

本文翻译自:“ THE UBER ENGINEERING TECH STACK, PART II: THE EDGE AND BEYOND ”,作者LUCIE LOZINSKI,已获得原网站授权。
Uber 技术
Uber 的使命是要让交通可靠得像人人随处可用的自来水一样。在上一篇中,我们讨论了 Uber 技术栈的底层部分。在这一篇中我们要讨论一下与乘客和司机相关的部分。让我们从全球市场开始,通过网页和手机讨论开来。

中间层:Marketplace
Marketplace 是 Uber 引擎的最前端,负责把真实世界的实时请求和位置数据等送入 Uber 系统。数据持久存储层、匹配系统和实时交易处理等都在这里。这里也有很多关于 UberRUSH 和 UberEATS 等产品的逻辑。在 Uber 系统中,Marketplace 的可用性要求是最高的。
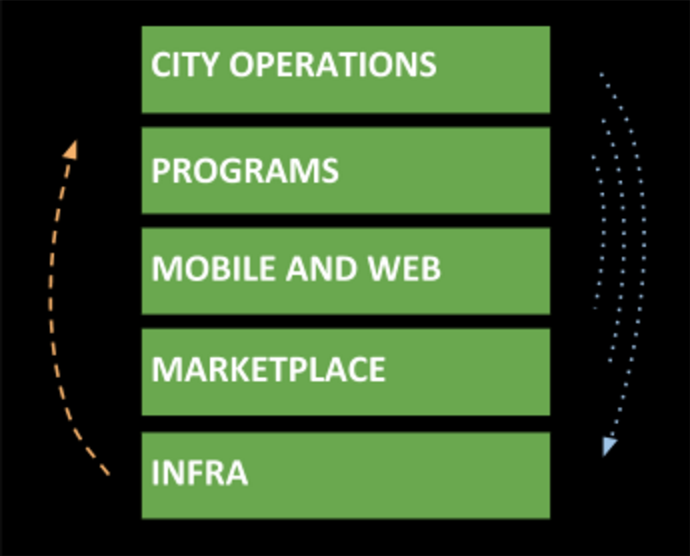
要理解 Marketplace,非常重要的一点是要记住 Uber 技术栈中的各个部分是会相互作用的。最底层的基础设施支撑着它上面的所有东西,但上层的功能也会调用下层。就 Marketplace 而言它自身是独立的,但它上层和下层的东西都会调用到它。
与 Uber 其他团队一样,Marketplace 自身也有着一套技术栈。在它内部,工程师们只为 Marketplace 自己构建基础设施和数据方案,包括数据组、集成组、前端工程师、后端工程师、还有用我们的四种编程语言(Python、Node.js、Go、Java)写成的各种服务。这种分层架构保证了 Uber 系统的高可用和对故障免疫。
Uber 的核心 Trip 处理引擎最早是用Node.js 写的,主要看中的是它的异步原语和简单的单线程处理。事实上我们也是敢把Node.js 用到生产环境的仅有的两个公司之一。Node.js 让我们可以管理大量的并发连接。但现在我们大多数服务都是用Go 写的了,而且越来越多。我们看中的是Go 的并发、效率和类型安全操作。
边界
我们手机App 的前端API 包含着超过600 个无状态节点,它们把许多服务组合起来了,把手机用户输入的请求路由到别的API 或服务上。所有东西全都是用Node.js 写的,只有边界部分除外, NGINX 前端在这里会终止 SSL 并做一些鉴权。NGINX 前端也会借助于 HAProxy 负载均衡器做前端 API 的代理。
Marketplace 的这一部分集成了许多内部基础设施原语。这个团队的工程师用开源软件 logtron 来向磁盘和 Kafka 写日志。我们用 uber-statsd-client 模块( stasd 的 Node.js 客户端)生成统计信息,再与我们自己研发的 M3 交互(前文讲过)。
高可用、自愈和持久化
为了支持最大程度的可用性需求,Marketplace 技术栈必须实时地接收和处理请求。即使这个模块发生非常短暂的停服,也会对我们的用户和业务产生非常严重的影响。Marketplace 的很多技术都是团队里的工程师研发出来先给自己用的。
Ringpop 是一套构建协作式分布式系统的库,它在 Marketplace 被推广到 Uber 其他团队乃至更外部之前解决了一些问题。对于开发者来说它在应用程序一级提供了与 DynamoDB 或 Riak 等分布式数据库类似的高可用、分区容忍等特性。
实时处理乘客和司机的状态数据并把它们作匹配的逻辑是用 Node.js 和 Go 语言写的。这些团队用 Ringpop 和 Sevnup 来实现功能,并在哈希环中有节点发生故障、或者有别的节点成为主键空间的主节点时做对象角色切换。
速度与吞吐量
为全公司的团队构建跨功能工具的工程师们是在 Uber 里用 Cassandra 和 Go 用得最多的,最主要的原因就是速度。Cassandra 做横向扩展非常容易,而 Go 语言的编译超级快。
吞吐量对 Marketplace 团队来说也是非常重要的。它们必须能处理最大量的业务请求,因为所有请求都会经过 Marketplace。即使是在业务量最高峰的时候,Marketplace 也必须能够抗住所有压力,否则请求都压根到不了 Uber 的其它模块。
优化与均衡
Marketplace 用动态调价、智能匹配、健康状态检查等手段来控制优化和均衡。这一块主要用的是 Python 写的 Flask 和 uWSGI 等,但我们为了追求更高的性能而在用 Go 替换 Python。网络调用和 I/O 产生的阻塞都很诡异地拖慢了我们的服务,要能处理相同量级的请求就只好部署更多的服务。在访问后端的 MySQL 数据库时 Python 很好用,但我们已经在用 Riak 和 Cassandra 集群替换 MySQL 的主从架构。
看到并使用数据
Marketplace 内部有个小团队是负责把 Marketplace 的数据可视化的,方便团队理解和观察全世界的状态。我们用 JavaScript 实现前端应用程序。后端用到的库和框架包括 React+Flux、 D3 和 Mapbox 等。就后端而言,使用的 Node.js 服务器也和 Uber 的 Web 工程师们用的是同一台。
Marketplace 内部的数据工程师们综合使用了各种数据库、自行研发的解决方案和外部开源技术,来实现数据处理、流处理、查询、机器学习和图处理等功能。
(点击放大图像)

