在运维系统自动化的过程中,会遇到哪些难点?怎样面对这些挑战?在这个变化过程中,运维团队的职能会发生怎样的演变?继《论运维自动化(上):运维系统须具备五个维度,全面自动化应分步实现》一文之后,蘑菇街运维经理赵成又谈及了不同阶段的自动化运维技术难点、团队职能的演变;同时给运维同学提出了一些个人的建议。
此外, ArchSummit 全球架构师峰会将在北京举行,赵成出任运维专场的出品人。
嘉宾介绍:
赵成,花名谦益,ArchSummit 明星讲师,蘑菇街运维经理,现在负责蘑菇街运维团队的管理以及运维体系的建设工作。在运维行业中已经做了 8 年,之前有过 5 年左右的业务开发经历。加入蘑菇街之前在华为一直做电信级业务的开发和运维工作。
InfoQ: 技术上具体而言,运维自动化难点有哪些?蘑菇街在运维自动化的过程中,遇到过最大的挑战?
赵成: 运维自动化的难点,我想应该是分阶段的:
1) 第一个阶段,是无到有的基础建设阶段,这个过程中,可能最重要的是第 3 个问题回答的部分,如何能够开展起来,这一阶段我们也是摸索了一段时间,不断地学习和交流,也借鉴了业界的一些优秀经验,从一头雾水到思路明确,关键是还是摸清楚这样一套体系应该怎么样的,应该怎么起步,方法上主要还是学习和交流,所以这样看下来,这个阶段技术不是难点,更重要的是在规划上要做好。
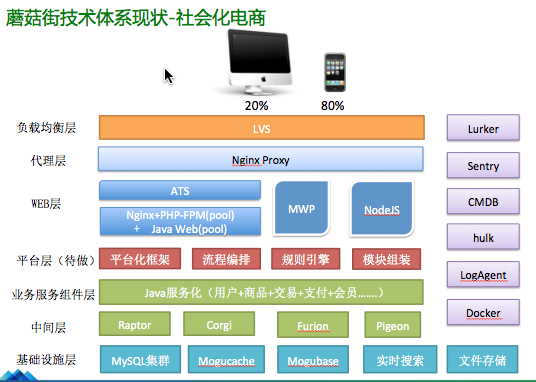
2) 第二个阶段,运维场景的整合阶段,也就是当前业界所提到的场景化运维这样一个思路,同时也是我们当前正在经历的一个阶段。这里直接拿一个我们最常见的应用扩容的实际场景举例,对于扩容这样一个需求,乍看上去,就是分配几台机器然后上线,但是对于一个大型的互联网系统来说,这样一个原生需求分解下来,通常会涉及到以下几个环节,机器申请、机器审核、机器分配、基础环境初始化、应用环境初始化、代码部署(涉及到前端的,还要有关联部署)、VIP 配置变更、DNS 配置变更、ACL 策略配置(DB& 网络)、应用启动、端口 & 服务状态检测、应用服务注册上线、线上业务引流、监控和告警指标检查。Ok,这样一个复杂的过程,其中的每一个点都是一个自动化的环节,可能都会有一个自动化的工具平台或脚本支持。所以可以看到,一个应用扩容的原生需求场景,在实际执行时是需要拆解成很多的原子操作,每个原子操作又可能是不同的人来负责,同时随着业务、稳定性和安全要求的变化,可能还会相应的原生操作的增删改需求。所以这种情况下,我们必须要通过对现实运维工作场景的提炼和抽象,归纳出所有的运维场景,通过流程和规则将以上的原子操作进行串联和整合,从而使得运维和开发同学只需要面对某一个场景,当场景触发后,通过流程和 SLA 自动化或自助地驱动每个环节的完成,而不是靠人去找,或者靠人去盯着驱动,整个技术团队依赖的是运维的能力,而不是运维的人。
所以这个阶段,总结下来,技术仍然不是最大的挑战和难点,难点是对运维场景和业务的理解,考验的是运维业务分析、抽象、归纳和整合能力。
3) 第三个阶段,智能运维阶段,比如智能告警、故障自愈、运营辅助决策等,我们前面提到的稳定性、体验和成本,也很大程度上依赖这个阶段的建设工作,因为这个阶段我们正在尝试,不能说有很多的实践经验和成果,所以在此就不在班门弄斧了。有兴趣的同学可以看一下腾讯的蓝鲸和织云两个运维体系,或许可以有更多的收获。
不过我想在这个阶段,技术上的挑战性将会是非常大的,因为智能化决策离不开数据支持、规则的建立,所以大数据、机器学习以及各类决策算法应用的引入将会是比较大的挑战。
InfoQ:你们运维团队规模和职能的演变过程分别是怎样的?
