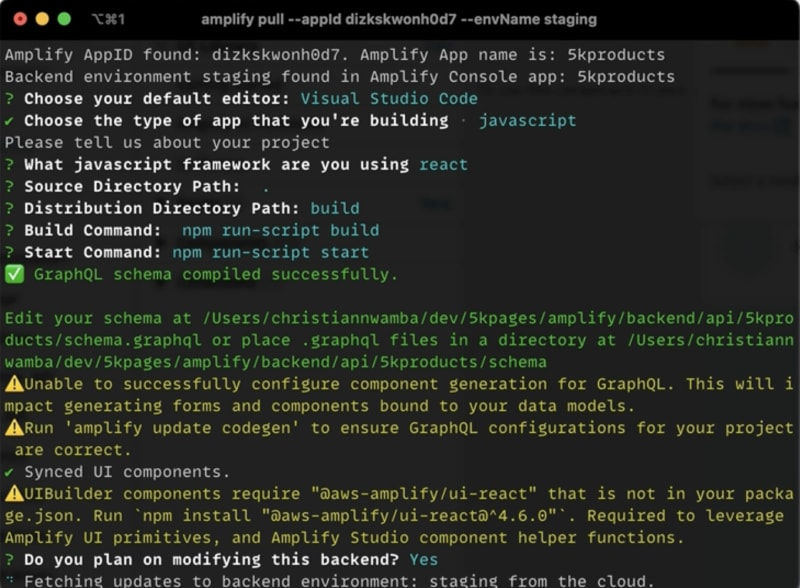
之后,请返回 CLI。在这里,你将被要求回答一系列问题,以收集有关项目配置的基本详细信息。接受下面图像中突出显示的默认值:
接下来,我配置了 Next.js 以识别图像的来源域。为此,请将以下内容添加到您的 next.config.js 文件中:
请确保将 domains 替换为从你的 S3 存储桶中复制的内容。
一旦我设置了一个 Amplify 项目,我就需要生成用于与数据交互的 GraphQL 操作的代码。
要生成这些操作,请在项目的根目录运行以下命令:
请接受下图中所示的默认值:
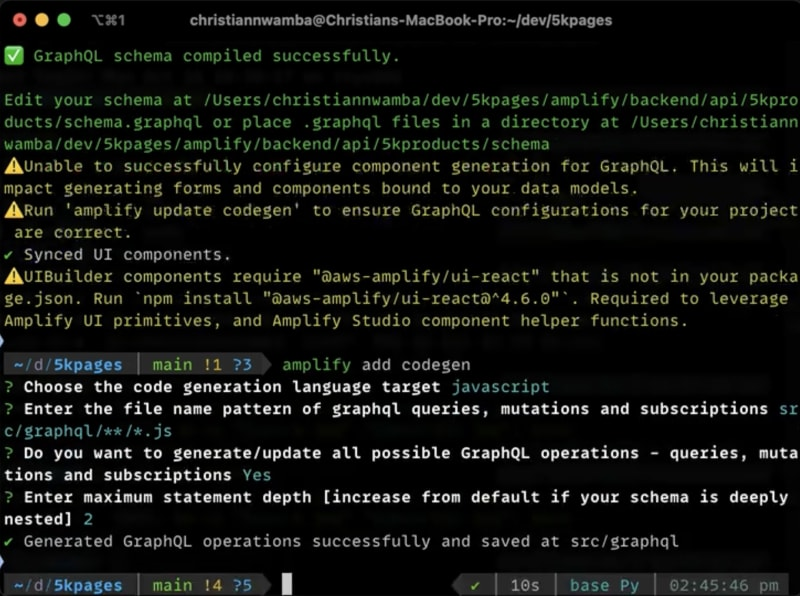
此命令将生成 GraphQL 操作并将其保存在 src/graphql 目录下。生成的操作可直接导入到你的组件中,与你的 API 进行无缝交互。
要获取并渲染产品列表,请将以下内容添加到你的 app/page.js 文件中:
在这个文件中,我导入了几个东西。首先,我从 AWS Amplify 库中导入了 API。这允许我与 GraphQL API 进行交互。我还导入了 Pagination 和 ProductList 组件,它们是用于显示产品列表和提供分页功能的 React 组件。此外,我还从 …/src/graphql/ 的 queries 文件中导入了 queries。
接下来,我定义了一个名为 fetchData 的异步函数,该函数根据提供的参数获取产品数据。在函数中,我定义了一个名为 variables 的对象,其中 limit 设置为 10,表示我想一次获取 10 个产品。
