
全生命周期管理(ALM)领域作为企业 DevOps 实践的总体支撑,应该说是 DevOps 领域中最为重要的实践领域,也是所有其他实践的基础设施。现在很多企业都非常重视 CI/CD 自动化工具的引入和推广,但是对 ALM 的建设的重视程度并不够。CI/CD 的火爆很大程度上是被 Docker 和 DevOps 的热潮带动的,但 CI/CD 自动化只是提升团队效率的一个环节,如果没有 ALM 工具的支撑,CI/CD 也只是空中楼阁,无法起到整体优化团队工作效率的作用,甚至局部的效率提高还会造成团队的不适应甚至抵触。如果管理者看不到自动化所产出的价值提升,团队感受不到自动化所带来的效率改进,这一切的问题都应该归根于企业没有建立端到端的研发数据链,数据不打通,问题的反应永远只是局部的,无法从问题的表象跟踪到问题的根源。《凤凰项目》中所提到的 DevOps 三步工作法的第一步:建立全局观;其实是后续的建立反馈和持续改进的基础。CI/CD 自动化在 DevOps 中所起到的作用更多的是加快反馈速度,但在没有建立全局观的情况下一味的进行反馈其实是没有作用的。
就研发数据链来说,下图所展示的《软件研发管理过程全景》中每个元素以及元素之间的链接就是 ALM 平台所最关注的重点。只有建立了完整的研发数据模型,有了这些关系,我们才能从整体上对研发效率进行评估,找到瓶颈,进而改进。建立这个模型的过程其实就是 DevOps 三步工作法的第一步:建立全局观。
