

序言
时间回到 2008 年,还在上海交通大学上学的张旭豪、康嘉等人在上海创办了饿了么,从校园外卖场景出发,饿了么一步一步发展壮大,成为外卖行业的领头羊。2017 年 8 月饿了么并购百度外卖,强强合并,继续开疆扩土。2018 年饿了么加入阿里巴巴大家庭,与口碑融合成立阿里巴巴本地生活公司。“爱什么,来什么”,是饿了么对用户不变的承诺。
饿了么的技术也伴随着业务的飞速增长也不断突飞猛进。据公开报道,2014 年 5 月的日订单量只有 10 万,但短短几个月之后就冲到了日订单百万,到当今日订单上千万单。在短短几年的技术发展历程上,饿了么的技术体系、稳定性建设、技术文化建设等都有长足的发展。各位可查看往期文章一探其中发展历程,在此不再赘述:
而可观测性作为技术体系的核心环节之一,也跟随饿了么技术的飞速发展,不断自我革新,从“全链路可观测性 ETrace”扩展到“多活下的可观测性体系 ETrace”,发展成目前“一站式可观测性平台 EMonitor”。

EMonitor 经过 5 年的多次迭代,现在已经建成了集指标数据、链路追踪、可视化面板、报警与分析等多个可观测性领域的平台化产品。EMonitor 每日处理约 1200T 的原始可观测性数据,覆盖饿了么绝大多数中间件,可观测超 5 万台机器实例,可观测性数据时延在 10 秒左右。面向饿了么上千研发人员,EMonitor 提供精准的报警服务和多样化的触达手段,同时运行约 2 万的报警规则。本文就细数饿了么可观测性的建设历程,回顾下“饿了么可观测性建设的那些年”。
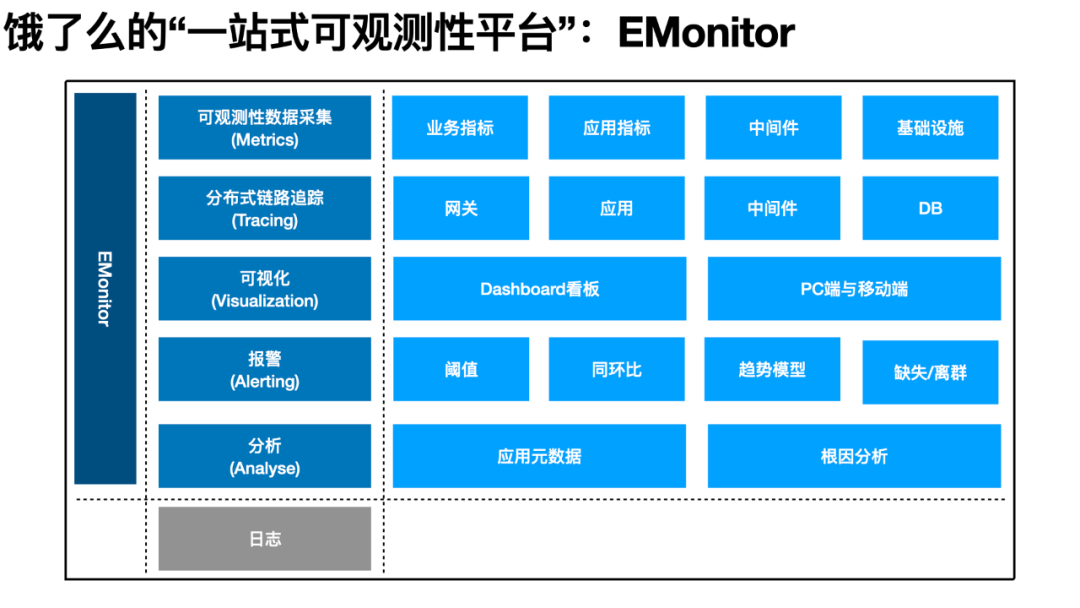
1.0:混沌初开,万物兴起
翻看代码提交记录,ETrace 项目的第一次提交在 2015 年 10 月 24 日。而 2015 年,正是饿了么发展的第七个年头,也是饿了么业务、技术、人员开始蓬勃发展的年头。彼时,饿了么的可观测性系统依赖 Zabbix、Statsd、Grafana 等传统的“轻量级”系统。而“全链路可观测性”正是当时的微服务化技术改造、后端服务 Java 化等技术发展趋势下的必行之势。
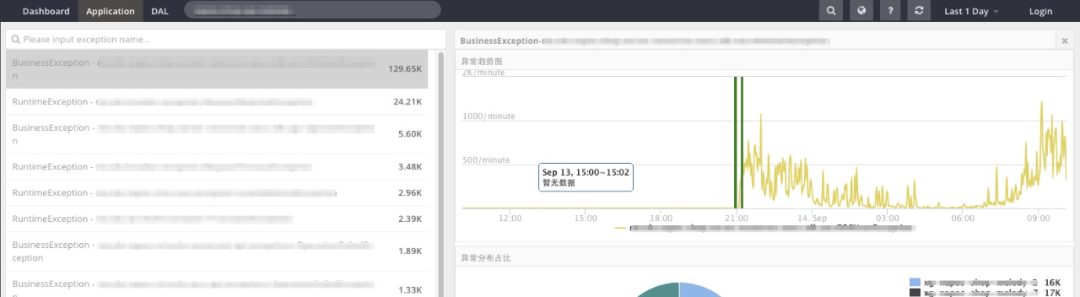
我们可观测性团队,在调研业界主流的全链路可观测性产品——包括著名的开源全链路可观测性产品“CAT”(https://github.com/dianping/cat)后,吸取众家之所长,在两个多月的爆肝开发后,推出了初代 ETrace。我们提供的 Java 版本 ETrace-Agent 随着新版的饿了么 SOA 框架“Pylon”在饿了么研发团队中的推广和普及开来。ETrace-Agent 能自动收集应用的 SOA 调用信息、API 调用信息、慢请求、慢 SQL、异常信息、机器信息、依赖信息等。下图为 1.0 版本的 ETrace 页面截图。
在经历了半年的爆肝开发和各中间件兄弟团队的鼎力支持,我们又开发了 Python 版本的 Agent,更能适应饿了么当时各语言百花齐放的技术体系。并且,通过和饿了么 DAL 组件、缓存组件、消息组件的密切配合与埋点,用户的应用增加了多层次的访问信息,链路更加完整,故障排查过程更加清晰。
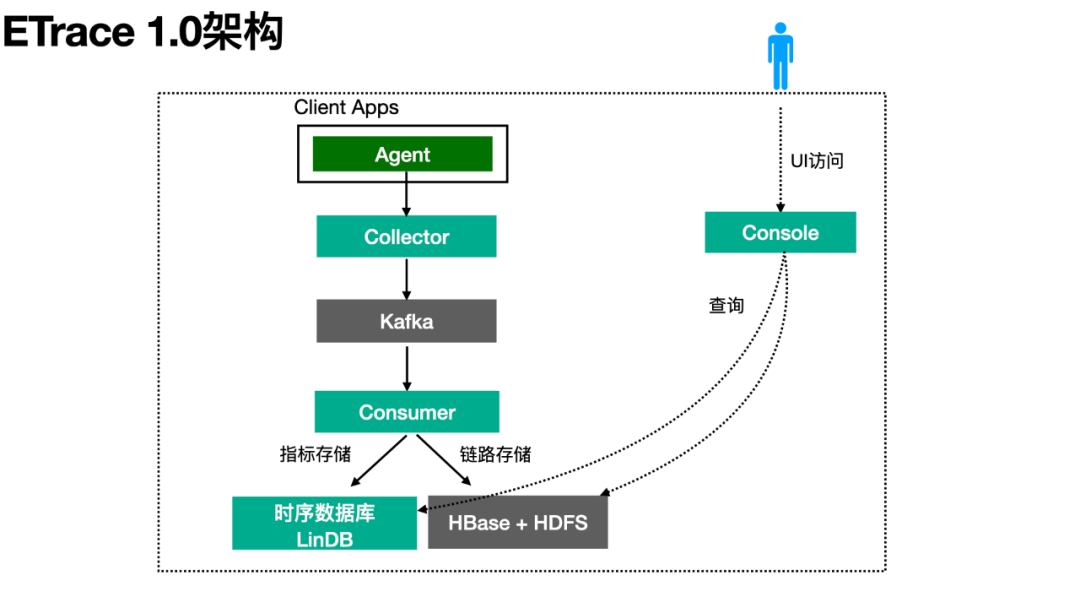
整体架构体系
ETrace 整体架构如下图。通过 SDK 集成在用户应用中的 Agent 定期将 Trace 数据经 Thrift 协议发送到 Collector(Agent 本地不落日志),Collector 经初步过滤后将数据打包压缩发往 Kafka。Kafka 下游的 Consumer 消费这些 Trace 数据,一方面将数据写入 HBase+HDFS,一方面根据与各中间件约定好的埋点规则,将链路数据计算成指标存储到时间序列数据库-- LinDB 中。在用户端,Console 服务提供 UI 及查询指标与链路数据的 API,供用户使用。
全链路可观测性的实现
所谓全链路可观测性,即每次业务请求中都有唯一的能够标记这次业务完整的调用链路,我们称这个 ID 为 RequestId。而每次链路上的调用关系,类似于树形结构,我们将每个树节点上用唯一的 RpcId 标记。
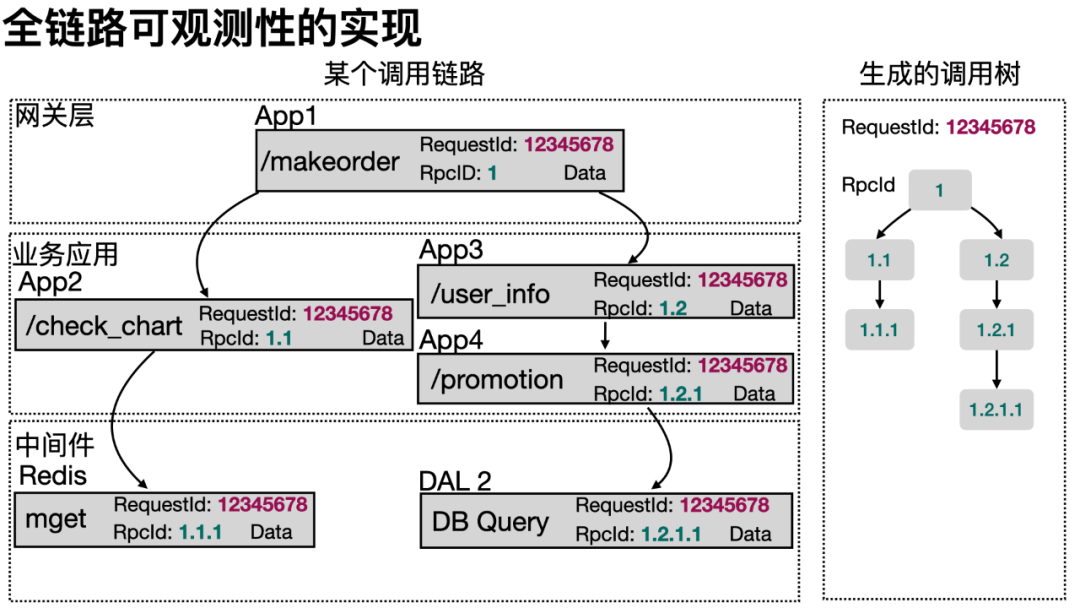
如图,在入口应用 App1 上会新建一个随机 RequestId(一个类似 UUID 的 32 位字符串,再加上生成时的时间戳)。因它为根节点,故 RpcId 为“1”。在后续的 RPC 调用中,RequestId 通过 SOA 框架的 Context 传递到下一节点中,且下一节点的层级加 1,变为形如“1.1”、“1.2”。如此反复,同一个 RequestId 的调用链就通过 RpcId 还原成一个调用树。
也可以看到,“全链路可观测性的实现”不仅依赖与 ETrace 系统自身的实现,更依托与公司整体中间件层面的支持。如在请求入口的 Gateway 层,能对每个请求生成“自动”新的 RequestId(或根据请求中特定的 Header 信息,复用 RequestId 与 RpcId);RPC 框架、Http 框架、Dal 层、Queue 层等都要支持在 Context 中传递 RequestId 与 RpcId。
Consumer 的设计细节
Consumer 组件的核心任务就是将链路数据写入存储。主要思路是以 RequestId+RpcId 作为主键,对应的 Data 数据写入存储的 Payload。再考虑到可观测性场景是写多读少,并且多为文本类型的 Data 数据可批量压缩打包存储,因此我们设计了基于 HDFS+HBase 的两层索引机制。
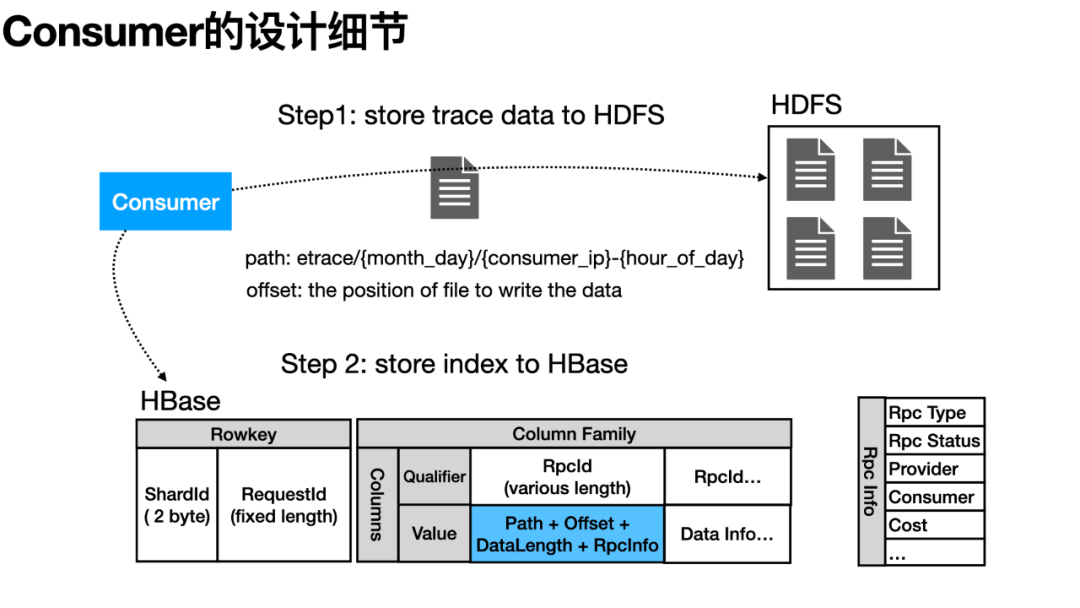
如图,Consumer 将 Collector 已压缩好的 Trace 数据先写入 HDFS,并记录写入的文件 Path 与写入的 Offset,第二步将这些“索引信息”再写入 HBase。特别的,构建 HBase 的 Rowkey 时,基于 ReqeustId 的 Hashcode 和 HBase Table 的 Region 数量配置,来生成两个 Byte 长度的 ShardId 字段作为 Rowkey 前缀,避免了某些固定 RequestId 格式可能造成的写入热点问题。( 因 RequestId 在各调用源头生成,如应用自身、Nginx、饿了么网关层等。可能某应用错误设置成以其 AppId 为前缀 RequestId,若没有 ShardId 来打散,则它所有 RequestId 都将落到同一个 HBase Region Server 上。)