然后,根据提供的动作和令牌修改分页的变量。如果动作是 next 并且提供了 nextToken,则将 variables.nextToken 设置为 nextToken 的值,这将获取下一组产品。如果动作是 prev 并且提供了 prevToken,则使用 prevToken 来获取上一组产品。
然后,该函数使用 queries.listProducts 查询和变量进行 GraphQL 调用,以获取产品数据。最后,它返回获取到的产品列表。
接下来,我定义了 Home 组件,它作为在主页上显示产品列表的主要 React 组件。该组件是异步的,并从 searchParams 中获取 nextToken、prevToken 和 action。
为了获取所需的产品列表,该组件使用这些参数调用了 fetchData 函数。
返回的 JSX 包括页面标题、传递给 ProductList 组件的获取到的产品列表以及用于处理分页控件的 Pagination 组件。
如果你现在打开浏览器,你将看到展示的产品。如果你点击 下一页 按钮,你可以查看更多产品,点击 上一页 按钮将显示上一组产品。
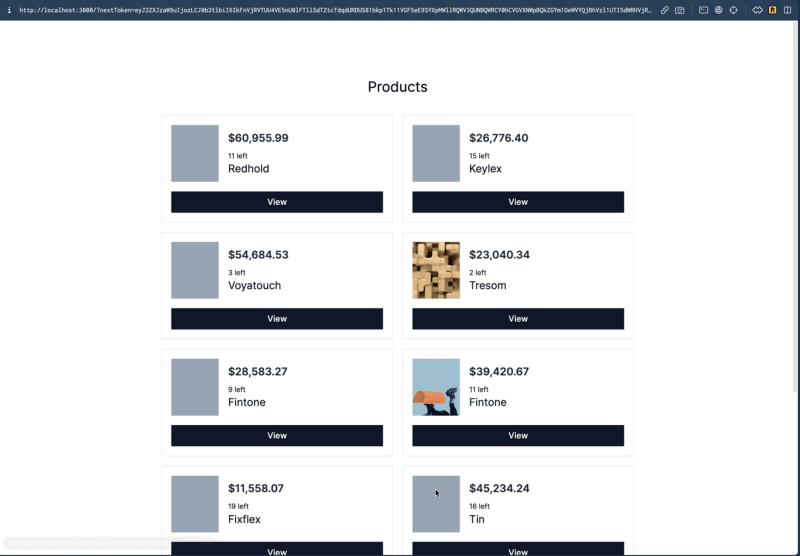
使用动态参数渲染动态页面
我想要探索动态参数和静态生成页面,并比较它们之间的性能差异。
对于动态参数,我们需要接收 id 作为参数。有了这个参数,我们就可以开始构建页面来渲染单个产品项。
在你的 app 文件夹中创建一个名为 [id] 的新文件夹。在 [id] 文件夹内,创建一个 page.js 文件并添加以下代码:
该文件以几个导入开始。API 导入自 AWS Amplify 库,用于与 GraphQL API 进行交互。queries 导入用于获取产品的详细信息。S3Image 导入用于显示存储在 Amazon S3 中的图像。next/link 中的 Link 导入用于客户端路由之间的转换。最后,Button 组件被导入用于 UI 目的。