数据流用的是Kafka 和Uber 的生产数据库。Hive、MapReduce、HDFS、Elasticsearch 和文件存储Web 服务等都被用来做特定用途的数据存储,以及处理相应的操作请求。与大家用惯了的LIDAR 不同,我们开发了它的一个变种。我们现在只在内部分享交互式数据分析记录的全量数据,运行的是 JupyterHub ,支撑多用户的 Jupyter (IPython)Notebook,并把它与 Apache Spark 和我们的数据平台做了集成。Marketplace 的数据团队是与 Uber 的数据技术团队不同的,但用的技术大部分还是重叠的。
在 Marketplace 之上,网页和手机端用的东西是完全不同的了。
上层:网页与手机
我们的网页端和手机端的工程师共用着许多相同的底层模块,但也还是有很多是上层独有的。这些部门的工程师们构建出来的就是你常用的 App 了,也会构建出给所有网页和手机工程师们共用的库和框架。这个团队最看重的是用户体验和易用性。
网页
网页团队和产品团队一起协作,构建和推广模块化的、分别部署的网页 App。所有的 App 都有相同的用户操作接口和用户体验。
语言
网页的核心功能都是用 Node.js 写的。Node.js 的社区非常大非常活跃,聚集了许多网页开发者。Node.js 让我们可以在客户端和服务器之间共享 JavaScript 代码,以打造通用、同构的网页应用程序。我们客户端的程序需要 Nodejs 风格的模块,因此我们用 Browserify 来打包。
网页服务器
我们的基础网页服务器 Bedrock 构建在应用非常广泛的网页框架 Express.js 基础之上。 Express.js 自带了许多中间件,可以提供安全、国际化和其他 Uber 特有的模块,来集成基础设施。
我们自建的服务通信层 Atreyu 会处理后端服务之间的通信,并且与 Bedrock 集成。Atreyu 让我们可以很容易地向 SOA 服务 API 发送请求,和 Falcor 或 Relay 非常相似。
(点击放大图像)