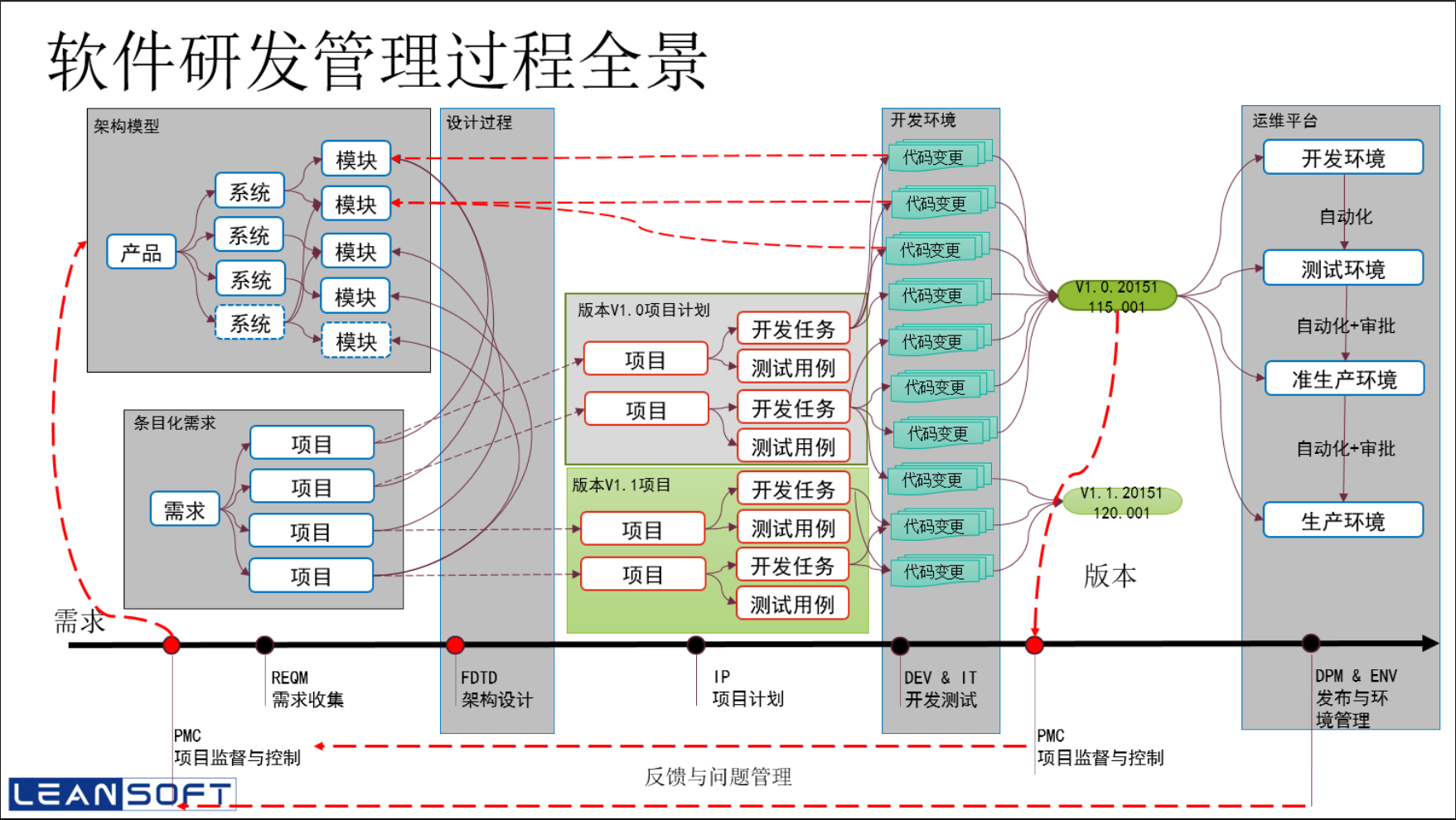
(说明:以上的全景图是基于敏捷开发模式的,在传统瀑布模式下,中间的项目计划一般是从“架构模型”过来的,而不是从“条目化需求”过来的)
在全生命周期管理实践中,工具的使用是非常重要的一环。我时常把 ALM 系统比作研发的 ERP,而实际上就是这样一种关系,ALM 平台就是研发的信息系统。在所有的 ALM 系统中,跟踪都是最基本的模块,比如:VSTS/TFS 中的工作项跟踪,或者 Atlassian 产品中的 Jira 工具都是专注于这个领域的成功产品。但是我们也应该注意到上图中除了对事务或者内容的跟踪以外,我们还需要把代码,用例,版本和环境也作为跟踪的一部分。要做到这一点,工作跟踪与配置管理,与自动化系统的数据链路打通就变成了一种必须。
在这种场景下,一体化的工具(如:微软的 VSTS/TFS)就发挥出了它的优势,因为内置了包括工作跟踪,测试管理,代码库(GIT)和自动化系统(CI/CD); 对于以上全过程的数据采集就变得易如反掌,同时配合后台的企业级数据挖掘和分析引擎,让研发数据链的建立,数据清洗和挖掘工作全自动化,不再需要另外投入精力从不同的系统中抓取数据并进行 ETL 聚合等操作。