
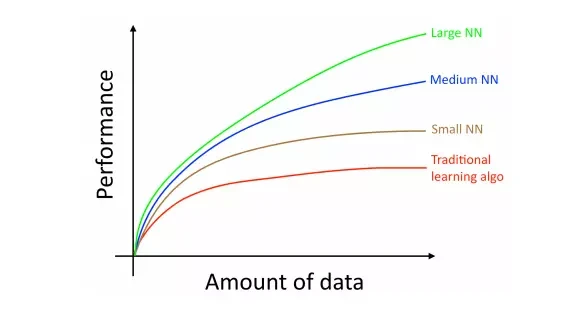
数据规模的扩展推动了深度学习的发展。如下图 Andrew Ng 在《Machine Learning Yearning》一书中展示的图。当达到一定的数量后,传统算法的性能不再随着数量而获得提升;但是,大中型神经网络计算的性能依然会持续提升,并且与传统算法的性能优势差距越来越大。
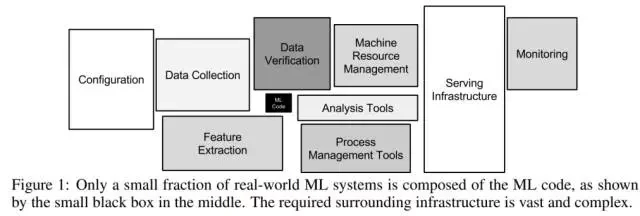
随着 Hadoop 兴起和发展,如今 Hadoop 已经成为了“数据重力中心”(Center of Data Gravity),这为深度学习的研究奠定基础。Google 曾经在 2015 年 NIPS(Conference and Workshop on Neural Information Processing Systems,神经信息处理系统大会)上发表《Hidden Technical Debt in Machine Learning Systems》的演讲中表示,为了支撑机器学习和深度学习,需要做大量工作即搭建工业级复杂的大数据分析流水线。
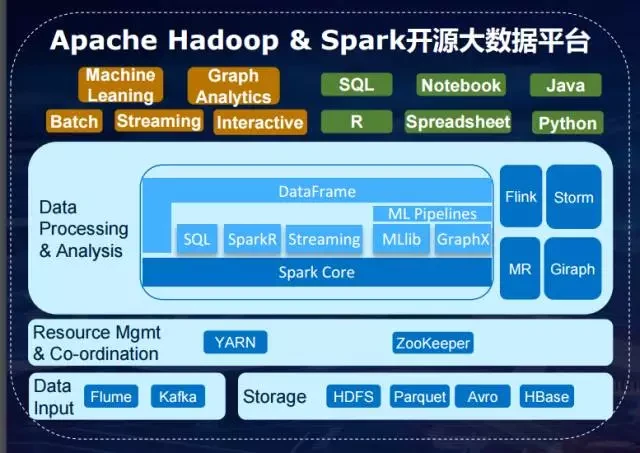
幸运的是,开源社区中的 Apache Hadoop/Spark 平台推动大数据分析进入了民主化时代。Spark 成为了业内进行大数据处理分析的主流计算框架,里面有非常多不同的组件提供各种各样的丰富的功能,从 SQL 的查询、流式的处理、机器学习、图像计算等等。
那么怎样才能让人工智能继大数据之后变成下一个民主化的技术浪潮呢?需要更易用、高效扩展、更低的成本和卓越的性能。
在戴金权看来,一方面深度学习社区每周都有新的技术突破,这非常令人激动并且也受到广泛关注;而另一方面,在真实的生产环境中“沉默的大多数”,事实上数据工程师们才是重度数据分析处理的大多数。不过,深度学习和大数据的社区是不完全匹配的,虽然数据工程师们不是深度学习专家,但是深度学习其他现有的软件框架、硬件架构并不友好,使用起来非常麻烦。简而言之,数据工程师们关心的是怎样更方便地适配到生产开发环境,并且真正应用解决问题(而不是 demo 的层面)。
BigDL 技术概览
初衷:基于已有 IT 格局,重点面向大数据从业者
BigDL 是英特尔在 Spark 上构建的一个面向 Apache Spark 的开源、分布式的深度学习框架,目标人群是大数据用户和数据科学家,其设计初心是为了让这些人更方便地应用深度学习,因此使用时无需修改、直接运行在现有 Hadoop/Spark 集群。
BigDL 的设计出发点:可以重用现有的工具和基础架构;充分利用 Hadoop/Spark 集群上存储的数据,在大数据(Spark)程序或工作流之中增加深度学习功能。BigDL 是在已定的 IT 技术栈之上,增加了对深度学习的支持,可以进行如数据清洗、数据仓库、特征工程、机器学习、图分析等应用。
BigDL 的一些特性
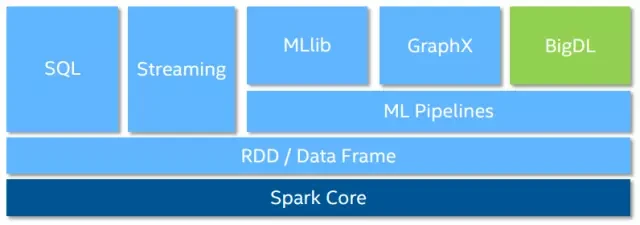
源码地址 https://github.com/intel-analytics/BigDL,http://software.intel.com/bigdl 目前 BigDL 对深度学习支持如下:
- 张量,层:超过 100 个(线性,卷积 Conv2D、Conv3D,降维,循环)
- 损失函数:数十个
- 优化算法:SGD、Adagrad、Adam、Adamax、RMSProp、Adadelta