在查询时,根据 RequestId + RpcId 作为查询条件,依次去 HBase、HDFS 查询原始数据,便能找到某次具体的调用链路数据。但有的需求场景是,只知道源头的 RequestId 需要查看整条链路的信息,希望只排查链路中状态异常的或某些指定 RPC 调用的数据。因此,我们在 HBbase 的 Column Value 上还额外写了 RPCInfo 的信息,来记录单次调用的简要信息。如:调用状态、耗时、上下游应用名等。
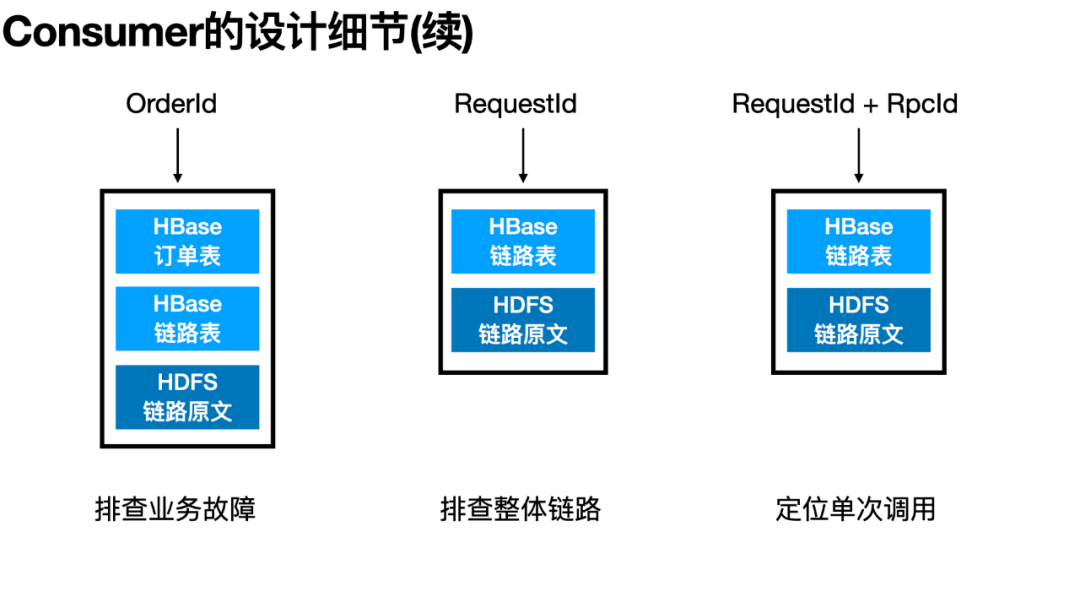
此外,饿了么的场景下,研发团队多以订单号、运单号作为排障的输入,因此我们和业务相关团队约定特殊的埋点规则——在 Transaction 上记录一个特殊的"orderId={实际订单号}"的 Tag——便会在 HBase 中新写一条“订单表”的记录。该表的设计也不复杂,Rowkey 由 ShardId 与订单号组成,Columne Value 部分由对应的 RequestId+RpcId 及订单基本信息(类似上文的 RPCInfo)三部分组成。
如此,从业务链路到全链路信息到详细单个链路,形成了一个完整的全链路排查体系。
Consumer 组件的另一个任务则是将链路数据计算成指标。实现方式是在写入链路数据的同时,在内存中将 Transaction、Event 等数据按照既定的计算逻辑,计算成 SOA、DAL、Queue 等中间件的指标,内存稍加聚合后再写入时序数据库 LinDB。
指标存储:LinDB 1.0
应用指标的存储是一个典型的时间序列数据库的使用场景。根据我们以前的经验,市面上主流的时间序列数据库——OpenTSDB、InfluxDB、Graphite——在扩展能力、集群化、读写效率等方面各有缺憾,所以我们选型使用 RocksDB 作为底层存储引擎,借鉴 Kafka 的集群模式,开发了饿了么的时间序列数据库--LinDB。
指标采用类似 Prometheus 的“指标名+键值对的 Tags”的数据模型,每个指标只有一个支持 Long 或 Double 的 Field。某个典型的指标如:
COUNTER: eleme_makeorder{city="shanghai",channel="app",status="success"} 45
我们主要做了一些设计实现:
指标写入时根据“指标名+Tags”进行 Hash 写入到 LinDB 的 Leader 上,由 Leader 负责同步给他的 Follower。
借鉴 OpenTSDB 的存储设计,将“指标名”、TagKey、TagValue 都转化为 Integer,放入映射表中以节省存储资源。
RocksDB 的存储设计为:以"指标名+TagKeyId + TagValueId+时间(小时粒度)“作为 Key,以该小时时间线内的指标数值作为 Value。
为实现 Counter、Timer 类型数据聚合逻辑,开发了 C++ 版本 RocksDB 插件。
这套存储方案在初期很好的支持了 ETrace 的指标存储需求,为 ETrace 大规模接入与可观测性数据的时效性提供了坚固的保障。有了 ETrace,饿了么的技术人终于能从全链路的角度去排查问题、治理服务,为之后的技术升级、架构演进,提供了可观测性层面的支持。
其中架构的几点说明
1. 是否保证所有可观测性数据的可靠性?
不,我们承诺的是“尽可能不丢”,不保证 100% 的可靠性。基于这个前提,为我们设计架构时提供了诸多便利。如,Agent 与 Collector 若连接失败,若干次重试后便丢弃数据,直到 Collector 恢复可用;Kafka 上下游的生产和消费也不必 ACK,避免影响处理效率。
2. 为什么在 DK 中的 Agent 将数据发给 Collector,而不是直接发送到 Kafka?
避免 Agent 与 Kafka 版本强绑定,并避免引入 Kafka Client 的依赖。
在 Collector 层可以做数据的分流、过滤等操作,增加了数据处理的灵活性。并且 Collector 会将数据压缩后再发送到 Kafka,有效减少 Kafka 的带宽压力。
Collector 机器会有大量 TCP 连接,可针对性使用高性能机器。
3. SDK 中的 Agent 如何控制对业务应用的影响?
纯异步的 API,内部采用队列处理,队列满了就丢弃。
Agent 不会写本地日志,避免占用磁盘 IO、磁盘存储而影响业务应用。
Agent 会定时从 Collector 拉取配置信息,以获取后端 Collector 具体 IP,并可实时配置来开关是否执行埋点。
4. 为什么选择侵入性的 Agent?
选择寄生在业务应用中的 SDK 模式,在当时看来更利于 ETrace 的普及与升级。而从现在的眼光看来,非侵入式的 Agent 对用户的集成更加便利,并且可以通过 Kubernates 中 SideCar 的方式对用户透明部署与升级。
5. 如何实现“尽量不丢数据”?
Agent 中根据获得的 Collector IP 周期性数据发送,若失败则重试 3 次。并定期(5 分钟)获取 Collector 集群的 IP 列表,随机选取可用的 IP 发送数据。
Collector 中实现了基于本地磁盘的 Queue,在后端的 Kafka 不可用时,会将可观测性数据写入到本地磁盘中。待 Kafka 恢复后,又会将磁盘上的数据,继续写入 Kafka。
6. 可观测性数据如何实现多语言支持?
Agent 与 Collector 之间选择 Thrift RPC 框架,并定制整个序列化方式。Java/Python/Go/PHP 的 Agent 依数据规范开发即可。
2.0:异地多活,大势初成
2016 年底,饿了么为了迎接业务快速增长带来的调整,开始推进“异地多活”项目。新的多数据中心架构对既有的可观测性架构也带来了调整,ETrace 亦经过了一年的开发演进,升级到多数据中心的新架构、拆分出实时计算模块、增加报警功能等,进入 ETrace2.0 时代。
异地多活的挑战
随着饿了么的异地多活的技术改造方案(https://zhuanlan.zhihu.com/p/32009822)确定,对可观测性平台提出了新的挑战:如何设计多活架构下的可观测性系统?以及如何聚合多数据中心的可观测性数据?