而使用相互独立的过程跟踪(如 JIRA, redmine),配置管理(如 SVN,GitHub/GitLab,BitBucket),测试管理(如:QC, TestLink),缺陷管理(如:Bugzilla)和自动化(如:Jenkins)工具,要建立完整的研发端到端数据链就必须另外建设独立的数据挖掘和分析平台;这部分工具不仅投资巨大,而且难度很高。这后一种场景在企业信息化建设中也是一种常见的误区,一般称为烟囱式建设或者信息孤岛效应,大多数企业管理者都会希望采用各个领域最专业的系统来建设,最后发现每个领域你都用不到那个系统功能的 20%,还要再花费巨大的时间和资金投入去进行系统集成和数据打通。
在研发领域,能够把管理者最关心的数据从团队成员的指尖送到管理者的面前,其实是这些系统最重要的功能之一,如下图:
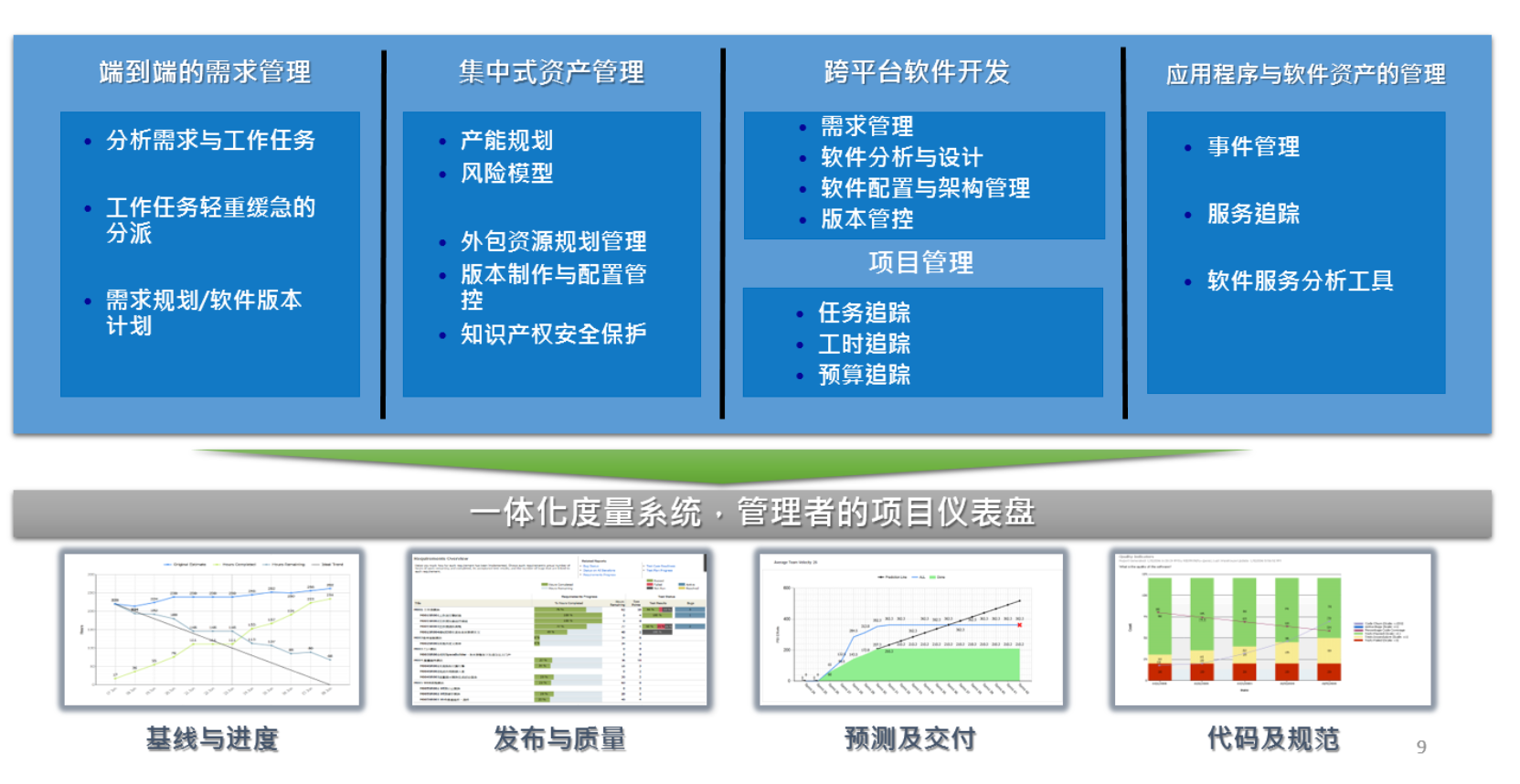
类似以下这张报表,如果没有完整的研发数据链和数据模型,是很难做到的
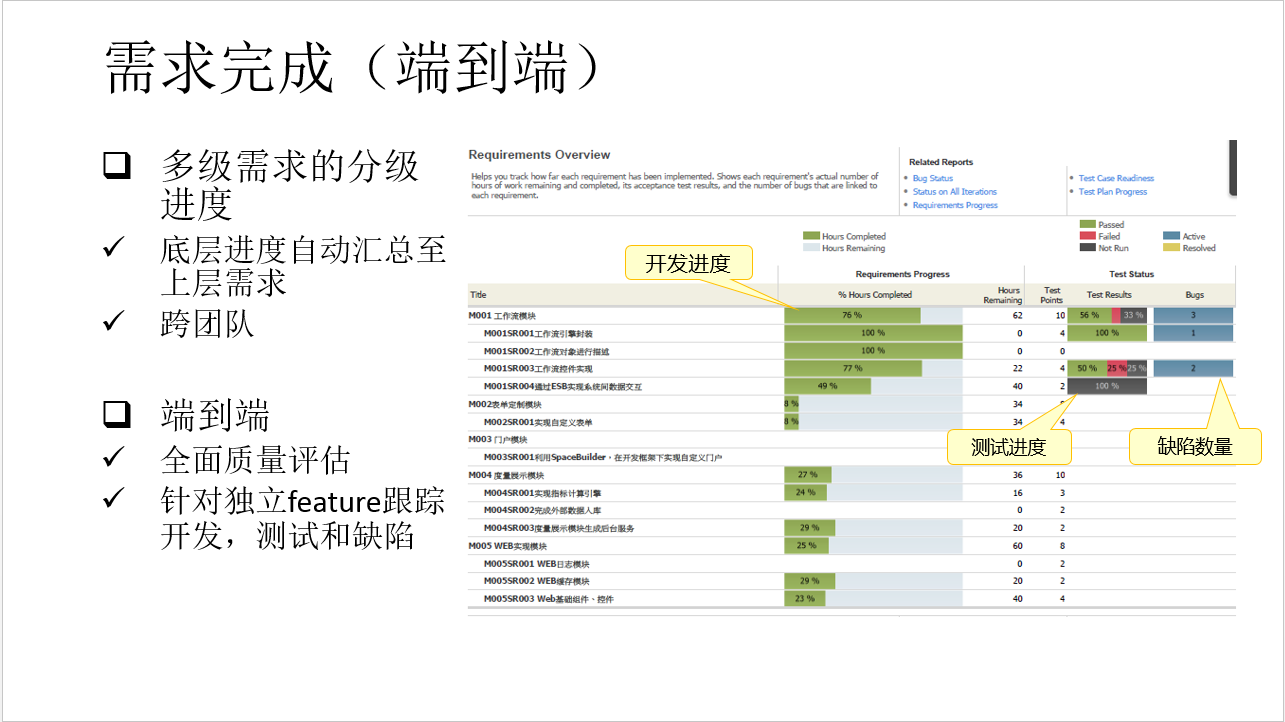