- 分布式训练 / 推理
- 保存和加载模型文件:包括 Torch、Caffe、TensorFlow
Spark 可以做很多事情,它提供的 API 相当于一个平台,BigDL 与其结合使用可以在非常大的数据规模上面做如 SQL Streaming 等一些传统的数据分析工作。

目前比较全面支持 Scala 和 Python 两个语言。由于 Java 与 Scala 都运行在 JVM 上,两者之间基本能做到无缝的集成,即支持 Scala 就意味着支持了工程师们的语言 Java;而 Python 是数据分析师们的语言。

上图展示了对 Python 的支持和使用方法。基于 PySpare,开发者们可以通过 BigDL 中的 Python API 调用常见的 Python 库,如 Numpy、Scipy、Pandas、Scikit-learn、Matplotlib 等。
同时,BigDL 的使用可以是单机、集群也可以是云,更换环境只需要修改几行配置代码即可。
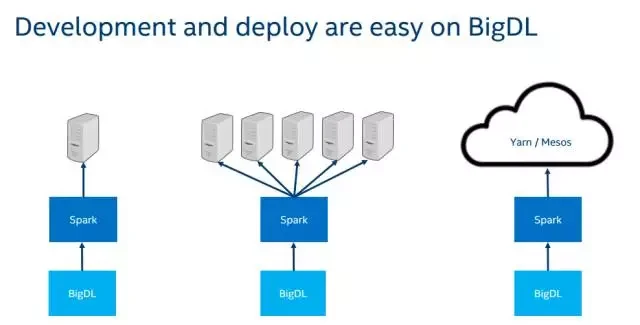
在各方面的使用上,BigDL 都是 Real out of box,不需要安装依赖包等。只要可以运行 Spark 的环境就可以运行 BigDL,堪称无痛使用。
除了 Hadoop/Spark 集群之外,BigDL 还可以运行于其他大数据分析平台与公有云之上,如 AWS、Azure、Alibaba、CDH 与 Cloudera、Databricks、Mesos 等。以 AWS 为例,两者合作将 BigDL 共同部署到 AWS EC2 上,同时 BigDL 又与 AWS EMR(Elastic MapReduce)直接继承,直接对使用者屏蔽集群的概念。
戴金权称 BigDL 本质上是一个标准的 Spark 应用,只要一个标准的 Hadoop / Spark 集群或者提供标准 Hadoop / Spark 服务的云就能运行。对于使用者而言,BigDL 的使用类似与自行编写一个 Spark 应用。
BigDL 0.1 于 2017 年发布,Intel 称其提高了深度学习在数据科学家中的易用性:
- Python API 的支持
- Jupyter Notebook 的支持
- TensorBoard 可视化的支持
- 更完备的 RNN (Recurrent Neural Network) 的支持
- 更健壮、更易扩展的大规模分布式训练
即将发布的 0.2.0 版本将包括:
-
Functional API 的支持(类似 Keras)
-
TensorFlow 模型导入和定义的支持
-
Spark ML Pipelines 的原生支持
-
Python 包(pip 安装)以及 Windows 平台的支持
-
导出模型到 Caffe、TensoFlow 或本地 JVM 运行
-
更高级的神经网络的支持
- Bi-directional RNN, tree LSTM, Convolutional LSTM, 3D Convolution & pooling, 等等
落地:光有模型并不足够,要搭建端到端流水线 英特尔技术专家告诉 InfoQ,现在 BigDL 已经被使用到生产环境中,规模因用户情况而异,集群节点可能是几个、十几个或几十个等;还有一些用户可能会上百,比如 eBay 有大概两百多节点。
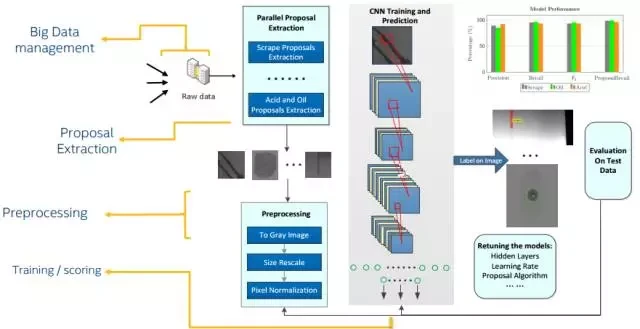
下图是工业制造中的产品缺陷检测:
2015 年,中国银联电子商务与电子支付国家实验室联合英特尔开展了基于神经网络的线上欺诈交易侦测模型研究。基于 Spark 的 ML Pipeline 进行机器学习流程的构建,采用英特尔 BigDL 分布式深度学习库提供的神经网络算法进行模型的训练与测试。
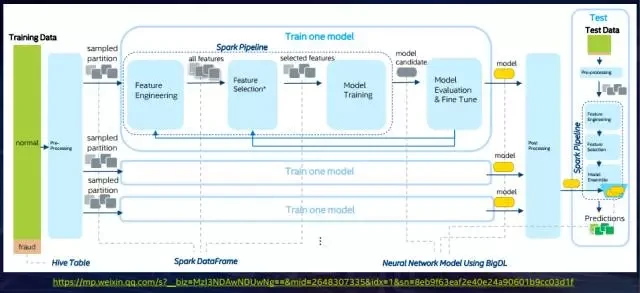
其实大部分银行本身都有一套欺诈交易侦测系统,只是研发程度不尽相同:有的是制定规则,例如个人短时间连续消费不能超过多少笔;有的是做决策。英特尔称其利用 BigDL 进行深度学习训练了 10-20 个独立的神经网络模型,经过 Bagging 集成测算比现有系统的准确率更高。
BigDL vs 其他深度学习框架
BigDL 和其他的深度学习框架其中一个不一样的地方是,它是专门为这样的大数据的运行环境所优化。一方面它在单点上利用英特尔的 MKL 库,多线程编程等等,可以得到非常高的性能。同时又充分利用了 Spark 架构,可以很方便在集群上进行横向扩展,可以很方便地跑在几十个甚至上百个节点上。
但是同时英特尔表示,BigDL 也会与 Spark ML 整合。一方面是因为 Spark ML 可以在分布式机器学习和数据科学中非常广泛的使用;另外一方面的原因 BigDL 本身就是构建在 Spark 之上的深度学习库,因此需要与原生的 Spark ML pipelines 进行整合。此外,还可以把 BigDL 模型导出到 Caffe、TensorFlow、Torch,开发者们甚至可以把它作为一个本地的 Java 程序在本地的 JVM 运行,与所有的 JVM 编程框架(如 Storm)结合使用。未来,还会有更多高级的神经网络支持,如双向 RNN、递归网络;增强 3D 图片处理能力。
谈谈大数据、云计算与人工智能
在戴金权看来,人工智能是一个比较宽泛的概念,一些规则系统、推理系统都算作早期的人工智能,这些年人工智能的发展很大程度是用深度学习、机器学习构建学习系统,扩建模型等。而这样的情况下,需要统一的大数据平台作为机器学习、深度学习应用的支撑;算法和模型固然重要,但是构建工业级的系统应用,就需大数据分析的整个平台。
从某种程度上来说,大数据平台和云计算架构非常类似,不管是基于公有云还是企业内部自建的平台,都需要横向扩展,实现资源调度和分享等。在很多云厂商的云计算服务中,数据存储、大数据的分析是非常重要的组成部分;而企业内部构建云也需要重点考虑如何构建数据的平台。
结语
英特尔称,打造 BigDL 的主要心力是在 Spark 大数据平台上能够更快、更容易应用深度学习解决方案,不仅仅是止步于设计一个深度学习框架。基于 Spark 平台而建的好处,是 BigDL 可以与其他组件方便地交互。
BigDL 支持整个 Hadoop 生态圈内各种功能组件,如管理机器、引入数据、存储数据及分析工具等,并且支持不同开发语言。同理,英特尔称也希望将 BigDL 更方便地嵌入已有大数据生态中,使研发变得更方便,从而达到“深度学习民主化”。
英特尔在人工智能方面做了非常多的工作,端到端的人工智能的工作,从硬件层到软件,再到上层的各种各样的应用体验。包括从数据中心端到设备端,这样的端到端的人工智能工作。目标就是为了能够更好地推动人工智能计算的民主化,让更多人,让各行各业更方便、更快地使用人工智能技术。
—— 戴金权
QA 问答
InfoQ:相比其他开源项目,BigDL 有没有待改进的地方?英伟达专注于 GPU,谷歌主攻 TPU,当前的情况会不会给你们带来一定的发展局限?