经过一年多的推广与接入,ETrace 已覆盖了饿了么绝大多数各语言的应用,每日处理数据量已达到了数十 T 以上。在此数据规模下,决不可能将数据拉回到某个中心机房处理。因此“异地多活”架构下的可观测性设计的原则是:各机房处理各自的可观测性数据。
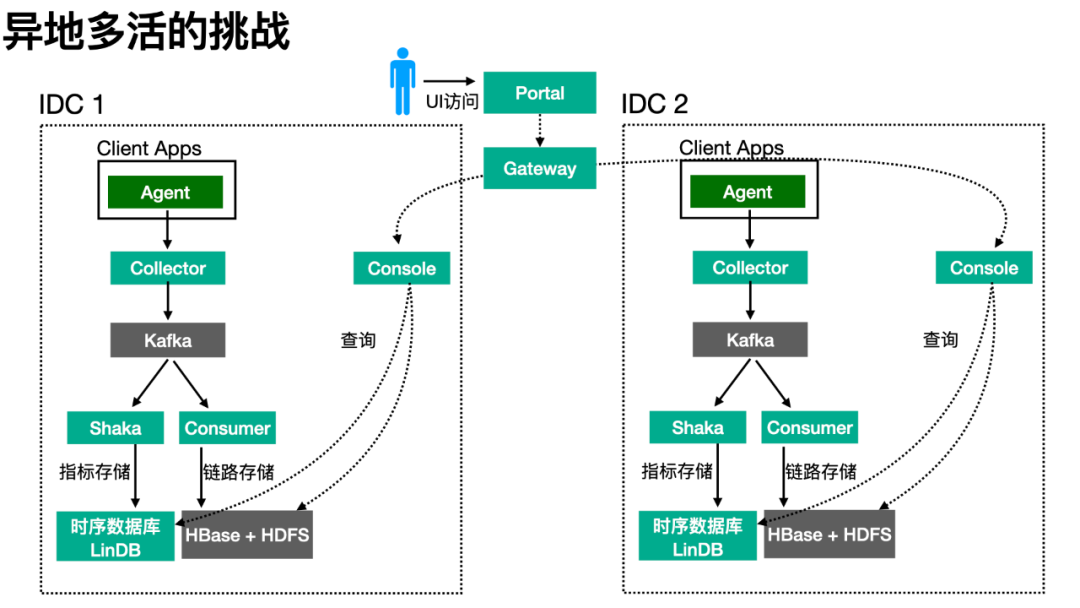
我们开发一个 Gateway 模块来代理与聚合各数据中心的返回结果,它会感知各机房间内 Console 服务。图中它处于某个中央的云上区域,实际上它可以部署在各机房中,通过域名的映射机制来做切换。
如此部署的架构下,各机房中的应用由与机房相绑定的环境变量控制将可观测性数据发送到该机房内的 ETrace 集群,收集、计算、存储等过程都在同一机房内完成。用户通过前端 Portal 来访问各机房内的数据,使用体验和之前类似。
即使考虑极端情况下——某机房完全不可用(如断网),“异地多活”架构可将业务流量切换到存活的机房中,让业务继续运转。而可观测性上,通过将 Portal 域名与 Gateway 域名切换到存活的机房中,ETrace 便能继续工作(虽然会缺失故障机房的数据)。在机房网络恢复后,故障机房内的可观测性数据也能自动恢复(因为该机房内的可观测性数据处理流程在断网时仍在正常运作)。
可观测性数据实时处理的挑战
在 1.0 版本中的 Consumer 组件,既负责将链路数据写入到 HBase/HDFS 中,又负责将链路数据计算成指标存储到 LinDB 中。两个流程可视为同步的流程,但前者可接受数分钟的延迟,后者要求达到实时的时效性。当时 HBase 集群受限于机器性能与规模,经常在数据热点时会写入抖动,进而造成指标计算抖动,影响可用性。因此,我们迫切需要拆分链路写入模块与指标计算模块。
在选型实时计算引擎时,我们考虑到需求场景是:
能灵活的配置链路数据的计算规则,最好能动态调整;
能水平扩展,以适应业务的快速发展;
数据输出与既有系统(如 LinDB 与 Kafka)无缝衔接;
很遗憾的是,彼时业界无现成的拿来即用的大数据流处理产品。我们就基于复杂事件处理(CEP)引擎 Esper 实现了一个类 SQL 的实时数据计算平台——Shaka。Shaka 包括“Shaka Console”和“Shaka Container”两个模块。Shaka Console 由用户在图形化界面上使用,来配置数据处理流程(Pipeline)、集群、数据源等信息。用户完成 Pipeline 配置后,Shaka Console 会将变更推送到 Zookeeper 上。无状态的 Shaka Container 会监听 Zookeeper 上的配置变更,根据自己所属的集群去更新内部运行的 Component 组件。而各 Component 实现了各种数据的处理逻辑:消费 Kafka 数据、处理 Trace/Metric 数据、Metric 聚合、运行 Esper 逻辑等。
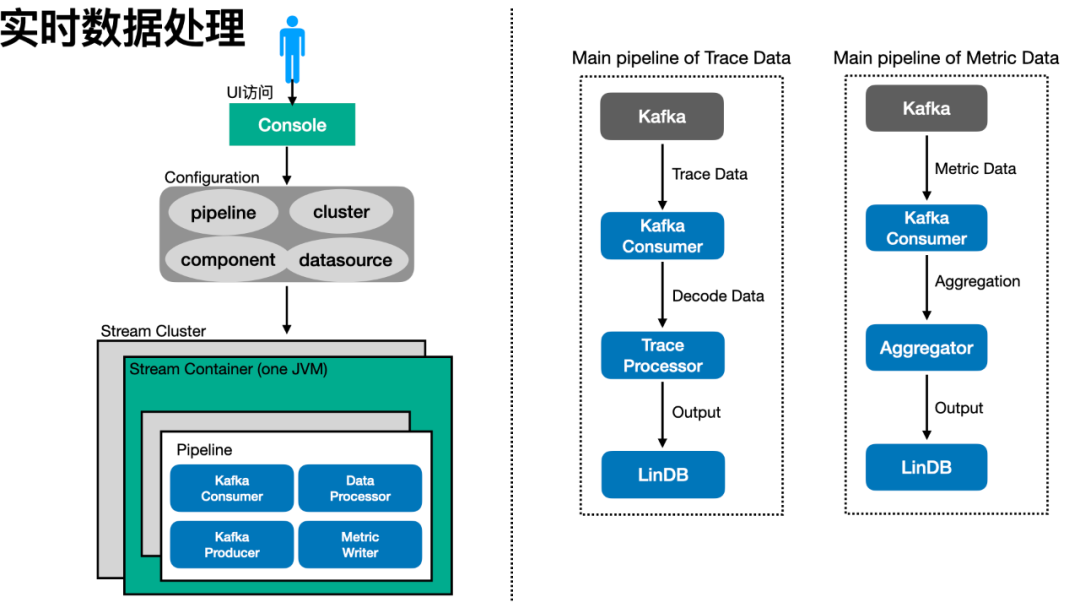
Trace 数据和 Metric 格式转换成固定的格式后,剩下来按需编写 Esper 语句就能生成所需的指标了。如下文所示的 Esper 语句,就能将类型为 Transaction 的 Trace 数据计算成以“{appId}.transaction”的指标(若 Consumer 中以编码方式实现,约需要近百行代码)。经过这次的架构升级,Trace 数据能快速的转化为实时的 Metric 数据,并且对于业务的可观测性需求,只用改改 SQL 语句就能快速满足,显著降低了开发成本和提升了开发效率。
ETrace API 示例
在 Java 或 Python 中提供链路埋点的 API:
新的 UI、更丰富的中间件数据
1.0 版本的前端 UI,是集成在 Console 项目中基于 Angular V1 开发的。我们迫切希望能做到前后端分离,各司其职。于是基于 Angular V2 的若干个月开发,新的 Portal 组件登场。得益于 Angular 的数据绑定机制,新的 ETrace UI 各组件间联动更自然,排查故障更方便。
饿了么自有中间件的研发进程也在不断前行,在可观测性的打通上也不断深化。2.0 阶段,我们进一步集成了——Redis、Queue、ElasticSearch 等等,覆盖了饿了么所有的中间件,让可观测性无死角。
杀手级功能:指标查看与链路查看的无缝整合
传统的可观测性系统提供的排障方式大致是:接收报警(Alert)--查看指标(Metrics)--登陆机器--搜索日志(Trace/Log),而 ETrace 通过 Metric 与 Trace 的整合,能让用户直接在 UI 上通过点击就能定位绝大部分问题,显著拔高了用户的使用体验与排障速度。
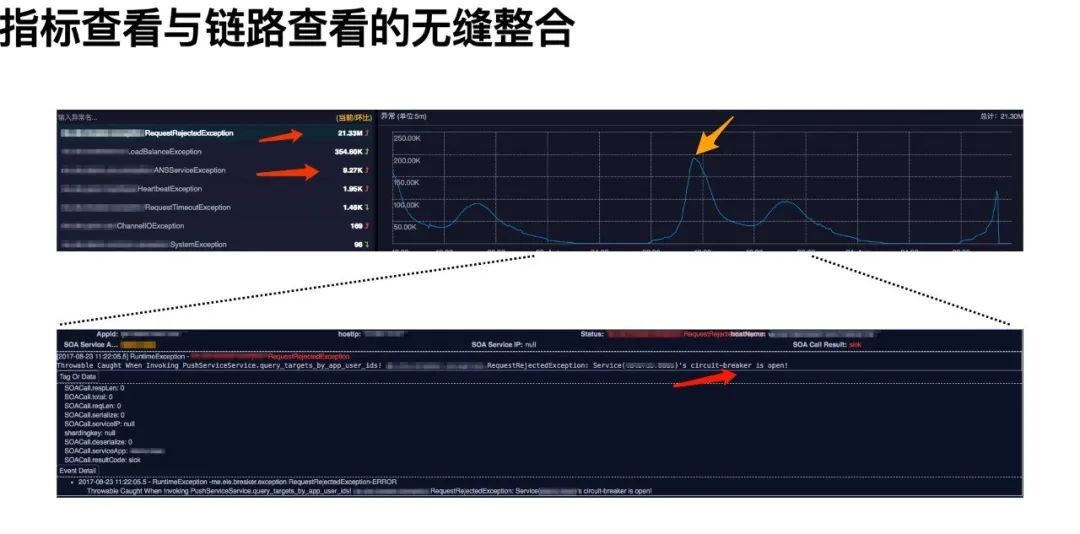
某个排查场景如:用户发现总量异常突然增加,可在界面上筛选机房、异常类型等找到实际突增的某个异常,再在曲线上直接点击数据点,就会弹出对应时间段的异常链路信息。链路上有详细的上下游信息,能帮助用户定位故障。

