

来自网易云容器编排技术负责人娄超、kubeup.com 创始人 Adieu、才云科技开源工程师岑鹏浩,各路大咖联袂献艺,为大家呈现了一场精彩纷呈的技术交流。

今天,为大家带来的是才云科技开源工程师岑鹏浩的演讲视频+ PPT ,请大家点击“阅读原文”获取。下面是其 《 Caicloud TaaS Introduction --TensorFlow on Kubernetes 》的演讲实录(全程文字速记由 IT 大咖说整理提供)

谢谢大家!我刚才刷微博说今天南京的降雨量已经达到 208 毫米,已经突破了历史最高值,上一次历史最高值好像是 2003 年。非常感谢大家今天能够冒雨过来,跟大家见证一个历史的时刻。
我今天的分享会比较轻松一点,大家中间有什么问题可以随时地打断提问。第一个会介绍一下深度学习是一个什么样的历史,还有它现在的一些现状,下面是一些 Caicloud 的简介,再下面是分布式 TensorFlow 是如何跑在 Kubernetes 上的。

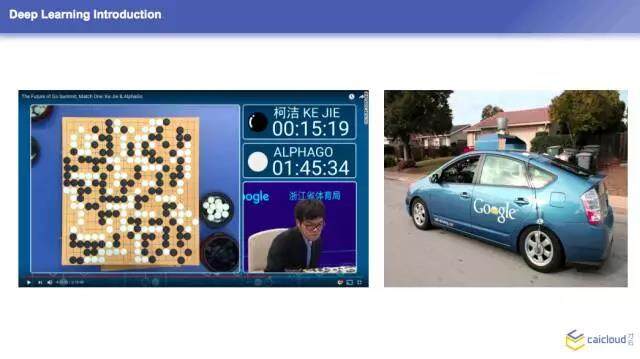
第一张图,大家有人知道是一个什么样的事情吗?OK ,就是前一段时间在浙江的乌镇搞了一个 AlphaGo 和柯洁的围棋比赛,柯洁是 0:3 失败,它就是用的深度学习的架构。右边是 Google 的一个项目,是自动驾驶的一个项目,大家应该很熟悉了,它其实也是基于深度学习来完成的一个项目。
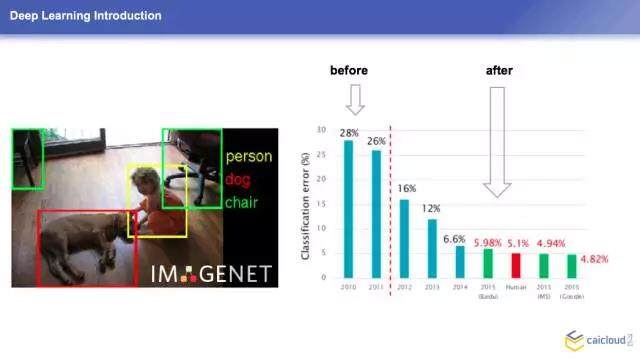
左边是一个图像识别出来的效果,大家可以看一下,你告诉它一张图片,它可以在这张图片里面自动标识出来图片里面有东西,不同的颜色是代表不同的东西,左边有两把椅子,有一只狗和一个小孩。这个背后也是用的深度学习的东西。
这个里面有很多庞大的一些图片的数据,你可以基于它的数据去训练你的模型,它也可以给出一些测试的数据,你可以根据它的测试数据来验证你的模型的准确率。右边一个就是图片识别历年的变化,每年会举办图片识别的比赛,包括学术界都会来验证他们深度学习的效果。大家可以看到 2010 年、2012 年之前,这个错误率是在 28%、26%的一个数值,当图像识别出来以后,错误率在大幅度下降。这边是有一个 5.1%,这个是人类自己识别的错误率。大家发现 2015 年之后机器的识别错误率明显低于人类。
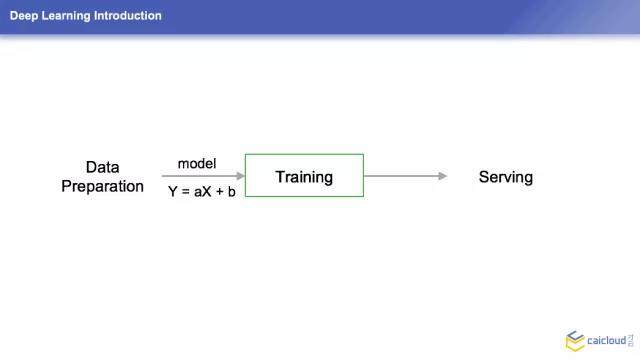