接下来,我定义了一个名为 Product 的异步组件。它首先定义了一个变量对象,并使用 params 中的 id 设置了 variables。这个 id 用于查询特定的产品。
然后,该函数使用 queries.getProduct 查询和 variables 进行了 GraphQL 调用。响应包含产品数据,该数据被提取并存储在 product 常量中。
最后,返回的 JSX 包括以下内容:使用 S3Image 组件的产品图像、产品的价格和库存数量、产品的名称、产品的描述,以及一个按钮,当点击时会将用户导航回主页。
我还定义了一个名为 revalidate 的常量,它指定了 Next.js 在页面上重新检查新数据的频率(50 分钟)。重新验证 Next.js 非常重要,以确保你的响应不会被缓存太长时间。如果你的内容需要频繁更改,缓存可能会引起保持内容新鲜性方面的挑战。
在这个演示中,与缓存相关的主要问题与使用 Amazon S3 存储图像有关。S3 不直接提供公共 URL。即使它提供了公共 URL,它也是使用一个过期的令牌进行签名的。一旦令牌过期,你将无法再使用相同的 URL 访问图像,而必须请求一个新的令牌。
这意味着如果 Next.js 缓存了你的响应并保存了 URL,它将不知道图像现在已经无效。当你尝试渲染图像时,它将不显示任何内容。除非你要求 Next.js 刷新其缓存并向存储请求新的 URL。
为了解决这个问题,我将 S3 图像的过期时间设置为一小时,并配置了 Next.js 在 50 分钟后重新验证图像。这样,Next.js 在 S3 图像过期之前进行了一次 fetch 请求,使缓存无效并显示更新后的页面。
使用静态参数渲染动态页面
到目前为止,我们已经学习了如何使用动态参数实现动态渲染。现在,让我们来探讨如何使用静态参数实现动态渲染。
