
来自SGLang的研究人员与英伟达(NVIDIA)合作,公布了 GB200 (Grace Blackwell) NVL72 系统的早期基准测试结果。结果显示,在处理 DeepSeek-V3 671B 模型时,该系统的大语言模型(LLM)推理吞吐量相较于 H100 提升了高达 2.7 倍。
此次性能提升归功于专为 Blackwell 架构构建的一系列软件优化,其中包括针对 FP8 优化的矩阵乘法、加速的注意力内核以及通过NVLink实现的高速令牌(token)路由。这些增强功能已被集成到 SGLang 运行时中,以充分利用 GB200 密集的“多 GPU 互联架构”和统一内存模型。
英伟达的GB200 NVL72定位为适用于大规模人工智能的通用平台,涵盖了训练与推理两大领域。本次基准测试专攻推理,让外界得以在更大规模的训练和服务测试公开前,提前预览了系统在真实负载下的性能表现。
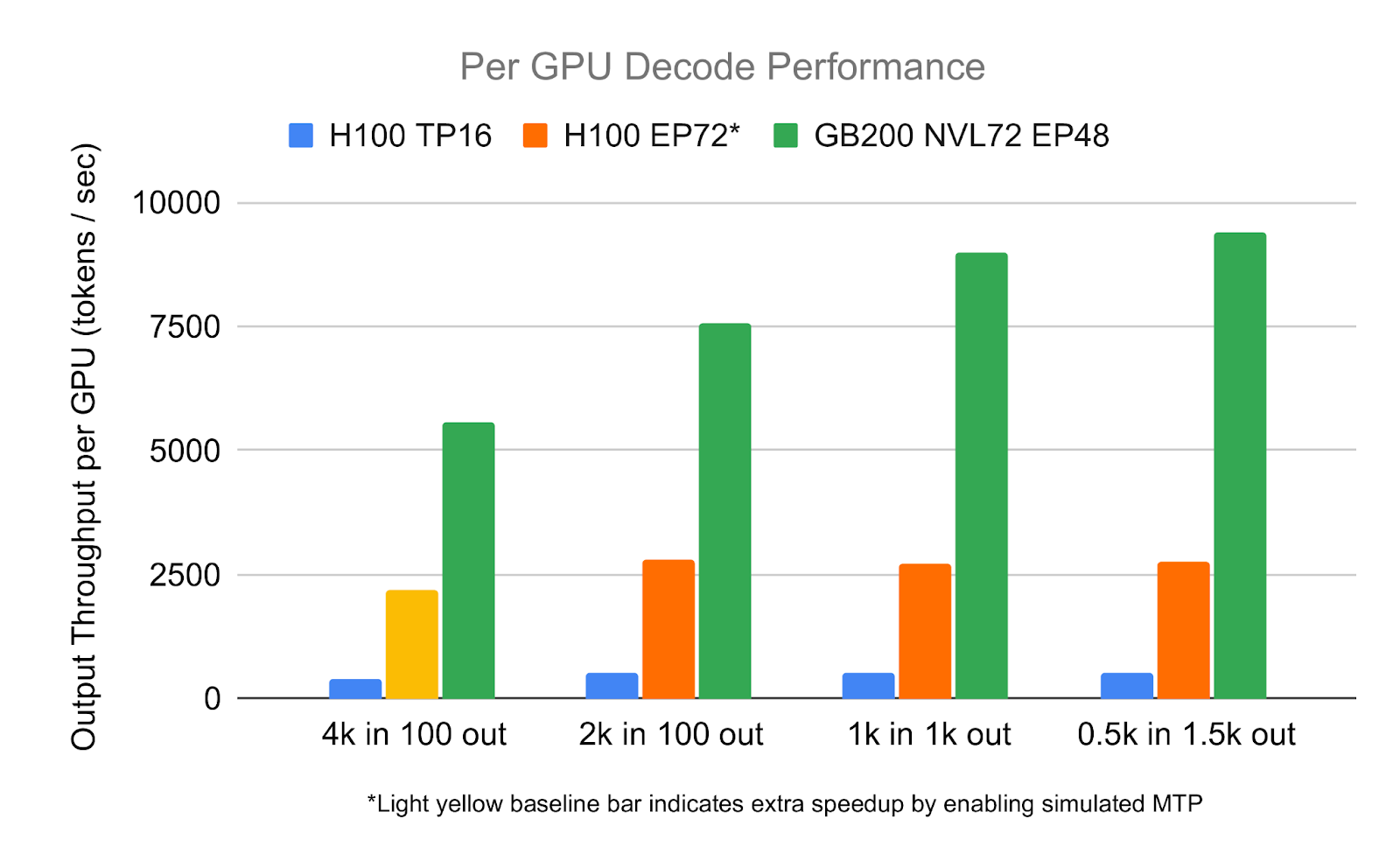
在使用 2000 个令牌作为 prompt 的解码基准测试中,SGLang 实现了每 GPU 每秒处理 7,583 个令牌的成绩,这比 H100 HGX 系统在相同工作负载下的表现提升了 2.7 倍。如此高的吞吐量能够为长上下文输入和高并发场景(例如技术文档摘要、具备代码库感知能力的人工智能助手,以及企业级检索增强生成 RAG)提供更快的响应速度。同时,它还减少了以交互方式服务大模型所需的 GPU 数量,从而在规模化部署时提升了延迟表现和成本效益。
该基准测试使用了由 DeepSeek 发布的DeepSeek-V3模型,这是一个拥有 6710 亿参数、仅包含解码器的大语言模型。该模型采用了 MoE 设计——每个令牌约激活 370 亿参数(约占总数的 9%),这意味着在推理过程中只使用了一小部分参数。
这种架构带来了现实的性能挑战:专家之间的令牌路由让GPU间的通信不堪重负,而庞大的模型尺寸和长提示也让 GPU 内存持续承压。
为实现此次性能飞跃,SGLang 团队在其运行时中集成了一系列 Blackwell 专属优化技术,例如:用于发挥新 UMMA 指令性能的高性能 FP8 矩阵乘法库 DeepGEMM;为 DeepSeek 模型预填充阶段优化的重写版融合注意力内核 FlashInfer FMHA;以及通过 NVLink 直接内存映射实现高效令牌分发的通信库 DeepEP。
该队还采用了两项技术:一是针对 Blackwell 内存层级结构优化的潜注意力内核 CUTLASS MLA,二是用于解耦式 KV Cache 传输的定制传输引擎 Mooncake。
总的来说,这些组件共同构成了一条软件路径,在 SGLang 的大规模多 GPU 推理实验中,最大限度地减少了计算、内存和通信的开销。
作者指出,尽管此次基准测试展示了解码吞吐量的显著提升,但仍有几个领域有待进一步优化。特别是预填充阶段尚未完全调整,并且许多内核尚未充分利用 GB200 的内存带宽或计算能力。此外,通信与计算也未完全重叠,这意味着未来仍有提升效率的空间。
后续工作将聚焦于优化预填充阶段,并进一步改善内存的延迟与利用率。