赵成:在 2013 年之前,我们并没有专职的运维同学,当时业务和资源体量并不大,系统也没有很高的复杂度,都是开发同学承担日常的运维工作。
2013-2014 年底,我们 3 名专职的运维同学,基本什么事情都做,主机、OS、网络、应用、Cache、DB 等等都要负责,属于全能型选手,有一些简单的运维系统和平台来做日常工作的支持,但是大部分仍然要靠人工处理。
2015 年之后,随着业务快速发展和体量规模的日益庞大。首先,驱动着我们的技术架构发生了如下的几个重要有变化:
- PHP 开始转向 Java 服务化:从原来的 Url 接口调用转变成了 RPC 的调用方式;我们的 Java 服务化框架 Tesla 正式大规模上线到生产环境;线上应用的数量也从原来相对单一的 PHP 一套代码和应用,快速分解为几十到上百个应用。
- 中间层技术方案转向中间件技术方案:早期采用了缓存中间层、DB 中间层等;为了解决连接数这个主要问题,开始转向专业的中间件技术方案,比如消息中间件 Corgi、分布式数据库中间件 Raptor、以及分布式存储 MoguCache 等解决方案。
- DB 分库分表:随着数据量的急速增长,开始朝着分库分表的方向发展,比如商品和交易,目前已经做到了 8 个分片;同时对于大量的离线或者冷数据,转向了 HBase 这样的技术解决方案。
- 虚拟化和私有云技术引入:为了提升资源利用率和部署效率,我们引入了 KVM 和 Docker 的虚拟化及容器技术,并以此为基础打造了我们自己的私有云平台。
业务技术的快速发展,运维面临的挑战难度系数直接指数级上升。如果运维体系跟不上,业务开发的效率和业务运行的稳定性将收到直接影响。所以也正是在这个阶段我们开始思考如何从整体上去规划运维体系和架构,从而能够快速的适应业务技术架构的发展。到目前为止,我们运维体系的调整变化有如下五个方面:
- 基础部分:管理上标准化的落地,技术上 CMDB、资源管理、应用配置管理以及应用上下线等日常基础工作自动化的建设。关于这一块内容,大家可以看一下我在 2015 北京 ArchSummit 峰会上的分享内容。
- 效率:持续集成 & 发布系统的开发,能够支持线下和线上多环境、预发和 Beta 多版本的管理和发布;同时能够跟日常项目管理结合,从项目维度来管理集成和发布的规范性。具体内容大家可以看一下我在 ArchSummit 微课堂交流群里的分享。
- 稳定性:如前面提到的全链路系统、容量评估系统、开关系统、限流降级系统、预案系统等等,也是稳定性团队与运维团队共同协作的成果。相关内容可以参考我的同事苏武在今年深圳 ArchSummit 峰会上的分享。
- 监控系统:开发了 Setnry 监控系统,支持应用为维度的自定义和自助式的配置(注:Setnry 由监控系统团队同学负责主要开发,运维同学参与技术和产品需求的设定。)
- 用户体验:如 ATS 静态化,以及 ATS 在私有云和公有云结合的混合云解决方案。在今年 618 的时候,公有云支持了我们详情页和会场页三分之一的流量,用户体验大大提升。关于这一块,可以参考我的同事无锋在今年北京 QCon 上的分享。
好了,最后回到问题上来,团队的规模和职能的演变,是随着要做的事情而变化,而不是单纯地去扩大人力规模。目前我们团队分为 4 个小组,20 人左右的规模,每个小组都是在领域内有非常高专业程度的同学组成。
- 基础运维团队:负责 IDC、主机、OS 以及其他硬件方面的运维工作
- 应用运维团队:负责应用的日常维护工作,以及稳定性保障和性能优化
- DBA 团队:负责线上 DB 的稳定和安全,以及 DB 的自动化运维
- 运维开发团队:负责运维体系和自动化的开发和建设工作
InfoQ: 您有哪些给运维同学的建议?