为了做到这一点,请转到你的代码编辑器并提交你对主分支所做的更改。要创建一个新的分支,请在终端中运行以下命令:
打开你的 app/[id]/page.js 文件,并将以下代码添加到文件底部:
这个函数使用 queries.listProducts GraphQL 查询获取所有产品(共 5000 个)。然后它在产品列表上进行映射,并提取出产品的 ID。
返回的 ID 数组将在构建时由 Next.js 用于静态生成,为每个产品 ID 创建一个预渲染页面。
如果你访问浏览器,刷新页面,并随机点击项目,你会注意到加载速度显著提高,这是静态生成实现的结果。
本地构建
现在让我们回顾一下我们到目前为止所做的工作,并比较动态参数和静态参数的构建时间。
要切换回主分支,请在终端中运行以下命令:
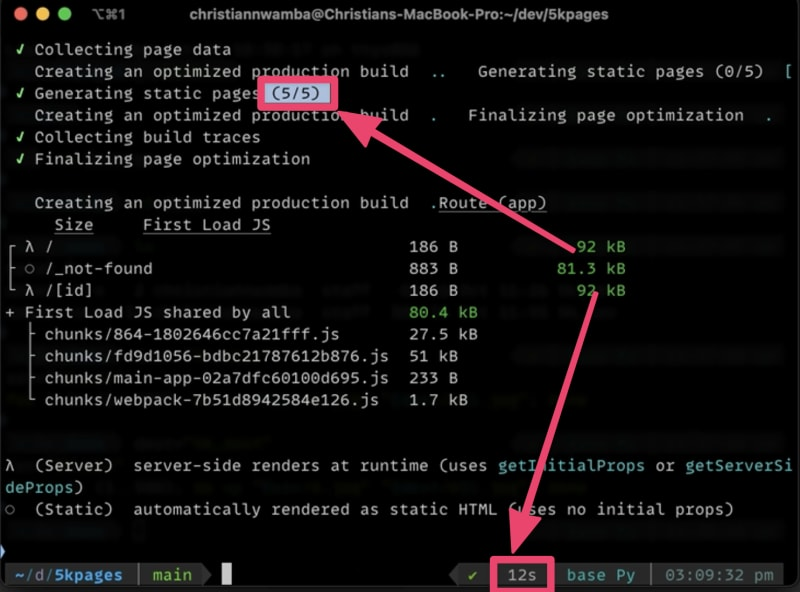
请在终端中运行以下命令,以查看动态参数的构建时间:
如下图所示,构建过程只生成了 5 个静态页面,并在 12 秒内完成。
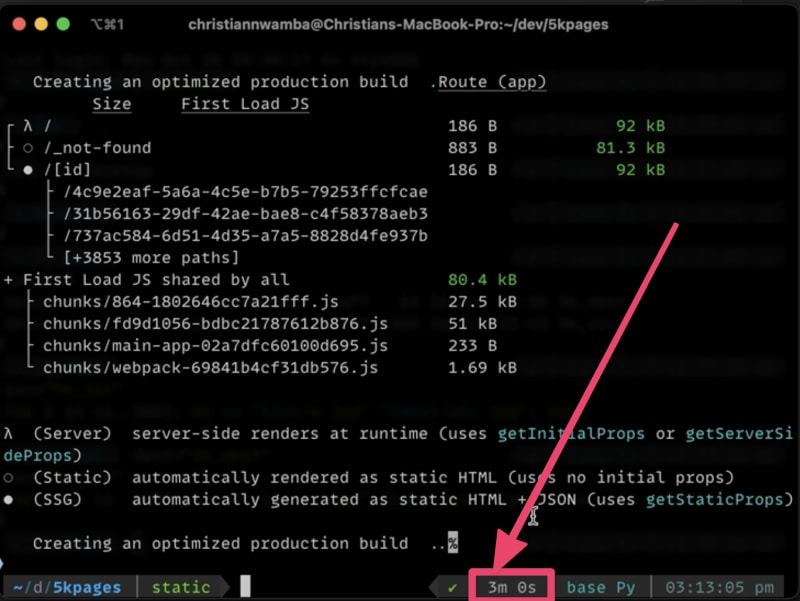
让我们对静态参数做同样的操作。在终端中运行以下命令:
注意,它正在迭代并尝试构建每个页面。在下面的图片中,你可以看到构建时间为 3 分钟,相当于 180 秒。
在生产环境中构建
下一步是部署到生产环境并进行测试。返回你的代码编辑器并发布静态分支。完成后,也发布主分支。
前往 AWS 控制台,搜索 AWS Amplify 并从服务列表中选择它。接下来,选择 5kpages 应用程序。
选择托管环境。
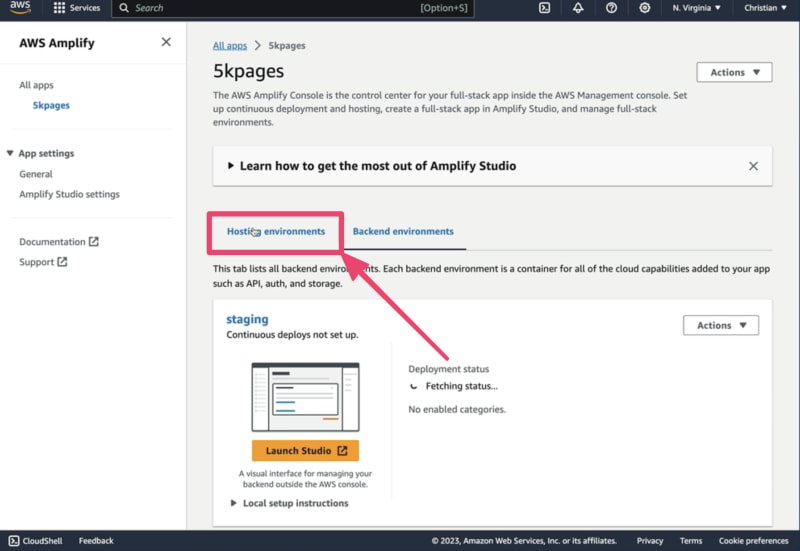
在下一页上选择 GitHub 或你的 Git 提供商,并点击连接分支按钮。
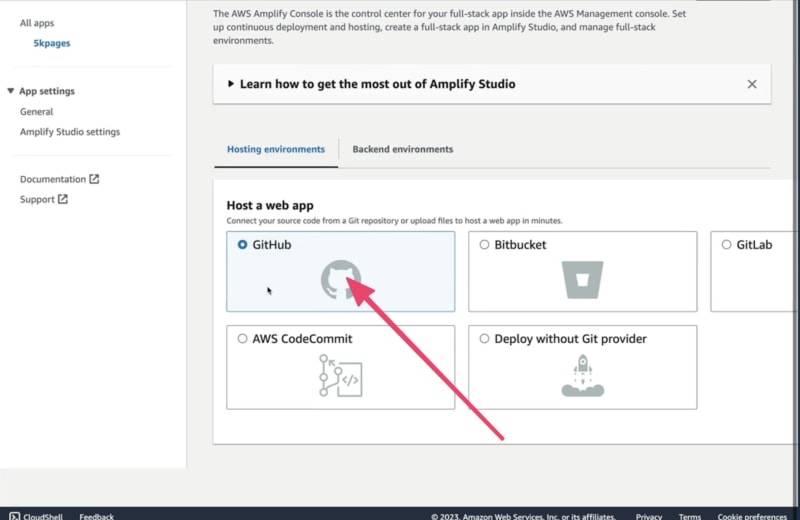