我们一般称此报表为:项目 / 产品交付进度,它不仅仅展示了事务工作的进度(开发进度一栏),同时也在每个需求维度上展示了质量情况(测试用例通过率和 bug 修复率)。这样对于管理人员来说,你无需知道细节就可以对某一特定需求的交付能力进行判断。
为了生成以上这张报表,我们需要聚合至少 3 类数据
-
- 不同层级需求上的进度情况:需求管理过程中,为了能够给不同的角色进行分工,或者区分不同类型或者粒度的需求,我们一般都会将需求组织成树形结构;并在最底层节点上挂接开发任务并分配给团队成员;团队成员在任务粒度上的进度反馈需要一层一层累加到最终用户可见的需求上;这个数据模型的建立主要通过工作跟踪模块来完成,数据分析的建立则需要经过一定 ETL 处理的数据仓库配合。
-
- 测试进度:测试管理涉及测试事务管理和测试内容管理两个部分,事务管理的是人员的工作量和进度,而内容管理的是产出的具体测试用例和执行结果。实际工作中,我们必须能够同时管理这 2 个维度的工作,同时将测试内容的结果反馈到具体的需求上,这样对交付才有作用。这部分的数据通过 ETL 进行处理时必须能够和前面的需求粒度产生数据联系。
-
- 缺陷进度:缺陷一般是测试产出或者用户(包括团队成员)的反馈,包括修复的情况。同样,这部分数据也需要在 ETL 的时候和需求粒度建立联系。
另外一个研发数据挖掘和分析的很有意思的应用是 Code Lens,如下图:
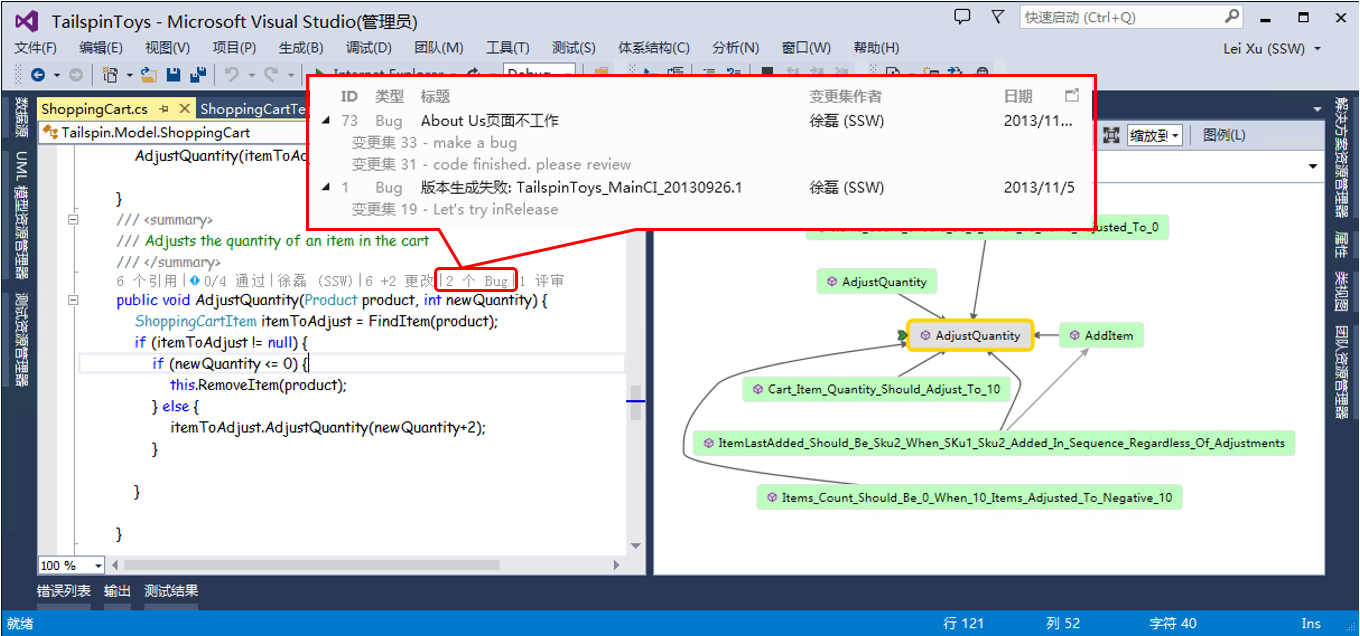
通过整合代码库历史记录与工作项跟踪信息,可以在开发人员编辑代码的同时在后台分析出当前的代码块在历史上曾经出现过哪些问题 /bug,帮助开发人员定位问题。
我们在研发管理上往往陷入一个误区,就是让具体做事情的人(程序员、测试人员等)觉得他们所做的任务更新,代码提交都是给别人做的;自己完全体会不到任何好处;久而久之,就失去了主动性,认为管理的事情跟自己无关,采取不配合甚至抵触,更有甚者则提供假数据蒙混过关。这其实不是开发人员的问题,造成这种状况的原因是我们没有让开发人员从自己所提供的数据中获取价值。如果我们能够提供更多类似 Code Lens 这种开发辅助工具,开发人员一定是乐于参与其中的。我们在 DevOps 中常说要打破部门壁垒,建立协作;这些不能只靠做游戏,我们还需要为流水线中的每个角色提供实打实的价值反馈,才能让大家真正成为一个整体。
简单总结一下,全生命周期管理平台数据分析的价值有二:
第一:为管理者提供更多的 Insight,让所有的细节串接成为研发全景图,提升管理者对实际状况的把控能力。只有看到才能评估,只有评估才能管理。
第二:为开发人员提供更多的 Insight,让流水线中的每个环节都能获得对他们有价值的反馈。只有反馈了价值才有正能量,只有正能量才能形成协作。