它的实现原理如上图所示。具体的,前文提到的实时计算模块 Shaka 将 Trace 数据计算成 Metric 数据时,会额外以抽样的方式将 Trace 上的 RequsetId 与 RpcId 也写到 Metric 上(即上文 Esper 语句中,生成的 Metric 中的 Sampling 字段)。这种 Metric 数据会被 Consumer 模块消费并写入到 HBase 一张 Sampling 表中。
用户在前端 Portal 的指标曲线上点击某个点时,会构建一个 Sampling 的查询请求。该请求会带上:该曲线的指标名、数据点的起止时间、用户选择过滤条件(即 Tags)。Consumer 基于这些信息构建一个 HBase 的 RegexStringComparator 的 Scan 查询。查询结果中可能会包含多个结果,对应着该时间点内数据点(Metric)上发生的多个调用链路(Trace),继而拿着结果中的 RequestId+RpcId 再去查询一次 HBase/HDFS 存储就能获得链路原文。(注:实际构建 HBase Rowkey 时 Tag 部分存的是其 Hashcode 而不是原文 String。)
众多转岗、离职的饿了么小伙伴,最念念不忘的就是这种“所见即所得”的可观测性排障体验。
报警 Watchdog 1.0
在应用可观测性基本全覆盖之后,报警的需求自然成了题中之义。技术选型上,根据我们在实时计算模块 Shaka 上收获的经验,决定再造一个基于实时数据的报警系统——Watchdog。
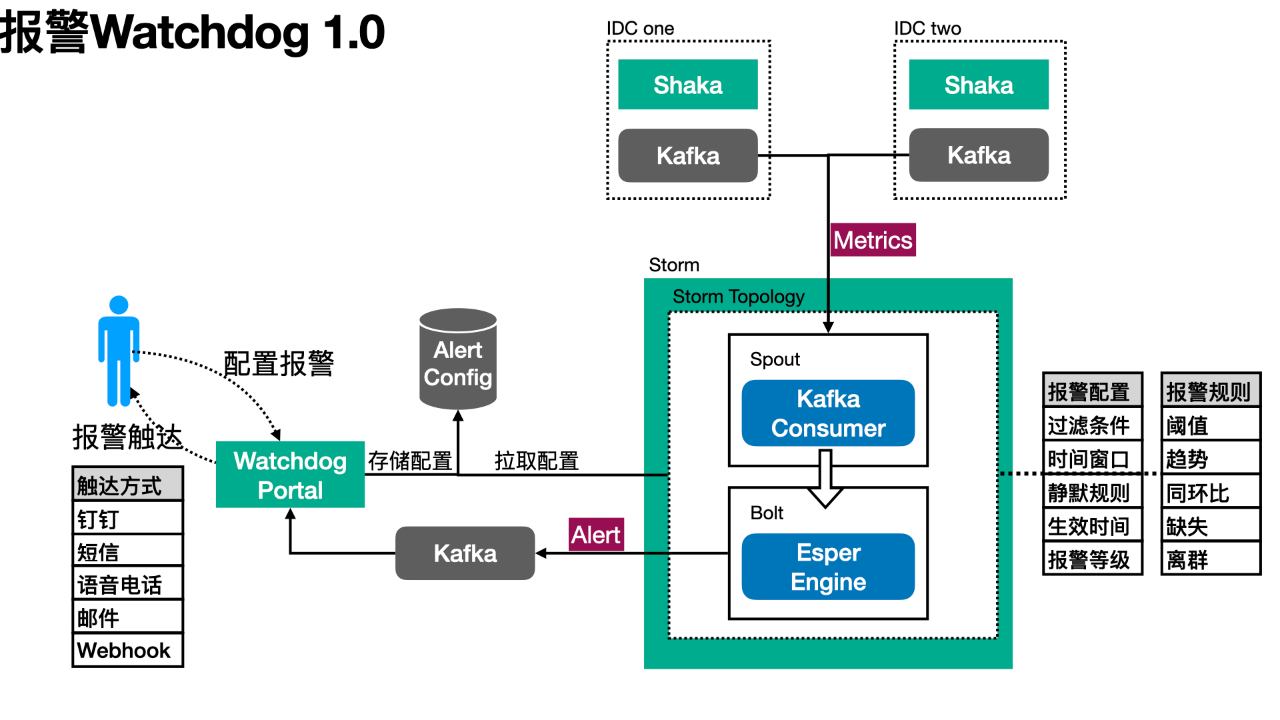
实时计算模块 Shaka 中已经将 Trace 数据计算成指标 Metrics,报警模块只需消费这些数据,再结合用户配置的报警规则产出报警事件即可。因此,我们选型使用 Storm 作为流式计算平台,在 Spount 层次根据报警规则过滤和分流数据,在 Bolt 层中 Esper 引擎运行着由用户配置的报警规则转化成 Esper 语句并处理分流后的 Metric 数据。若有符合 Esper 规则的数据,即生成一个报警事件 Alert。Watchdog Portal 模块订阅 Kafka 中的报警事件,再根据具体报警的触达方式通知到用户。默认 Esper 引擎中数据聚合时间窗口为 1 分钟,所以整个数据处理流程的时延约为 1 分钟左右。
Metrics API 与 LinDB 2.0:
在 ETrace 1.0 阶段,我们只提供了 Trace 相关的 API,LinDB 仅供内部存储使用。用户逐步的意识到如果能将“指标”与“链路”整合起来,就能发挥更大的功用。因此我们在 ETrace-Agent 中新增了 Metrics 相关的 API:
基于这些 API,用户可以在代码中针对他的业务逻辑进行指标埋点,为后来可观测性大一统提供了实现条件。在其他组件同步开发时,我们也针对 LinDB 做了若干优化,提升了写入性能与易用性:
增加 Histogram、Gauge、Payload、Ratio 多种指标数据类型;
从 1.0 版本的每条指标数据都调用一次 RocksDB 的 API 进行写入,改成先在内存中聚合一段时间,再通过 RocksDB 的 API 进行批量写入文件。
3.0:推陈出新,融会贯通
可观测性系统大一统
在 2017 年的饿了么,除了 ETrace 外还有多套可观测性系统:基于 Statsd/Graphite 的业务可观测性系统、基于 InfluxDB 的基础设施可观测性系统。后两者都集成 Grafana 上,用户可以去查看他的业务或者机器的详细指标。但实际排障场景中,用户还是需要在多套系统间来回切换:根据 Grafana 上的业务指标感知业务故障,到 ETrace 上查看具体的 SOA/DB 故障,再到 Grafana 上去查看具体机器的网络或磁盘 IO 指标。
虽然,我们也开发了 Grafana 的插件来集成 LinDB 的数据源,但因本质上差异巨大的系统架构,还是让用户“疲于奔命”式的来回切换系统,用户难以有统一的可观测性体验。因此 2018 年初,我们下定决心:将多套可观测性系统合而为一,打通“业务可观测性+应用可观测性+基础设施可观测性”,让 ETrace 真正成为饿了么的一站式可观测性平台。
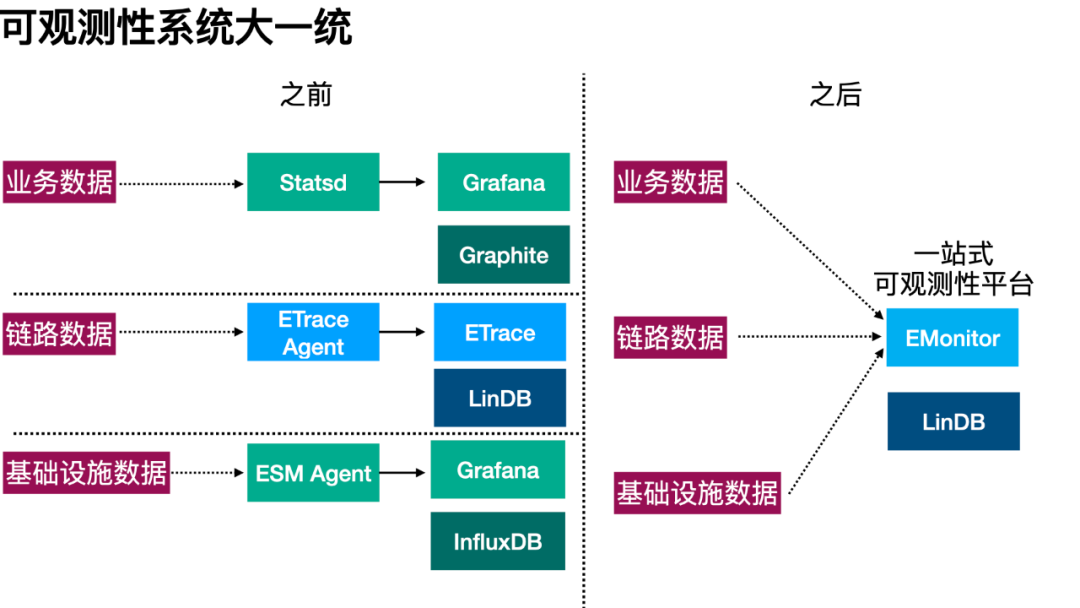
1、LinDB 3.0
所谓“改造”未动,“存储”先行。想要整合 InfluxDB 与 Statsd,先要研究他们与 LinDB 的异同。我们发现,InfluxDB 是支持一个指标名(Measurement)上有多个 Field Key 的。如,InfluxDB 可能有以下指标:
若是 LinDB 2.0 的模式,则需要将上述指标转换成两个指标:
可以想见在数据存储与计算效率上,单 Field 模式有着极大的浪费。但更改指标存储的 Schema,意味着整个数据处理链路都需要做适配和调整,工作量和改动极大。然而不改就意味着“将就”,我们不能忍受对自己要求的降低。因此又经过了几个月的爆肝研发,LinDB 3.0 开发完成。
这次改动,除了升级到指标多 Fields 模式外,还有以下优化点:
集群方面引入 Kafka 的 ISR 设计,解决了之前机器故障时查询数据缺失的问题。
存储层面支持更加通用的多 Field 模式,并且支持对多 Field 之间的表达式运算。
引入了倒排索引,显著提高了对于任意 Tag 组合的过滤查询的性能。
支持了自动化的 Rollup 操作,对于任意时间范围的查询自动选取合适的粒度来聚合。
经过这次大规模优化后,从最初的每日 5T 指标数据涨到如今的每日 200T 数据,LinDB 3.0 都经受住了考验。指标查询的响应时间的 99 分位线为 200ms。详细设计细节可参看分布式时序数据库--LinDB(https://zhuanlan.zhihu.com/p/35998778)。
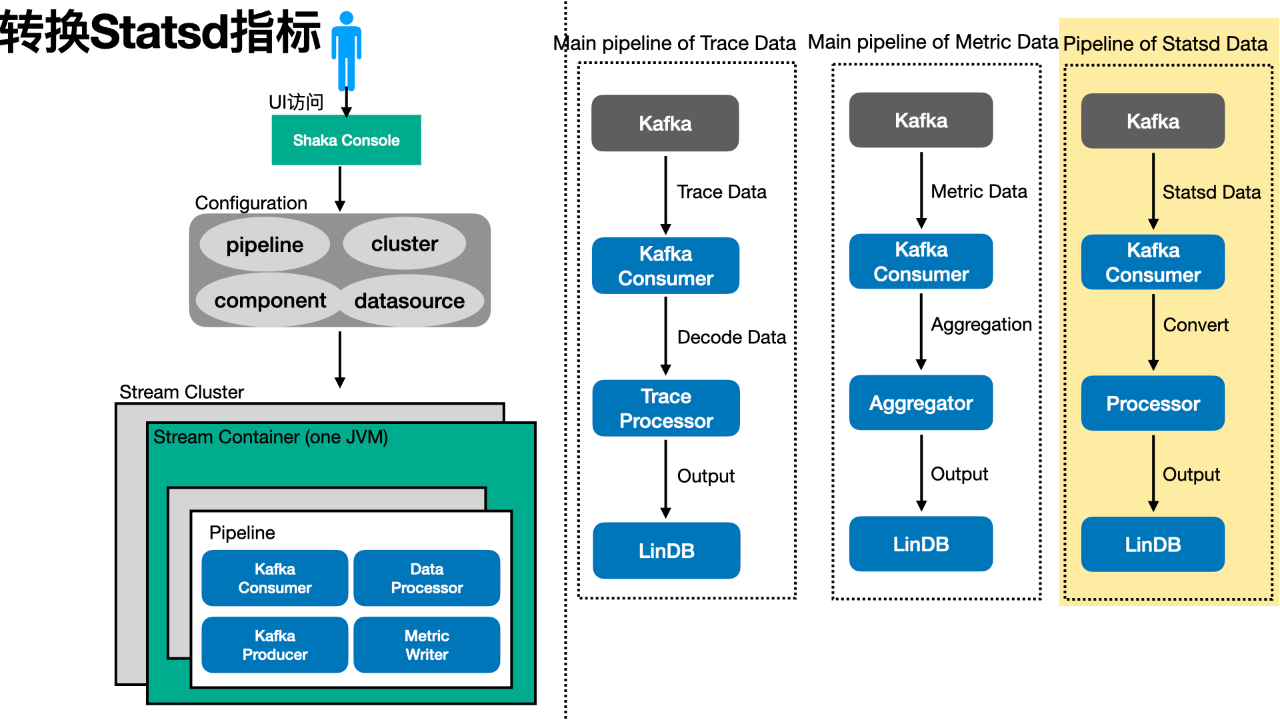
2、将 Statsd 指标转成 LinDB 指标
Statsd 是饿了么广泛使用的业务指标埋点方案,各机房有一个数十台机器规模的 Graphite 集群。考虑到业务的核心指标都在 Statsd 上,并且各个 AppId 以 ETrace Metrics API 替换 Statsd 是一个漫长的过程(也确实是,前前后后替换完成就花了将近一年时间)。为了减少对用户与 NOC 团队的影响,我们决定:用户更新代码的同时,由 ETrace 同时“兼容”Statsd 的数据。
得益于饿了么强大的中间件体系,业务在用 Statsd API 埋点的同时会“自动”记一条特殊的 Trace 数据,携带上 Statsd 的 Metric 数据。那么只要处理 Trace 数据中的 Statsd 埋点,我们就能将大多数 Statsd 指标转化为 LinDB 指标。如下图:多个 Statsd 指标会转为同一个 LinDB 指标。
之前我们的实时计算模块 Shaka 就在这里派上了大用场:只要再新增一路数据处理流程即可。如下图,新增一条 Statsd 数据的处理 Pipeline,并输出结果到 LinDB。在用户的代码全部从 Statsd API 迁移到 ETrace API 后,这一路处理逻辑即可移除。
3、将 InfluxDB 指标转成 LinDB 指标
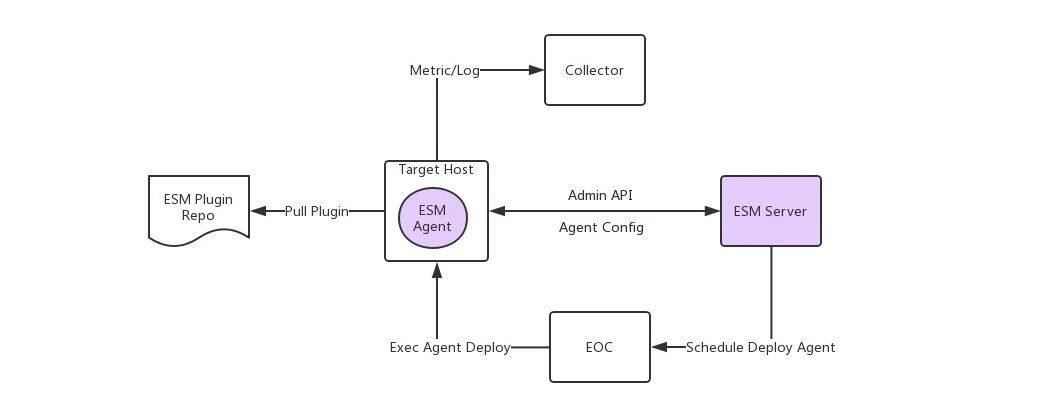
InfluxDB 主要用于机器、网络设备等基础设施的可观测性数据。饿了么每台机器上,都部署了一个 ESM-Agent。它负责采集机器的物理指标(CPU、网络协议、磁盘、进程等),并在特定设备上进行网络嗅探(Smoke Ping)等。这个数据采集 Agent 原由 Python 开发,在不断需求堆叠之后,已庞大到难以维护;并且每次更新可观测逻辑,都需要全量发布每台机器上的 Agent,导致每次 Agent 的发布都令人心惊胆战。
我们从 0 开始,以 Golang 重新开发了一套 ESM-Agent,做了以下改进:
可观测性逻辑以插件的形式,推送到各宿主机上。不同的设备、不同应用的机器,其上运行的插件可以定制化部署。
制定插件的交互接口,让中间件团队可定制自己的数据采集实现,解放了生产力。
移除了 etcd,使用 MySql 做配置数据存储,减轻了系统的复杂度。
开发了便利的发布界面,可灰度、全量的推送与发布 Agent,运维工作变得轻松。
最重要的,收集到的数据以 LinDB 多 Fields 的格式发送到 Collector 组件,由其发送到后续的处理与存储流程上。
3、将 InfluxDB 指标转成 LinDB 指标
InfluxDB 主要用于机器、网络设备等基础设施的可观测性数据。饿了么每台机器上,都部署了一个 ESM-Agent。它负责采集机器的物理指标(CPU、网络协议、磁盘、进程等),并在特定设备上进行网络嗅探(Smoke Ping)等。这个数据采集 Agent 原由 Python 开发,在不断需求堆叠之后,已庞大到难以维护;并且每次更新可观测逻辑,都需要全量发布每台机器上的 Agent,导致每次 Agent 的发布都令人心惊胆战。
我们从 0 开始,以 Golang 重新开发了一套 ESM-Agent,做了以下改进:
可观测性逻辑以插件的形式,推送到各宿主机上。不同的设备、不同应用的机器,其上运行的插件可以定制化部署。
制定插件的交互接口,让中间件团队可定制自己的数据采集实现,解放了生产力。
移除了 etcd,使用 MySql 做配置数据存储,减轻了系统的复杂度。
开发了便利的发布界面,可灰度、全量的推送与发布 Agent,运维工作变得轻松。
最重要的,收集到的数据以 LinDB 多 Fields 的格式发送到 Collector 组件,由其发送到后续的处理与存储流程上。
从 ETrace 到 EMonitor,不断升级的可观测性体验