选择你打算托管的存储库,选择main分支作为动态参数,并点击下一步按钮继续。
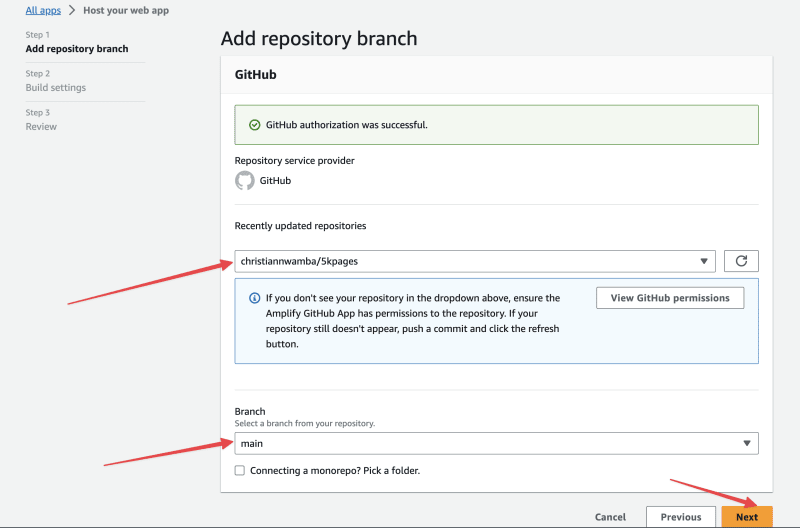
在构建设置页面上,选择一个环境或创建一个新环境。如果你有现有的服务角色,请选择一个现有的服务角色,或者点击创建新角色按钮创建一个允许 Amplify Hosting 访问资源的新角色。完成选择后,点击下一步按钮继续。
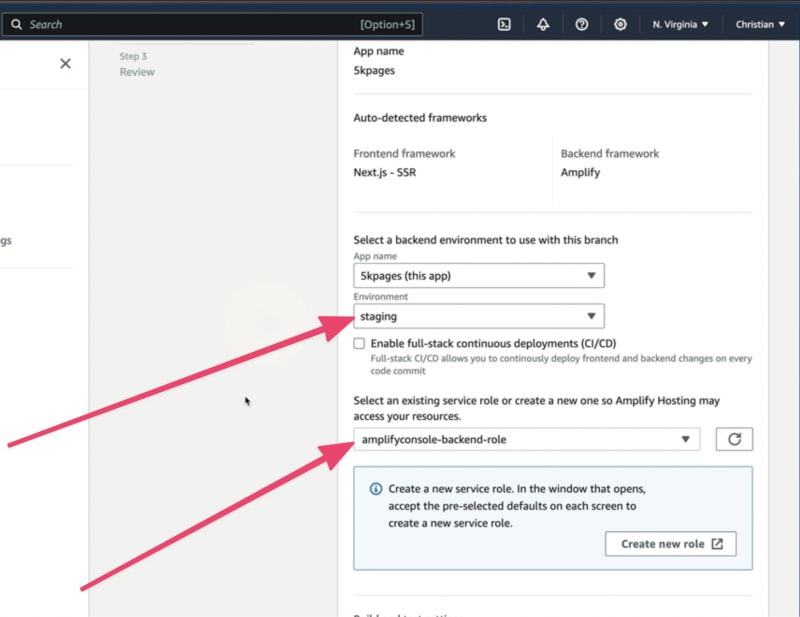
查看你的 存储库详情 和 应用程序设置,然后点击 保存并部署。
开发和用户体验洞见
在构建和部署应用的静态和动态版本时,我一直在追踪一些数字。我想看看在考虑以下几点时是否有任何有用的洞见:
构建时间有多快?
对于访客来说,感知加载速度如何?
开发体验
构建时间有多快?
测量构建时间很容易 - iTerm(本地)和 AWS Amplify(生产环境)在构建过程中都有时间戳,我只需要相减即可。下表显示,在构建时间上,动态参数比静态生成的页面要快。(部署时间仅考虑构建 Next.js 应用程序的时间,不包括配置和后端构建时间。)
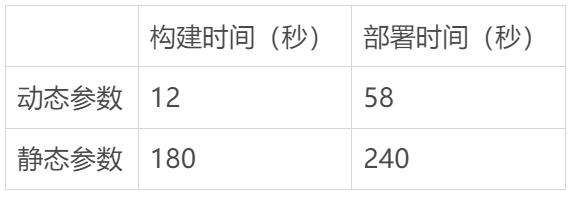
构建时间与部署时间的差异很明显 - 如果我希望每个页面都能静态生成,Next.js 必须构建 5000 个页面中的每一个。
在动态模式下开发,在静态模式下发布
我偶然发现的一个没有人谈论的策略是,在非生产环境中测试时不调用 generateStaticParams 。在暂存服务器上等待构建 5k 个页面是一种痛苦的开发经验。
我的建议是只在生产环境中启用 generateStaticParams ,因为你几乎不会频繁构建生产环境。
用户体验
访问者的感知加载速度如何?