我曾经为多家大型企业实施过微软的 VSTS/TFS 全生命周期管理平台,这些企业最看重的一点其实就是是 TFS 在研发数据分析上所体现的开箱即用能力。这些年,微软 TFS(包括在线的 VSTS)的版本更新越加频繁(从每 2 年一个版本提升到每 3 周一个版本),我们的客户非常关心这些新特性的发布情况,同时我们自己也需要不停的跟进这些新特性以便给客户提供最优化的方案。
因此,我们决定从 2017 年 5 月份开始维护 “VSTS/TFS 功能发布时间轴”,这个页面将跟随 VSTS 的三周发布频率,定期更新,同时对新发布的功能进行简要介绍。希望能够帮助广大企业和开发团队及时了解这一工具的最新动态,持续优化自己的 DevOps 实践。
页面地址: http://devopshub.cn/vsts-tfs-feature-timeline/
这个页面分为 2 部分,同时显示 VSTS 在线版的发布时间和 TFS 企业版的发布版本号,中间的特性列表中包含指向这些功能介绍的链接。我们会逐步将这些功能的介绍链接翻译成中文,让国内的团队能够第一时间了解这些功能的变化。
1. 开发中的功能列表
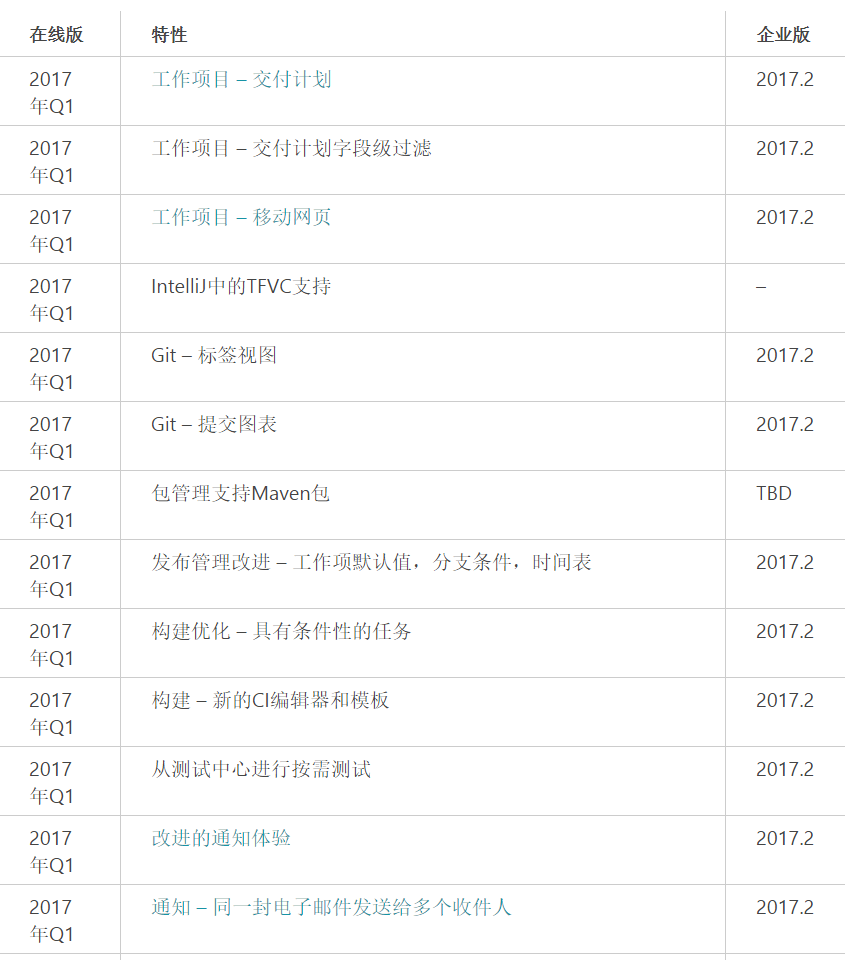
2. 已经发布的功能列表
