
RDMA,其全称为 Remote Direct Memory Access(远程内存直接访问),是新一代数据中心高速网络互联的基础协议之一。RDMA 协议来自于高性能计算领域,它改进了传统的 TCP/IP 协议栈在高速网络下的诸多缺点,使得网络通信数据传输不再经过内核或 CPU,取而代之的则是直接通过网卡读写内存来进行,从而在应用上能够充分利用万兆以上的网络带宽。
随着模型复杂度和数据规模的快速增长,深度学习系统需要越来越多的 GPU(多机多卡)进行并行训练。时至今日,GPU 往往使用高吞吐量、低延迟的 RDMA 网络传输技术,而大规模、高拓展性的深度学习系统,则需要基于以太网的 RDMA (RDMA over Converged Ethernet) 技术,即 RoCE。
通常,在大规模数据中心使用 RDMA 有两种技术选择,Infiniband 或 RoCE。两者相比,RoCE 更适用于目前的数据中心网络架构,因现有的互联网数据中心本身就是使用以太网建设的,所以在运营难度、人力安排及成本控制等方面,RoCE 具有明显优势。RoCE 被认为是可以支持大规模网络 RDMA 的技术,因此也同样适用于 Amber。
与业界相流行的 TensorFlow、MXNET 相同,Amber 也是一种深度学习计算框架,它是由微信-香港科技大学人工智能联合实验室 (WHAT Lab) 所研发,支持大规模分布式并行深度学习计算。其数据传输模块中的 RDMA 功能,由香港科技大学陈凯教授开发的 RoCE 提供技术支持,使得 Amber 能够充分使用硬件 RDMA 性能,实现低延迟、高吞吐量的模型传输。
在现有的多机学习任务中,性能瓶颈主要表现在计算和网络上,而对于网络密集型的任务,网络传输则往往成为整个系统的瓶颈点,因此追求更高效的网络传输方式,便成为当前机器学习多机任务的一个主要关注点。分布式计算需要将数据或者模型在参与计算的机器之间传输,所以 Amber 希望能够使用低延迟、高带宽、高效率的 RDMA 作为网络传输协议。另需指出,Amber 将会部署在腾讯现有的 IDC 数据中心之中。
以下对测试方法和对应结果做一个简单介绍。
为了对使用 RoCE 技术的 Amber(Amber/RoCE)和使用 TCP 的 Amber(Amber/TCP)进行一系列性能对比,我们主要就三个重要的深度学习应用进行了测试,它们分别是朋友圈分类(ego_network)、对话模型(deep_conversation)、图像识别模型(VGG 和 AlexNet)。

整体性能
测试目标是 Amber 作为分布式计算框架的处理能力,使用的度量标准是每秒钟处理数据样本的个数(Samples per second)。每秒钟处理的数据样本越多,表明计算框架的处理能力越强。在测试中,我们使用了 localps 和 default 两种参数服务器配置模式。
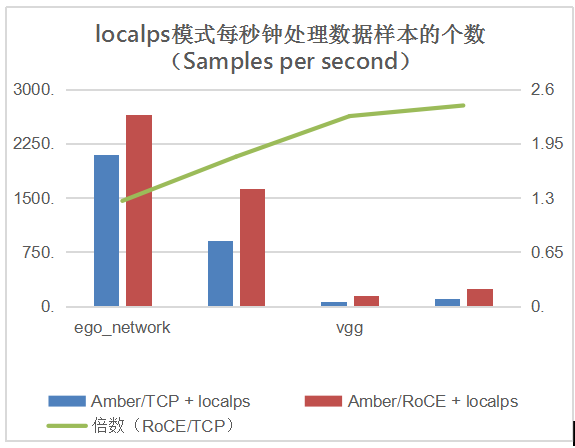