深度学习是怎么做的呢?其实简单地概括来讲,就是三个步骤。第一个步骤是数据的准备,大家可以理解为一些特征的提取,包括去分析你到底要解决什么问题。比如刚才那个例子,就是我怎么样让机器来识别一张图片里面有什么样的东西,这就是具体的实际问题。当你的数据准备好以后,你要准备你训练的数据以及你测试的数据。当你的数据准备好了之后,下面就是一些训练的工作,其实就是不断地优化你的模型,让它不断地接近你的预期,当你的预期比较满足了,你就可以把这个模型打包成一个产品,真正地提供一个服务。这个数据准备好,就是通过一个模型训练,训练好了之后打包,就是一个很简单的步骤。
模型大家可以简单地理解为一个数学公式,大家比较好理解。训练的过程,其实 X 就是一些输入,就是我一些训练的数据,我把 X 传给这样一个方程,A 和 B 是我要找到的两个值,大家可以认为是我训练的一个结果。就是我要找到一个非常满意的那个 A 和 B,让这个 Y 等于我的一个预期。这样的解释大家可以明白吗?就是一个比较简单的解释。
训练的过程就是不断地把这个 X 值去调整,不断地去评估 Y 的值,这样经过很多轮迭代之后,就可以把 Y 的值出来的结果和我们的预期相符。这样我们就认为一次训练就结束了。当然实际在工作中可能这会是一个不断优化的过程,真正的一个模型可能它的参数,就是 A 和 B 可能是成千上万的。我们今天讲的主要就是训练这一块的内容,前面的数据准备和后面的模型托管基本上没有涉及到。
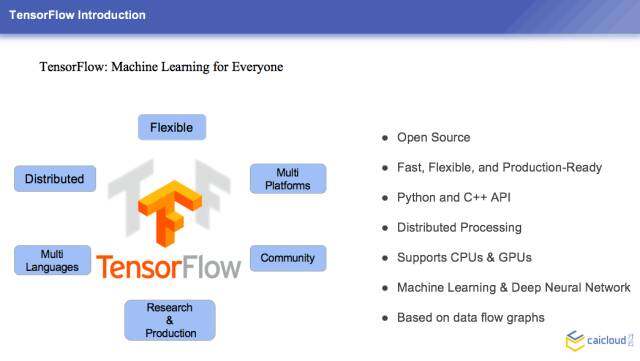
现在有了一个对 TensorFlow 深度学习的框架,它的支持语言很多,它支持分布式的东西。有人用怎么样用一句话来概括一下 TensorFlow 是什么特点?
TensorFlow 是深度学习里面提供了一个类似积木的框架,你可以通过这套积木来设计你想要的汽车也好,房子也好,可以简单地这样比喻一下。学术界可以用这套积木来搭建设计很精美的模型,来展示给大众来看一下。工业界也可以用这套积木来构建他们很稳定的一个产品,把他们的一些对外的服务提供出来。所以这边会有一个特点,就是它兼顾着学术界和工业界,这也是它能在很短的时间内迅速推广的一个比较重要的原因。这边列了一些它的好处,包括它内嵌了很多深度学习的算法和模型,大家入手会比较方便一点。
TensorFlow 可以跑在很多硬件的平台上面,包括 CPU、 GPU 和 TPU,大家听说过 TPU 没有?是 Google 专门用来跑 TensorFlow 的一个专门的服务器,AlphaGo 也是跑在这个上面的,所以说它的平台的一些可扩展性是非常好的。