为了了解静态生成网站和动态网站之间的差异,我使用 PageSpeed Insights 对网站进行了分析。以下是首页、动态参数页面和静态生成页面的服务器和缓存速度指数的日志。
为了提供背景,我分析了来自 Next.js 展示页面 的 6 个网站,平均速度指数为 2.6 秒。(在部署成功后立即进行了服务器速度指标测试。通过再次分析进行了缓存速度指标测试)
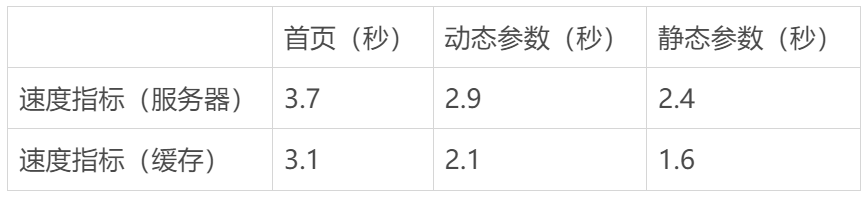
我的第一个观察结果是主页比动态页面加载速度相对较慢,因为主页需要渲染更多的图片。
如预期的那样,静态生成的页面比动态参数加载速度快 1.2 倍。在实际情况中,一个页面将会有更多的文本、字体和图片,与我的演示相比,所以请将 1.2 倍视为近似值,因为在这种情况下差异肯定会更加显著。
其他用户体验指标
速度指标给你一个全面的视角,但在测量网站性能时,仅考虑速度是不够的。什么是速度 是一篇很好的文章,可以帮助你了解为什么以及还应该考虑什么。考虑到这一点,我决定在这里提供 PageSpeed Insights 中所有图片的详细信息,以便你可以深入了解。