戴金权:首先,英特尔目前专注的目标就是希望能够在现有大数据的集群上性能最好,所以我们主要集中在大规模的基于至强处理器的集群上进行优化。如果你今天去看所有大数据的集群,大都是这样的生产环境。当然,英特尔致力于很多硬件加速、硬件优化方面的工作,例如我们之后会有从某种程度来说更偏向于 ASIC 这样的一些产品,我们也会在之后把这些支持和优化加进来,只是说这可能是我们下一步工作的方向。
InfoQ:大数据或者深度学习,如果以后分析到很关键的数据,安全问题怎么考虑?鉴于攻击行为越来越多,英特尔在这方面有什么样的考虑?
戴金权:我觉得目前面临几方面的问题,大数据方面的安全本身就是一个非常重要的课题,英特尔在大数据安全方面,包括英特尔,包括英特尔和 Cloudera 合作,我们在开源社区里面有非常多的考虑。大家如果关注到的话,在 Hadoop 整个生态系统里,除了有数据处理,其实还有很多数据安全,数据如何管理的项目,以更好的来提供数据保护,这其实是英特尔一直做的事情。
InfoQ:现在人工智能等等不同的技术发展趋势很热门,英特尔如何看待?
Michael Greene:就像你所说的,我在英特尔和整个软件行业从事多年,这么多年以来英特尔研发软件的方式和方法从来没有变过,就是永远基于客户的需求,并为他们带来能够切实的解决方案。对我们来说,客户的需求永远是第一位的,这也是为什么我们会一直非常紧密的跟踪他们的需求,当然在这个过程中我们也会更紧密地追踪整个软件行业发展的趋势。人工智能和机器学习不仅是目前行业的趋势,也是绝大多数客户需求的技术方向,我们的客户都在向我们提出要求,希望能够有更好的认知引擎,能够有更好的产品定位,希望从大数据当中更快更好的获得洞察。这也是英特尔去开发、调整、升级软件的一个基础,是希望能够尽我们所能为客户带来最好的客户体验。今天戴金权肯定也为你们介绍了我们相关的软件和开发,包括最新的 BigDL,BigDL 的一个初衷就是希望能够让客户用更简单和高效的方式运用他们的大数据,做更好的分析性的解决方案。
InfoQ:英特尔之前给大家的印象是一家聚焦于硬件的公司,现在能说软件对于英特尔而言也越来越重要了吗?
Michael Greene:事实上一直以来软件对于英特尔都是非常重要的,因为软件对于我们客户是非常重要的,所以对于我们也是非常重要的。最早开始我们就寻求很多不同的方式去和软件开发商合作,比如最早在 PC 端,微软和开源社区 Linux 都是我们的合作伙伴,后来软件开发的重心从 PC 端迁移到云、数据中心,还有您提到的机器学习和 AI,我们也会跟随这样的趋势,我们的软件开发也会有这样的重心的迁徙。
所以我还是要强调,软件对英特尔来说一直是非常重要的。当我们的客户或者我们的用户来买我们的处理器,不管是至强还是凌动,买的不是硅晶片,而是需要上面的软件能够运行。所以我们一直说英特尔的生命就在于软件和硬件的结合,这也是我们的热情所在,也是一直以来我们追寻的方向。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论