举个例子,你在手机上面现在有那种翻译的软件,其实现在已经有人做出来了,就是把 TensorFlow 用在手机上面,可以帮助你算出来的一些结果。这个是列的一些常用的语言,C++ 是比较好的,JAVA 也有。

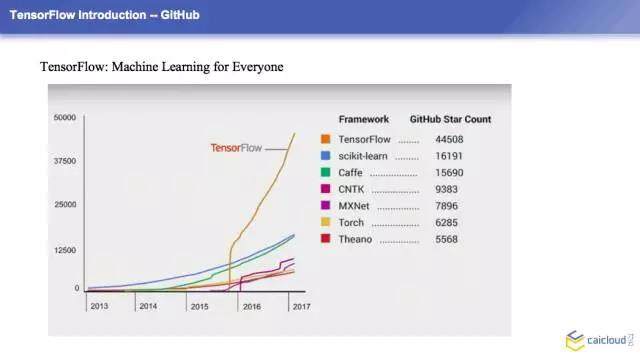
一个好的开源框架其实跟它的社区是密切相关的,这个是常用的一些深度学习的社区活跃度。TensorFlow 是在 2015 年 11 月份开源的,大家可以看到很明显的一个上升的曲线。Google 开源了这个之后,社区的活跃度提升是非常明显的,它已经远远超过了其他的一些开源的框架。
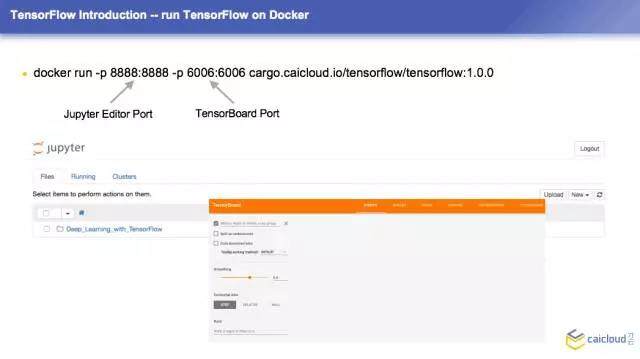
TensorFlow 的一些历史我们就讲到这里,现在我们简单地运行一个 TensorFlow 的程序,这边列出了一个 docker 的镜像,这个也很简单,把两边端口暴露出来,这个是我们才云自己构建的镜像。这个镜像跑会有两个效果,会启用一个在线的编辑器,可以在里面运行的代码。第二个是启用了一个可视化的工具,可以看出来你的模型长什么样子。
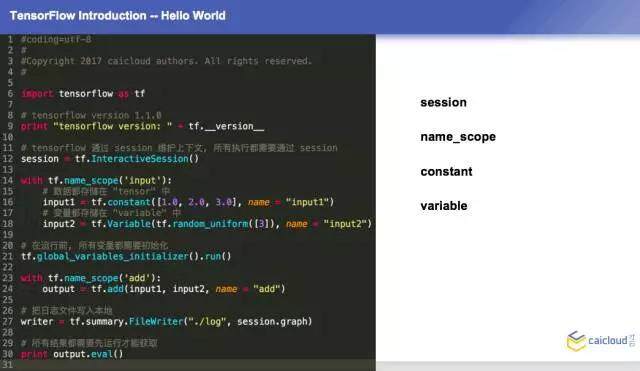
我们这边有一个 Hello World 的程序,就是一个简单的代码,最重要的就是 session,这个是很关键的一个东西。它怎么样说明变量呢?其实它会说明一些常量或者一些变量,都是有一些很常见的说明方法。这边我们定义了 input 1 和 input 2。这里有一个需要注意的地方就是要对这个变量进行初始化,初始化之后才能使用这个变量。第二个是我加入了一个算法,把我们刚才定义的 input 1 和 input 2 加起来,是一个很简单的例子。这边定义了一个 writer,最后一句就是真正开始运行起来了。
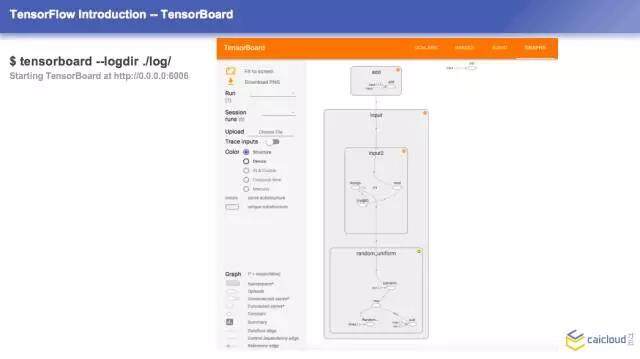
运行完了之后,刚才也讲到了 tensorboard,这个是默认的一个端口,启起来之后,右边是一个目录的效果,大家可以看到 inprt 2,这边有一个加法。你把每个图形展开之后就是是生成随机数的方法,里面都是它生成的细节。当这个模型很复杂的时候,这个东西是很有帮助的,可以很直观地来理解这些东西之间的关系,这样看起来会很方便。
刚才也说了 TensorFlow 它开源,它很快,它支持的框架很多等众多优点。但其实它也不是万能的,每一个新的东西出来它都是解决了部分的问题。