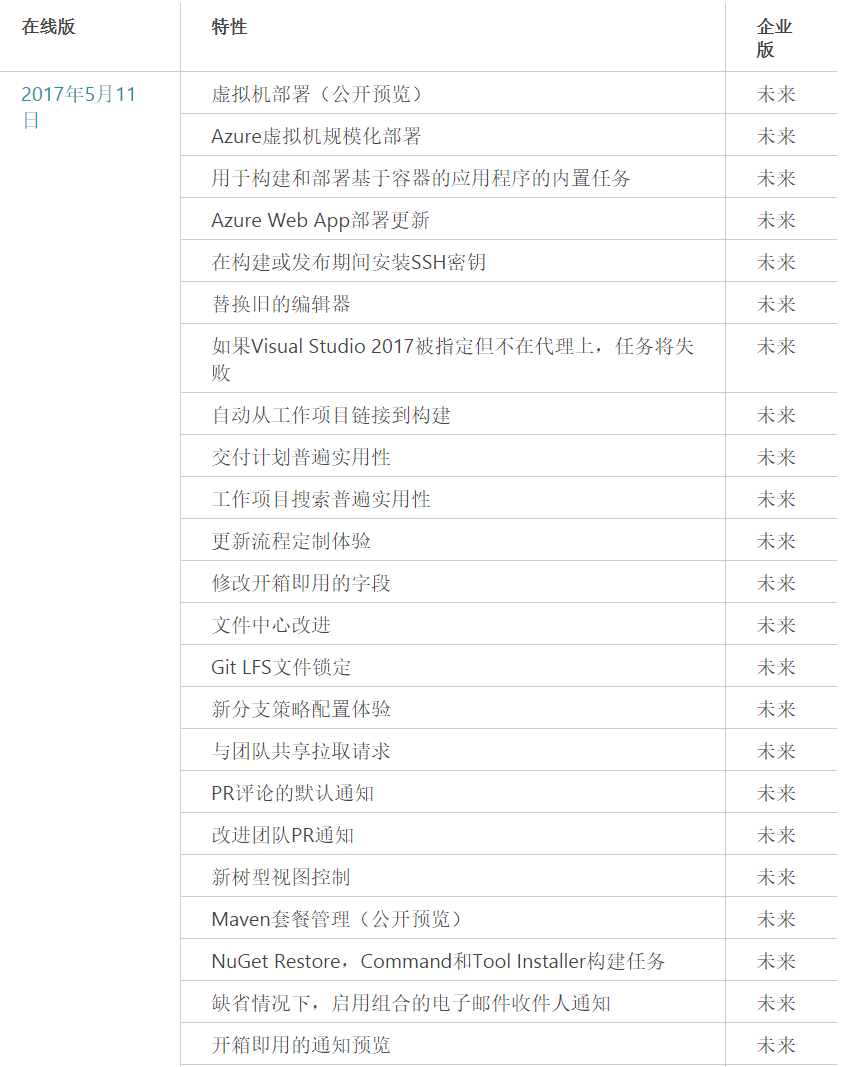
这次,我们还同时发布了 2017 年 5 月 11 日的 VSTS 迭代更新说明: http://devopshub.cn/2017/05/19/vsts-update-may-11-team-services/
这个页面的发布要特别感谢我们团队的 90 后程序员 Caden,在短短 1 周之内就完成了页面的搭建和翻译工作。
作者简介
徐磊:一名写了十几年代码但还没写够的程序员,微软最有价值专家(MVP)之一。1999 年,毕业于北京理工大学工业管理专业和计算机专业;2001 年,硕士毕业于 UNSW 信息工程专业。从事过网管、技术支持、网络、软件开发等工作。2004 年加入了 SSW( www.ssw.com.au );2005 年组建 SSW 中国研发中心任 Country Manager;2012 年成立独资公司 SSW LIMITED BEIJING 任 GM;2014 年创立 Lean-Soft,专注于软件工程领域的创新实践。个人博客站点: http://devopshub.cn ,微信订阅号 devopshub。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论