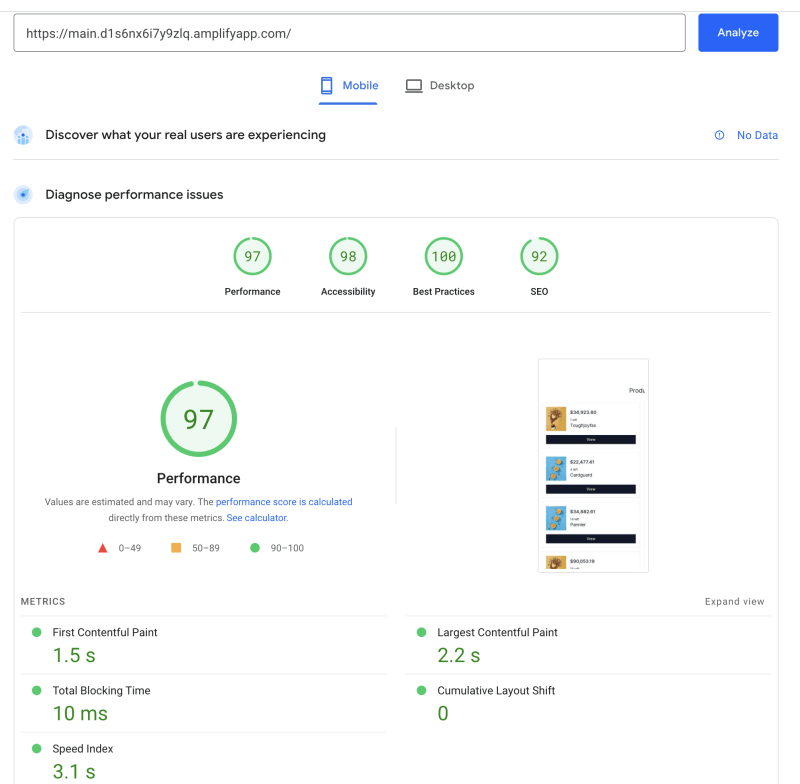
来自服务器的首页:
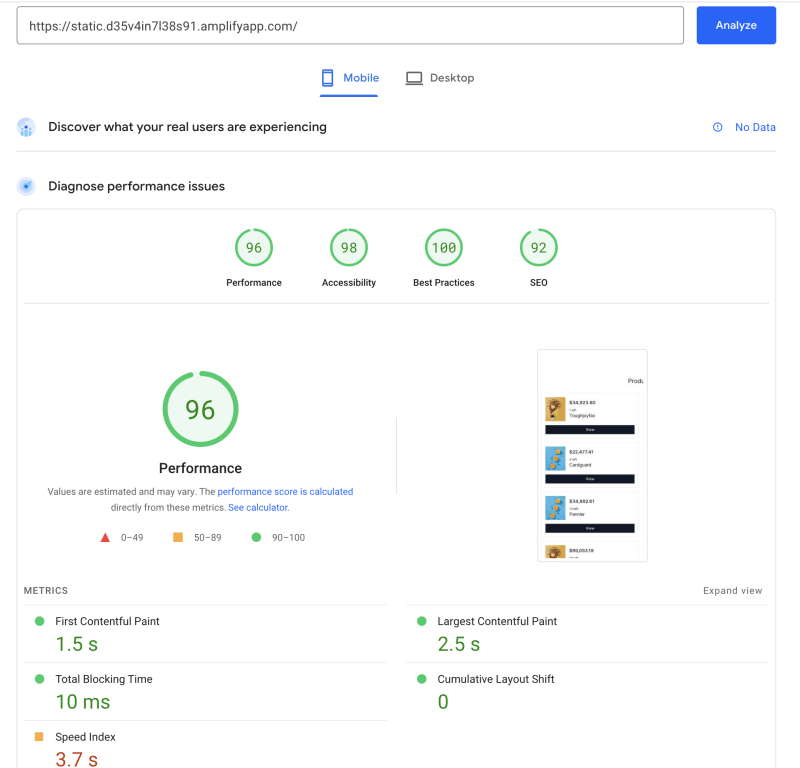
来自服务器的动态参数页面:
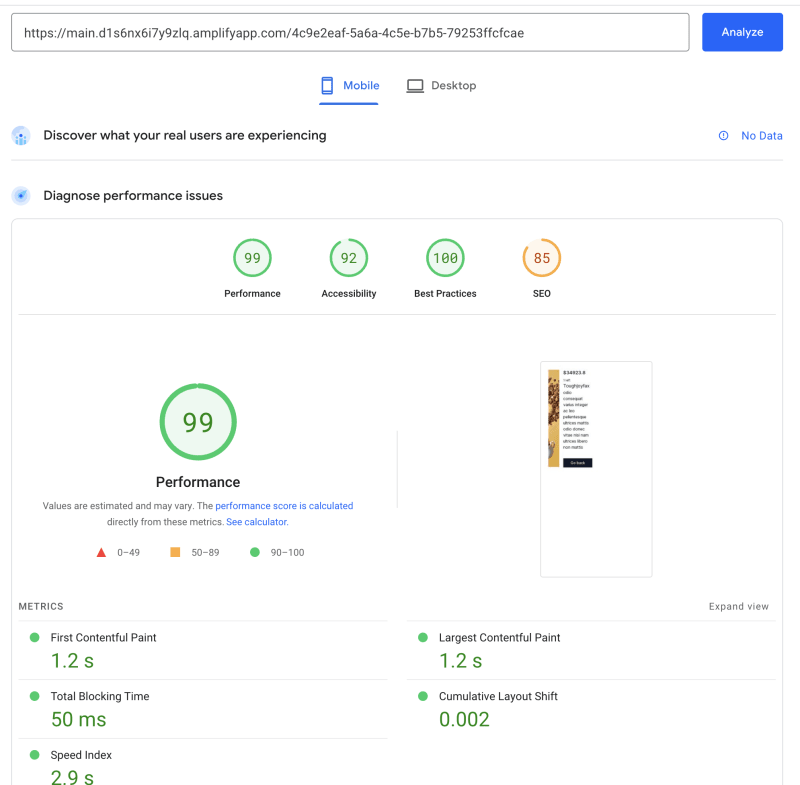
来自服务器的静态生成页面:
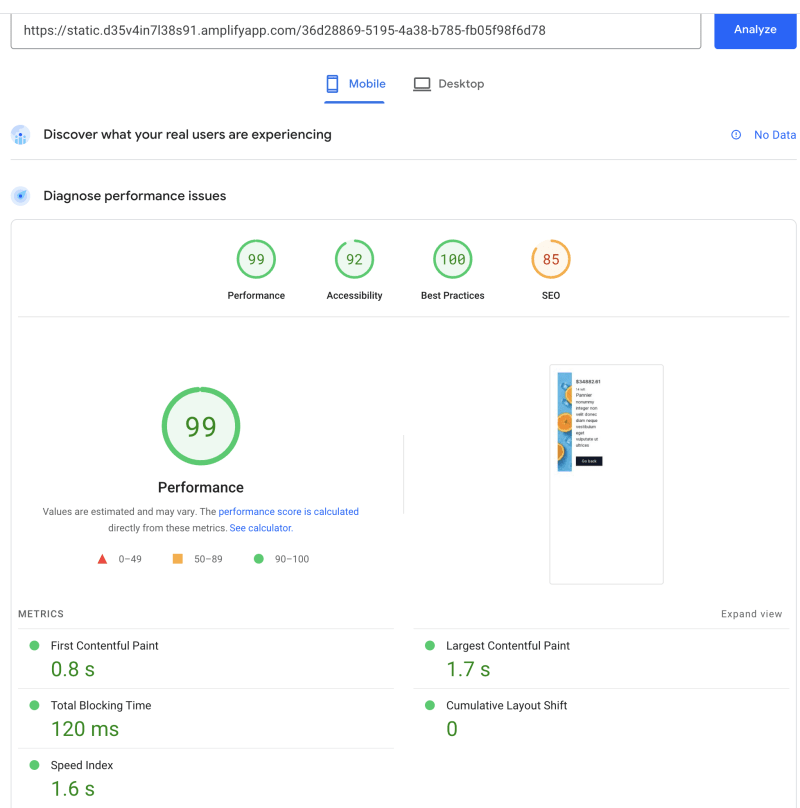
来自缓存的首页:
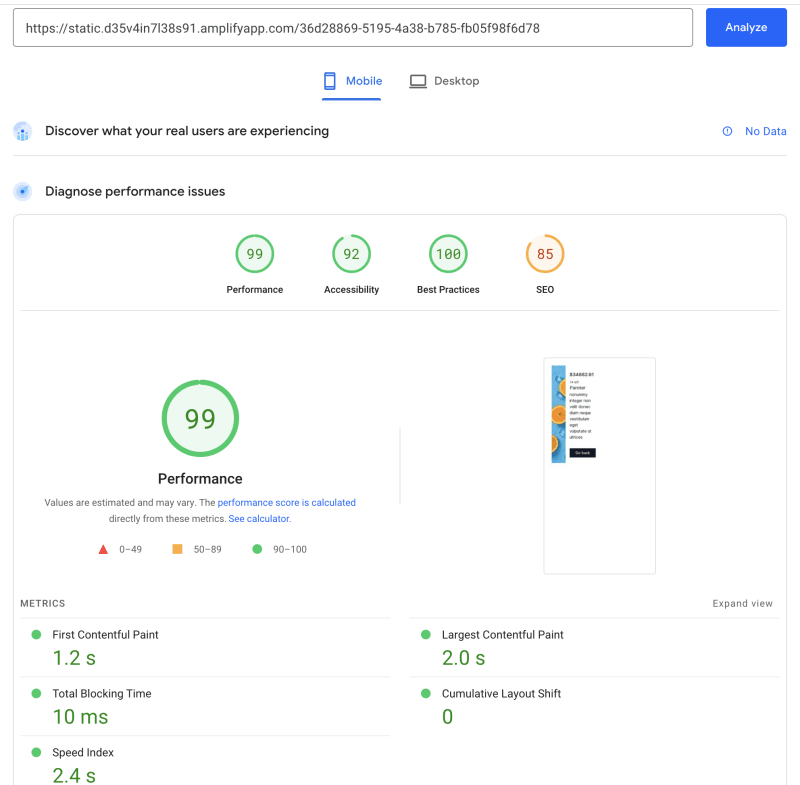
来自缓存的动态参数页面:

来自缓存的静态参数页面:
清理
为了确保你的 AWS 账户中没有未使用的资源,请运行以下命令来删除在此项目中创建的所有资源,如果你不打算保留它们。
我的观点
对我来说,这是一个富有洞察力的实验,它得出了一些有趣的结论,这些结论将在接下来的几个月中指导我在使用 Next.js 时的工作。
对于我的客户体验:我将始终默认在生产环境中使用静态生成的页面,除非动态页面的内容经常更改。此外,Amplify Hosting 在构建所有页面时没有错误,并且没有额外的延迟,这符合我的期望。
对于我的开发体验:在处理动态页面时,我将忽略静态页面生成。它可以作为一个事后的考虑,因为 Next.js 已经设计了 generateStaticParams 以便可插拔。如果你想了解更多关于 Amplify hosting 的信息,可以参考 这里 的入门指南:
https://docs.aws.amazon.com/amplify/latest/userguide/getting-started.html
原文链接:
https://dev.to/codebeast/can-nextjs-handle-5000-pages-1ejn
相关阅读:
Next.js 13 新的实验性特性,实现 App“动态无限制”

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论