2017 年底,我们团队终于迎来了一名正式的前端开发工程师,可观测性团队正式从后端开发写前端的状态中脱离出来。在之前的 Angular 的开发体验中,我们深感“状态转换”的控制流程甚为繁琐,并且开发的组件难以复用(虽然其后版本的 Angular 有了很大的改善)。在调用当时流行的前端框架后,我们在 Vue 与 React 之中选择了后者,辅以 Ant Design 框架,开发出了媲美 Grafana 的指标看版与便利的链路看板,并且在 PC 版本之外还开发了移动端的定制版本。我们亦更名了整个可观测性产品,从“ETrace”更新为“EMonitor”:不仅仅是链路可观测性系统,更是饿了么的一站式可观测性平台。
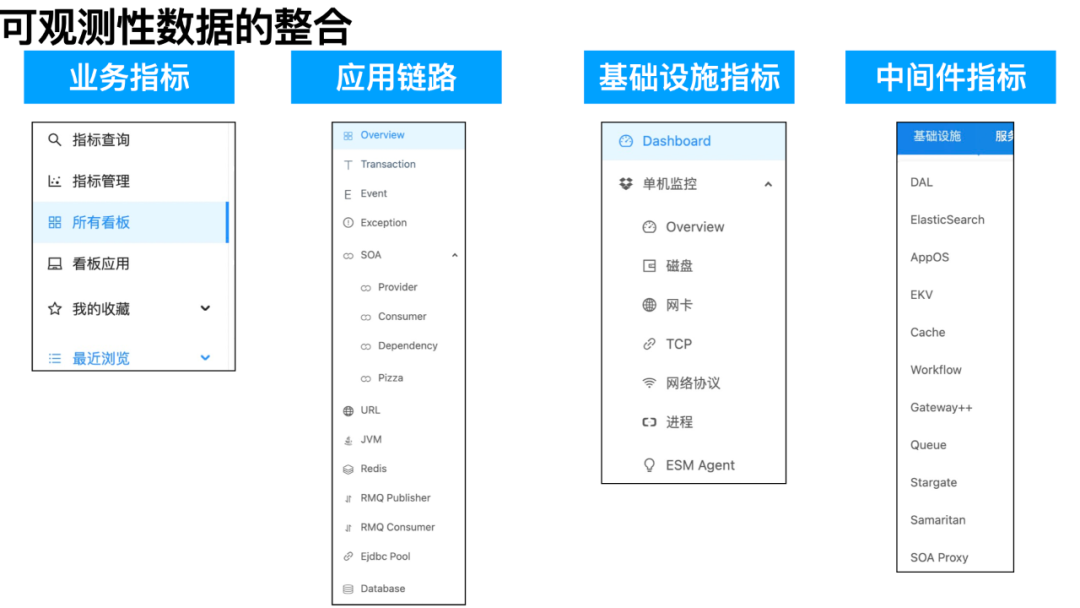
1、可观测性数据的整合:业务指标 + 应用链路 + 基础设施指标 + 中间件指标
在指标系统都迁移到 LinDB 后,我们在 EMonitor 上集成了“业务指标 + 应用链路 + 基础设施指标 + 中间件指标”的多层次的可观测性数据,让用户能在一处观测它的业务数据、排查业务故障、深挖底层基础设施的数据。
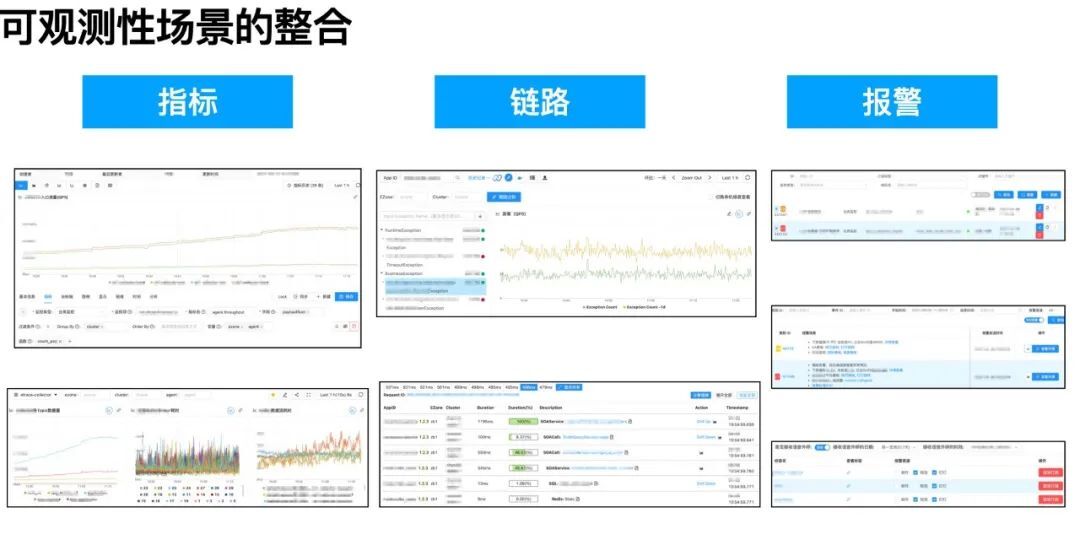
2、可观测性场景的整合:指标 + 链路 + 报警
在可观测性场景上,“指标看板”用于日常业务盯屏与宏观业务可观测性,“链路”作为应用排障与微观业务逻辑透出,“报警”则实现可观测性自动化,提高应急响应效率。
3、灵活的看板配置与业务大盘
在指标配置上,我们提供了多种图表类型--线图、面积图、散点图、柱状图、饼图、表格、文本等,以及丰富的自定义图表配置项,能满足用户不同数据展示需求。
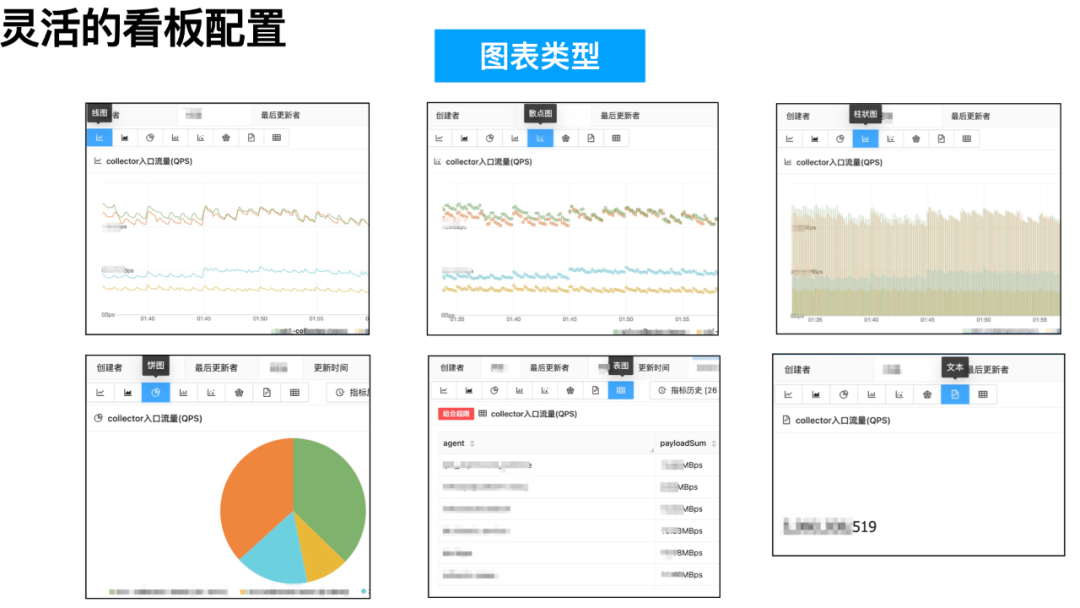
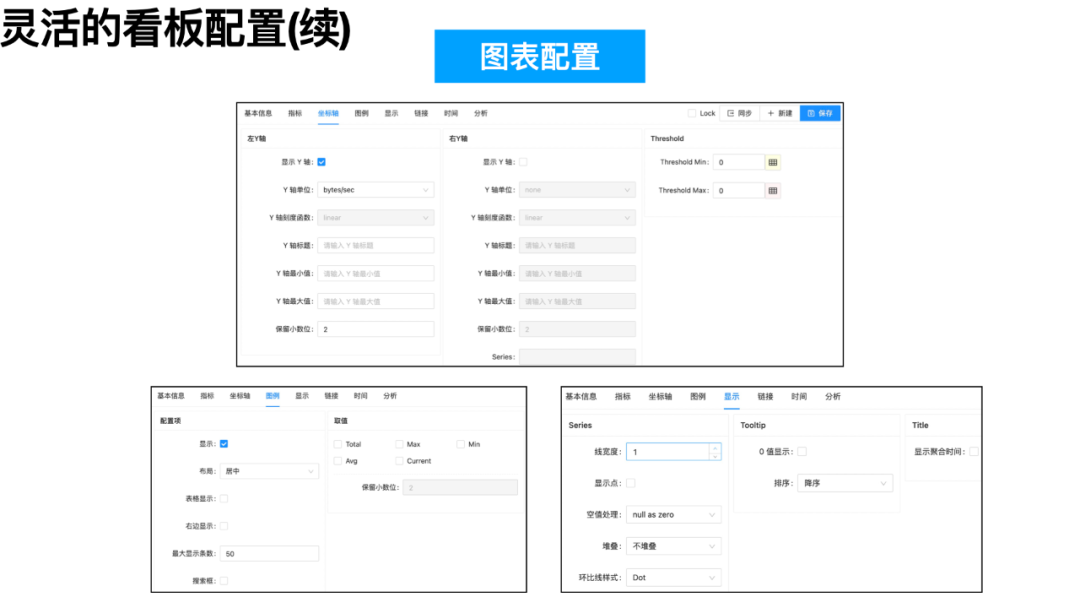
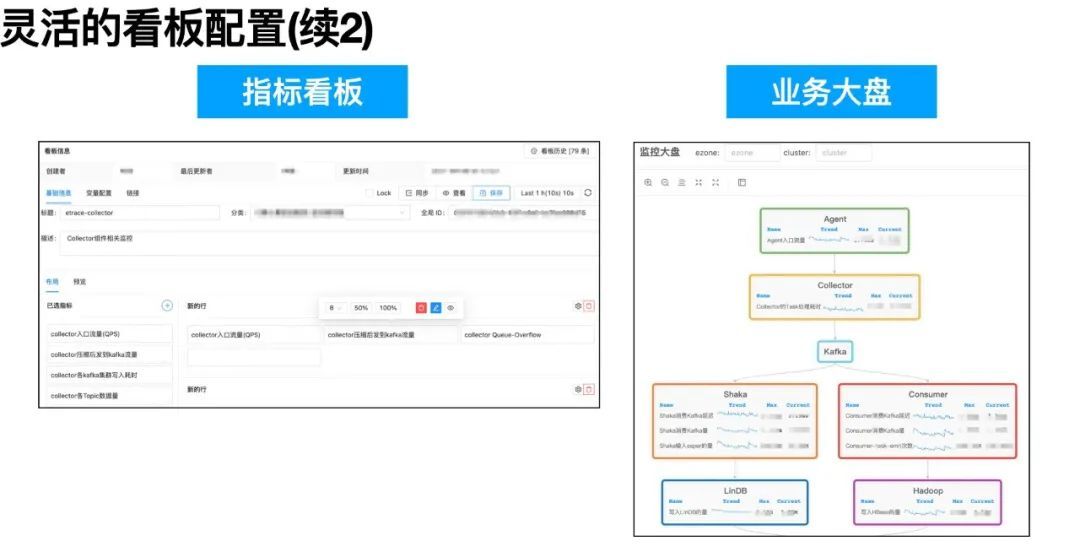
在完成单个指标配置后,用户需要将若干个指标组合成所需的指标看板。用户在配置页面中,先选择待用的指标,再通过拖拽的方式,配置指标的布局便可实时预览布局效果。一个指标可被多个看板引用,指标的更新也会自动同步到所有看板上。为避免指标配置错误而引起歧义,我们也开发了“配置历史”的功能,指标、看板等配置都能回滚到任意历史版本上。
看板配置是静态图表组合,而业务大盘提供了生动的业务逻辑视图。用户可以根据他的业务场景,将指标配置整合成一张宏观的业务图。
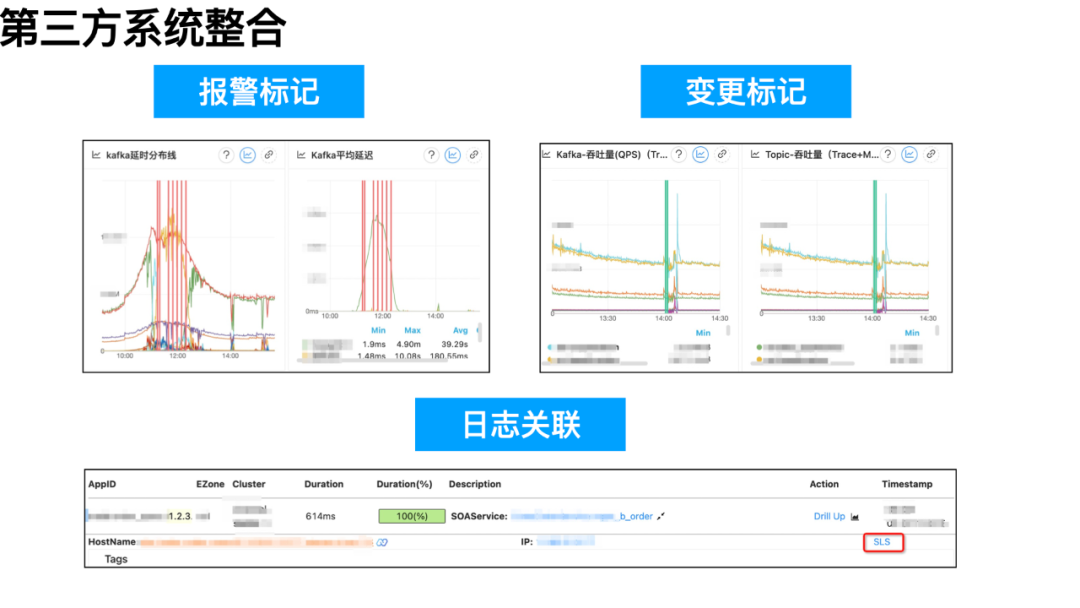
4、第三方系统整合:变更系统 + SLS 日志
因每条报警信息和指标配置信息都与 AppId 关联,那么在指标看板上可同步标记出报警的触发时间。同理,我们拉取了饿了么变更系统的应用变更数据,将其标注到对应 AppId 相关的指标上。在故障发生时,用户查看指标数据时,能根据有无变更记录、报警记录来初步判断故障原因。
饿了么的日志中间件能自动在记录日志时加上对应的 ETrace 的 RequestId 等链路信息。如此,用户查看 SLS 日志服务时,能反查到整条链路的 RequestId;而 EMonitor 也在链路查看页面,拼接好了该应用所属的 SLS 链接信息,用户点击后能直达对应的 SLS 查看日志上下文。
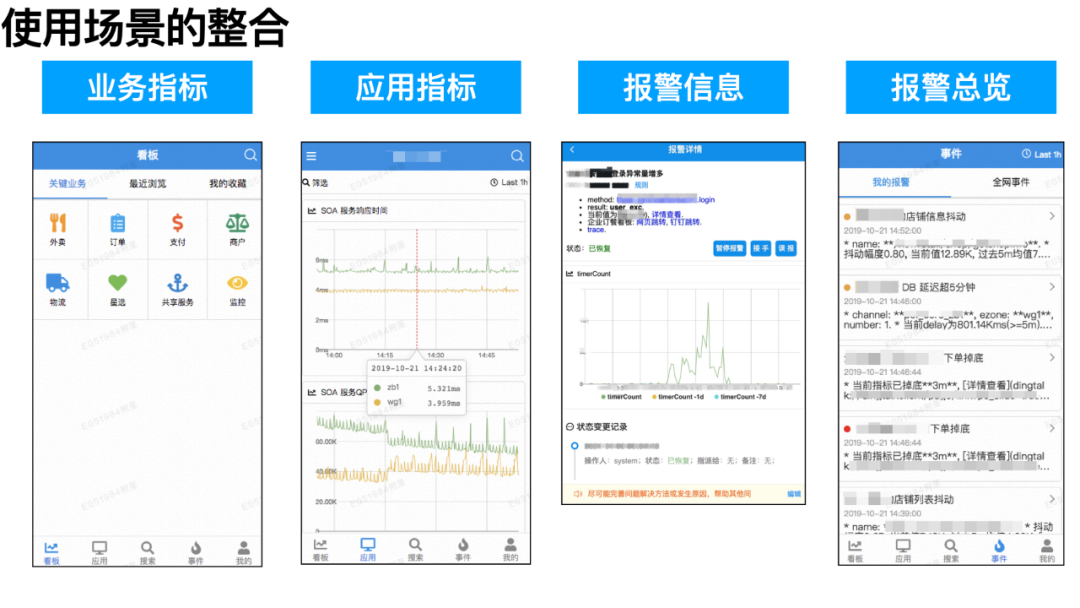
5、使用场景的整合:桌面版 + 移动版
除提供桌面版的 EMonitor 外,我们还开发了移动版的 EMonitor,它也提供了大部分可观测性系统的核心功能——业务指标、应用指标、报警信息等。移动版 EMonitor 能内嵌于钉钉之中,打通了用户认证机制,帮助用户随时随地掌握所有的可观测性信息。
6、为了极致的体验,精益求精
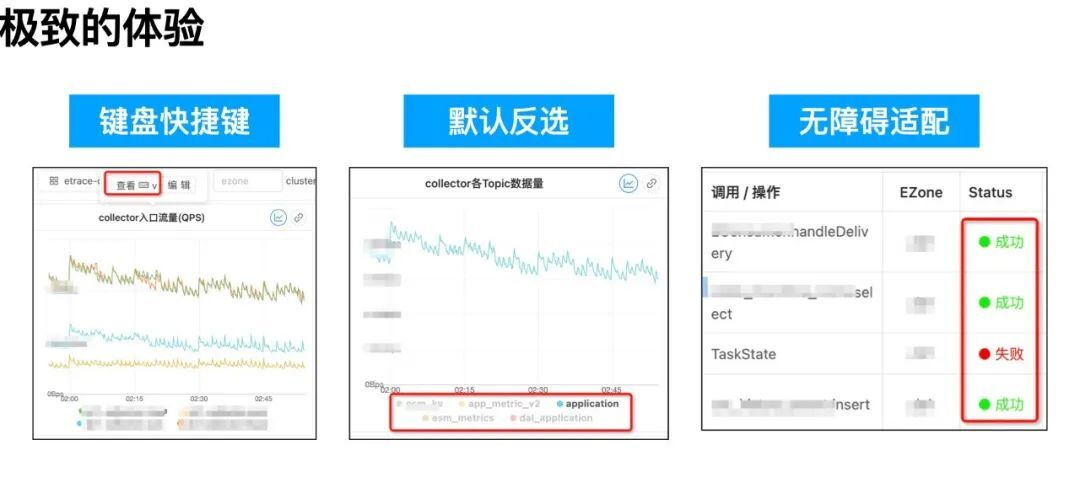
为了用户的极致使用体验,我们在 EMonitor 上各功能使用上细细打磨,这里仅举几个小例子:
我们为极客开发者实现了若干键盘快捷键。例如,“V”键就能展开查看指标大图。
图上多条曲线时,点击图例是默认单选,目的是让用户只看他关心的曲线。此外,若是“Ctrl+鼠标点击”则是将其加选择的曲线中。这个功能在一张图几十条曲线时,对比几个关键曲线时尤为有用。
为了让色弱开发者更容易区分成功或失败的状态,我们针对性的调整了对应颜色的对比度。
成为饿了么一站式可观测性平台
EMonitor 开发完成后,凭借优异的用户体验与产品集成度,很快在用户中普及开来。但是,EMonitor 要成为饿了么的一站式可观测性平台,还剩下最后一战——NOC 可观测性大屏。
NOC 可观测性大屏替换
饿了么有一套完善的应急处理与保障团队,包括 7*24 值班的 NOC(Network Operation Center)团队。在 NOC 的办公区域,有一整面墙上都是可观测性大屏,上面显示着饿了么的实时的各种业务曲线。下图为网上找的一张示例图,实际饿了么的 NOC 大屏比它更大、数据更多。