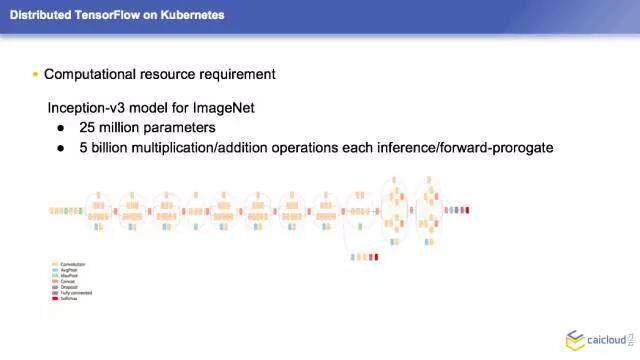
我们可以看到深度学习对于计算资源的需求是非常庞大的,现在有一个叫 Inception — v3 的模型,它这个模型大概长这个样子,就是深度神经网络的一个模型,它里面大概有 2500 万的参数需要去调整。当它执行这样一次训练过程,大概需要执行 50 亿次的加法或者是乘法的操作,当你真正地遇到实际问题的时候,你的模型就会非常的庞大,它带来的实际计算的需求也会非常惊人。
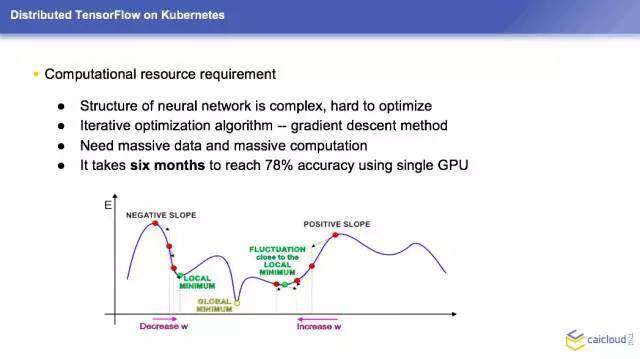
还有就是它的神经网络的模型是非常复杂的,它很难去优化,这边举出一个例子,我们把刚才 Inception — v3 的模型,在单个 GPU 上训练达到 78% 的正确率,大概需要半年时间。这个在我们真正的工作当中是不能容忍的,半年的时间才知道我这个模型跑出什么结果,公司可能都已经不存在了。
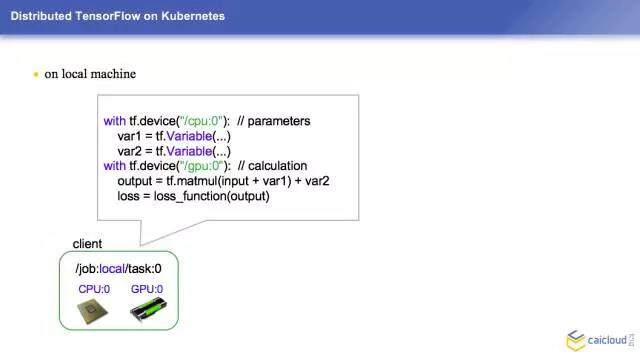
我们这边其实利用了 TensorFlow 和 Kubernetes 结合来解决了真正遇到的问题,我们接下来会给大家简单地介绍一下怎样把一个分布式的 TensorFlow 跑起来。我们先讲一下在单机上面怎么跑,我们这边有一个机器,它的名字叫 job:local,它其实是一个 task:0,它里面 CPU 和 GPU 各有一块。我们首先在 CPU 上保存变量,然后在 GPU 上面进行计算,这样会更快地得到我们的结果。
output 简单地进行一个乘法,把这个和变量 1 做一个乘法,和变量 2 进行一个加法。我们同时要计算一下我们的损失函数,大家可以理解我用损失函数来评估我计算出来的结果和我预期之间的差,当这个差越小的时候说明它越接近我的预期。
这边要给大家引入一个叫 Worker 和 PS 的概念,Worker 可以理解为真正干活的人,真正做计算的工作。PS 是一个参数服务器,它用来保存我们整个模型当中的变量,它其实是不干活的,只是放变量的一个地方,Worker 会去拉这个模型,更新一些计算,把这个更新后的变量放到 PS 上面。这个怎么实现呢?这边有一个 device,这个是固定的东西,我告诉它我是在 PS 上面跑的。在 worker 后面也是同样的,只是真正的 CPU 变成了 GPU。刚才两个机器也是不变的,改变就是在这个地方变了一下。这样的话,就把不同的事情分配到了不同的机器上来做。
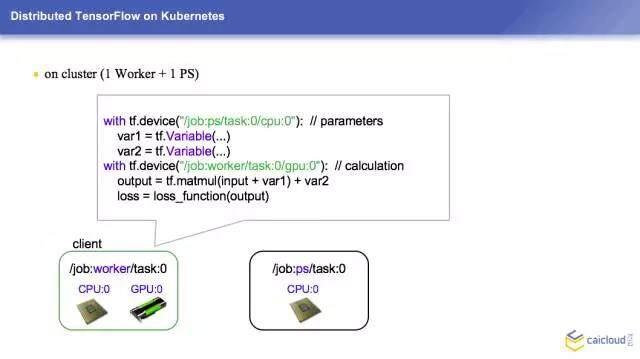