赵成:下面谈一下对运维同学职业方向和发展的建议吧。以基础运维和应用运维为例,我们在职责划分和职业方向上规划时,一直在强调:我们不能简简单单的把自己定位成是被动响应或者是开发的延续;如果是这样定义,那只能是别人说什么我们就做什么。我们应该要从单纯运维向技术运营的方向去发展:要把日常运维工作中做的事情不断地总结归纳,提炼出有价值的产品功能和需求;进一步要能够具备一定的产品设计和系统规划能力,从而向运维开发、稳定性、监控等周边团队提出我们的需求(也只有运维能够准确地提出这样的需求,因为只有运维对线上的痛点最有感触,并且对系统的整体性把握度也最高),与周边团队形成指导和协作的状态;同时产品和系统落地使用后,我们能够通过产品和系统的使用和数据的分析,更好地指导应用和业务如何优化做设计和开发。我们认为这样一种协作模式才是真正的 DevOps,我们期望的 DevOps 是一种团队理念和协作模式,无时无刻不在我们的日常工作中体现着。
所以,只要是对业务发展和稳定性有益的事情,同时又是跟运维相关的,我们都是会支持的。如上所说,运维的同学如果能够很好的把握住设计和运营的方向,就非常容易成长为一位运维架构师甚至是业务架构师,从而也把自己的职业发展空间打开了。
当然,有些同学的技术能力非常强,喜欢钻研技术,从业务体量和并发量上说,我们的基础部件如 LVS、Nginx、JDK、Tomcat 等等都仍然有很大的优化空间,还有哪些非常好的技术可以落地来支持我们的业务,只要能落地,如果感兴趣,去搞吧。同时,一些前瞻性的技术,如数据分析、数据建模、机器学习,也是很好的学习方向。我们是 100% 鼓励技术专家的这个成长方向。
不过这里最后还是强调一点,我们做的任何事情和使用的技术,一定是从业务现状和问题出发去选择技术,而不能拿技术来要求业务进行适配。凡是不以业务为出发点或者不能够跟业务相结合的技术,就不会有生命力。切记!
InfoQ: 运维人员需要学习哪些知识去提高自己的价值呢?
赵成:对于运维新手们,一定要学习编程,数据结构、算法和设计模式一样很重要(未来的运维如果不懂开发、不懂架构,对于后面的发展极为不利);同时对于网络、硬件、OS 这些基础知识也要打好扎实的技术。我建议大家可以看看 Google SRE 这本书。这里想说的是,Google SRE 的要求是要比开发的要求要高很多的,不仅仅要具备开发能力,对网络、硬件、OS 这些也要具备才可以,不懂这些你只能当开发,是做不了 SRE 的,同时 SRE 还要定期与业务开发轮岗去写业务的代码,出现问题的时候 SRE 是可以不依赖开发直接改代码来解决问题的。
对于运维老司机们,因为工作背景的原因,在写代码上或许没什么优势,但是在这个行当里摸爬滚打这么多年的经验就是最宝贵的财富。不过怎么样能够更好地将经验转化成优势,就需要注重产品设计和系统规范能力;同时可以去主动学习一下大数据分析、机器学习这些前沿技术的应用,如何能够应用到日常工作中过来,也是会大作为的。
总体而言,运维的同学不要给自己设限,凡是跟工作相关的技术、原理和业务都可以深入下去摸个清楚,一段时间后,一定可以有成长。
InfoQ:感谢赵成老师接受我们的采访,期待 ArchSummit 全球架构师峰会上您策划的运维创造价值的时代专题。