当时这个可观测大屏是将 Grafana 的指标看版投影上去。我们希望将 NOC 大屏也替换成 EMonitor 的看版。如前文所说,我们逐步将用户的 Statsd 指标数据转换成了 LinDB 指标,在 NOC 团队的协助下,一个一个将 Grafana 的可观测性指标“搬”到 EMonitor 上。此外,在原来白色主题的 EMonitor 之上,我们开发了黑色主题以适配投屏上墙的效果(白色背景投屏太刺眼)。
终于赶在 2018 年的双十一之前,EMonitor 正式入驻 NOC 可观测大屏。在双十一当天,众多研发挤在 NOC 室看着墙上的 EMonitor 看版上的业务曲线不断飞涨,作为可观测性团队的一员,这份自豪之情由衷而生。经此一役,EMonitor 真正成为了饿了么的“一站式可观测性平台”,Grafana、Statsd、InfluxDB 等都成了过去时。
报警 Watchdog 2.0
同样在 EMonitor 之前,亦有 Statsd 与 InfluxDB 对应的多套报警系统。用户若想要配置业务报警、链路报警、机器报警,需要辗转多个报警系统之间。各系统的报警的配置规则、触达体验亦是千差万别。Watchdog 报警系统也面临着统一融合的挑战。
在调研其他系统的报警规则实现后,Watchdog 中仍以 LinDB 的指标作为元数据实现。
针对其他报警系统的有显著区别的订阅模式,我们提出了"报警规则+一个规则多个订阅标签+一个用户订阅多个标签"的方式,完美迁移了几乎其他系统所有的报警规则与订阅关系。
其他各系统在报警触达与触达内容上也略有不同。我们统一整合成“邮件+短信+钉钉+语音外呼”四种通知方式,并且提供可参数化的自定义 Markdown 模板,让用户可自己定时报警信息。
经过一番艰苦的报警配置与逻辑整合后,我们为用户“自动”迁移了上千个报警规则,并最终为他们提供了一个统一的报警平台。

报警,更精准的报警
外卖行业的业务特性是业务的午高峰与晚高峰,在业务曲线上便是两个波峰的形状。这样的可观测数据,自然难以简单使用阈值或比率来做判断。即使是根据历史同环比、3-Sigma、移动平均等规则,也难以适应饿了么的可观测性场景。因为,饿了么的业务曲线并非一成不变,它受促销、天气因素、区域、压测等因素影响。开发出一个自适应业务曲线变化的报警算法,势在必行。
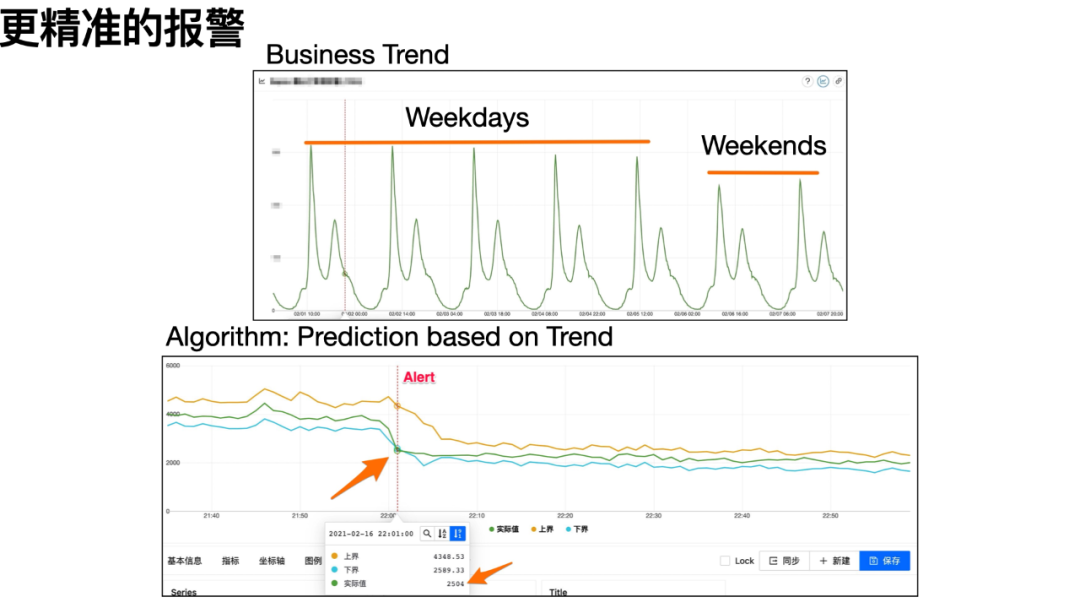
我们经过调研既有规则,与饿了么的业务场景,推出了全新的“趋势”报警。简要算法如下:
计算历史 10 天的指标数据中值作为基线。其中这 10 天都取工作日或非工作日。不取 10 天的均值而取中值是为了减少压测或机房流量切换造成的影响。
根据二阶滑动平均算法,得到滑动平均值与当前实际值的差值。
将基线与差值相加作为预测值。
根据预测值的数量级,计算出波动的幅度(如上界与下界的数值)。
若当前值不在预测值与波动幅度确定的上下界之中,则触发报警。
如上图所示,22 点 01 分的实际值因不在上下界所限定的区域之中,会触发报警。但从后续趋势来看,该下降趋势符合预期,因此实际中还会辅以“偏离持续 X 分钟”来修正误报。(如该例中,可增加“持续 3 分钟才报警”的规则,该点的数据便不会报警)算法中部分参数为经验值,而其中波动的阈值参数用户可按照自己业务调整。用户针对具备业务特征的曲线,再也不用费心的去调整参数,配置上默认的“趋势”规则就可以覆盖大多数的可观测性场景,目前“趋势”报警在饿了么广泛运用。
智能可观测性:根因分析,大显神威
作为 AIOPS 中重要的一环,根因分析能帮助用户快速定位故障,缩短故障响应时间,减少故障造成的损失。2020 年初,我们结合饿了么场景,攻坚克难,攻破“指标下钻”、“根因分析”两大难关,在 EMonitor 上成功落地。
根因分析最大的难点在于:包含复杂维度的指标数据难以找到真正影响数据波动的具体维度;孤立的指标数据也难以分析出应用上下游依赖引起的故障根因。例如,某个应用的异常指标突增,当前我们只能知道突增的异常名、机房维度的异常分布、机器维度的异常分布等,只有用户手工去点击异常指标看来链路之后,才能大致判断是哪个 SOA 方法/DB 请求中的异常。继而用户根据异常链路的环节,去追溯上游或下游的应用,重复类似的排查过程,最后以人工经验判断出故障点。
因此,在“指标下钻”上,我们针对目标指标的曲线,细分成最精细的每个维度数据(指标 group by 待分析的 tag 维度),使用 KMeans 聚类找出故障数据的各维度的最大公共特征,依次计算找到最优的公共特征,如此便能找到曲线波动对应的维度信息。
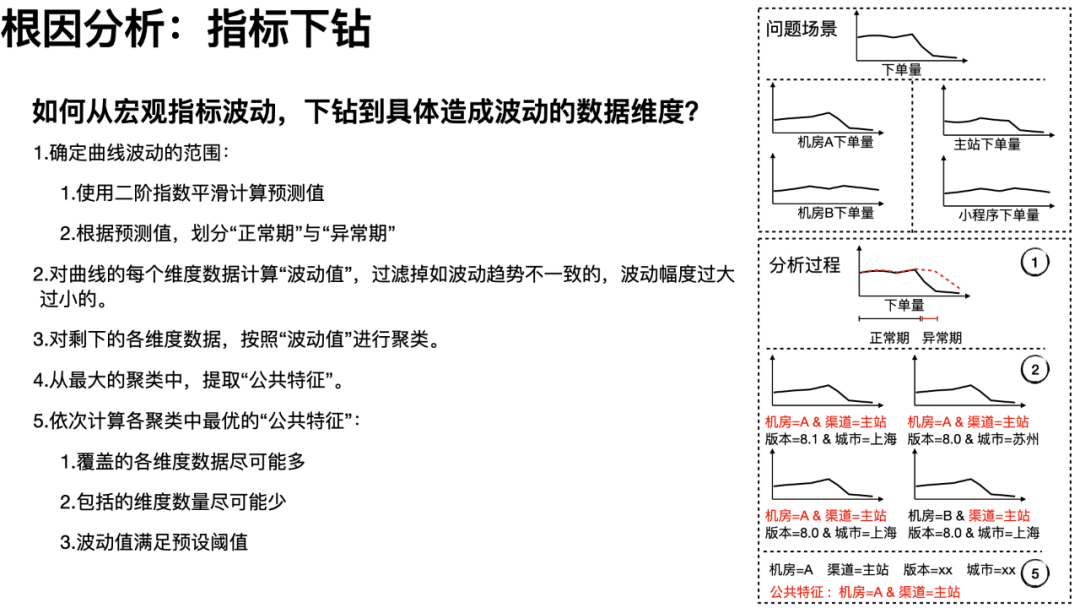
其次,在链路数据计算时,我们就能将额外的上下游附加信息附加到对应的指标之中。如,可在异常指标中追加一个维度来记录产生异常的 SOA 方法名。这样在根据异常指标分析时,能直接定位到是这个应用的那个 SOA 方法抛出的异常,接下来“自动”分析是 SOA 下游故障还是自身故障(DB、Cache、GC 等)。