如上图所示,司机的主页就是在坚实的Bedrock 基础之上构建出来的许多Uber 页面之一。
渲染、状态处理和构建
我们用React.js 和标准Flux 来做应用程序的渲染和状态处理,有些团队已经开始尝试用Redux 来做未来的状态容器。我们也在把名为Superfine 的现有 OOCSS/BEM 风格的 CSS 工具集演进成一套由 CSS 封装的 React.js UI 模块,是用样式对象构建的,和 Radium 类似。
我们的构建系统叫 Core Tasks,是一套基于 Gulp.js 构建的脚本集合,用于编译前端程序并且管理版本,再推送到网页服务的文件存储上,让我们可以利用 CDN 服务。
最后,我们用内部的 NPM 注册表来管理超大量的公共注册包和只向内部广播的包。每个工程师都可以向它发布,这就让我们可以轻松地在团队间共享模块和 React.js 组件。
手机
Uber 曾经有过非常专门的手机部门。现在公司的部门都是跨职能的,我们叫应用程序团队。每个跨职能团队的成员都有不同背景,从后端到设计到数据科学都有。
开发语言
Uber 的 iOS 程序员是用 Objective C 和 Swift 开发的,Android 程序员用 Java。也有一些开发 React 组件。Swift 有很多静态分析和编译时安全检查,所以要把代码写的有错也不容易。我们比较喜欢面向协议编程。在手机方面我们的演进方向是基于模块化的库的系统。
库
在不同的顶层技术方面,我们会用第三方的库,或者为了自己的特定需求而专门构建。许多现有可用的开源库都是通用的,这样会造成 App 安装包非常庞大。对手机程序来说,每一 K 字节都很重要。
Android
Android 方面用 Gradle 作构建系统。我们用了 OkHttp 、 Retrofit 和 Gson 。 Dagger 是依赖注入框架。
我们用开源库来使 UI 代码简洁易用。 Butter Knife 让我们可以通过处理注解把视图和回调绑定到字段和方法上。 Picasso 提供了图像加载功能。
Espresso 扩展让我们可以在 IDE(我们用 Android Studio)中用熟悉的 Android SDK 写出许多自动化代码。为了适应架构,我们用 RxJava 来简化对异步和基于事件的编程。日志功能我们用 Timber 。
iOS
所有 iOS 代码都保存在我们用 Buck 构建的一台集中存储上。 Masonry 和有自动布局功能的 SnapKit 用于做组件摆放和大小适配。崩溃检测用的是 KSCrash ,但上报崩溃报告用的是我们自己的报告框架。我们用 OCMock 模仿和构造测试类来测试 Objective-C 代码。我们也用协议生成了虚拟类来测试 Swift。
存储
我们用 LevelDB 做存储。后台是标准的 Schemaless 和 MySQL,我们正在逐步向全部使用 Schemaless 迁移。
开发
我们主要有四个 App:Android 乘客端、Android 司机端、iOS 乘客端和 iOS 司机端。这意味着每个星期我们每个平台上都要有上百位工程师向代码库中提交代码,并且发布。万一发生了什么问题我们也没办法快速恢复。所以,我们要构建一些系统来让这种开发模式更可靠。
手机程序开发是百分之百确定地,大家都在主分支上进行开发,然后大家各自提交。我们也还在用Git 做软件版本管理,但写App 代码的工程师都是直接向主分支进行提交的。这么多人在主分支上提交代码风险是非常大的。所以我们用了自己开发的服务和程序配置平台,非常易用,也非常容易基于它进行构建,这样相关团队就可以限制自己的代码改动对Uber 其他服务和业务的影响。平台使用功能标记位来在服务器端打开或关闭代码功能。我们会做灰度发布,并且仔细跟进发布的情况。
工程师们不必考虑构建窗口的问题,它们都是按照功能标记增量进行的。我们没有手工的QA 流程,相反我们对自动化和监控做了很多投入。我们的持续集成让我们可以快速扩张,而监控让我们的快速响应系统可以捕获并改正任何有问题的代码。
栈外之栈
难以描述好Uber 的技术栈,一部分原因是这里没有非常确定性的规则。当大家想到技术栈这个词时,脑海中往往会浮现出一根图腾柱,最下面是基础设施,最上面是用户可用的各具特色的功能。有非常清晰的层次和边界。
而Uber,则差不多每一层都有自己的一套技术栈。比如手机功能团队就前端工程师和后端工程师都是在一起工作的,而且只要能满足自己项目的需要,爱用什么数据存储方案都可以自己决定。而对于某些团队来说,比如财务相关的钱,相应的技术栈都是以保证自己需求为最高目的的。
总之,我们的工作有趣之处不在于我们用什么技术栈,而在于我们做实时真实交易时要进行的大规模高速处理。支撑Uber 的技术一定会变,但我们的速度、可塑性、紧迫感和克服困难的动力会一直都在。听起来有意思吗?加入我们吧!
一张由在旧金山随机选取的一百万条匿名行程汇总而成的街道图。较亮的是市中心。
也请阅读: The Uber Engineering Tech Stack, Part I: The Foundation
感谢 Conor Myhrvold, Botswana 的图片:“Chapman’s Baobab”。
Baobab(猴面包树)以它们的生命力强、长寿、粗厚的树干和树枝而闻名。喀拉哈里沙漠中的这棵猴面包树也是非洲最古老的树之一。

暂无签名

中国卓越技术团队访谈录(2022 年第二季)
本迷你书精选了微软 Edge、蚂蚁可信原生、明源云、文因互联、Babylon.js 等技术团队在技术落地、团队建...










评论