这边其实 TensorFlow 底层是用 gRPC 来执行工作的,这个给大家提一句。这个地方有问题吗?就是怎么样把不同的东西放到不同的设备上来跑。
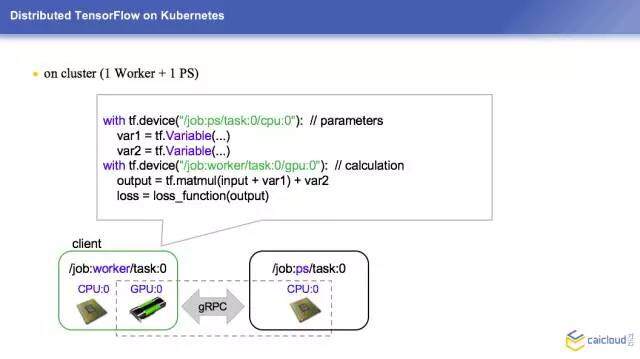
这边做一个简单的总结,PS 就是放一些变量,来更新一些参数。Worker 做的事情就很多了,包括一些数据的预处理等等,这都是需要用到的计算的事情,这样的计算就是让它的数据更接近我们的预期。现在我们有了两个 Worker,大家看一下这边的代码,对于 PS 来说其实跟刚才的场景是一模一样的,没有什么变化,把我的参数都放到这个上面去。这个时候我定义了一些 inputs,大家可以理解为一些训练的数据集,我要传递给这个模型,让它基于这些训练的数据集来定义我想要的结果。
outputs 我们定义了一个数组来保存,这边有一个 for 很简单,这个 for i in 其实就是在两台不同的机器上来分做不同的事情。这边的 device 跟刚才一样,只不过这边是叫 task:0,这边叫 task:1,这边把完整的语句拼出来了。我会把所有计算出来的结果存储到这个里面,损失函数的计算还是一样的,它是基于一个输出的计算。
PS 和每个 Worker 之间是单独通讯的,两个 Worker 之间是不通讯的,只有 PS 和 Worker 之间是通讯的。
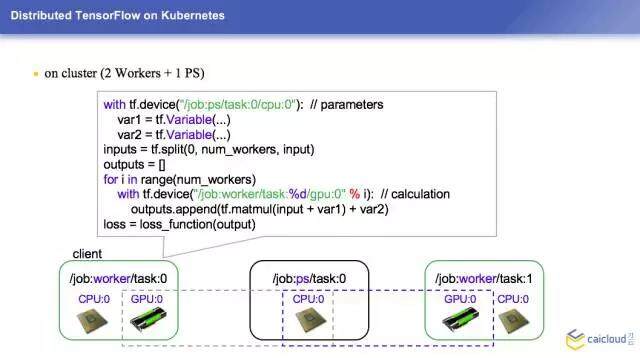
现在我们深入地看一下分布式的 TensorFlow 是怎么跑起来的,刚才在那个里面跟大家说了一下,tf 里面 Session 是一个比较重要的概念,这边是做一些初始化的工作,按照我设定好的一个训练步骤,就是这样一个变量执行一个具体训练的操作,其实代码都是伪代码。这个过程就是怎样在单机上面跑一个训练的过程。
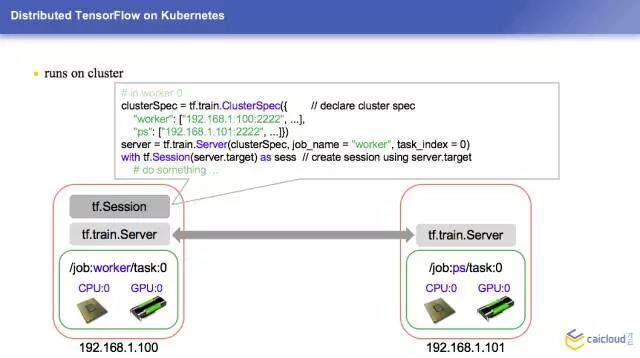
现在我们有两台机器,是在一个集群里面,在这个上面还是要有一个 Session 的,它是一个很基本的东西。它们是怎么互相发现的呢?在两台机器里面会取一个 Server,这边一个,这边一个,它们两个是通过这个 Server 进行通讯的。我们假设左边是 1.100,这边是 1.101 机器,这边的机器我们是用来干活的,右边这台机器是用来存参数和模型的。首先我们要定义一个 clusterSpec,我定义了一个 ClusterSpec 之后,我要把这个传进来,要告诉我这个机器到底是第几台 Worker 或者是第几台 PS。在这个 PS 上面,其实是不需要申明这个 Session 的,它只要调用这个方法,等在那儿就可以了,等着这个 Worker 来跟它通讯,就 OK 了。