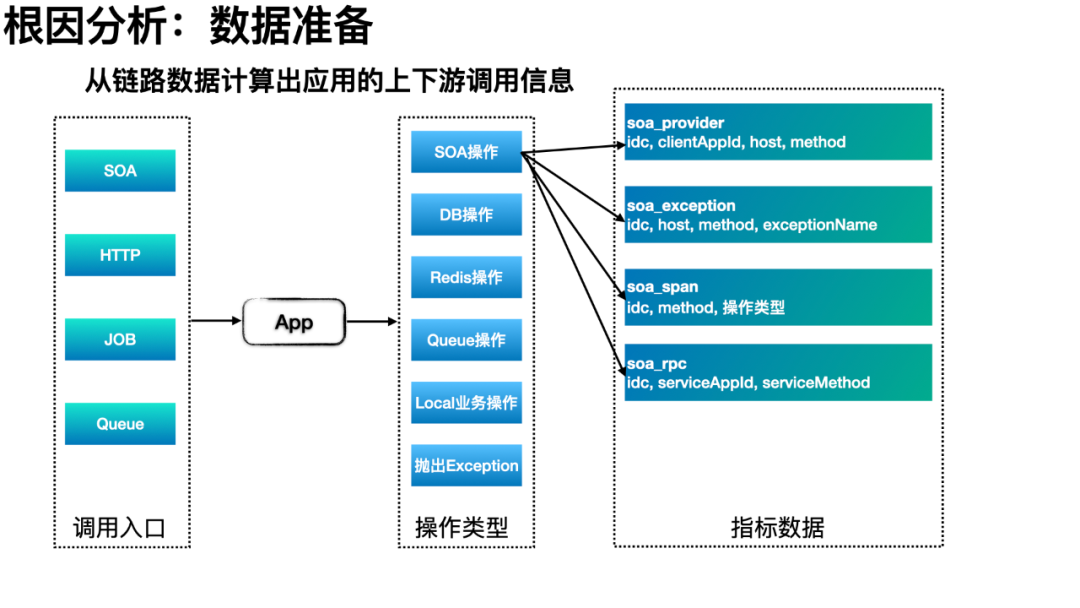
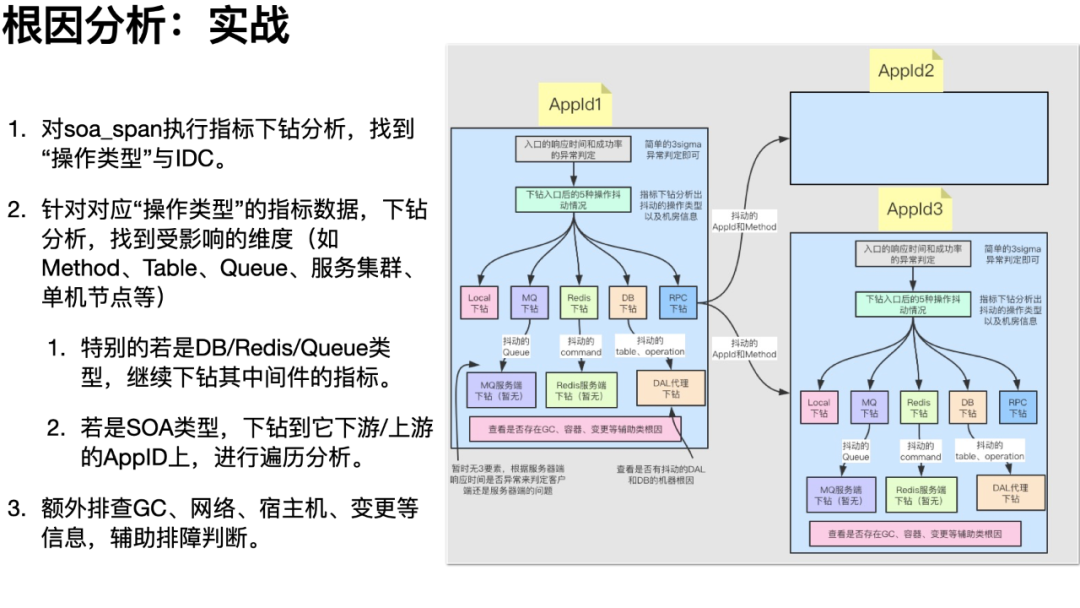
在 2020.3 月在饿了么落地以来,在分析的上百例故障中,根因分析的准确率达到 90% 以上,显著缩短了故障排查的时间,帮助各业务向稳定性建设目标向前跨进了一大步。
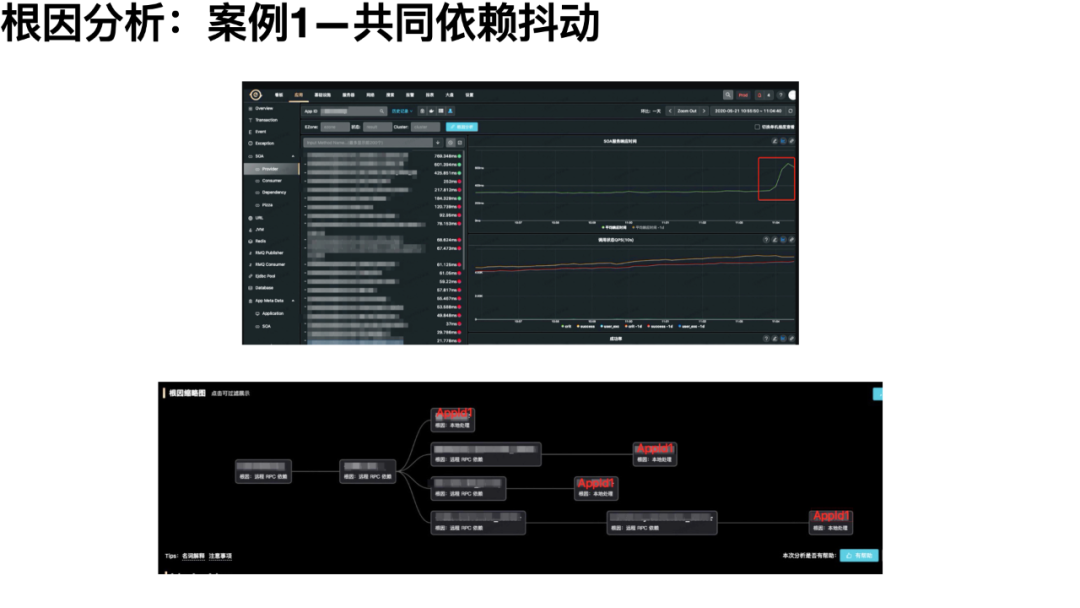
4.0:继往开来,乘势而上
经过 4、5 年的发展,风云变幻但团队初心不改,为了让用户用好可观测性系统,EMonitor 没有停下脚步,自我革新,希望让“天下没有难用的可观测性系统”。我们向集团的可观测性团队请教学习,结合本地生活自己的技术体系建设,力争百尺竿头更进一步,规划了以下的 EMonitor 4.0 的设计目标。
进行多租户化改造,保障核心数据的时延和可靠性
在本地生活的技术体系与阿里巴巴集团技术体系的不断深入的融合之中,单元化的部署环境以及对可观测性数据不同程度的可靠性要求,催生了“多租户化”的设计理念。我们可以根据应用类型、数据类型、来源等,将可观测性数据分流到不同的租户中,再针对性配置数据处理流程及分配处理能力,实现差异化的可靠性保障能力。
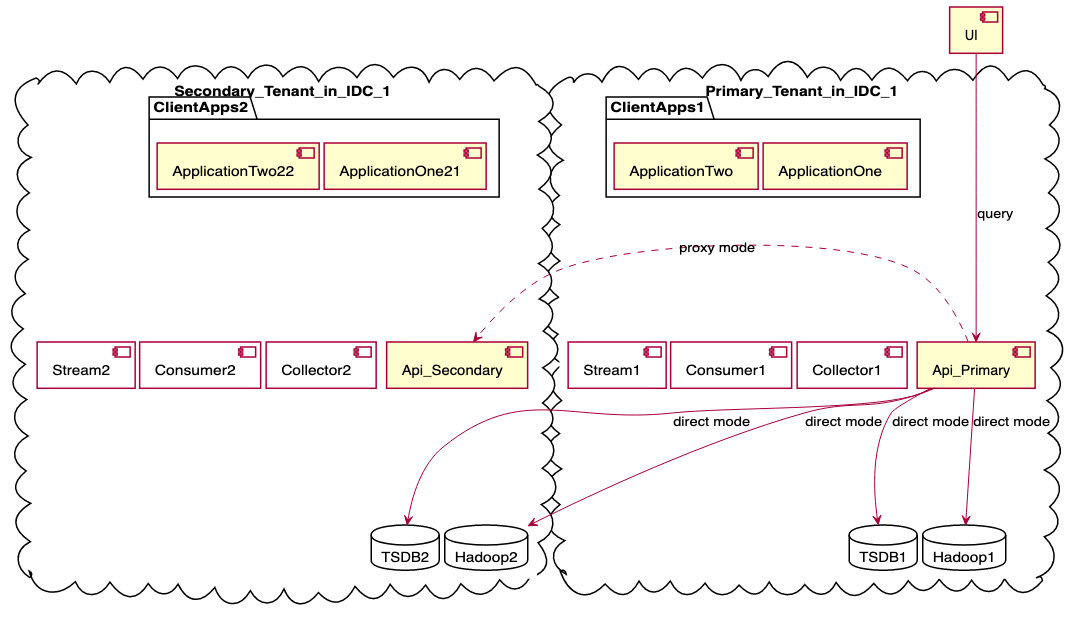
初步我们可以划分为两个集群——核心应用集群与非核心应用集合,根据在应用上标记的“应用等级”将其数据自动发送到对应集群中。两套集群在资源配置上优先侧重核心集群,并且完全物理隔离。此外通过配置开关可动态控制某个应用归属的租户,实现业务的柔性降级,避免当下偶尔因个别应用的不正确埋点方式会影响整体可观测可用性的问题。
未来可根据业务发展进一步发展出业务相关的租户,如到家业务集群、到店业务集群等。或者按照区域的划分,如弹内集群、弹外集群等。
打通集团弹内、弹外的可观测性数据,成为本地生活的一站式可观测性平台
目前本地生活很多业务领域已经迁入集团,在 Trace 链路可观测方面,虽然在本地生活上云的项目中,EMonitor 已经通过中间件改造实现鹰眼 TraceId 在链路上的传递,并记录了 EMonitor RequestId 与鹰眼 TraceId 的映射关系。但 EMonitor 与鹰眼在协议上的天然隔阂仍使得用户需要在两个平台间跳转查看同一条 Trace 链路。因此,我们接下来的目标是与鹰眼团队合作,将鹰眼的 Trace 数据集成到 EMonitor 上,让用户能一站式的排查问题。
其次,本地生活上云后,众多中间件已迁移到云上中间件,如云 Redis、云 Kafka、云 Zookeeper 等。对应的可观测性数据也需要额外登陆到阿里云控制台去查看。云上中间的可观测性数据大多已存储到 Prometheus 之中,因此我们计划在完成 Prometheus 协议兼容后,就与云上中间件团队合作,将本地生活的云上可观测性数据集成到 EMonitor 上。
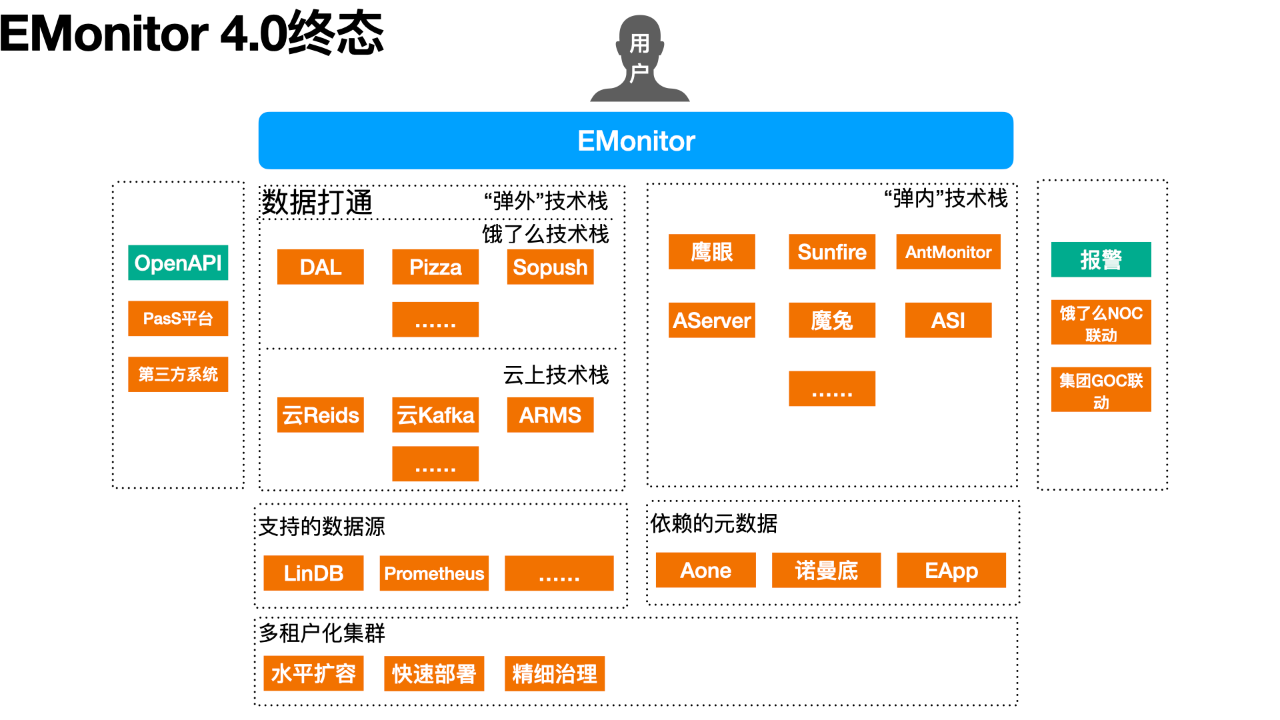
拥抱云原生,兼容 Prometheus、OpenTelemetry 等开源协议
云原生带来的技术革新势不可挡,本地生活的绝大多数应用已迁移到集团的容器化平台——ASI 上,对应带来的新的可观测环节也亟需补全。如,ASI 上 Prometheus 协议的容器可观测性数据、Envoy 等本地生活 PaaS 平台透出的可观测性数据与 Trace 数据等。
因此,我们计划在原先仅支持 LinDB 数据源的基础上,增加对 Prometheus 数据源的支持;扩展 OpenTelemetry 的 otel-collector exporter 实现,将 Open Telemetry 协议的 Trace 数据转换成 EMonitor 的 Trace 格式。如此便可补全云原生技术升级引起的可观测性数据缺失,并提供高度的适配性,满足本地生活的可观测性建设。
结语
纵观各大互联网公司的产品演进,技术产品的走向与命运都离不开公司业务的发展轨迹。我们饿了么的技术人是幸运的,能赶上这一波技术变革的大潮,能够发挥聪明才智,打磨出一些为用户津津乐道的技术产品。我们 EMonitor 可观测性团队也为能参与到这次技术变更中深感自豪,EMonitor 能被大家认可, 离不开每位参与到饿了么可观测性体系建设的同伴,也感谢各位对可观测性系统提供帮助、支持、建议的伙伴!
作者简介:
柯圣,花名“炸天”,饿了么监控技术组负责人。自 2016 年加入饿了么,长期深耕于可观测性领域,全程参与了 ETrace 到 EMonitor 的饿了么可观测性系统的发展历程。
本文转载自:阿里巴巴中间件(ID:Aliware_2018)
原文链接:饿了么 EMonitor 演进史

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论