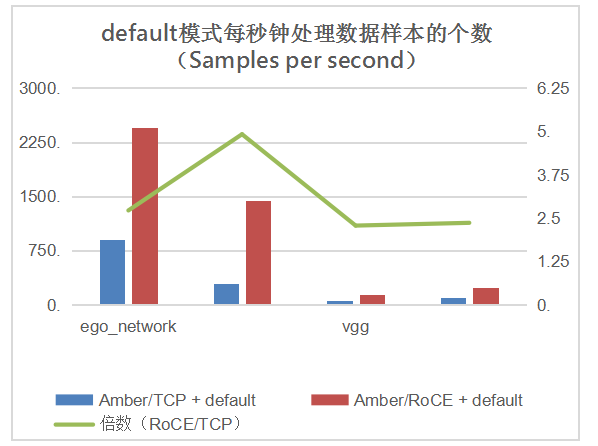
从上图可见,整体来说,在多种模式和多种应用下,使用 RoCE 技术的 Amber 都表现出更高性能:使用 localps 的平均加速倍数(Amber/RoCE 的任务完成时间与 Amber/TCP 的任务完成时间的比值)为 1.93 倍,而使用 default 的更高达 3.072 倍,这是因为 default 模式需要的网络传输量更大,因此更快的网络技术会得到更明显的体现。
网络带宽
分布式应用的一个重要微观指标是网络带宽的利用率,它可以用一个应用的平均吞吐量来衡量。吞吐量越高,则表明一个应用可以更有效地使用网络资源在单位时间内可以完成更多的任务。下图中标识了 Amber/RoCE 和 Amber/TCP 在各个任务中的的平均网络吞吐量。
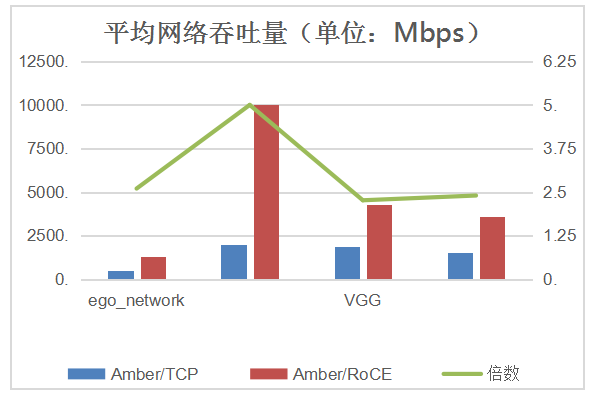
可见,与 Amber/TCP 相比,Amber/RoCE 能更有效利用网络资源,达到平均 3.07 倍的吞吐量。这也对应了 Amber/RoCE 在整体性能上的优势。
系统扩展性
在并行计算领域,加速比表示当并行算法与对应的顺序执行算法相比较时速度快了多少,而理想加速比则是系统所能达到的最优扩展性。当某一并行算法达到理想加速比时,若将处理器数量加倍,执行速度也会加倍,即称为具有“优秀的可扩展性”。下表以效率为指标,对比了 Amber/TCP 和 Amber/RoCE 的可扩展性。效率为加速比和参与计算的节点数目的比值,越接近 1 代表多机性能的线性扩展性越好。图像识别应用往往会使用比较深的神经网络,所以其模型也较大,多个机器在训练中的模型同步对于网络传输系统的可扩展性也更为敏感。因此,为了体现 Amber/RoCE 的可扩展性,我们采用了三个著名的用于图像识别的深度学习模型, CNN、VGG16 和 AlexNet。

从上表可以看出,Amber/RoCE 表现出优异的可扩展性。此外,基本上可以认为,多机性能是单机性能的线性扩展,这也有利于更大规模的模型并行跑在不同机器上而不用担心网络带来较大的性能损耗。
综上所述,RoCE 技术适用于大规模数据中心的 RDMA 网络传输,而对于需要在类似数据中心环境内部署的 Amber 深度学习框架,我们为之开发了相应的网络传输系统。实验表明,使用 RoCE 可以大大加快深度学习任务的完成时间,提高网络的利用率,并且能够达到近似最优的可扩展性。RoCE 网络技术也适用与其他深度学习计算框架,WHAT Lab 的并行计算团队也在对其他的框架进行 RoCE 传输层的开发。
作者简介
陈力,香港科技大学计算机科学与工程系的博士四年级。他的研究领域为数据中心网络,主要课题有:光网络,传输层协议,软件定义网络,以及大数据系统。
钟轶,微信技术架构部后台开发工程师。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论