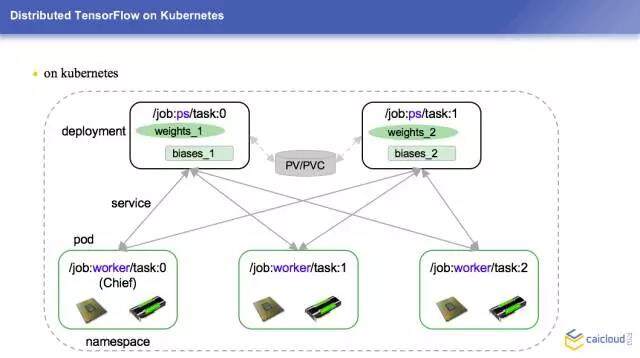
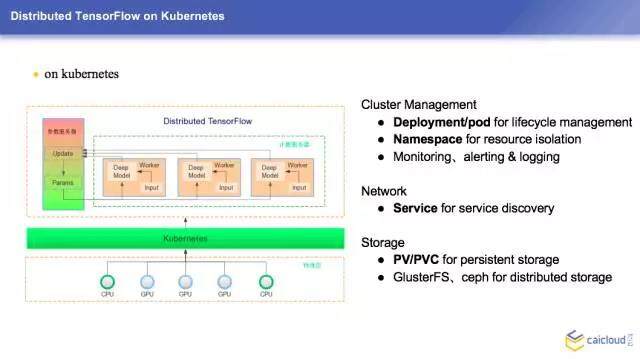
现在我们讲一下怎么把它跑在 Kubernetes 上面,如果大家有什么问题不清楚的也可以问一下,我可以简单地给大家介绍一下。这边我们有两个 PS,大家可以认为是两台参数服务器,下面是三个干活的人,它们上面分别保存了不同的参数,现在就是要不停地调整参数。每个 Worker 和 PS 之间是有线联系的,是可以互相通讯的,但是 Worker 和 Worker 之间是不联系的,Worker 我们是跑在 Pod 里面的。这些参数服务器之间是要有一个共享存储的,我们这边是用的一个分布式的存储,它其实也是用到 Kubernetes 和 PV 和 PVC 进行一个存储化的工作。
这边简单地总结一下,我们用到 Kubernetes 的一些 Deployment 和 Pod 进行一些生命周期的管理,网络方面用 Service 做服务发现,存储是用 PV 和 PVC 做一些存储持久化,最下面是用一些分布式的存储来搭建这样一个基础服务。
这边可以看到物理层其实有很多的计算资源,CPU、GPU,中间用 Kubernetes 把整个的物理机给管理起来,在 Kubernetes 的上面跑的是 TensorFlow,有计算,中间有通讯的过程。
下面介绍一下我们的 Taas 是怎么工作的,Taas 是搭载在微软的公有云上面,在它的上面我们会搭建一个集群,在它的上面我们把 TensorFlow 跑起来。

https://taas.caicloud.io 这个网址大家可以记一下,我们现在这个平台是在内测的阶段,大家可以关注我们的微信公众号,大家可以申请自己的帐号,可以自己来玩一下。
这个公有云已经是在内部测试的阶段,我们会邀请我们大学里的合作伙伴,或者工业界的一些合作伙伴,给他们一些类似的帐号来用,大家如果感兴趣可以自己去申请,在 6 月底大概会开放出来这样一个平台。
本文转载自才云 Caicloud 公众号。
原文链接:https://mp.weixin.qq.com/s/H3hHOQjGKM2nCdQKTQwZwQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论